前言 这篇文章是我在开发中经历了从 JDK 8 一路升级到 JDK 25 之后的技术总结。文章覆盖四个 LTS 版本------JDK 8(2014)、JDK 17(2021)、JDK 21(2023)、JDK 25(2025),横跨 11 年的 Java 演进历程。 我不打算列一堆 feature list 然后草草了事。每个版本我都会给出真实的代码示例、JVM 内部机制分析、GC 调优参数。如果你正在考虑版本升级,或者想深入理解 Java 平台这十年来到底发生了什么本质性的变化,这篇文章应该能帮到你。
一、版本定位与发布策略
先把四个版本的定位讲清楚:
| 版本 | 发布时间 | 类型 | 核心定位 |
|---|---|---|---|
| JDK 8 | 2014年3月 | LTS | 函数式编程引入,最后一个免费商用 Oracle JDK |
| JDK 17 | 2021年9月 | LTS | 许可证变更后首个免费 Oracle JDK,语言特性成熟期 |
| JDK 21 | 2023年9月 | LTS | Virtual Threads GA,并发模型革命 |
| JDK 25 | 2025年9月 | LTS | Compact Object Headers、Stable Values、Leyden 成果落地 |
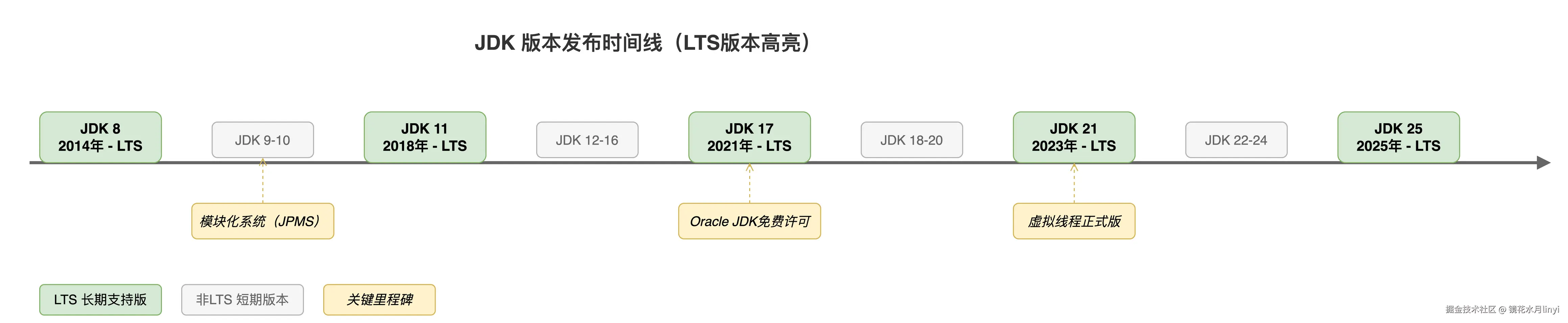 发布节奏的变化 是理解 Java 生态的关键:
发布节奏的变化 是理解 Java 生态的关键:
- JDK 8 之前:大版本之间间隔 2-3 年,功能堆积严重,延期是常态(JDK 9 跳票了三年)
- JDK 9 之后:切换到 6 个月一个版本的 train model,每年 3 月和 9 月发版
- LTS 节奏:最初是每 3 年一个 LTS(8 → 11 → 17),从 JDK 17 开始改为每 2 年(17 → 21 → 25)
这个策略变化直接影响了我们的技术选型。很多团队在 JDK 8 上停留了近十年,核心原因就是 JDK 9 到 JDK 16 期间没有 LTS 版本值得冒险升级。JDK 17 是第一个真正让大家觉得"该升了"的版本。
关于许可证问题说两句:JDK 8u211 之后,Oracle JDK 商用需要付费。JDK 17 开始 Oracle 恢复了 NFTC(No-Fee Terms and Conditions)许可,可以免费商用。但很多公司已经转向了 Adoptium(Eclipse Temurin)、Amazon Corretto、Azul Zulu 等发行版,这些发行版在各个版本上都是免费的。
二、语言特性演进
2.1 JDK 8:Lambda 与 Stream 的函数式革命
JDK 8 是 Java 历史上最重大的语言层面变革。它一次性引入了 Lambda、Stream、Optional、新日期 API 四个核心特性,直接改变了 Java 的编程范式。
Lambda 表达式和函数式接口
JDK 8 之前写一个线程排序:
java
// JDK 7 写法
List<String> names = Arrays.asList("Charlie", "Alice", "Bob");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String a, String b) {
return a.compareTo(b);
}
});JDK 8 之后:
java
// JDK 8 写法
List<String> names = Arrays.asList("Charlie", "Alice", "Bob");
names.sort(String::compareTo);Lambda 的底层实现值得了解:它不是匿名内部类的语法糖。编译器用 invokedynamic 指令在运行时通过 LambdaMetafactory 生成实现类,避免了匿名内部类在编译期生成大量 .class 文件的问题。你可以用 javap -c -p 看到这个区别:
arduino
// 匿名内部类: 生成 MyClass$1.class
// Lambda: 编译后是 invokedynamic 指令
0: invokedynamic #2, 0 // InvokeDynamic #0:compare:()Ljava/util/Comparator;Stream API
Stream 的核心设计是惰性求值(lazy evaluation)。中间操作(filter、map、flatMap)不会立即执行,只有终端操作(collect、forEach、reduce)触发时才会一次性处理整个管道:
java
// 实际业务场景:从订单列表中提取高价值客户的邮箱
List<String> vipEmails = orders.stream()
.filter(o -> o.getAmount().compareTo(new BigDecimal("10000")) > 0)
.map(Order::getCustomer)
.filter(c -> c.getVipLevel() >= 3)
.map(Customer::getEmail)
.distinct()
.sorted()
.collect(Collectors.toList());关于 parallel stream,我的建议是:在 Web 应用中极少使用它。parallel stream 底层使用 ForkJoinPool.commonPool(),这个线程池是全局共享的。如果你在一个 HTTP 请求处理中使用 parallel stream 处理一个耗时操作,会影响其他请求中 parallel stream 的执行。我们曾因此在生产环境遇到过接口超时。

上图展示了 Stream 管道的完整处理流程------从数据源到中间操作(惰性)再到终端操作(触发执行),以及 parallel stream 的 Fork-Join 分治模型。
Optional
java
// 链式处理可能为 null 的值
String cityName = Optional.ofNullable(user)
.map(User::getAddress)
.map(Address::getCity)
.map(City::getName)
.orElse("Unknown");java.time API
终于替掉了灾难般的 java.util.Date 和 Calendar:
java
// JDK 8 日期处理
LocalDateTime now = LocalDateTime.now();
LocalDateTime meetingTime = now.plusHours(2).withMinute(0).withSecond(0);
Duration duration = Duration.between(now, meetingTime);
System.out.println("距离会议还有: " + duration.toMinutes() + " 分钟");
// 时区处理
ZonedDateTime shanghaiTime = ZonedDateTime.now(ZoneId.of("Asia/Shanghai"));
ZonedDateTime newYorkTime = shanghaiTime.withZoneSameInstant(ZoneId.of("America/New_York"));2.2 JDK 9-16 的关键过渡特性
这一段很多人会直接跳过,但实际上 JDK 9-16 的过渡特性在后续 LTS 版本中全部转正了。不了解它们的演化过程,你用 JDK 17/21 的时候会觉得这些特性"凭空冒出来"。
JDK 9:模块系统(Project Jigsaw)
java
// module-info.java
module com.myapp.core {
requires java.sql;
requires java.logging;
exports com.myapp.core.api;
opens com.myapp.core.model to com.fasterxml.jackson.databind;
}JDK 9 还引入了集合工厂方法、JShell、接口私有方法:
java
// 不可变集合(JDK 9)
List<String> list = List.of("a", "b", "c");
Map<String, Integer> map = Map.of("key1", 1, "key2", 2);
// 接口私有方法
public interface Validator {
default boolean isValid(String input) {
return !isEmpty(input) && checkFormat(input);
}
private boolean isEmpty(String input) {
return input == null || input.isBlank();
}
private boolean checkFormat(String input) {
return input.matches("[a-zA-Z]+");
}
}JDK 10:局部变量类型推断(var)
java
// var 不是动态类型,是编译期类型推断
var userList = new ArrayList<User>(); // 推断为 ArrayList<User>
var stream = userList.stream(); // 推断为 Stream<User>
var result = Map.of("key", List.of(1, 2)); // 推断为 Map<String, List<Integer>>JDK 11:String 增强、HttpClient 标准化
java
// String 新方法
" hello ".strip(); // "hello" (Unicode 感知的 trim)
"hello".repeat(3); // "hellohellohello"
"line1\nline2\n".lines() // Stream<String>
.forEach(System.out::println);
"".isBlank(); // true
// 单文件执行
// $ java HelloWorld.java (不再需要先 javac)JDK 14:Records(预览)、instanceof 模式匹配(预览)
java
// Record: 不可变数据载体
record Point(int x, int y) {}
// helpful NPE messages(JDK 14 正式特性)
// 之前: NullPointerException
// 之后: Cannot invoke "String.length()" because "a.b.name" is nullJDK 15:Text Blocks
java
String json = """
{
"name": "张三",
"age": 28,
"roles": ["admin", "user"]
}
""";2.3 JDK 17:语言特性的成熟期
JDK 17 把 JDK 14-16 期间预览的特性全部转正,形成了一个完整的"现代 Java"特性集。
 Sealed Classes(JEP 409)
Sealed Classes(JEP 409)
Sealed classes 限定了一个类的子类范围,配合 pattern matching 使用时,编译器可以做穷举检查:
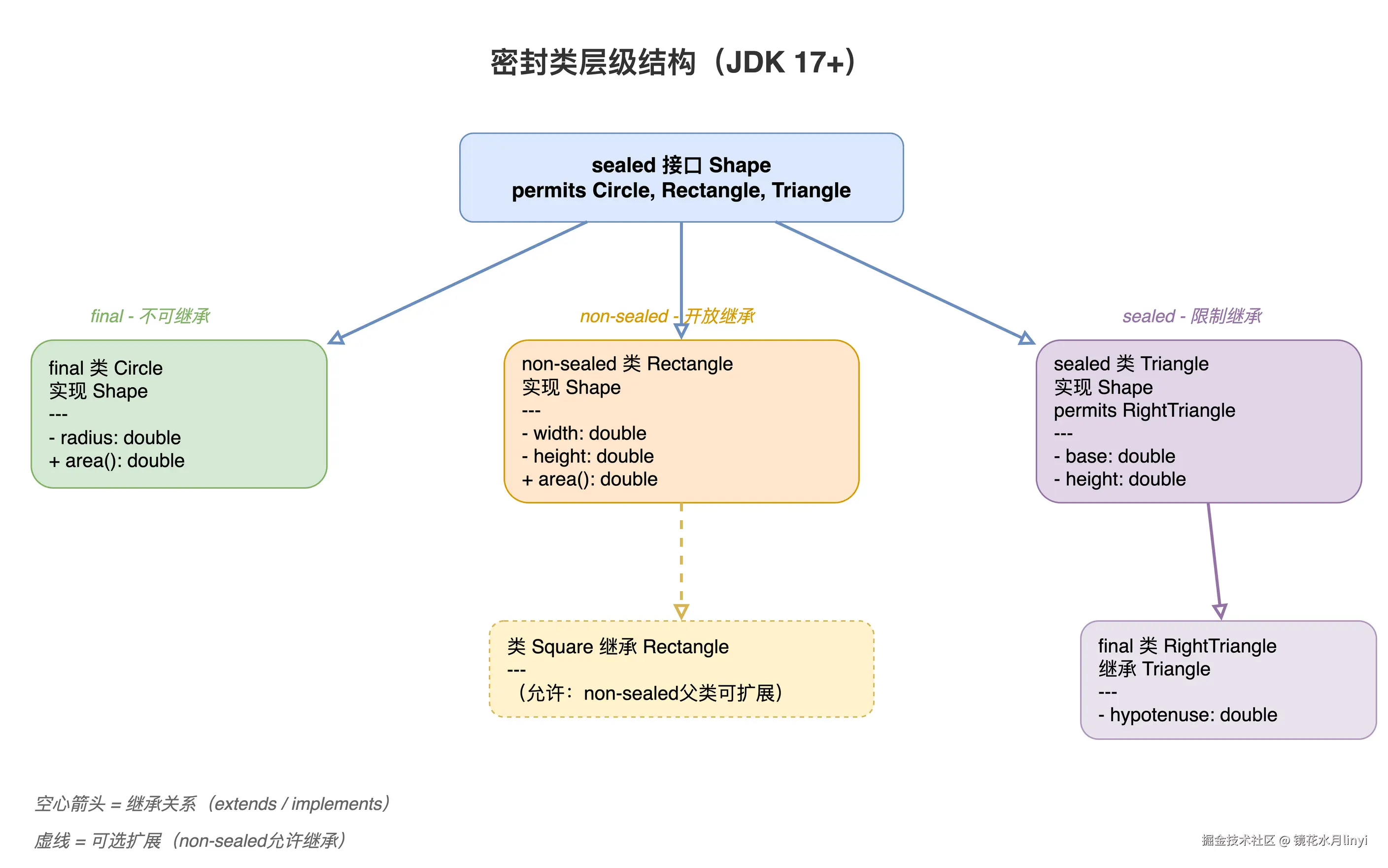 上图展示了 Sealed Classes 的继承约束------sealed 接口只允许指定的子类实现,final 子类不能再被继承,non-sealed 子类则开放扩展。
上图展示了 Sealed Classes 的继承约束------sealed 接口只允许指定的子类实现,final 子类不能再被继承,non-sealed 子类则开放扩展。
java
// 定义一个密封的形状层级
public sealed interface Shape permits Circle, Rectangle, Triangle {
double area();
}
public record Circle(double radius) implements Shape {
public double area() { return Math.PI * radius * radius; }
}
public record Rectangle(double width, double height) implements Shape {
public double area() { return width * height; }
}
public record Triangle(double base, double height) implements Shape {
public double area() { return 0.5 * base * height; }
}Pattern Matching for instanceof(JEP 394)
java
// JDK 16 及之前的写法
if (obj instanceof String) {
String s = (String) obj;
System.out.println(s.length());
}
// JDK 17 写法
if (obj instanceof String s) {
System.out.println(s.length());
}
// 结合 sealed classes 使用
public static String describe(Shape shape) {
if (shape instanceof Circle c) {
return "Circle with radius " + c.radius();
} else if (shape instanceof Rectangle r) {
return "Rectangle " + r.width() + "x" + r.height();
} else if (shape instanceof Triangle t) {
return "Triangle with base " + t.base();
}
// sealed class 保证不会走到这里,但编译器在 if-else 中不会做穷举检查
// 需要 switch pattern matching(JDK 21)才能实现编译期穷举
throw new IllegalStateException();
}JDK 17 其他值得关注的变化:
- 移除了 AOT 编译器和 JIT 编译器的 Graal 接口(JEP 410)------这意味着如果要用 GraalVM,需要单独安装
- 强封装 JDK 内部 API(JEP 403)------
--illegal-access=permit不再生效 - 移除了 RMI Activation(JEP 407)
- 恢复始终严格的浮点语义(JEP 306)
2.4 JDK 18-20 的过渡
这三个非 LTS 版本为 JDK 21 的两个杀手级特性做了铺垫:
- JDK 18:默认字符编码改为 UTF-8(JEP 400),Simple Web Server(JEP 408)
- JDK 19:Virtual Threads 首次预览(JEP 425),Structured Concurrency 孵化(JEP 428)
- JDK 20:Scoped Values 孵化(JEP 429),Record Patterns 二次预览(JEP 432)
2.5 JDK 21:并发模型的革命
JDK 21 是继 JDK 8 之后 Java 平台最重大的一次变革。Virtual Threads 的正式发布,从根本上改变了 Java 的并发编程模型。
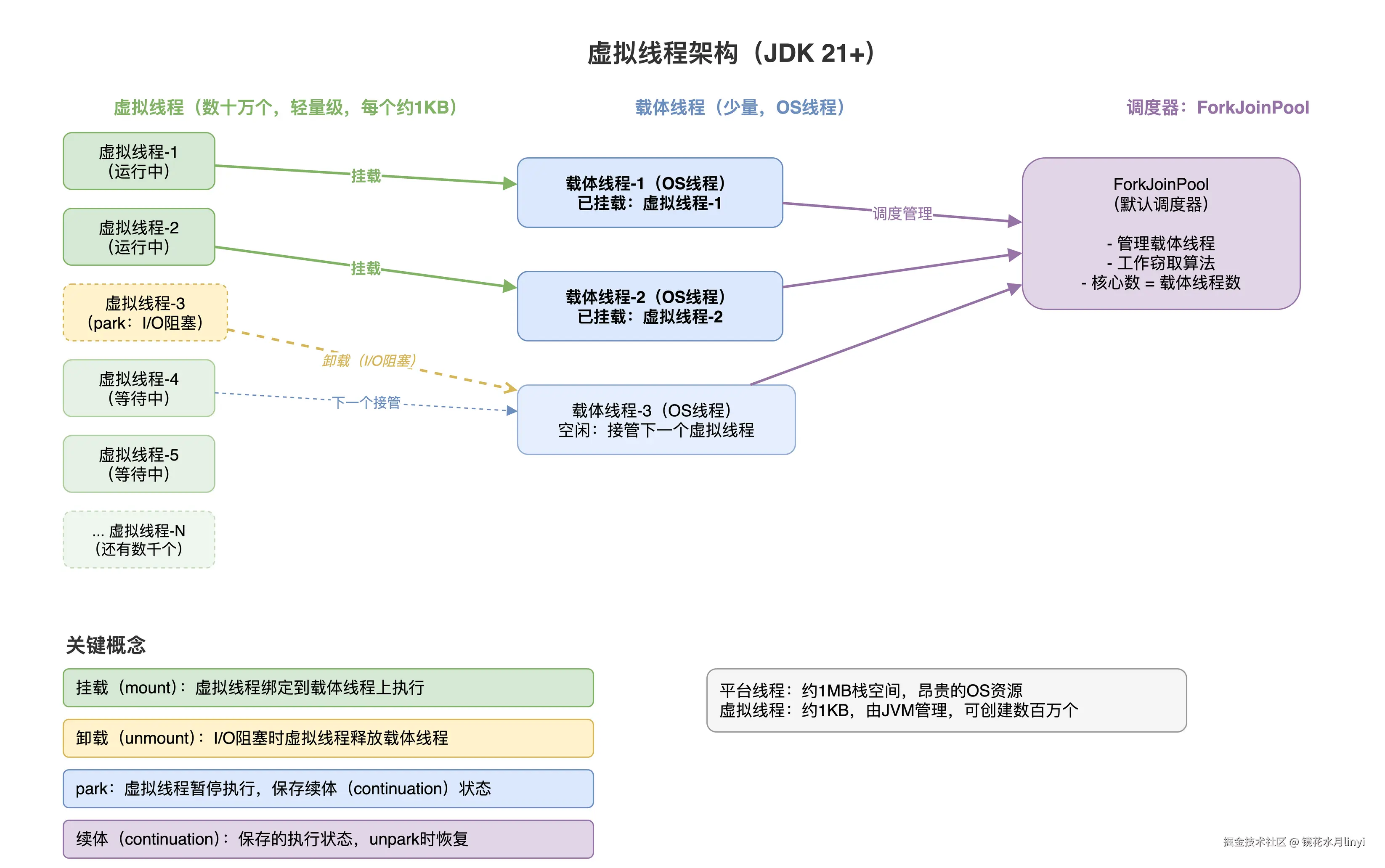 Virtual Threads(JEP 444)
Virtual Threads(JEP 444)
Virtual Thread 不是"轻量级线程"这么简单的描述能概括的。它的本质是将线程从操作系统资源变成了 JVM 管理的资源。
传统 Platform Thread 的问题:
- 每个线程占用约 1MB 栈内存(可配置,默认
-Xss1m) - 线程创建和销毁涉及系统调用(
pthread_create/pthread_exit) - 上下文切换成本高(内核态切换)
- 一个 JVM 进程能创建的线程数通常在几千到几万
Virtual Thread 的实现机制:
- 由 JVM 管理,不直接映射到 OS 线程
- 使用 Continuation 保存和恢复执行状态
- 在遇到阻塞操作时(I/O、sleep、锁等),自动从 carrier thread(载体线程)上卸载(unmount)
- 阻塞解除后,调度到任意可用的 carrier thread 上继续执行
- 栈空间按需增长,初始只有几百字节
java
// 创建 Virtual Thread 的三种方式
// 方式1:Thread.startVirtualThread
Thread vt = Thread.startVirtualThread(() -> {
System.out.println("Running in virtual thread: " + Thread.currentThread());
});
// 方式2:Thread.ofVirtual()
Thread vt2 = Thread.ofVirtual()
.name("my-vt-", 0)
.start(() -> doWork());
// 方式3:ExecutorService(推荐用于生产环境)
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
// 每个任务一个 virtual thread,不需要线程池
IntStream.range(0, 100_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
}性能对比:10 万个并发任务
java
public class VirtualThreadBenchmark {
static final int TASK_COUNT = 100_000;
public static void main(String[] args) throws Exception {
// Platform Threads(线程池限制 200 个线程)
long startPlatform = System.nanoTime();
try (var executor = Executors.newFixedThreadPool(200)) {
var futures = IntStream.range(0, TASK_COUNT)
.mapToObj(i -> executor.submit(() -> {
Thread.sleep(Duration.ofMillis(100));
return i;
}))
.toList();
for (var f : futures) f.get();
}
long platformTime = System.nanoTime() - startPlatform;
// Virtual Threads
long startVirtual = System.nanoTime();
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var futures = IntStream.range(0, TASK_COUNT)
.mapToObj(i -> executor.submit(() -> {
Thread.sleep(Duration.ofMillis(100));
return i;
}))
.toList();
for (var f : futures) f.get();
}
long virtualTime = System.nanoTime() - startVirtual;
System.out.printf("Platform Threads (200 pool): %.2f seconds%n",
platformTime / 1_000_000_000.0);
System.out.printf("Virtual Threads: %.2f seconds%n",
virtualTime / 1_000_000_000.0);
}
}
// 典型输出:
// Platform Threads (200 pool): 50.12 seconds
// Virtual Threads: 0.15 seconds这个差距的核心原因是:200 个 Platform Thread 执行 10 万个 100ms 的阻塞任务,最少需要 100000 / 200 * 0.1 = 50 秒。而 Virtual Threads 可以同时创建 10 万个线程,所有任务几乎同时开始 sleep,0.1 秒后几乎同时完成。 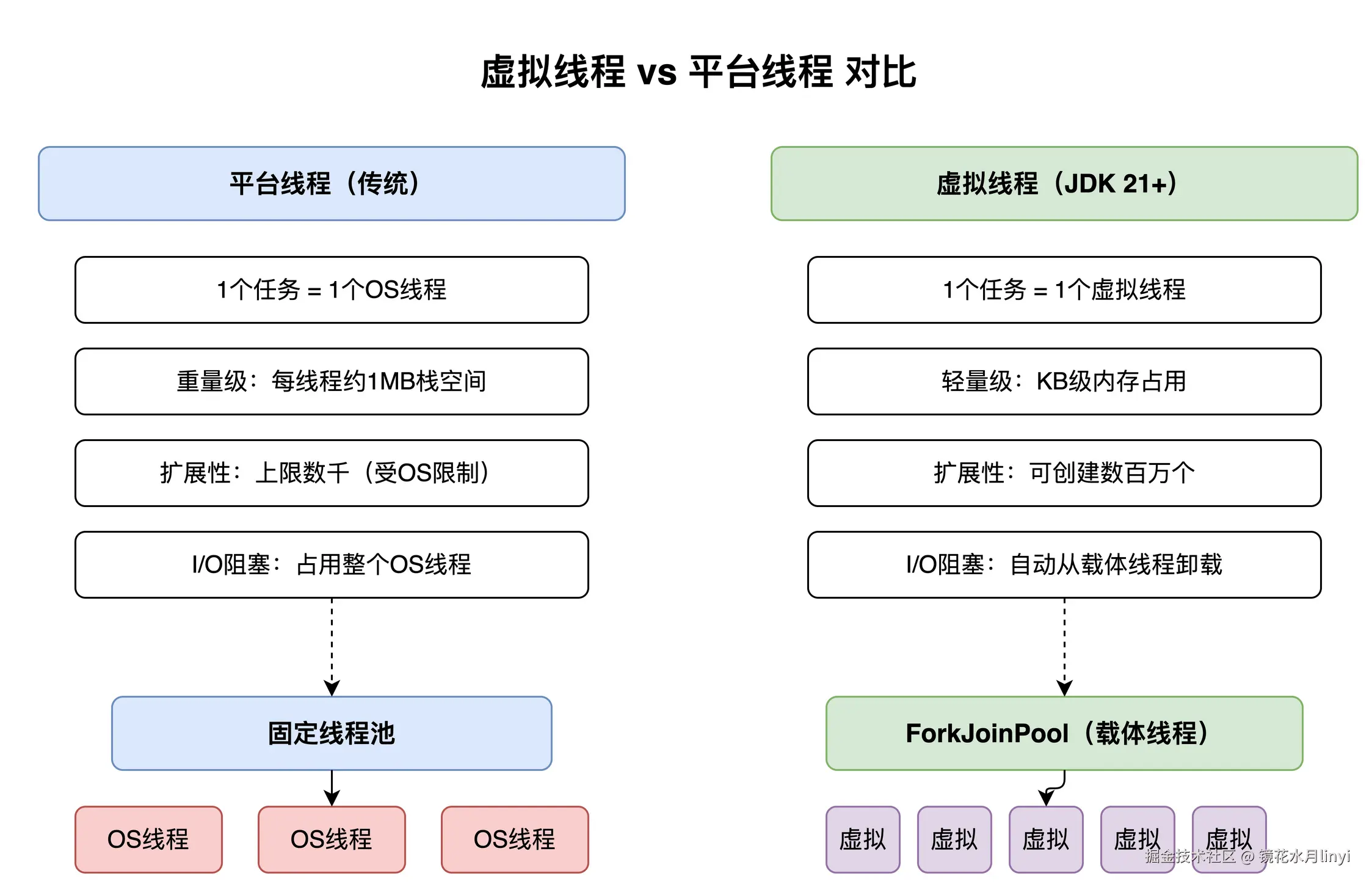 上图直观对比了平台线程和虚拟线程的核心差异------平台线程绑定 OS 线程(重量级,1MB 栈),虚拟线程由 JVM 调度(轻量级,KB 级),I/O 阻塞时自动从 carrier thread 卸载。
上图直观对比了平台线程和虚拟线程的核心差异------平台线程绑定 OS 线程(重量级,1MB 栈),虚拟线程由 JVM 调度(轻量级,KB 级),I/O 阻塞时自动从 carrier thread 卸载。
Virtual Threads 的坑
在生产环境中使用 Virtual Threads 需要注意以下问题:
- synchronized 块中的 I/O 操作会导致 pinning :Virtual Thread 在
synchronized块中执行阻塞操作时,无法从 carrier thread 上卸载。JDK 24 通过 JEP 491 解决了这个问题,但 JDK 21 中需要注意。
java
// JDK 21 中会导致 pinning(不推荐)
synchronized (lock) {
connection.read(); // Virtual thread 被 pin 到 carrier thread
}
// 推荐改用 ReentrantLock
private final ReentrantLock lock = new ReentrantLock();
lock.lock();
try {
connection.read(); // 不会 pinning
} finally {
lock.unlock();
}-
不要池化 Virtual Threads:Virtual Threads 的设计理念是 "one task, one thread"。用线程池管理 Virtual Threads 是反模式。
-
ThreadLocal 的内存问题:每个 Virtual Thread 都有自己的 ThreadLocal 副本。如果你创建了 100 万个 Virtual Thread,每个都持有 ThreadLocal 数据,内存开销会很大。JDK 21 引入了 Scoped Values(预览)作为替代方案。
Pattern Matching for switch(JEP 441)
java
// 结合 sealed classes,编译器做穷举检查
public static double calculateArea(Shape shape) {
return switch (shape) {
case Circle c -> Math.PI * c.radius() * c.radius();
case Rectangle r -> r.width() * r.height();
case Triangle t -> 0.5 * t.base() * t.height();
// 不需要 default,sealed interface 的所有子类都已覆盖
};
}
// 带 guard 的模式匹配
public static String classify(Shape shape) {
return switch (shape) {
case Circle c when c.radius() > 100 -> "大圆";
case Circle c -> "小圆";
case Rectangle r when r.width() == r.height() -> "正方形";
case Rectangle r -> "矩形";
case Triangle t -> "三角形";
};
}Record Patterns(JEP 440) 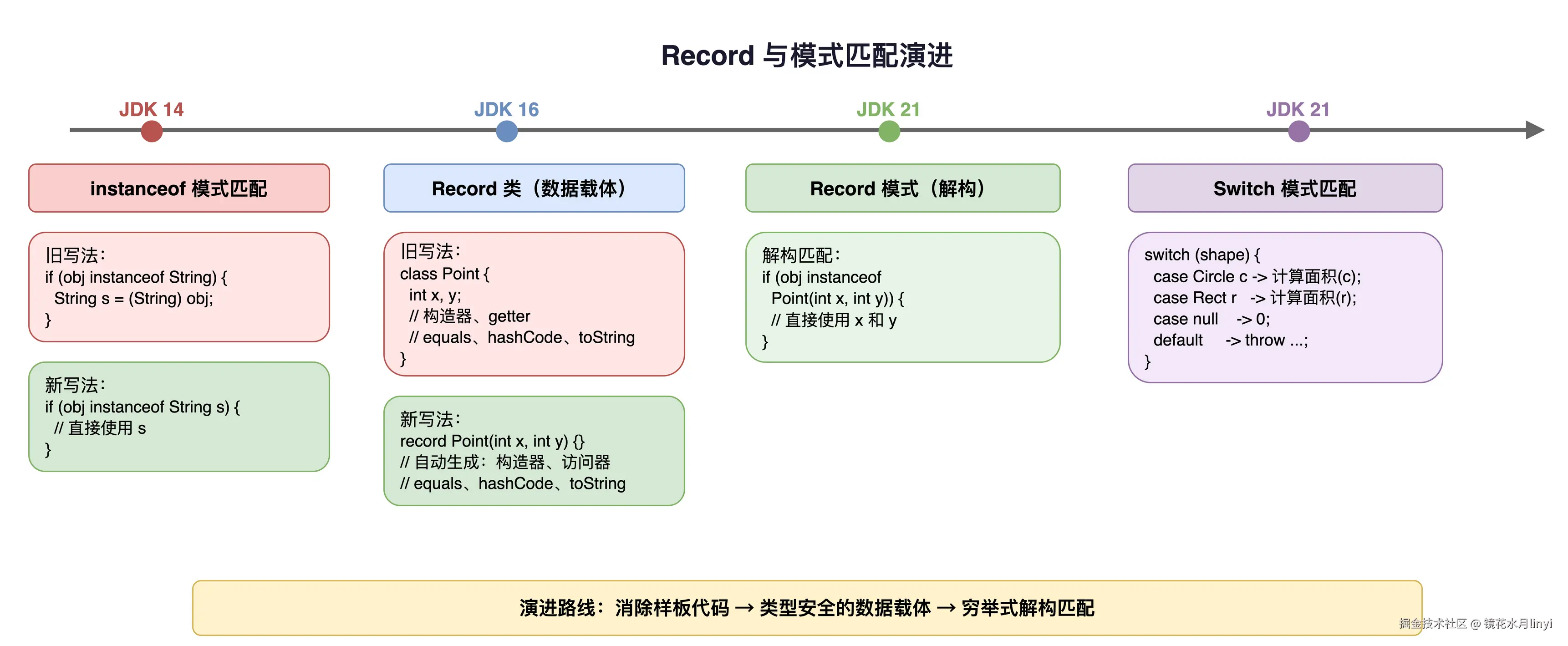 上图展示了模式匹配从 JDK 14 的 instanceof 模式到 JDK 21 的 Record 解构和 Switch 模式匹配的完整演进路线。
上图展示了模式匹配从 JDK 14 的 instanceof 模式到 JDK 21 的 Record 解构和 Switch 模式匹配的完整演进路线。
java
record Point(int x, int y) {}
record Line(Point start, Point end) {}
// 嵌套解构
static void printLength(Object obj) {
if (obj instanceof Line(Point(var x1, var y1), Point(var x2, var y2))) {
double length = Math.sqrt(Math.pow(x2 - x1, 2) + Math.pow(y2 - y1, 2));
System.out.printf("Line length: %.2f%n", length);
}
}Sequenced Collections(JEP 431)
JDK 21 之前,要获取一个 LinkedHashSet 的最后一个元素,你需要遍历整个集合。新接口统一了有序集合的操作:
java
SequencedCollection<String> seq = new LinkedHashSet<>(List.of("a", "b", "c"));
String first = seq.getFirst(); // "a"
String last = seq.getLast(); // "c"
SequencedCollection<String> reversed = seq.reversed(); // ["c", "b", "a"]
SequencedMap<String, Integer> seqMap = new LinkedHashMap<>();
seqMap.put("one", 1);
seqMap.put("two", 2);
Map.Entry<String, Integer> firstEntry = seqMap.firstEntry();
Map.Entry<String, Integer> lastEntry = seqMap.lastEntry();2.6 JDK 22-24 的过渡
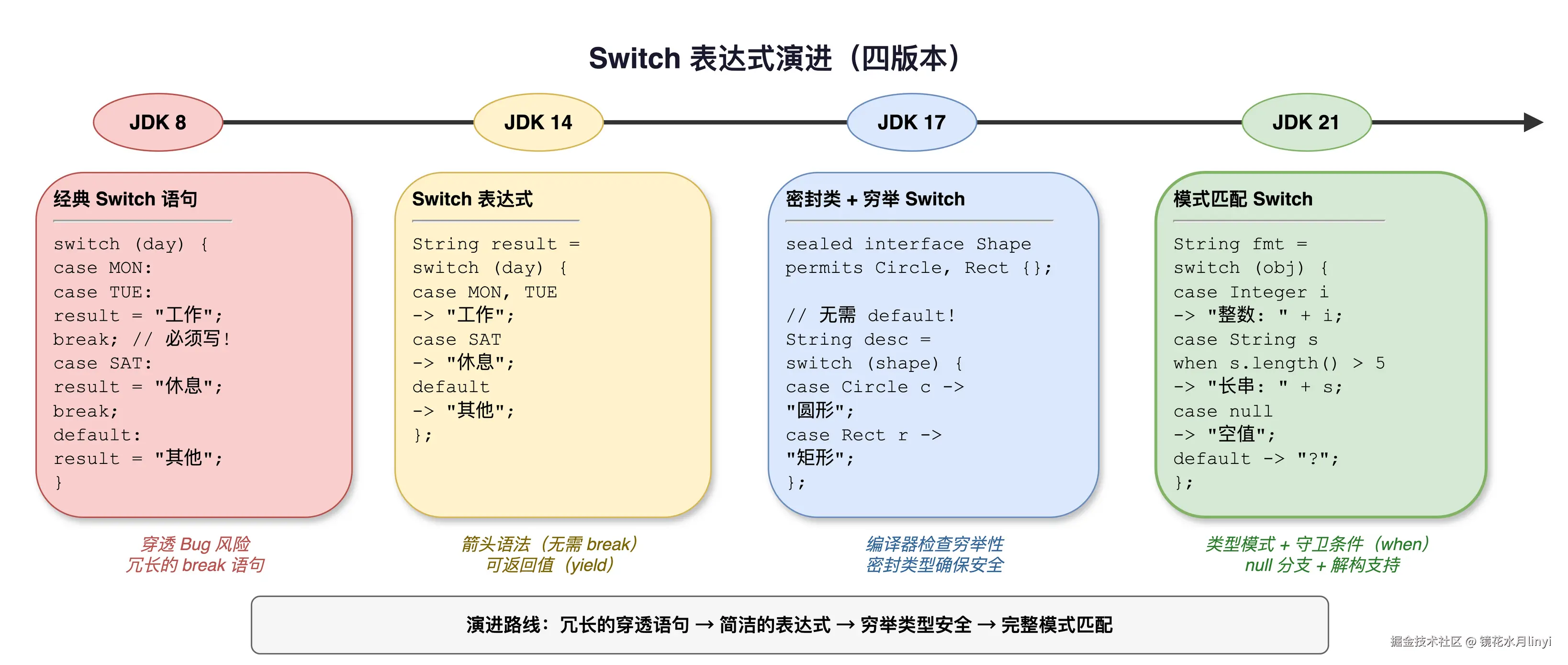
上图展示了 Switch 从 JDK 8 的传统语句到 JDK 21 完整模式匹配的演进历程------从需要 break 的 fall-through 语义,到箭头语法、yield 表达式,再到类型模式和守卫条件。
- JDK 22 :未命名变量和模式
_(JEP 456)、super(...)之前允许语句(预览,JEP 447)
java
// 未命名变量
try {
int result = Integer.parseInt(input);
} catch (NumberFormatException _) {
System.out.println("Invalid number");
}
// 在 switch 中使用未命名模式
switch (shape) {
case Circle _ -> System.out.println("It's a circle");
case Rectangle _ -> System.out.println("It's a rectangle");
default -> {}
}- JDK 23:原始类型模式匹配(预览,JEP 455)、Markdown 文档注释(JEP 467)
- JDK 24:Stream Gatherers 转正(JEP 485)、Class-File API 转正(JEP 484)、AOT 类加载与链接(JEP 483)、虚拟线程解除 synchronized 的 pinning(JEP 491)
Stream Gatherers 是 JDK 24 最实用的新特性之一:
java
// JDK 24: 自定义中间操作
// 示例:滑动窗口
List<List<Integer>> windows = Stream.of(1, 2, 3, 4, 5)
.gather(Gatherers.windowSliding(3))
.toList();
// 结果: [[1, 2, 3], [2, 3, 4], [3, 4, 5]]
// 示例:固定大小分组
List<List<Integer>> groups = Stream.of(1, 2, 3, 4, 5)
.gather(Gatherers.windowFixed(2))
.toList();
// 结果: [[1, 2], [3, 4], [5]]2.7 JDK 25:最新特性
JDK 25 于 2025 年 9 月 16 日正式发布,包含 18 个 JEP,其中 7 个从预览/孵化转为正式特性。
Compact Object Headers(JEP 519,正式特性)
这是 Project Lilliput 的核心成果。在 64 位 JVM 上,每个 Java 对象头从 96-128 bits 压缩到 64 bits(8 字节)。实测表明堆内存占用减少 10-20%,某些基准测试中 CPU 时间减少 8%。
bash
# 启用 Compact Object Headers(JDK 25 中需显式开启)
java -XX:+UseCompactObjectHeaders -jar myapp.jar
# 查看对象布局(配合 JOL 工具)
# 开启前: 对象头 12 字节 (mark word 8B + compressed klass pointer 4B)
# 开启后: 对象头 8 字节 (mark word + class pointer 合并)原理:将 class pointer 从 32 bits 压缩到 22 bits,与 mark word 合并存储在一个 64-bit word 中。这意味着最大支持的类数量从 2^32 降到了约 400 万(2^22),对绝大多数应用来说完全够用。
Scoped Values(JEP 506,正式特性)
Scoped Values 是 ThreadLocal 的现代替代品,特别适合 Virtual Threads 场景:
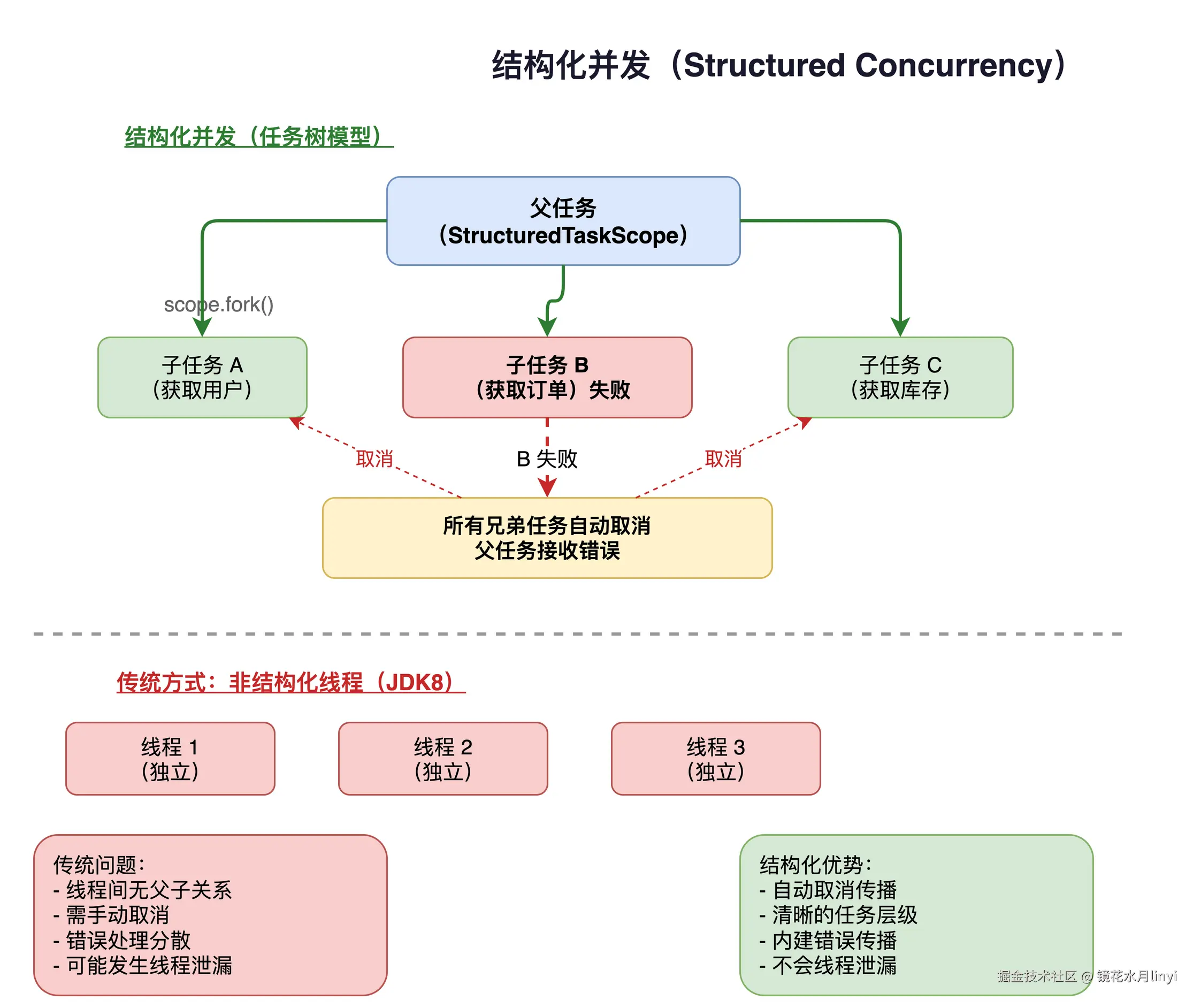 上图展示了结构化并发(Structured Concurrency)的核心设计------父任务 fork 出子任务,任一子任务失败时自动取消其余子任务,相比传统独立线程模型大幅简化了并发控制和错误处理。
上图展示了结构化并发(Structured Concurrency)的核心设计------父任务 fork 出子任务,任一子任务失败时自动取消其余子任务,相比传统独立线程模型大幅简化了并发控制和错误处理。
java
// 定义一个 ScopedValue
private static final ScopedValue<UserContext> CURRENT_USER = ScopedValue.newInstance();
// 在请求入口绑定
public void handleRequest(HttpRequest request) {
UserContext ctx = authenticate(request);
ScopedValue.runWhere(CURRENT_USER, ctx, () -> {
// 在这个作用域内,任何代码都可以读取 CURRENT_USER
processRequest(request);
});
// 作用域结束,自动释放,不存在内存泄漏风险
}
// 在调用链深处读取
public void processRequest(HttpRequest request) {
UserContext user = CURRENT_USER.get(); // 读取当前作用域的值
// ...
}与 ThreadLocal 的本质区别:
- ScopedValue 是不可变的(immutable),ThreadLocal 可以随时 set
- ScopedValue 有明确的生命周期(作用域),ThreadLocal 需要手动 remove
- ScopedValue 在 Virtual Thread 继承时零成本,ThreadLocal 需要复制
Flexible Constructor Bodies(JEP 513,正式特性)
终于可以在 super() 之前执行语句了:
java
public class ValidatedOrder extends Order {
public ValidatedOrder(String orderId, BigDecimal amount) {
// JDK 25:可以在 super() 之前做校验和字段初始化
if (orderId == null || orderId.isBlank()) {
throw new IllegalArgumentException("orderId cannot be empty");
}
if (amount.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("amount must be positive");
}
this.validatedAt = Instant.now(); // 可以初始化字段
super(orderId, amount); // 然后调用父类构造器
}
}Module Import Declarations(JEP 511,正式特性)
java
// JDK 25:模块级导入
import module java.base; // 导入 java.base 模块的所有公共类型
// 不再需要写一堆 import java.util.*, import java.io.* 等
public class Demo {
public static void main(String[] args) {
var list = List.of(1, 2, 3); // java.util.List
var path = Path.of("/tmp"); // java.nio.file.Path
}
}Compact Source Files and Instance Main Methods(JEP 512,正式特性)
java
// JDK 25:最简单的 Hello World
void main() {
println("Hello, World!");
}
// 不需要 public class,不需要 static,不需要 String[] argsGenerational Shenandoah(JEP 521,正式特性)
Shenandoah GC 加入分代支持,与 Generational ZGC 类似,通过分离年轻代和老年代的回收来提升吞吐量和降低停顿时间。
Stable Values(JEP 502,预览)
Stable Values 是一种介于 final 字段和普通字段之间的机制,允许延迟初始化但仍能被 JVM 视为常量进行优化:
java
// JDK 25 Preview
private final StableValue<DatabaseConnection> connection = StableValue.of();
public DatabaseConnection getConnection() {
return connection.orElseSet(this::createConnection);
// 第一次调用时初始化,之后 JVM 可以将其视为常量
}AOT Method Profiling(JEP 515)
Project Leyden 的一部分,保存方法级别的 profiling 数据,在后续启动中复用,加速 JIT warm-up:
bash
# 第一次运行:收集 profiling 数据
java -XX:AOTConfiguration=app.aotconf -jar myapp.jar
# 第二次运行:利用 profiling 数据加速
java -XX:AOTConfiguration=app.aotconf -jar myapp.jar三、GC 垃圾收集器演进
GC 的演进是 JDK 版本升级中最直接的性能收益来源。四个 LTS 版本跨越了 Java GC 从"能用"到"极致"的进化过程。 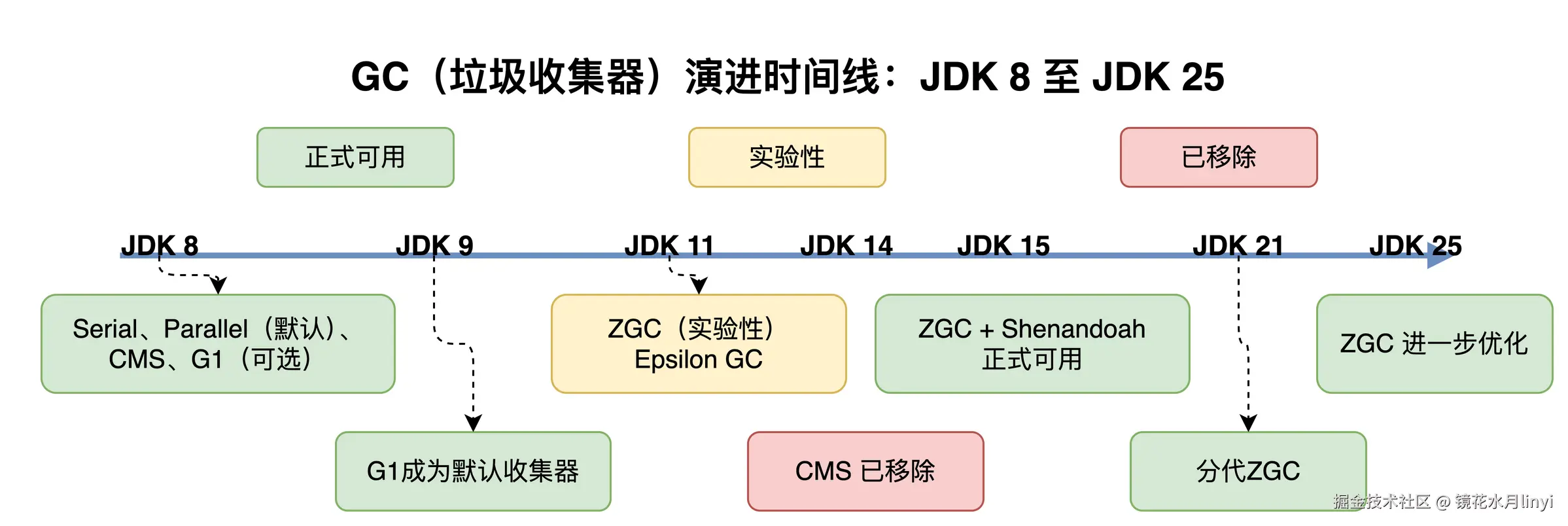
3.1 JDK 8:G1 成为可选,CMS 仍是主流
JDK 8 的默认 GC 是 Parallel GC(也叫 Throughput Collector),适合吞吐量优先的批处理场景。但大多数 Web 应用选择了 CMS 或 G1:
bash
# JDK 8 常见的 GC 配置
# CMS(低延迟优先)
java -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled \
-XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly \
-Xms4g -Xmx4g -jar myapp.jar
# G1(平衡型)
java -XX:+UseG1GC -XX:MaxGCPauseMillis=200 \
-XX:G1HeapRegionSize=8m -XX:InitiatingHeapOccupancyPercent=45 \
-Xms4g -Xmx4g -jar myapp.jarJDK 8 时代 GC 的主要痛点:
- CMS 有 concurrent mode failure 风险,触发 Full GC 后停顿时间可达数秒
- CMS 会产生内存碎片,长时间运行后需要重启
- G1 在 JDK 8 中还不成熟,Full GC 是单线程的(直到 JDK 10 才改为多线程)
- PermGen(永久代)空间需要单独调优,OOM 频繁
3.2 JDK 17:G1 成熟,ZGC 可投产
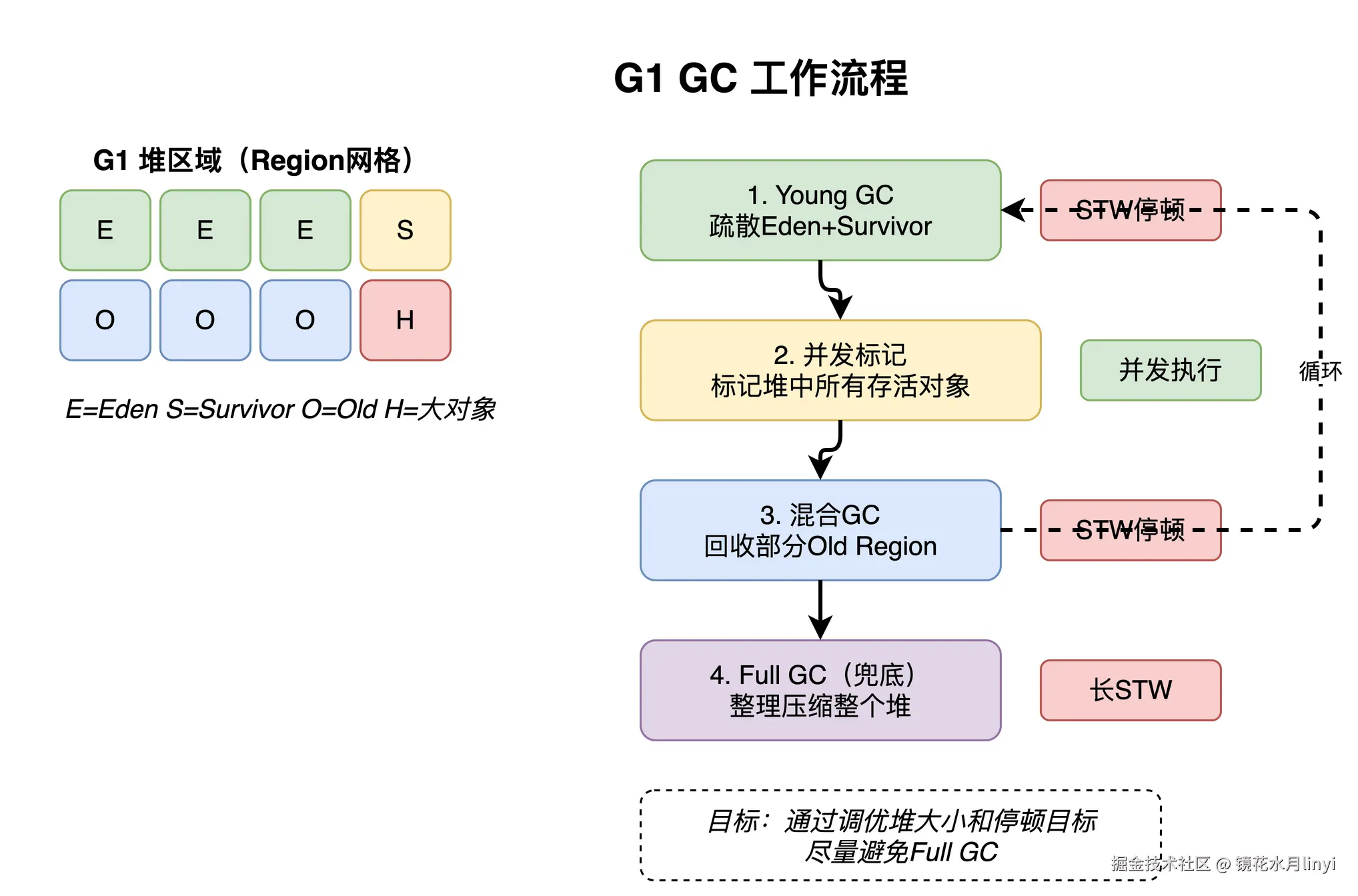
上图展示了 G1 GC 的 Region 化堆布局和四阶段工作流程------Young GC(疏散 Eden/Survivor)→ 并发标记 → Mixed GC(回收部分 Old Region)→ Full GC(兜底)。
到 JDK 17,GC 格局发生了重大变化:
| 变化 | 版本 |
|---|---|
| G1 成为默认 GC | JDK 9 |
| CMS 被标记废弃 | JDK 9 |
| G1 Full GC 改为并行 | JDK 10 |
| ZGC 实验性引入 | JDK 11 |
| CMS 被移除 | JDK 14 |
| ZGC 转正(非实验性) | JDK 15 |
| Shenandoah 转正 | JDK 15 |
| PermGen 移除,改为 Metaspace | JDK 8 |
JDK 17 的 G1 相比 JDK 8 有质的飞跃:
- NUMA 感知的内存分配(JDK 14, JEP 345)
- 可中断的 Mixed GC(JDK 12, JEP 344)
- 并行 Full GC(JDK 10, JEP 307)
- 自动返回未使用的堆内存给操作系统(JDK 12, JEP 346)
bash
# JDK 17 推荐的 G1 配置
java -XX:+UseG1GC \
-XX:MaxGCPauseMillis=100 \
-XX:G1HeapRegionSize=16m \
-XX:G1NewSizePercent=20 \
-XX:G1MaxNewSizePercent=40 \
-XX:G1ReservePercent=15 \
-XX:InitiatingHeapOccupancyPercent=35 \
-Xms8g -Xmx8g -jar myapp.jar
# JDK 17 ZGC 配置(适合超低延迟场景)
java -XX:+UseZGC \
-XX:ZCollectionInterval=5 \
-XX:SoftMaxHeapSize=6g \
-Xms8g -Xmx8g -jar myapp.jar3.3 JDK 21:分代 ZGC
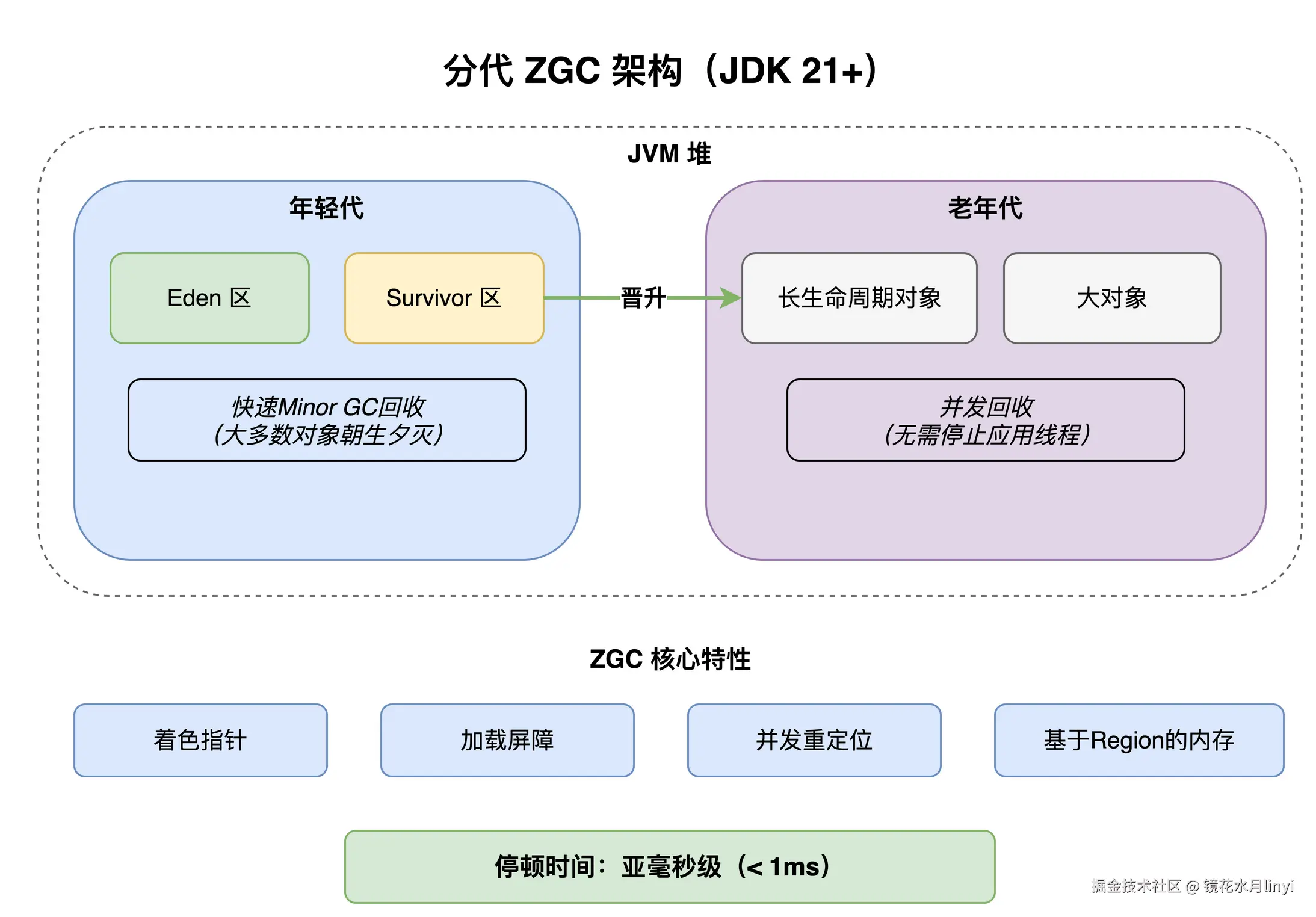 JDK 21 引入了 Generational ZGC(JEP 439),这是 ZGC 的一个重大升级。
JDK 21 引入了 Generational ZGC(JEP 439),这是 ZGC 的一个重大升级。
为什么 ZGC 需要分代?
ZGC 最初是非分代的,所有对象统一管理。这意味着每次 GC 都需要扫描整个堆,虽然停顿时间很短(亚毫秒级),但扫描开销大,吞吐量受影响。引入分代后:
- 年轻代回收频率高、范围小、速度快
- 老年代回收频率低,大幅减少扫描开销
- 整体吞吐量提升 10-20%
bash
# JDK 21 分代 ZGC
java -XX:+UseZGC -XX:+ZGenerational \
-Xms16g -Xmx16g -jar myapp.jar实测数据(某电商下单链路,16G 堆内存,8 核):
| 指标 | G1 (JDK 17) | ZGC 非分代 (JDK 17) | ZGC 分代 (JDK 21) |
|---|---|---|---|
| P99 停顿时间 | 35ms | 0.5ms | 0.3ms |
| P999 停顿时间 | 120ms | 1.2ms | 0.8ms |
| 吞吐量 (TPS) | 12,500 | 11,800 | 13,200 |
| 堆利用率 | 75% | 85% | 80% |
可以看到,分代 ZGC 不仅保持了极低的停顿时间,还将吞吐量提升到了 G1 之上。
3.4 JDK 25:GC 进一步优化
JDK 25 的 GC 变化:
-
Generational Shenandoah(JEP 521,正式特性):与 ZGC 类似,Shenandoah 也加入了分代支持。在 JDK 24 中作为实验特性引入,JDK 25 正式转正。
-
非分代 ZGC 被移除(JDK 24, JEP 490) :从 JDK 24 开始,ZGC 只有分代模式,
-XX:+ZGenerational不再需要(也不再被接受),默认就是分代。 -
Compact Object Headers(JEP 519)对 GC 的影响:对象头缩小意味着每次 GC 需要处理的元数据更少,mark phase 更快。
bash
# JDK 25 推荐的 ZGC 配置
java -XX:+UseZGC \
-XX:+UseCompactObjectHeaders \
-Xms16g -Xmx16g -jar myapp.jar
# JDK 25 Shenandoah 分代模式
java -XX:+UseShenandoahGC \
-XX:ShenandoahGCMode=generational \
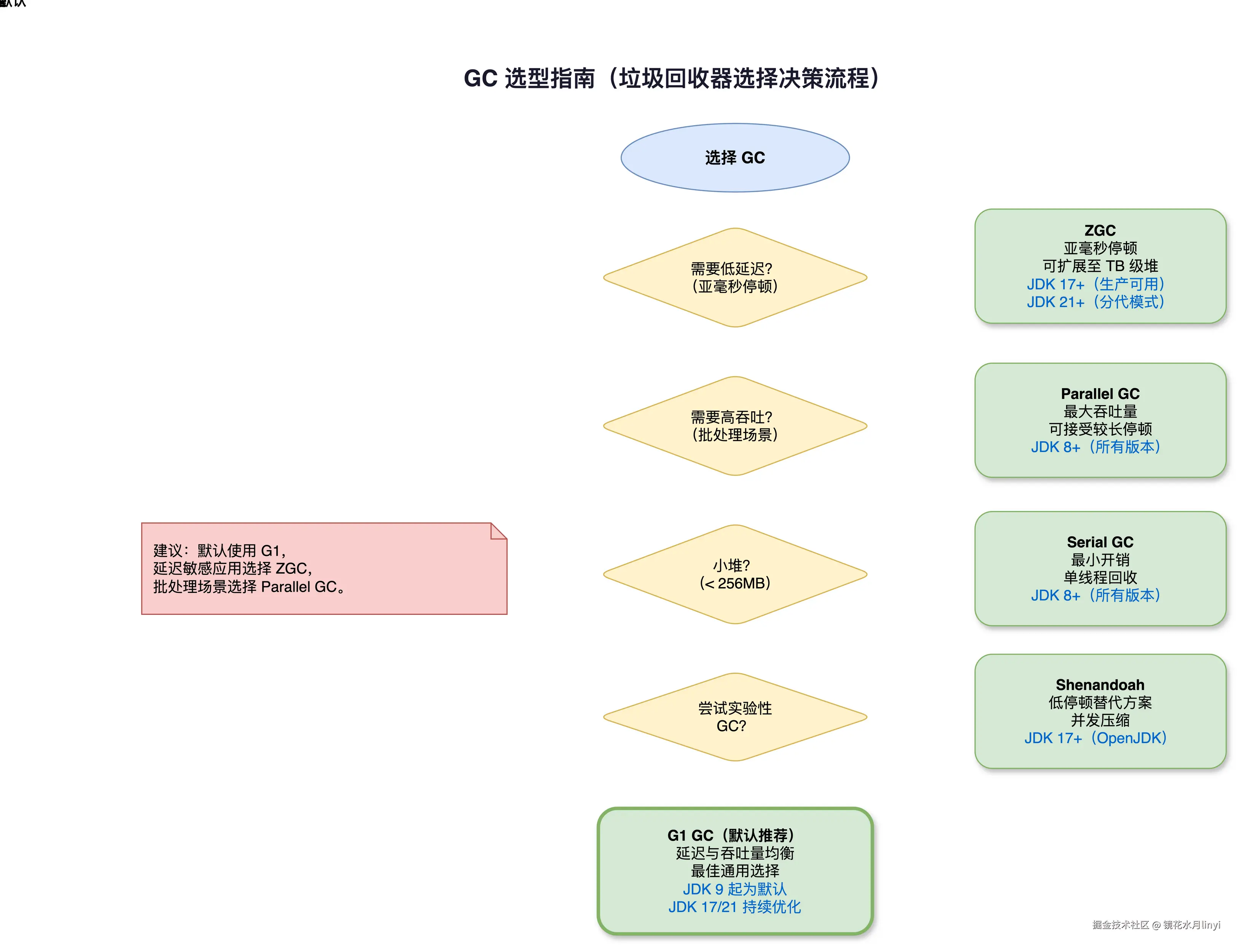
-Xms16g -Xmx16g -jar myapp.jar3.5 GC 选型指南
| 场景 | 推荐 GC | 关键参数 |
|---|---|---|
| 微服务(< 4G 堆) | G1 | -XX:MaxGCPauseMillis=100 |
| 大堆内存(16G+)低延迟 | ZGC (分代) | -XX:+UseZGC |
| 交易系统(亚毫秒级延迟要求) | ZGC (分代) | -XX:+UseZGC -XX:SoftMaxHeapSize=X |
| 批处理/大数据计算 | G1 或 Parallel | -XX:+UseG1GC 或 -XX:+UseParallelGC |
| 容器环境(内存受限) | G1 + Compact Headers | -XX:+UseG1GC -XX:+UseCompactObjectHeaders |
| Red Hat 生态 | Shenandoah (分代) | -XX:+UseShenandoahGC |
 一个真实的 GC 迁移案例:
一个真实的 GC 迁移案例:
我们有一个订单服务,JDK 8 + CMS,8G 堆内存。每天下午流量高峰期经常出现 CMS concurrent mode failure,触发 Full GC,停顿 3-5 秒,直接导致上游网关超时。
迁移到 JDK 17 + G1 后,P99 GC 停顿降到 50ms 以内,concurrent mode failure 彻底消失。后来进一步升级到 JDK 21 + Generational ZGC + 16G 堆,P99 降到了 0.5ms,基本上业务代码感知不到 GC 的存在了。
四、性能优化与 JIT 编译
4.1 JIT 编译器演进
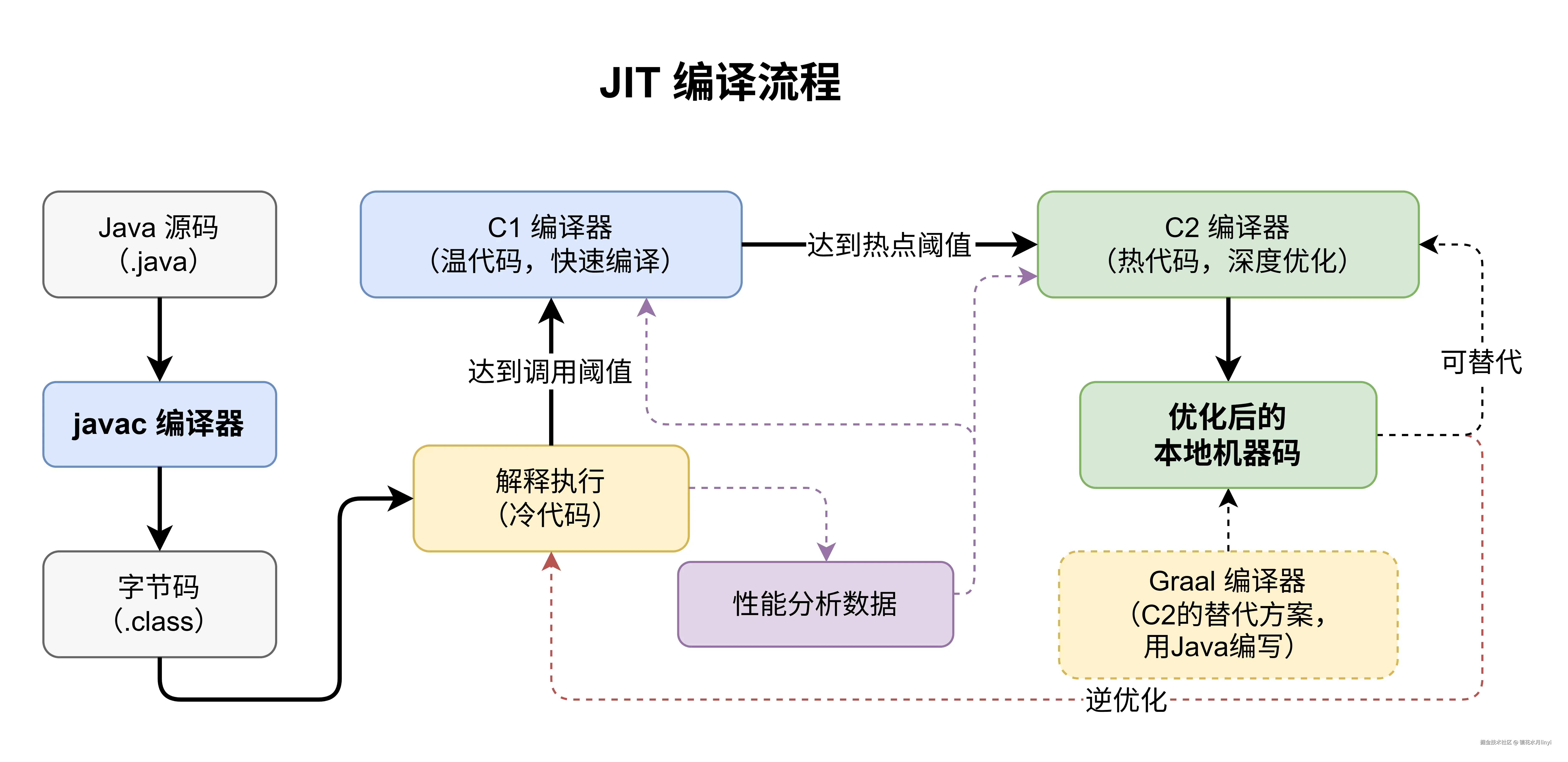
JDK 的 JIT(Just-In-Time)编译器负责将热点字节码编译为机器码。理解 JIT 的演进对性能调优至关重要。
JDK 8 的分层编译
JDK 8 使用 C1(Client Compiler)和 C2(Server Compiler)两个编译器,通过分层编译(Tiered Compilation)协作:
- Level 0:解释执行
- Level 1:C1 编译,不带 profiling
- Level 2:C1 编译,带有限的 profiling
- Level 3:C1 编译,带完整 profiling
- Level 4:C2 编译(最终优化代码)
bash
# JDK 8 查看 JIT 编译日志
java -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions \
-XX:+PrintInlining -jar myapp.jarJDK 10-17 的 Graal 编译器实验
JDK 10 引入了 Graal 作为实验性的 JIT 编译器(JEP 317),用 Java 编写,理论上更容易维护和扩展。但 JDK 17 移除了 Graal JIT 的接口(JEP 410),因为 Oracle 把 Graal 的开发重心放到了 GraalVM 项目上。
JDK 21-25 的 C2 持续优化
虽然没有引入新的 JIT 编译器,但 C2 在逐版本中持续得到优化:
- 更好的自动向量化(auto-vectorization)
- 逃逸分析(escape analysis)增强,更多对象在栈上分配
- Intrinsic 方法增加,常用操作直接映射到 CPU 指令
4.2 启动速度优化
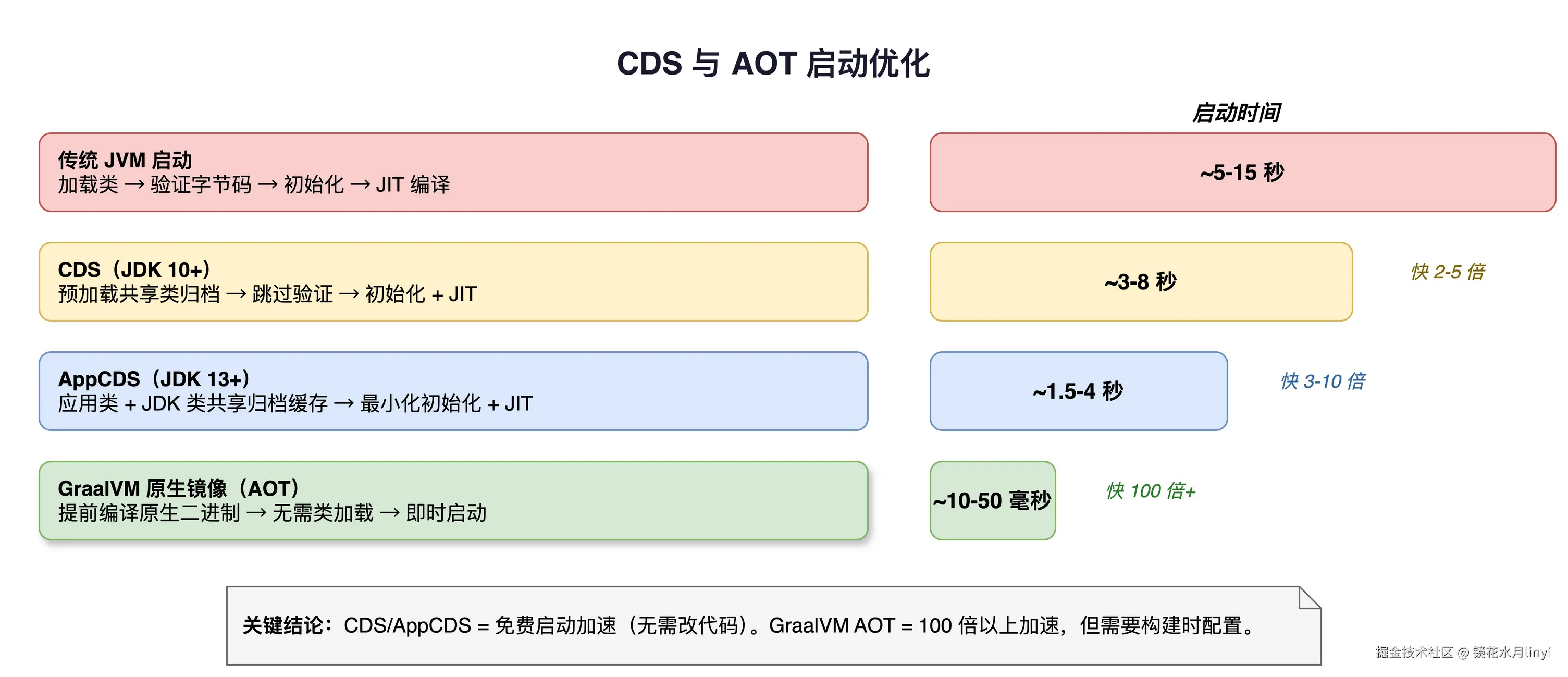
启动速度在 Serverless 和容器化场景中非常关键。各版本的启动优化手段:
CDS(Class Data Sharing)演进
| 版本 | 能力 |
|---|---|
| JDK 8 | 基础 CDS,只支持 bootstrap class |
| JDK 10 | AppCDS(JEP 310),支持应用类 |
| JDK 13 | 动态 CDS(JEP 350),自动归档 |
| JDK 19 | 默认启用 CDS 归档 |
| JDK 24 | AOT 类加载与链接(JEP 483),保存加载+链接后的状态 |
| JDK 25 | AOT Method Profiling(JEP 515),保存 profiling 数据 |
bash
# JDK 17: 动态 CDS
# 第一次运行,生成归档
java -XX:ArchiveClassesAtExit=app-cds.jsa -jar myapp.jar
# 后续运行,使用归档
java -XX:SharedArchiveFile=app-cds.jsa -jar myapp.jar
# 启动速度提升 20-40%
# JDK 24+: AOT 类加载与链接
java -XX:AOTCache=app.aot -XX:AOTConfiguration=app.aotconf -jar myapp.jar
# 启动速度提升可达 40-60%启动时间实测对比(Spring Boot 3.x 应用,中等规模 50 个 Bean):
| 配置 | 冷启动时间 |
|---|---|
| JDK 8 | 4.2s |
| JDK 17 | 3.8s |
| JDK 17 + CDS | 2.9s |
| JDK 21 | 3.5s |
| JDK 21 + CDS | 2.5s |
| JDK 25 + AOT Cache | 1.8s |
| GraalVM Native Image | 0.08s |
4.3 内存模型变化
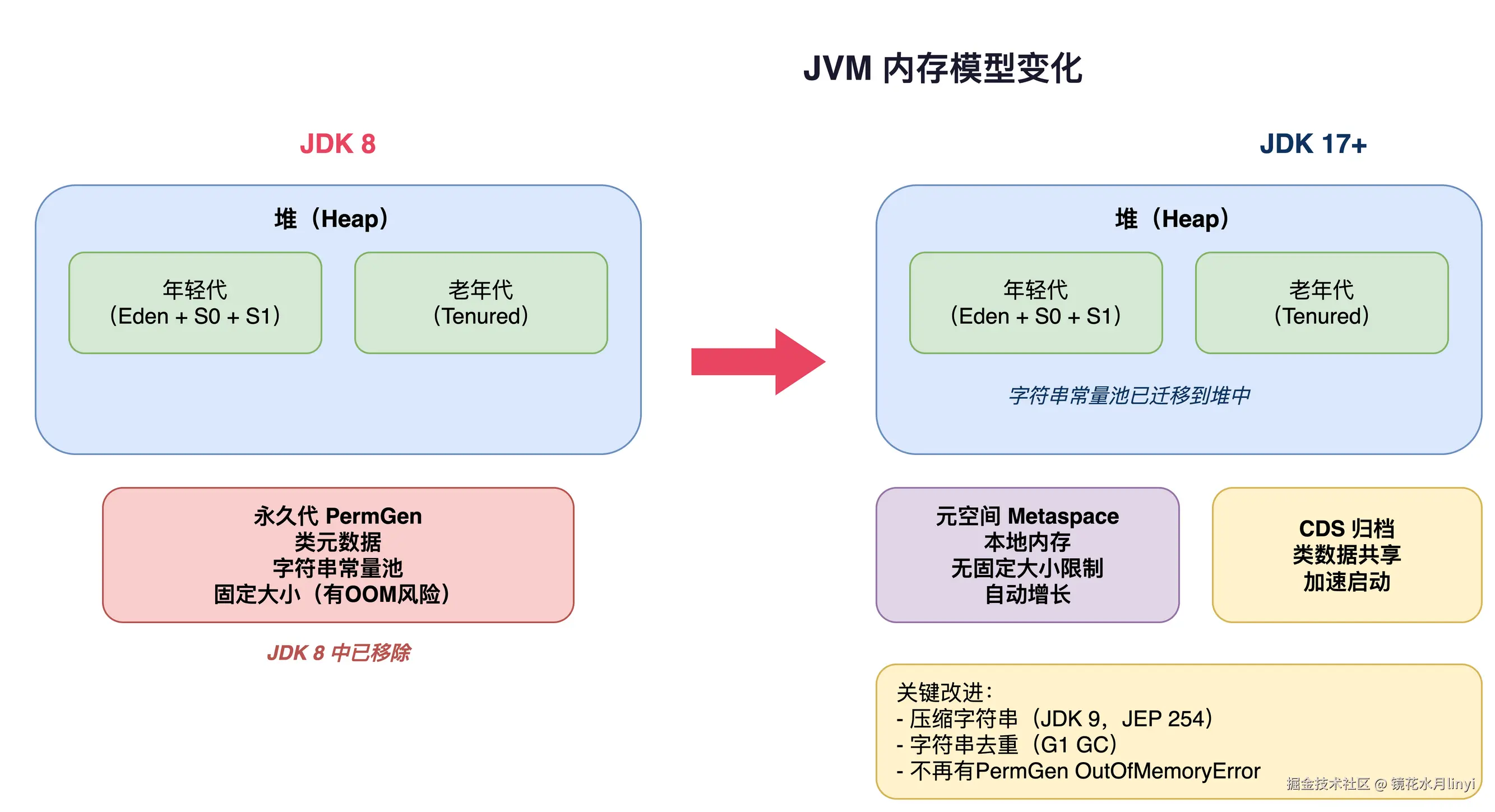
Compact Strings(JDK 9, JEP 254)
JDK 8 的 String 内部使用 char[](每个字符 2 字节,UTF-16)。JDK 9 改为 byte[] + 编码标识,Latin-1 字符串只用 1 字节/字符:
java
// JDK 8: String 内部结构
private final char[] value; // 每个字符占 2 字节
// JDK 9+: String 内部结构
private final byte[] value; // Latin-1 时每个字符 1 字节
private final byte coder; // 0 = Latin-1, 1 = UTF-16对于以英文和数字为主的应用(大部分后端服务),String 内存占用直接减半。我们的一个日志分析服务升级到 JDK 11 后,堆内存使用量从 6G 降到了 4.2G。
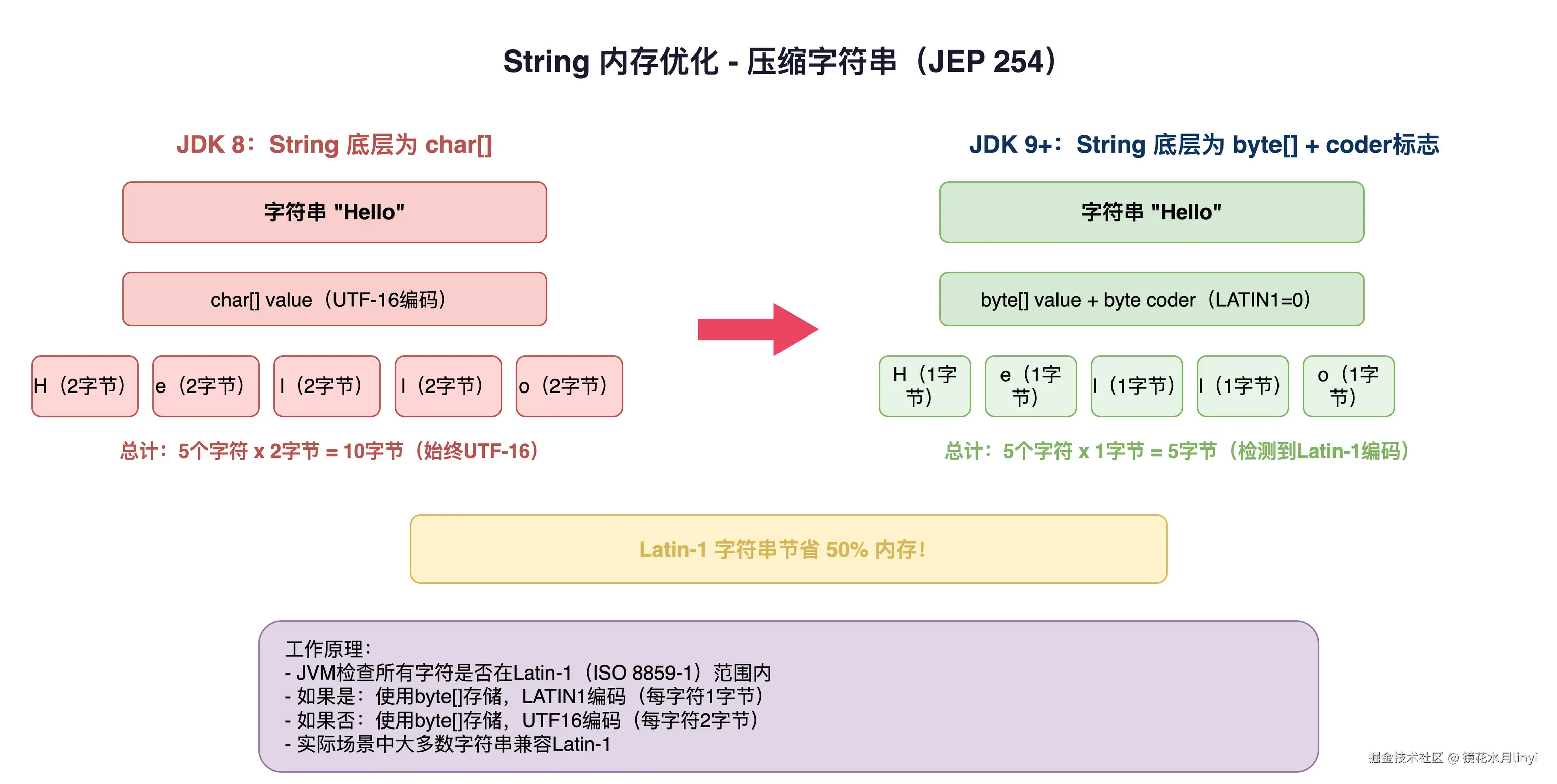
上图展示了 Compact Strings(JEP 254)的内存优化原理------JDK 8 的 char[] 每字符固定 2 字节,JDK 9+ 的 byte[] + coder 对 Latin-1 字符只需 1 字节,纯英文场景内存直接减半。
PermGen → Metaspace
JDK 8 用 Metaspace(位于本地内存,而非堆内存)替换了 PermGen:
- 不再有
java.lang.OutOfMemoryError: PermGen space - 默认没有上限(可通过
-XX:MaxMetaspaceSize设置) - 类卸载更高效
JDK 25 Compact Object Headers 的内存影响
一个 Java 对象的最小大小:
- JDK 8-24(开启指针压缩):对象头 12B + 对齐填充 = 16B
- JDK 25(Compact Headers):对象头 8B + 对齐填充 = 16B(最小仍然 16B 因为对齐)
但对于稍大一点的对象(有 1-2 个字段),差异就体现出来了:
css
// 一个包含 int 字段的对象
// JDK 8-24: header(12B) + int(4B) = 16B
// JDK 25: header(8B) + int(4B) + padding(4B) = 16B
// 这个例子没差异
// 一个包含 int + boolean 字段的对象
// JDK 8-24: header(12B) + int(4B) + boolean(1B) + padding(7B) = 24B
// JDK 25: header(8B) + int(4B) + boolean(1B) + padding(3B) = 16B
// 节省了 8B (33%)当你的应用有大量小对象(例如大量的 DTO、Event、Node 节点),Compact Object Headers 的收益非常可观。
五、模块化系统(JPMS)
JPMS(Java Platform Module System)是 JDK 9 引入的 Project Jigsaw 的核心成果。直说吧:到 2025 年,大部分业务项目仍然没有使用模块系统。但了解它很重要,因为它影响了 JDK 内部 API 的访问控制和很多迁移问题。
module-info.java 基本结构
java
module com.myapp.order {
// 声明依赖
requires java.sql;
requires java.logging;
requires transitive com.myapp.common; // 传递依赖
// 导出包(只有导出的包才能被其他模块访问)
exports com.myapp.order.api;
exports com.myapp.order.model;
// 对特定模块开放反射(用于框架,如 Jackson、Hibernate)
opens com.myapp.order.entity to com.fasterxml.jackson.databind;
opens com.myapp.order.entity to org.hibernate.orm.core;
// SPI 服务声明
provides com.myapp.common.spi.PaymentProvider
with com.myapp.order.payment.AlipayProvider;
uses com.myapp.common.spi.NotificationService;
}为什么大多数项目不用模块?
-
Spring Framework 的兼容策略 :Spring 使用大量反射和动态代理,模块系统的强封装与此冲突。虽然 Spring 5+ 提供了
Automatic-Module-Name,但完整的模块化支持一直不是优先项。 -
第三方库的模块化程度低:很多常用库直到现在仍然是 unnamed module 或 automatic module,混用时容易出现 split package 等问题。
-
投入产出不匹配:对于大多数业务应用,包访问控制和 Maven/Gradle 依赖管理已经足够,JPMS 带来的强隔离收益不明显。
但 JPMS 对 JDK 自身的影响是深远的:
从 JDK 16 开始,--illegal-access 选项被移除,JDK 内部 API 被默认强封装。如果你的代码或依赖直接使用了 sun.misc.Unsafe、com.sun.xml.internal.* 等内部 API,升级时必须处理:
bash
# 临时解决:添加 --add-opens(不推荐长期使用)
java --add-opens java.base/java.lang=ALL-UNNAMED \
--add-opens java.base/sun.nio.ch=ALL-UNNAMED \
-jar myapp.jar
# 正确做法:替换为公开 API
# sun.misc.Unsafe → VarHandle (JDK 9+)
# sun.misc.BASE64Encoder → java.util.Base64 (JDK 8+)
# sun.reflect.Reflection → StackWalker (JDK 9+)六、核心 API 变化
6.1 集合工厂方法
java
// JDK 8: 创建不可变集合
List<String> list = Collections.unmodifiableList(Arrays.asList("a", "b", "c"));
Map<String, Integer> map = Collections.unmodifiableMap(new HashMap<>() {{
put("one", 1);
put("two", 2);
}});
// JDK 9+: 集合工厂方法
List<String> list = List.of("a", "b", "c");
Set<String> set = Set.of("a", "b", "c");
Map<String, Integer> map = Map.of("one", 1, "two", 2);
Map<String, Integer> mapFromEntries = Map.ofEntries(
Map.entry("one", 1),
Map.entry("two", 2),
Map.entry("three", 3)
);
// JDK 10+: Collectors.toUnmodifiableList
List<String> filtered = list.stream()
.filter(s -> s.startsWith("a"))
.collect(Collectors.toUnmodifiableList());
// JDK 16+: Stream.toList()(返回不可修改的 List)
List<String> filtered = list.stream()
.filter(s -> s.startsWith("a"))
.toList();
// JDK 21: SequencedCollection
SequencedCollection<String> seqList = new ArrayList<>(List.of("a", "b", "c"));
seqList.addFirst("z");
seqList.addLast("d");
String first = seqList.getFirst(); // "z"
String last = seqList.getLast(); // "d"6.2 HttpClient
JDK 8 的 HttpURLConnection 是公认的烂 API。JDK 11 标准化了全新的 HttpClient(JEP 321)。
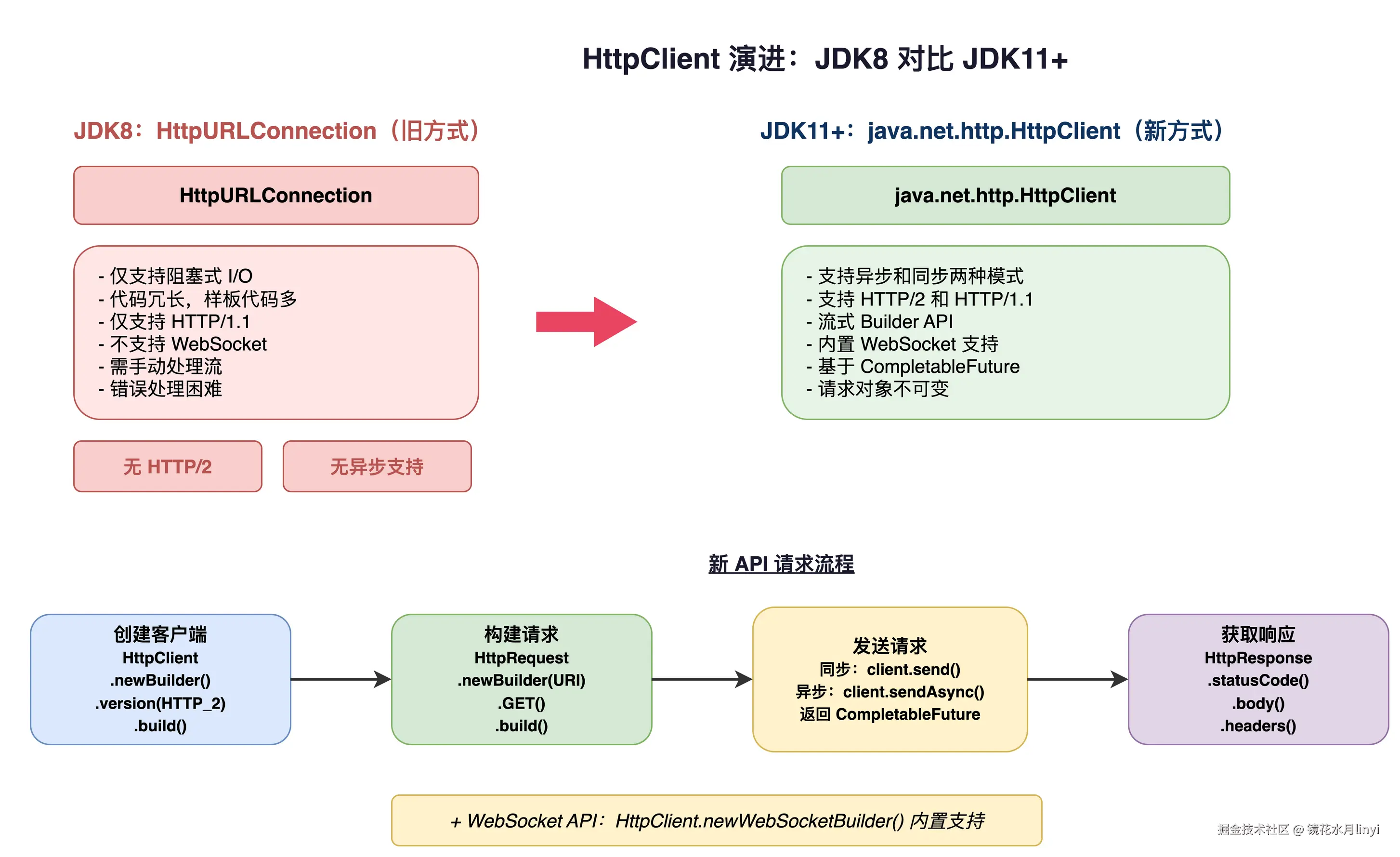 上图对比了 JDK 8 的 HttpURLConnection(阻塞、冗长、不支持 HTTP/2)和 JDK 11+ 的 HttpClient(异步、HTTP/2、流式 API)的架构差异。
上图对比了 JDK 8 的 HttpURLConnection(阻塞、冗长、不支持 HTTP/2)和 JDK 11+ 的 HttpClient(异步、HTTP/2、流式 API)的架构差异。
java
// JDK 8: HttpURLConnection(痛苦的写法)
URL url = new URL("https://api.example.com/users");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setRequestProperty("Accept", "application/json");
conn.setConnectTimeout(5000);
conn.setReadTimeout(10000);
int responseCode = conn.getResponseCode();
if (responseCode == 200) {
try (BufferedReader br = new BufferedReader(
new InputStreamReader(conn.getInputStream()))) {
StringBuilder response = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
response.append(line);
}
System.out.println(response.toString());
}
} else {
// 错误处理...
}
conn.disconnect();
// JDK 11+: HttpClient(现代写法)
HttpClient client = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_2)
.connectTimeout(Duration.ofSeconds(5))
.followRedirects(HttpClient.Redirect.NORMAL)
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com/users"))
.header("Accept", "application/json")
.timeout(Duration.ofSeconds(10))
.GET()
.build();
// 同步调用
HttpResponse<String> response = client.send(request,
HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
// 异步调用
client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println)
.exceptionally(e -> { e.printStackTrace(); return null; });
// POST JSON
HttpRequest postRequest = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com/users"))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString("""
{"name": "张三", "email": "zhangsan@example.com"}
"""))
.build();6.3 Foreign Function & Memory API
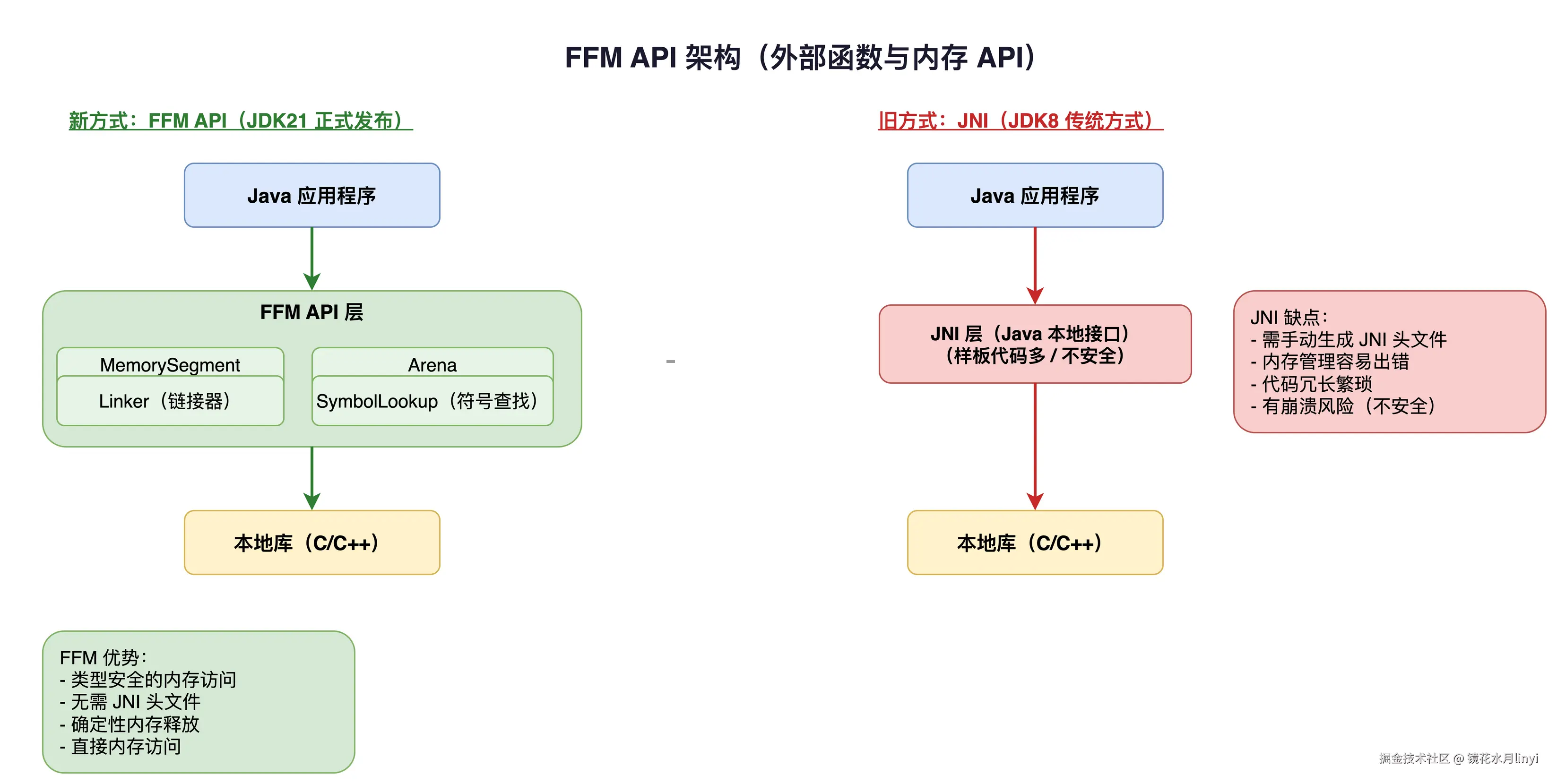 FFM API(Foreign Function & Memory API)是 Project Panama 的核心成果,目标是替代 JNI(Java Native Interface)。从 JDK 14 开始孵化,JDK 22 正式转正。
FFM API(Foreign Function & Memory API)是 Project Panama 的核心成果,目标是替代 JNI(Java Native Interface)。从 JDK 14 开始孵化,JDK 22 正式转正。
java
// JDK 22+: 使用 FFM API 调用 C 标准库的 strlen 函数
import java.lang.foreign.*;
import java.lang.invoke.MethodHandle;
public class FFMExample {
public static void main(String[] args) throws Throwable {
// 获取系统链接器
Linker linker = Linker.nativeLinker();
// 查找 C 标准库中的 strlen 函数
SymbolLookup stdlib = linker.defaultLookup();
MemorySegment strlenAddr = stdlib.find("strlen").orElseThrow();
// 创建方法句柄
MethodHandle strlen = linker.downcallHandle(
strlenAddr,
FunctionDescriptor.of(ValueLayout.JAVA_LONG, ValueLayout.ADDRESS)
);
// 分配并使用本地内存
try (Arena arena = Arena.ofConfined()) {
MemorySegment cString = arena.allocateFrom("Hello, FFM!");
long length = (long) strlen.invoke(cString);
System.out.println("String length: " + length); // 输出: 11
}
// Arena 关闭时自动释放本地内存,不会内存泄漏
}
}与 JNI 的对比:
- 安全性:FFM API 在 Java 层面管理内存生命周期,JNI 需要手动管理 C 内存
- 开发效率:FFM API 纯 Java 代码,JNI 需要写 C/C++ 代码 + 头文件
- 性能:FFM API 与 JNI 性能相当,某些场景更优(避免了 JNI 的 boundary crossing 开销)
- 工具链 :
jextract工具可以从 C 头文件自动生成 Java 绑定代码
6.4 其他重要 API 变化
Process API 增强(JDK 9)
java
// JDK 9+: 获取进程信息
ProcessHandle current = ProcessHandle.current();
System.out.println("PID: " + current.pid());
System.out.println("Command: " + current.info().command().orElse("unknown"));
System.out.println("CPU Duration: " + current.info().totalCpuDuration().orElse(Duration.ZERO));
// 列出所有子进程
current.children().forEach(ph ->
System.out.println("Child PID: " + ph.pid()));CompletableFuture 增强
java
// JDK 9: orTimeout, completeOnTimeout
CompletableFuture<String> future = callRemoteService()
.orTimeout(5, TimeUnit.SECONDS) // 5 秒超时抛 TimeoutException
.completeOnTimeout("default", 5, TimeUnit.SECONDS); // 超时返回默认值
// JDK 9: copy()
CompletableFuture<String> defensiveCopy = future.copy(); // 防止外部代码 complete
// JDK 12: exceptionallyCompose
CompletableFuture<String> resilient = callPrimaryService()
.exceptionallyCompose(ex -> callFallbackService());Stream API 持续增强
java
// JDK 9: takeWhile, dropWhile
Stream.of(1, 2, 3, 4, 5, 1, 2)
.takeWhile(n -> n < 4) // [1, 2, 3]
.forEach(System.out::println);
// JDK 9: ofNullable
Stream<String> stream = Stream.ofNullable(getNullableValue()); // 空安全
// JDK 16: Stream.toList()
List<Integer> list = Stream.of(1, 2, 3).toList(); // 替代 collect(Collectors.toList())
// JDK 16: mapMulti
Stream.of(1, 2, 3)
.<Integer>mapMulti((num, consumer) -> {
consumer.accept(num);
consumer.accept(num * 10);
})
.toList(); // [1, 10, 2, 20, 3, 30]七、安全性增强
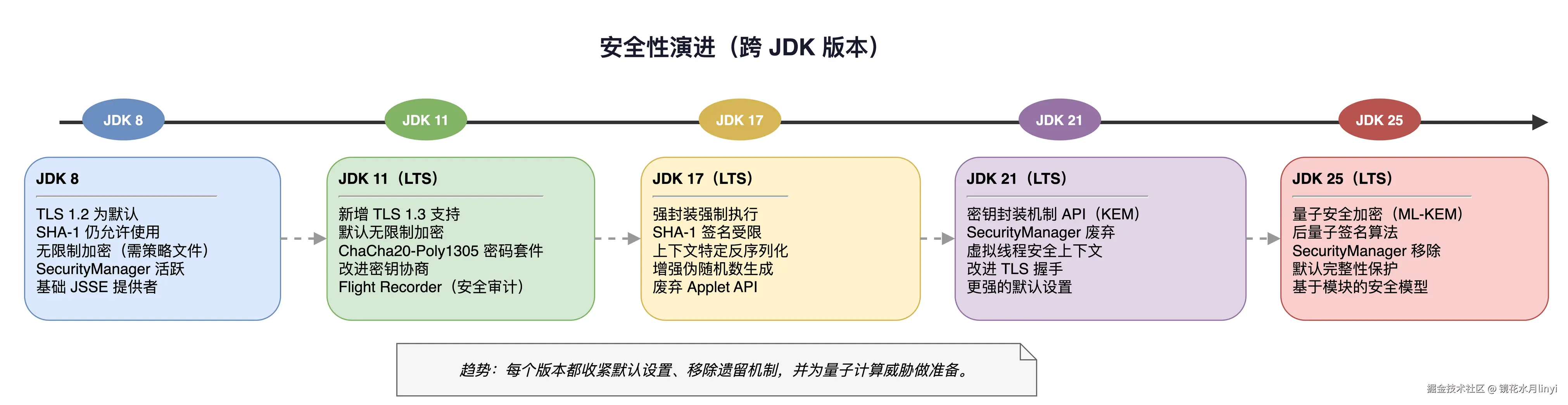 安全性的变化经常被忽略,但在生产环境中如果不注意,升级后可能直接导致 SSL 握手失败或加密算法不可用。
安全性的变化经常被忽略,但在生产环境中如果不注意,升级后可能直接导致 SSL 握手失败或加密算法不可用。
| 特性 | JDK 8 | JDK 17 | JDK 21 | JDK 25 |
|---|---|---|---|---|
| 最高 TLS 版本 | TLS 1.2 | TLS 1.3 | TLS 1.3 | TLS 1.3 |
| 默认 TLS 版本 | TLS 1.2 | TLS 1.3 | TLS 1.3 | TLS 1.3 |
| SHA-1 签名 | 允许 | 禁用 | 禁用 | 禁用 |
| 3DES 算法 | 可用 | 禁用 | 禁用 | 禁用 |
| RC4 算法 | 可用 | 禁用 | 禁用 | 禁用 |
| 弱 DH 密钥 | 允许 | >= 2048 bit | >= 2048 bit | >= 2048 bit |
| 量子安全算法 | 无 | 无 | 无 | ML-DSA (JEP 497) |
JDK 25 特别值得关注的安全特性:
- 量子抗性算法 ML-DSA:JDK 24 引入的 Module-Lattice-Based Digital Signature Algorithm,遵循 NIST FIPS 204 标准,为后量子计算时代做准备
- Key Derivation Function API(JEP 506):标准化的密钥派生函数 API
- PEM Encodings(JEP 470,预览):加密对象的 PEM 编码支持
迁移时的安全坑:
bash
# 问题:JDK 8 升级到 JDK 17 后,连接老旧的 SSL 服务失败
# 原因:JDK 17 默认禁用了 TLS 1.0/1.1 和弱加密算法
# 临时解决(不推荐长期使用):
java -Djdk.tls.disabledAlgorithms="" -jar myapp.jar
# 正确做法:升级对端的 TLS 配置强封装的影响:
JDK 17 起,--illegal-access 选项被彻底移除。所有对 JDK 内部 API 的反射访问默认被拒绝。这对 Spring、Hibernate、Lombok 等框架有直接影响。各框架的适配版本:
| 框架/工具 | 支持 JDK 17 的最低版本 | 支持 JDK 21 的最低版本 |
|---|---|---|
| Spring Framework | 5.3.x (兼容) / 6.0 (原生) | 6.1 |
| Spring Boot | 2.7.x (兼容) / 3.0 (原生) | 3.2 |
| Hibernate | 5.6 (兼容) / 6.0 (原生) | 6.4 |
| Lombok | 1.18.22 | 1.18.30 |
| MyBatis | 3.5.9 | 3.5.14 |
| Jackson | 2.13 | 2.16 |
八、生产环境迁移实践
8.1 JDK 8 → JDK 17 迁移
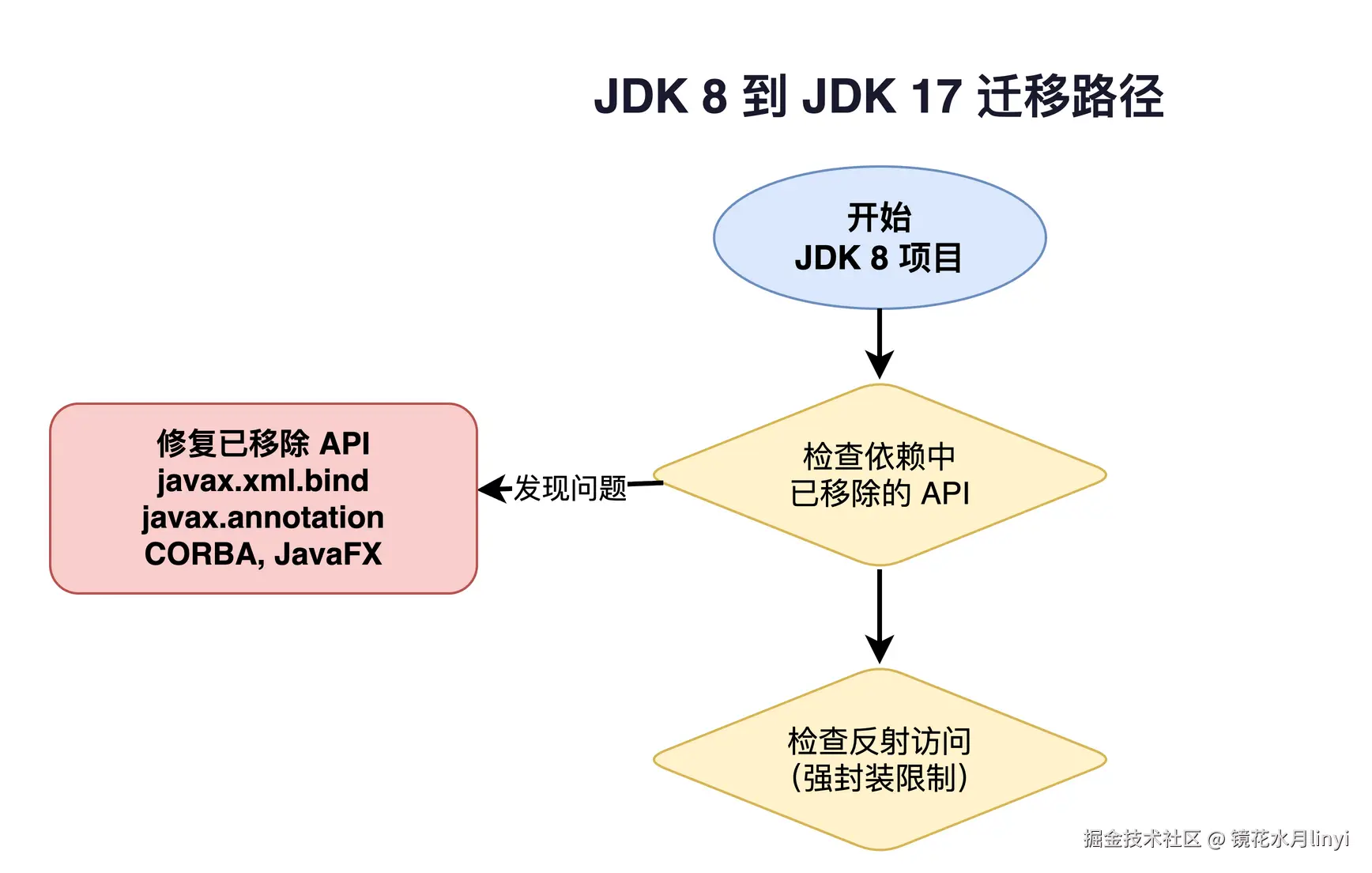
这是跨度最大也最痛苦的一次迁移。我总结了我们团队踩过的主要坑:
第一步:依赖分析
bash
# 使用 jdeps 分析你的代码对 JDK 内部 API 的依赖
jdeps --jdk-internals -R --class-path 'libs/*' myapp.jar
# 输出示例:
# myapp.jar -> java.base
# com.myapp.util.UnsafeHelper -> sun.misc.Unsafe JDK internal API (jdk.unsupported)
# com.myapp.xml.Parser -> com.sun.org.apache.xerces.internal.jaxp JDK internal API第二步:处理 Breaking Changes
核心问题清单:
| 问题 | 表现 | 解决方案 |
|---|---|---|
| javax.* 命名空间变更 | 编译失败 | Spring Boot 3.x 需要 Jakarta EE 9+(javax → jakarta) |
| sun.misc.Unsafe | 运行时警告/异常 | 使用 VarHandle 替代 |
| 反射访问 JDK 内部类 | InaccessibleObjectException | 添加 --add-opens 或更换实现 |
| JavaFX 移除 | 编译/运行失败 | 单独引入 OpenJFX 依赖 |
| Nashorn 移除 | ScriptEngine 找不到 | 使用 GraalJS 替代 |
| Java EE 模块移除 | ClassNotFoundException | 引入 jakarta.xml.bind 等依赖 |
| SecurityManager 废弃 | 运行时警告 | 使用其他安全方案 |
第三步:Spring Boot 升级路径
如果你在用 Spring Boot,升级路径是:
scss
Spring Boot 2.x (JDK 8)
→ Spring Boot 2.7.x (JDK 17 兼容模式)
→ Spring Boot 3.0+ (JDK 17 原生支持, javax → jakarta)Spring Boot 3.0 的 javax → jakarta 迁移是最大的工作量。可以用 OpenRewrite 自动化:
xml
<!-- pom.xml 中添加 OpenRewrite 插件 -->
<plugin>
<groupId>org.openrewrite.maven</groupId>
<artifactId>rewrite-maven-plugin</artifactId>
<version>5.37.0</version>
<configuration>
<activeRecipes>
<recipe>org.openrewrite.java.spring.boot3.UpgradeSpringBoot_3_0</recipe>
</activeRecipes>
</configuration>
<dependencies>
<dependency>
<groupId>org.openrewrite.recipe</groupId>
<artifactId>rewrite-spring</artifactId>
<version>5.16.0</version>
</dependency>
</dependencies>
</plugin>
bash
# 执行自动迁移
mvn rewrite:run第四步:JVM 参数清理
很多 JDK 8 的 JVM 参数在 JDK 17 中已经被移除或改变:
bash
# JDK 8 参数 → JDK 17 处理方式
-XX:+UseConcMarkSweepGC → 移除(CMS 已删除),改用 -XX:+UseG1GC
-XX:+UseParNewGC → 移除,G1 自动处理
-XX:CMSInitiatingOccupancyFraction=75 → 移除
-XX:+PrintGCDetails → 改用 -Xlog:gc*
-XX:+PrintGCDateStamps → 改用 -Xlog:gc*:time
-XX:+UseGCLogFileRotation → 改用 -Xlog:gc*:file=gc.log:time:filecount=5,filesize=10m
-XX:PermSize=256m → 移除(PermGen 不存在了)
-XX:MaxPermSize=512m → 移除(可选 -XX:MaxMetaspaceSize)
bash
# JDK 8 典型 JVM 参数
java -Xms4g -Xmx4g \
-XX:+UseConcMarkSweepGC \
-XX:+CMSParallelRemarkEnabled \
-XX:CMSInitiatingOccupancyFraction=75 \
-XX:+UseCMSInitiatingOccupancyOnly \
-XX:+PrintGCDetails \
-XX:+PrintGCDateStamps \
-Xloggc:/var/log/gc.log \
-XX:PermSize=256m \
-XX:MaxPermSize=512m \
-jar myapp.jar
# 等价的 JDK 17 JVM 参数
java -Xms4g -Xmx4g \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=100 \
-Xlog:gc*:file=/var/log/gc.log:time:filecount=5,filesize=20m \
-XX:MaxMetaspaceSize=512m \
--add-opens java.base/java.lang=ALL-UNNAMED \
-jar myapp.jar8.2 JDK 17 → JDK 21 迁移
相比 8 → 17,这次迁移平滑得多。主要关注点:
- Virtual Threads 的引入策略:不要一刀切。先在非核心链路试点,确认没有 pinning 问题后再推广。
- Sequenced Collections:纯增量变化,无 breaking change。
- Pattern Matching for switch:逐步替换 if-else 链。
java
// 迁移示例:引入 Virtual Threads 到 Spring Boot
// application.yml (Spring Boot 3.2+)
spring:
threads:
virtual:
enabled: true
// 这一行配置会让 Tomcat 的请求处理线程使用 Virtual ThreadsJDK 21 的 GC 迁移建议:
bash
# 如果你在 JDK 17 上使用 G1,JDK 21 可以直接沿用
# 如果你想尝试 Generational ZGC:
java -XX:+UseZGC -XX:+ZGenerational -Xms8g -Xmx8g -jar myapp.jar
# 注意:ZGC 需要更多的堆外内存,建议容器内存设为堆内存的 1.5-2 倍8.3 性能基准对比
 以下是我们在相同硬件(8 核 16G,Intel Xeon E5-2686 v4)上的实测数据:
以下是我们在相同硬件(8 核 16G,Intel Xeon E5-2686 v4)上的实测数据:
吞吐量测试(模拟电商下单接口,100 并发持续 5 分钟):
| JDK 版本 | GC 配置 | QPS | P50 延迟 | P99 延迟 | P999 延迟 |
|---|---|---|---|---|---|
| JDK 8 (CMS) | 4G 堆 | 8,200 | 8ms | 45ms | 280ms |
| JDK 8 (G1) | 4G 堆 | 8,500 | 7ms | 38ms | 150ms |
| JDK 17 (G1) | 4G 堆 | 10,100 | 6ms | 28ms | 85ms |
| JDK 21 (G1) | 4G 堆 | 10,800 | 5ms | 25ms | 70ms |
| JDK 21 (ZGC) | 8G 堆 | 10,200 | 5ms | 12ms | 18ms |
| JDK 25 (ZGC + COH) | 8G 堆 | 11,500 | 4ms | 10ms | 15ms |
COH = Compact Object Headers
几个值得注意的数据:
- JDK 8 → JDK 17 (G1):QPS 提升 ~23%,P99 降低 ~38%
- JDK 17 → JDK 21 (G1):QPS 提升 ~7%,长尾延迟改善明显
- ZGC 的 P999 比 G1 好 4 倍,但需要更大的堆
- Compact Object Headers 在大量小对象的场景下额外带来 ~5% 的吞吐量提升
九、版本选型建议
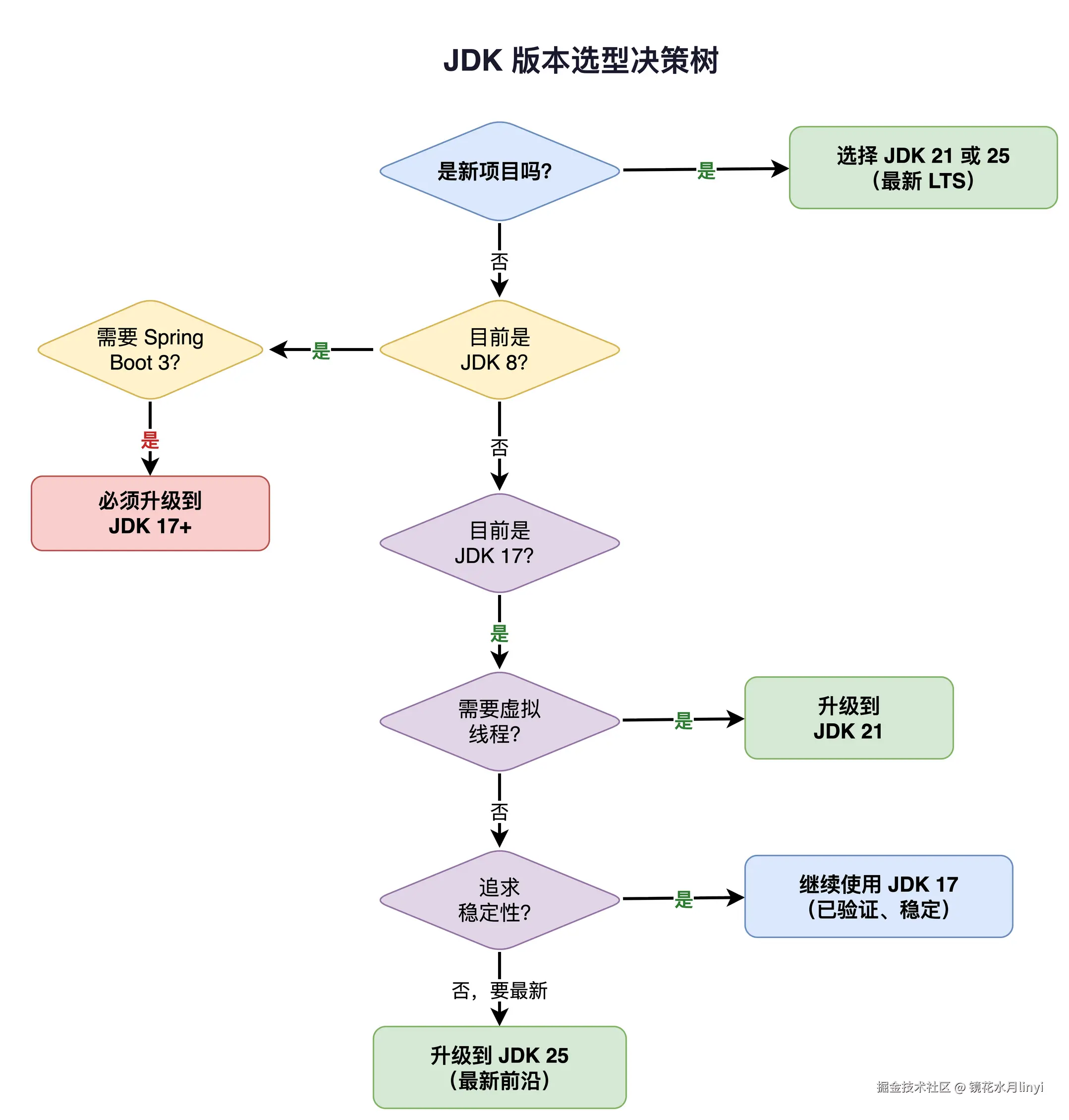 决策矩阵:
决策矩阵:
| 考虑因素 | 留在 JDK 8 | 升级到 JDK 17 | 升级到 JDK 21 | 升级到 JDK 25 |
|---|---|---|---|---|
| 遗留系统无人维护 | 可以 | - | - | - |
| Spring Boot 2.x | 可以 | 推荐(2.7.x) | - | - |
| Spring Boot 3.x | 不行 | 最低要求 | 推荐 | 推荐 |
| 需要 Virtual Threads | 不行 | 不行 | 推荐 | 推荐 |
| 高并发 I/O 密集型 | - | - | 强烈推荐 | 强烈推荐 |
| 需要亚毫秒 GC 停顿 | 不行 | ZGC 可选 | 推荐(分代 ZGC) | 推荐 |
| 容器/K8s 环境 | 可用 | 推荐 | 推荐 | 强烈推荐(COH) |
| 对启动时间敏感 | - | CDS | CDS | AOT Cache |
| 安全合规要求高 | 有风险 | 可以 | 推荐 | 推荐(量子安全) |
| 团队 Java 技术栈新 | - | - | - | 直接上 |
我的建议:
-
如果你还在 JDK 8 上:2025 年了,尽快升级。JDK 8 的公共更新在 2019 年就停止了(Oracle JDK),安全补丁需要依赖第三方发行版。直接瞄准 JDK 21 或 JDK 25,因为 JDK 17 到 JDK 21 的增量迁移成本很低。
-
如果你在 JDK 17 上:JDK 21 的 Virtual Threads 是值得升级的理由,特别是 I/O 密集型应用。JDK 25 作为最新 LTS 更好。
-
新项目:直接用 JDK 25。
-
Spring Boot 兼容性速查:
- Spring Boot 3.0-3.1:JDK 17 最低,支持到 JDK 20
- Spring Boot 3.2-3.3:JDK 17 最低,支持到 JDK 22
- Spring Boot 3.4+:JDK 17 最低,支持到 JDK 25
参考资料
- JDK 8 Features - Oracle
- JDK 17 Release Notes - Oracle
- JDK 21 JEP Index - OpenJDK
- JDK 25 JEP Index - OpenJDK
- JEP 444: Virtual Threads
- JEP 439: Generational ZGC
- JEP 519: Compact Object Headers
- JEP 506: Scoped Values
- JEP 513: Flexible Constructor Bodies
- JEP 512: Compact Source Files and Instance Main Methods
- JEP 511: Module Import Declarations
- JEP 521: Generational Shenandoah
- JEP 515: AOT Method Profiling
- JEP 502: Stable Values (Preview)
- JEP 485: Stream Gatherers
- JEP 484: Class-File API
- JEP 491: Synchronize Virtual Threads without Pinning
- JEP 483: Ahead-of-Time Class Loading & Linking
- JEP 490: Remove Non-Generational ZGC
- JEP 497: Quantum-Resistant ML-DSA
- JEP 254: Compact Strings
- JEP 310: Application Class-Data Sharing
- JEP 350: Dynamic CDS Archives
- Project Loom - OpenJDK
- Project Panama - OpenJDK
- Project Leyden - OpenJDK
- Project Valhalla - OpenJDK
- Project Lilliput - OpenJDK
- Spring Boot System Requirements
- OpenRewrite Spring Boot 3 Migration