
导读:
---------------------------------------------------------------------------------------------------------------------------------
多模态大语言模型(MLLM)在通用视觉理解上已取得长足进展,但在农业领域却面临一个根本瓶颈:缺乏大规模、高质量且经过科学验证的视觉问答数据。现有农业数据集要么类别少、要么标注未经专业校验,导致模型容易产生"生物学幻觉"------把一种病害张冠李戴到另一种作物上。
Khalifa University的研究团队提出了Vision-to-Verified-Knowledge(V2VK)管线,通过视觉描述、网络检索验证、指令合成三阶段自动生成经过科学文献校验的农业VQA数据,由此构建了覆盖3,099个农业类别、607,125条VQA对 的AgriMM基准。在此数据上微调得到的AgriChat模型,仅用单张RTX 3090训练,在域内评估中LLM Judge得分达到77.43%(超次优模型11.7个百分点),PlantVillage零样本得分74.26%(+16.9pp),CDDM零样本得分69.94%(+10.4pp),推理仅需约2.3秒/次。代码、数据和模型权重已全部开源。
论文信息
---------------------------------------------------------------------------------------------------------------------------------
标题:AgriChat: A Multimodal Large Language Model for Agriculture Image Understanding
作者:Abderrahmene Boudiaf, Irfan Hussain, Sajid Javed
机构:Department of Computer Science, Khalifa University of Science and Technology, Abu Dhabi, UAE(阿联酋)
模型权重:https://huggingface.co/boudiafA/AgriChat/tree/main/weights/AgriChat
数据集:https://huggingface.co/boudiafA/AgriChat/tree/main/dataset
开源状态:代码、数据、模型权重全部公开
一、农业视觉理解为什么缺数据?
农业是全球粮食安全的基础,但作物病害、虫害和产量优化等问题长期依赖人工经验判断。AI系统有潜力提升作物产量和资源利用效率,但这一切的前提是模型能准确识别数以千计的作物品种和病害类型。
当前农业多模态数据面临三重困境。第一,类别覆盖窄:PlantVillageVQA仅覆盖52个类别,AGMMU仅5个类别,远不足以支撑跨物种的细粒度推理。第二,标注质量参差:部分数据集的知识标注来自静态资料或早期文献,未经实时科学文献校验,容易引入过时或错误的病理描述。第三,任务维度单一:已有数据集多聚焦于病害分类或物种识别中的某一个任务,缺乏同时覆盖细粒度物种识别、病害诊断、作物计数等多任务的统一基准。
论文将现有数据集进行了系统对比:
| 数据集 | 图像数 | VQA对数 | 类别数 | 多源 | 细粒度 | 计数 | 网络验证 | 可获取 |
|---|---|---|---|---|---|---|---|---|
| CDDM | 137,000 | 1,000,000 | 76 | -- | -- | -- | -- | 是 |
| PlantVillageVQA | 55,448 | 193,609 | 52 | -- | -- | -- | 部分 | 是 |
| Agri-3M-VL | ~1.0M | ~3.0M | 42,253 | 是 | 是 | -- | -- | -- |
| AgroInstruct | 108,701 | 70,000 | 202 | 是 | -- | -- | -- | -- |
| AGMMU | 57,079 | 58,571 | 5 | -- | -- | -- | 部分 | 是 |
| AgriMM | 121,425 | 607,125 | 3,099 | 是 | 是 | 是 | 是 | 是 |
可以看到,从现有公开数据集来看,AgriMM是已知同时满足多源聚合、细粒度覆盖、计数任务、网络验证且完全公开的农业VQA基准。值得注意的是,Agri-3M-VL虽然图像和VQA对数量更大,但其数据和代码均未公开,且缺乏网络验证环节。
二、V2VK管线:三阶段自动生成高质量农业VQA数据
---------------------------------------------------------------------------------------------------------------------------------
V2VK(Vision-to-Verified-Knowledge)是本文的核心数据生产方法,通过三个阶段将原始农业图像转化为经过科学验证的问答对。
第一阶段:视觉描述(Visual Grounding via Image Captioning)
使用Gemma 3(12B)模型对农业图像进行结构化描述。输入包括图像本身和来自AgriMM的ground-truth标签(例如将学名"Solanum lycopersicum"注入Prompt),输出涵盖作物名称与类型、生长阶段、地面覆盖度、植物密度、拍摄角度、环境条件和植物健康指标等维度的自然语言描述。将标签注入Prompt的做法可以有效防止标签漂移(label drift),确保描述与实际物种一致。
第二阶段:知识检索与验证(Knowledge Retrieval and Verification)
使用Gemini 3 Pro(启用Web Search的RAG框架)以类名为关键词检索当代科学文献,输出约300词的标准化描述,涵盖分类学、形态学、栖息地、已知病害等信息。对于物种识别任务,检索植物分类学、形态学和生态学描述;对于病害分类任务,检索病因、症状表现、病原生物学和环境触发因素。关键在于,检索结果经过Human-in-the-loop验证协议------专家标注员对照已建立的农业分类学和植物病理学文献进行人工核查,确保检索到的生物特征与视觉证据准确对应。
第三阶段:指令合成(Instruction Synthesis)
使用LLaMA-3.1-8B-Instruct将前两阶段的输出整合为多样化的VQA对。每张图像生成5个不同类型的问题:
- 识别(Identification)------识别植物及品种;
- 视觉推理(Visual Reasoning)------哪些视觉特征可用于鉴别该物种;
- 健康状态(Condition & Health)------叶片、果实、茎秆的状态与生长阶段;
- 栽培知识(Cultivation Knowledge)------农艺需求;
- 解剖细节(Anatomy/Detail)------特定可见部位的结构描述。作物计数子集的ground-truth计数来自bounding box标注的数量统计。最终生成607,125条VQA对。

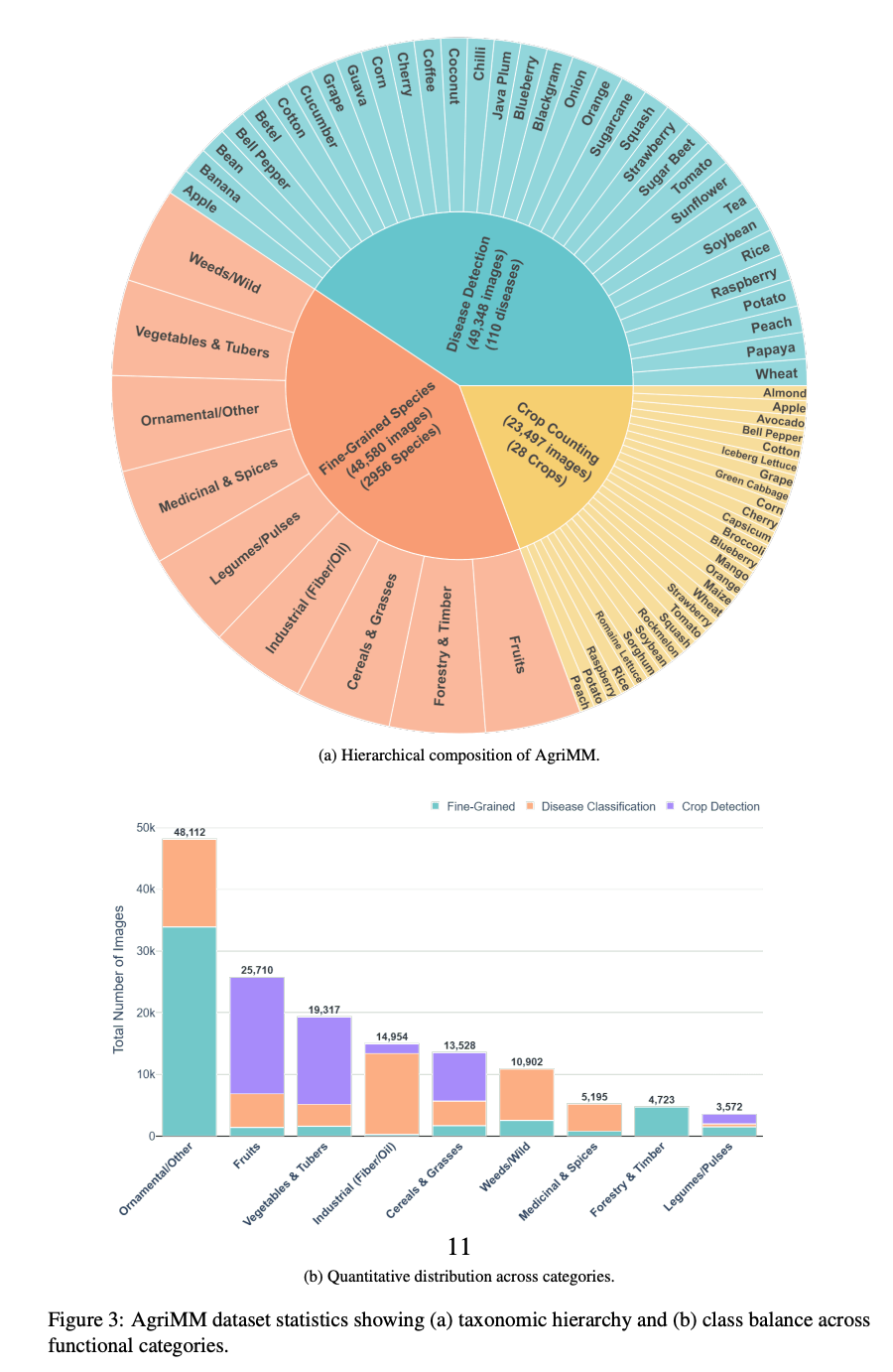
AgriMM基准的构成
AgriMM汇集了63个源数据集,分为三大子集:
| 子集 | 图像数 | 类别/物种数 | 覆盖范围 |
|---|---|---|---|
| 细粒度物种识别 | 48,580 | 2,956个物种 | 分为9大农业类别 |
| 病害分类 | 49,348 | 110种病害,33种主要作物 | 跨29个地理多样的病害数据集 |
| 作物计数与检测 | 23,497 | 33种作物 | 涵盖不同时间、成熟度和密度水平 |
九大农业类别中,观赏/其他植物(48,112张)和水果(25,710张)占比最大,其后依次是蔬菜与块茎(19,317张)、工业作物(14,954张)、谷物与牧草(13,528张)、杂草/野生(10,902张)、药用与香料(5,195张)、林业与木材(4,723张)和豆类(3,572张)。
三、AgriMM基准与AgriChat模型实验
---------------------------------------------------------------------------------------------------------------------------------
模型架构
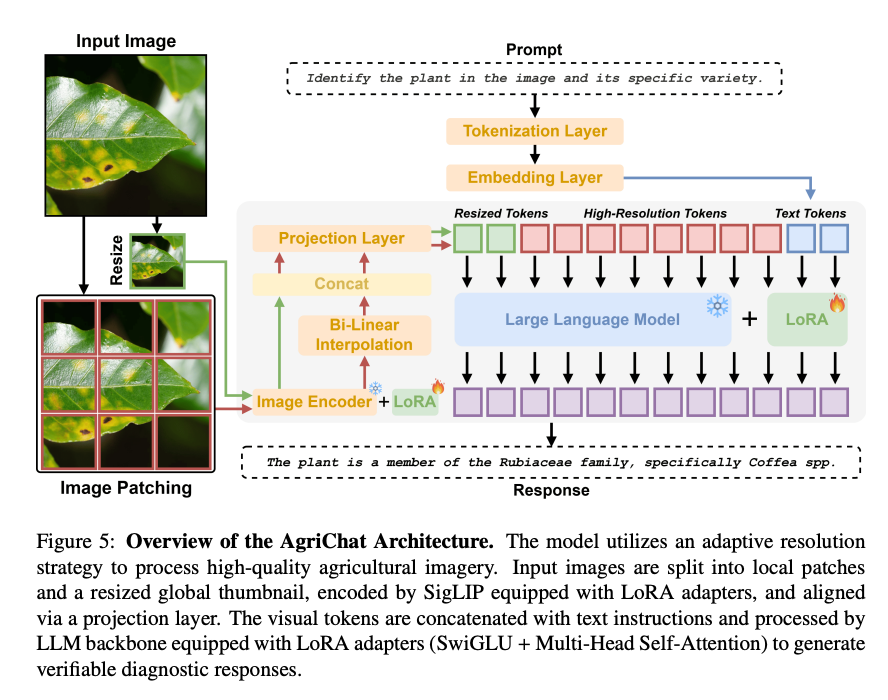
AgriChat基于LLaVA-OneVision架构构建,包含四个核心模块:
视觉编码器:SigLIP-SO400M,输入分辨率384x384/tile,每个tile编码为729个token
高分辨率视觉编码:自适应分辨率策略(Adaptive Resolution Strategy),最大支持1344x1344分辨率,通过双路径特征提取(局部patch编码+全局缩略图编码)捕获细粒度视觉信息
跨模态投影网络:2层MLP(GELU激活),将视觉特征维度从1152映射到3584
语言模型解码器 :Qwen-2-7B,隐藏维度3584
训练采用**LoRA(Low-Rank Adaptation)**参数高效微调策略:语言模型backbone使用rank=128、alpha=256,目标层覆盖q/k/v/o/gate/up/down共7类投影层;视觉编码器使用rank=32、alpha=64。所有预训练权重冻结,仅训练LoRA adapter和MLP投影层。
硬件方面,整个训练在**单张NVIDIA RTX 3090(24GB显存)**上完成,训练1个epoch,有效批量大小为16(per-device batch size 1,梯度累积16步),学习率2x10^-4,使用bfloat16混合精度。
评估体系
论文采用了三层指标体系:词汇/N-gram指标(BLEU-4, ROUGE-2, METEOR)、语义/嵌入指标(BERTScore, Long-CLIP余弦相似度, T5余弦相似度, SBERT相似度),以及LLM-as-a-Judge评估------使用Qwen3-30B-A3B-Instruct-2507作为评判模型,在NVIDIA Judge's Verdict Benchmark中位列Tier 1,从正确性、完整性、清晰度和简洁性四个维度进行4点Likert量表评分。
对比模型包括:LLaVA-OneVision(7B,AgriChat的基座模型)、Llama-3.2(Vision-11B)和Qwen-2.5(VL-7B)。
主实验结果
以LLM Judge得分(最能反映回答综合质量的指标)为核心来看四个评估基准的表现:
域内评估------AgriMM
AgriChat在LLM Judge上取得77.43%,次优模型Qwen-2.5仅65.77%,领先** 11.7个百分点**。词汇指标上优势更为明显:BLEU-4达到49.34(次优LLaVA-OneVision为14.13,+35.2),METEOR达到66.70(+28.8)。这表明域内微调不仅提升了内容准确性,也对齐了输出格式。
零样本迁移------PlantVillage
AgriChat在LLM Judge上取得74.26%,次优LLaVA-OneVision为57.41%,领先16.9个百分点。但在部分语义相似度指标上,AgriChat低于LLaVA-OneVision(如SBERT: 32.13 vs 41.64,BERTScore: 83.58 vs 86.02),论文解释这是因为AgriChat的输出结构良好但措辞与参考答案不同。
零样本泛化------CDDM病害诊断
AgriChat在LLM Judge上取得69.94%,次优Qwen-2.5为59.51%,领先10.4个百分点。METEOR指标表现尤其突出,达到39.59(次优Llama-3.2仅18.63,+21.0)。
零样本------AGMMU开放式问答(唯一落后场景)
AgriChat在LLM Judge上仅取得46.93%,低于Qwen-2.5的** 59.93%,落后13.0个百分点**。这是AgriChat唯一表现不及通用模型的场景。论文将此归因于专家-通才权衡:AgriChat作为"专科诊断师"在视觉识别和诊断上高度准确,但在需要广泛开放式知识检索的任务(如治疗方案生成、农田管理建议)上趋于保守------论文认为这在实际应用中更像是一种安全机制,避免给出未经验证的治疗建议。
值得一提的是,在AGMMU的**多选题(MCQs)**子集上,AgriChat的Accuracy为70.19,与Qwen-2.5的70.94基本持平(仅差0.8个百分点),但在BLEU-4(64.94 vs 3.29)和METEOR(63.87 vs 31.70)等指标上大幅领先,说明AgriChat的回答格式与评估标准对齐得更好。
推理性能
在RTX 3090上进行4-bit量化推理测试:
| 模型 | 推理时间 (s/query) | 吞吐量 (it/sec) | 显存占用 (GB) |
|---|---|---|---|
| LLaVA-OneVision (7B) | 1.546 | 0.647 | 9.99-10.99 |
| AgriChat (7B) | 2.315 | 0.432 | 10.71-12.32 |
| Llama-3.2 (11B) | 9.938 | 0.101 | 7.18-8.16 |
| Qwen-2.5 (7B) | 29.769 | 0.034 | 11.33-11.76 |
AgriChat约2.3秒/次查询,比Llama-3.2快约4.3倍,比Qwen-2.5快约12.9倍,折算约1,555次诊断查询/小时,显存峰值12.32GB。虽然比基座LLaVA-OneVision略慢(多约0.8秒),但考虑到域内性能的大幅提升,这一开销是合理的。
四、消融实验:LoRA rank、Vision LoRA和训练策略
论文在AgriMM域内数据上进行了三组消融实验,逐步验证每个设计选择的贡献。
LoRA Rank的影响
| 指标 | Rank 32 | Rank 64 | Rank 128 |
|---|---|---|---|
| BLEU-4 | 0.4422 | 0.4860 | 0.4860 |
| METEOR | 0.6172 | 0.6599 | 0.6588 |
| BERTScore | 0.9377 | 0.9447 | 0.9461 |
| LLM Judge (%) | 73.46 | 76.54 | 76.39 |
从rank 32到rank 64,各项指标均有显著提升:BLEU-4相对提升约10%,LLM Judge提升3.08个百分点。但从rank 64到rank 128,语义指标仅有微小增幅(BERTScore从0.9447到0.9461),LLM Judge甚至略有下降(76.54 vs 76.39)。这说明rank 64已捕获主要的域适应收益,更高的rank主要提供额外的容量余量。论文最终选择rank 128以留出headroom。
Vision LoRA的影响
| 指标 | 无 Vision LoRA | 有 Vision LoRA |
|---|---|---|
| BLEU-4 | 0.4860 | 0.4934 |
| ROUGE-2 | 0.5663 | 0.5729 |
| METEOR | 0.6588 | 0.6670 |
| BERTScore | 0.9461 | 0.9471 |
| LLM Judge (%) | 76.39 | 77.43 |
对视觉编码器(SigLIP)施加rank 32的LoRA微调后,所有指标一致提升。LLM Judge从76.39%提升到77.43%(+1.36个百分点),词汇指标提升最明显(BLEU-4: +1.52%,ROUGE-2: +1.17%),语义指标提升较温和(BERTScore: +0.11%)。这表明让视觉编码器适应农业域的视觉特征(如病斑纹理、叶脉形态等)对提升诊断质量有实际贡献。
训练策略:Single-stage vs Two-stage
| 指标 | Single-stage | Two-stage |
|---|---|---|
| BLEU-4 | 0.4934 | 0.4286 |
| ROUGE-2 | 0.5729 | 0.4925 |
| METEOR | 0.6670 | 0.6103 |
| BERTScore | 0.9471 | 0.9364 |
| LLM Judge (%) | 77.43 | 73.26 |
Two-stage训练(先纯文本再多模态)在所有指标上全面落后于single-stage:BLEU-4下降15.12%,LLM Judge下降4.17个百分点。论文将原因归结为灾难性遗忘(catastrophic forgetting):第一阶段针对文本优化的adapter权重,在第二阶段引入视觉模态时被部分覆盖。这一结果为类似的域适应微调提供了实践参考------在数据充分的情况下,直接进行多模态联合训练更为有效。
五、总结与思考
AgriChat展示了一条从数据生产到模型微调的完整路径:V2VK管线利用视觉描述、网络RAG检索和指令合成三阶段自动构建经过科学验证的农业VQA数据,生成的AgriMM基准以121,425张图像、607,125条VQA对和3,099个类别覆盖了物种识别、病害诊断和作物计数三大任务。基于此数据微调的AgriChat在域内和多数零样本场景中表现出明显的领域优势,且整个训练仅需单张RTX 3090,推理约2.3秒/次,具备实际部署的可行性。
在此基础上,有几点值得进一步思考。首先是专家-通才的边界问题:AgriChat在AGMMU开放式问答中落后通用模型13.0个百分点,说明V2VK管线构建的数据偏向"诊断型"知识,而治疗方案、管理建议等开放性知识仍依赖通用模型的广泛预训练------后续如何在保持诊断精度的同时补充管理类知识,是一个值得关注的方向。其次,V2VK管线的可迁移性值得关注:三阶段"视觉描述-知识检索-指令合成"的框架并不限于农业,任何专业领域(如工业质检、医学病理)只要有标注图像和可检索的专业文献,理论上都可以复用这一管线快速构建领域VQA数据集。论文提到的下一步是扩展至害虫识别和增加每类别的图像表示量,这将进一步检验该方法在长尾分布下的鲁棒性。