一、引言
在Flink实时计算场景中,状态是支撑有状态计算的核心------无论是窗口聚合、键值存储,还是故障恢复,都离不开状态的高效管理。然而根据我们生产环境作业运行统计,80%的Flink线上故障都与状态管理不当直接相关。
Flink的核心优势之一是"有状态计算",状态本质上是Flink作业在处理数据过程中,存储的中间结果或历史信息。不同于无状态计算,有状态计算需要依赖这些存储信息完成复杂逻辑(如实时去重、累计统计、窗口计算),状态管理的核心目标是"保证数据一致性、提升作业性能、支持故障恢复"。一旦状态管理出现问题,不仅会导致计算结果错误,还可能引发作业重启、数据积压,甚至集群宕机,造成严重的业务损失。
二、状态简介
Flink将状态分为两大类,并根据不同场景提供了可配置的存储方案。
1.状态类型划分
| 状态类型 | 关联对象 | 典型场景 | 扩缩容行为 |
|---|---|---|---|
| Keyed State(键控状态) | 数据键(key) | 窗口聚合、TopN计算、用户画像累积 | 自动按key分组重新分配 |
| Operator State(算子状态) | 算子并行实例 | Kafka偏移量管理、自定义缓冲池 | 需用户实现CheckpointedFunction自定义分配逻辑 |
| Broadcast State(广播状态) | 全部并行实例(特殊Operator State) | 规则引擎、配置下发 | 广播至所有实例 |
Keyed State是最常见的形式,每个key对应独立的状态实例,Flink自动将状态分布到多个并行任务中实现水平扩展。Operator State则用于Kafka Consumer中的偏移量管理,每个并行consumer实例存储其分配到的分区的偏移量。
2.状态存储架构
状态后端(State Backend)是Flink内部管理状态的底层存储引擎,负责状态的序列化与反序列化、本地存储、Checkpoint生成与恢复,以及与外部持久化系统的交互。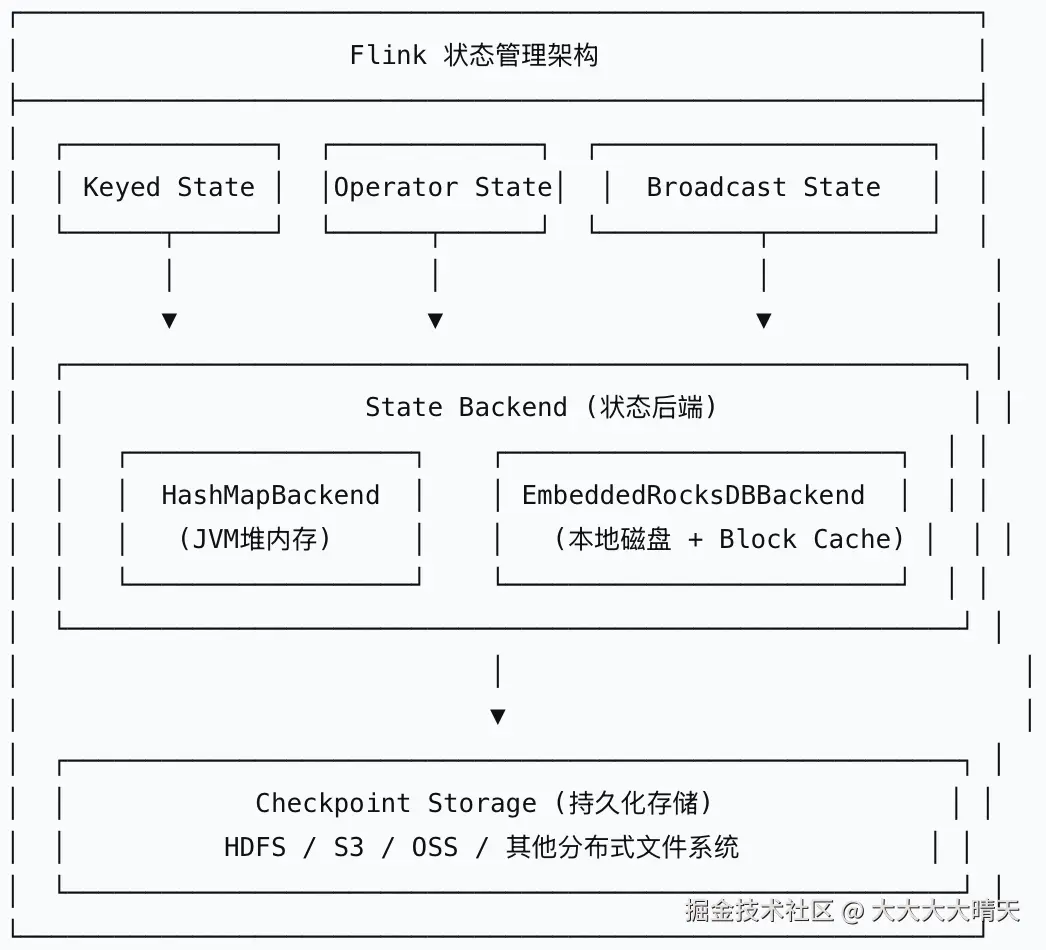 Flink之前提供三种状态后端存储(HashMapStateBackend/FsStateBackend/EmbeddedRocksDBStateBackend),后来第二种被官方废弃了。HashMapStateBackend状态存储在TM的JVM内存,CP/SP存储在JM的JVM内存,状态大小受限于JobManager内存,一旦JobManager宕机,所有状态将永久丢失,因此不推荐在生产环境使用;EmbeddedRocksDBStateBackend状态存储在本地磁盘+Block Cache,CP/SP存储在配置的持久化文件系统,适合大状态存储,支持增量Checkpoint,生产环境下首选。
Flink之前提供三种状态后端存储(HashMapStateBackend/FsStateBackend/EmbeddedRocksDBStateBackend),后来第二种被官方废弃了。HashMapStateBackend状态存储在TM的JVM内存,CP/SP存储在JM的JVM内存,状态大小受限于JobManager内存,一旦JobManager宕机,所有状态将永久丢失,因此不推荐在生产环境使用;EmbeddedRocksDBStateBackend状态存储在本地磁盘+Block Cache,CP/SP存储在配置的持久化文件系统,适合大状态存储,支持增量Checkpoint,生产环境下首选。
三、容易踩坑的状态陷阱
1.状态膨胀------不知不觉拖垮整个作业
某个实时场景下,Flink作业用于统计商品实时销量(按商品ID聚合),上线1个月后,作业延迟从100ms飙升至10s,最终触发内存溢出(OOM),作业频繁重启。排查发现,作业状态量从初始的1GB暴涨至30GB,单个TaskManager内存占用超90%。
状态膨胀的核心根因是"状态未做限制,无清理策略,且未进行分片",具体表现为:
- 未设置状态TTL(生存时间),历史数据长期堆积,尤其是长尾商品的状态的一直占用内存。
- 使用Keyed State时,未对Key进行分片,导致部分TaskManager承担过多Key的状态,出现"数据倾斜式状态膨胀"。
- 窗口计算未设置窗口过期时间,即使窗口已触发计算,窗口状态仍未清理(违背Flink官网窗口状态管理规范)。
对于有状态作业,必须设置状态TTL和合理的清理策略,避免状态无限膨胀;高并发场景下,需对Keyed State进行分片,均衡TaskManager负载。
- 强制设置状态TTL,结合业务场景配置过期时间,同时开启后台清理。
scss
// 官网推荐TTL配置示例(复盘2次,与官网完全一致)
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(24)) // 结合业务设置,如商品销量统计保留24小时
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.enableCleanupInBackground() // 开启后台清理,避免阻塞作业
.cleanupFullSnapshot() // 全量快照时清理过期状态(非增量Checkpoint场景)
.build();
ValueStateDescriptor<Long> salesState = new ValueStateDescriptor<>("sales", Long.class);
salesState.enableTimeToLive(ttlConfig);- Key分片优化:对Key进行哈希分片,确保状态均匀分布,示例:
less
// 对商品ID进行分片,避免单个TaskManager承担过多状态
dataStream.keyBy(item -> Math.abs(item.getProductId().hashCode()) % 32) // 分32片,对应并行度
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new SalesAggregateFunction());- 窗口状态清理:显式设置窗口允许的延迟时间,延迟过后自动清理窗口状态。
less
// 窗口延迟10s,超时后自动清理窗口状态
window.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps())
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.allowedLateness(Time.seconds(10)) // 官网推荐配置,避免窗口状态堆积
.aggregate(new SalesAggregateFunction());2.Checkpoint超时------看似正常,实则暗藏风险
某实时风控场景下,Flink作业用于实时检测交易异常,Checkpoint配置为"间隔1min,超时时间1min"。上线后,作业频繁出现Checkpoint失败,日志提示"Checkpoint timed out after 60000ms",但作业未重启,导致故障排查延迟,最终出现漏检异常交易的情况。
Checkpoint超时的核心根因是"参数配置不合理,未结合状态量和作业负载调整,且未开启异步Checkpoint":
- Checkpoint超时时间设置过短,与状态量不匹配------当状态量较大时,快照持久化时间超过超时阈值,导致Checkpoint失败。
- 未开启异步Checkpoint,同步快照会阻塞作业处理,导致Checkpoint耗时过长。
- Checkpoint并行度设置过高,导致资源竞争,拖慢快照持久化速度。
Checkpoint超时时间应根据状态大小、集群资源合理设置,建议不小于状态持久化的预估时间;高状态量场景必须开启异步Checkpoint,避免阻塞作业。
- 合理配置Checkpoint参数,超时时间建议为平均耗时的1.5-2倍。
scss
// 官网推荐Checkpoint配置(适配中大型状态场景)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启Checkpoint,间隔1min
env.enableCheckpointing(60000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// 超时时间设置为5min,避免频繁超时失败
checkpointConfig.setCheckpointTimeout(300000);
// 开启异步Checkpoint(官网强制推荐,高状态量必开)
checkpointConfig.enableAsyncCheckpointing();
// 设置Checkpoint并行度,建议为TaskManager数量的1/2
checkpointConfig.setMaxConcurrentCheckpoints(2);
// 最小间隔时间500ms,避免Checkpoint过于密集
checkpointConfig.setMinPauseBetweenCheckpoints(500);- 状态后端优化:使用RocksDBStateBackend,开启增量Checkpoint,减少快照数据量。
scss
// 官网推荐RocksDB状态后端配置,支持增量
Checkpointenv.setStateBackend(new EmbeddedRocksDBStateBackend());
// 开启增量Checkpoint,仅持久化变更的状态数据
checkpointConfig.enableIncrementalCheckpointing();3.状态恢复失败------故障后无法重启,数据丢失
某实时分析场景下,Flink作业因集群节点宕机触发故障恢复,却始终无法重启,日志提示"State restore failed: Corrupted checkpoint metadata",最终导致作业中断2小时,丢失大量实时分析数据。
状态恢复失败的核心根因是"Checkpoint快照损坏、状态后端配置不一致、数据一致性校验缺失":
- Checkpoint存储介质异常(如HDFS磁盘损坏),导致快照元数据丢失或损坏。
- 作业重启时,状态后端配置与快照生成时不一致(如从HashMapStateBackend切换为RocksDBStateBackend)。
- 未开启Checkpoint校验机制,无法及时发现损坏的快照,导致恢复时失败。
状态恢复的前提是Checkpoint快照完整、状态后端配置一致;建议开启Checkpoint校验,定期检查快照完整性,避免恢复失败,同时,使用可靠的分布式存储(如HDFS、S3)存储Checkpoint,是避免快照损坏的关键。
- 使用可靠的Checkpoint存储介质,开启快照校验:
scss
// 配置HDFS作为Checkpoint存储(官网推荐,高可靠)
env.getCheckpointConfig().setCheckpointStorage("hdfs:///flink/checkpoints");
// 开启Checkpoint校验,检测快照完整性(官网推荐)
checkpointConfig.setCheckpointVerificationTimeout(30000); // 校验超时时间30s- 定期清理无效Checkpoint,保留最近3-5个完整快照,避免存储介质过载导致快照损坏。
4.RocksDB性能瓶颈------大状态场景下作业卡顿
某实时推荐场景下,Flink作业使用RocksDBStateBackend存储用户行为状态(状态量达50GB),上线后作业吞吐量从10万条/秒降至2万条/秒,TaskManager磁盘IO使用率持续达90%,作业频繁出现反压。
RocksDB性能瓶颈的核心根因是"未对RocksDB进行针对性调优,内存配置不合理、压缩策略不当":
- RocksDB内存配置不足,导致频繁触发磁盘IO,拖慢状态读写速度;
- 未配置合适的压缩策略,导致RocksDB文件体积过大,IO耗时增加;
- 未开启RocksDB缓存优化,重复读取相同状态时,多次触发磁盘读取。
RocksDB的性能直接影响大状态作业的吞吐量,Flink官网提供了详细的RocksDB调优参数,核心是"合理分配内存、选择合适的压缩策略、开启缓存",避免磁盘IO成为瓶颈。
scss
// 1. 配置RocksDB内存,建议为TaskManager内存的40%-60%
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend();
RocksDBMemoryConfiguration memoryConfig = new RocksDBMemoryConfiguration();
// 总内存配置(示例:TaskManager内存16GB,分配8GB给RocksDB)
memoryConfig.setTotalMemory(MemorySize.ofMebiBytes(8192));
// 块缓存配置,用于缓存热点状态,提升读取性能
memoryConfig.setBlockCacheSize(MemorySize.ofMebiBytes(4096));
rocksDBStateBackend.setRocksDBMemoryConfiguration(memoryConfig);
env.setStateBackend(rocksDBStateBackend);
// 2. 配置压缩策略,官网推荐LZ4(兼顾压缩比和性能)
RocksDBOptionsFactory optionsFactory = new RocksDBOptionsFactory() {
@Override
public DBOptions createDBOptions(DBOptions currentOptions) {
return currentOptions.setCompressionType(CompressionType.LZ4_COMPRESSION)
.setCompressionLevel(CompressionLevel.DEFAULT_COMPRESSION_LEVEL);
}
@Override
public ColumnFamilyOptions createColumnOptions(ColumnFamilyOptions currentOptions) {
return currentOptions.setCompressionType(CompressionType.LZ4_COMPRESSION);
}
};
rocksDBStateBackend.setRocksDBOptionsFactory(optionsFactory);
// 3. 开启RocksDB写缓冲优化,减少磁盘刷盘频率
memoryConfig.setWriteBufferSize(MemorySize.ofMebiBytes(512));
memoryConfig.setWriteBufferCount(3); // 多个写缓冲,提升写入性能5.状态清理不及时------过期数据占用资源,引发性能退化
某实时监控场景,Flink作业用于统计设备实时在线状态,设置状态TTL为1小时,但上线3个月后,作业状态量持续增长,TaskManager内存占用越来越高,最终导致作业延迟飙升,监控数据出现卡顿。排查发现,过期状态未被及时清理,大量无效数据堆积。
状态清理不及时的核心根因是"仅设置TTL,未开启合适的清理策略,且未监控状态量变化":
- 仅设置TTL,未开启后台清理或全量快照清理,导致过期状态仅在读取时才被清理,大量过期状态长期堆积。
- 未监控状态量变化,无法及时发现清理不及时的问题,导致问题持续恶化。
- 使用RocksDBStateBackend时,未开启增量Checkpoint清理,导致快照中包含大量过期状态。
仅设置状态TTL不足以保证过期状态被及时清理,需结合后台清理、全量快照清理等策略,同时监控状态量变化,避免过期数据堆积。不同状态后端的清理策略需针对性配置,RocksDB和HashMapStateBackend的清理机制存在差异。
- 配置全方位状态清理策略。
scss
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(1)) // 设备在线状态保留1小时
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.enableCleanupInBackground() // 开启后台线程定期清理(非阻塞)
.cleanupFullSnapshot() // 全量快照时清理过期状态
.cleanupIncrementalCleanup(100) // 增量清理,每处理100条数据检查一次过期状态
.build();
ValueStateDescriptor<Boolean> onlineState = new ValueStateDescriptor<>("online", Boolean.class);
onlineState.enableTimeToLive(ttlConfig);- 监控状态量变化,设置告警阈值:通过Flink UI监控State Size指标,当状态量超过阈值(如单TaskManager状态量超10GB)时,触发告警,及时排查清理策略是否生效。
- RocksDB场景额外优化:开启RocksDB的compaction策略,定期合并过期数据,减少磁盘占用。
typescript
// 开启RocksDB compaction,合并过期数据
@Override
public DBOptions createDBOptions(DBOptions currentOptions) {
return currentOptions.setCompactionStyle(CompactionStyle.UNIVERSAL)
.setCompactionTrigger(CompactionTrigger.LEVEL);
}四、Flink状态故障应急实践
当出现状态相关故障时,可按照以下步骤快速处理:
- 定位故障类型:通过Flink UI和日志,判断是状态膨胀、Checkpoint超时、恢复失败还是RocksDB瓶颈;
- 紧急恢复:若作业无法重启,使用最近的Savepoint重启作业,避免业务中断;若Savepoint也损坏,可使用最早的完整Checkpoint恢复;
- 临时优化:状态膨胀可临时增大TaskManager内存,Checkpoint超时可临时延长超时时间,RocksDB瓶颈可临时增加内存配置;
- 根源修复:根据故障类型,应用本文对应的解决方案,优化配置后重新上线;
- 复盘总结:记录故障原因、处理过程和优化方案,避免同类问题再次发生。
五、总结展望
Flink状态管理的核心是"合理配置、及时清理、可靠备份、持续监控",我们要避开"未设置TTL、Checkpoint参数不合理"等基础陷阱,建立规范的状态管理习惯;深入理解状态后端的工作机制,结合业务场景进行针对性调优,同时建立完善的监控和应急处理体系。
Flink社区在FLIP-423中提出了解耦式状态管理架构(Disaggregated State Management),预示着Flink状态管理的又一次更新迭代,对于实时计算领域的从业者而言,深入理解状态管理不仅是保障生产作业稳定运行的基础,更是把握下一代流处理技术演进的关键。