AI大模型兼容,踩坑到崩溃

前言
大模型厂商众多,OpenAI、Anthropic、Google Gemini、GitHub Copilot、xAI Grok......每个厂商的 API 接口设计都不尽相同。如果业务代码直接耦合某一家 SDK,换模型几乎等于重写。
本文介绍一种统一抽象层的设计思路:让业务代码只依赖一套接口协议,底层可以无缝切换任意大模型。同时兼容同步对话和流式输出,并支持工具调用(Function Calling)这一复杂能力。
本文展示核心设计决策和实现思路(文中仅用伪代码)。
1. 问题:模型差异在哪里?
做模型兼容之前,先看清楚差异到底有哪些。
1.1 消息结构的差异
OpenAI 系列(含 Copilot、Grok):
- 用
role: "assistant"表示模型回复 - 用
role: "tool"独立消息传递工具结果
json
// OpenAI 工具结果
{ "role": "tool", "tool_call_id": "abc123", "content": "..." }Anthropic:
- 同样用
role: "assistant"表示模型回复 - 工具结果内嵌在
user消息的content数组里,不是独立消息
json
// Anthropic 工具结果
{ "role": "user", "content": [
{ "type": "tool_result", "tool_use_id": "abc123", "content": "..." }
]}Gemini:
- 用
role: "model"而不是assistant - 工具结果用
functionResponse作为 part 嵌入 user 消息
json
// Gemini 工具结果
{ "role": "user", "parts": [
{ "functionResponse": { "name": "get_weather", "response": { "content": "..." } } }
]}这还只是工具结果这一项差异。继续往下看。
1.2 System Prompt 的不同放置方式
| 模型 | System Prompt 放在哪? |
|---|---|
| Anthropic | 请求体中独立的 system 字段 |
| OpenAI / Copilot / Grok | 前置一条 role: "system" 的消息 |
| Gemini | 请求 config 中的 systemInstruction 字段 |
1.3 工具定义的结构差异
定义一个工具,OpenAI 用 parameters,Anthropic 用 input_schema,Gemini 用 parametersJsonSchema------名字都不一样,但语义完全相同。
1.4 停止原因(stop_reason)词汇不统一
模型停止生成的原因,各家叫法不同:
| 模型 | 可能的原始值 | 实际含义 |
|---|---|---|
| OpenAI | stop |
对话正常结束 |
| OpenAI | tool_calls |
调用了工具 |
| Anthropic | end_turn |
对话正常结束 |
| Gemini | STOP |
对话正常结束 |
| 任意 | MAX_TOKENS |
token 耗尽 |
业务代码如果直接判断这些原始值,换模型就等于改业务逻辑。
2. 核心思路:抽象接口 + 适配器模式
解决方案是两层结构:
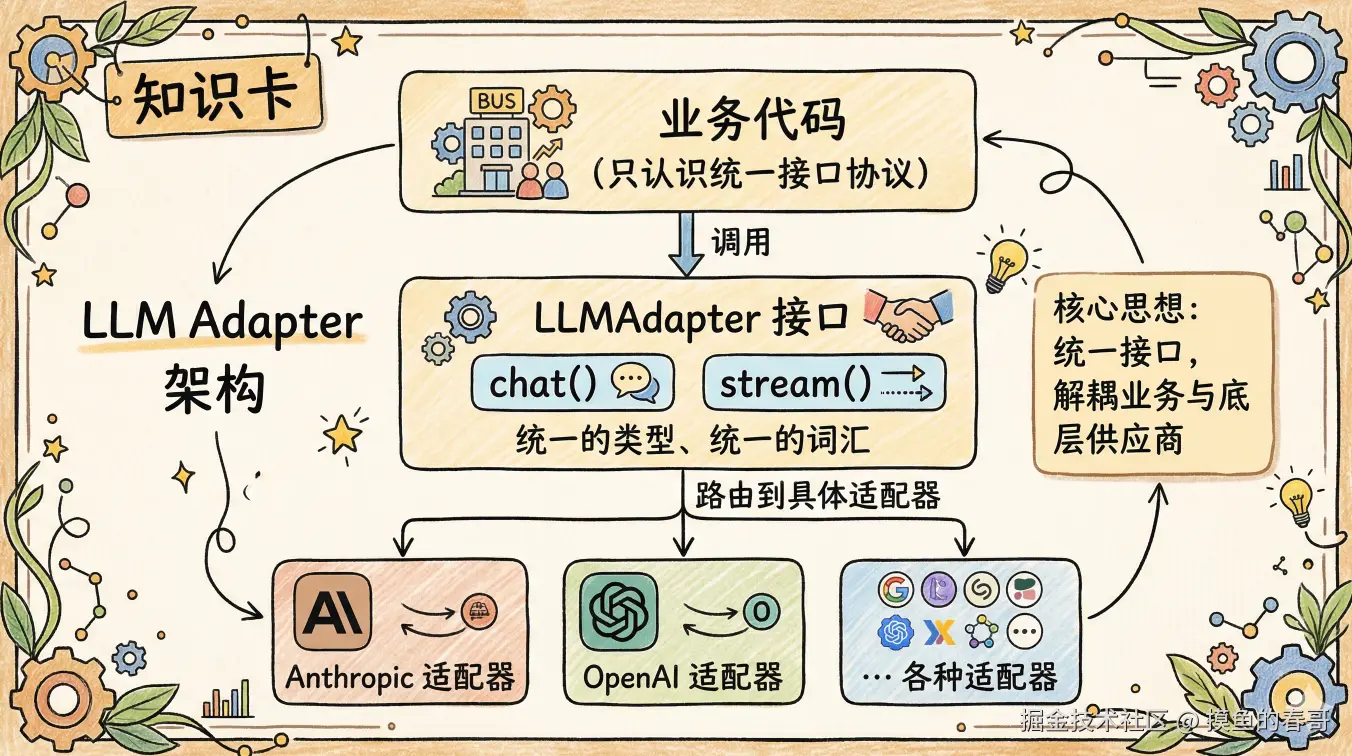
核心原则:适配器只做转换,不做业务决策。
每个适配器只负责三件事:
- 消息转换:把统一格式转成目标模型的 Wire Format
- 响应转换:把模型返回结果转回统一格式
- 流式事件 yield:按协议输出 text / tool_use / done / error
适配器不知道 token 花了多少,不知道要不要重试,更不知道业务在做什么。
3. 统一接口长什么样?
业务代码只需要认识这两个方法:
python
# 伪代码
class LLMAdapter:
name: str
async def chat(
messages: list[Message],
options: ChatOptions,
) -> LLMResponse: ...
async def stream(
messages: list[Message],
options: StreamOptions,
) -> AsyncIterator[StreamEvent]: ...Message 是统一的消息结构,LLMResponse 是统一的响应结构。任何模型适配器返回的内容,结构完全一致。
3.1 统一的内容块
模型可能返回文本、工具调用、工具结果、图片。这些用"内容块"来统一表达:
python
# 伪代码
class TextBlock:
type: "text"
text: str
class ToolUseBlock:
type: "tool_use"
id: str # 本次工具调用的唯一 ID
name: str # 工具名
input: dict # 工具参数(已解析好的字典)
class ToolResultBlock:
type: "tool_result"
tool_use_id: str # 关联到哪一次工具调用
content: str | dict
is_error: bool | None
class ImageBlock:
type: "image"
source: ImageSource注意这里 ToolUseBlock.input 已经是 dict,而不是 JSON 字符串------解析工作由适配器完成,业务代码不需要处理原始参数字符串。
3.2 归一化的 stop_reason
适配器负责把模型原始的停止原因转换成统一词汇:
python
# 伪代码
NORMALIZED_STOP_REASONS = {
"stop": "end_turn", # OpenAI
"tool_calls": "tool_use", # OpenAI
"MAX_TOKENS": "max_tokens", # 任意
"length": "max_tokens", # OpenAI
"end_turn": "end_turn", # Anthropic
"STOP": "end_turn", # Gemini
}业务代码只需要判断三种停止原因:end_turn(对话结束)、tool_use(调用了工具)、max_tokens(token 耗尽)。换模型?不用改。
4. 工厂函数:隐藏适配器细节
业务代码不应该直接 new 某个适配器,而是通过工厂函数创建:
python
# 伪代码
def create_adapter(
provider: Literal["anthropic", "openai", "copilot", "grok", "gemini"],
api_key: str | None = None,
base_url: str | None = None,
) -> LLMAdapter:
# 工厂函数负责:
# 1. 环境变量解析(每个 provider 映射不同 env key)
# 2. 实例化正确的适配器
# 3. 返回新实例(每次调用新建,无单例)这样业务代码在切换模型时,只需要改一个字符串:
python
# 伪代码
llm = create_adapter("anthropic") # 换成 Claude
llm = create_adapter("openai", base_url="https://api.deepseek.com") # 换成 DeepSeek5. 工具调用:最难的部分
工具调用是兼容层最复杂的点,涉及三个维度:工具定义格式、工具结果传递、流式参数拼接。前两个维度在前文已覆盖,本节重点讲流式处理各家差异------这是最容易出 bug 的地方。
5.1 各家流式处理全对比
OpenAI(含 Copilot、Grok)
流式返回的是 function.arguments 字符串片段,逐步推送:
ini
[chunk] delta.function.arguments = '{"city":'
[chunk] delta.function.arguments = ' "Seatt'
[chunk] delta.function.arguments = 'le"}'适配器按 index(工具调用在列表中的位置)分 buffer 累积:
css
buffer[0] = { id: "call_abc", name: "get_weather", raw_args: '{"city": "Seattle"}' }流结束后一次性 JSON.parse(buffer[0].raw_args),得到 {city: "Seattle"}。
Anthropic
Anthropic SDK 对外暴露的是 content_block_delta 事件,其中 input_json_delta 类型专用于工具参数:
ini
[chunk] type="content_block_start", index=0, block.type="tool_use", id="toolu_xyz", name="get_weather"
[chunk] type="content_block_delta", index=0, delta.type="input_json_delta", partial_json='{"city":'
[chunk] type="content_block_delta", index=0, delta.type="input_json_delta", partial_json=' "Seattle"}'
[chunk] type="content_block_delta", index=0, delta.type="text_delta", text="\n\n" ← 可能穿插文本
[chunk] type="content_block_stop", index=0适配器同样按 index 累积 partial_json 到 buffer。注意:input_json_delta 已经是合法的 JSON 字符串片段(带引号和逗号),累积完毕后直接 parse 即可。
Gemini
Gemini SDK 根本不流式返回参数。functionCall 以完整对象形式一次性到达:
css
[chunk] part.functionCall = {
id: "gemini-call-001",
name: "get_weather",
args: { city: "Seattle" } ← args 已是 dict,不是 JSON 字符串
}这意味着 Gemini 适配器不需要任何 buffer 逻辑,遇到 functionCall 直接 yield 即可。
Ollama / 本地模型(vLLM 等)
这类 OpenAI 兼容 API 有时会"偷懒":工具调用其实是通过文本返回的,而不是用 tool_calls 字段:
css
[chunk] delta.content = 'I will use get_weather with {"city": "Seattle"}'适配器需要检测到这种情况,在流结束后从文本中正则提取 出 JSON 来构造 ToolUseBlock。这是一种兼容性兜底逻辑。
5.2 完整流式状态机(OpenAI 为例)
ini
请求发出
│
▼
S1: 收到 chunk
├── delta.content != null → yield text 事件
│
└── delta.tool_calls != null
├── index=0, id="call_abc", name="get_weather"
│ → 初始化 buffer[0] = {id, name, raw_args: ""}
└── index=0, function.arguments='{"city":'
→ 拼入 buffer[0].raw_args += '{"city":'
│
▼
S2: finish_reason != null → 记录最终 finish_reason
│
▼
S3: 流结束,遍历 buffer,按 index 顺序
├── buffer[0]: raw_args='{"city": "Seattle"}'
│ JSON.parse → input={city: "Seattle"}
│ yield tool_use 事件
└── buffer[1]: raw_args='{"query": "news"}'
JSON.parse → input={query: "news"}
yield tool_use 事件
│
▼
S4: yield done 事件(携带 final LLMResponse)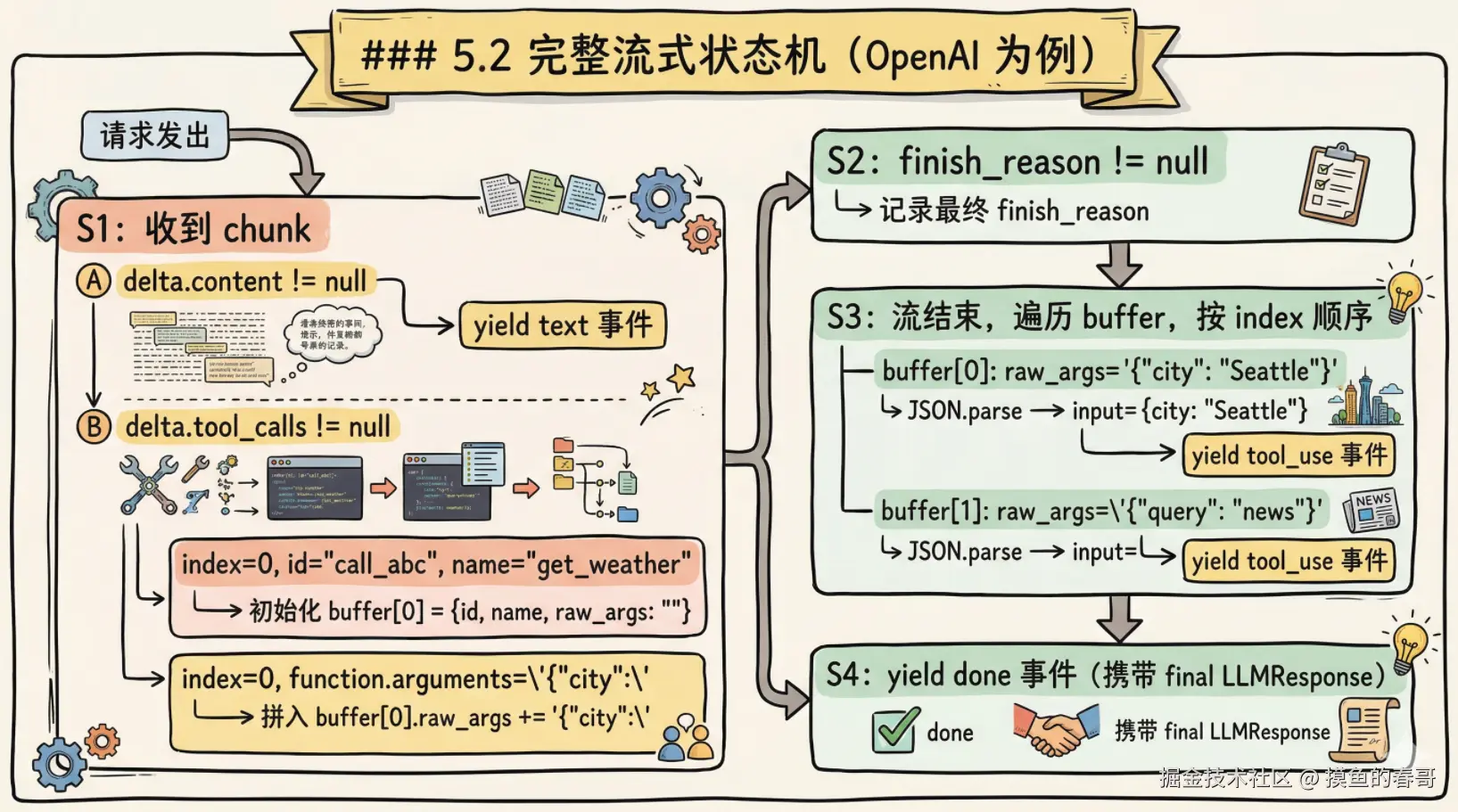
5.3 统一策略:collect-then-parse
不管底层是哪种模式,适配器对外的流式接口必须统一。核心原则只有一条:不区分来源,一致地累积,一致地输出。
python
# 伪代码
async def stream(self, messages, options) -> AsyncIterator[StreamEvent]:
# key = index(工具调用在列表中的位置)
tool_buffers: dict[int, ToolBuffer] = {}
# ToolBuffer = { id: str, name: str, raw_args: str }
async for chunk in model_stream(messages, options):
# --- 文本处理:各模型一致 ---
if chunk.has_text:
yield StreamEvent(type="text", data=chunk.text)
# --- 工具调用处理:按模型分发 ---
if chunk.provider == "openai":
for tc in chunk.tool_calls or []:
ensure_buffer(tc.index, tc.id, tc.name)
if tc.arguments:
tool_buffers[tc.index].raw_args += tc.arguments
elif chunk.provider == "anthropic":
for delta in chunk.content_block_deltas:
if delta.type == "input_json_delta":
ensure_buffer(delta.index, delta.id, delta.name)
tool_buffers[delta.index].raw_args += delta.partial_json
elif chunk.provider == "gemini":
for fc in chunk.function_calls:
yield StreamEvent(type="tool_use", data=ToolUseBlock(
id=fc.id or fabricate_id(),
name=fc.name,
input=fc.args, # args 已是 dict,无需 parse
))
continue # Gemini 不走下面的统一解析逻辑
# --- 统一解析:OpenAI / Anthropic ---
for buf in tool_buffers.values():
try:
parsed = json.loads(buf.raw_args)
except json.JSONDecodeError:
parsed = {} # 解析失败,优雅降级,不崩溃
yield StreamEvent(type="tool_use", data=ToolUseBlock(
id=buf.id, name=buf.name, input=parsed
))
yield StreamEvent(type="done", data=final_response)关键点:
- 流式过程中不解析 JSON :片段来了只累积。理由很简单------JSON 字符串在流式传输中途往往是不完整的(
{"city":),此时 parse 必然失败。 - 解析失败不崩溃 :
try/except包裹json.loads,失败时返回空字典{},调用方会收到参数为空的工具调用,可以在业务层决定是重试还是报错。 - Gemini 是例外 :SDK 已经把参数解析成
dict,不需要 buffer,直接 yield。这是唯一一个不走 collect-then-parse 流程的模型。
5.4 并行工具调用的处理
有时候模型会一次性并行调用多个工具,这些调用在流式返回时通过 index 字段区分:
ini
[chunk] tool_calls[0]: id="call_1", name="get_weather", arguments='{"city": "Seattle"}'
[chunk] tool_calls[1]: id="call_2", name="get_time", arguments='{"tz": "PST"}'
[chunk] tool_calls[0]: arguments='...下一块的片段...'
[chunk] tool_calls[1]: arguments='...下一块的片段...'buffer 按 index 组织,各自独立累积,互不干扰。流结束时按 index 顺序 yield(index 是 int,天然有序)。
6. 认证:适配器的"隐形"工作
每个模型的 API key 环境变量名不同:
| 模型 | 环境变量 |
|---|---|
| Anthropic | ANTHROPIC_API_KEY |
| OpenAI | OPENAI_API_KEY |
| Gemini | GEMINI_API_KEY / GOOGLE_API_KEY |
| Grok | XAI_API_KEY |
| Copilot | GITHUB_COPILOT_TOKEN / GITHUB_TOKEN(还支持 OAuth2 交互式认证) |
工厂函数负责根据 provider 映射到正确的环境变量,适配器只接收一个已经解析好的 API key,保持职责单一。
7. 错误处理契约
适配器错误处理遵循三条规则:
-
API 错误透传:非 2xx 响应或 SDK 异常不捕获,直接抛给调用方。调用方才知道要不要重试、怎么重试。
-
解析失败不崩溃:工具参数 JSON 解析失败,返回空字典,不中断流。
-
未知块类型不丢弃:模型返回了某个我们不认识的内容块类型时,降级成文本块返回,保证数据不丢失。
8. 架构收益
有了这层抽象,能得到什么?
换模型零感知:从 Claude 换到 GPT-5,业务代码一行不用改,改个 provider 字符串就够了。
工具调用一套实现:不管底层是 OpenAI 的 tool_calls 还是 Anthropic 的 content_block,流式处理逻辑完全统一。
可测试性强 :直接 mock LLMAdapter 接口,不需要真实的 API key 就能测试业务逻辑。
新增模型成本低:实现一个新适配器,只需要关注格式转换,不影响任何已有代码。
结语
模型厂商的接口差异是表面,本质都是"输入消息,输出 token"。找到这个本质,用适配器模式把差异封装在底层,业务代码就能真正做到"跟厂商解耦"。
这套设计已经在 TypeScript 项目中验证过,思路同样适用于 Python、Go 或任何有类型系统的语言。核心在于那两条原则:统一接口收敛一切差异,适配器只做格式转换不做业务。