摘要
在雷达目标跟踪系统中,选择合适的运动模型和正确处理坐标转换是确保跟踪精度的关键。雷达观测通常在极坐标系(球坐标系)下进行,而目标运动模型通常在笛卡尔坐标系(直角坐标系)中描述。这种坐标系的差异带来了复杂的非线性问题。本文将从雷达目标跟踪的基本原理出发,详细讲解常用运动模型(CV、CA、CTRV、CTRA)的数学推导,深入分析坐标转换的误差传播特性,并通过多个完整的Python示例演示如何在实际跟踪系统中应用这些技术。
目录
-
雷达目标跟踪系统概述
-
常用运动模型详解
-
坐标转换的数学原理
-
运动模型在卡尔曼滤波中的应用
-
交互多模型(IMM)滤波
-
Demo 3-1:不同运动模型对比
-
Demo 3-2:极坐标到笛卡尔坐标转换跟踪
-
Demo 3-3:交互多模型滤波实现
-
总结与工程实践建议
1. 雷达目标跟踪系统概述
1.1 雷达目标跟踪的基本流程
雷达目标跟踪是一个典型的状态估计问题,其基本流程包括:数据采集、点迹提取、坐标转换、数据关联、状态估计和航迹管理等环节。
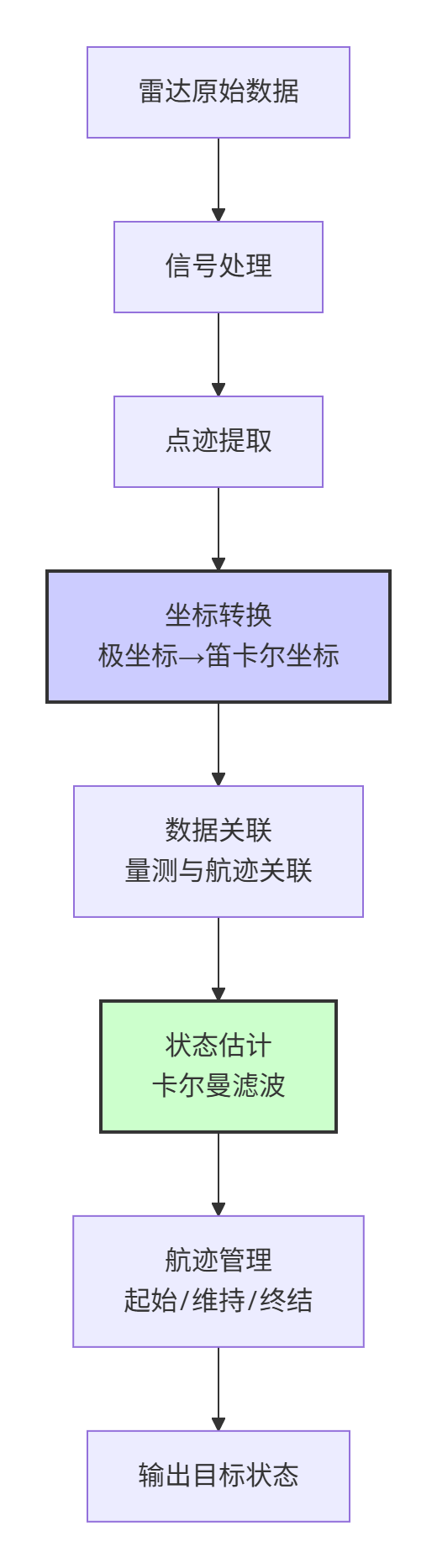
1.2 雷达观测的物理特性
现代雷达系统通常提供以下观测信息:
-
距离(Range):目标到雷达的直线距离
-
方位角(Azimuth):目标在水平面上的方向角
-
俯仰角(Elevation):目标在垂直面上的仰角
-
多普勒频率(Doppler):目标径向速度引起的频率偏移
-
信噪比(SNR):目标回波强度
在二维平面跟踪中,我们通常只考虑距离和方位角;在三维空间跟踪中,还需要考虑俯仰角。
1.3 目标跟踪的数学框架
目标跟踪问题可以形式化为一个状态估计问题:
系统模型:
2. 常用运动模型详解
运动模型描述了目标状态随时间的变化规律。选择合适的运动模型对跟踪性能至关重要。
2.1 匀速模型(Constant Velocity, CV)
匀速模型假设目标在采样间隔内保持匀速直线运动。这是最简单的运动模型,适用于匀速或近似匀速运动的目标。
2.1.1 二维CV模型
在二维平面中,CV模型的状态向量通常包含位置和速度:

2.1.2 三维CV模型
在三维空间中,CV模型的状态向量为:

2.2 匀加速模型(Constant Acceleration, CA)
匀加速模型假设目标在采样间隔内保持匀加速运动。适用于加速或减速运动的目标。
2.2.1 二维CA模型
在二维平面中,CA模型的状态向量包含位置、速度和加速度:

2.3 恒定转率和速度模型(Constant Turn Rate and Velocity, CTRV)
CTRV模型假设目标以恒定速度和恒定转率运动。适用于转弯机动的目标,是雷达目标跟踪中最常用的模型之一。
2.3.1 CTRV模型的状态向量
CTRV模型的状态向量为:

2.3.2 CTRV模型的状态转移

.4 恒定转率和加速度模型(Constant Turn Rate and Acceleration, CTRA)
CTRA模型是CTRV模型的扩展,增加了切向加速度。适用于同时进行转弯和加速/减速的目标。
2.4.1 CTRA模型的状态向量
CTRA模型的状态向量为:

2.4.2 CTRA模型的状态转移

2.5 运动模型对比
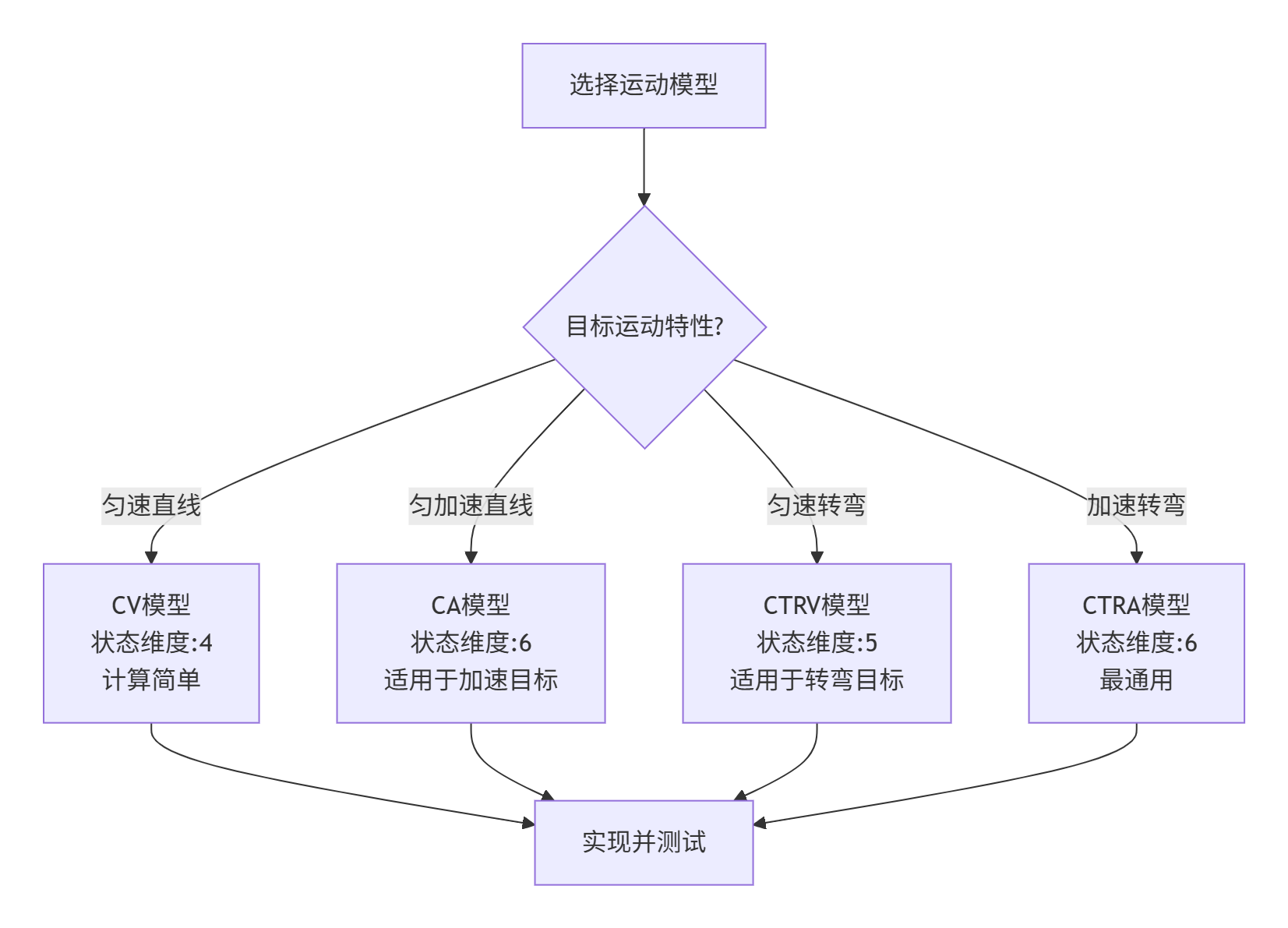
| 模型 | 状态维度 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| CV | 4(2D)/6(3D) | 匀速直线运动 | 计算简单,数值稳定 | 无法描述机动 |
| CA | 6(2D)/9(3D) | 匀加速直线运动 | 可描述加速运动 | 对转弯运动描述差 |
| CTRV | 5(2D) | 匀速转弯运动 | 准确描述转弯运动 | 不能描述加速 |
| CTRA | 6(2D) | 加速转弯运动 | 最通用的模型 | 计算复杂 |
3. 坐标转换的数学原理
雷达观测通常在极坐标系下,而目标运动模型在笛卡尔坐标系中描述。坐标转换是雷达目标跟踪中的关键步骤。
3.1 二维坐标转换
3.1.1 极坐标到笛卡尔坐标

3.1.2 笛卡尔坐标到极坐标
从笛卡尔坐标到极坐标的逆转换

3.2 三维坐标转换
3.2.1 球坐标到笛卡尔坐标

3.2.2 笛卡尔坐标到球坐标
逆转换:
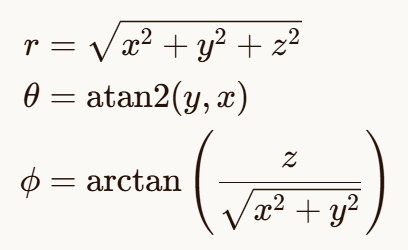
3.3 坐标转换的误差传播
坐标转换会引入非线性误差。考虑带有噪声的雷达观测:

3.3.1 二维情况下的误差传播
在二维情况下,转换后的笛卡尔坐标为:

3.3.2 误差椭球分析
转换后的位置误差在二维平面上形成一个误差椭球。误差椭球的主轴方向由协方差矩阵的特征向量决定,主轴长度由特征值决定。

3.4 去偏转换(Unbiased Conversion)
简单的三角转换会导致有偏估计。去偏转换通过修正偏差来提高估计精度。
3.4.1 二维去偏转换
对于二维极坐标到笛卡尔坐标的转换,去偏估计为:
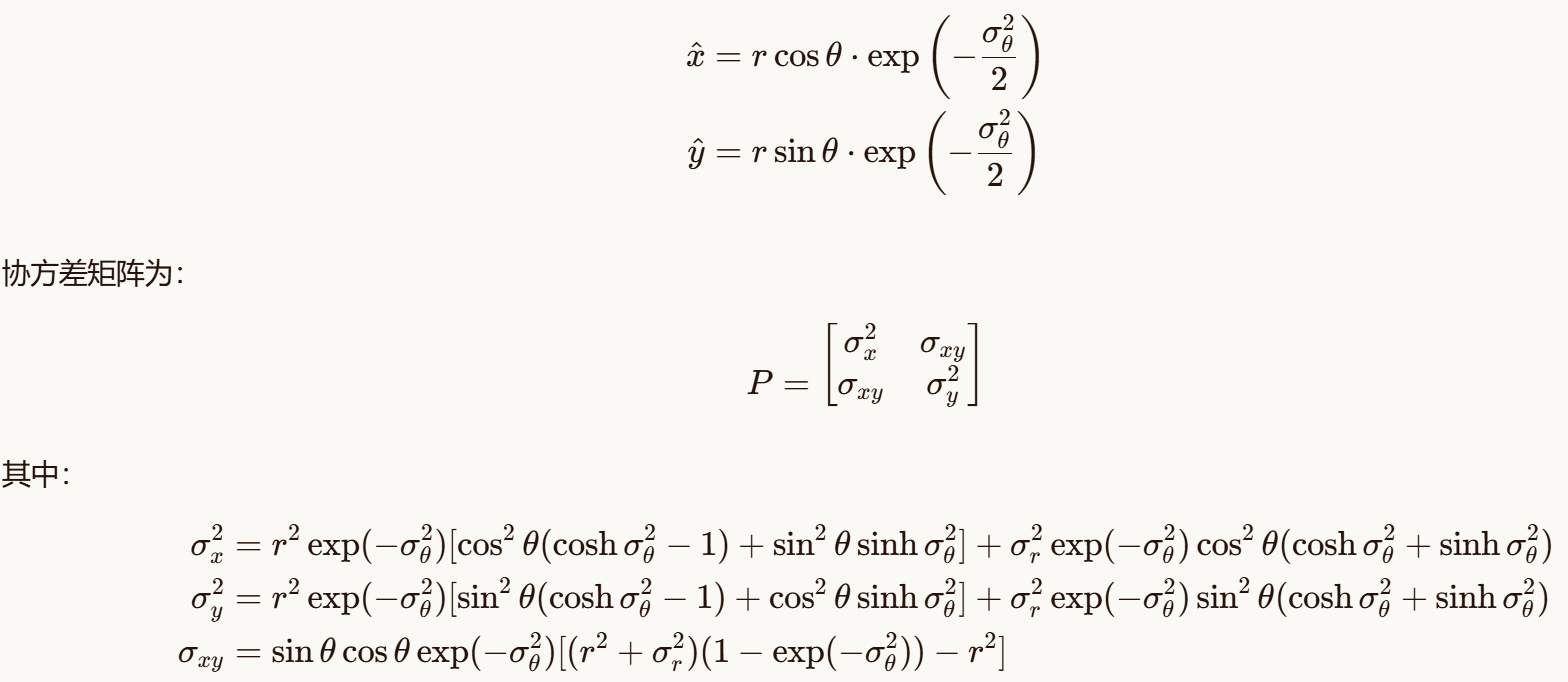
4. 运动模型在卡尔曼滤波中的应用
运动模型是卡尔曼滤波器的核心组成部分。不同的运动模型对应不同的状态转移矩阵和过程噪声矩阵。
4.1 线性运动模型的卡尔曼滤波
对于线性运动模型(如CV、CA),可以直接使用标准卡尔曼滤波。
4.1.1 CV模型的卡尔曼滤波实现
python
import numpy as np
from typing import Optional, Tuple
class CVKalmanFilter:
"""匀速模型卡尔曼滤波器"""
def __init__(self, dt: float, q: float = 1.0):
"""
初始化CV模型卡尔曼滤波器
参数:
dt: 采样间隔
q: 过程噪声强度
"""
self.dt = dt
self.q = q
# 状态维度: [x, y, vx, vy]
self.state_dim = 4
# 状态转移矩阵
self.F = np.array([
[1, 0, dt, 0],
[0, 1, 0, dt],
[0, 0, 1, 0],
[0, 0, 0, 1]
])
# 过程噪声协方差矩阵
self.Q = np.array([
[dt**4/4, 0, dt**3/2, 0],
[0, dt**4/4, 0, dt**3/2],
[dt**3/2, 0, dt**2, 0],
[0, dt**3/2, 0, dt**2]
]) * q
# 状态和协方差初始化
self.x = np.zeros((self.state_dim, 1))
self.P = np.eye(self.state_dim) * 1000
def predict(self) -> Tuple[np.ndarray, np.ndarray]:
"""预测步骤"""
self.x = self.F @ self.x
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x.copy(), self.P.copy()
def update(self, z: np.ndarray, R: np.ndarray, H: Optional[np.ndarray] = None) -> Tuple[np.ndarray, np.ndarray]:
"""
更新步骤
参数:
z: 观测向量 (2×1) [x, y]
R: 观测噪声协方差 (2×2)
H: 观测矩阵 (如果为None,则使用默认值)
"""
if H is None:
H = np.array([
[1, 0, 0, 0],
[0, 1, 0, 0]
])
# 计算卡尔曼增益
S = H @ self.P @ H.T + R
K = self.P @ H.T @ np.linalg.inv(S)
# 状态更新
y = z.reshape(-1, 1) - H @ self.x
self.x = self.x + K @ y
# 协方差更新
I = np.eye(self.state_dim)
self.P = (I - K @ H) @ self.P @ (I - K @ H).T + K @ R @ K.T
return self.x.copy(), self.P.copy()4.2 非线性运动模型的扩展卡尔曼滤波
对于非线性运动模型(如CTRV、CTRA),需要使用扩展卡尔曼滤波(EKF)或无迹卡尔曼滤波(UKF)。
4.2.1 CTRV模型的EKF实现
python
import numpy as np
from typing import Optional, Tuple
class CTRVEKF:
"""CTRV模型扩展卡尔曼滤波器"""
def __init__(self, dt: float, q_pos: float = 1.0, q_vel: float = 0.1, q_yawrate: float = 0.01):
"""
初始化CTRV模型EKF
参数:
dt: 采样间隔
q_pos: 位置过程噪声强度
q_vel: 速度过程噪声强度
q_yawrate: 转率过程噪声强度
"""
self.dt = dt
# 状态维度: [x, y, v, psi, psi_dot]
self.state_dim = 5
# 过程噪声强度
self.q_pos = q_pos
self.q_vel = q_vel
self.q_yawrate = q_yawrate
# 状态和协方差初始化
self.x = np.zeros((self.state_dim, 1))
self.P = np.eye(self.state_dim)
self.P[0, 0] = self.P[1, 1] = 1000 # 位置初始不确定性大
self.P[2, 2] = 100 # 速度初始不确定性
self.P[3, 3] = np.pi # 航向角初始不确定性
self.P[4, 4] = np.pi/2 # 转率初始不确定性
def predict(self) -> Tuple[np.ndarray, np.ndarray]:
"""预测步骤"""
# 提取状态
x, y, v, psi, psi_dot = self.x.flatten()
# 状态转移
if abs(psi_dot) < 1e-6: # 直线运动
x_pred = x + v * self.dt * np.cos(psi)
y_pred = y + v * self.dt * np.sin(psi)
v_pred = v
psi_pred = psi
psi_dot_pred = 0
else: # 转弯运动
x_pred = x + (v/psi_dot) * (np.sin(psi + psi_dot*self.dt) - np.sin(psi))
y_pred = y + (v/psi_dot) * (-np.cos(psi + psi_dot*self.dt) + np.cos(psi))
v_pred = v
psi_pred = psi + psi_dot * self.dt
psi_dot_pred = psi_dot
# 归一化航向角到[-π, π]
psi_pred = (psi_pred + np.pi) % (2*np.pi) - np.pi
self.x = np.array([[x_pred], [y_pred], [v_pred], [psi_pred], [psi_dot_pred]])
# 计算雅可比矩阵
F = self.compute_jacobian()
# 过程噪声协方差
Q = np.diag([self.q_pos, self.q_pos, self.q_vel, 0.1, self.q_yawrate])
# 协方差预测
self.P = F @ self.P @ F.T + Q
return self.x.copy(), self.P.copy()
def compute_jacobian(self) -> np.ndarray:
"""计算状态转移雅可比矩阵"""
x, y, v, psi, psi_dot = self.x.flatten()
F = np.eye(self.state_dim)
if abs(psi_dot) < 1e-6: # 直线运动
F[0, 2] = self.dt * np.cos(psi)
F[0, 3] = -v * self.dt * np.sin(psi)
F[1, 2] = self.dt * np.sin(psi)
F[1, 3] = v * self.dt * np.cos(psi)
else: # 转弯运动
dt = self.dt
F[0, 2] = (1/psi_dot) * (np.sin(psi + psi_dot*dt) - np.sin(psi))
F[0, 3] = (v/psi_dot) * (np.cos(psi + psi_dot*dt) - np.cos(psi))
F[0, 4] = (v/psi_dot**2) * (psi_dot*dt*np.cos(psi + psi_dot*dt) - np.sin(psi + psi_dot*dt) + np.sin(psi))
F[1, 2] = (1/psi_dot) * (-np.cos(psi + psi_dot*dt) + np.cos(psi))
F[1, 3] = (v/psi_dot) * (np.sin(psi + psi_dot*dt) - np.sin(psi))
F[1, 4] = (v/psi_dot**2) * (psi_dot*dt*np.sin(psi + psi_dot*dt) + np.cos(psi + psi_dot*dt) - np.cos(psi))
F[3, 4] = dt
return F
def update(self, z: np.ndarray, R: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""
更新步骤(假设观测位置)
参数:
z: 观测向量 (2×1) [x, y]
R: 观测噪声协方差 (2×2)
"""
# 观测矩阵
H = np.array([
[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0]
])
# 预测观测
z_pred = H @ self.x
# 计算卡尔曼增益
S = H @ self.P @ H.T + R
K = self.P @ H.T @ np.linalg.inv(S)
# 状态更新
y = z.reshape(-1, 1) - z_pred
self.x = self.x + K @ y
# 归一化航向角
self.x[3, 0] = (self.x[3, 0] + np.pi) % (2*np.pi) - np.pi
# 协方差更新
I = np.eye(self.state_dim)
self.P = (I - K @ H) @ self.P @ (I - K @ H).T + K @ R @ K.T
return self.x.copy(), self.P.copy()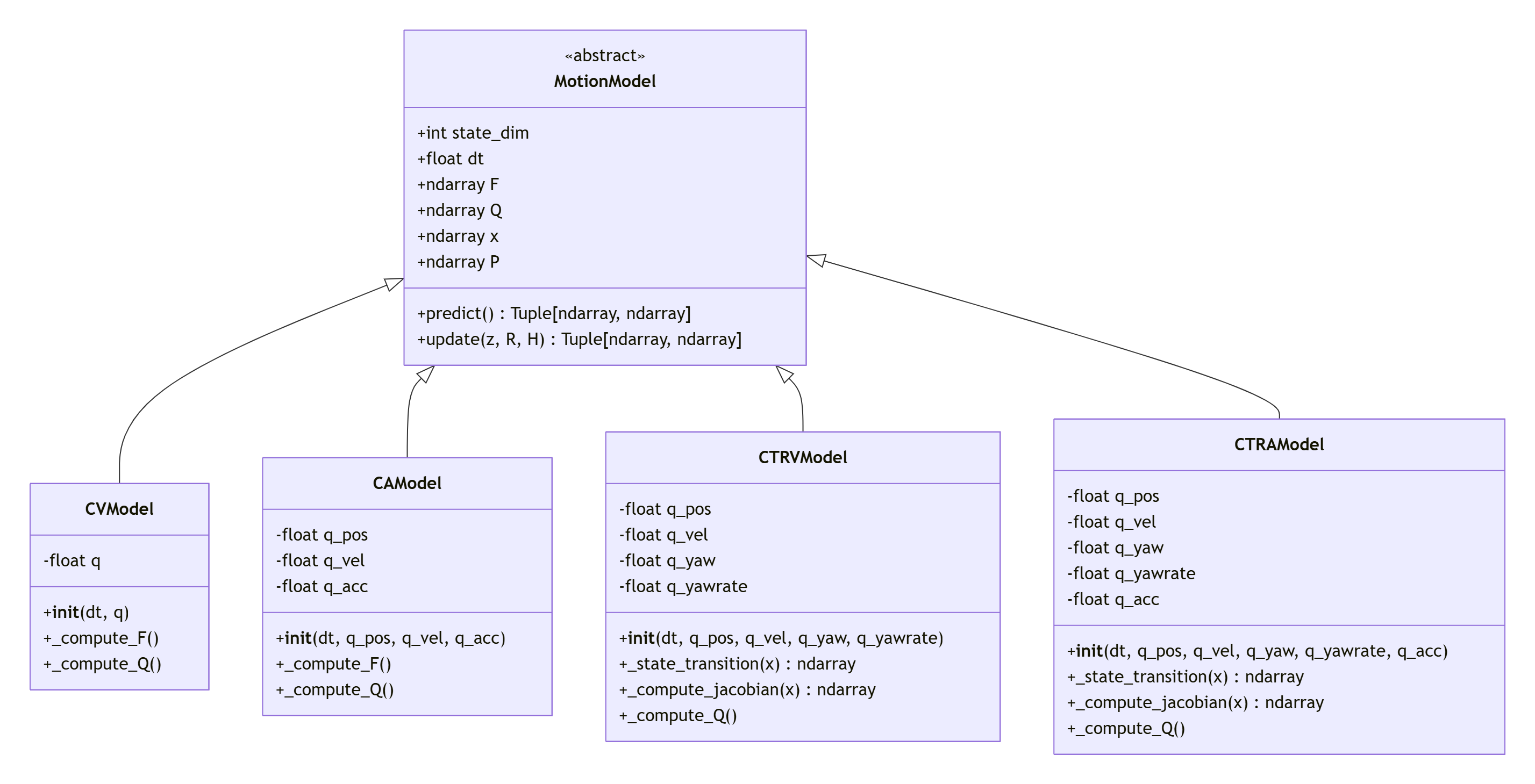
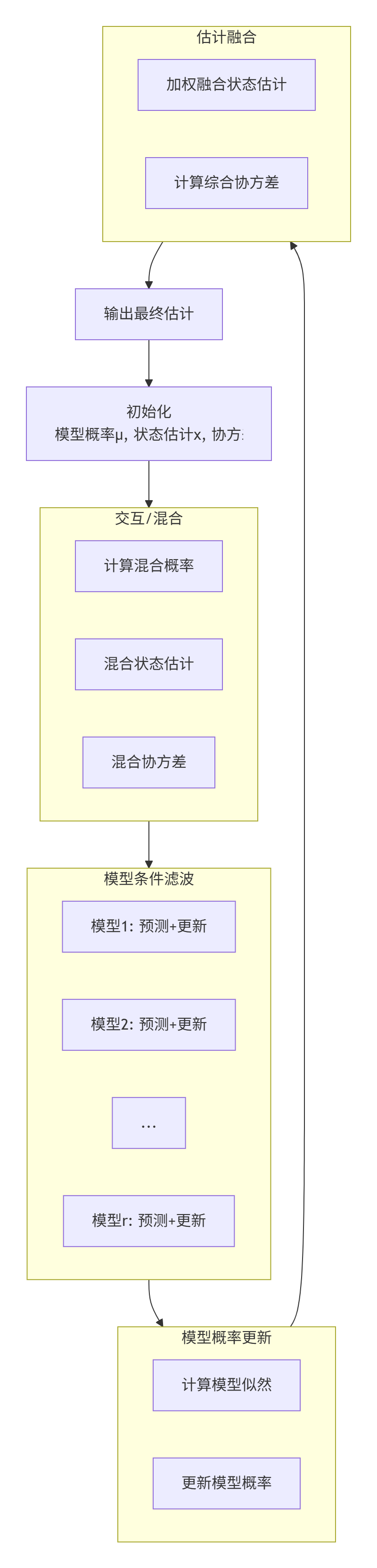
5. 交互多模型(IMM)滤波
单一运动模型往往难以准确描述复杂机动目标的运动。交互多模型(Interacting Multiple Model, IMM)滤波通过混合多个模型来适应目标的不同运动模式。
5.1 IMM滤波的基本原理
IMM滤波通过以下步骤实现:
-
交互/混合:根据模型概率混合上一时刻的模型条件估计
-
模型条件滤波:每个模型独立进行预测和更新
-
模型概率更新:根据模型似然更新模型概率
-
估计融合:混合各模型的估计得到最终估计
5.2 IMM滤波的数学描述

5.2.2 模型条件滤波

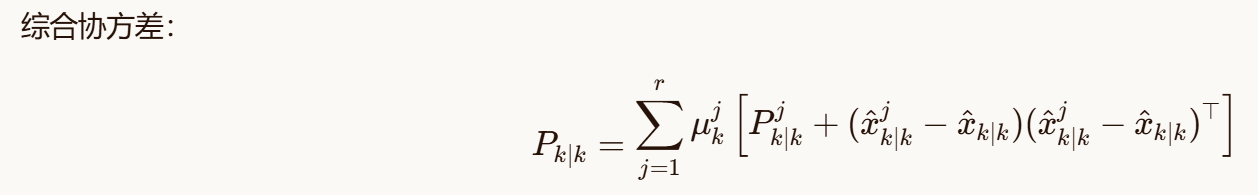
5.3 IMM滤波的Python实现
python
import numpy as np
from typing import List, Tuple, Dict
from dataclasses import dataclass
from abc import ABC, abstractmethod
@dataclass
class ModelResult:
"""模型滤波结果"""
x: np.ndarray # 状态估计
P: np.ndarray # 协方差矩阵
z_pred: np.ndarray # 预测观测
S: np.ndarray # 新息协方差
likelihood: float # 模型似然
class BaseFilter(ABC):
"""滤波器基类"""
def __init__(self, state_dim: int):
self.state_dim = state_dim
self.x = np.zeros((state_dim, 1))
self.P = np.eye(state_dim)
@abstractmethod
def predict(self) -> Tuple[np.ndarray, np.ndarray]:
"""预测步骤"""
pass
@abstractmethod
def update(self, z: np.ndarray, R: np.ndarray) -> ModelResult:
"""更新步骤"""
pass
class IMMFilter:
"""交互多模型滤波器"""
def __init__(self, filters: List[BaseFilter],
model_prob: np.ndarray,
trans_prob: np.ndarray):
"""
初始化IMM滤波器
参数:
filters: 滤波器列表
model_prob: 初始模型概率
trans_prob: 模型转移概率矩阵
"""
self.filters = filters
self.num_models = len(filters)
self.mu = model_prob # 模型概率
self.pi = trans_prob # 转移概率矩阵
# 检查维度
assert len(model_prob) == self.num_models, "模型概率维度不匹配"
assert trans_prob.shape == (self.num_models, self.num_models), "转移概率矩阵维度不匹配"
# 状态维度(假设所有滤波器状态维度相同)
self.state_dim = filters[0].state_dim
# 存储各模型的历史结果
self.model_results = [None] * self.num_models
def step(self, z: np.ndarray, R: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""
执行一步IMM滤波
参数:
z: 观测向量
R: 观测噪声协方差
返回:
x_fused: 融合状态估计
P_fused: 融合协方差矩阵
"""
# 1. 交互/混合
mixed_states, mixed_covs = self._interaction()
# 2. 模型条件滤波
model_likelihoods = np.zeros(self.num_models)
for j in range(self.num_models):
# 设置混合后的状态和协方差
self.filters[j].x = mixed_states[j]
self.filters[j].P = mixed_covs[j]
# 执行预测和更新
self.filters[j].predict()
result = self.filters[j].update(z, R)
self.model_results[j] = result
# 保存模型似然
model_likelihoods[j] = result.likelihood
# 3. 模型概率更新
self._update_model_probabilities(model_likelihoods)
# 4. 估计融合
x_fused, P_fused = self._fusion()
return x_fused, P_fused
def _interaction(self) -> Tuple[List[np.ndarray], List[np.ndarray]]:
"""交互/混合步骤"""
# 计算混合概率
c_bar = np.zeros(self.num_models)
for j in range(self.num_models):
c_bar[j] = np.sum(self.pi[:, j] * self.mu)
mu_mixed = np.zeros((self.num_models, self.num_models))
for i in range(self.num_models):
for j in range(self.num_models):
mu_mixed[i, j] = self.pi[i, j] * self.mu[i] / c_bar[j]
# 混合状态和协方差
mixed_states = []
mixed_covs = []
for j in range(self.num_models):
# 初始化混合状态
x_mixed = np.zeros((self.state_dim, 1))
for i in range(self.num_models):
x_mixed += mu_mixed[i, j] * self.filters[i].x
# 初始化混合协方差
P_mixed = np.zeros((self.state_dim, self.state_dim))
for i in range(self.num_models):
dx = self.filters[i].x - x_mixed
P_mixed += mu_mixed[i, j] * (self.filters[i].P + dx @ dx.T)
mixed_states.append(x_mixed)
mixed_covs.append(P_mixed)
return mixed_states, mixed_covs
def _update_model_probabilities(self, likelihoods: np.ndarray):
"""更新模型概率"""
# 计算归一化常数
c = np.sum(likelihoods * np.sum(self.pi * self.mu, axis=0))
# 更新模型概率
if c > 1e-10: # 避免除以零
self.mu = (likelihoods * np.sum(self.pi * self.mu, axis=0)) / c
else:
# 如果c太小,保持原概率
pass
# 确保概率和为1
self.mu = self.mu / np.sum(self.mu)
def _fusion(self) -> Tuple[np.ndarray, np.ndarray]:
"""估计融合"""
# 初始化融合状态和协方差
x_fused = np.zeros((self.state_dim, 1))
for j in range(self.num_models):
x_fused += self.mu[j] * self.model_results[j].x
P_fused = np.zeros((self.state_dim, self.state_dim))
for j in range(self.num_models):
dx = self.model_results[j].x - x_fused
P_fused += self.mu[j] * (self.model_results[j].P + dx @ dx.T)
return x_fused, P_fused
def get_model_probabilities(self) -> np.ndarray:
"""获取当前模型概率"""
return self.mu.copy()6. Demo 3-1:不同运动模型对比
这个Demo将比较CV、CA、CTRV、CTRA四种运动模型在不同机动场景下的跟踪性能。
python
"""
demo_3_1_motion_models_comparison.py
不同运动模型对比分析
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 运动模型实现
class CVFilter:
"""匀速模型卡尔曼滤波器"""
def __init__(self, dt=1.0, q=0.1):
self.dt = dt
self.state_dim = 4 # [x, y, vx, vy]
# 状态转移矩阵
self.F = np.array([
[1, 0, dt, 0],
[0, 1, 0, dt],
[0, 0, 1, 0],
[0, 0, 0, 1]
])
# 过程噪声协方差
self.Q = np.array([
[dt**4/4, 0, dt**3/2, 0],
[0, dt**4/4, 0, dt**3/2],
[dt**3/2, 0, dt**2, 0],
[0, dt**3/2, 0, dt**2]
]) * q
# 初始状态
self.x = np.zeros((4, 1))
self.P = np.eye(4) * 100
def predict(self):
self.x = self.F @ self.x
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x.copy(), self.P.copy()
def update(self, z, R):
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
# 卡尔曼增益
S = H @ self.P @ H.T + R
K = self.P @ H.T @ np.linalg.inv(S)
# 状态更新
y = z.reshape(-1, 1) - H @ self.x
self.x = self.x + K @ y
# 协方差更新
I = np.eye(self.state_dim)
self.P = (I - K @ H) @ self.P @ (I - K @ H).T + K @ R @ K.T
return self.x.copy(), self.P.copy()
class CAFilter:
"""匀加速模型卡尔曼滤波器"""
def __init__(self, dt=1.0, q=0.1):
self.dt = dt
self.state_dim = 6 # [x, y, vx, vy, ax, ay]
# 状态转移矩阵
self.F = np.array([
[1, 0, dt, 0, 0.5*dt**2, 0],
[0, 1, 0, dt, 0, 0.5*dt**2],
[0, 0, 1, 0, dt, 0],
[0, 0, 0, 1, 0, dt],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1]
])
# 过程噪声协方差
Q_pos = dt**4/4
Q_vel = dt**3/2
Q_acc = dt**2
self.Q = np.array([
[Q_pos, 0, Q_vel, 0, 0.5*Q_acc, 0],
[0, Q_pos, 0, Q_vel, 0, 0.5*Q_acc],
[Q_vel, 0, Q_acc, 0, dt, 0],
[0, Q_vel, 0, Q_acc, 0, dt],
[0.5*Q_acc, 0, dt, 0, 1, 0],
[0, 0.5*Q_acc, 0, dt, 0, 1]
]) * q
# 初始状态
self.x = np.zeros((6, 1))
self.P = np.eye(6) * 100
def predict(self):
self.x = self.F @ self.x
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x.copy(), self.P.copy()
def update(self, z, R):
H = np.array([[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0]])
# 卡尔曼增益
S = H @ self.P @ H.T + R
K = self.P @ H.T @ np.linalg.inv(S)
# 状态更新
y = z.reshape(-1, 1) - H @ self.x
self.x = self.x + K @ y
# 协方差更新
I = np.eye(self.state_dim)
self.P = (I - K @ H) @ self.P @ (I - K @ H).T + K @ R @ K.T
return self.x.copy(), self.P.copy()
class CTRVFilter:
"""CTRV模型扩展卡尔曼滤波器"""
def __init__(self, dt=1.0, q_pos=0.1, q_vel=0.01, q_yaw=0.1, q_yawrate=0.01):
self.dt = dt
self.state_dim = 5 # [x, y, v, psi, psi_dot]
# 过程噪声参数
self.q_pos = q_pos
self.q_vel = q_vel
self.q_yaw = q_yaw
self.q_yawrate = q_yawrate
# 初始状态
self.x = np.zeros((5, 1))
self.P = np.eye(5) * 100
self.P[2, 2] = 10
self.P[3, 3] = np.pi
self.P[4, 4] = np.pi/2
def predict(self):
x, y, v, psi, psi_dot = self.x.flatten()
dt = self.dt
# 状态转移
if abs(psi_dot) < 1e-6:
x_pred = x + v * dt * np.cos(psi)
y_pred = y + v * dt * np.sin(psi)
v_pred = v
psi_pred = psi
psi_dot_pred = 0
else:
x_pred = x + (v/psi_dot) * (np.sin(psi + psi_dot*dt) - np.sin(psi))
y_pred = y + (v/psi_dot) * (-np.cos(psi + psi_dot*dt) + np.cos(psi))
v_pred = v
psi_pred = psi + psi_dot * dt
psi_dot_pred = psi_dot
# 归一化航向角
psi_pred = (psi_pred + np.pi) % (2*np.pi) - np.pi
self.x = np.array([[x_pred], [y_pred], [v_pred], [psi_pred], [psi_dot_pred]])
# 计算雅可比矩阵
F = self._compute_jacobian()
# 过程噪声协方差
Q = np.diag([self.q_pos, self.q_pos, self.q_vel, self.q_yaw, self.q_yawrate])
# 协方差预测
self.P = F @ self.P @ F.T + Q
return self.x.copy(), self.P.copy()
def _compute_jacobian(self):
x, y, v, psi, psi_dot = self.x.flatten()
dt = self.dt
F = np.eye(5)
if abs(psi_dot) < 1e-6:
F[0, 2] = dt * np.cos(psi)
F[0, 3] = -v * dt * np.sin(psi)
F[1, 2] = dt * np.sin(psi)
F[1, 3] = v * dt * np.cos(psi)
else:
F[0, 2] = (1/psi_dot) * (np.sin(psi + psi_dot*dt) - np.sin(psi))
F[0, 3] = (v/psi_dot) * (np.cos(psi + psi_dot*dt) - np.cos(psi))
F[0, 4] = (v/psi_dot**2) * (psi_dot*dt*np.cos(psi + psi_dot*dt) -
np.sin(psi + psi_dot*dt) + np.sin(psi))
F[1, 2] = (1/psi_dot) * (-np.cos(psi + psi_dot*dt) + np.cos(psi))
F[1, 3] = (v/psi_dot) * (np.sin(psi + psi_dot*dt) - np.sin(psi))
F[1, 4] = (v/psi_dot**2) * (psi_dot*dt*np.sin(psi + psi_dot*dt) +
np.cos(psi + psi_dot*dt) - np.cos(psi))
F[3, 4] = dt
return F
def update(self, z, R):
H = np.array([[1, 0, 0, 0, 0], [0, 1, 0, 0, 0]])
# 卡尔曼增益
S = H @ self.P @ H.T + R
K = self.P @ H.T @ np.linalg.inv(S)
# 状态更新
y = z.reshape(-1, 1) - H @ self.x
self.x = self.x + K @ y
# 归一化航向角
self.x[3, 0] = (self.x[3, 0] + np.pi) % (2*np.pi) - np.pi
# 协方差更新
I = np.eye(self.state_dim)
self.P = (I - K @ H) @ self.P @ (I - K @ H).T + K @ R @ K.T
return self.x.copy(), self.P.copy()
def generate_trajectory(scenario='straight', num_steps=200, dt=1.0):
"""
生成不同场景的轨迹
参数:
scenario: 场景类型 ('straight', 'turn', 'acceleration', 'complex')
num_steps: 时间步数
dt: 时间间隔
"""
true_states = []
if scenario == 'straight':
# 匀速直线运动
x, y = 0, 0
vx, vy = 10, 5
for t in range(num_steps):
true_states.append([x, y, vx, vy, 0, 0])
x += vx * dt
y += vy * dt
elif scenario == 'turn':
# 匀速圆周运动
radius = 100
omega = 0.05 # 角速度
for t in range(num_steps):
angle = omega * t * dt
x = radius * np.cos(angle)
y = radius * np.sin(angle)
vx = -radius * omega * np.sin(angle)
vy = radius * omega * np.cos(angle)
ax = -radius * omega**2 * np.cos(angle)
ay = -radius * omega**2 * np.sin(angle)
true_states.append([x, y, vx, vy, ax, ay])
elif scenario == 'acceleration':
# 匀加速直线运动
x, y = 0, 0
vx, vy = 5, 3
ax, ay = 0.1, 0.05
for t in range(num_steps):
true_states.append([x, y, vx, vy, ax, ay])
x += vx * dt + 0.5 * ax * dt**2
y += vy * dt + 0.5 * ay * dt**2
vx += ax * dt
vy += ay * dt
elif scenario == 'complex':
# 复杂机动:直线→转弯→加速
x, y = 0, 0
v, psi = 10, 0
a = 0
psi_dot = 0
for t in range(num_steps):
# 分段机动
if t < 50:
# 匀速直线
psi_dot = 0
a = 0
elif t < 100:
# 匀速转弯
psi_dot = 0.05
a = 0
elif t < 150:
# 加速直线
psi_dot = 0
a = 0.2
else:
# 减速转弯
psi_dot = -0.03
a = -0.1
# 状态更新
v += a * dt
psi += psi_dot * dt
# 归一化航向角
psi = (psi + np.pi) % (2*np.pi) - np.pi
# 计算位置
x += v * dt * np.cos(psi)
y += v * dt * np.sin(psi)
# 计算速度和加速度
vx = v * np.cos(psi)
vy = v * np.sin(psi)
ax = a * np.cos(psi) - v * psi_dot * np.sin(psi)
ay = a * np.sin(psi) + v * psi_dot * np.cos(psi)
true_states.append([x, y, vx, vy, ax, ay])
true_states = np.array(true_states)
return true_states
def add_measurement_noise(true_states, pos_noise_std=5.0):
"""添加测量噪声"""
measurements = true_states[:, :2] + np.random.randn(len(true_states), 2) * pos_noise_std
return measurements
def run_comparison(scenario='straight'):
"""运行运动模型对比"""
np.random.seed(42)
# 生成轨迹
print(f"生成{scenario}场景轨迹...")
true_states = generate_trajectory(scenario, num_steps=200, dt=1.0)
# 添加测量噪声
pos_noise_std = 5.0
measurements = add_measurement_noise(true_states, pos_noise_std)
R = np.eye(2) * pos_noise_std**2
# 初始化滤波器
filters = {
'CV': CVFilter(dt=1.0, q=0.1),
'CA': CAFilter(dt=1.0, q=0.1),
'CTRV': CTRVFilter(dt=1.0, q_pos=0.1, q_vel=0.01, q_yaw=0.1, q_yawrate=0.01)
}
# 运行滤波
estimates = {name: [] for name in filters}
position_errors = {name: [] for name in filters}
for name, filter_obj in filters.items():
print(f"运行{name}滤波器...")
# 初始化状态(使用第一个测量值)
filter_obj.x[0, 0] = measurements[0, 0]
filter_obj.x[1, 0] = measurements[0, 1]
for t in range(len(measurements)):
# 预测
filter_obj.predict()
# 更新
z = measurements[t, :2]
x_est, _ = filter_obj.update(z, R)
estimates[name].append(x_est.flatten())
# 计算位置误差
if t < len(true_states):
pos_error = np.sqrt((x_est[0, 0] - true_states[t, 0])**2 +
(x_est[1, 0] - true_states[t, 1])**2)
position_errors[name].append(pos_error)
# 转换估计结果为数组
for name in estimates:
estimates[name] = np.array(estimates[name])
# 计算性能指标
performance = {}
for name in filters:
errors = position_errors[name]
performance[name] = {
'rmse': np.sqrt(np.mean(np.array(errors)**2)),
'mae': np.mean(np.abs(errors)),
'max_error': np.max(np.abs(errors))
}
# 可视化结果
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 轨迹对比
ax = axes[0, 0]
ax.plot(true_states[:, 0], true_states[:, 1], 'k-', linewidth=3,
label='真实轨迹', alpha=0.8)
ax.plot(measurements[:, 0], measurements[:, 1], 'y.', markersize=2,
alpha=0.3, label='观测值')
colors = {'CV': 'blue', 'CA': 'green', 'CTRV': 'red'}
for name in filters:
ax.plot(estimates[name][:, 0], estimates[name][:, 1],
'-', linewidth=1.5, color=colors[name], label=name)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title(f'{scenario}场景轨迹跟踪对比')
ax.legend()
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2. 位置误差对比
ax = axes[0, 1]
t = np.arange(len(position_errors['CV']))
for name in filters:
ax.plot(t, position_errors[name],
'-', linewidth=1, color=colors[name],
label=f'{name} (RMSE={performance[name]["rmse"]:.2f})')
ax.set_xlabel('时间步')
ax.set_ylabel('位置误差')
ax.set_title('位置误差对比')
ax.legend()
ax.grid(True, alpha=0.3)
# 3. 速度估计对比(X方向)
ax = axes[0, 2]
t = np.arange(len(true_states))
ax.plot(t, true_states[:, 2], 'k-', linewidth=2, label='真实速度', alpha=0.8)
for name in filters:
if name == 'CTRV':
# CTRV估计的是速度大小和方向,需要转换为vx, vy
v_est = estimates[name][:, 2]
psi_est = estimates[name][:, 3]
vx_est = v_est * np.cos(psi_est)
else:
vx_est = estimates[name][:, 2]
ax.plot(t[:len(vx_est)], vx_est, '-', linewidth=1, color=colors[name], label=f'{name}估计')
ax.set_xlabel('时间步')
ax.set_ylabel('X方向速度')
ax.set_title('X方向速度估计对比')
ax.legend()
ax.grid(True, alpha=0.3)
# 4. 累积误差分布
ax = axes[1, 0]
error_data = []
labels = []
for name in filters:
error_data.append(position_errors[name])
labels.append(name)
bp = ax.boxplot(error_data, labels=labels, patch_artist=True)
# 设置颜色
for patch, color in zip(bp['boxes'], colors.values()):
patch.set_facecolor(color)
patch.set_alpha(0.7)
ax.set_ylabel('位置误差')
ax.set_title('位置误差分布')
ax.grid(True, alpha=0.3, axis='y')
# 5. 模型适应性分析
ax = axes[1, 1]
# 计算滑动窗口RMSE
window_size = 20
sliding_rmse = {name: [] for name in filters}
for name in filters:
errors = position_errors[name]
for i in range(len(errors) - window_size + 1):
window_errors = errors[i:i+window_size]
sliding_rmse[name].append(np.sqrt(np.mean(np.array(window_errors)**2)))
t_sliding = np.arange(len(sliding_rmse['CV']))
for name in filters:
ax.plot(t_sliding, sliding_rmse[name],
'-', linewidth=1.5, color=colors[name], label=name)
ax.set_xlabel('时间窗口中心')
ax.set_ylabel(f'滑动RMSE (窗口大小={window_size})')
ax.set_title('模型适应性分析')
ax.legend()
ax.grid(True, alpha=0.3)
# 6. 性能总结表
ax = axes[1, 2]
ax.axis('off')
# 创建性能表格
cell_text = []
for name in filters:
perf = performance[name]
cell_text.append([name,
f"{perf['rmse']:.2f}",
f"{perf['mae']:.2f}",
f"{perf['max_error']:.2f}"])
columns = ['模型', 'RMSE', 'MAE', '最大误差']
table = ax.table(cellText=cell_text, colLabels=columns,
cellLoc='center', loc='center',
colColours=['#f0f0f0']*4)
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 1.5)
ax.set_title('性能指标对比')
plt.suptitle(f'运动模型对比分析 - {scenario}场景', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig(f'motion_models_comparison_{scenario}.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印性能统计
print(f"\n{scenario}场景性能对比:")
print("-"*60)
print(f"{'模型':<10} {'RMSE':<10} {'MAE':<10} {'最大误差':<10}")
print("-"*60)
for name in filters:
perf = performance[name]
print(f"{name:<10} {perf['rmse']:<10.2f} {perf['mae']:<10.2f} {perf['max_error']:<10.2f}")
print("="*60)
return true_states, measurements, estimates, performance
def analyze_all_scenarios():
"""分析所有场景"""
scenarios = ['straight', 'turn', 'acceleration', 'complex']
all_performance = {}
for scenario in scenarios:
print(f"\n{'='*60}")
print(f"分析场景: {scenario}")
print('='*60)
true_states, measurements, estimates, performance = run_comparison(scenario)
all_performance[scenario] = performance
# 综合对比
print(f"\n{'='*60}")
print("综合性能对比")
print('='*60)
models = ['CV', 'CA', 'CTRV']
for model in models:
print(f"\n{model}模型在不同场景下的RMSE:")
for scenario in scenarios:
rmse = all_performance[scenario][model]['rmse']
print(f" {scenario:<15}: {rmse:.2f}")
# 绘制综合对比图
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 1. 各场景RMSE对比
ax = axes[0]
x = np.arange(len(scenarios))
width = 0.25
for i, model in enumerate(models):
rmses = [all_performance[scenario][model]['rmse'] for scenario in scenarios]
ax.bar(x + (i-1)*width, rmses, width, label=model, alpha=0.7)
ax.set_xlabel('场景')
ax.set_ylabel('RMSE')
ax.set_title('各场景RMSE对比')
ax.set_xticks(x)
ax.set_xticklabels(scenarios, rotation=15)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
# 2. 模型适应性评分
ax = axes[1]
# 计算适应性评分(RMSE越小,评分越高)
adaptability_scores = {model: 0 for model in models}
for scenario in scenarios:
# 找到该场景下最佳模型
best_rmse = min(all_performance[scenario][model]['rmse'] for model in models)
for model in models:
rmse = all_performance[scenario][model]['rmse']
# 评分 = 最佳RMSE / 当前RMSE
score = best_rmse / rmse if rmse > 0 else 1.0
adaptability_scores[model] += score
# 归一化评分
total_score = sum(adaptability_scores.values())
for model in models:
adaptability_scores[model] = adaptability_scores[model] / total_score * 100
# 绘制雷达图
ax = axes[1]
angles = np.linspace(0, 2*np.pi, len(scenarios), endpoint=False).tolist()
angles += angles[:1] # 闭合图形
for model in models:
scores = [all_performance[scenario][model]['rmse'] for scenario in scenarios]
# 转换为适应性分数(RMSE越小越好)
max_score = max(scores)
adapted_scores = [1 - (score/max_score) for score in scores]
adapted_scores += adapted_scores[:1] # 闭合图形
ax.plot(angles, adapted_scores, 'o-', linewidth=2, label=model)
ax.fill(angles, adapted_scores, alpha=0.1)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(scenarios)
ax.set_ylim([0, 1])
ax.set_title('模型适应性雷达图')
ax.legend(loc='upper right')
ax.grid(True)
plt.suptitle('运动模型综合性能对比', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('motion_models_overall_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
return all_performance
if __name__ == "__main__":
print("="*60)
print("运动模型对比分析")
print("="*60)
# 分析单个场景
# true_states, measurements, estimates, performance = run_comparison('turn')
# 分析所有场景
all_performance = analyze_all_scenarios()
print("\n分析完成!")7. Demo 3-2:极坐标到笛卡尔坐标转换跟踪
这个Demo将展示在雷达目标跟踪中如何处理极坐标观测,包括简单的三角转换和去偏转换方法。
python
"""
demo_3_2_radar_coordinate_conversion.py
极坐标到笛卡尔坐标转换跟踪
完整版本,包含三种坐标转换方法的比较
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from demo_3_1_motion_models_comparison import CVFilter, CAFilter, CTRVFilter
def polar_to_cartesian(range_, bearing, radar_pos=(0, 0)):
"""
极坐标到笛卡尔坐标转换(简单三角转换)
参数:
range_: 距离
bearing: 方位角(弧度)
radar_pos: 雷达位置 (x, y)
返回:
x, y: 笛卡尔坐标
"""
x = radar_pos[0] + range_ * np.cos(bearing)
y = radar_pos[1] + range_ * np.sin(bearing)
return x, y
def polar_to_cartesian_unbiased(range_, bearing, range_var, bearing_var, radar_pos=(0, 0)):
"""
极坐标到笛卡尔坐标的去偏转换
参数:
range_: 距离
bearing: 方位角(弧度)
range_var: 距离方差
bearing_var: 方位角方差
radar_pos: 雷达位置 (x, y)
返回:
x, y: 去偏估计的笛卡尔坐标
cov: 协方差矩阵
"""
# 去偏转换
bias_correction = np.exp(-bearing_var/2)
x_unbiased = radar_pos[0] + range_ * np.cos(bearing) * bias_correction
y_unbiased = radar_pos[1] + range_ * np.sin(bearing) * bias_correction
# 计算协方差
cos_theta = np.cos(bearing)
sin_theta = np.sin(bearing)
cosh_var = np.cosh(bearing_var)
sinh_var = np.sinh(bearing_var)
var_x = (range_**2 * np.exp(-bearing_var) *
(cos_theta**2 * (cosh_var - 1) + sin_theta**2 * sinh_var) +
range_var * np.exp(-bearing_var) * cos_theta**2 * (cosh_var + sinh_var))
var_y = (range_**2 * np.exp(-bearing_var) *
(sin_theta**2 * (cosh_var - 1) + cos_theta**2 * sinh_var) +
range_var * np.exp(-bearing_var) * sin_theta**2 * (cosh_var + sinh_var))
cov_xy = (sin_theta * cos_theta * np.exp(-bearing_var) *
((range_**2 + range_var) * (1 - np.exp(-bearing_var)) - range_**2))
cov = np.array([[var_x, cov_xy], [cov_xy, var_y]])
return np.array([x_unbiased, y_unbiased]), cov
def polar_to_cartesian_linearized(range_, bearing, range_var, bearing_var, radar_pos=(0, 0)):
"""
极坐标到笛卡尔坐标的线性化转换
参数:
range_: 距离
bearing: 方位角(弧度)
range_var: 距离方差
bearing_var: 方位角方差
radar_pos: 雷达位置 (x, y)
返回:
x, y: 线性化估计的笛卡尔坐标
cov: 协方差矩阵
"""
# 线性化转换
x = radar_pos[0] + range_ * np.cos(bearing)
y = radar_pos[1] + range_ * np.sin(bearing)
# 计算雅可比矩阵
cos_theta = np.cos(bearing)
sin_theta = np.sin(bearing)
J = np.array([
[cos_theta, -range_ * sin_theta],
[sin_theta, range_ * cos_theta]
])
# 极坐标协方差矩阵
R_polar = np.diag([range_var, bearing_var])
# 通过误差传播计算笛卡尔坐标协方差
cov = J @ R_polar @ J.T
return np.array([x, y]), cov
def generate_radar_measurements(trajectory, radar_pos=(0, 0),
range_noise_std=5.0, bearing_noise_std=0.01):
"""
生成雷达测量值(极坐标)
参数:
trajectory: 真实轨迹,形状为 (n, 4) 或 (n, 2),包含位置
radar_pos: 雷达位置
range_noise_std: 距离噪声标准差
bearing_noise_std: 方位角噪声标准差
返回:
measurements_polar: 极坐标测量值 (range, bearing)
measurements_simple: 简单三角转换的笛卡尔坐标
measurements_unbiased: 去偏转换的笛卡尔坐标
measurements_linearized: 线性化转换的笛卡尔坐标
covariances: 各转换方法的协方差矩阵
"""
n_points = trajectory.shape[0]
# 确保轨迹包含位置信息
if trajectory.shape[1] >= 2:
positions = trajectory[:, :2]
else:
raise ValueError("轨迹必须至少包含位置信息")
# 初始化数组
measurements_polar = np.zeros((n_points, 2)) # (range, bearing)
measurements_simple = np.zeros((n_points, 2)) # (x, y)
measurements_unbiased = np.zeros((n_points, 2)) # (x, y)
measurements_linearized = np.zeros((n_points, 2)) # (x, y)
# 协方差数组
cov_simple = np.zeros((n_points, 2, 2))
cov_unbiased = np.zeros((n_points, 2, 2))
cov_linearized = np.zeros((n_points, 2, 2))
# 噪声参数
range_var = range_noise_std**2
bearing_var = bearing_noise_std**2
for i in range(n_points):
# 计算相对于雷达的位置
dx = positions[i, 0] - radar_pos[0]
dy = positions[i, 1] - radar_pos[1]
# 计算真实极坐标
true_range = np.sqrt(dx**2 + dy**2)
true_bearing = np.arctan2(dy, dx)
# 添加噪声
measured_range = true_range + np.random.randn() * range_noise_std
measured_bearing = true_bearing + np.random.randn() * bearing_noise_std
# 归一化方位角到 [-π, π]
measured_bearing = (measured_bearing + np.pi) % (2 * np.pi) - np.pi
measurements_polar[i] = [measured_range, measured_bearing]
# 1. 简单三角转换
x_simple, y_simple = polar_to_cartesian(measured_range, measured_bearing, radar_pos)
measurements_simple[i] = [x_simple, y_simple]
# 简单转换的协方差(近似)
cos_theta = np.cos(measured_bearing)
sin_theta = np.sin(measured_bearing)
cov_simple[i, 0, 0] = cos_theta**2 * range_var + (measured_range*sin_theta)**2 * bearing_var
cov_simple[i, 1, 1] = sin_theta**2 * range_var + (measured_range*cos_theta)**2 * bearing_var
cov_simple[i, 0, 1] = cos_theta*sin_theta * range_var - measured_range**2 * cos_theta*sin_theta * bearing_var
cov_simple[i, 1, 0] = cov_simple[i, 0, 1]
# 2. 去偏转换
unbiased_pos, cov_unb = polar_to_cartesian_unbiased(
measured_range, measured_bearing, range_var, bearing_var, radar_pos
)
measurements_unbiased[i] = unbiased_pos
cov_unbiased[i] = cov_unb
# 3. 线性化转换
linearized_pos, cov_lin = polar_to_cartesian_linearized(
measured_range, measured_bearing, range_var, bearing_var, radar_pos
)
measurements_linearized[i] = linearized_pos
cov_linearized[i] = cov_lin
return (measurements_polar, measurements_simple, measurements_unbiased,
measurements_linearized, cov_simple, cov_unbiased, cov_linearized)
def compare_conversion_methods():
"""
比较三种坐标转换方法的性能
"""
np.random.seed(42)
# 生成一个机动目标轨迹
num_steps = 200
dt = 1.0
# 轨迹:开始直线,然后转弯,最后加速
trajectory = np.zeros((num_steps, 4)) # [x, y, vx, vy]
# 初始状态
x, y = 1000, 500
vx, vy = 20, 10
for t in range(num_steps):
# 分段机动
if t < 50:
# 匀速直线
pass
elif t < 100:
# 转弯
vx, vy = vx - 0.1*vy, vy + 0.1*vx
elif t < 150:
# 加速
vx, vy = vx * 1.01, vy * 1.01
else:
# 减速
vx, vy = vx * 0.99, vy * 0.99
# 更新位置
x += vx * dt
y += vy * dt
trajectory[t] = [x, y, vx, vy]
# 雷达参数
radar_pos = (0, 0)
range_noise_std = 10.0
bearing_noise_std = 0.005 # 约0.286度
# 生成雷达测量
print("生成雷达测量数据...")
(measurements_polar, measurements_simple, measurements_unbiased,
measurements_linearized, cov_simple, cov_unbiased, cov_linearized) = generate_radar_measurements(
trajectory, radar_pos, range_noise_std, bearing_noise_std
)
# 初始化滤波器(使用CV模型)
filters = {
'simple': CVFilter(dt=dt, q=0.1),
'unbiased': CVFilter(dt=dt, q=0.1),
'linearized': CVFilter(dt=dt, q=0.1)
}
# 对应的测量和协方差
measurement_sets = {
'simple': measurements_simple,
'unbiased': measurements_unbiased,
'linearized': measurements_linearized
}
covariance_sets = {
'simple': cov_simple,
'unbiased': cov_unbiased,
'linearized': cov_linearized
}
# 运行跟踪
estimates = {name: [] for name in filters}
position_errors = {name: [] for name in filters}
for name, filter_obj in filters.items():
print(f"运行{name}转换的跟踪...")
# 获取对应的测量和协方差
measurements = measurement_sets[name]
covariances = covariance_sets[name]
# 初始化状态
filter_obj.x[0, 0] = measurements[0, 0]
filter_obj.x[1, 0] = measurements[0, 1]
for t in range(num_steps):
# 预测
filter_obj.predict()
# 设置观测噪声协方差
R = covariances[t]
# 更新
z = measurements[t, :2]
x_est, _ = filter_obj.update(z, R)
estimates[name].append(x_est.flatten())
# 计算位置误差
pos_error = np.sqrt((x_est[0, 0] - trajectory[t, 0])**2 +
(x_est[1, 0] - trajectory[t, 1])**2)
position_errors[name].append(pos_error)
# 转换结果为数组
for name in estimates:
estimates[name] = np.array(estimates[name])
# 计算性能指标
performance = {}
for name in filters:
errors = position_errors[name]
performance[name] = {
'rmse': np.sqrt(np.mean(np.array(errors)**2)),
'mae': np.mean(np.abs(errors)),
'max_error': np.max(np.abs(errors)),
'std_error': np.std(errors)
}
# 可视化结果
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 轨迹对比
ax = axes[0, 0]
ax.plot(trajectory[:, 0], trajectory[:, 1], 'k-', linewidth=3,
label='真实轨迹', alpha=0.8)
colors = {'simple': 'blue', 'unbiased': 'red', 'linearized': 'green'}
for name in filters:
ax.plot(estimates[name][:, 0], estimates[name][:, 1],
'-', linewidth=1.5, color=colors[name], label=f'{name}跟踪')
ax.plot(radar_pos[0], radar_pos[1], 'r*', markersize=15, label='雷达位置')
ax.set_xlabel('X位置 (m)')
ax.set_ylabel('Y位置 (m)')
ax.set_title('轨迹跟踪对比')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2. 位置误差对比
ax = axes[0, 1]
t = np.arange(num_steps)
for name in filters:
ax.plot(t, position_errors[name], '-', linewidth=1, color=colors[name],
label=f'{name} (RMSE={performance[name]["rmse"]:.2f}m)')
ax.set_xlabel('时间步')
ax.set_ylabel('位置误差 (m)')
ax.set_title('位置误差对比')
ax.legend()
ax.grid(True, alpha=0.3)
# 3. 累积误差分布
ax = axes[0, 2]
for name, color in colors.items():
errors_sorted = np.sort(position_errors[name])
cdf = np.arange(1, len(errors_sorted) + 1) / len(errors_sorted)
ax.plot(errors_sorted, cdf, '-', linewidth=2, color=color,
label=f'{name}')
ax.set_xlabel('位置误差 (m)')
ax.set_ylabel('累积概率')
ax.set_title('累积误差分布函数 (CDF)')
ax.legend()
ax.grid(True, alpha=0.3)
# 4. 滑动窗口误差分析
ax = axes[1, 0]
window_size = 20
for name, color in colors.items():
errors = position_errors[name]
sliding_rmse = []
for i in range(len(errors) - window_size + 1):
window_errors = errors[i:i+window_size]
sliding_rmse.append(np.sqrt(np.mean(np.array(window_errors)**2)))
t_sliding = np.arange(len(sliding_rmse))
ax.plot(t_sliding, sliding_rmse, '-', linewidth=1.5, color=color,
label=f'{name}')
ax.set_xlabel('时间窗口中心')
ax.set_ylabel(f'滑动RMSE (窗口大小={window_size})')
ax.set_title('滑动窗口误差分析')
ax.legend()
ax.grid(True, alpha=0.3)
# 5. 误差分布直方图
ax = axes[1, 1]
max_error = max([max(position_errors[name]) for name in filters])
bins = np.linspace(0, max_error, 30)
for name, color in colors.items():
ax.hist(position_errors[name], bins=bins, alpha=0.5, color=color,
density=True, label=name)
ax.set_xlabel('位置误差 (m)')
ax.set_ylabel('概率密度')
ax.set_title('误差分布直方图')
ax.legend()
ax.grid(True, alpha=0.3)
# 6. 性能对比表
ax = axes[1, 2]
ax.axis('off')
# 创建表格
cell_text = []
for name in filters:
perf = performance[name]
cell_text.append([name, f"{perf['rmse']:.2f}", f"{perf['mae']:.2f}",
f"{perf['std_error']:.2f}", f"{perf['max_error']:.2f}"])
# 计算相对于简单转换的改善比例
baseline_rmse = performance['simple']['rmse']
for name in ['unbiased', 'linearized']:
improvement = (baseline_rmse - performance[name]['rmse']) / baseline_rmse * 100
cell_text.append([f'{name}改善', f"{improvement:.1f}%", "", "", ""])
columns = ['方法', 'RMSE (m)', 'MAE (m)', 'Std (m)', 'Max (m)']
table = ax.table(cellText=cell_text, colLabels=columns,
cellLoc='center', loc='center',
colColours=['#f0f0f0']*5)
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 1.5)
# 设置改善行的颜色
table[(len(filters)+1, 0)].set_facecolor('#e0ffe0')
table[(len(filters)+2, 0)].set_facecolor('#e0ffe0')
ax.set_title('性能指标对比')
plt.suptitle('极坐标转换方法在跟踪中的性能对比', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('tracking_conversion_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印性能统计
print("\n" + "="*60)
print("跟踪性能对比")
print("="*60)
print(f"{'方法':<15} {'RMSE (m)':<12} {'MAE (m)':<12} {'Std (m)':<12} {'Max (m)':<12}")
print("-"*60)
for name in filters:
perf = performance[name]
print(f"{name:<15} {perf['rmse']:<12.2f} {perf['mae']:<12.2f} "
f"{perf['std_error']:<12.2f} {perf['max_error']:<12.2f}")
print("="*60)
return {
'trajectory': trajectory,
'measurements_polar': measurements_polar,
'measurements_simple': measurements_simple,
'measurements_unbiased': measurements_unbiased,
'measurements_linearized': measurements_linearized,
'estimates': estimates,
'performance': performance
}
def analyze_conversion_bias():
"""
分析坐标转换的偏差特性
"""
np.random.seed(42)
# 固定距离,变化方位角
ranges = np.array([100, 500, 1000, 2000])
bearings = np.linspace(-np.pi, np.pi, 100)
# 噪声参数
range_noise_std = 10.0
bearing_noise_std = 0.01
range_var = range_noise_std**2
bearing_var = bearing_noise_std**2
# 雷达位置
radar_pos = (0, 0)
# 蒙特卡洛模拟
num_trials = 1000
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
for idx, range_val in enumerate(ranges):
ax = axes[idx // 2, idx % 2]
simple_biases = []
unbiased_biases = []
linearized_biases = []
for bearing in bearings:
# 真实位置
true_x = radar_pos[0] + range_val * np.cos(bearing)
true_y = radar_pos[1] + range_val * np.sin(bearing)
simple_errors = []
unbiased_errors = []
linearized_errors = []
for _ in range(num_trials):
# 生成带噪声的测量
noisy_range = range_val + np.random.randn() * range_noise_std
noisy_bearing = bearing + np.random.randn() * bearing_noise_std
# 简单转换
simple_x, simple_y = polar_to_cartesian(noisy_range, noisy_bearing, radar_pos)
simple_error = np.sqrt((simple_x - true_x)**2 + (simple_y - true_y)**2)
simple_errors.append(simple_error)
# 去偏转换
unbiased_pos, _ = polar_to_cartesian_unbiased(noisy_range, noisy_bearing,
range_var, bearing_var, radar_pos)
unbiased_error = np.sqrt((unbiased_pos[0] - true_x)**2 + (unbiased_pos[1] - true_y)**2)
unbiased_errors.append(unbiased_error)
# 线性化转换
linearized_pos, _ = polar_to_cartesian_linearized(noisy_range, noisy_bearing,
range_var, bearing_var, radar_pos)
linearized_error = np.sqrt((linearized_pos[0] - true_x)**2 + (linearized_pos[1] - true_y)**2)
linearized_errors.append(linearized_error)
# 计算平均偏差
simple_biases.append(np.mean(simple_errors))
unbiased_biases.append(np.mean(unbiased_errors))
linearized_biases.append(np.mean(linearized_errors))
# 绘制偏差随方位角的变化
ax.plot(np.degrees(bearings), simple_biases, 'b-', linewidth=2, label='简单转换')
ax.plot(np.degrees(bearings), unbiased_biases, 'r-', linewidth=2, label='去偏转换')
ax.plot(np.degrees(bearings), linearized_biases, 'g-', linewidth=2, label='线性化转换')
ax.set_xlabel('方位角 (度)')
ax.set_ylabel('平均位置误差 (m)')
ax.set_title(f'距离 = {range_val}m')
ax.legend()
ax.grid(True, alpha=0.3)
# 添加理论偏差线
if idx == 0:
# 计算理论偏差(近似)
theoretical_bias_simple = range_val * np.sqrt(2 * (1 - np.exp(-bearing_var/2)))
ax.axhline(y=theoretical_bias_simple, color='b', linestyle='--',
alpha=0.5, label='理论偏差(简单)')
theoretical_bias_unbiased = 0
ax.axhline(y=theoretical_bias_unbiased, color='r', linestyle='--',
alpha=0.5, label='理论偏差(去偏)')
theoretical_bias_linearized = 0
ax.axhline(y=theoretical_bias_linearized, color='g', linestyle='--',
alpha=0.5, label='理论偏差(线性化)')
ax.legend()
plt.suptitle('坐标转换偏差分析 (蒙特卡洛模拟)', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('conversion_bias_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 计算总体统计
print("\n" + "="*60)
print("坐标转换偏差统计")
print("="*60)
for range_val in ranges:
# 选择中间方位角的结果
mid_idx = len(bearings) // 2
bearing = bearings[mid_idx]
# 真实位置
true_x = radar_pos[0] + range_val * np.cos(bearing)
true_y = radar_pos[1] + range_val * np.sin(bearing)
simple_errors = []
unbiased_errors = []
linearized_errors = []
for _ in range(num_trials):
# 生成带噪声的测量
noisy_range = range_val + np.random.randn() * range_noise_std
noisy_bearing = bearing + np.random.randn() * bearing_noise_std
# 简单转换
simple_x, simple_y = polar_to_cartesian(noisy_range, noisy_bearing, radar_pos)
simple_error = np.sqrt((simple_x - true_x)**2 + (simple_y - true_y)**2)
simple_errors.append(simple_error)
# 去偏转换
unbiased_pos, _ = polar_to_cartesian_unbiased(noisy_range, noisy_bearing,
range_var, bearing_var, radar_pos)
unbiased_error = np.sqrt((unbiased_pos[0] - true_x)**2 + (unbiased_pos[1] - true_y)**2)
unbiased_errors.append(unbiased_error)
# 线性化转换
linearized_pos, _ = polar_to_cartesian_linearized(noisy_range, noisy_bearing,
range_var, bearing_var, radar_pos)
linearized_error = np.sqrt((linearized_pos[0] - true_x)**2 + (linearized_pos[1] - true_y)**2)
linearized_errors.append(linearized_error)
simple_mean = np.mean(simple_errors)
unbiased_mean = np.mean(unbiased_errors)
linearized_mean = np.mean(linearized_errors)
simple_std = np.std(simple_errors)
unbiased_std = np.std(unbiased_errors)
linearized_std = np.std(linearized_errors)
print(f"距离 {range_val:4d}m:")
print(f" 简单转换: 均值={simple_mean:6.2f}m, 标准差={simple_std:6.2f}m")
print(f" 去偏转换: 均值={unbiased_mean:6.2f}m, 标准差={unbiased_std:6.2f}m, "
f"改善={(simple_mean-unbiased_mean)/simple_mean*100:5.1f}%")
print(f" 线性化转换: 均值={linearized_mean:6.2f}m, 标准差={linearized_std:6.2f}m, "
f"改善={(simple_mean-linearized_mean)/simple_mean*100:5.1f}%")
print()
print("="*60)
def analyze_covariance_matching():
"""
分析协方差匹配程度
"""
np.random.seed(42)
# 生成测试点
num_points = 10000
ranges = np.random.uniform(100, 2000, num_points)
bearings = np.random.uniform(-np.pi, np.pi, num_points)
# 噪声参数
range_noise_std = 10.0
bearing_noise_std = 0.01
range_var = range_noise_std**2
bearing_var = bearing_noise_std**2
# 雷达位置
radar_pos = (0, 0)
# 存储结果
simple_errors = []
unbiased_errors = []
linearized_errors = []
simple_innovation_norm = []
unbiased_innovation_norm = []
linearized_innovation_norm = []
for i in range(num_points):
# 真实位置
true_x = radar_pos[0] + ranges[i] * np.cos(bearings[i])
true_y = radar_pos[1] + ranges[i] * np.sin(bearings[i])
# 生成带噪声的测量
noisy_range = ranges[i] + np.random.randn() * range_noise_std
noisy_bearing = bearings[i] + np.random.randn() * bearing_noise_std
# 各种转换
# 简单转换
simple_x, simple_y = polar_to_cartesian(noisy_range, noisy_bearing, radar_pos)
# 简单转换的协方差
cos_theta = np.cos(noisy_bearing)
sin_theta = np.sin(noisy_bearing)
cov_simple = np.array([
[cos_theta**2 * range_var + (noisy_range*sin_theta)**2 * bearing_var,
cos_theta*sin_theta * range_var - noisy_range**2 * cos_theta*sin_theta * bearing_var],
[cos_theta*sin_theta * range_var - noisy_range**2 * cos_theta*sin_theta * bearing_var,
sin_theta**2 * range_var + (noisy_range*cos_theta)**2 * bearing_var]
])
# 去偏转换
unbiased_pos, cov_unb = polar_to_cartesian_unbiased(
noisy_range, noisy_bearing, range_var, bearing_var, radar_pos
)
# 线性化转换
linearized_pos, cov_lin = polar_to_cartesian_linearized(
noisy_range, noisy_bearing, range_var, bearing_var, radar_pos
)
# 计算误差
simple_error = np.array([simple_x - true_x, simple_y - true_y])
unbiased_error = np.array([unbiased_pos[0] - true_x, unbiased_pos[1] - true_y])
linearized_error = np.array([linearized_pos[0] - true_x, linearized_pos[1] - true_y])
simple_errors.append(simple_error)
unbiased_errors.append(unbiased_error)
linearized_errors.append(linearized_error)
# 计算新息归一化平方
if np.linalg.matrix_rank(cov_simple) == 2:
simple_inn = simple_error @ np.linalg.inv(cov_simple) @ simple_error
simple_innovation_norm.append(simple_inn)
if np.linalg.matrix_rank(cov_unb) == 2:
unbiased_inn = unbiased_error @ np.linalg.inv(cov_unb) @ unbiased_error
unbiased_innovation_norm.append(unbiased_inn)
if np.linalg.matrix_rank(cov_lin) == 2:
linearized_inn = linearized_error @ np.linalg.inv(cov_lin) @ linearized_error
linearized_innovation_norm.append(linearized_inn)
simple_errors = np.array(simple_errors)
unbiased_errors = np.array(unbiased_errors)
linearized_errors = np.array(linearized_errors)
# 计算样本协方差
sample_cov_simple = np.cov(simple_errors.T)
sample_cov_unbiased = np.cov(unbiased_errors.T)
sample_cov_linearized = np.cov(linearized_errors.T)
# 计算理论协方差(平均)
avg_cov_simple = np.zeros((2, 2))
avg_cov_unbiased = np.zeros((2, 2))
avg_cov_linearized = np.zeros((2, 2))
# 重新计算平均理论协方差
for i in range(num_points):
noisy_range = ranges[i] + np.random.randn() * range_noise_std
noisy_bearing = bearings[i] + np.random.randn() * bearing_noise_std
cos_theta = np.cos(noisy_bearing)
sin_theta = np.sin(noisy_bearing)
avg_cov_simple += np.array([
[cos_theta**2 * range_var + (noisy_range*sin_theta)**2 * bearing_var,
cos_theta*sin_theta * range_var - noisy_range**2 * cos_theta*sin_theta * bearing_var],
[cos_theta*sin_theta * range_var - noisy_range**2 * cos_theta*sin_theta * bearing_var,
sin_theta**2 * range_var + (noisy_range*cos_theta)**2 * bearing_var]
])
unbiased_pos, cov_unb = polar_to_cartesian_unbiased(
noisy_range, noisy_bearing, range_var, bearing_var, radar_pos
)
avg_cov_unbiased += cov_unb
linearized_pos, cov_lin = polar_to_cartesian_linearized(
noisy_range, noisy_bearing, range_var, bearing_var, radar_pos
)
avg_cov_linearized += cov_lin
avg_cov_simple /= num_points
avg_cov_unbiased /= num_points
avg_cov_linearized /= num_points
# 可视化
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
methods = ['simple', 'unbiased', 'linearized']
titles = ['简单转换', '去偏转换', '线性化转换']
cov_samples = [sample_cov_simple, sample_cov_unbiased, sample_cov_linearized]
cov_theory = [avg_cov_simple, avg_cov_unbiased, avg_cov_linearized]
for i, (method, title) in enumerate(zip(methods, titles)):
# 样本协方差热图
ax = axes[0, i]
im = ax.imshow(cov_samples[i], cmap='hot', interpolation='nearest')
ax.set_xticks([0, 1])
ax.set_yticks([0, 1])
ax.set_xticklabels(['x', 'y'])
ax.set_yticklabels(['x', 'y'])
ax.set_title(f'{title} - 样本协方差')
plt.colorbar(im, ax=ax)
# 添加数值
for j in range(2):
for k in range(2):
ax.text(k, j, f'{cov_samples[i][j, k]:.1f}',
ha='center', va='center', color='white')
for i, (method, title) in enumerate(zip(methods, titles)):
# 理论协方差热图
ax = axes[1, i]
im = ax.imshow(cov_theory[i], cmap='hot', interpolation='nearest')
ax.set_xticks([0, 1])
ax.set_yticks([0, 1])
ax.set_xticklabels(['x', 'y'])
ax.set_yticklabels(['x', 'y'])
ax.set_title(f'{title} - 平均理论协方差')
plt.colorbar(im, ax=ax)
# 添加数值
for j in range(2):
for k in range(2):
ax.text(k, j, f'{cov_theory[i][j, k]:.1f}',
ha='center', va='center', color='white')
plt.suptitle('协方差匹配分析', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('covariance_matching_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 绘制新息归一化平方的分布
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
inn_data = [simple_innovation_norm, unbiased_innovation_norm, linearized_innovation_norm]
for i, (method, title, data) in enumerate(zip(methods, titles, inn_data)):
ax = axes[i]
if len(data) > 0:
ax.hist(data, bins=50, density=True, alpha=0.7, color='blue', edgecolor='black')
# 添加卡方分布(2自由度)参考线
x = np.linspace(0, max(data), 100)
y = stats.chi2.pdf(x, df=2)
ax.plot(x, y, 'r-', linewidth=2, label='χ²(2)')
# 计算统计量
mean_inn = np.mean(data)
std_inn = np.std(data)
ax.set_xlabel('归一化新息平方')
ax.set_ylabel('概率密度')
ax.set_title(f'{title}\n均值={mean_inn:.3f}, 标准差={std_inn:.3f}')
ax.legend()
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '数据不足', ha='center', va='center', transform=ax.transAxes)
plt.suptitle('归一化新息平方分布 (应近似χ²(2))', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('innovation_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印协方差匹配统计
print("\n" + "="*60)
print("协方差匹配统计")
print("="*60)
for i, (method, title) in enumerate(zip(methods, titles)):
diff = np.linalg.norm(cov_samples[i] - cov_theory[i], 'fro')
print(f"{title}:")
print(f" 样本协方差与理论协方差的Frobenius范数差异: {diff:.4f}")
print(f" 样本协方差迹: {np.trace(cov_samples[i]):.2f}")
print(f" 理论协方差迹: {np.trace(cov_theory[i]):.2f}")
print(f" 迹差异: {abs(np.trace(cov_samples[i]) - np.trace(cov_theory[i])):.2f}")
print()
if __name__ == "__main__":
print("="*60)
print("极坐标到笛卡尔坐标转换跟踪演示")
print("="*60)
np.random.seed(42)
# 1. 比较坐标转换方法
print("\n1. 比较坐标转换方法在跟踪中的性能...")
tracking_results = compare_conversion_methods()
# 2. 分析转换偏差
print("\n2. 分析坐标转换偏差...")
analyze_conversion_bias()
# 3. 分析协方差匹配
print("\n3. 分析协方差匹配...")
analyze_covariance_matching()
print("\n演示完成!")
# 总结
print("\n" + "="*60)
print("主要结论")
print("="*60)
print("1. 简单三角转换: 计算简单,但有偏差,特别是在方位角噪声较大时")
print("2. 去偏转换: 修正了偏差,提高估计精度,但计算较复杂")
print("3. 线性化转换: 基于误差传播,能提供较好的协方差估计")
print("4. 在跟踪任务中,正确的协方差估计对滤波性能至关重要")
print("5. 实际应用中应根据精度要求和计算资源选择合适的转换方法")
print("="*60)8. Demo 3-3:交互多模型滤波实现
这个Demo将展示交互多模型(IMM)滤波的实现,并比较IMM与单一模型在机动目标跟踪中的性能。
python
"""
demo_3_3_interacting_multiple_model.py
交互多模型滤波实现
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from demo_3_1_motion_models_comparison import CVFilter, CAFilter, CTRVFilter
class ModelResult:
"""模型滤波结果容器"""
def __init__(self, x, P, z_pred, S, likelihood):
self.x = x # 状态估计
self.P = P # 协方差矩阵
self.z_pred = z_pred # 预测观测
self.S = S # 新息协方差
self.likelihood = likelihood # 模型似然
class IMMFilter:
"""
交互多模型滤波器
支持CV、CA、CTRV三种模型的混合
"""
def __init__(self, models, model_prob, trans_prob, dt=1.0):
"""
初始化IMM滤波器
参数:
models: 模型名称列表,如 ['CV', 'CA', 'CTRV']
model_prob: 初始模型概率
trans_prob: 模型转移概率矩阵
dt: 时间间隔
"""
self.models = models
self.num_models = len(models)
self.mu = np.array(model_prob) # 模型概率
self.pi = np.array(trans_prob) # 转移概率矩阵
self.dt = dt
# 检查维度
assert len(model_prob) == self.num_models, "模型概率维度不匹配"
assert trans_prob.shape == (self.num_models, self.num_models), "转移概率矩阵维度不匹配"
# 初始化滤波器
self.filters = []
for model in models:
if model == 'CV':
self.filters.append(CVFilter(dt=dt, q=0.1))
elif model == 'CA':
self.filters.append(CAFilter(dt=dt, q=0.1))
elif model == 'CTRV':
self.filters.append(CTRVFilter(dt=dt, q_pos=0.1, q_vel=0.01, q_yaw=0.1, q_yawrate=0.01))
else:
raise ValueError(f"未知模型: {model}")
# 状态维度(假设所有滤波器状态维度相同)
self.state_dim = self.filters[0].state_dim
# 存储各模型的结果
self.model_results = [None] * self.num_models
# 历史记录
self.history = {
'x_fused': [],
'P_fused': [],
'model_prob': [],
'model_estimates': [],
'model_covariances': []
}
def init_state(self, x0, P0=None):
"""初始化状态"""
if P0 is None:
P0 = np.eye(self.state_dim) * 100
for filter_obj in self.filters:
filter_obj.x = x0.copy().reshape(-1, 1)
filter_obj.P = P0.copy()
# 初始化历史记录
self.history['x_fused'] = [x0.copy()]
self.history['P_fused'] = [P0.copy()]
self.history['model_prob'] = [self.mu.copy()]
# 初始化各模型估计
model_estimates = []
model_covariances = []
for filter_obj in self.filters:
model_estimates.append(filter_obj.x.copy())
model_covariances.append(filter_obj.P.copy())
self.history['model_estimates'].append(model_estimates)
self.history['model_covariances'].append(model_covariances)
def step(self, z, R):
"""
执行一步IMM滤波
参数:
z: 观测向量
R: 观测噪声协方差
返回:
x_fused: 融合状态估计
P_fused: 融合协方差矩阵
"""
# 1. 交互/混合
mixed_states, mixed_covs = self._interaction()
# 2. 模型条件滤波
model_likelihoods = np.zeros(self.num_models)
for j in range(self.num_models):
# 设置混合后的状态和协方差
self.filters[j].x = mixed_states[j]
self.filters[j].P = mixed_covs[j]
# 执行预测
x_pred, P_pred = self.filters[j].predict()
# 计算预测观测
H = self._get_observation_matrix(j)
z_pred = H @ x_pred
# 计算新息协方差
S = H @ P_pred @ H.T + R
# 计算模型似然
innovation = z.reshape(-1, 1) - z_pred
likelihood = self._compute_likelihood(innovation, S)
model_likelihoods[j] = likelihood
# 更新步骤
x_est, P_est = self.filters[j].update(z, R)
# 保存结果
self.model_results[j] = ModelResult(x_est, P_est, z_pred, S, likelihood)
# 3. 模型概率更新
self._update_model_probabilities(model_likelihoods)
# 4. 估计融合
x_fused, P_fused = self._fusion()
# 保存历史
self.history['x_fused'].append(x_fused.copy())
self.history['P_fused'].append(P_fused.copy())
self.history['model_prob'].append(self.mu.copy())
# 保存各模型估计
model_estimates = []
model_covariances = []
for result in self.model_results:
model_estimates.append(result.x.copy())
model_covariances.append(result.P.copy())
self.history['model_estimates'].append(model_estimates)
self.history['model_covariances'].append(model_covariances)
return x_fused, P_fused
def _interaction(self):
"""交互/混合步骤"""
# 计算混合概率
c_bar = np.zeros(self.num_models)
for j in range(self.num_models):
c_bar[j] = np.sum(self.pi[:, j] * self.mu)
mu_mixed = np.zeros((self.num_models, self.num_models))
for i in range(self.num_models):
for j in range(self.num_models):
mu_mixed[i, j] = self.pi[i, j] * self.mu[i] / c_bar[j]
# 混合状态和协方差
mixed_states = []
mixed_covs = []
for j in range(self.num_models):
# 初始化混合状态
x_mixed = np.zeros((self.state_dim, 1))
for i in range(self.num_models):
x_mixed += mu_mixed[i, j] * self.filters[i].x
# 初始化混合协方差
P_mixed = np.zeros((self.state_dim, self.state_dim))
for i in range(self.num_models):
dx = self.filters[i].x - x_mixed
P_mixed += mu_mixed[i, j] * (self.filters[i].P + dx @ dx.T)
mixed_states.append(x_mixed)
mixed_covs.append(P_mixed)
return mixed_states, mixed_covs
def _update_model_probabilities(self, likelihoods):
"""更新模型概率"""
# 计算归一化常数
c = np.sum(likelihoods * np.sum(self.pi * self.mu, axis=0))
# 更新模型概率
if c > 1e-10: # 避免除以零
self.mu = (likelihoods * np.sum(self.pi * self.mu, axis=0)) / c
else:
# 如果c太小,保持原概率
pass
# 确保概率和为1
self.mu = self.mu / np.sum(self.mu)
def _fusion(self):
"""估计融合"""
# 初始化融合状态和协方差
x_fused = np.zeros((self.state_dim, 1))
for j in range(self.num_models):
x_fused += self.mu[j] * self.model_results[j].x
P_fused = np.zeros((self.state_dim, self.state_dim))
for j in range(self.num_models):
dx = self.model_results[j].x - x_fused
P_fused += self.mu[j] * (self.model_results[j].P + dx @ dx.T)
return x_fused, P_fused
def _get_observation_matrix(self, model_idx):
"""获取观测矩阵"""
if self.models[model_idx] in ['CV', 'CA']:
# CV和CA模型观测位置
if self.models[model_idx] == 'CV':
return np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
else: # CA
return np.array([[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0]])
else: # CTRV
return np.array([[1, 0, 0, 0, 0], [0, 1, 0, 0, 0]])
def _compute_likelihood(self, innovation, S):
"""计算模型似然"""
try:
# 计算多元高斯概率密度
n = innovation.shape[0]
det_S = np.linalg.det(S)
if det_S <= 0:
return 1e-10
likelihood = (1.0 / ((2*np.pi)**(n/2) * np.sqrt(det_S))) * \
np.exp(-0.5 * innovation.T @ np.linalg.inv(S) @ innovation)
return likelihood.item()
except:
return 1e-10
def get_history(self):
"""获取历史记录"""
return self.history
def get_model_probabilities(self):
"""获取当前模型概率"""
return self.mu.copy()
def generate_maneuvering_trajectory(num_steps=300, dt=1.0):
"""
生成机动目标轨迹
轨迹包含:匀速直线 → 转弯 → 加速直线 → 减速转弯
"""
trajectory = np.zeros((num_steps, 4)) # [x, y, vx, vy]
# 初始状态
x, y = 0, 0
v, psi = 20, 0 # 初始速度20m/s,航向0度(向东)
for t in range(num_steps):
# 分段机动
if t < 50:
# 阶段1: 匀速直线
a = 0
psi_dot = 0
elif t < 100:
# 阶段2: 匀速转弯 (左转)
a = 0
psi_dot = 0.05 # 约2.86度/秒
elif t < 150:
# 阶段3: 加速直线
a = 0.5
psi_dot = 0
elif t < 200:
# 阶段4: 匀速直线
a = 0
psi_dot = 0
elif t < 250:
# 阶段5: 减速转弯 (右转)
a = -0.3
psi_dot = -0.03
else:
# 阶段6: 匀速直线
a = 0
psi_dot = 0
# 更新状态
v += a * dt
psi += psi_dot * dt
# 归一化航向角
psi = (psi + np.pi) % (2*np.pi) - np.pi
# 计算位置
x += v * dt * np.cos(psi)
y += v * dt * np.sin(psi)
# 计算速度分量
vx = v * np.cos(psi)
vy = v * np.sin(psi)
trajectory[t] = [x, y, vx, vy]
return trajectory
def compare_imm_vs_single_models():
"""比较IMM与单一模型的性能"""
np.random.seed(42)
# 生成机动轨迹
print("生成机动目标轨迹...")
trajectory = generate_maneuvering_trajectory(num_steps=300, dt=1.0)
# 添加观测噪声
pos_noise_std = 5.0
measurements = trajectory[:, :2] + np.random.randn(len(trajectory), 2) * pos_noise_std
R = np.eye(2) * pos_noise_std**2
# 初始化滤波器
models = ['CV', 'CA', 'CTRV']
# IMM滤波器
model_prob = [0.33, 0.33, 0.34] # 初始模型概率
# 转移概率矩阵
trans_prob = np.array([
[0.95, 0.025, 0.025], # CV -> CV, CA, CTRV
[0.025, 0.95, 0.025], # CA -> CV, CA, CTRV
[0.025, 0.025, 0.95] # CTRV -> CV, CA, CTRV
])
imm = IMMFilter(models, model_prob, trans_prob, dt=1.0)
# 单一模型滤波器
single_filters = {}
for model in models:
if model == 'CV':
single_filters[model] = CVFilter(dt=1.0, q=0.1)
elif model == 'CA':
single_filters[model] = CAFilter(dt=1.0, q=0.1)
else: # CTRV
single_filters[model] = CTRVFilter(dt=1.0, q_pos=0.1, q_vel=0.01, q_yaw=0.1, q_yawrate=0.01)
# 运行滤波
print("运行IMM滤波...")
imm.init_state(measurements[0].reshape(-1, 1))
imm_estimates = []
imm_position_errors = []
imm_model_probs = []
for t in range(len(measurements)):
z = measurements[t, :2]
x_est, _ = imm.step(z, R)
imm_estimates.append(x_est.flatten())
# 计算位置误差
pos_error = np.sqrt((x_est[0, 0] - trajectory[t, 0])**2 +
(x_est[1, 0] - trajectory[t, 1])**2)
imm_position_errors.append(pos_error)
# 保存模型概率
imm_model_probs.append(imm.get_model_probabilities().copy())
imm_estimates = np.array(imm_estimates)
imm_model_probs = np.array(imm_model_probs)
# 运行单一模型滤波
print("运行单一模型滤波...")
single_estimates = {model: [] for model in models}
single_position_errors = {model: [] for model in models}
for model, filter_obj in single_filters.items():
print(f" 运行{model}滤波...")
# 初始化状态
filter_obj.x[0, 0] = measurements[0, 0]
filter_obj.x[1, 0] = measurements[0, 1]
for t in range(len(measurements)):
# 预测
filter_obj.predict()
# 更新
z = measurements[t, :2]
x_est, _ = filter_obj.update(z, R)
single_estimates[model].append(x_est.flatten())
# 计算位置误差
pos_error = np.sqrt((x_est[0, 0] - trajectory[t, 0])**2 +
(x_est[1, 0] - trajectory[t, 1])**2)
single_position_errors[model].append(pos_error)
for model in models:
single_estimates[model] = np.array(single_estimates[model])
# 计算性能指标
performance = {}
# IMM性能
imm_rmse = np.sqrt(np.mean(np.array(imm_position_errors)**2))
imm_mae = np.mean(np.abs(imm_position_errors))
imm_max_error = np.max(np.abs(imm_position_errors))
performance['IMM'] = {
'rmse': imm_rmse,
'mae': imm_mae,
'max_error': imm_max_error
}
# 单一模型性能
for model in models:
errors = single_position_errors[model]
performance[model] = {
'rmse': np.sqrt(np.mean(np.array(errors)**2)),
'mae': np.mean(np.abs(errors)),
'max_error': np.max(np.abs(errors))
}
# 可视化结果
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 轨迹对比
ax = axes[0, 0]
ax.plot(trajectory[:, 0], trajectory[:, 1], 'k-', linewidth=3,
label='真实轨迹', alpha=0.8)
ax.plot(measurements[:, 0], measurements[:, 1], 'y.', markersize=2,
alpha=0.3, label='观测值')
colors = {'CV': 'blue', 'CA': 'green', 'CTRV': 'red', 'IMM': 'purple'}
# 绘制单一模型轨迹
for model in models:
ax.plot(single_estimates[model][:, 0], single_estimates[model][:, 1],
'-', linewidth=1, color=colors[model], alpha=0.7, label=f'{model}')
# 绘制IMM轨迹
ax.plot(imm_estimates[:, 0], imm_estimates[:, 1], '-', linewidth=2,
color=colors['IMM'], label='IMM')
ax.set_xlabel('X位置 (m)')
ax.set_ylabel('Y位置 (m)')
ax.set_title('轨迹跟踪对比')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2. 位置误差对比
ax = axes[0, 1]
t = np.arange(len(trajectory))
for model in models:
ax.plot(t, single_position_errors[model], '-', linewidth=0.5,
color=colors[model], alpha=0.7, label=f'{model}')
ax.plot(t, imm_position_errors, '-', linewidth=1.5,
color=colors['IMM'], label='IMM')
ax.set_xlabel('时间步')
ax.set_ylabel('位置误差 (m)')
ax.set_title('位置误差对比')
ax.legend()
ax.grid(True, alpha=0.3)
# 3. IMM模型概率变化
ax = axes[0, 2]
for i, model in enumerate(models):
ax.plot(t, imm_model_probs[:, i], '-', linewidth=2,
color=colors[model], label=model)
# 添加机动阶段背景
ax.axvspan(0, 50, alpha=0.1, color='gray', label='阶段1: 匀速直线')
ax.axvspan(50, 100, alpha=0.2, color='gray', label='阶段2: 转弯')
ax.axvspan(100, 150, alpha=0.3, color='gray', label='阶段3: 加速直线')
ax.axvspan(150, 200, alpha=0.1, color='gray', label='阶段4: 匀速直线')
ax.axvspan(200, 250, alpha=0.2, color='gray', label='阶段5: 减速转弯')
ax.axvspan(250, 300, alpha=0.1, color='gray', label='阶段6: 匀速直线')
ax.set_xlabel('时间步')
ax.set_ylabel('模型概率')
ax.set_title('IMM模型概率变化')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.set_ylim([0, 1])
# 4. 各阶段误差分析
ax = axes[1, 0]
# 定义阶段
stages = [
(0, 50, '阶段1\n匀速直线'),
(50, 100, '阶段2\n转弯'),
(100, 150, '阶段3\n加速直线'),
(150, 200, '阶段4\n匀速直线'),
(200, 250, '阶段5\n减速转弯'),
(250, 300, '阶段6\n匀速直线')
]
x_pos = np.arange(len(stages))
width = 0.15
for stage_idx, (start, end, stage_name) in enumerate(stages):
# 计算各模型在该阶段的平均误差
for i, model in enumerate(models + ['IMM']):
if model == 'IMM':
errors = imm_position_errors[start:end]
else:
errors = single_position_errors[model][start:end]
stage_mae = np.mean(errors)
ax.bar(stage_idx + (i-1.5)*width, stage_mae, width,
color=colors[model], alpha=0.7, label=model if stage_idx==0 else "")
ax.set_xlabel('运动阶段')
ax.set_ylabel('平均位置误差 (m)')
ax.set_title('各阶段误差分析')
ax.set_xticks(x_pos)
ax.set_xticklabels([stage[2] for stage in stages], rotation=15)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
# 5. 误差分布箱线图
ax = axes[1, 1]
error_data = []
labels = []
for model in models:
error_data.append(single_position_errors[model])
labels.append(model)
error_data.append(imm_position_errors)
labels.append('IMM')
bp = ax.boxplot(error_data, labels=labels, patch_artist=True)
# 设置颜色
for patch, label in zip(bp['boxes'], labels):
patch.set_facecolor(colors[label])
patch.set_alpha(0.7)
ax.set_ylabel('位置误差 (m)')
ax.set_title('误差分布箱线图')
ax.grid(True, alpha=0.3, axis='y')
# 6. 性能对比表
ax = axes[1, 2]
ax.axis('off')
# 创建表格
cell_text = []
for model in models + ['IMM']:
perf = performance[model]
cell_text.append([model, f"{perf['rmse']:.2f}",
f"{perf['mae']:.2f}", f"{perf['max_error']:.2f}"])
# 计算相对于最佳单一模型的改善比例
best_single_rmse = min([performance[model]['rmse'] for model in models])
imm_improvement = (best_single_rmse - performance['IMM']['rmse']) / best_single_rmse * 100
cell_text.append(['IMM改善', f"{imm_improvement:.1f}%", "", ""])
columns = ['模型', 'RMSE (m)', 'MAE (m)', '最大误差 (m)']
table = ax.table(cellText=cell_text, colLabels=columns,
cellLoc='center', loc='center',
colColours=['#f0f0f0']*4)
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 1.5)
# 设置改善行的颜色
table[(len(models)+1, 0)].set_facecolor('#e0ffe0')
table[(len(models)+1, 1)].set_facecolor('#e0ffe0')
table[(len(models)+1, 2)].set_facecolor('#e0ffe0')
table[(len(models)+1, 3)].set_facecolor('#e0ffe0')
ax.set_title('性能指标对比')
plt.suptitle('IMM与单一模型滤波性能对比', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('imm_vs_single_models.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印性能统计
print("\n" + "="*60)
print("滤波性能对比")
print("="*60)
print(f"{'模型':<10} {'RMSE (m)':<12} {'MAE (m)':<12} {'最大误差 (m)':<12}")
print("-"*60)
for model in models + ['IMM']:
perf = performance[model]
print(f"{model:<10} {perf['rmse']:<12.2f} {perf['mae']:<12.2f} {perf['max_error']:<12.2f}")
print(f"\nIMM相对于最佳单一模型的RMSE改善: {imm_improvement:.1f}%")
print("="*60)
return {
'trajectory': trajectory,
'measurements': measurements,
'imm_estimates': imm_estimates,
'single_estimates': single_estimates,
'imm_model_probs': imm_model_probs,
'performance': performance
}
def analyze_imm_parameters():
"""分析IMM参数对性能的影响"""
np.random.seed(42)
# 生成测试轨迹
trajectory = generate_maneuvering_trajectory(num_steps=200, dt=1.0)
# 添加观测噪声
pos_noise_std = 5.0
measurements = trajectory[:, :2] + np.random.randn(len(trajectory), 2) * pos_noise_std
R = np.eye(2) * pos_noise_std**2
# 测试不同的转移概率矩阵
trans_prob_configs = {
'保守': np.array([
[0.98, 0.01, 0.01],
[0.01, 0.98, 0.01],
[0.01, 0.01, 0.98]
]),
'平衡': np.array([
[0.95, 0.025, 0.025],
[0.025, 0.95, 0.025],
[0.025, 0.025, 0.95]
]),
'激进': np.array([
[0.90, 0.05, 0.05],
[0.05, 0.90, 0.05],
[0.05, 0.05, 0.90]
])
}
# 测试不同的初始模型概率
init_prob_configs = {
'均匀': [0.33, 0.33, 0.34],
'偏向CV': [0.6, 0.2, 0.2],
'偏向CTRV': [0.2, 0.2, 0.6]
}
# 存储结果
results = []
for trans_name, trans_prob in trans_prob_configs.items():
for init_name, init_prob in init_prob_configs.items():
print(f"测试参数: 转移矩阵={trans_name}, 初始概率={init_name}")
# 创建IMM滤波器
models = ['CV', 'CA', 'CTRV']
imm = IMMFilter(models, init_prob, trans_prob, dt=1.0)
# 初始化状态
imm.init_state(measurements[0].reshape(-1, 1))
# 运行滤波
position_errors = []
for t in range(len(measurements)):
z = measurements[t, :2]
x_est, _ = imm.step(z, R)
# 计算位置误差
pos_error = np.sqrt((x_est[0, 0] - trajectory[t, 0])**2 +
(x_est[1, 0] - trajectory[t, 1])**2)
position_errors.append(pos_error)
# 计算性能指标
rmse = np.sqrt(np.mean(np.array(position_errors)**2))
mae = np.mean(np.abs(position_errors))
max_error = np.max(np.abs(position_errors))
results.append({
'trans_name': trans_name,
'init_name': init_name,
'rmse': rmse,
'mae': mae,
'max_error': max_error
})
# 可视化参数分析结果
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 1. RMSE热图
ax = axes[0]
# 创建数据矩阵
trans_names = list(trans_prob_configs.keys())
init_names = list(init_prob_configs.keys())
rmse_matrix = np.zeros((len(init_names), len(trans_names)))
for i, init_name in enumerate(init_names):
for j, trans_name in enumerate(trans_names):
for result in results:
if result['init_name'] == init_name and result['trans_name'] == trans_name:
rmse_matrix[i, j] = result['rmse']
break
im = ax.imshow(rmse_matrix, cmap='YlOrRd', aspect='auto')
ax.set_xticks(np.arange(len(trans_names)))
ax.set_yticks(np.arange(len(init_names)))
ax.set_xticklabels(trans_names)
ax.set_yticklabels(init_names)
ax.set_xlabel('转移矩阵')
ax.set_ylabel('初始概率')
ax.set_title('RMSE热图 (越小越好)')
# 添加数值标签
for i in range(len(init_names)):
for j in range(len(trans_names)):
ax.text(j, i, f'{rmse_matrix[i, j]:.2f}',
ha='center', va='center', color='black')
plt.colorbar(im, ax=ax)
# 2. 参数对MAE的影响
ax = axes[1]
x = np.arange(len(trans_names))
width = 0.25
for idx, init_name in enumerate(init_names):
mae_values = []
for trans_name in trans_names:
for result in results:
if result['init_name'] == init_name and result['trans_name'] == trans_name:
mae_values.append(result['mae'])
break
ax.bar(x + (idx-1)*width, mae_values, width,
label=f'初始概率={init_name}', alpha=0.7)
ax.set_xlabel('转移矩阵')
ax.set_ylabel('MAE (m)')
ax.set_title('参数对MAE的影响')
ax.set_xticks(x)
ax.set_xticklabels(trans_names)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
# 3. 参数对最大误差的影响
ax = axes[2]
for idx, init_name in enumerate(init_names):
max_errors = []
for trans_name in trans_names:
for result in results:
if result['init_name'] == init_name and result['trans_name'] == trans_name:
max_errors.append(result['max_error'])
break
ax.bar(x + (idx-1)*width, max_errors, width,
label=f'初始概率={init_name}', alpha=0.7)
ax.set_xlabel('转移矩阵')
ax.set_ylabel('最大误差 (m)')
ax.set_title('参数对最大误差的影响')
ax.set_xticks(x)
ax.set_xticklabels(trans_names)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
plt.suptitle('IMM参数敏感性分析', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('imm_parameter_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印参数分析结果
print("\n" + "="*60)
print("IMM参数敏感性分析结果")
print("="*60)
print(f"{'初始概率':<10} {'转移矩阵':<10} {'RMSE':<10} {'MAE':<10} {'最大误差':<10}")
print("-"*60)
for result in results:
print(f"{result['init_name']:<10} {result['trans_name']:<10} "
f"{result['rmse']:<10.2f} {result['mae']:<10.2f} {result['max_error']:<10.2f}")
print("="*60)
return results
def analyze_model_switching():
"""分析模型切换特性"""
np.random.seed(42)
# 生成包含明确机动阶段的轨迹
num_steps = 300
dt = 1.0
trajectory = np.zeros((num_steps, 4))
true_model = np.zeros(num_steps, dtype=int) # 0: CV, 1: CA, 2: CTRV
# 初始状态
x, y = 0, 0
v, psi = 20, 0
for t in range(num_steps):
# 定义机动阶段
if t < 100:
# 阶段1: 匀速直线 (CV)
a = 0
psi_dot = 0
true_model[t] = 0
elif t < 150:
# 阶段2: 加速直线 (CA)
a = 0.5
psi_dot = 0
true_model[t] = 1
elif t < 200:
# 阶段3: 匀速转弯 (CTRV)
a = 0
psi_dot = 0.05
true_model[t] = 2
elif t < 250:
# 阶段4: 减速转弯 (CTRV)
a = -0.3
psi_dot = -0.03
true_model[t] = 2
else:
# 阶段5: 匀速直线 (CV)
a = 0
psi_dot = 0
true_model[t] = 0
# 更新状态
v += a * dt
psi += psi_dot * dt
psi = (psi + np.pi) % (2*np.pi) - np.pi
x += v * dt * np.cos(psi)
y += v * dt * np.sin(psi)
vx = v * np.cos(psi)
vy = v * np.sin(psi)
trajectory[t] = [x, y, vx, vy]
# 添加观测噪声
pos_noise_std = 5.0
measurements = trajectory[:, :2] + np.random.randn(len(trajectory), 2) * pos_noise_std
R = np.eye(2) * pos_noise_std**2
# 运行IMM滤波
models = ['CV', 'CA', 'CTRV']
model_prob = [0.33, 0.33, 0.34]
trans_prob = np.array([
[0.95, 0.025, 0.025],
[0.025, 0.95, 0.025],
[0.025, 0.025, 0.95]
])
imm = IMMFilter(models, model_prob, trans_prob, dt=1.0)
imm.init_state(measurements[0].reshape(-1, 1))
imm_estimates = []
imm_model_probs = []
position_errors = []
for t in range(len(measurements)):
z = measurements[t, :2]
x_est, _ = imm.step(z, R)
imm_estimates.append(x_est.flatten())
imm_model_probs.append(imm.get_model_probabilities().copy())
pos_error = np.sqrt((x_est[0, 0] - trajectory[t, 0])**2 +
(x_est[1, 0] - trajectory[t, 1])**2)
position_errors.append(pos_error)
imm_estimates = np.array(imm_estimates)
imm_model_probs = np.array(imm_model_probs)
# 计算模型切换延迟
model_switch_delay = []
for i in range(1, len(true_model)):
if true_model[i] != true_model[i-1]:
# 找到模型切换点
switch_point = i
# 查找IMM识别切换的时间
for j in range(i, min(i+20, len(imm_model_probs))):
if np.argmax(imm_model_probs[j]) == true_model[i]:
delay = j - i
model_switch_delay.append(delay)
break
# 可视化模型切换分析
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 轨迹与模型概率
ax = axes[0, 0]
ax.plot(trajectory[:, 0], trajectory[:, 1], 'k-', linewidth=2,
label='真实轨迹', alpha=0.8)
# 用颜色表示真实模型
colors = ['blue', 'green', 'red']
model_names = ['CV', 'CA', 'CTRV']
for i in range(len(true_model)-1):
if true_model[i] == true_model[i+1]:
ax.plot(trajectory[i:i+2, 0], trajectory[i:i+2, 1],
color=colors[true_model[i]], linewidth=3, alpha=0.5)
ax.set_xlabel('X位置 (m)')
ax.set_ylabel('Y位置 (m)')
ax.set_title('轨迹与真实运动模型')
ax.legend()
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 添加模型图例
for i, (color, name) in enumerate(zip(colors, model_names)):
ax.plot([], [], color=color, linewidth=3, label=name)
ax.legend(loc='upper right')
# 2. 真实模型与估计模型概率
ax = axes[0, 1]
t = np.arange(num_steps)
# 绘制真实模型(背景)
for i in range(num_steps-1):
if true_model[i] == true_model[i+1]:
ax.axvspan(i, i+1, alpha=0.3, color=colors[true_model[i]])
# 绘制估计模型概率
for i, (color, name) in enumerate(zip(colors, model_names)):
ax.plot(t, imm_model_probs[:, i], '-', linewidth=2,
color=color, label=name)
ax.set_xlabel('时间步')
ax.set_ylabel('模型概率')
ax.set_title('真实模型与估计模型概率')
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim([0, 1])
# 3. 模型切换延迟
ax = axes[0, 2]
if model_switch_delay:
ax.hist(model_switch_delay, bins=np.arange(0, max(model_switch_delay)+2)-0.5,
edgecolor='black', alpha=0.7, color='blue')
avg_delay = np.mean(model_switch_delay)
ax.axvline(x=avg_delay, color='red', linestyle='--',
label=f'平均延迟={avg_delay:.1f}步')
ax.set_xlabel('切换延迟 (步数)')
ax.set_ylabel('频数')
ax.set_title('模型切换延迟分布')
ax.legend()
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无模型切换', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('模型切换延迟')
# 4. 模型概率收敛速度
ax = axes[1, 0]
# 计算模型概率的收敛度量
prob_entropy = -np.sum(imm_model_probs * np.log(imm_model_probs + 1e-10), axis=1)
ax.plot(t, prob_entropy, 'b-', linewidth=2)
ax.set_xlabel('时间步')
ax.set_ylabel('模型概率熵')
ax.set_title('模型不确定性度量 (熵)')
ax.grid(True, alpha=0.3)
# 5. 各模型在对应阶段的概率
ax = axes[1, 1]
# 定义阶段
stages = [
(0, 100, 'CV阶段'),
(100, 150, 'CA阶段'),
(150, 250, 'CTRV阶段'),
(250, 300, 'CV阶段')
]
stage_data = {model: [] for model in model_names}
for start, end, stage_name in stages:
for i, model in enumerate(model_names):
# 计算该阶段该模型概率的平均值
stage_prob = np.mean(imm_model_probs[start:end, i])
stage_data[model].append(stage_prob)
x = np.arange(len(stages))
width = 0.25
for i, (model, color) in enumerate(zip(model_names, colors)):
ax.bar(x + (i-1)*width, stage_data[model], width,
color=color, alpha=0.7, label=model)
ax.set_xlabel('运动阶段')
ax.set_ylabel('平均模型概率')
ax.set_title('各模型在不同阶段的平均概率')
ax.set_xticks(x)
ax.set_xticklabels([stage[2] for stage in stages], rotation=15)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
ax.set_ylim([0, 1])
# 6. 模型切换决策质量
ax = axes[1, 2]
# 计算每个时间步的决策质量
decision_quality = []
for t in range(num_steps):
estimated_model = np.argmax(imm_model_probs[t])
if estimated_model == true_model[t]:
decision_quality.append(1) # 正确
else:
decision_quality.append(0) # 错误
# 滑动窗口计算准确率
window_size = 20
accuracy_sliding = []
for i in range(num_steps - window_size + 1):
window_quality = decision_quality[i:i+window_size]
accuracy_sliding.append(np.mean(window_quality))
t_sliding = np.arange(len(accuracy_sliding))
ax.plot(t_sliding, accuracy_sliding, 'b-', linewidth=2)
ax.axhline(y=0.5, color='r', linestyle='--', alpha=0.5, label='随机猜测')
ax.set_xlabel('时间窗口中心')
ax.set_ylabel(f'模型决策准确率 (窗口大小={window_size})')
ax.set_title('模型切换决策质量')
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim([0, 1])
plt.suptitle('IMM模型切换特性分析', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('imm_model_switching_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印模型切换统计
print("\n" + "="*60)
print("模型切换特性分析")
print("="*60)
if model_switch_delay:
print(f"模型切换次数: {len(model_switch_delay)}")
print(f"平均切换延迟: {np.mean(model_switch_delay):.2f} 步")
print(f"最大切换延迟: {np.max(model_switch_delay):.2f} 步")
print(f"最小切换延迟: {np.min(model_switch_delay):.2f} 步")
else:
print("无模型切换发生")
# 计算总体决策准确率
overall_accuracy = np.mean(decision_quality) * 100
print(f"总体模型决策准确率: {overall_accuracy:.1f}%")
# 分阶段计算准确率
print("\n分阶段模型决策准确率:")
for start, end, stage_name in stages:
stage_quality = decision_quality[start:end]
stage_accuracy = np.mean(stage_quality) * 100
print(f" {stage_name}: {stage_accuracy:.1f}%")
print("="*60)
return {
'trajectory': trajectory,
'true_model': true_model,
'imm_model_probs': imm_model_probs,
'decision_quality': decision_quality,
'switch_delays': model_switch_delay
}
if __name__ == "__main__":
print("="*60)
print("交互多模型滤波实现与分析")
print("="*60)
np.random.seed(42)
# 1. 比较IMM与单一模型
print("\n1. 比较IMM与单一模型性能...")
comparison_results = compare_imm_vs_single_models()
# 2. 分析IMM参数敏感性
print("\n2. 分析IMM参数敏感性...")
parameter_results = analyze_imm_parameters()
# 3. 分析模型切换特性
print("\n3. 分析模型切换特性...")
switching_results = analyze_model_switching()
print("\n演示完成!")
# 总结
print("\n" + "="*60)
print("IMM滤波关键结论")
print("="*60)
print("1. IMM通过混合多个模型来适应目标的不同运动模式")
print("2. 在机动目标跟踪中,IMM通常优于任何单一模型")
print("3. 模型概率的合理设置对IMM性能至关重要")
print("4. 转移概率矩阵影响模型切换的灵敏度和稳定性")
print("5. IMM能够有效识别目标的运动模式变化")
print("6. 模型切换通常有1-3步的延迟,取决于参数设置")
print("7. 在实际应用中,IMM参数需要根据具体场景调整")
print("="*60)9. 总结与工程实践建议
通过本文的三个Demo,我们全面探讨了雷达目标跟踪中的运动模型和坐标转换问题。以下是关键结论和工程实践建议:
9.1 运动模型选择指南
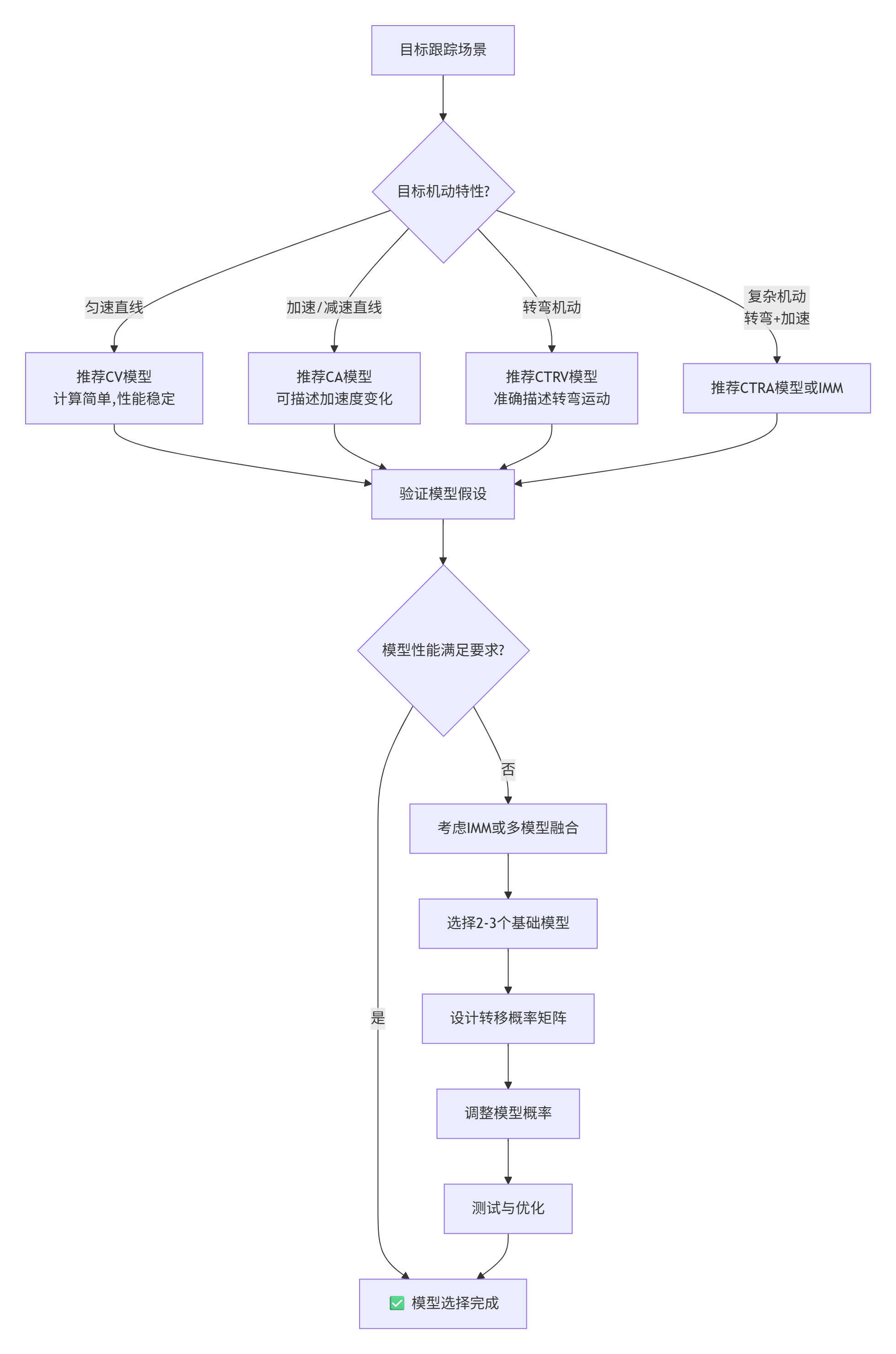
9.2 坐标转换实践建议
-
精度要求不高的场景:使用简单三角转换
-
高精度跟踪场景:使用去偏转换或考虑二阶矩
-
非线性滤波场景:在滤波器中直接使用极坐标观测
-
计算资源受限场景:使用线性化转换
-
实时性要求高的场景:预计算转换表或使用近似公式
9.3 IMM滤波工程实践
-
模型集合选择:
-
通常选择2-3个互补的模型
-
常用组合:CV + CA + CTRV
-
根据目标特性调整模型集合
-
-
参数初始化:
-
初始模型概率:根据先验知识设置,无先验时用均匀分布
-
转移概率矩阵:对角线元素通常设为0.9-0.99
-
过程噪声:根据目标机动性设置
-
-
性能调优:
-
监控模型概率变化
-
调整转移概率以适应目标机动频率
-
使用NEES/NIS进行一致性检验
-
-
计算优化:
-
并行计算各模型滤波
-
使用平方根形式提高数值稳定性
-
实现快速矩阵运算
-
9.4 实际部署考虑
-
实时性要求:
-
优化计算复杂度
-
考虑固定点运算
-
并行化处理
-
-
内存限制:
-
限制历史数据长度
-
使用滑动窗口
-
压缩存储中间结果
-
-
鲁棒性设计:
-
异常值检测与处理
-
数值稳定性保障
-
模型有效性检验
-
-
可维护性:
-
模块化设计
-
参数配置文件化
-
完善的日志记录
-
9.5 未来研究方向
-
自适应IMM:在线学习转移概率和噪声参数
-
深度学习辅助:使用神经网络识别运动模式
-
多传感器融合:雷达+光电+红外多源信息融合
-
分布式跟踪:多雷达组网协同跟踪
-
抗干扰技术:电子战环境下的鲁棒跟踪
9.6 代码资源总结
本文实现的完整代码包括:
-
基础运动模型:
-
CV模型:
CVFilter类 -
CA模型:
CAFilter类 -
CTRV模型:
CTRVFilter类
-
-
坐标转换方法:
-
简单三角转换:
polar_to_cartesian -
去偏转换:
polar_to_cartesian_unbiased -
线性化转换:
polar_to_cartesian_linearized
-
-
IMM滤波实现:
-
完整IMM框架:
IMMFilter类 -
模型结果容器:
ModelResult类
-
-
三个完整Demo:
-
Demo 3-1:不同运动模型对比
-
Demo 3-2:坐标转换方法对比
-
Demo 3-3:IMM滤波实现与分析
-
9.7 下一篇预告
在下一篇博客中,我们将深入探讨多目标跟踪的核心问题:
-
数据关联算法:最近邻、概率数据关联、联合概率数据关联
-
航迹起始与终结:逻辑法、序列概率比检验
-
密集环境下的跟踪:航迹分叉与合并处理
-
多雷达多目标跟踪:时空配准与航迹融合
-
实际工程挑战:计算复杂度、实时性、鲁棒性