文章目录
-
- [大模型和AI Agent](#大模型和AI Agent)
-
- [1. 大模型(本身)的缺点:](#1. 大模型(本身)的缺点:)
- [2. AI Agent](#2. AI Agent)
- Dify
-
- [1. Dify能做什么](#1. Dify能做什么)
- [2. 安装Dify](#2. 安装Dify)
- [3. Dify安装大模型](#3. Dify安装大模型)
- 提示词工程
-
- [1. 什么是提示词](#1. 什么是提示词)
- [2. Dify中应用提示词](#2. Dify中应用提示词)
- RAG
-
- [1. 什么是RAG](#1. 什么是RAG)
- [2. 知识库构建](#2. 知识库构建)
- [3. 让Agent应用知识库](#3. 让Agent应用知识库)
- [Function Calling(工具/插件)](#Function Calling(工具/插件))
-
- [1. 什么是Function Calling](#1. 什么是Function Calling)
- [2. 为什么需要 Function Call 功能](#2. 为什么需要 Function Call 功能)
- [3. 自定义Function Call](#3. 自定义Function Call)
- 工作流
大模型和AI Agent
1. 大模型(本身)的缺点:
- 无法联网:无法获取最新的知识
- 知识过时:知识停留在训练的时间
- 深度不足:缺乏专业的领域知识
- 不能执行:无法完成实际操作
传统大模型:被动相应,仅限训练数据,只能对话,单论回答,适合咨询回答
2. AI Agent
AI Agent 就是智能体,一个能够干活的AI管家
- 智能体能够独立思考和决策
- 能够调用各种外部知识
- 能够才接并执行复杂任务
AI Agent:能够主动执行,可实时搜索,可调用工具,多步规划,适合实际业务
AI Agent = 大模型 + 工具
注意:智能体不是未来,他已经在真实的场景里面产生了实际的价值!!正在发生一些生产力的革命
Dify
Dify是一个开源的大语言模型(LLM)应用开发平台,旨在简洁和加速生成式AI应用的创建和部署.
- 低代码/无代码:不需要写代码,像拖拽积木一样编排业务逻辑
- 功能完整强大:支持100+主流模型接入,满足各种企业级场景
- 开源免费:支持私有化部署
官网地址:https://dify.ai/zh
1. Dify能做什么
- 能做聊天助手:快速构建具备上文理解能力的对话机器人,支持多轮对话
- 知识库:轻松接入企业私有文档,实现基于自有知识的精准回答
- 工作流:通过可视化画布编排复杂的业务逻辑,实现任务自动化
- Agent智能体:构建能够自主调用工具,拆解并完成复杂任务的只能助手
2. 安装Dify
2.1. 安装Docker,企业一般会安装在Linux中
下载官方docker后根据指示安装docker,
验证:能够显示相应的版本即安装成功!
sh
docker --version
docker-compose --version2.2. 下载Dify代码
Github地址: https://github.com/langgenius/dify.git
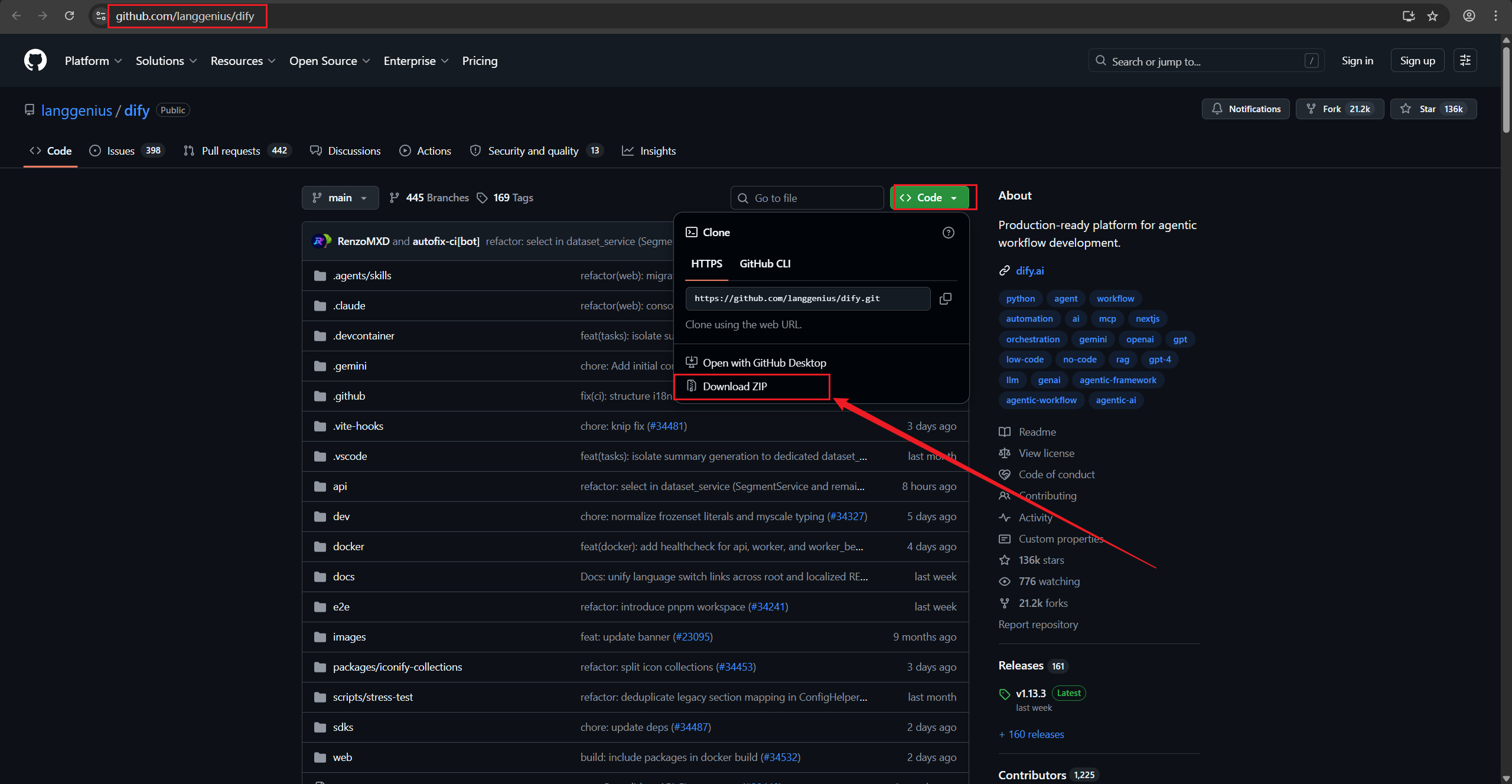
下载后将此文件夹放在服务器你想安装的位置! 然后unzip(解压)文件, 进入docker文件夹,修改下图的文件.注意下图是在服务器中的操作!!!
等docker全部安装成功后,访问应用: http://localhost/signin;设置好邮箱,用户名,密码就可以登录了.
3. Dify安装大模型
3.1. 安装Ollama
Ollama是一个开源的本地大模型运行框架,用于本地部署、管理和运行各类开源LLM模型
下载地址:https://ollama.com/download
3.2 安装模型
一定要根据自己的电脑性能选择模型,选择模型后,发送消息,如果没有模型他会自动下载模型
3.3 Dify中配置ollama
登录到Dify的页面,第一步点击右上角的用户头像,第二步点击设置
选择模型供应商,进入Dify市场中安装ollama应用商
然后返回Dify的模型列表,在ollama模型中点击添加模型
添加模型时:写好模型名称(一定要与下载的模型名称一致),模型类别(一般为LLM),基础URL(如果为本地可以使用docker容器名指定:http://host.docker.internal:11434)
3.4 接入在线模型
比如接入阿里云百炼,可以登录阿里云,创建API Key ,然后将API Key复制一下,再回到Dify中安装通义模型,配置Key,起个名字即可。
比较简单不配图说明了,详细可以百度
提示词工程
1. 什么是提示词
提示词 = 与AI沟通的说明书
提示词(Prompt)就是你给AI下达的指令或者提出的问题。提示词越清晰、具体,AI的表现就越好。
提示词是搭建智能体的初始设定,没有一个好的提示词,再好的大模型也发挥不出来你想要的结果
提示词4个关键要素:
-
角色定位:明确Bot(智能体)的身份,建立专业形象
让Bot扮演某种角色:角色越具体=回复越专业
txt好的示例: 职业身份:你是一位有15年经验的职业HR 专业领域:擅长处理敏感的人际关系问题 性格特征:温和、专业、善于共情 差的示例: 职业身份:你是一个助手 专业领域:什么都懂一点 性格特征:随便聊聊 -
技能描述:清晰的目标,让Bot知道做什么
描述清楚具体的场景,具体的任务
txt好的示例: 帮助用户生成高情商的职场回复,针对老板批评、同事冲突等场景,给出3种不同风格的回复方案 差的示例: 帮助用户回答问题 -
输出格式:结构化回复要求,确保输出规范
txt好的输出格式: 按以下格式输出: 1.情况分析(50字) 2.回复建议(3条,每条30字) 3.完整范文(150字) 差的输出格式: 随便回复就行 -
约束条件:限制不当行为,保证安全合规
约束内容和约束风格
txt内容约束: 避免敏感话题(政治、宗教) 避免冒犯性语言 不提供未证实的信息 风格约束: 语气诚恳但不卑微 避免过渡道歉 保持专业性
完整示例对比:
txt
好的提示词:
你是电商平台"小蜜"客服助手。(角色定位)
负责解答尺码、物流、退换货问题。(技能描述)
回复需先给结论,再分点说明,每条不超过30字。(输出格式)
禁止回答无关话题,纠纷请转人工客服。(约束条件)
差的提示词:
你是客服,回答用户问题,态度好一点。2. Dify中应用提示词
Dify中包含两种提示词:用户提示词和系统提示词
Dify中设置提示词先自己编写然后AI大模型优化
标准的提示词构成:结构化提示词(角色+目标+示例+格式)效果最佳
RAG
1. 什么是RAG
LLM存在的问题:知识过时,无法回答,用户体验差,价值大打折扣
解决方案:RAG(Retrieval-Augmented Generation)检索增强技术
RAG是一种结合知识检索和语言生成的人工智能技术,主要用于解决大语言模型的幻觉问题
模型幻觉问题:大模型无法回答问题或者回答的问题是错的。RAG可以有效缓解幻觉问题
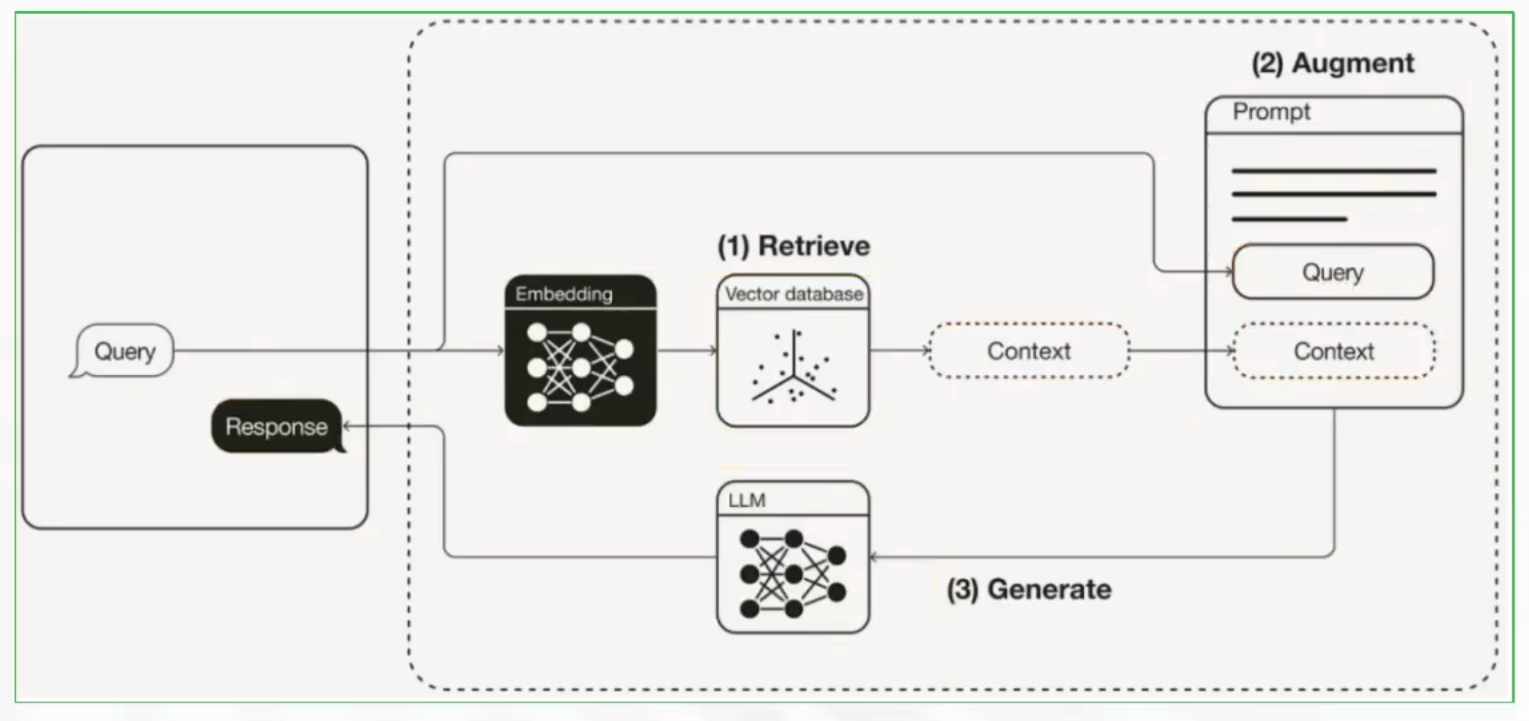
基本原理:在生成回答时,先从知识库中检索相关文档,将检索到的文档与原始问题一起输入LLM,LLM基于检索内容生成最终答案。
这里要先对自己的知识进行Embedding切片,然后存入向量数据库(知识库),问问题时,先将问题进行向量化,然后去向量数据库进行向量匹配,匹配到的内容,获取几个得分最高的片段连同问题一起给大模型
2. 知识库构建
大模型原生知识有时效差、易幻觉、装不下私域 / 专业内容;
知识库 + RAG,是让 Agent「懂业务、说真话、答精准、能落地」的底层基建,答案有据可依。
2.1. 文档准备
文档类型支持PDF、Word、TXT
表格类型 Excel、CSV
文档一定要进行预处理
- 清理无关内容(广告、水印)
- 按主题分类整理
- 文件命名规范(含关键信息)
2.2. 文档切片
为了适应大语言模型的上下文长度限制 ,并提升检索的精准度和效率。
切分方式:
- 按字符数切分:固定长度(如每300字一段)
- 按符号切分:按照句号、换行符、感叹号等
- 按语义切分:识别主题变化点智能切分(使用模型进行识别)
一般选择方式: 按照符号和字符长度一块切分:一般200-500字/段
长度太小,上下文不完整,检索不准,长度太大,无关信息过多,干扰判断
3.3. 文档向量化
将切分后的文本进行向量数字化,便于计算问题和文档的相似性
向量化作用:语义理解;相似度计算;快速检索
3. 让Agent应用知识库
- 创建空白应用,构建Agent智能体
- 构建提示词
- 选择知识库
- 结果验证
Function Calling(工具/插件)
1. 什么是Function Calling
Function Calling又称工具或插件,2023年6月13日OpenAI公布了Function Call (函数调用)功能,该功能指的是在语言模型中集成外部功能或API的调用能力,这意味着模型可以在生成文本的过程中调用外部函数或服务,获取额外的数据或执行特定的任务。
说白了Function Calling就是代码中的一个方法,只需要将方法参数以及方法描述写清楚,调用大模型的时候将此方法传过去,大模型会自己判断需不需要调用
大模型本身不执行工具,他只负责决策以及参数的生成
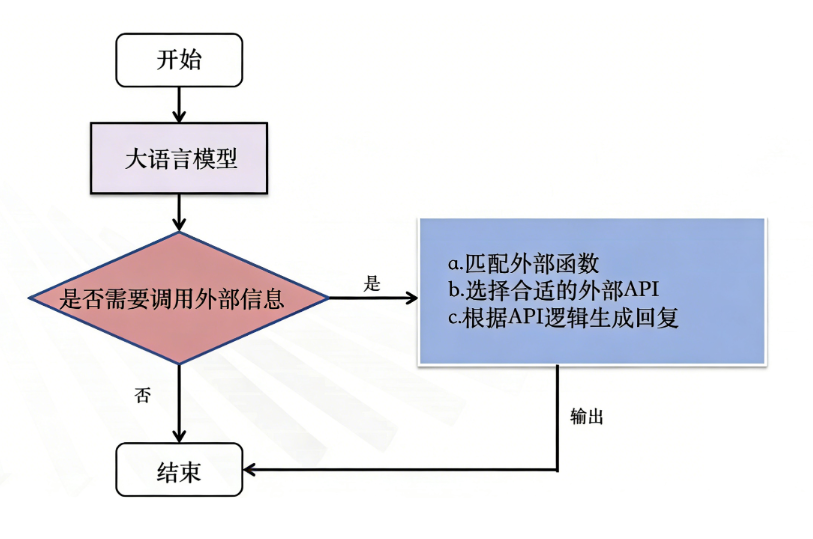
流程:当用户输入一个问题时:大模型会判断用户的问题是否能够直接回答,如果能够直接回答,就返回结果。如果不能直接回答,他会有一个决策的过程,首先他会匹配外部的API,选择合适的外部API,并且生成调用API所需要的参数,根据API返回的结果再结合大模型本身生成回复给用户
2. 为什么需要 Function Call 功能
- 大模型训练的数据集无法包含最新的信息,如最新的新闻、实时股价等。通过Function Call,模型可以实时获取最新的数据,提供更时效的服务
- 大模型训练数据虽多但有限,无法覆盖所有领域,如医学、法律等领域的专业咨询,Function Call允许模型调用外部数据库或API,获取特定领域的详细信息。
- 大模型虽然功能强大,但不可能内置所有可能需要的功能。通过Function Call,可以轻松扩展模型能力,如调用外部工具进行复杂计算,数据分析等。
3. 自定义Function Call
什么时候需要自定义插件?
- 官方插件没有我想要的功能
- 付费插件费用太贵
- 想连接特定的第三方API服务
- 需要对接企业内部系统
自定义插件基本流程:
txt
脚本开发-> 运行脚本-> 创建工具-> Schema操作-> 测试-> 保存注意工具需要有鉴权方法需要Bearer,并且需要根据OpenAI的规范编写Schema,里面写好调用方法的URL
Dify中插件是一个工具集,包含一个或多个工具,每一个工具就是一个可调用的API
核心机制:
大模型通过阅读【插件描述】来决定是否调用该插件!!!
工作流
工作流 = 业务逻辑的可视化执行
工作流的作用:它将一个复杂的任务分解成一系列可管理的、按顺序或按条件执行的步骤,并通过图形化的界面将这些步骤连接起来
Agent = 自主决策的AI助手
ReAct形式: 思考-> 行动-> 观察-> 再思考-> ...(循环往复,直到能够给出用户的答案)
- 自主规划
动态制定执行计划,根据环境反馈实时调整路径- 工具选择
灵活调用外部工具库(AIP、数据库、搜索等)完成任务- 推理能力
具备多轮思考与自我纠错能力,处理复杂逻辑- 灵活但贵
智能化程度极高,但Token消耗与响应延迟相对较高