1. 什么是WorkFlow
之前咱们的用法是一种QueryEngine的用法,就是将大模型当成一个查询的工具在使用,而workflow是LlmaIndex的新一代编排引擎。
1.1 核心逻辑
LlamaIndex的workflow,本质上是一个事件驱动(Event-driven)的状态机,如果各位友人们经常做开发的话,一定一下就理解。 咱们可以将其流程想象成一场"接力赛":
-
选手(Steps) : 我们会在代码里用
@step装饰函数,这个函数就是step,负责具体的逻辑。 -
接力棒(Events) :我们会用来判断状态的自定义类,继承自
Event,用于在Step间传递数据。 -
终点线(StopEvent) : 和普通的
Event一样,只是作为最后一棒,某个Step返回StopEvent就意味着"接力赛"结束了,咱们将结果返回给用户。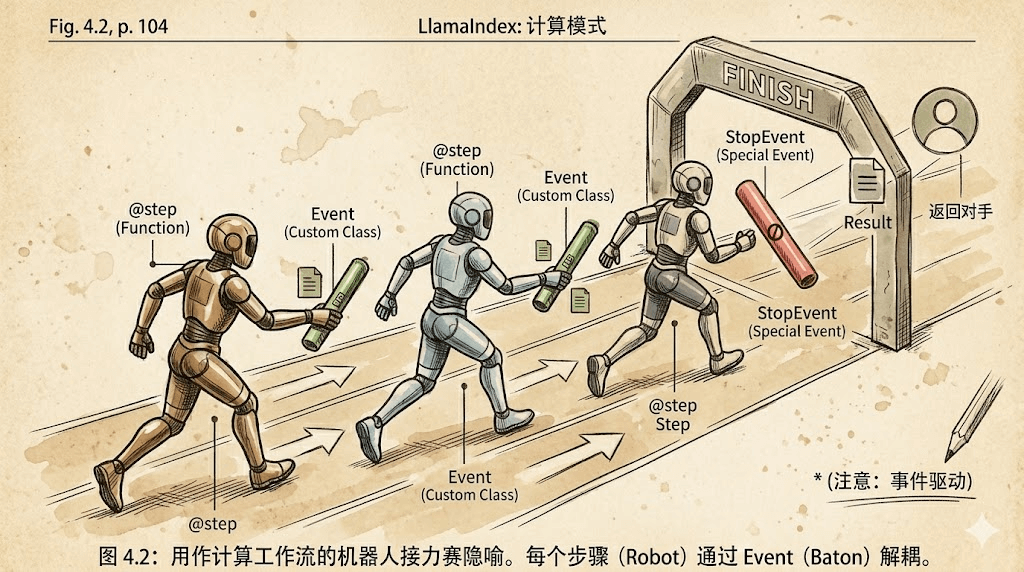
1.2 核心组件
-
Event
是Workflow的灵魂,咱们可以定义各种Event,其决定了数据流向何处。from llama_index.core.workflow import Event
class NewsExtractedEvent(Event):
content: str # 这里可以随便定义内容
xxx: int # 多少条都可以 -
@step
是逻辑处理单元。一个Step可以通过返回值来"发射"事件。
- 生产者 : 返回一个
Event实例。 - 消费者 : 在接收的下一步Step函数的函数声明参数中加上对应的
Event实例。
- 生产者 : 返回一个
-
StartEvent & StopEvent
是流程的"起跑线"和"终点线"。一般我们只用定义
StopEvent,当调用workflow.run()自动会触发StartEvent,任何Step只要返回了StopEvent,整个workflow就会停止并输出结果。
结合起来,就是这样一个极简的Workflow模板
from llama_index.core.workflow import Workflow, step, StartEvent, StopEvent, Event
class ProcessedDataEvent(Event):
data: str
class MyWorkflow(Workflow):
@step
async def ingest(self, ev: StartEvent) -> ProcessedDataEvent:
# 1. 接收初始输入
input_data = ev.get("input")
return ProcessedDataEvent(data=input_data.upper())
@step
async def finish(self, ev: ProcessedDataEvent) -> StopEvent:
# 2. 接收上一步处理后的数据
return StopEvent(result=f"处理完成: {ev.data}")
# 运行
wf = MyWorkflow()
await wf.run(input="hello world") # -> "处理完成: HELLO WORLD"通常来讲,咱们会把step定义给一个调用llm处理的函数. 我们待会儿就用Workflow重写咱们上一篇中的Agent。
2. API获取
咱们这次给大家换换口味,不用本地加载模型,而是用API的方式去调用大模型,所以本篇博客的代码可以在没有显卡的电脑上运行,可以脱离Kaggle的显卡环境。
PS : 虽然调用API更方便,但是本地加载或者本地部署更安全
(阿尔周末也尝试过在kaggle上直接去用vllm/ollama部署,然后调用,但是遇到了太多没法解决的问题,本次就直接用现成的API了。如果能解决,到时候再出一篇教程吧,如果还记得这个事儿的话,哈哈哈)
接下来介绍两个可以用免费模型的API: Groq 和硅基流动。
2.1 Groq
Groq并不是模型开发者,只是大模型的搬运工,是一个推理加速平台,其核心是自研的LPU(Language Processing Unit),所以它的推理速度那是相当惊人,这也是阿尔推荐它的很重要的一个理由。
- Groq模型矩阵
| 模型系列 | 模型 ID (API 调用名) | 厂商 | 上下文窗口 | 特点与优势 |
|---|---|---|---|---|
| Llama 3.3 | llama-3.3-70b-versatile |
Meta | 128k | 最强逻辑,性能对标 GPT-4o |
| Llama 3.1 | llama-3.1-8b-instant |
Meta | 128k | 极速响应,适合简单逻辑与翻译 |
| Llama 3.2 | llama-3.2-11b-vision-preview |
Meta | 128k | 多模态支持,可识别并理解图片 |
| Gemma 2 | gemma2-9b-it |
8k | 指令遵循强,结构化输出更稳定 | |
| Mixtral | mixtral-8x7b-32768 |
Mistral | 32k | 经典的混合专家模型,长文本表现好 |
| Whisper | whisper-large-v3 |
OpenAI | - | 极速语音转文字 (STT) |
-
Groq的限制
Groq的免费层级给的非常慷慨,堪称大善人,但是为了防止滥用,还是设置了很多限制。通常对每个模型独立计算
通常从RPM(Requets Per Minute)每分钟请求数,RPD(Requests Per Day)每天请求数,TPM(Tokens Per Minute)每分钟消耗Token数三个维度限制,当然对于咱们来说是完全够用的
-
注册Groq Api Key
-
进入Groq官网,点击右上角的
Start Building -
用谷歌账号登录即可
-
点击最上面菜单栏的
API KEYS
-
点击 Create API Key,可以设置一个过期日期,然后保存下来,待会儿咱们配置到kaggle的Secrets中即可
-
-
生成API Key
2.2 硅基流动
硅基流动是咱们要介绍的二号大模型的搬运工,国内开发者使用比较多,可以在上面找到很多便宜大碗的模型,也有不少免费的模型可以用,咱们今天就要用它的免费模型。
- 硅基流动模型矩阵
| 模型系列 | 最新代表型号 (API 调用名) | 核心优势 | 上下文窗口 | 状态 |
|---|---|---|---|---|
| DeepSeek | deepseek-ai/DeepSeek-V3.2 |
性能对标顶级闭源模型,极强逻辑 | 128k | 旗舰收费 |
| DeepSeek | deepseek-ai/DeepSeek-R1 |
推理增强模型,擅长复杂数学与逻辑 | 64k | 部分免费 |
| Qwen | Qwen/Qwen3-30B-A3B |
阿里最新一代模型,中文语境指令遵循极强 | 128k | 免费/收费 |
| Qwen-VL | Qwen/Qwen3-VL-72B |
顶级视觉理解能力,支持视频分析 | 32k | 旗舰收费 |
| GLM | Z.ai/GLM-5 |
智谱旗舰,专注于长周期 Agent 任务 | 205k | 旗舰收费 |
| Kimi | moonshotai/Kimi-K2.5 |
原生多模态智能体模型,长文本处理极佳 | 262k | 旗舰收费 |
| Step | stepfun-ai/Step-3.5-Flash |
极高性价比的轻量模型,推理速度极快 | 262k | 低成本/免费 |
| MiniMax | MiniMaxAI/MiniMax-M2.5 |
擅长角色扮演与情感交互 | 197k | 旗舰收费 |
| Llama 3 | meta-llama/Llama-3.3-70B-Instruct |
国际最强开源模型,适配各类 Agent 框架 | 128k | 旗舰收费 |
-
硅基流动的限制
硅基流动有着比Groq更多的可用模型,有不少永久免费的模型, 甚至还有推广(阿尔这里就不贴推广码了,大家自行注册即可)和新用户赠金,但是其免费版的并发数很低,具体的模型也有RPM和TPM限制。
-
注册硅基流动API Key
-
进入硅基流动官网,用手机号或者微信号注册
-
点击左侧侧边栏的API密钥 , 点击新建API密钥
-

-
我们待会儿使用Qwen/Qwen3-8B这个免费模型
3. 代码实战
3.1 环境准备
这次和此前不同,诶,咱们今天用API不用自己加载模型,不用开GPU加速,Accelerator 选择None即可。
然后老样子,先装依赖库
# 1. 确保安装最新版 uv
!pip install -U uv
# 2. 使用修正后的包名进行安装
# llama-index 包含核心组件
# llama-index-llms-groq 是 Groq 的适配器
# llama-index-llms-llms-openai-like 是 所有适配openai接口的适配器
!uv pip install llama-index llama-index-llms-groq llama-index-llms-openai-like feedparser requests transformers注意,这里咱们硅基流动其实也是有专门的定制库的,llama-index-llms-siliconflow,只是这里咱们为了通用性用了llama-index-llms-openai-like。(实际上是因为最开始试了Groq效果不好,觉得换中文模型会好一点,然鹅效果也不好,这次主要还是介绍这个WorkFlow架构吧)
3.2 配置密钥
和上篇博客一样,咱们在Add-ons ->Secrets 中添加上Groq 和硅基流动 的API Key,命名为GROQ_API_KEY 和SILICON-API_KEY(当然,名字无所谓,和代码匹配就好)
3.3 使用API来示例llm
Tools和之前一样,咱们就不赘述了。
-
定义Groq的模型
import os
from llama_index.llms.groq import Groq
from llama_index.core import Settingsos.environ["GROQ_API_KEY"] = user_secrets.get_secret("GROQ_API_KEY")
推荐使用 llama-3.3-70b,它的逻辑推理能力足以应对多智能体协作
Settings.llm = Groq(model="llama-3.3-70b-versatile")
-
定义硅基流动的Qwen模型
from llama_index.llms.openai_like import OpenAILike
Settings.llm = OpenAILike(
model="Qwen/Qwen3-8B",
api_key=user_secrets.get_secret("SILICON-API_KEY"),
api_base="https://api.siliconflow.cn/v1",
is_chat_model=True
)
可以看出来,定制的接口只用定义对应的API KEY在环境变量里,通用的接口需要补充清楚模型名,api-key,api的url等等。
3.4 整体流程
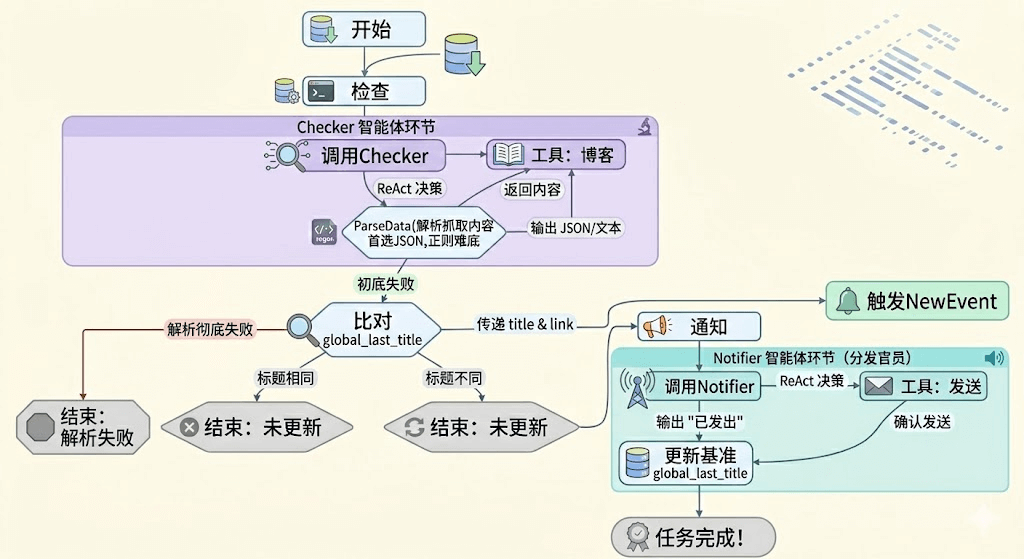
我们打算定义两个Agent
- Checker: 负责去调用获取最新博客以及解析
- Notifier: 负责向我们发送通知
当有新的博客的时候,Checker向Notifer发送事件,告知notifier新博客的标题和链接。然后结束。
整体流程如下:
3.5 定义Event
from llama_index.core.workflow import Workflow, step, StartEvent, StopEvent, Context, Event
class NewBlogPostEvent(Event):
title: str
link: str由于Checker流转向Notifer的时候,只需要给它标题和链接即可,咱们的NewBlogPostEvent只用包含title和link字段。
3.6 定义两个合作的Agent
我们先定义Checker
-
交代好它的角色(ROLE) ,任务(TASK) 和输出要求(OUTPUT_FORMAT)
-
将checker需要调用的工具给它
from llama_index.core.agent.workflow import ReActAgent
CHECKER_SYSTEM_PROMPT = """
ROLE
咱们是一个极其精准的数据提取专家。
TASK
- 调用工具获取最新博客文章。
- 提取其标题和链接。
- 必须以 JSON 格式输出。
OUTPUT_FORMAT
{"title": "文章标题", "link": "文章链接"}
"""
checker = ReActAgent(
name="checker",
system_prompt=CHECKER_SYSTEM_PROMPT,
tools=[tool_get_blog],
llm=Settings.llm
)
然后咱们再来定义Notifier
NOTIFIER_SYSTEM_PROMPT = """
### ROLE
咱们是一个通知官。
### TASK
请根据提供的信息发送通知。
直接调用工具发送,不要解释咱们的行为。发送成功后回复"已发出"即可。
"""
notifier = ReActAgent(
name="notifier",
system_prompt=NOTIFIER_SYSTEM_PROMPT,
tools=[tool_send_all],
llm=Settings.llm
)3.7 定义Workflow
- 从Workflow类派生出我们的workflow类
- 定义step ,从
StartEvent开始到StopEvent结束
这里因为模型的指令跟随能力比较差,格式化输出不了,咱们用了一个正则来兜底。
import os
import re
import json
global_last_title = ""
class DemoBlogMonitor(Workflow):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.checker = checker
self.notifier = notifier
@step
async def check_step(self, ev: StartEvent) -> NewBlogPostEvent | StopEvent:
global global_last_title
rss_url = ev.get("rss_url")
print(f"--- [Checker] 目标: {rss_url} ---")
print(f"--- [Checker] 基准: '{global_last_title}' ---")
response = await self.checker.run(user_msg=f"请提取此 RSS 的最新数据:{rss_url}")
res_text = str(response)
print(f"DEBUG [Agent Output]: {res_text}")
try:
json_match = re.search(r"(\{.*\})", res_text, re.DOTALL)
if not json_match:
raise ValueError("未在回复中找到 JSON 块")
data = json.loads(json_match.group(1))
current_title = data.get("title", "").strip()
current_link = data.get("link", "").strip()
if not current_title or not current_link:
raise ValueError("JSON 数据缺失字段")
# 在 Python 侧进行确定性比对
if current_title != global_last_title:
print(f"发现新动态: {current_title}")
# 注意:这里我们只在成功触发通知时更新状态
return NewBlogPostEvent(title=current_title, link=current_link)
else:
return StopEvent(result=f"判定:内容未更新")
except Exception as e:
# 如果 JSON 解析失败,尝试最后的正则兜底
print(f"WARN: JSON 解析失败 ({e}), 尝试正则兜底...")
link_match = re.search(r"(https?://\S+)", res_text)
if link_match:
link = link_match.group(1).strip(" "\"。")
# 假设引号中间的内容是标题
title_match = re.search(r"[是"\"'](.*?)["\"']", res_text)
title = title_match.group(1) if title_match else "未识别标题"
if title != global_last_title:
return NewBlogPostEvent(title=title, link=link)
return StopEvent(result=f"解析彻底失败。原文: {res_text}")
@step
async def notify_step(self, ev: NewBlogPostEvent) -> StopEvent:
global global_last_title
print(f"--- [Notifier] 正在发送: {ev.title} ---")
await self.notifier.run(user_msg=f"发送通知:标题《{ev.title}》,链接 {ev.link}")
# 只有通知成功发出后,才真正更新全局基准
global_last_title = ev.title
return StopEvent(result=f"完成。新基准已设为: {ev.title}")3.8 运行
async def main():
monitor = DemoBlogMonitor(timeout=120)
print("\n>>> Run #1")
await monitor.run(rss_url="https://blog.algieba12.cn/atom.xml")
print("\n>>> Run #2")
await monitor.run(rss_url="https://blog.algieba12.cn/atom.xml")
await main()这里咱们运行两遍,确认全局变量会同步更新到新状态,咱们实际使用的时候,可以将其持久化存储下来,而不是用变量global_last_title将状态保存在内存中
4. 代码
本篇博客代码示例可在Kaggle笔记本
5. 常见问题 (Q&A)
Q1: 为什么不让 Agent 直接判断是否有更新,而是要在 Python 代码里写 if current_title != global_last_title:?
A: 为了系统的绝对稳定性!(划重点)
大模型在 ReAct 模式下有时会产生"幻觉"或者表现得过于"客气"。
- 现象:最开始的设计是让模型自己比对已知标题和新标题,结果模型看到传进去的旧标题占位符,误以为这是一道"填空题",不仅没有进行比对,还很有礼貌地让我把真实标题填进去。
- 结论 :最佳实践是逻辑解耦。让 Agent 专注于它最擅长的事情(从杂乱网页中精准提取非结构化数据),而将确定性的逻辑判断(字符串比对)交还给传统的 Python 代码来做。
Q2: 为什么一定要强制模型输出 JSON 格式?之前用 | 这种自定义分隔符不行吗?
A: 因为自然语言的边界太模糊,且极易与真实数据冲突。
这是本次开发多智能体协作时遇到的最大痛点!
- 表达欲失控 :高级模型(比如 Llama-3.3 或 Qwen)即使在 Prompt 里千叮咛万嘱咐只输出数据,也极大概率会在结果前后加上"好的,最新文章是..."之类的废话,导致
split("|")直接报错。 - 特殊符号冲突 :碰巧咱们博客的标题里本身就带有
|符号。正则匹配遇到这种情况会产生严重的边界歧义。 - JSON 的优势 :JSON 拥有明确的边界标识(花括号和双引号)。再配合 Python 正则
re.search(r"(\{.*\})")专门抓取大括号之间的内容,就能彻底免疫模型的"废话"。
Q3: 运行 Workflow 时碰到了 WorkflowValidationError: The following events are produced but never consumed 报错是怎么回事?
A: 这是 LlamaIndex 工作流引擎的一种"管道安全检查"机制。
它的意思是:咱们的 check_step 辛辛苦苦生产了一个 NewBlogPostEvent,但是工作流里没有任何一个 Step 声明要接收并处理这个事件,导致事件"无家可归"。
- 排查方法 :检查咱们的消费者函数(在这个例子中是
notify_step)。 - 解决方案 :确保其参数严格加上了对应的类型注解,写成
async def notify_step(self, ev: NewBlogPostEvent)。这样引擎就能自动把上一步产生的数据路由到这里,完成闭环。
Q4: 调用 Groq 或硅基流动 API 时,频繁遇到 429 Too Many Requests 怎么办?
A: 这是因为多智能体循环请求过快,触发了并发限制。
在开发 ReAct Agent 时,模型需要反复执行"思考-行动-观察"的循环,短时间内会产生高密度的 API 请求。
- 冷却机制 :如果是演示项目,可以在每次检测循环之间或者 Step 之间加一个简单的
await asyncio.sleep(2)进行冷却。 - 精简上下文:尽量精简 Prompt 和工具返回的数据量,避免单次请求打满 TPM(Tokens Per Minute)限制。如果是生产环境,建议使用硅基流动的付费版以获取更高的并发额度。
Q5: 在生产环境中,我还应该使用 global global_last_title 这种全局变量来管理状态吗?