一.多副本机制介绍
Kafka受欢迎有一个很大的原因是因为他提供了天然的容灾解决方案,可以应对机器故障等各种异常。Kafka是通过副本机制来实现容灾,扩展来说,有了多副本,我们就有如下优势:
- 高可用性,如果Leader副本所在的Broker宕机,Kafka会在其它副本中选取一个新的副本,确保服务的持续性,具体的规则后面介绍。
- 容灾,即使部分副本数据丢失,只要有一个副本是完整的,数据就不会丢失,简单来说就是多备份情况下数据丢失风险变小。
kafka副本概念
要学习Kafka多副本机制,我们得先熟悉一下Kafka副本机制的几个概念:
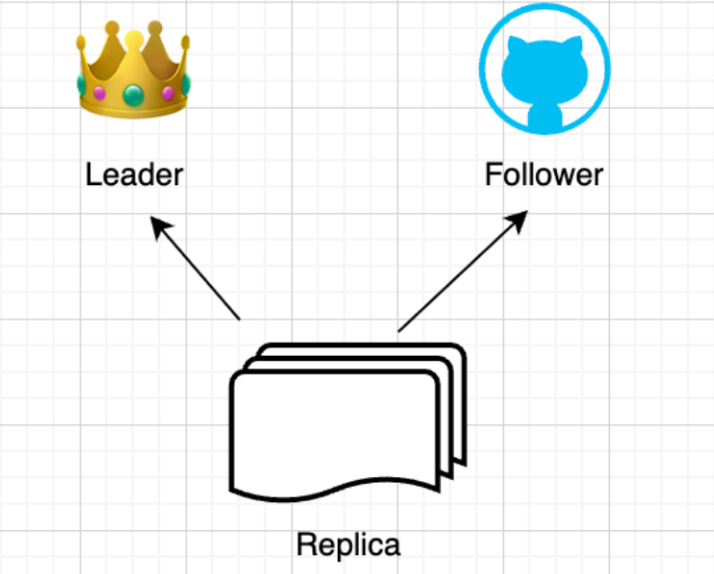
- Replica:Replica是指Kafka集群中的一个副本,它可以是Leader副本或者Follower副本的一种。每个分区都有多个副本,其中一个是Leader副本,其余的是Follower副本。每个副本都保存了分区的完整数据,以保证数据的可靠性和高可用性。
- Leader:Leader是指Kafka集群中的一个分区副本,它负责处理该分区的所有读写请求。Leader副本是唯一可以自主向分区写入数据的副本,它将写入的数据都会同步到所有的Follower副本中,以保证数据的可靠性和一致性。
你以为你的消息是写到了"分区"里,但实际上,你是写到了"分区中那个被选为 Leader 的物理副本"所在的磁盘上。
- Follower:Follower是指Kafka集群中的一个分区副本,Follower副本不能直接向分区写入数据,它只能从Leader副本中复制数据,并将数据同步到本地的副本中,以保证数据的可靠性和一致性。在Leader副本挂掉的时候,Follower副本有机会被选举为新的leader副本从而保证分区的可用性。
这里要注意的一个关键点:副本机制意味着每次数据写入,数据不只是写入一台Broker,最终还会同步到其它Broker作为副本备份。
那么如何创建多副本呢?副本个数是在主题创建时指定的,如果是开发或者测试环境,可以只指定副本数量为1,此时意味着他没有备份。如果是生产环境,一般而言是设置3个副本或者更多,这样可以实现容灾切换。
注意: 分区的副本数必须小于等于Broker数量,比如你的Broker数量只是一个,却想为分片创建两个副本,就会报如下错:

为Kafka内部主题分配多副本
我们上面讲了,,创建Topic时就可以指定多副本,但是Kafka还有一些非用户创建的主题,也就是内部主题,这种主题不是由用户创建的,该如何指定多副本呢?
- 最著名的内部主题:
__consumer_offsets
这是你最常打交道、也是最重要的内部主题。
-
它的作用:记录每个消费者组在每个分区上读到的位移(Offset)。
-
为什么存在:以前 Kafka 的位移是存在 Zookeeper 里的,但 Zookeeper 不适合高频写操作。后来 Kafka 决定"肥水不流外送",直接把位移当成一条普通消息,发到这个专用的主题里。
-
什么时候创建:当你第一次启动一个消费者并加入消费者组时,Kafka 发现这个主题不存在,就会自动创建它。
-
这个配置默认是1,也就是说我们不主动配置的话,这个消费偏移主题就只有1个副本,那么如果这个副本坏了,我们将丢失消费者的偏移提交数据,消费者重启后就无法从上次的位置消费消息。所以为了更高可靠性,如果生产环节有多个broker,这个参数offsets.topic.replication.factor需要大于1,比如常见的就是配置为3。
因为一个消费者组可以消费同一主题的多个分片,所以consumer_offsets 会【groupld+主题对应分片号】来区分各个offset
二.多副本下的写入机制
多副本可以理解为一份数据多个备份,那么我们肯定希望所有副本最终有相同数据,但是这时候就有个问题,写入的时候,是写入到哪个副本呢?
副本写入机制
Kafka的做法是选择其中一个副本作为Leader,Leader就相当于这个副本集合对外的代表,剩余的副本就是数据的备份。对于生产者而言,它只用和Leader打交道,Leader再和其它副本进行数据同步。
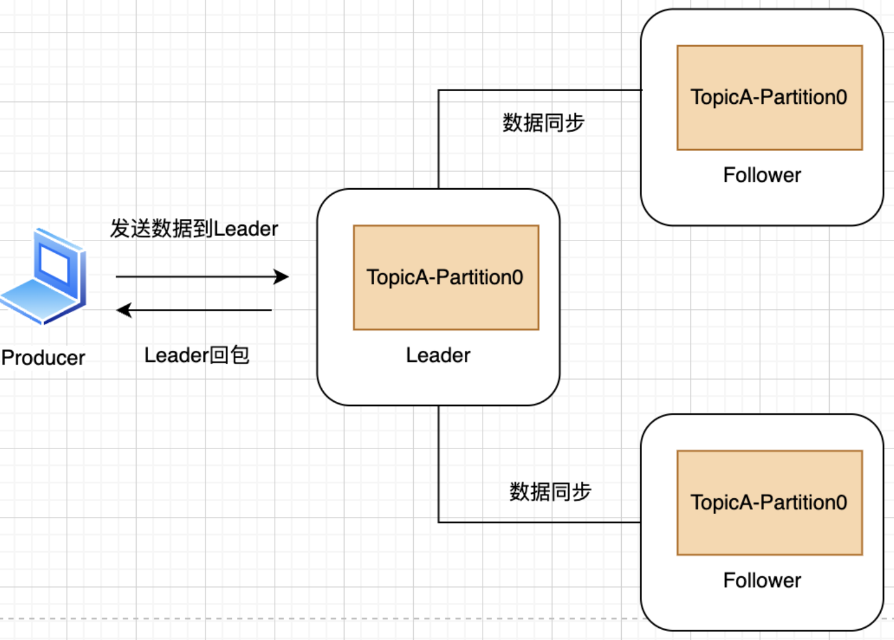
那写入Leader之后,就算写入成功吗,换句话说就是Leader多久回包,是等数据同步完成,还是Leader自己完成写入就回?这里我们需要看下之前章节介绍过下的写入机制,这个机制是由生产者侧的acks配置决定的,不同写入策略的答案是不一样的,详情看之前的笔记。
可以看到,我们只要选择写入策略是acks=all,那么就可以保证进入Kafka的存储数据是基本不会丢失的,因为一个副本挂掉之后,这也是Kafka的可靠性所在:
当然你说几台机器刚好都坏了,那确实可能丢失,但这种极端情况大多数业务后端都是可以忽略的,如果非要解决这种极端情况也不是没有办法,比如副本放在同一城市的不同的机房,这样一个机房发生灾难,另一个机房还能存活,甚至可以跨城市备份,当然这样的成本也会更高。
选择al的可靠性虽然会很高,但是你有没有想过一个问题,假设策略是all,是不是任何一个副本对应的机器,只要挂掉,就无法写入了,举个极端点的例子,一个Kafka集群有1024台机器,如果1台出问题了,整个集群就不可用了,这会不会太严苛了?
实际上,这里的"所有副本"是有条件的,所有是指跟上节奏,在ISR集合里的副本,跟不上节奏的副本就会被剔除在外,这样在保证可靠性的同时,也有一定的容错性。下面,我们来讲讲这个ISR是什么东西。
ISR机制
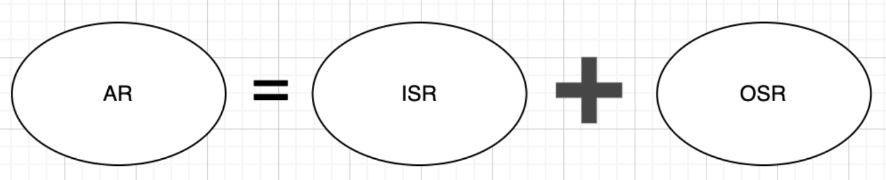
1. 核心公式
在 Kafka 中,这三者的关系可以用一个简单的加法表示:
-
AR (Assigned Replicas) :全部副本。指的是在创建 Topic 时,你指定的所有副本。
-
ISR (In-Sync Replicas) :同步副本。指的是那些紧跟 Leader 步伐、数据没有掉队的"尖子生"。
-
OSR (Out-of-Sync Replicas) :失步副本。指的是因为网络卡顿、机器宕机等原因,数据落后 Leader 太多的"后进生"。
2. 详解:
① ISR
-
成员:包含 Leader 副本和所有能跟上进度的 Follower 副本。
-
权力 :只有在 ISR 里的副本,才有资格被选举为新的 Leader(除非你开启了不顾数据死活的
unclean.leader.election.enable)。 -
考核指标 :Kafka 0.9 版本后,只看一个参数
replica.lag.time.max.ms(默认 10 秒)。- 如果 Follower 在 10 秒内没向 Leader 发请求,或者没追上 Leader 的最新数据,就会被无情踢出 ISR,扔进 OSR。
② OSR
-
状态:它们还在尝试同步,但由于各种原因(比如 Follower 所在的机器 CPU 爆了),它们的数据水位离 Leader 还有一段距离。
-
回归:一旦 OSR 里的副本努力追赶,数据同步进度跟上了 Leader,它又会重新回到 ISR 的怀抱。
③ AR
- 它是静态分配的。你在创建 Topic 时说"我要 3 副本",那么这 3 个物理位置就是 AR,无论它们现在是死是活。
三.副本同步机制
前面说到,有了副本之后,就可以将一份数据,备份到不同机器上,即使部分机器出问题,数据也能找回来,也就实现了可靠性和容灾性。但这里还有两个问题需要考虑:
- 数据如何从Leader同步到Follower,是推还是拉?
- 多副本下哪些数据对外可见?
你可能会认为,数据是先写入Kafka Leader,再由Leader往Follower里写,其实不是的,在Kafka中,是Follower主动拉取Leader的数据进行同步。follower会定时的去fetch拉取leader的数据,成功后会更新自己的位点。在下一次fetch的时候会携带自己的位点,这样leader 就知道follower的进度了。
那么follower怎么拉取数据呢?
首先,不可能拉所有数据,不然每次拉取的成本太高,**一定是根据某个偏移来拉,这里就要引入LEO(Log End Offset)**的概念:
LEO是指下一条要写入的位置,根据LEO,Leader就知道某个Follower数据同步到哪里了。
根据所有ISR副本的LEO,实际就能知道目前数据的同步情况在所。有ISR副本中都同步的数据,才算是真正落地的数据,是不是描述起来比较绕?所以Kafka抽象了一个叫HW的概念来表示这些真正落地的数据。
HW全称是High Watermark,相当于是一条高水位线,在高水位线之下的消息,都已经被所有的ISR副本复制,属于已经落地的消息,这些确认的数据,才是可以对外展示的,也就是说这些高水位之下的消息才可以被消费者拉取到。
任何等于或高于高水位线的消息,都可能还没有被所有的ISR副本复制,因此属于未落地消息,不会被消费者读取到,我们用下图例子来。进行更直观的讲解:
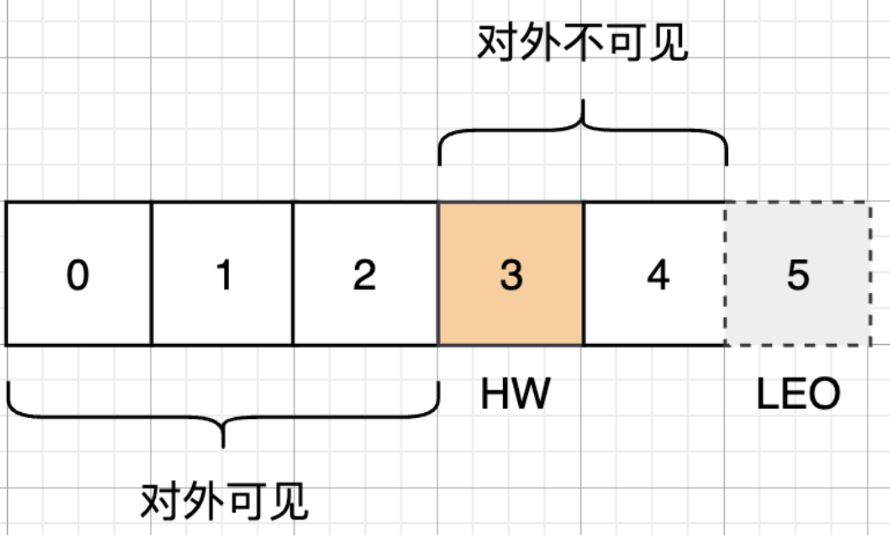
- HW目前是在3号位置。
- 在3号位置之前的0,1,2位置,是对外可见的
- 在3号位置及以后的3,4号位置,对外是不可见的,也就是无法拉取到
- 最后一条数据是在4号位置,下一条数据应该写入到5号位置,所以5号位置就是LEO所在
所以影响HW的,是所有ISR副本中的最小的那个LEO,因为ISR中的副本不止一个,所以是最小的那个
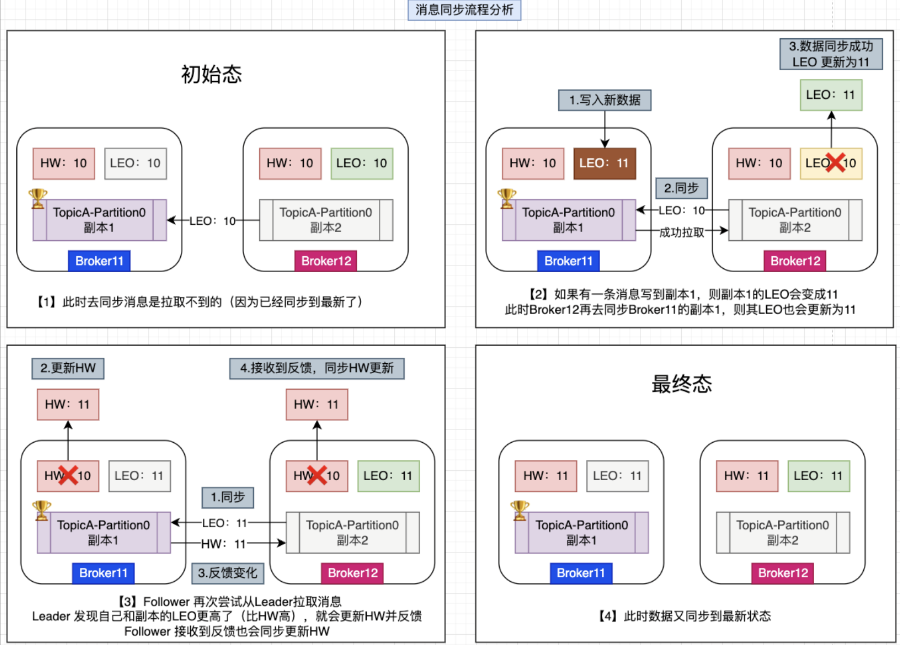
接下来进行数据同步再梳理
首先就是前置条件:有一个主题TopicA,为了简单我们设定只有一个分片Partition0;主题A有两个副本,副本1和副本2,副本1是Leader副本,副本2是Follower副本。副本1在Broker11上,副本2在Broker12上,副本1和副本2的HW和LEO都处于10这个位置: