作者:Maris5188
摘要:本文完整拆解面向电商卖家的AI智能选品系统全流程实现,涵盖多平台数据采集、机会评分算法、DeepSeek大模型报告生成、对话式选品助手等核心模块,基于FastAPI异步架构落地,附关键代码片段和架构设计细节,适合AI+电商、LLM应用落地、异步开发方向开发者参考,可直接复用核心逻辑快速搭建属于自己的选品系统。
一、前言:电商选品的痛点与****AI 解决方案
做电商的核心共识是"七分靠选品,三分靠运营",但传统选品模式效率低下、依赖经验,早已跟不上当前快速迭代的市场节奏:
-
多平台手动检索:逐个打开各电商平台,重复搜索关键词,耗时费力;
-
数据整理繁琐:手动记录价格、销量、评价等数据到Excel,易出错、效率低;
-
决策依赖直觉:缺乏量化分析,靠经验判断品类潜力,容错率低;
-
市场响应滞后:一个品类完整分析需2-3天,等分析完成,市场红利已消失。
基于此,我们打造了这套AI智能选品系统,核心目标:用AI将选品全流程压缩至5分钟,实现"输入一个关键词,输出一份完整选品报告",让卖家从繁琐的手动操作中解放,聚焦运营核心。
二、系统核心能力与技术栈选型(实战重点)
2.1****核心能力拆解(可直接落地复用)
系统围绕"数据采集-分析-决策-交互"全链路设计,核心能力可直接对接电商卖家需求:
- 一键多平台采集:输入关键词,自动各电商平台(需求侧)+批发网(供给侧)商品数据,无需手动操作;
- 市场趋势自动化分析:集成百度指数、阿里指数抓取,自动判断品类热度、同比/环比变化,规避冷门品类;
- AI智能报告生成:数值分析+DeepSeek大模型洞察结合,既有精准的价格、销量统计,也有专业的市场分析和商品推荐理由;
- 对话式选品助手:自然语言交互,支持意图识别,聊一聊就能创建选品任务,零操作门槛;
- 一键导出:支持Excel(3个Sheet)、CSV格式导出,数据可直接用于运营决策或供应商对接。
2.2****技术栈选型(适配异步、高可用,附选型理由)
结合电商选品"高并发采集、低延迟响应、数据可靠"的需求,技术栈选型如下(附实战选型逻辑,避免踩坑):
|--------|-----------------------------|----------------------------------------------------------------------|
| 组件 | 选型 | 选择理由(实战重点) |
| Web框架 | FastAPI | 原生支持async/await,异步不阻塞,自带BackgroundTasks实现后台任务,接口响应毫秒级,适配多平台数据采集的并发需求 |
| ORM | SQLAlchemy Async + aiomysql | 异步连接数据库,避免采集、分析过程中阻塞接口,自带连接池管理,提升数据库操作效率 |
| 大模型 | DeepSeek | 中文理解能力强,性价比高,API兼容OpenAI格式,可快速替换适配,适合生成中文市场洞察和对话交互 |
| 电商数据采集 | 第三方API | 一个接口覆盖4大电商平台,无需单独开发各平台爬虫,减少反爬风险,降低开发成本 |
| 趋势爬虫 | Crawl4AI + Playwright | 无头浏览器渲染动态页面,结合LLM结构化提取数据,解决百度指数、阿里指数无API的问题 |
| 缓存 | Redis | 缓存API采集结果、Cookie信息,TTL设置24小时,减少重复调用API,节省额度、提升响应速度 |
| 请求校验 | Pydantic v2 | 强类型校验,避免非法请求导致的系统异常,简化参数处理逻辑,提升代码可维护性 |
三、核心模块深度拆解(附关键代码,可直接复用)
3.1****多平台数据采集与归一化(基础核心)
核心挑战:不同电商平台的数据字段差异巨大(如淘宝销量字段为sell_num,京东为comments,拼多多为sales),需做统一归一化,确保后续分析层无需关注数据来源。
采集策略:每个平台采集3页×40条数据(最多480条原始数据),区分需求侧(重点看销量、价格)和供给侧(重点看供应价、起订量)。
关键代码(数据归一化,OneBoundNormalizer类核心逻辑):
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python # 不同平台数据归一化映射,解决字段不一致问题 class OneBoundNormalizer: @staticmethod def normalize(product, platform): # 淘宝数据归一化 if platform == "taobao": return { "product_name": product.get("title", ""), "price": float(product.get("price", 0.0)), "monthly_sales": int(product.get("sell_num", 0)), "review_count": int(product.get("comment_num", 0)), "rating": float(product.get("score", 0.0)), "source_platform": "taobao" } # 京东数据归一化 elif platform == "jd": return { "product_name": product.get("name", ""), "price": float(product.get("price", 0.0)), "monthly_sales": int(product.get("comments", 0)), # 京东用评论数近似销量 "review_count": int(product.get("comments", 0)), "rating": float(product.get("score", 0.0)), "source_platform": "jd" } # 拼多多数据归一化 elif platform == "pdd": return { "product_name": product.get("goods_name", ""), "price": float(product.get("price", 0.0)), "monthly_sales": int(product.get("sales", 0)), "review_count": int(product.get("comment_count", 0)), "rating": float(product.get("avg_score", 0.0)), "source_platform": "pdd" } # 1688数据归一化 elif platform == "1688": return { "product_name": product.get("title", ""), "price": float(product.get("price", 0.0)), "monthly_sales": int(product.get("sale_info", {}).get("gmv_30days", 0)), "review_count": int(product.get("comment_count", 0)), "rating": float(product.get("score", 0.0)), "source_platform": "1688" } else: return None |
容错与缓存设计(避免API调用失败、重复消耗):
- API调用采用指数退避重试机制,最多重试3次,应对网络波动;
- Redis缓存采集结果,缓存键格式:sel:search:{平台}:{关键词}:{页码},TTL=24小时;
- 采集失败时,标记为"部分失败",不影响整体任务执行,保证核心数据可用。
3.2****机会评分算法(量化选品潜力,核心亮点)
选品的核心是"判断该不该做",我们设计了五维加权评分模型(满分100分),用量化数据替代经验判断,确保选品的科学性。
评分模型(权重贴合电商卖家核心需求):
|-------|-----|--------|-------------------------|
| 维度 | 权重 | 衡量指标 | 计算逻辑 |
| 销量表现 | 30% | 市场验证程度 | 平台同类商品月销量归一化(0-100分) |
| 利润空间 | 25% | 盈利能力 | (售价-供应价)/售价 × 100,归一化处理 |
| 口碑评价 | 15% | 用户认可度 | 商品评分×评价数量占比,归一化处理 |
| 价格竞争力 | 15% | 价格优势 | 低于同类商品均价越多,分数越高 |
| 商品评分 | 15% | 品质保障 | 商品基础评分(0-5分)归一化至0-100分 |
评分计算公式(可直接复用):
\text{Opportunity Score} = 0.30 \times S_{sales} + 0.25 \times S_{margin} + 0.15 \times S_{reviews} + 0.15 \times S_{price} + 0.15 \times S_{rating} 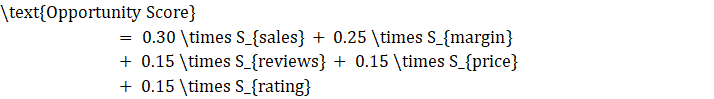
核心逻辑:销量和利润权重最高,贴合电商卖家"卖得动、赚得到"的核心需求,其他指标辅助验证商品潜力。
3.3 DeepSeek****大模型集成( AI 增强,提升效率)
核心设计原则:AI增强但不依赖,数值计算(价格、销量、评分)由代码确定性完成,LLM只负责语言理解和洞察生成,避免LLM做数学题导致的错误。
LLM调用场景与参数调优(实战关键,避免冗余消耗):
|---------|-------------|------------------------|--------------------|
| 应用场景 | Temperature | 调优理由 | 输出格式 |
| 报告市场概述 | 0.3 | 低随机性,保证事实准确,贴合数据趋势 | ≤200字,简洁明了的趋势总结 |
| 商品推荐理由 | 0.3 | 结构化输出,贴合商品数据,不夸大 | JSON格式,包含核心优势、风险提示 |
| 对话式选品助手 | 0.7 | 适度发散,提升对话自然度,贴合用户口语化需求 | 自然语言+嵌入式JSON(意图识别) |
关键代码(DeepSeek API调用,兼容OpenAI格式):
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python import requests import json class DeepSeekService: def init(self, api_key): self.api_key = api_key self.base_url = "https://api.deepseek.com/v1/chat/completions" async def generate_report_summary(self, market_data): """生成报告市场概述,低随机性""" prompt = f"""基于以下市场数据,生成≤200字的市场概述,重点说明品类热度、价格分布、销量趋势: {json.dumps(market_data, ensure_ascii=False)} 要求:客观、简洁,基于数据,不添加主观猜测,语言专业。""" response = requests.post( self.base_url, headers={ "Content-Type": "application/json", "Authorization": f"Bearer {self.api_key}" }, json={ "model": "deepseek-chat", "messages": {"role": "user", "content": prompt}, "temperature": 0.3, "max_tokens": 200 } ) return response.json()"choices"0"message""content" |
3.4****对话式选品助手(提升用户体验,降低门槛)
核心设计:打破"填表单→看报告"的传统模式,支持自然语言交互,用户聊一聊就能完成选品任务,适配非技术背景的电商卖家。
意图识别机制:LLM回复中嵌入结构化JSON数据,系统自动解析,渲染快捷操作按钮,实现"对话→执行"零门槛。
示例(用户与AI交互流程):
用户:最近蓝牙耳机市场怎么样?想找50-200块的
AI助手:蓝牙耳机当前市场热度较高,阿里指数近7天环比上涨12%,价格集中在80-150元,销量top10以降噪款为主...建议分析价格区间50-200元的蓝牙耳机一键创建选品任务
(系统自动解析AI回复中的JSON意图,渲染"一键创建任务"按钮,用户点击即可触发选品流程)
意图识别JSON格式(可直接复用解析逻辑):
|------------------------------------------------------------------------------------------------------|
| json { "intent": "create_task", "params": { "keyword": "蓝牙耳机", "price_min": 50, "price_max": 200 } } |
四、系统整体架构与任务执行流程
4.1****整体架构(分层设计,便于扩展)
采用经典分层架构,融入AI能力,各层职责清晰,便于后续扩展(如新增电商平台、优化算法):
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| plain text ┌──────────────────────────────────────────────────────────┐ │ 前端 (Vue.js + Element Plus) │ └───────────────────────────┬──────────────────────────────┘ │ HTTPS + JWT Bearer Token ┌───────────────────────────▼──────────────────────────────┐ │ API 层 (FastAPI / ASGI) │ │ 任务管理 · 报告查询 · 对话交互 · 管理 │ └───────────────────────────┬──────────────────────────────┘ │ ┌───────────────────────────▼──────────────────────────────┐ │ 服务编排层 │ │ SelectionService ──► DataService ──► ReportService │ │ SelectionChatService TrendDataService │ └──────────┬───────────────────────────────┬───────────────┘ │ │ ┌──────────▼───────────┐ ┌──────────────▼───────────────┐ │ 数据采集层 │ │ AI / LLM 层 │ │ OneBound API 客户端 │ │ DeepSeek (报告/对话/提取) │ │ Crawl4AI 趋势爬虫 │ │ Crawl4AI + LLM 策略 │ └──────────┬───────────┘ └──────────────┬───────────────┘ │ │ ┌──────────▼───────────────────────────────▼───────────────┐ │ 数据存储层 │ │ MySQL (异步 SQLAlchemy) + Redis (缓存) │ └──────────────────────────────────────────────────────────┘ |
4.2****任务执行全流程(异步设计,用户无等待)
用户输入关键词创建任务后,系统后台异步执行4个阶段,接口毫秒级返回,前端通过轮询获取进度,不影响用户操作:
- 阶段1:数据采集------抓取4大平台商品数据+百度/阿里指数,归一化后写入数据库;
- 阶段2:数据分析------计算商品利润率、机会评分,完成Top10潜力品排序;
- 阶段3:报告生成------代码计算数值部分,LLM生成市场概述和推荐理由,整合为完整报告;
- 阶段4:任务完成------报告入库,前端轮询获取结果,支持导出和查看详情。
异步任务核心代码(FastAPI BackgroundTasks):
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python from fastapi import APIRouter, BackgroundTasks from sqlalchemy.ext.asyncio import AsyncSession router = APIRouter(prefix="/seller/api/selection") @router.post("/task/create") async def create_task( keyword: str, price_min: float = 0, price_max: float = 10000, background_tasks: BackgroundTasks, db: AsyncSession ): # 1. 创建任务记录,状态设为"排队中" task = await selection_service.create_task( keyword=keyword, price_min=price_min, price_max=price_max, db=db ) # 2. 后台异步执行选品任务,不阻塞接口返回 background_tasks.add_task(selection_service.execute_task, task.id, db) # 3. 立即返回任务信息,前端轮询查询状态 return {"code": 200, "data": task, "msg": "任务已创建,正在执行"} |
五、工程实践与避坑指南(实战重点)
5.1****为什么不用 Celery ?(按需选择,避免过度设计)
产品早期选择FastAPI BackgroundTasks而非Celery,核心原因是"简化部署、降低成本",具体对比:
|--------|------------------------------|----------------------------------------|
| 对比项 | BackgroundTasks | Celery |
| 部署复杂度 | 零额外基础设施,直接集成在FastAPI中 | 需部署Broker(Redis/RabbitMQ)+ Worker,复杂度高 |
| 适用场景 | 中低并发、单实例部署,适合产品早期 | 高并发、分布式部署,适合业务量爆发后 |
| 代码迁移成本 | 低,后续可直接替换为Celery(只需修改任务调用方式) | 高,需提前设计任务队列、持久化等逻辑 |
避坑建议:产品早期无需追求"分布式",优先实现核心功能,等用户量、任务量增长后,再迁移到Celery即可。
5.2 LLM****调用容错设计(避免系统崩溃)
大模型调用存在不确定性(如网络波动、API限流),核心容错策略:
- 核心数据与AI生成数据分离:数值分析部分(价格、销量、评分)由代码计算,确保永远正确;
- LLM调用非阻塞:即使LLM调用失败,报告核心数据依然完整,仅缺失市场概述和推荐理由;
- 重试机制:LLM调用失败后,自动重试2次,避免偶发故障导致的体验下降。
5.3****多租户安全隔离(面向多卖家场景)
系统面向多个电商卖家,安全隔离是底线,核心实现:
- JWT身份认证:每个请求携带JWT令牌,解析出shop_id,所有数据库查询自动附加WHERE shop_id = ?;
- 数据隔离:任务、报告、对话记录均绑定shop_id,卖家只能查看自己的相关数据;
- 敏感数据脱敏:1688供应商名称、联系方式等敏感信息自动脱敏,保护供应商隐私。
六、总结与未来演进
这套AI智能选品系统的核心设计哲学:数据驱动(保证底线)、AI增强(提升效率)、异步优先(优化体验)、安全隔离(保障可靠),完美解决传统选品的痛点,可直接落地用于电商卖家选品决策。
未来演进方向(可按需扩展):
- Phase 2:引入Celery+WebSocket,实现分布式任务和实时状态推送,替代前端轮询;
- Phase 3:新增抖音电商、Shopee等平台,支持定时选品,自动监控品类变化;
- Phase 4:开发选品Agent,基于历史数据学习,实现自动化选品决策,进一步降低用户操作门槛。
对于想入门AI+电商、FastAPI异步开发、LLM应用落地的开发者,本文提供了完整的实战思路和代码片段,可直接复用核心模块,快速搭建自己的选品系统。如果有疑问,欢迎在评论区交流探讨!
关键词:AI选品系统;FastAPI;DeepSeek;多平台数据采集;电商选品;LLM应用落地
作者:Maris5188