大家好,我是舒一笑不秃头,喜欢分享和写作,更多精彩内容~
很多人一提到"设备指纹",第一反应就是:
这是不是某种黑盒算法?是不是偷偷拿到了设备唯一 ID?
其实不是。
在真实项目里,设备指纹没有那么玄学。它更像是把当前访问终端的一组环境特征收集起来,经过标准化处理后,再压缩成一个固定长度的摘要。
今天我就拿一个常见的 Java 实现思路做一次拆解,看看设备指纹到底是怎么生成的,它为什么能区分设备,又有哪些边界。
先说结论
设备指纹能区分不同设备,并不是因为它依赖了某个"神奇字段"。
它真正做的是这 4 件事:
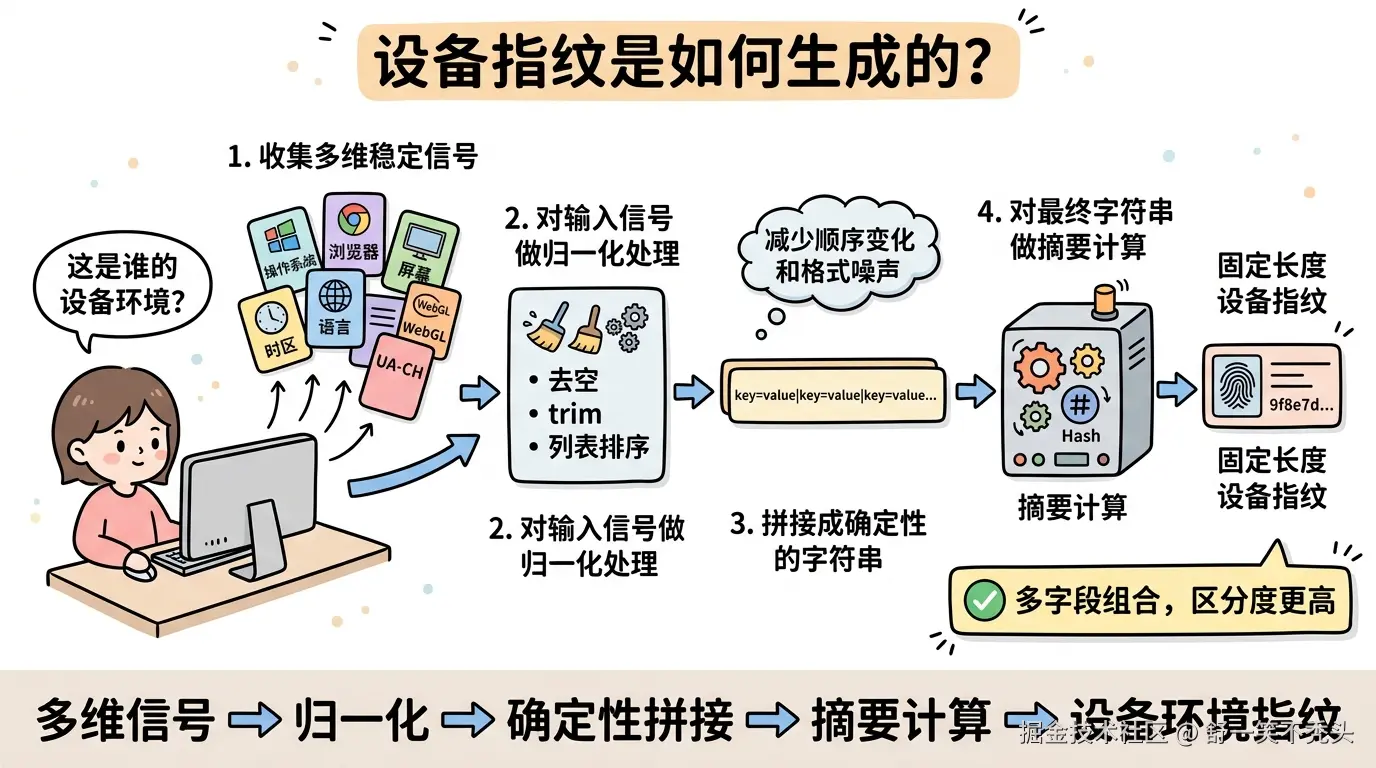
- 收集多维稳定信号 例如系统、浏览器、屏幕、时区、语言、WebGL、UA-CH 等。
- 对输入信号做归一化处理 去空、trim、列表排序,尽量减少顺序变化和格式噪声。
- 拼接成确定性的字符串 例如:
key=value|key=value|key=value... - 对最终字符串做摘要计算 得到一个固定长度的设备指纹。
一句话总结:
单个字段不可靠,但多个字段组合起来,区分度会明显提升。
所以它的核心不是"绝对识别某一台设备",而是:
用足够多的环境特征,生成一个高概率可区分的设备环境摘要。
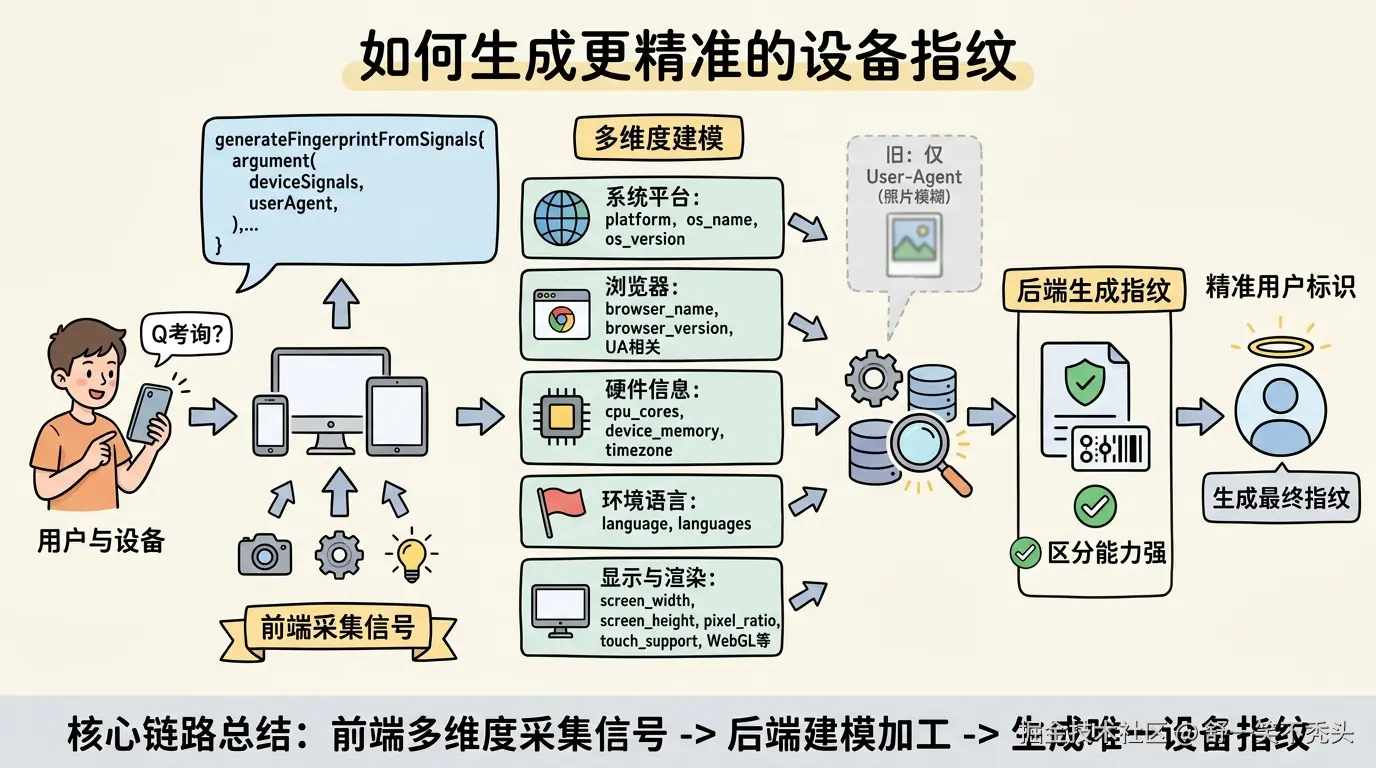
主路径:优先使用前端设备信号
一个比较常见的实现方式,是前端采集设备信号,后端负责生成最终指纹。
例如入口逻辑大致可以理解为:
scss
generateFingerprintFromSignals(deviceSignals, userAgent);也就是说,如果前端能上报完整的设备信号,后端就优先基于这些信号生成指纹。
常见的采集字段包括:
sql
platform
os_name
os_version
browser_name
browser_version_major
cpu_cores
device_memory
timezone
language
languages
screen_width
screen_height
color_depth
pixel_ratio
touch_support
webgl_vendor
webgl_renderer
ua_ch.*
user_agent你可以把它理解成:
以前只看 User-Agent,相当于只看一张模糊照片。
现在收集 20+ 个维度,相当于从系统、浏览器、硬件、显示环境、语言环境、图形渲染能力等多个角度一起建模。
这就是设备指纹区分能力的来源。
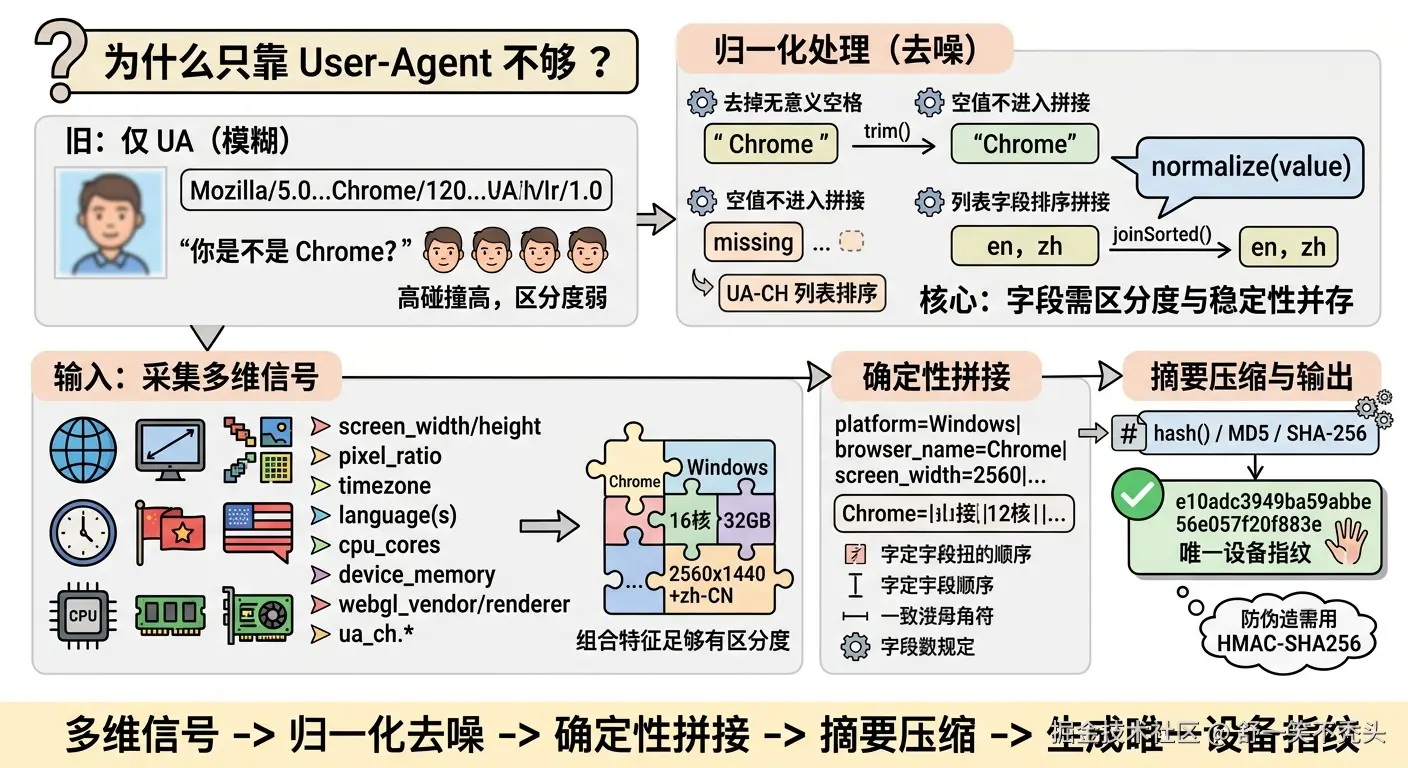
为什么只靠 User-Agent 不够?
很多系统早期做设备识别,喜欢直接用 User-Agent。
比如:
erlang
Mozilla/5.0 ... Chrome/120 ...看起来挺详细,但问题也很明显:
同一个浏览器版本、同一个系统版本、同一种设备型号下,很多用户的 UA 可能非常接近,甚至完全一样。
所以只用 UA,本质上是在问:
"你是不是 Chrome?你是不是 Windows?你是不是某个版本?"
这当然不够。
而多信号指纹会继续追问:
你的屏幕分辨率是多少?
你的像素比是多少?
你的语言列表是什么?
你的时区是什么?
你的 CPU 核数是多少?
你的设备内存是多少?
你的 WebGL vendor 是什么?
你的 WebGL renderer 是什么?
你的 UA-CH 品牌版本列表是什么?这些字段单独看都不一定可靠,但组合起来之后,区分度就会明显提升。
关键点一:收集多维信号,拉开设备差异
设备指纹真正有价值的地方,不是最后用了什么摘要算法,而是前面收集了足够多的信号。
例如下面这些字段:
sql
screen_width
screen_height
color_depth
pixel_ratio
timezone
language
languages
webgl_vendor
webgl_renderer
cpu_cores
device_memory它们分别描述了不同维度:
| 字段 | 代表含义 |
|---|---|
screen_width / screen_height |
屏幕尺寸 |
pixel_ratio |
设备像素比 |
timezone |
时区 |
language / languages |
语言环境 |
cpu_cores |
CPU 核心数 |
device_memory |
设备内存 |
webgl_vendor |
图形厂商 |
webgl_renderer |
图形渲染器 |
ua_ch.* |
浏览器提供的客户端提示信息 |
如果只看其中一个字段,当然很容易撞。
比如很多人都是:
ini
timezone=Asia/Shanghai
language=zh-CN
browser_name=Chrome但如果把这些字段组合起来:
ini
Chrome + Windows + 16核 + 32GB内存 + 2560x1440 + pixel_ratio=2 + WebGL Renderer + zh-CN + Asia/Shanghai这个组合就比单个 UA 难撞得多。
这就是设备指纹的基本逻辑:
不追求某个字段唯一,而是追求组合特征足够有区分度。
关键点二:归一化处理,减少噪声
设备指纹最怕什么?
不是字段少,而是字段不稳定。
同一个设备,如果今天生成一个指纹,明天又生成另一个指纹,那这个指纹就没法用。
所以实现里通常会做几件非常关键的"去噪"工作。
1. 去掉无意义空格
例如前端上报:
arduino
" Chrome "和:
arduino
"Chrome"如果不处理,这两个值会被认为不一样。
所以生成指纹前,需要统一做 trim 处理:
scss
normalize(value);它的作用就是把输入标准化,避免因为空格、空字符串等问题造成指纹漂移。
2. 空值不进入指纹串
如果某些字段为空,直接拼进去可能会出现:
ini
device_memory=null或者:
makefile
webgl_renderer=这类值不仅没有信息量,还可能污染最终指纹。
所以更好的做法是:
只有真正有值的字段才进入最终指纹串。
这点很重要。
因为设备信号在不同浏览器、不同权限、不同采集环境下,可能会缺失一部分字段。
空值不参与拼接,可以减少无意义差异。
3. 列表字段先排序再拼接
语言列表这种字段很容易出现顺序波动。
比如:
zh-CN,en-US和:
en-US,zh-CN如果不排序,这两个列表拼出来的字符串就不一样。
但它们本质上可能表达的是同一组语言偏好。
所以更稳妥的做法是先排序,再拼接:
scss
joinSorted(languages);这样可以降低顺序噪声。
4. UA-CH 品牌列表也要排序
UA-CH 里的品牌版本列表也有类似问题。
浏览器可能返回类似:
css
Chromium 120
Google Chrome 120
Not A Brand 99如果顺序不稳定,指纹也会跟着漂。
所以可以按品牌名排序后再展开。
这一步看起来很小,但在生产环境里很有价值。
因为设备指纹的核心诉求不是"字段越多越好",而是:
字段既要有区分度,也要尽量稳定。
关键点三:确定性拼接
归一化之后,可以把字段拼成类似这样的字符串:
ini
platform=Windows|os_name=Windows|os_version=10|browser_name=Chrome|browser_version_major=120|screen_width=2560|screen_height=1440|pixel_ratio=2|timezone=Asia/Shanghai|language=zh-CN|webgl_vendor=Google Inc.|webgl_renderer=ANGLE注意这里的重点是:确定性。
同样的输入,必须拼出同样的字符串。
这就要求:
- 字段顺序固定;
- 空值处理一致;
- 列表排序一致;
- 字符串格式一致;
- 分隔符一致。
只要这些规则稳定,同一台设备在环境不变的情况下,就会生成同样的原始指纹串。
关键点四:最后做摘要压缩
最后一步通常是对拼接结果做摘要计算:
bash
hash(String.join("|", parts));很多实现会使用 MD5、SHA-256 或其他摘要算法。
这里容易被误解。
摘要算法在这个场景里,主要不是用来做安全签名,也不是用来防伪造。
它只是把一长串设备特征压缩成一个固定长度的字符串,方便存储、比较和索引。
例如原始字符串可能很长:
ini
platform=Windows|os_name=Windows|browser_name=Chrome|screen_width=2560|...经过摘要后变成:
e10adc3949ba59abbe56e057f20f883e比较起来就方便多了。
但是必须注意:
如果你要防篡改、防伪造、防重放,单纯摘要算法不够。
更合适的做法是使用:
HMAC-SHA256或者结合服务端密钥做签名。
它为什么"通常有效"?
设备指纹的有效性,本质上是一个概率问题。
单字段很容易撞:
ini
browser_name=Chrome这个字段几乎没有什么区分能力。
加上系统:
ini
browser_name=Chrome
os_name=Windows稍微好一点,但仍然很容易撞。
继续加上屏幕、时区、语言、WebGL、CPU、内存、UA-CH:
ini
Chrome + Windows + 2560x1440 + pixel_ratio=2 + Asia/Shanghai + zh-CN + 16 cores + 32GB + WebGL Renderer这时候,两个不同设备完全相同的概率就会下降很多。
所以设备指纹的核心是:
用多个不完全可靠的信号,组合出一个相对可靠的判断依据。
它不是百分百唯一,但在真实业务流量里,已经足够支撑很多风控、登录保护、异常识别场景。
降级路径:前端信号没有,也能生成基础指纹
一个比较实用的设计是:
如果前端设备信号不可用,后端不直接失败,而是走降级逻辑。
降级路径可以使用请求头信息,比如:
sql
User-Agent
Accept-Language
Accept-Charset然后同样做拼接和摘要计算。
这意味着:
即使前端没有完整上报设备信号,后端仍然可以生成一个基础可用的弱指纹。
当然,这种弱指纹的区分能力肯定不如完整设备信号。
可以这样理解:
| 模式 | 使用信号 | 区分能力 |
|---|---|---|
| 强指纹 | 前端多维设备信号 + UA | 较强 |
| 弱指纹 | UA + 请求头 | 较弱 |
| 无指纹 | 什么都没有 | 不可用 |
所以生产里更建议把它拆成两层:
strong_fingerprint
weak_fingerprint这样后续做风控、排查、统计时会更清晰。
设备指纹的边界,一定要讲清楚
设备指纹很有用,但它不是万能的。
尤其在项目评审、风控设计、隐私合规场景下,下面这些边界必须提前说明。
1. 它不是绝对唯一设备 ID
设备指纹不是身份证号,也不是硬件唯一编号。
它只能说:
这次访问的设备环境,和之前某次访问的设备环境高度相似。
它并不能 100% 证明两次访问来自同一台物理设备。
例如两台设备如果满足:
同型号
同系统版本
同浏览器版本
同语言
同分辨率
同图形环境那它们理论上可能生成相同指纹。
所以设备指纹应该被称为"概率性标识",而不是"唯一设备 ID"。
2. 指纹可能会变化
同一台设备也可能因为环境变化导致指纹变化。
比如:
- 浏览器升级;
- 系统升级;
- 修改系统语言;
- 切换显示器;
- 调整缩放比例;
- 浏览器隐私策略变化;
- WebGL 信息被屏蔽;
- 用户使用隐私插件;
- UA-CH 返回内容变化。
这些都会导致设备信号发生变化。
所以线上不能简单地认为:
指纹变了 = 一定换设备更合理的判断是:
指纹轻微变化 = 疑似同设备
指纹大幅变化 = 疑似新设备这就需要结合账号、IP、地理位置、行为节奏一起判断。
3. 摘要算法不是安全机制
再强调一遍:
摘要算法在这里只是压缩手段,不是安全机制。
如果攻击者知道你的拼接规则,并且能伪造前端上报字段,那么他就可能构造相同或相似的指纹。
所以设备指纹不能单独用于安全决策。
更合理的做法是:
设备指纹 + 登录态 + IP ASN + 地理位置 + 行为特征 + 风险评分设备指纹应该是风控体系里的一个信号,而不是唯一依据。
生产落地时,我建议做这 5 个增强
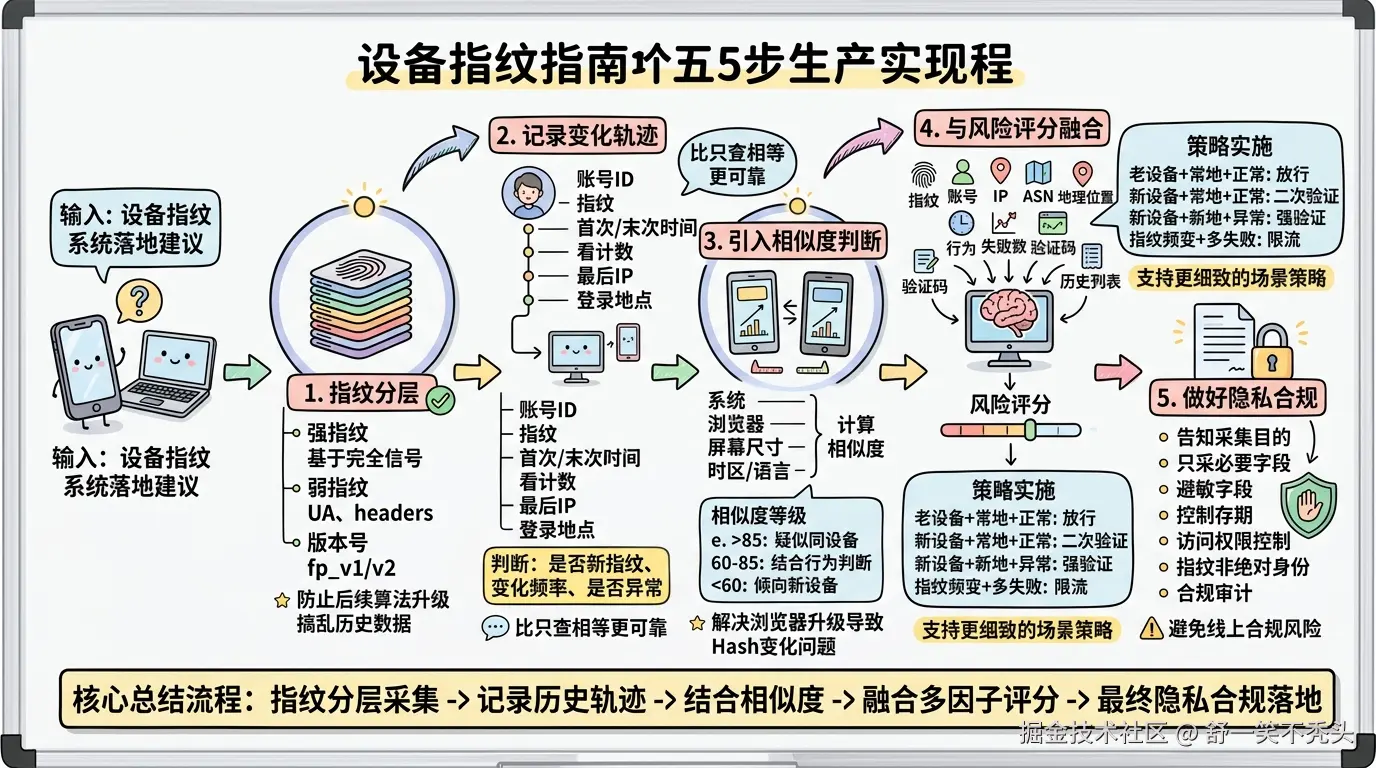
如果要把这套逻辑真正放到线上,我建议至少做下面 5 件事。
1. 指纹分层
不要只存一个字段。
建议拆成:
strong_fingerprint
weak_fingerprint
fingerprint_version例如:
strong_fingerprint:基于完整前端信号
weak_fingerprint:基于 UA 和请求头
fingerprint_version:fp_v1 / fp_v2这样后续升级算法时,不会把历史数据搞乱。
2. 记录指纹变化轨迹
不要只看当前指纹。
应该记录账号下历史设备指纹变化:
account_id
fingerprint
first_seen_at
last_seen_at
seen_count
last_ip
last_login_location这样可以判断:
- 这个指纹是不是第一次出现;
- 它和历史指纹有多像;
- 是否短时间内频繁变化;
- 是否伴随登录地点变化;
- 是否伴随异常行为。
这比简单判断"指纹是否相等"要可靠得多。
3. 引入相似度判断
设备指纹最终通常是一个 hash。
hash 的问题是:
只要一个字段变了,最终 hash 就完全不同。
所以除了存 hash,也可以保留一份结构化特征,用于相似度比较。
比如:
sql
os_name 相同
browser_name 相同
screen_width 相同
screen_height 相同
timezone 相同
language 相同
webgl_renderer 相似然后给每个字段一个权重,计算设备相似度。
例如:
相似度 > 85:疑似同设备
相似度 60~85:需要结合行为判断
相似度 < 60:倾向新设备这样可以解决"浏览器升级导致 hash 变化"的问题。
4. 和风险评分融合
设备指纹单独看价值有限,和其他信号组合起来才有威力。
例如:
设备指纹
账号
IP
ASN
地理位置
登录时间
操作行为
失败次数
验证码结果
历史设备列表可以组合成一个风险评分:
ini
risk_score = 设备风险 + 网络风险 + 行为风险 + 账号风险这样就可以支持更细的策略:
| 场景 | 策略 |
|---|---|
| 老设备 + 老地点 + 正常行为 | 放行 |
| 新设备 + 老地点 + 正常行为 | 二次验证 |
| 新设备 + 新地点 + 异常行为 | 强验证 |
| 指纹频繁变化 + 登录失败多 | 限流或拦截 |
这才是设备指纹最常见的生产用法。
5. 做好隐私合规
设备指纹涉及终端识别,一定要注意合规。
至少要做到:
- 明确告知用户采集目的;
- 只采集必要字段;
- 避免采集过度敏感信息;
- 控制保存周期;
- 做好访问权限控制;
- 不把指纹当作绝对身份凭证;
- 支持合规审计。
技术方案再好,如果合规没处理好,线上风险会很大。
一个更直白的比喻
设备指纹的本质,不是给设备发身份证。
它更像是在做一份"环境体检报告":
系统是什么?
浏览器是什么?
屏幕多大?
语言是什么?
时区在哪?
图形渲染信息是什么?
硬件能力大概是什么?然后把这份体检报告压缩成一个短字符串。
报告越丰富、越稳定、越规范化,区分能力就越强。
项目评审里可以这么解释
如果你要在技术评审里说明这套方案,可以直接这样写:
我们通过多维设备信号构建设备环境特征,包括系统、浏览器、屏幕、语言、时区、WebGL、UA-CH 等信息。
在生成指纹前,会对字段进行标准化、空值过滤、列表排序和确定性拼接,以减少输入噪声。
最终使用摘要算法生成固定长度指纹,用于设备识别、登录保护和风险判断。
该指纹属于概率性标识,不作为绝对设备 ID 使用,需要与账号、网络环境、地理位置和行为特征联合判定。
最后总结一下
设备指纹能区分设备,靠的不是某一个特殊字段,而是这套组合拳:
多维信号采集
↓
输入归一化
↓
稳定排序
↓
确定性拼接
↓
摘要压缩
↓
设备环境指纹它的优势是:
- 实现简单;
- 接入成本低;
- 区分度比纯 UA 高;
- 适合登录风控、设备识别、异常检测等场景。
它的边界是:
- 不是绝对唯一;
- 会随环境变化;
- 不能单独承担安全决策;
- 需要注意隐私合规。
所以最准确的理解应该是:
设备指纹不是"识别一台设备",而是"识别一次访问背后的设备环境特征"。
你们线上是怎么做设备识别的?
- 纯 UA 派
- 多信号指纹派
- 指纹 + 行为风控融合派
评论区聊聊你们踩过的坑。 如果大家感兴趣,我可以继续写一篇: 《设备指纹误判排查手册:从日志、SQL 到风控策略怎么查》 。