Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合
- [0. 导言](#0. 导言)
-
- [0.1 路线四不是"少一个输入",而是问题定义被重写](#0.1 路线四不是“少一个输入”,而是问题定义被重写)
- [0.2 为什么这是必然演化](#0.2 为什么这是必然演化)
- [1. 为什么 pose-aware 设定越来越不够](#1. 为什么 pose-aware 设定越来越不够)
-
- [1.1 posed sparse-view 本质上是一个被清理过的研究设定](#1.1 posed sparse-view 本质上是一个被清理过的研究设定)
- [1.2 从受控多视图到真实图像集合,posed 假设为什么不可持续](#1.2 从受控多视图到真实图像集合,posed 假设为什么不可持续)
- [1.3 工程判断:为什么 pose-free 是应用侧的必需品](#1.3 工程判断:为什么 pose-free 是应用侧的必需品)
- [2. posed → unposed:问题本质发生了什么变化](#2. posed → unposed:问题本质发生了什么变化)
-
- [2.1 这不只是"多估计一个位姿变量"](#2.1 这不只是“多估计一个位姿变量”)
- [2.2 pose-free 与 generalized SfM 的关系是什么](#2.2 pose-free 与 generalized SfM 的关系是什么)
- [2.3 尺度、规范自由度与错误传播](#2.3 尺度、规范自由度与错误传播)
- [2.4 为什么这会改变模型设计](#2.4 为什么这会改变模型设计)
- [3. canonical space 思想为什么重要](#3. canonical space 思想为什么重要)
-
- [3.1 NoPoSplat 的关键装置:把一个输入视角锚成规范坐标系](#3.1 NoPoSplat 的关键装置:把一个输入视角锚成规范坐标系)
- [3.2 canonical space 缓解了什么](#3.2 canonical space 缓解了什么)
- [3.3 它与显式全局位姿估计的区别,以及局限](#3.3 它与显式全局位姿估计的区别,以及局限)
- [4. PF3plat:粗对齐 + refinement + confidence 的路线](#4. PF3plat:粗对齐 + refinement + confidence 的路线)
-
- [4.1 为什么粗对齐会成为 pose-free 下的必要步骤](#4.1 为什么粗对齐会成为 pose-free 下的必要步骤)
- [4.2 geometry confidence 的结构性意义](#4.2 geometry confidence 的结构性意义)
- [4.3 PF3plat 相比 canonical-space-only 多解决了什么](#4.3 PF3plat 相比 canonical-space-only 多解决了什么)
- [4.4 geometry confidence 很可能成为标准模块](#4.4 geometry confidence 很可能成为标准模块)
- [5. SelfSplat:不依赖 3D prior 的意义与难点](#5. SelfSplat:不依赖 3D prior 的意义与难点)
-
- [5.1 "3D prior-free"为什么重要](#5.1 “3D prior-free”为什么重要)
- [5.2 reciprocal improvement 的方法结构](#5.2 reciprocal improvement 的方法结构)
- [5.3 这种路线为什么难](#5.3 这种路线为什么难)
- [5.4 相比 PF3plat / Splatt3R 的取舍](#5.4 相比 PF3plat / Splatt3R 的取舍)
- [6. Splatt3R:foundation geometry 为什么能成为新基座](#6. Splatt3R:foundation geometry 为什么能成为新基座)
-
- [6.1 从 photometric hard learning 到 foundation geometry bootstrapping](#6.1 从 photometric hard learning 到 foundation geometry bootstrapping)
- [6.2 foundation geometry 的结构意义](#6.2 foundation geometry 的结构意义)
- [6.3 foundation geometry 与 end-to-end 3DGS 的张力在哪里](#6.3 foundation geometry 与 end-to-end 3DGS 的张力在哪里)
- [6.4 这是否意味着未来会更多采用"先 geometry,后 Gaussian 属性扩展"的路线](#6.4 这是否意味着未来会更多采用“先 geometry,后 Gaussian 属性扩展”的路线)
- [7. AnySplat:从 stereo / sparse 走向 arbitrary image collections](#7. AnySplat:从 stereo / sparse 走向 arbitrary image collections)
-
- [7.1 问题推进:不再只处理"成对/小规模 pose-free"](#7.1 问题推进:不再只处理“成对/小规模 pose-free”)
- [7.2 为什么 arbitrary image collections 会再次抬高难度](#7.2 为什么 arbitrary image collections 会再次抬高难度)
- [7.3 统一预测 scene + cameras,为什么是更真实的任务定义](#7.3 统一预测 scene + cameras,为什么是更真实的任务定义)
- [8. TokenSplat:为什么开始做 token-aligned pose-free reconstruction](#8. TokenSplat:为什么开始做 token-aligned pose-free reconstruction)
-
- [8.1 从几何对齐走向特征对齐](#8.1 从几何对齐走向特征对齐)
- [8.2 为什么 token alignment 在 pose-free 里会越来越重要](#8.2 为什么 token alignment 在 pose-free 里会越来越重要)
- [8.3 pose estimation 与 Gaussian reconstruction 为什么越来越联合](#8.3 pose estimation 与 Gaussian reconstruction 为什么越来越联合)
- [8.4 TokenSplat 如何缓解 overlapping Gaussians 的冗余与错配](#8.4 TokenSplat 如何缓解 overlapping Gaussians 的冗余与错配)
- [8.5 路线四方法演化图与统一对比](#8.5 路线四方法演化图与统一对比)
- [9. pose-free 共同失败模式:尺度歧义、局部重叠不足、错配累积](#9. pose-free 共同失败模式:尺度歧义、局部重叠不足、错配累积)
-
- [9.1 尺度歧义](#9.1 尺度歧义)
- [9.2 局部重叠不足](#9.2 局部重叠不足)
- [9.3 错配累积](#9.3 错配累积)
- [9.4 photometric loss 的几何约束变弱](#9.4 photometric loss 的几何约束变弱)
- [9.5 foundation prior 的 domain bias](#9.5 foundation prior 的 domain bias)
- [9.6 一个综合判断](#9.6 一个综合判断)
- [10. 对机器人、移动采集、in-the-wild 3D 的意义](#10. 对机器人、移动采集、in-the-wild 3D 的意义)
-
- [10.1 对机器人视觉与在线采集的意义](#10.1 对机器人视觉与在线采集的意义)
- [10.2 对 casual capture 与消费级采集的意义](#10.2 对 casual capture 与消费级采集的意义)
- [10.3 对车载、头戴与空间感知的意义](#10.3 对车载、头戴与空间感知的意义)
- [10.4 为什么路线四会反过来重塑前馈式 3DGS 的问题定义](#10.4 为什么路线四会反过来重塑前馈式 3DGS 的问题定义)
- [11. 结语](#11. 结语)
- 参考文献
0. 导言
0.1 路线四不是"少一个输入",而是问题定义被重写
在前几条 feed-forward 3DGS 路线中,问题通常被写成:给定一组稀疏输入图像及其已知相机参数,直接前馈预测一组可渲染的 3D Gaussian primitives。pixelSplat、MVSplat、DepthSplat 虽然在高斯布局方式、深度建模与多视图聚合机制上各不相同,但它们共享一个更深层的前提:相机与场景之间的几何关系已经由外部系统提供,网络要学的是"如何把已知几何条件转成高斯表示"。
路线四出现以后,问题不再是"在已知位姿下生成更好的高斯",而变成了:在缺失外参与内参、输入重叠不足、尺度不稳定、图像顺序任意的前提下,如何仍然构造一个几何上自洽、渲染上可用的 Gaussian scene representation。NoPoSplat、PF3plat、SelfSplat、Splatt3R、AnySplat、TokenSplat 代表的并不是一组零散技巧,而是一条明确的方法学转向:前馈式 3DGS 不再把 pose 当作外部真值,而开始把 camera 与 scene 一起视为需要 jointly infer 的对象。
形式上,可将 posed 与 pose-free 两类任务分别写为:
G ^ = f θ ! ( I i , K i , T i i = 1 N ) , (1) \hat{\mathcal G}= f_{\theta}!\left({I_i,K_i,T_i}_{i=1}^{N}\right), \tag{1} G^=fθ!(Ii,Ki,Tii=1N),(1)
以及
( G ^ , C ^ ) = f θ ! ( I i i = 1 N ) , C ^ = ( K ^ i , T ^ i ) i = 1 N . (2) (\hat{\mathcal G},\hat{\mathcal C})= f_{\theta}!\left({I_i}{i=1}^{N}\right), \qquad \hat{\mathcal C}= {(\hat K_i,\hat T_i)}{i=1}^{N}. \tag{2} (G^,C^)=fθ!(Iii=1N),C^=(K^i,T^i)i=1N.(2)
其中, G \mathcal G G 表示高斯场景, I i I_i Ii 表示输入图像, K i , T i K_i,T_i Ki,Ti 分别表示相机内参与外参。式 ( 1 ) (1) (1) 中 camera 是条件,式 ( 2 ) (2) (2) 中 camera 变成了输出变量。真正的分歧不在于"有没有位姿输入",而在于相机是否仍然是已知边界条件。
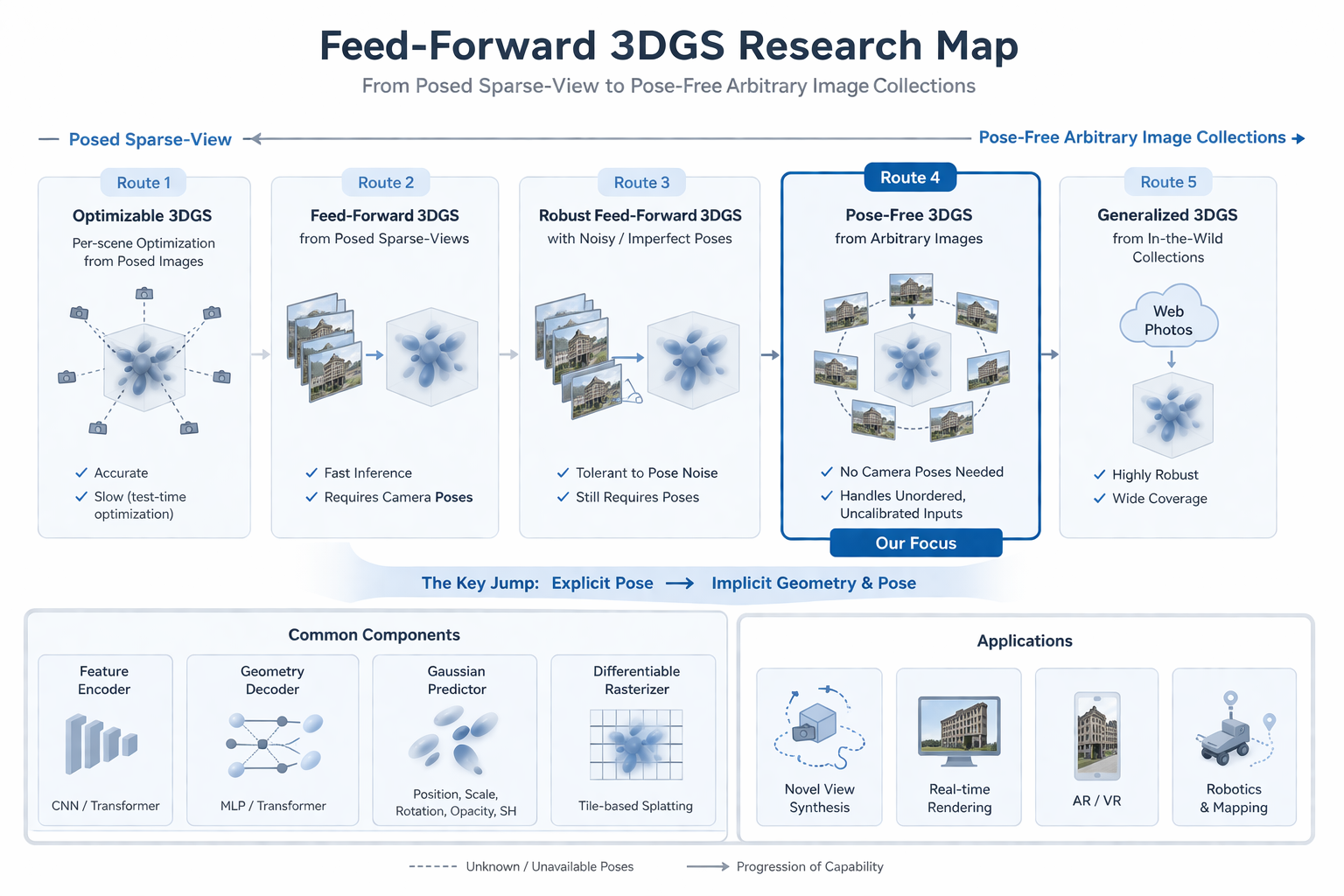
0.2 为什么这是必然演化
真实世界 3D 重建很少满足"少量图像 + 干净重叠 + 精确标定 + 受控采集路径"这一组同时成立的假设。DUSt3R 已经明确把"arbitrary image collections、无标定、无位姿"的重建设定推到台前;MASt3R 进一步将 matching 建立在 3D pointmap 表达之上;MASt3R-SfM 则直接把 unconstrained image collections 作为 SfM 的新标准输入范式。路线四正是在这样的背景下出现:如果 feed-forward 3DGS 真的想成为真实世界 3D 的通用表示接口,它最终就必须面对 uncalibrated image collections,而不能永远停留在被清理过的 posed sparse-view 研究设定中。
换句话说,路线四的历史作用,不是替 posed 路线补一个可选分支,而是把前馈式 3DGS 从"实验室重建器"推向"真实世界图像集合重建器"。这对机器人视觉、移动采集、casual capture、世界模型接口都具有结构性意义。
1. 为什么 pose-aware 设定越来越不够
1.1 posed sparse-view 本质上是一个被清理过的研究设定
pixelSplat 从图像对出发重建 3D Gaussian radiance field,MVSplat 用 plane sweeping cost volume 来稳定高斯中心估计,DepthSplat 则把预训练单目深度特征引入多视图深度与高斯重建。这些方法很强,但它们强在已知相机条件下的高斯预测能力,而不是对真实采集不确定性的处理能力。
这类设定通常默认以下条件成立:
- 第一,输入相机内外参可信;
- 第二,视图之间具有足够几何重叠;
- 第三,输入视角分布与训练分布足够相近;
- 第四,重建链路中的几何误差主要来自 scene ambiguity,而不是 camera ambiguity。上述前提一旦成立,网络便可以把绝大部分建模容量投入到深度估计、属性预测、可见性聚合与渲染质量提升上。
但真实世界采集恰恰经常违反这些前提。手机随拍、机器人移动采集、车载相机流、头戴设备、网络图像集合、旅游照片、无人机非规则航迹,都很难保证精确 pose、稳定 overlap 与受控尺度。MASt3R-SfM 对 unconstrained image collections 的强调,本身就说明传统"先有干净相机、再做三维"的范式已经难以覆盖现实输入。
1.2 从受控多视图到真实图像集合,posed 假设为什么不可持续
形式上,受控采集更接近一个局部多视图系统,而真实输入更接近一个图像集合问题。设图像集合为
I = I i i = 1 N , E = ( i , j ) ∣ Overlap ( I i , I j ) > 0 , (3) \mathcal I= {I_i}_{i=1}^{N}, \qquad \mathcal E= {(i,j)\mid \text{Overlap}(I_i,I_j) > 0}, \tag{3} I=Iii=1N,E=(i,j)∣Overlap(Ii,Ij)>0,(3)
则 posed 设定默认图结构 E \mathcal E E 具有较稳定的几何可用性,并且每个节点的相机参数是外部已知;而在真实图像集合中, E \mathcal E E 往往稀疏、非均匀、甚至局部断裂,相机参数也不再可直接使用。
需要明确的是,路线四不是因为"大家想让任务更难"才出现,而是因为一旦任务面向真实世界输入,posed 假设本身就不再可持续。NoPoSplat 直接把 sparse unposed images 作为输入,PF3plat 明确指出 dense views、accurate poses、substantial overlaps 这些常见假设在现实中经常不成立,AnySplat 更进一步把 uncalibrated image collections 与 casually captured multi-view datasets 当作目标场景。
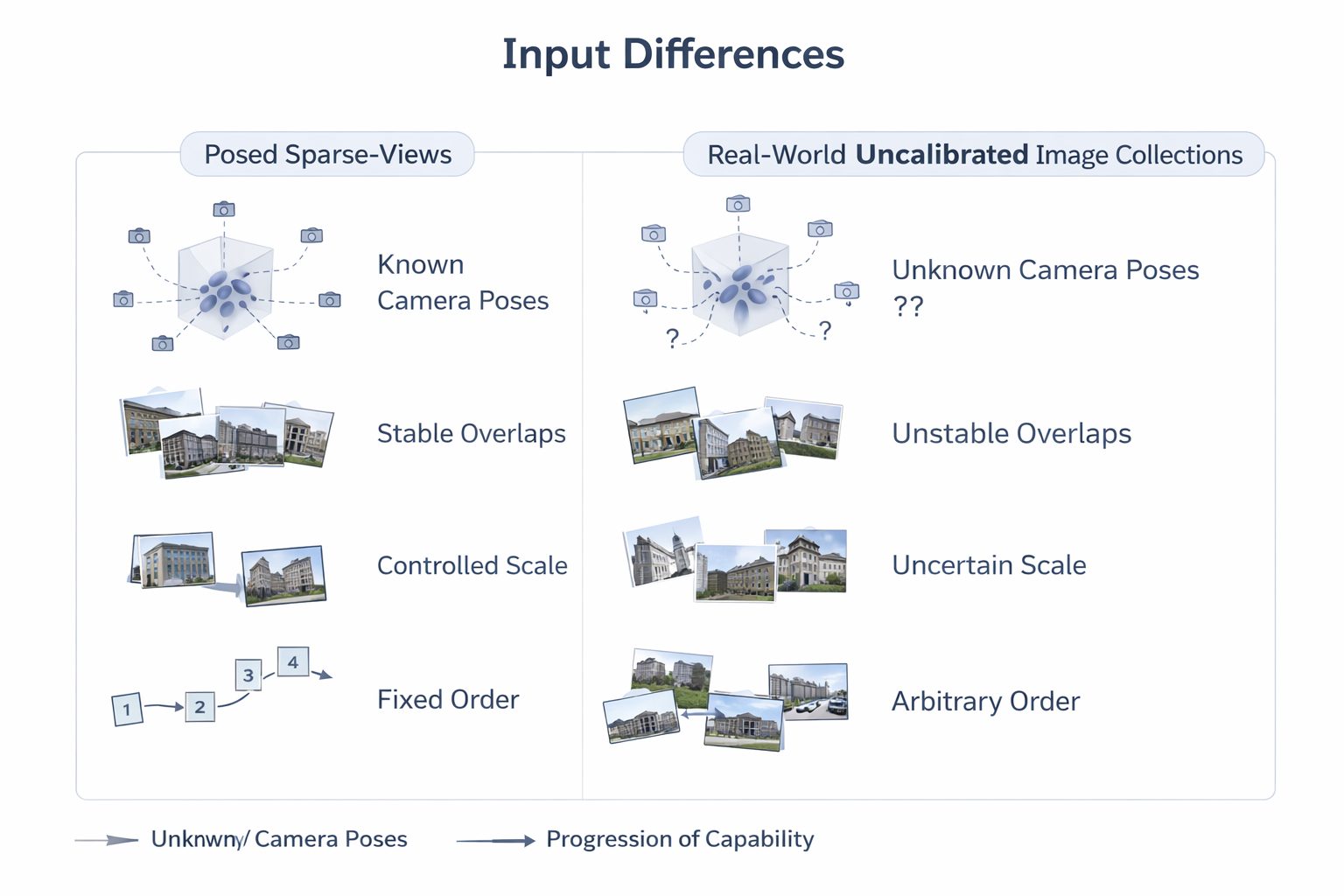
1.3 工程判断:为什么 pose-free 是应用侧的必需品
从工程链路看,严格依赖外部相机求解意味着系统前面必须有一条稳定、可扩展、跨场景泛化的 SfM/SLAM/标定链路;而在许多实际流程中,这条链路反而是最脆弱的环节。MASt3R-SfM 明确指出传统由 minimal solvers 组成的 SfM 管线会传播误差,并在 overlap 不足、运动不足等场景失败。路线四本质上是在把这些上游不确定性前移到模型定义内部,用 joint scene-camera estimation 的方式重新组织任务。
真实应用天然要求 pose-free / uncalibrated 方案,不是因为它更"先进",而是因为它更贴近原始输入分布。
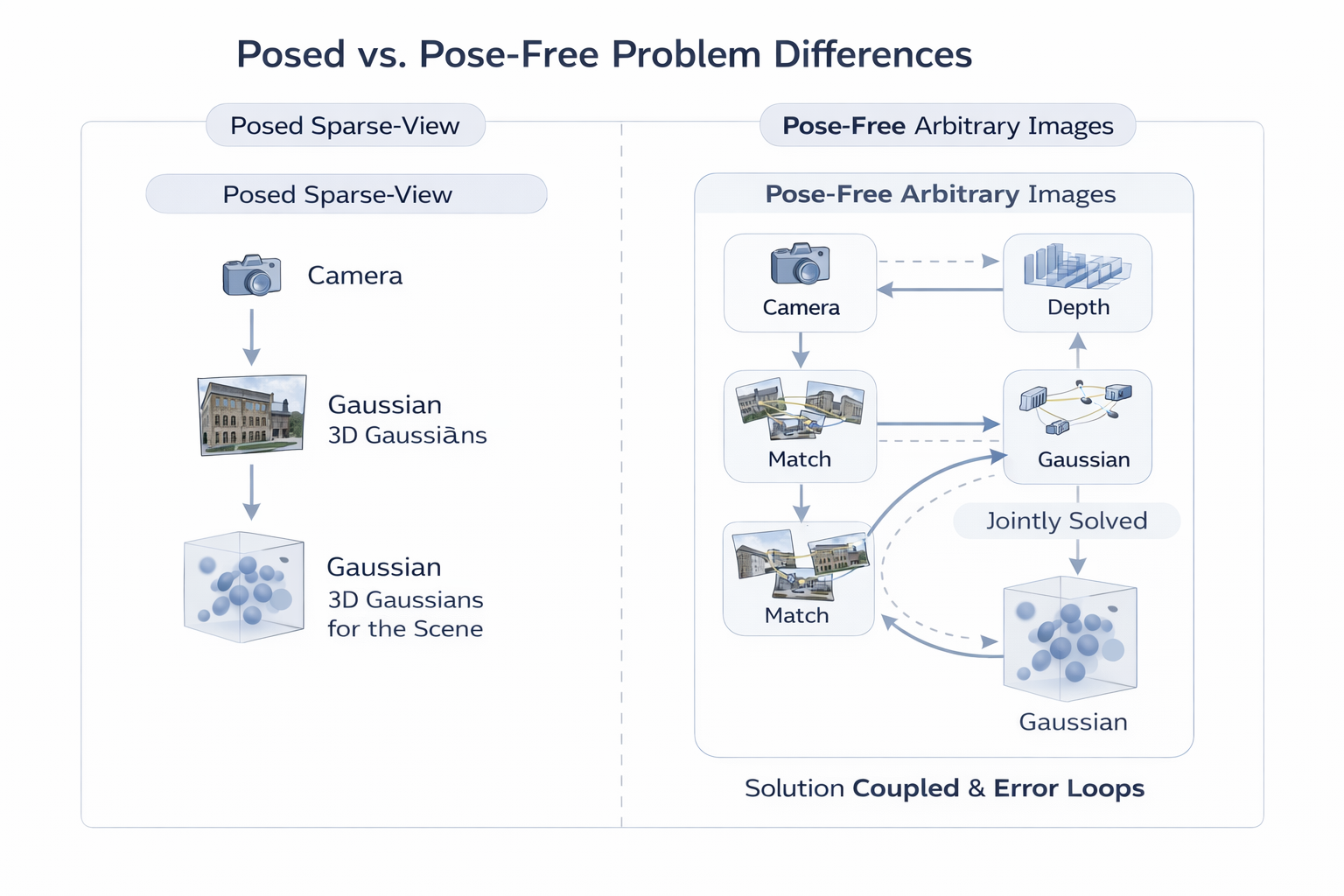
2. posed → unposed:问题本质发生了什么变化
2.1 这不只是"多估计一个位姿变量"
如果把 posed 任务理解成"给定相机后估计场景",那么 unposed 任务其实更接近"同时估计场景与相机"。这意味着 scene representation 与 pose estimation 不再是串联关系,而是耦合关系。可以把它抽象成:
min G , C L render ! ( R ( G , C ) , , I ) + λ L geom ( G , C ) , (4) \min_{\mathcal G,\mathcal C} \mathcal L_{\text{render}}!\left( \mathcal R(\mathcal G,\mathcal C),, \mathcal I \right) + \lambda \mathcal L_{\text{geom}}(\mathcal G,\mathcal C), \tag{4} G,CminLrender!(R(G,C),,I)+λLgeom(G,C),(4)
其中 R \mathcal R R 是 Gaussian renderer, C \mathcal C C 是所有相机参数集合。与 posed 场景相比, C \mathcal C C 不再是常量,而是优化/预测变量,因此任何相机误差都会直接改变渲染监督的几何解释。
PF3plat 对这一点给出了非常直接的观察:在 pixel-aligned 3DGS 中,一旦跨视图 Gaussian 错位,训练梯度会变得 noisy 或 sparse,导致训练不稳定、难收敛。换句话说,位姿误差不是下游误差,而是直接污染高斯布局与监督信号本身的上游误差。
2.2 pose-free 与 generalized SfM 的关系是什么
本篇的一个核心判断是:pose-free 前馈式 3DGS,本质上更接近 generalized SfM + feed-forward Gaussian reconstruction 的耦合问题。
DUSt3R 将 arbitrary image collections 下的重建写成 pointmap regression,MASt3R 在此基础上把 matching grounded in 3D,MASt3R-SfM 则明确把 unconstrained image collections 下的 joint camera/geometry recovery 当作核心任务。路线四中的多篇工作,本质上都在做类似的事:不是在既有相机下重建高斯,而是在 feed-forward 框架里重演一遍"如何从图像集合中恢复相机---几何关系"。
因此,pose-free 3DGS 与 generalized SfM 的共同问题包括:
- 一是 correspondence 是否稳定;
- 二是 coordinate frame 如何确定;
- 三是尺度与 gauge ambiguity 如何处理;
- 四是局部错误如何避免在全局表示中累积。
但它又不同于传统 SfM。传统 SfM 输出的是 points / cameras / sparse-dense geometry,而 pose-free 3DGS 还要输出可渲染、高效、显式的 Gaussian scene representation。因此它并不是"先 SfM 再渲染"的简单组合,而是一个更高耦合度的 joint scene-camera estimation + differentiable rendering 问题。
2.3 尺度、规范自由度与错误传播
在无绝对位姿约束的情况下,至少存在一个相似变换规范自由度。形式上,对任意 S ∈ S i m ( 3 ) S \in \mathrm{Sim}(3) S∈Sim(3),都有
Π ( K i , T i , X ) = Π ! ( K i , , T i S − 1 , , S X ) , (5) \Pi(K_i,T_i,X)= \Pi!\left(K_i,,T_i S^{-1},,S X\right), \tag{5} Π(Ki,Ti,X)=Π!(Ki,,TiS−1,,SX),(5)
其中 Π \Pi Π 是投影算子, X X X 是场景点。式 ( 5 ) (5) (5) 表明:如果没有额外锚定,camera 与 scene 的联合解只在相似变换意义下可辨识。NoPoSplat 明确把 scale ambiguity 作为核心问题讨论,并引入 intrinsic token embedding 来辅助尺度预测,这已经说明 pose-free 下"尺度"不是附属细节,而是任务结构的一部分。
进一步地,高斯中心误差可以抽象为多路误差的合成:
δ μ ≈ J d , δ d + J p , δ T + J m , δ m , (6) \delta \mu \approx J_{d},\delta d + J_{p},\delta T + J_{m},\delta m, \tag{6} δμ≈Jd,δd+Jp,δT+Jm,δm,(6)
其中 δ d \delta d δd 表示深度误差, δ T \delta T δT 表示位姿误差, δ m \delta m δm 表示匹配误差, J ⋅ J_{\cdot} J⋅ 为相应雅可比。式 ( 6 ) (6) (6) 不是某篇论文的原始公式,而是路线四问题结构的一个紧凑概括:在 posed 设定中, δ T \delta T δT 常被外部系统压到很小;而在 pose-free 设定中, δ T \delta T δT 本身就是主变量,且会与 δ d , δ m \delta d,\delta m δd,δm 互相放大。
2.4 为什么这会改变模型设计
这意味着 pose-free 模型设计不可能只在 posed backbone 上"删掉 pose 输入"就结束。它必须重新处理四类结构性问题:
第一,如何建立统一坐标组织;
第二,如何在缺少可靠 pose 时建立 coarse alignment;
第三,如何把 correspondence uncertainty 显式纳入模型;
第四,如何避免 photometric loss 在错误相机条件下失真。
也正因为如此,路线四才会自然演化出 canonical space、coarse alignment、foundation geometry、token-aligned fusion、geometry confidence 这些关键设计点。
3. canonical space 思想为什么重要
3.1 NoPoSplat 的关键装置:把一个输入视角锚成规范坐标系
NoPoSplat 的核心设计非常值得单独看待。它不是先恢复每个输入视图的全局位姿,再把各视角局部高斯变换到统一世界坐标,而是直接把一个输入视角的局部相机坐标系定义为 canonical space,然后训练网络将所有视图对应的 Gaussian primitives 统一预测到这个参考空间中。这样做的直接收益是,模型避开了"每帧局部预测 + 外部 pose 拼接"的误差链条。
形式上,可记参考视角为 r r r,其坐标系为 F r \mathcal F_r Fr,则所有高斯中心满足
μ j ∈ F r , G ^ = f θ ! ( I i i = 1 N ; r ) . (7) \mu_j \in \mathcal F_r, \qquad \hat{\mathcal G}= f_{\theta}!\left({I_i}_{i=1}^{N}; r\right). \tag{7} μj∈Fr,G^=fθ!(Iii=1N;r).(7)
式 ( 7 ) (7) (7) :它把"没有全局坐标"这个问题,转写为"先选一个局部但统一的参考坐标系"。本质上,这是对 pose-free 多视图问题的一次规整化(regularization by coordinate anchoring)。
3.2 canonical space 缓解了什么
canonical space 至少缓解了三件事。
第一,它减少了显式相机求解对高斯布局的直接依赖。网络不是在多个局部视图里分别预测再做变换,而是从一开始就学习一个统一参考系中的场景表示。
第二,它给尺度、朝向、视图聚合提供了一个规范容器。NoPoSplat 对 scale ambiguity 的处理说明 canonical space 不是简单换坐标名,而是与尺度锚定、相机内参编码、下游 pose estimation 共同构成一个完整框架。
第三,它把 pose-free 问题从"全局相机求解失败则全盘失败"转成"先在 canonical frame 内形成可渲染结构,再从结构中恢复相机关系"。NoPoSplat 的 coarse-to-fine pose estimation 就体现了这种思路:先有 canonical 结构,再做更精细的相机定位。
3.3 它与显式全局位姿估计的区别,以及局限
需要明确的是,canonical space 并不等于"恢复了真实世界全局坐标"。它更多是一个内部规范参考系,而不是外部物理世界坐标。它解决的是多视图预测如何放到一个共同 frame 中,而不是绝对意义上的 world-frame localization。
因此它也有明确局限。
其一,参考视角的选择会影响坐标组织稳定性;
其二,当参考视角视野狭窄、遮挡严重或 overlap 极低时,canonical anchor 可能本身就不稳定;
其三,canonical space 只是把"坐标统一"问题规整化,并没有自动解决 correspondence uncertainty 与 scale ambiguity 的全部来源。
这也是为什么路线四很快从 canonical-space-only 走向 PF3plat 的 coarse alignment + confidence,再走向 Splatt3R 的 foundation geometry,最后走向 TokenSplat 的 token-level alignment。NoPoSplat 的历史作用,不在于给出了最终答案,而在于它最早清晰地展示了:pose-free 3DGS 首先需要一个内部统一坐标装置。
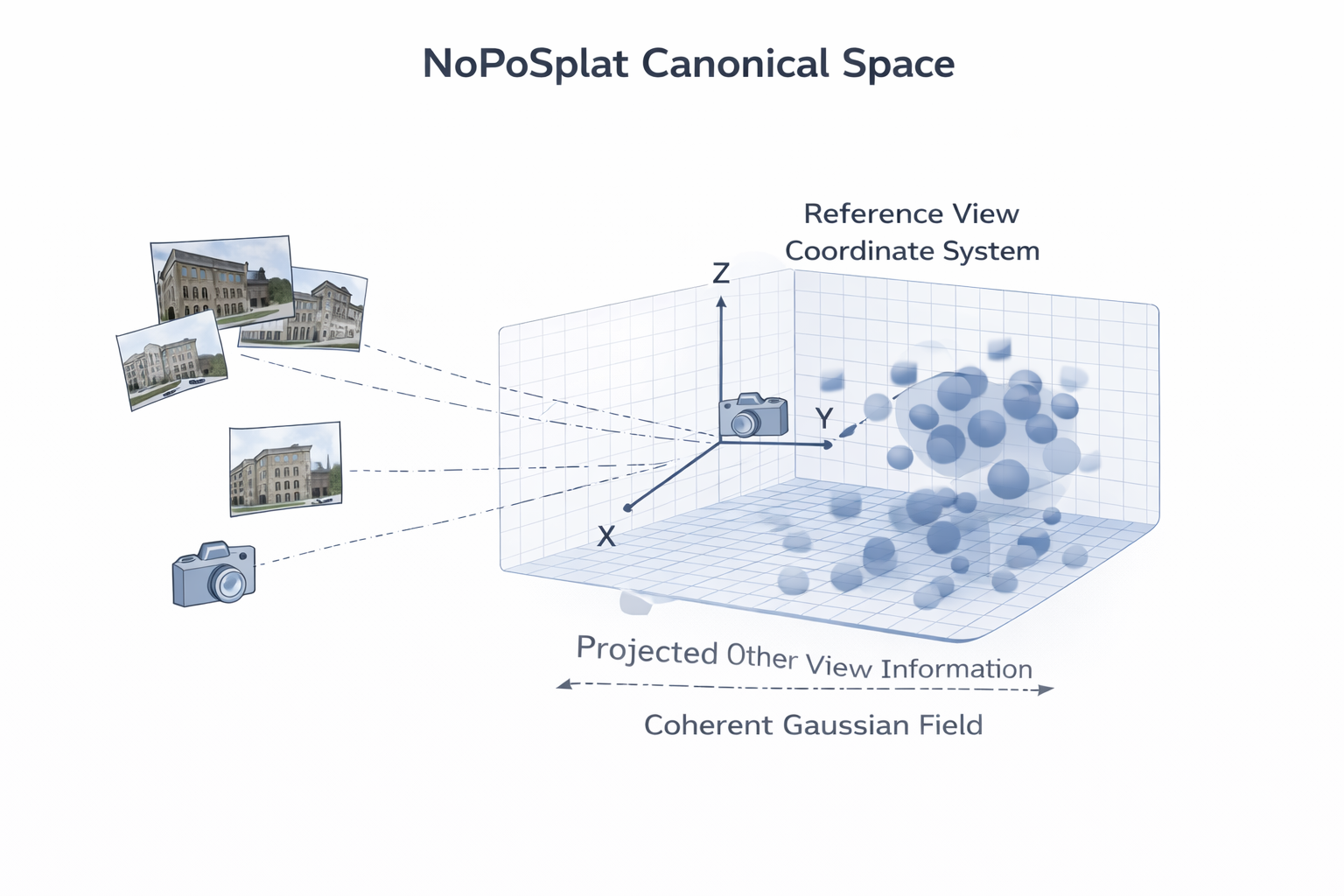
4. PF3plat:粗对齐 + refinement + confidence 的路线
4.1 为什么粗对齐会成为 pose-free 下的必要步骤
PF3plat 的问题意识非常直接:在 pixel-aligned 3DGS 中,若没有可靠 pose,跨视图 Gaussian 很容易错位;一旦错位,渲染误差回传到高斯中心的梯度就会变得稀疏或噪声化,训练难以稳定。为此,PF3plat 不是简单依赖 photometric loss 硬学几何,而是显式引入 pre-trained monocular depth estimation + visual correspondence 来先做 coarse alignment。
可以把它抽象为:
( D ~ i , T ~ i ) = A coarse ( I i ; , Φ mono , Φ match ) , (8) (\tilde D_i,\tilde T_i)= \mathcal A_{\text{coarse}} \big(I_i;,\Phi_{\text{mono}},\Phi_{\text{match}}\big), \tag{8} (D~i,T~i)=Acoarse(Ii;,Φmono,Φmatch),(8)
其中 Φ mono \Phi_{\text{mono}} Φmono 与 Φ match \Phi_{\text{match}} Φmatch 分别表示预训练深度与对应关系先验, D ~ i , T ~ i \tilde D_i,\tilde T_i D~i,T~i 表示粗深度与粗相机。然后 PF3plat 再通过轻量模块做 refinement:
( D ^ i , T ^ i ) = R θ ! ( D ~ i , T ~ i , I j ) . (9) (\hat D_i,\hat T_i)= \mathcal R_{\theta}!\left(\tilde D_i,\tilde T_i,{I_j}\right). \tag{9} (D^i,T^i)=Rθ!(D~i,T~i,Ij).(9)
式 ( 8 ) (8) (8) 到式 ( 9 ) (9) (9) 的意义在于:pose-free 不是不要几何,而是必须先建立一个足够可靠的几何初始支架。
4.2 geometry confidence 的结构性意义
PF3plat 最值得重视的不是"又加了一个 refinement module",而是它把 geometry confidence 显式引入了 Gaussian center 的可靠性建模。论文摘要明确指出,refined depth and pose 被进一步用于估计 geometry confidence scores,以评估 3D Gaussian centers 的可信度,并据此调制高斯属性预测。
形式上,可写为:
w j = σ ! ( g θ ( D ^ , T ^ , corr , j ) ) , g j = ( μ j , Σ j , α j , c j ) , (10) w_j= \sigma!\left( g_{\theta}(\hat D,\hat T,\text{corr},j) \right), \qquad g_j= \big(\mu_j,\Sigma_j,\alpha_j,c_j\big), \tag{10} wj=σ!(gθ(D^,T^,corr,j)),gj=(μj,Σj,αj,cj),(10)
其中 w j w_j wj 是第 j j j 个 Gaussian center 的几何可信度。后续属性分支不再把所有中心一视同仁,而是有条件地信任几何位置。
这一步的结构性作用很大。因为在 posed 设定下,我们通常默认高斯中心的几何位置已经足够可信;但在 pose-free 场景中,"这个中心是否值得相信"本身就是首要问题。PF3plat 首次比较系统地把这一点做成显式模块,这很可能会成为下一阶段 pose-free 3DGS 的标准配置。
4.3 PF3plat 相比 canonical-space-only 多解决了什么
与 NoPoSplat 相比,PF3plat 的推进在于它不满足于"先给一个统一坐标",而是进一步处理了如何得到更可信的局部几何支架。canonical space 解决的是"放到哪";PF3plat 则更关注"放得准不准"。
换句话说,NoPoSplat 的主要贡献是规整化 coordinate organization,而 PF3plat 的主要贡献是把 pose-free 误差源拆成 coarse alignment、lightweight refinement 与 geometry confidence 三个层次来控制。其本质不是更复杂,而是更接近真实工程:先粗配准,再局部修正,再按可信度加权。
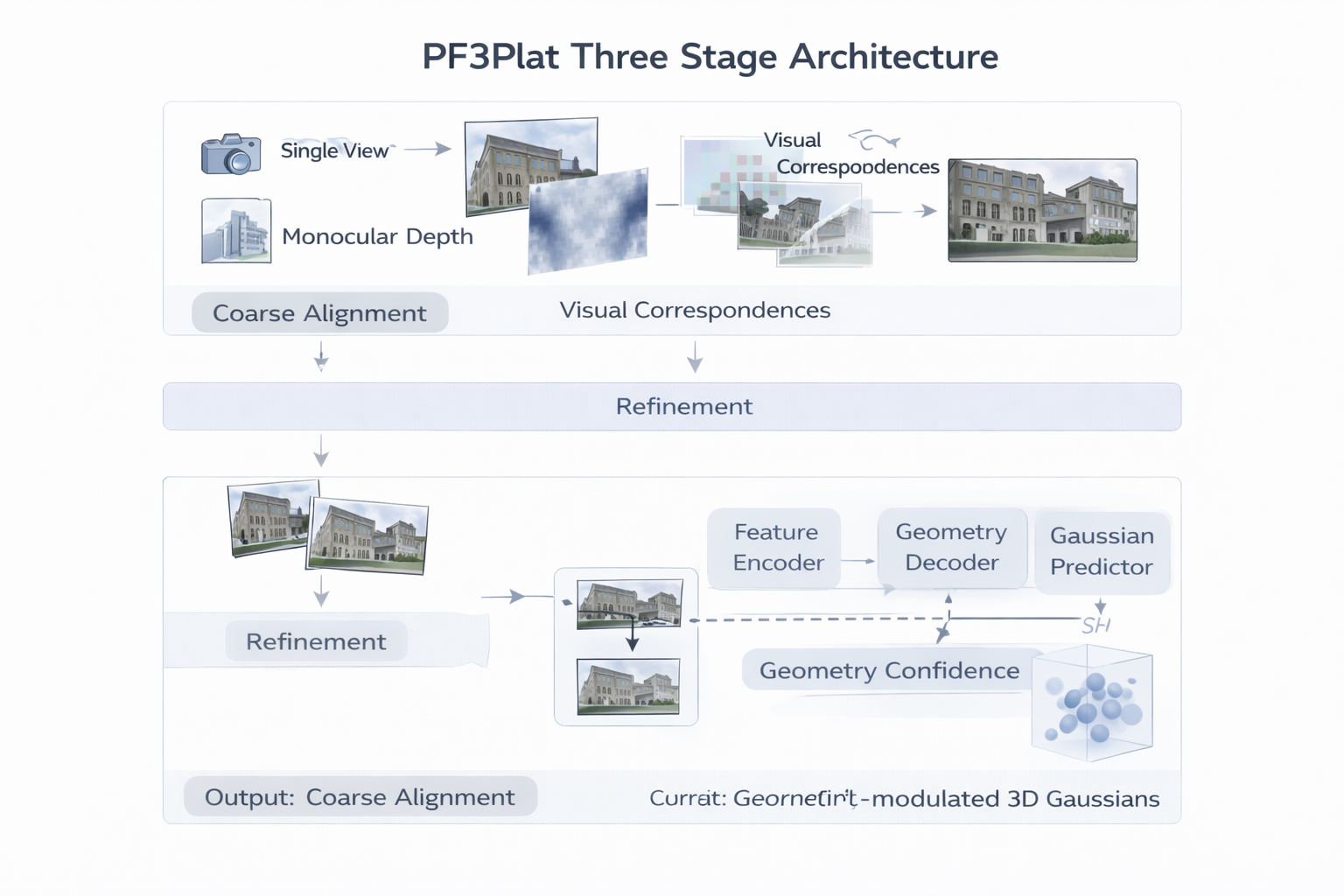
4.4 geometry confidence 很可能成为标准模块
geometry confidence 大概率会成为后续 pose-free 3DGS 的标准模块。
理由并不复杂。只要任务仍然要求 jointly infer scene + cameras,那么高斯中心就不可避免带有不确定性;只要不确定性存在,系统就需要知道哪些高斯可以高权使用,哪些高斯应该降权、剪枝、延迟融合或交给后续 refinement。PF3plat 已经把"center reliability"做成显式信号,TokenSplat 又把 fusion confidence 引入 token-level aggregation;这说明 uncertainty-aware fusion 正在从附加技巧变成主干设计。
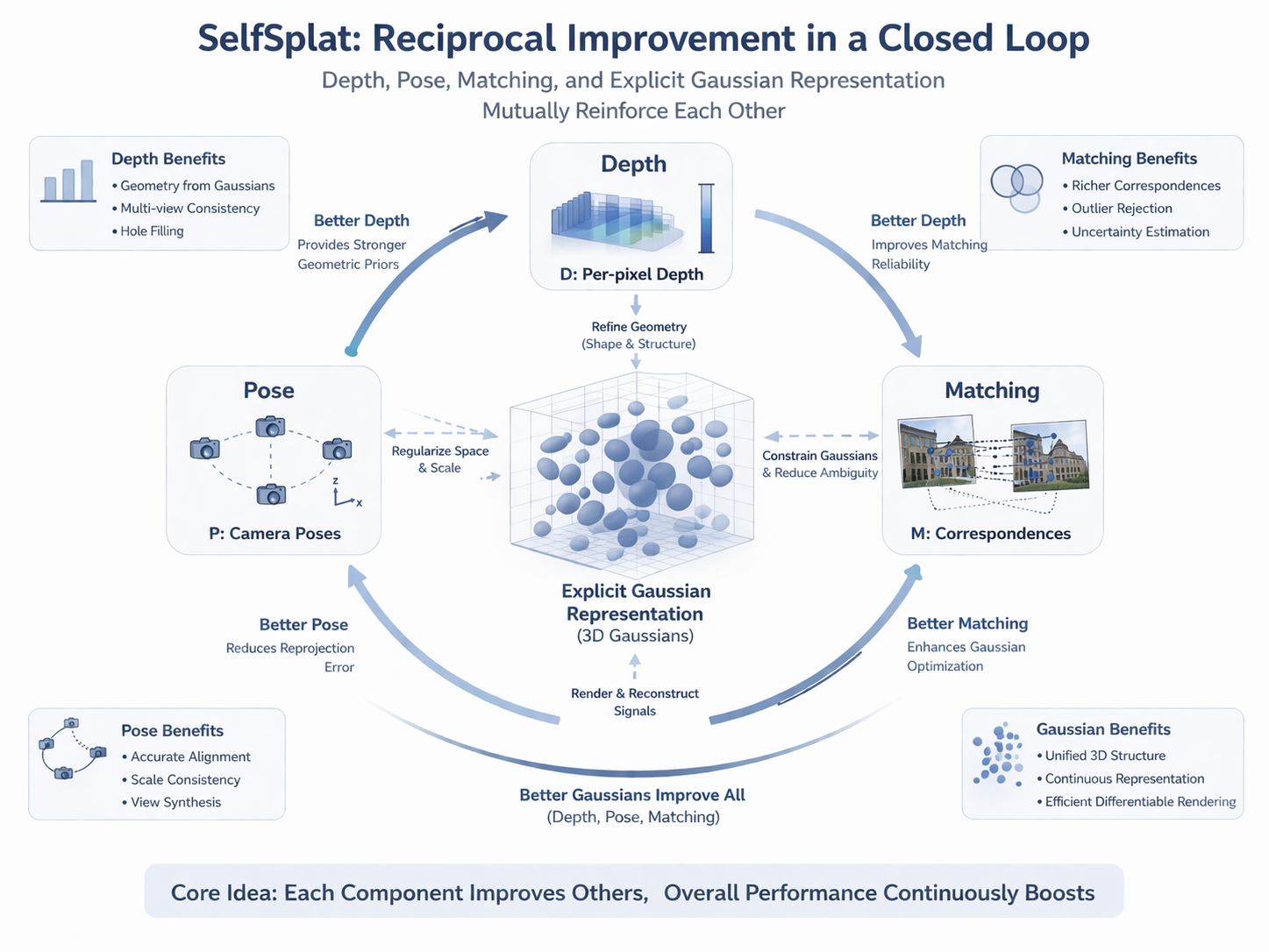
5. SelfSplat:不依赖 3D prior 的意义与难点
5.1 "3D prior-free"为什么重要
SelfSplat 的标题本身就点明了其立场:pose-free and 3D prior-free generalizable 3D Gaussian Splatting。它强调的不只是没有 pose supervision,更是没有显式接入外部 3D foundation prior。论文摘要明确指出,该方法通过显式 3D representation、自监督 depth / pose estimation、matching-aware pose estimation network 与 depth refinement module,实现 pose accuracy 与 3D reconstruction quality 的 reciprocal improvements。
这条路线的重要性在于,它试图回答一个更严格的问题:如果不给外部几何大模型兜底,仅依靠模型内部的表示、匹配与自监督约束,pose-free 3DGS 能否仍然建立强几何一致性? 如果答案是可以,那么 pose-free 3DGS 的能力上限不必完全绑定 foundation geometry;如果答案是不行,那么 foundation prior 就不仅是加分项,而会变成必要基座。
5.2 reciprocal improvement 的方法结构
可以把 SelfSplat 的思想概括为一个互相促进的闭环:
( D ^ , T ^ , G ^ ) = f θ ( I ) , L = L render + λ 1 L pose + λ 2 L depth + λ 3 L match . (11) (\hat D,\hat T,\hat{\mathcal G})= f_{\theta}(\mathcal I), \qquad \mathcal L= \mathcal L_{\text{render}} + \lambda_1 \mathcal L_{\text{pose}} + \lambda_2 \mathcal L_{\text{depth}} + \lambda_3 \mathcal L_{\text{match}}. \tag{11} (D^,T^,G^)=fθ(I),L=Lrender+λ1Lpose+λ2Ldepth+λ3Lmatch.(11)
这里 D ^ , T ^ , G ^ \hat D,\hat T,\hat{\mathcal G} D^,T^,G^ 不是各自独立预测,而是在一个共享结构中互相修正:更好的 pose 帮助高斯布局更稳定,更稳定的显式 3D 表示又反过来约束 depth 与 pose。这正是 SelfSplat 所说的 reciprocal improvement 的方法学含义。
其结构性意义在于,它没有把"几何先验"外包给一个 foundation geometry 模型,而是在模型内部建立一套相互支撑的几何闭环。这条路线更"纯",也更有理论研究价值。
5.3 这种路线为什么难
难点恰恰在于它没有外部 3D prior 兜底。
第一,初始 correspondence 更脆弱;
第二,photometric/self-supervised signal 更容易被错误相机扭曲;
第三,模型必须在没有强外部 pointmap prior 的情况下自己学出较稳的几何结构。
也因此,SelfSplat 的代价是:它对内部模块设计的一致性要求更高。matching-aware pose estimation 与 depth refinement 在这里不是锦上添花,而是防止整个闭环坍塌的关键支点。8)
5.4 相比 PF3plat / Splatt3R 的取舍
如果说 PF3plat 借助 pre-trained monocular depth 与 visual correspondence 搭建粗几何支架,Splatt3R 则更进一步直接站在 MASt3R 这样的 foundation geometry 上,那么 SelfSplat 的独特性就在于:它试图证明 pose-free 3DGS 并不必然等于依赖外部 3D foundation prior。
这条路线的价值,不一定体现在"最稳"的工程方案上,而更体现在它为问题本体做了去依赖化验证:pose-free 的关键,未必只能通过更强大的外部 geometry model 来解决,也可以通过更严密的内部 reciprocal design 来逼近。
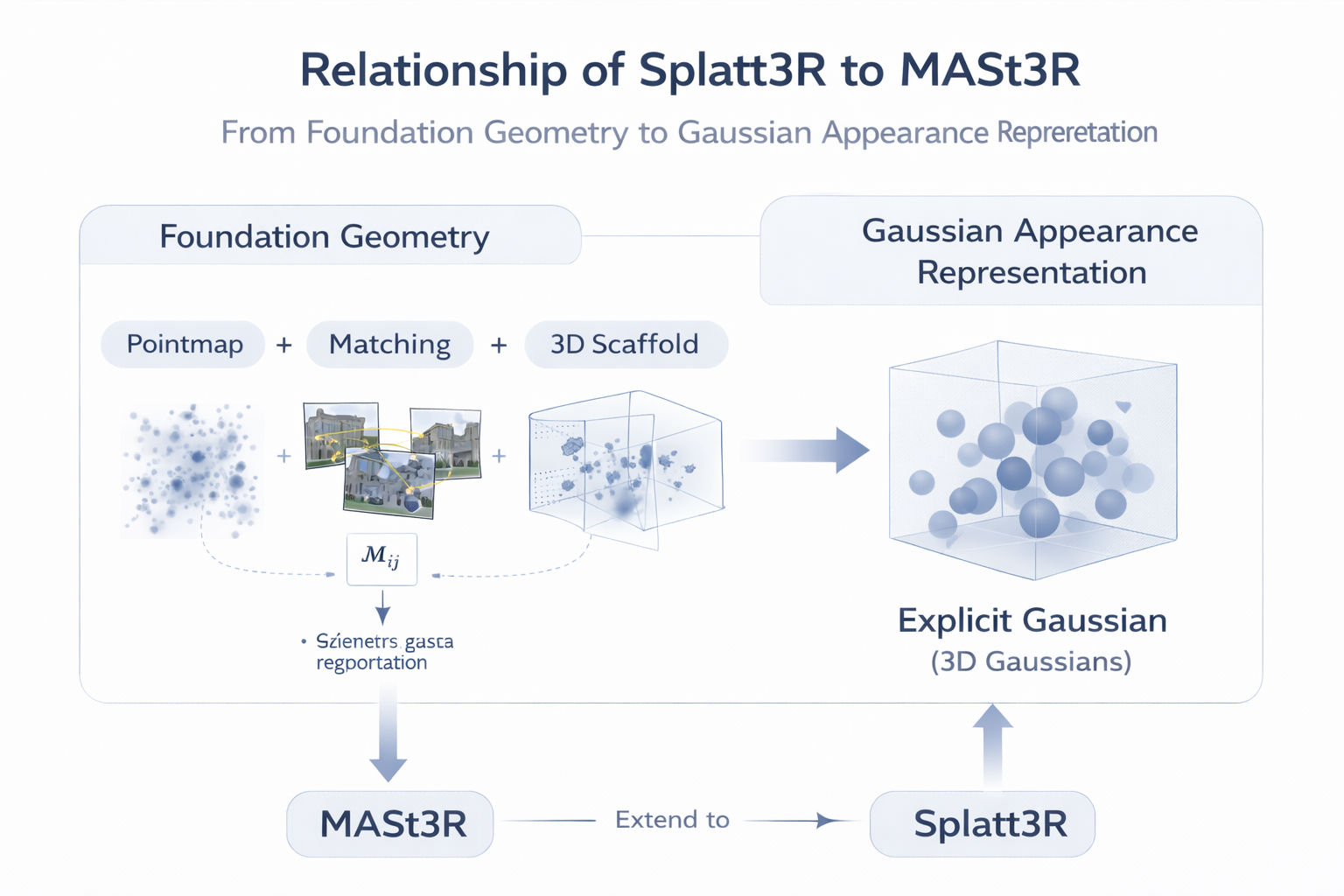
6. Splatt3R:foundation geometry 为什么能成为新基座
6.1 从 photometric hard learning 到 foundation geometry bootstrapping
Splatt3R 是路线四里一个极具代表性的分水岭。它的核心思想非常清楚:pose-free 3DGS 不一定要从 photometric loss 端到端硬学全部几何,完全可以先借助 foundation geometry 得到强鲁棒的 3D 结构,再补齐 Gaussian 所需的 appearance attributes。 论文摘要明确说明,Splatt3R 建立在 MASt3R 这一 foundation 3D geometry reconstruction 方法之上;与只输出 point cloud 的原始 MASt3R 不同,Splatt3R 进一步预测高斯原语所需的额外属性,并采用先 geometry loss、后 novel view synthesis objective 的训练思路。
形式上,可把这一路线写成:
P = Φ fg ( I a , I b ) , G ^ = h θ ( P , I a , I b ) , (12) P= \Phi_{\text{fg}}(I_a,I_b), \qquad \hat{\mathcal G}= h_{\theta}(P,I_a,I_b), \tag{12} P=Φfg(Ia,Ib),G^=hθ(P,Ia,Ib),(12)
其中 Φ fg \Phi_{\text{fg}} Φfg 表示 foundation geometry 模块输出的 pointmap / matching / local 3D structure, h θ h_{\theta} hθ 负责将其扩展为完整高斯表示。
6.2 foundation geometry 的结构意义
为什么 MASt3R 一类方法会对 pose-free 3DGS 产生巨大影响?
因为它们已经证明:在 uncalibrated、unposed、wide-baseline 的输入条件下,pointmap regression 与 3D-grounded matching 可以比传统 2D matching 更稳地恢复局部 3D 结构;MASt3R-SfM 又进一步展示了 foundation geometry 可以成为 truly unconstrained image collections 的高效 image retriever 与几何恢复基座。
这意味着路线四出现了一个新的"基座层"选择:
不是从零学 camera-aware geometry,而是先用 foundation geometry 给出 robust local 3D scaffold,再把 Gaussian appearance、opacity、covariance 等属性填进去。
Splatt3R 的意义就在这里:它把 pose-free 3DGS 与 foundation geometry 牢固地焊接在了一起。
6.3 foundation geometry 与 end-to-end 3DGS 的张力在哪里
foundation geometry 与 end-to-end 3DGS 的张力,不在于谁更"先进",而在于几何归纳应该内生于高斯重建网络,还是外包给一个更通用的上游视觉几何基座。
站在 end-to-end 立场看,理想系统应当直接从图像到高斯一次前馈完成,减少模块边界,避免误差接口;NoPoSplat、PF3plat、SelfSplat 都体现了这种取向。
站在 foundation geometry 立场看,真实世界输入太脏,若不先有 robust pointmap / matching prior,系统会在 low-overlap、wide-baseline、uncalibrated 场景下过早陷入错误局部极值;DUSt3R、MASt3R、MASt3R-SfM 与 Splatt3R 则体现了这一判断。
我的判断是:未来两者不会二选一,而会形成分层体系。 foundation geometry 更像"几何操作系统",end-to-end Gaussian head 更像"任务化渲染层"。Splatt3R 只是这条趋势的起点,而不是终点。
6.4 这是否意味着未来会更多采用"先 geometry,后 Gaussian 属性扩展"的路线
大概率是的。尤其在 in-the-wild、wide-baseline、uncalibrated 设定下,这条路线具有明显工程吸引力。因为它把最脆弱的"几何恢复"环节交给了已在大规模数据上获得鲁棒性的 foundation model,把前馈 3DGS 的重点转向"如何将结构几何转写为高效、可渲染、可编辑的 Gaussian asset"。Splatt3R 已经是这个范式的明确信号。
7. AnySplat:从 stereo / sparse 走向 arbitrary image collections
7.1 问题推进:不再只处理"成对/小规模 pose-free"
AnySplat 的重要性,在于它把路线四从"研究型 pose-free sparse views"继续推向了 uncalibrated image collections。论文摘要明确指出,AnySplat 面向 uncalibrated image collections,并在一趟 forward pass 中同时预测 3D Gaussian primitives 以及每个输入图像对应的相机内外参;同时它强调 sparse-view 与 dense-view 两类场景都要覆盖,并直接面向 casually captured multi-view datasets。
这一步非常关键。Splatt3R 仍然聚焦 stereo pair,NoPoSplat / PF3plat / SelfSplat 仍多以稀疏多视图为主,而 AnySplat 把任务定义扩大为:输入可以是 unconstrained views,模型必须同时恢复 scene 与 cameras,且不应只在低视图数设定下工作。
7.2 为什么 arbitrary image collections 会再次抬高难度
因为这相当于同时打开了四个自由度:
输入数量不定;
图像顺序不定;
重叠图结构不定;
相机参数全部未知。
形式上,任务已经更接近:
( G ^ , C ^ ) = f θ ! ( I , O ( I ) ) , (13) (\hat{\mathcal G},\hat{\mathcal C})= f_{\theta}!\left(\mathcal I,\mathcal O(\mathcal I)\right), \tag{13} (G^,C^)=fθ!(I,O(I)),(13)
其中 O ( I ) \mathcal O(\mathcal I) O(I) 表示未知的 overlap graph 与图像组织关系。AnySplat 的难点,不只是 predict cameras,而是要在这种不稳定图结构上保持 scene consistency。
真正的分歧不在于 arbitrary collection 是否"更大",而在于它更接近现实:用户给你的不一定是精心排列的 sparse multi-view rig,而往往就是一组随手拍来的图像集合。
7.3 统一预测 scene + cameras,为什么是更真实的任务定义
在 posed 时代,camera 是数据条件;在 AnySplat 这里,camera 成为场景解释的一部分。这样做虽然更难,但也更符合实际工作流。因为真实链路里,场景和相机并不是两个独立问题:一个稳定的 scene hypothesis 往往能够反过来约束 cameras,而一组合理 cameras 也会决定 Gaussian 布局是否能够闭合。
因此,AnySplat 的价值不是"同时多输出一个分支",而是把 joint scene-camera estimation 作为任务定义固定下来。这是路线四向真实应用靠近的重要一步。
图片内容描述:AnySplat 面向 arbitrary image collections 的统一任务图,输入为顺序任意、数量可变、无标定图像集合,输出 scene Gaussians 与相机参数;clean academic diagram, technical illustration, white background, blue gray palette, enterprise research style
8. TokenSplat:为什么开始做 token-aligned pose-free reconstruction
8.1 从几何对齐走向特征对齐
TokenSplat 是路线四与路线三开始相互接壤的标志。它不再只是"先恢复几何再生成高斯",而是把 token-level semantic alignment 直接作为 pose-free reconstruction 的核心机制。论文摘要明确指出,TokenSplat 的核心是 Token-aligned Gaussian Prediction module:它在 feature space 中对齐不同视图的语义对应 token,由 coarse token positions 与 fusion confidence 引导,多尺度上下文聚合实现长程跨视图推理,并减小 overlapping Gaussians 带来的冗余。
形式上,可抽象为:
z i = E ( I i ) , z ˉ = F ! ( z i , p i coarse , c i fusion ) , (14) z_i = E(I_i), \qquad \bar z= \mathcal F!\left( {z_i}, {p_i^{\text{coarse}}}, {c_i^{\text{fusion}}} \right), \tag{14} zi=E(Ii),zˉ=F!(zi,picoarse,cifusion),(14)
再由
( G ^ , C ^ ) = D ( z ˉ , t cam ) , (15) (\hat{\mathcal G},\hat{\mathcal C})= D(\bar z, t^{\text{cam}}), \tag{15} (G^,C^)=D(zˉ,tcam),(15)
输出 Gaussian 与 camera,其中 t cam t^{\text{cam}} tcam 表示 learnable camera tokens。这里的关键变化是:对齐不再只发生在显式几何空间,也发生在 token feature space。
8.2 为什么 token alignment 在 pose-free 里会越来越重要
因为当 pose 未知、overlap 不足、尺度不稳时,显式几何对齐往往需要一个较好的初值;而 token-level alignment 可以在更早阶段利用语义与上下文先建立跨视图对应关系。TokenSplat 的 coarse token positions、fusion confidence、ADF-Decoder,本质上都是为了让 camera cues 与 scene semantics 在 feature space 中保持"可对齐但不混淆"的状态。
这意味着路线四正在发生一个很重要的范式变化:
过去的 pose-free 更像"先尽量恢复几何,再交给高斯";
而 TokenSplat 开始把"如何在表征空间中组织跨视图对应"本身当成主问题。
8.3 pose estimation 与 Gaussian reconstruction 为什么越来越联合
TokenSplat 引入 learnable camera tokens,并通过 Asymmetric Dual-Flow Decoder 约束 camera tokens 与 image tokens 的方向性通信,这一设计其实揭示了一个更深层判断:pose estimation 与 Gaussian reconstruction 并不是两个可以长期分离的模块,而是同一场景解释过程的两种投影。
当系统要在 unposed multi-view images 上稳定工作时,相机的 viewpoint cues 与场景的 semantics/geometry 必须共同被建模;否则,要么 camera 分支过弱,无法为 scene 提供几何支撑;要么 scene 分支过强,把 viewpoint 线索吞没成语义特征,最终导致 pose 漂移。
8.4 TokenSplat 如何缓解 overlapping Gaussians 的冗余与错配
TokenSplat 明确把 reduce redundancy from overlapping Gaussians 作为目标之一。其背后逻辑并不复杂:如果跨视图语义对应没有在特征层对齐,那么多个视角很可能会对同一物理区域重复产生局部高斯,或者更糟糕地把不对应的区域错误融合到一起。token-aligned fusion 的作用,恰恰是在高斯生成前就降低这种冗余与错配。
这一步的结构性意义在于,它把路线四从"几何补位"推进到了"表征重写"。也就是说,pose-free 不再只是 posed 方法去掉相机输入后的补救版,而是在逼迫 feed-forward 3DGS 重新思考多视图信息应该在哪一层对齐。
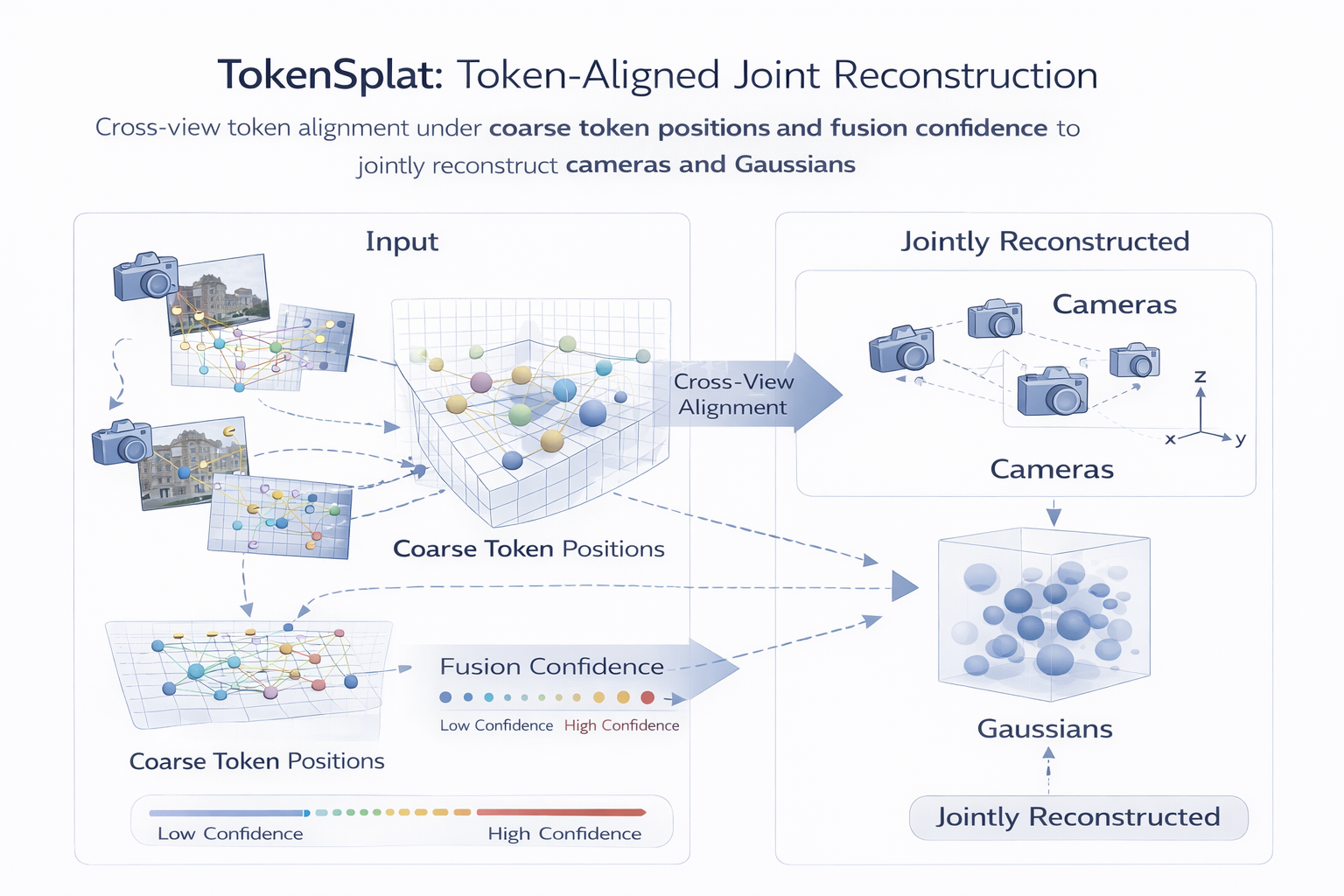
8.5 路线四方法演化图与统一对比
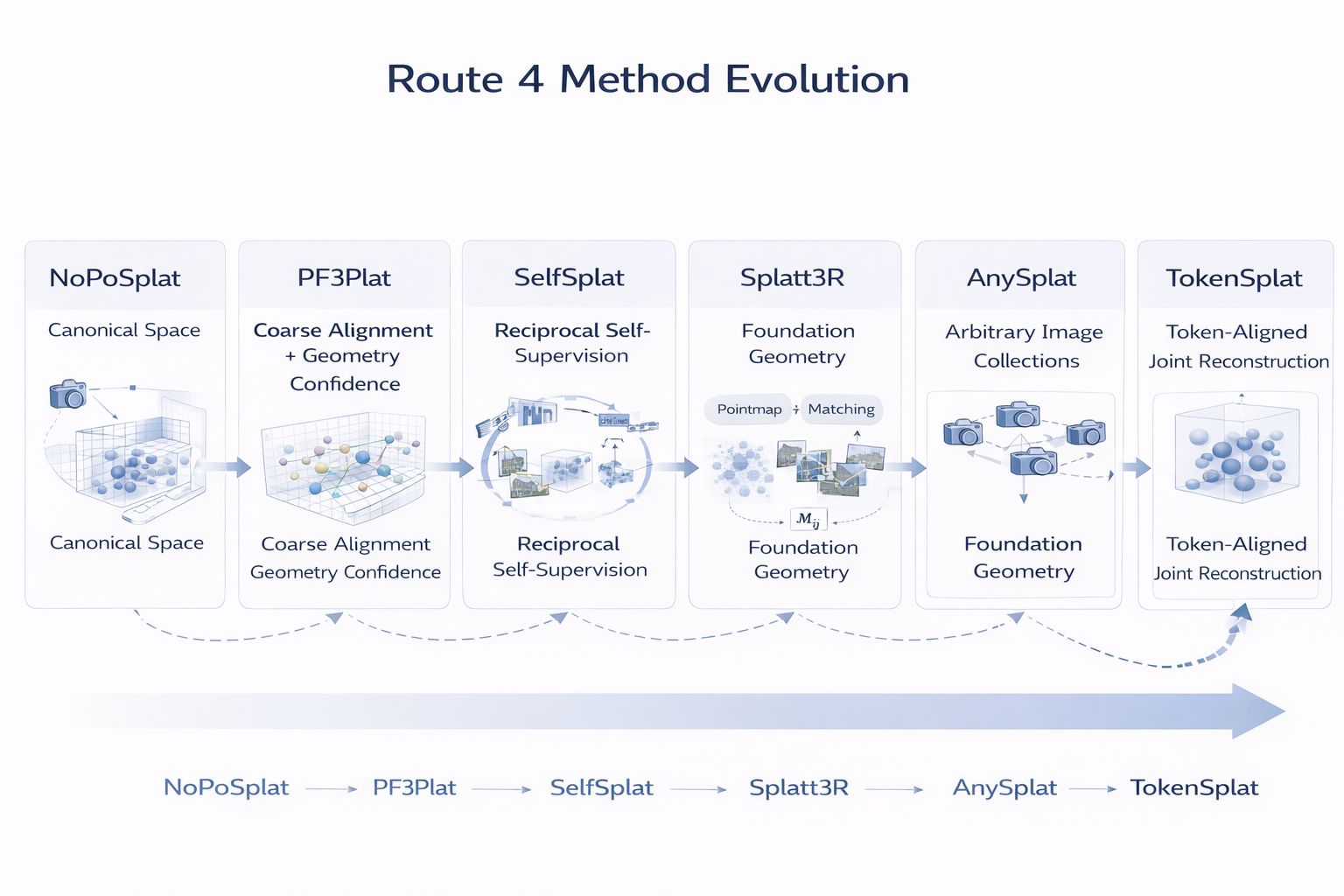

可配套整理为如下对比表:
| 方法 | 输入设定 | 外部几何先验 | 坐标组织方式 | pose 处理方式 | confidence 机制 | 适用场景 | 主要贡献 | 主要局限 |
|---|---|---|---|---|---|---|---|---|
| NoPoSplat | unposed sparse multi-view | 否 | canonical space | 先构 canonical 高斯,再 coarse-to-fine pose estimation | 未显式做 Gaussian confidence | 稀疏、低重叠 pose-free 重建 | 首次清晰建立 canonical-space pose-free 3DGS 框架 | 对 reference-anchor 与内部尺度规整仍较敏感 |
| PF3plat | unposed images,弱重叠也考虑 | 预训练单目深度 + correspondence | 粗对齐后的统一高斯布局 | coarse alignment + lightweight refinement | geometry confidence 显式建模 | 更现实的 sparse / low-overlap 场景 | 把粗对齐、refinement、confidence 三层结构做实 | 仍依赖外部预训练几何模块 |
| SelfSplat | unposed multi-view | 否,3D prior-free | 内部显式 3D 表示闭环 | self-supervised depth/pose + matching-aware refinement | 未以 PF3plat 风格显式中心置信度呈现 | generalizable、prior-free 设定 | 证明不借外部 foundation 也可建立强几何闭环 | 初始几何更难、系统稳定性要求更高 |
| Splatt3R | uncalibrated stereo pairs | 是,MASt3R | foundation pointmap scaffold → Gaussian expansion | 借 foundation geometry 隐式支撑 pose-free 几何 | 更像上游 pointmap 可靠性,而非显式 Gaussian confidence | in-the-wild、wide-baseline pair | 代表"先 geometry,后 Gaussian"路线 | 主要聚焦 pair-level,不等于完整 arbitrary collections |
| AnySplat | uncalibrated image collections,sparse/dense 均考虑 | 未以 Splatt3R 式 foundation geometry 为主卖点 | unified scene-camera prediction | 一次前馈同时预测 scene + intrinsics/extrinsics | 可视为联合估计中的隐式置信约束 | casually captured arbitrary collections | 把任务定义推进到更真实的 unconstrained views | 图结构与集合组织复杂度更高 |
| TokenSplat | unposed multi-view | 以 token alignment 为核心,不是纯 foundation 依赖 | token-aligned fusion + camera tokens | joint Gaussian reconstruction + pose estimation | fusion confidence 显式出现 | pose-free 多视图联合建模 | 把路线四推进到 token-level alignment | 方法更复杂,对表征设计依赖更强 |
上表中的方法定位与核心机制综合自各论文摘要和项目说明。
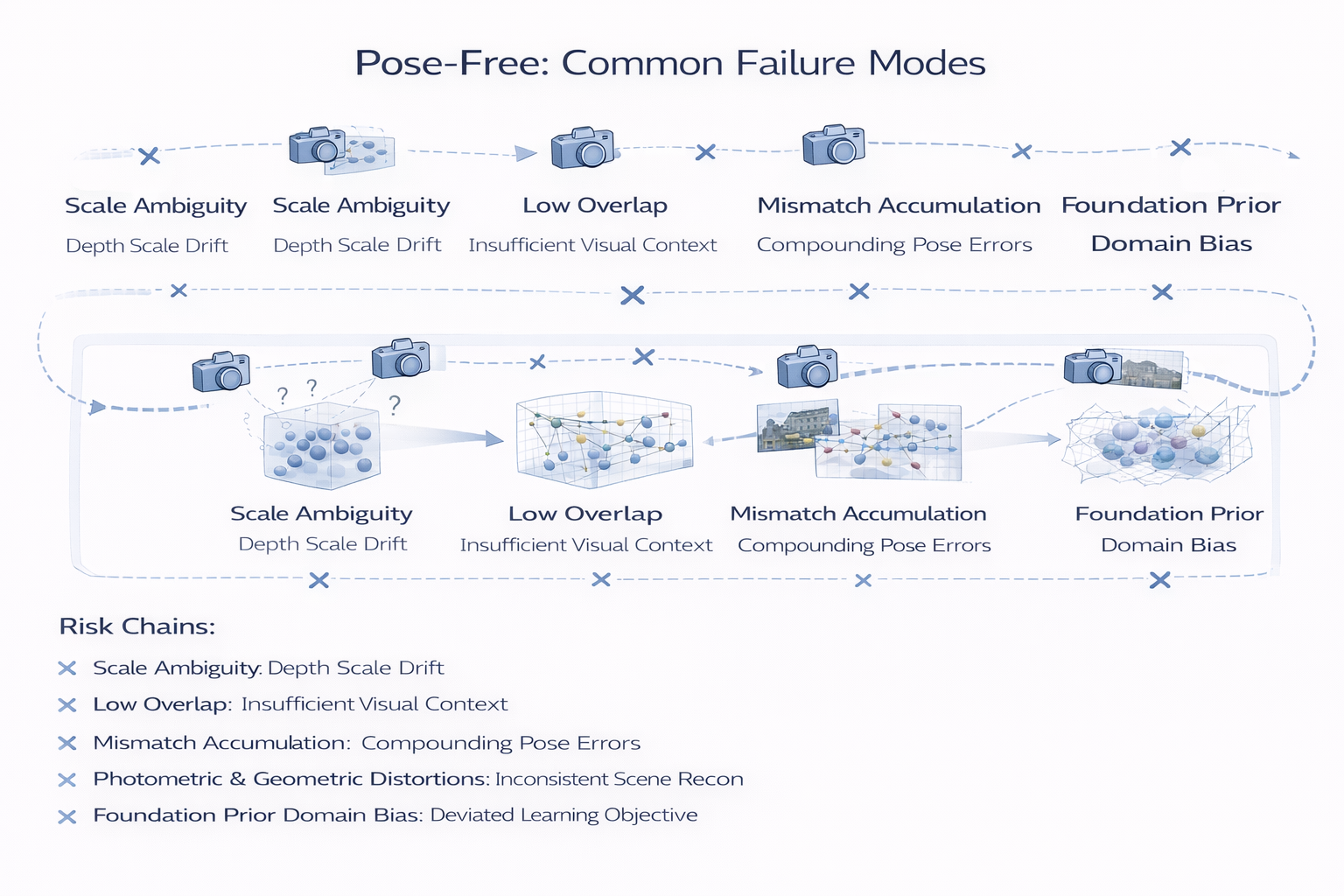
9. pose-free 共同失败模式:尺度歧义、局部重叠不足、错配累积
这一节是路线四最关键的批判性阅读入口。因为只有理解失败模式,才能理解为什么 canonical space、coarse alignment、foundation geometry、token-aligned fusion 会先后出现。
9.1 尺度歧义
无位姿条件下,绝对尺度本来就不可辨识。更麻烦的是,相对尺度一旦不稳,会直接污染 Gaussian centers。NoPoSplat 之所以需要专门讨论 scale ambiguity 并设计 intrinsic token embedding,恰恰说明在 pose-free 3DGS 中,尺度不是"训练时自会学会"的副产品,而是需要结构性处理的难点。
形式上,如果参考解为 ( G , C ) (\mathcal G,\mathcal C) (G,C),则任意相似变换 S ∈ S i m ( 3 ) S \in \mathrm{Sim}(3) S∈Sim(3) 都可诱导等价投影,这意味着系统需要某种额外锚定来压缩可行解空间。canonical space、intrinsic embedding、foundation pointmap priors,本质上都在扮演不同形式的尺度/规范约束。
9.2 局部重叠不足
真实图像集合的重叠图往往不是均匀致密图,而是带有长尾边、弱边和局部孤岛的图。MASt3R-SfM 直接指出,传统 SfM 在图像 overlap 不足或运动不足时容易失败;NoPoSplat 也强调其方法在 limited input image overlap 场景下的价值。=
可定义 overlap 权重图:
w i j = O v e r l a p ( I i , I j ) , G ov = ( V , E , w ) , (16) w_{ij}= \mathrm{Overlap}(I_i,I_j), \qquad \mathcal G_{\text{ov}}= (\mathcal V,\mathcal E,w), \tag{16} wij=Overlap(Ii,Ij),Gov=(V,E,w),(16)
若图 G ov \mathcal G_{\text{ov}} Gov 局部过稀或近似断裂,则 scene-camera estimation 会退化为病态问题。此时系统最常见的失败表现有三种:
一是重建只在若干局部视图团块内成立,整体无法闭合;
二是错误桥接两个本不该连通的局部区域;
三是高斯云在弱重叠边上发生几何漂移。
这正是 foundation geometry 与 token alignment 变得重要的直接原因:它们都在试图提供比原始 photometric overlap 更强的跨视图关联信号。
9.3 错配累积
pose-free 下最危险的不是单次局部错误,而是局部错误通过 pose / depth / Gaussian 三条通路相互放大。PF3plat 讨论 misaligned 3D Gaussians 导致 noisy or sparse gradients;SelfSplat 因此必须引入 matching-aware pose estimation 与 depth refinement;TokenSplat 则进一步在 token-level 用 fusion confidence 控制多视图聚合。
可以把这种放大链路写成:
δ m → δ T → δ μ → δ I ^ → δ ∇ → next-step mismatch , (17) \delta m \rightarrow \delta T \rightarrow \delta \mu \rightarrow \delta \hat I \rightarrow \delta \nabla \rightarrow \text{next-step mismatch}, \tag{17} δm→δT→δμ→δI^→δ∇→next-step mismatch,(17)
其中 δ m \delta m δm 是匹配误差, δ T \delta T δT 是相机误差, δ μ \delta \mu δμ 是 Gaussian center 误差, δ I ^ \delta \hat I δI^ 是渲染误差, δ ∇ \delta \nabla δ∇ 是失真的训练梯度。式 ( 17 ) (17) (17) 说明:pose-free 的危险在于误差会自举式放大。
9.4 photometric loss 的几何约束变弱
在 posed 设定下,photometric consistency 通常可以较直接地约束几何,因为相机射线是可信的;但在 pose-free 设定下,若相机本身不准,那么 photometric loss 的几何意义会被削弱。PF3plat 对 noisy/sparse gradients 的描述,其实就是这一现象的具体体现。
设 photometric loss 为
L photo = ∑ i = 1 N ∣ I i − R ( G , C ^ i ) ∣ 1 . (18) \mathcal L_{\text{photo}}= \sum_{i=1}^{N} \left| I_i- \mathcal R(\mathcal G,\hat C_i) \right|_1. \tag{18} Lphoto=i=1∑N Ii−R(G,C^i) 1.(18)
当 C ^ i \hat C_i C^i 偏差较大时,式 ( 18 ) (18) (18) 中的误差不再纯粹来自 scene mismatch,而混入了 ray geometry bias。此时梯度会同时试图修 scene 与补 camera,导致优化语义混杂。也因此,路线四的方法越来越少依赖"纯 photometric 一把梭",而会额外引入 canonical anchoring、coarse alignment、matching priors 或 foundation pointmaps。
9.5 foundation prior 的 domain bias
foundation geometry 很强,但并不意味着没有代价。Splatt3R 的优势恰恰来自 MASt3R 式几何基座;但一旦目标域与 foundation model 的训练域差异过大,pointmap / matching prior 也可能携带 domain bias,将错误几何规律更自信地注入系统。
形式上,若 foundation prior 表示为
P ⋆ = Φ fg ( I ) , (19) P^{\star}= \Phi_{\text{fg}}(\mathcal I), \tag{19} P⋆=Φfg(I),(19)
当测试域分布偏离训练域时, P ⋆ P^{\star} P⋆ 可能不再是"低方差真先验",而变成"高自信伪先验"。这一点尤其值得警惕,因为 pose-free 系统通常会把这些先验当作几何支架,一旦支架偏了,下游高斯属性预测再强也只是在歪楼上装修。
9.6 一个综合判断
路线四的共同困难,可以概括为一句话:
在 pose-free reconstruction 中,camera uncertainty 不只是附加噪声,而是会重写整个学习问题的监督语义。
这也正是为什么本文始终强调:路线四的真正主题不是"去掉位姿输入",而是重新组织 geometry、correspondence、coordinates、camera-scene relation。
10. 对机器人、移动采集、in-the-wild 3D 的意义
10.1 对机器人视觉与在线采集的意义
机器人与移动平台采集数据时,输入往往具有路径不规则、视角突变、局部遮挡、动态模糊、临时曝光变化等特点。严格依赖高质量外部 pose,会把系统可靠性过度押注在上游定位链路上。路线四的价值在于,它把部分几何恢复能力内生到 scene representation 模型中,使 feed-forward 3DGS 不必完全等上游相机解"整理干净"之后才开始工作。
本质上,这让 3DGS 更像一个 perception interface,而不是一个只吃干净多视图输入的 graphics backend。
10.2 对 casual capture 与消费级采集的意义
AnySplat 直接面向 casually captured multi-view datasets,Splatt3R 强调 uncalibrated natural images 与 in-the-wild reconstruction。这说明路线四并不是纯学术设定,它直接对应手机、相机、社交图片集合这类低门槛输入。
如果 feed-forward 3DGS 要进入更大规模的真实用户场景,那么它不能要求用户先跑一遍复杂 SfM,再把整理好的相机喂给模型。路线四正在把这种"前置几何门槛"压低。
10.3 对车载、头戴与空间感知的意义
DUSt3R 与 MASt3R-SfM 已经表明,unconstrained image collections 可以成为新的几何输入范式;路线四则将这一步继续推进到 explicit Gaussian scene asset 的直接生成。这对于车载感知、头戴设备、空间记录与 world-model interface 都非常关键,因为这些系统天然产生的是连续、异质、相机状态不完全可信的图像流或图像集合。
如果没有 pose-free 能力,3DGS 很难成为真正通用的场景表示接口;它最多只能是一个在"相机已知时很高效"的渲染表达。
10.4 为什么路线四会反过来重塑前馈式 3DGS 的问题定义
路线四的长期影响,不只是让 3DGS 支持 unposed 输入,而是会反过来重塑"feed-forward 3DGS 到底在解什么问题"的定义。
过去,我们可以把 feed-forward 3DGS 理解成:在已知几何条件下,快速生成高质量高斯场。
未来,更合理的定义可能是:在不完备 camera 条件下,从真实图像集合中 jointly infer cameras、geometry 与 renderable Gaussian scene。
这两者听起来只差几个词,但问题边界完全不同。
11. 结语
路线四不是"去掉位姿输入"这么简单,而是前馈式 3DGS 重新组织几何、对应、坐标系、相机与场景关系的关键跃迁。
NoPoSplat 用 canonical space 让 pose-free 3DGS 第一次有了清晰的内部规范坐标装置;PF3plat 说明 pose-free 不能只靠 photometric loss 硬学,必须显式处理 coarse alignment 与 geometry confidence;SelfSplat 证明在不依赖外部 3D prior 的情况下,内部 reciprocal design 仍然可能建立几何闭环;Splatt3R 则把 foundation geometry 确立为一条强势新基座;AnySplat 将问题推进到更真实的 arbitrary image collections;TokenSplat 更进一步,开始在 token-level 重新定义跨视图对齐与 joint scene-camera estimation。
这条路线的历史作用,不在于它是否最终会完全替代 posed 路线,而在于它把前馈式 3DGS 从"干净设定下的高效重建器"推进为"真实世界输入下的场景解释器"。也正因此,路线四不是边缘分支,而是整个 feed-forward 3DGS 研究地图里的关键转折点。
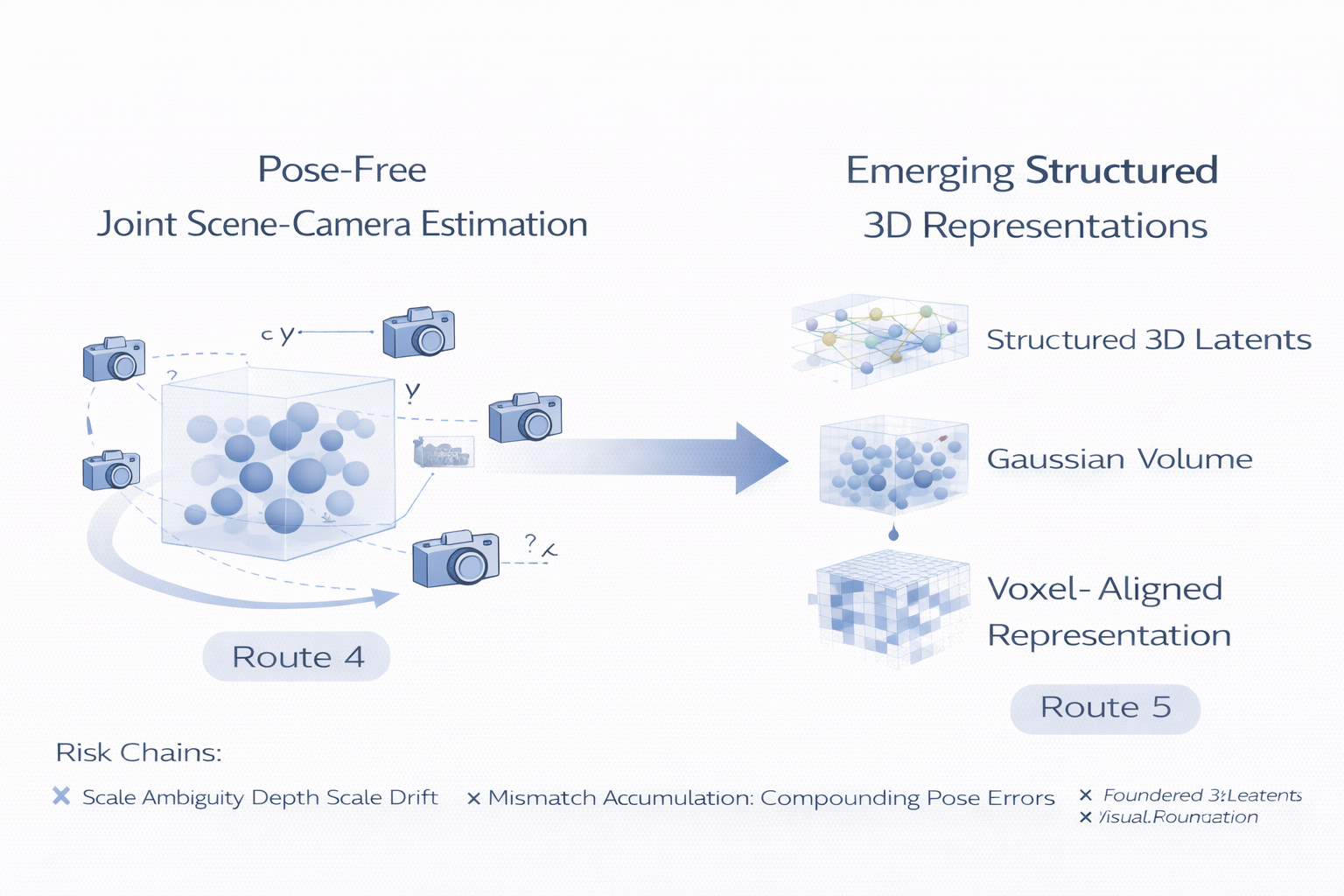
再往前走,问题会自然过渡到下一条主线:
当 canonical space、coarse alignment、foundation geometry、token alignment 都还不足以完全稳定 pose-free reconstruction 时,我们是否需要更强的structured 3D latents / Gaussian volumes / voxel-aligned intermediates ,来进一步吸收 scene ambiguity、camera uncertainty 与 long-range aggregation 的复杂性?
这,就是路线五要回答的问题。
参考文献
- pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction 。作为 posed 路线背景,代表早期成对输入的 feed-forward 3DGS。(arXiv)
- MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images 。作为 posed 路线背景,代表 cost-volume 驱动的多视图深度---高斯中心联合建模。(arXiv)
- DepthSplat: Connecting Gaussian Splatting and Depth 。作为 posed 路线背景,代表单目深度预训练特征与 feed-forward 3DGS 的融合。(arXiv)
- NoPoSplat: No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images 。路线四的 canonical space 代表作。(arXiv)
- PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting 。路线四中 coarse alignment + refinement + geometry confidence 的代表方法。(arXiv)
- SelfSplat: Pose-Free and 3D Prior-Free Generalizable 3D Gaussian Splatting 。路线四中 prior-free reciprocal design 的代表。(arXiv)
- Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs 。路线四中 foundation geometry 基座化的关键节点。(arXiv)
- AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views 。路线四从 pose-free sparse views 走向 arbitrary image collections 的关键推进。(arXiv)
- TokenSplat: Token-aligned 3D Gaussian Splatting for Feed-forward Pose-free Reconstruction 。路线四开始与 token aggregation / 大模型表征交叉的标志。(arXiv)
- DUSt3R: Geometric 3D Vision Made Easy 。pointmap-based unconstrained 3D reconstruction 的重要背景。(arXiv)
- MASt3R: Grounding Image Matching in 3D with MASt3R 。foundation geometry / 3D-grounded matching 的关键背景。(arXiv)
- MASt3R-SfM: a Fully-Integrated Solution for Unconstrained Structure-from-Motion 。理解 pose-free 与 generalized SfM 关系的重要参照。(arXiv)