线上业务的数据库性能瓶颈,80%以上都源于慢SQL。很多开发者面对慢SQL,只会盲目加索引,反而引发索引维护成本高、优化器选错索引等更多问题。
一、慢SQL的全链路发现与定位流程
优化的第一步是精准定位慢SQL,而非上来就盲目改写。只有先找到高频、高影响的慢SQL,才能针对性解决问题,避免无效优化。
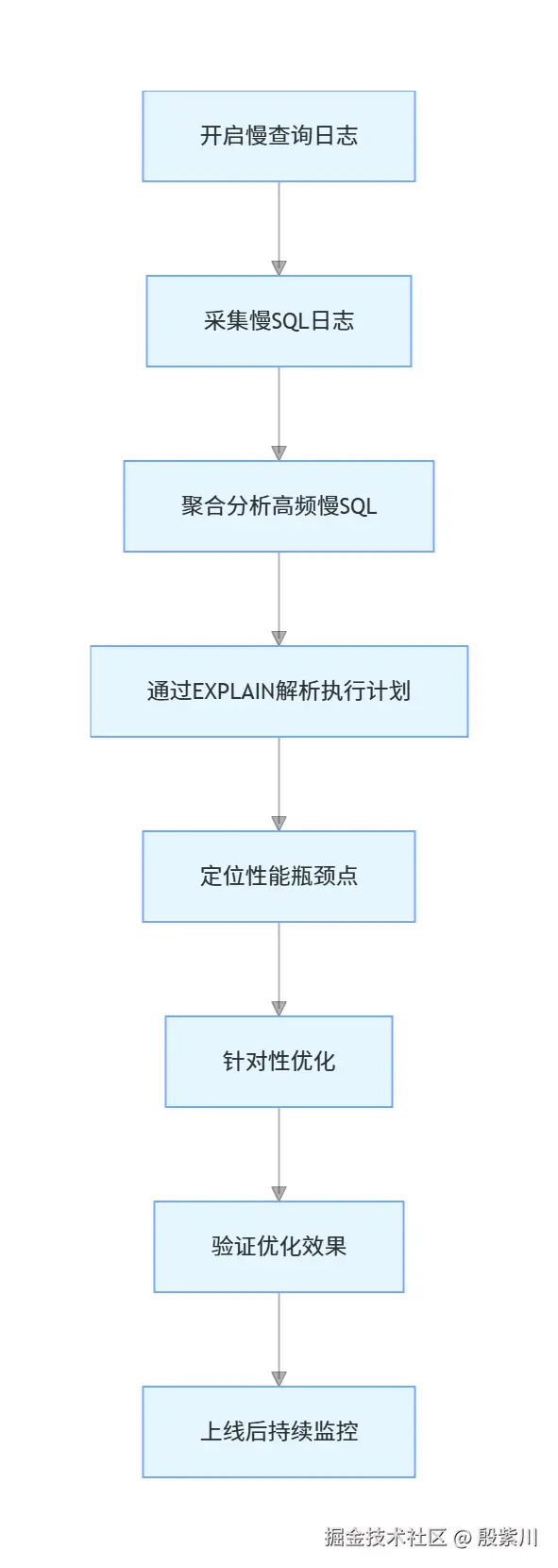
1.1 慢查询日志的正确配置
慢查询日志是MySQL内置的慢SQL采集工具,会记录执行时间超过阈值的SQL语句,是定位慢SQL的核心手段。以下为MySQL 8.0的生产级配置规范:
临时配置(重启后失效,用于临时排查)
ini
-- 开启慢查询日志
set global slow_query_log = 'ON';
-- 慢SQL阈值,单位秒,生产环境建议设置为1秒,核心场景可设为0.5秒
set global long_query_time = 1;
-- 日志输出方式,FILE为文件输出,TABLE为系统表输出
set global log_output = 'FILE';
-- 关闭无索引SQL的强制记录,避免日志刷满,仅配合最小扫描行数限制使用
set global log_queries_not_using_indexes = 'OFF';
-- 仅记录扫描行数超过1000行的SQL,过滤无效小表查询
set global min_examined_row_limit = 1000;永久配置(写入my.cnf/my.ini配置文件)
ini
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/mysql-slow.log
long_query_time = 1
log_output = FILE
log_queries_not_using_indexes = OFF
min_examined_row_limit = 1000❝
核心注意点:
log_queries_not_using_indexes不可长期开启,否则会将所有未使用索引的SQL(哪怕执行仅几毫秒)全部写入日志,导致磁盘空间被快速占满,仅在全量索引排查时临时开启。
1.2 补充定位手段
除慢查询日志外,还有3种高频定位方式,覆盖不同场景:
- performance_schema与sys库 :MySQL 8.0默认开启,可通过
sys.schema_unused_indexes查看无用索引,sys.statement_analysis聚合分析全量SQL的执行耗时、扫描行数等指标,无需开启慢查询日志即可使用。 - show processlist:实时查看数据库当前正在执行的线程,快速定位长执行时间的SQL、死锁与阻塞问题。
- APM全链路监控工具:如SkyWalking、Prometheus+Grafana等,可从业务请求维度追踪慢SQL,关联接口调用上下文,定位线上业务的慢SQL根因。
二、EXPLAIN执行计划:慢SQL优化的核心抓手
定位到慢SQL后,第一步必须通过EXPLAIN解析SQL的执行计划,看懂MySQL优化器是如何执行SQL的,才能精准找到性能瓶颈,而非凭感觉改写。
EXPLAIN的使用方式非常简单,只需在SQL语句前加上EXPLAIN关键字即可,MySQL 8.0还支持EXPLAIN FORMAT=JSON,可输出更详细的成本估算信息。
ini
EXPLAIN SELECT * FROM t_user_order WHERE user_id = 1001;本文所有示例均基于以下订单表,可直接在MySQL 8.0中执行创建:
sql
CREATE TABLE `t_user_order` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`order_no` varchar(32) NOT NULL COMMENT '订单编号',
`user_id` bigint NOT NULL COMMENT '用户ID',
`order_status` tinyint NOT NULL DEFAULT '0' COMMENT '订单状态:0-待付款,1-已付款,2-已取消',
`order_amount` decimal(10,2) NOT NULL COMMENT '订单金额',
`pay_time` datetime DEFAULT NULL COMMENT '支付时间',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`),
KEY `idx_userid_status` (`user_id`,`order_status`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户订单表';
INSERT INTO `t_user_order` (`order_no`, `user_id`, `order_status`, `order_amount`, `pay_time`, `remark`)
VALUES
('ORD202401010001', 1001, 1, 99.00, '2024-01-01 10:00:00', '正常订单'),
('ORD202401010002', 1001, 0, 199.00, NULL, '待付款订单'),
('ORD202401010003', 1002, 1, 299.00, '2024-01-01 11:00:00', '正常订单'),
('ORD202401010004', 1003, 2, 399.00, '2024-01-01 12:00:00', '已取消订单');2.1 执行计划核心字段全解析
EXPLAIN的输出结果包含12个字段,其中对优化最关键的有type、key、key_len、rows、Extra,下面逐一拆解核心字段的含义与判断标准。
1. id:SQL执行顺序标识
id值表示SQL的执行优先级,id值越大,越先执行;id值相同,从上到下依次执行。
- 子查询的id值会大于外层主查询,优先执行子查询
- 联合查询
UNION的结果集id为NULL,最后执行
2. select_type:查询类型
用于区分当前行是普通查询、子查询、联合查询还是派生表查询,核心类型如下:
SIMPLE:简单查询,不包含子查询、UNIONPRIMARY:主查询,外层的查询语句SUBQUERY:包含在SELECT/WHERE中的子查询DERIVED:派生表查询,包含在FROM中的子查询UNION/UNION RESULT:联合查询及其结果合并
3. type:访问类型(核心中的核心)
type表示MySQL在表中找到目标行的访问方式,直接决定了SQL的查询性能 ,性能从优到劣依次为: system > const > eq_ref > ref > range > index > ALL
优化的最低目标是让SQL达到range级别,核心业务场景尽量达到ref级别,必须杜绝ALL全表扫描。
| 类型 | 含义与场景 | 示例 |
|---|---|---|
| system | 系统表,表中仅有一行数据,极少出现 | 查mysql系统表 |
| const | 主键/唯一索引的等值查询,最多匹配一行数据,性能最优 | SELECT * FROM t_user_order WHERE id = 1; |
| eq_ref | 主键/唯一索引的关联查询,关联的每行仅匹配一条结果 | SELECT a.* FROM t_user_order a JOIN t_user_order b ON a.id = b.id; |
| ref | 非唯一索引的等值查询,可匹配多行数据 | SELECT * FROM t_user_order WHERE user_id = 1001; |
| range | 索引范围查询,包含between、>、<、in、or等 |
SELECT * FROM t_user_order WHERE create_time >= '2024-01-01'; |
| index | 遍历整个索引树,无需回表,比全表扫描略好,因为索引文件小于数据文件 | SELECT id FROM t_user_order; |
| ALL | 全表扫描,遍历聚簇索引的所有叶子节点,性能最差,必须优化 | SELECT * FROM t_user_order WHERE remark = '测试'; |
4. possible_keys与key
possible_keys:MySQL优化器候选的、可能用到的索引列表key:MySQL优化器最终实际使用的索引,为NULL表示未使用索引
❝
核心判断:如果
possible_keys有值,但key为NULL,说明出现了索引失效,是优化的核心关注点。
5. key_len:索引使用长度
key_len表示MySQL使用的索引字节长度,可通过该值精准判断联合索引用到了哪些列,是验证最左前缀原则的核心依据。
MySQL 8.0 索引长度计算规则:
- 数值类型:
tinyint=1、smallint=2、int=4、bigint=8 - 时间类型:
datetime=5(MySQL 5.6+)、timestamp=4 - 字符串类型:
varchar(n)=n*4(utf8mb4字符集,单字符4字节) +2(变长字段长度标识) +1(允许NULL值);char(n)=n*4+1(允许NULL值)
示例:联合索引idx_userid_status (user_id bigint not null, order_status tinyint not null)
- 仅
user_id等值查询:key_len=8,仅用到第一列 user_id + order_status等值查询:key_len=9,用到了全部两列
6. rows:预估扫描行数
rows是MySQL优化器估算的、为了找到目标行需要扫描的行数,该值越小越好。
- 全表扫描时,
rows为表的总行数 - 索引查询时,
rows为索引匹配的预估行数 - 该值是优化器选择索引的核心依据,统计信息不准确会导致该值偏差,引发优化器选错索引
7. filtered:行过滤比例
filtered表示返回结果的行数占扫描行数的百分比,该值越大越好,最大值为100。
- 100表示扫描的所有行都符合过滤条件,无无效扫描
- 1表示扫描100行仅返回1行,过滤效率极低,需要优化索引或过滤条件
8. Extra:额外信息(性能预警核心)
Extra包含了SQL执行的额外细节,藏着大量性能风险点,核心关键项如下:
Using index:覆盖索引,查询的所有列都包含在索引中,无需回表查询聚簇索引,性能极佳,是优化的核心目标。 示例:SELECT user_id, order_status FROM t_user_order WHERE user_id = 1001;Using where:存储引擎返回行后,在Server层进行过滤,通常是过滤条件未命中索引。Using filesort:文件排序,MySQL无法通过索引完成排序,只能在内存或磁盘中进行排序,性能极差,必须优化。 示例:SELECT * FROM t_user_order WHERE user_id = 1001 ORDER BY remark;Using temporary:使用临时表存储中间结果,常见于GROUP BY、ORDER BY使用了非索引列,性能极差,必须优化。 示例:SELECT order_status, COUNT(*) FROM t_user_order GROUP BY remark;Using index condition:索引条件下推(ICP),在存储引擎层就通过索引条件过滤数据,无需回表,减少IO开销。
三、索引失效的10大高频场景与根因拆解
很多时候,明明建了索引,SQL却还是全表扫描,核心原因就是索引失效。索引失效的本质是:MySQL优化器认为使用索引的查询成本高于全表扫描,因此放弃了索引,选择全表扫描。
下面拆解线上最高频的10大索引失效场景,每个场景都包含错误示例、正确改写与底层原理解析。
3.1 索引列上使用函数或表达式计算
底层原理:B+树中存储的是索引列的原始值,而非函数计算后的值,MySQL无法通过索引树定位到计算后的结果,只能全表扫描后逐行计算过滤。
错误示例:
sql
EXPLAIN SELECT * FROM t_user_order WHERE DATE(create_time) = '2024-01-01';create_time建有索引idx_create_time,但使用了DATE()函数,索引完全失效,type=ALL。
正确改写:
sql
EXPLAIN SELECT * FROM t_user_order WHERE create_time >= '2024-01-01' AND create_time < '2024-01-02';将计算转移到常量端,保留索引列的原始值,type=range,成功命中索引。
扩展方案:MySQL 8.0支持函数索引,可针对计算后的结果建索引:
scss
CREATE INDEX idx_date_create_time ON t_user_order((DATE(create_time)));3.2 隐式类型转换
底层原理 :当索引列的类型与查询值的类型不一致时,MySQL会自动对索引列做隐式类型转换,相当于在索引列上执行了函数,直接导致索引失效。线上最高发的场景:varchar类型字段用数字查询。
错误示例:
ini
EXPLAIN SELECT * FROM t_user_order WHERE order_no = 202401010001;order_no是varchar类型,建有唯一索引uk_order_no,但查询值为数字,MySQL对order_no做了隐式数字转换,索引失效,type=ALL。
正确改写:
ini
EXPLAIN SELECT * FROM t_user_order WHERE order_no = '202401010001';查询值添加引号,与索引列类型匹配,type=const,成功命中唯一索引。
❝
关键区分:数字类型字段用字符串查询,不会导致索引失效!例如
user_id是bigint类型,WHERE user_id = '1001',MySQL仅会对常量字符串做转换,不影响索引列,索引依然有效。
3.3 模糊查询左通配/前后通配
底层原理:B+树的索引是按前缀有序排列的,左通配或前后通配无法确定索引前缀,MySQL无法通过索引树快速定位,只能全表扫描。
错误示例:
sql
-- 左通配,索引失效
EXPLAIN SELECT * FROM t_user_order WHERE order_no LIKE '%0001';
-- 前后通配,索引失效
EXPLAIN SELECT * FROM t_user_order WHERE order_no LIKE '%0001%';正确改写:
sql
-- 右通配,前缀确定,成功命中索引
EXPLAIN SELECT * FROM t_user_order WHERE order_no LIKE 'ORD2024%';type=range,成功命中索引。
扩展方案:必须使用左通配时,可使用倒序索引适配:
sql
-- 创建倒序索引
CREATE INDEX idx_order_no_reverse ON t_user_order(REVERSE(order_no));
-- 倒序查询,命中索引
EXPLAIN SELECT * FROM t_user_order WHERE REVERSE(order_no) LIKE REVERSE('%0001');3.4 联合索引不满足最左前缀原则
底层原理:联合索引的B+树是按索引列的顺序排序的,先按第一列排序,第一列相同时再按第二列排序,以此类推。查询时必须从左到右匹配索引列,跳过中间列后,后续列无法命中索引。
以联合索引idx_userid_status (user_id, order_status)为例: 有效场景:
sql
-- 匹配第一列,命中索引
EXPLAIN SELECT * FROM t_user_order WHERE user_id = 1001;
-- 匹配全部两列,命中索引
EXPLAIN SELECT * FROM t_user_order WHERE user_id = 1001 AND order_status = 1;失效场景:
ini
-- 跳过第一列,完全无法命中索引,type=ALL
EXPLAIN SELECT * FROM t_user_order WHERE order_status = 1;
-- 第一列使用范围查询,后续列无法命中索引,key_len=8,仅用到第一列
EXPLAIN SELECT * FROM t_user_order WHERE user_id > 1000 AND order_status = 1;优化技巧:联合索引设计时,将等值查询的列放在前面,范围查询的列放在最后,避免范围查询导致后续列失效。
3.5 使用OR连接非索引列条件
底层原理 :OR的查询条件中,只要有一个列没有索引,MySQL就会放弃索引,直接全表扫描。因为需要找到满足任意一个条件的行,非索引列必须全表扫描,优化器认为直接全表扫描的成本更低。
错误示例:
sql
-- user_id有索引,remark无索引,OR连接后索引失效
EXPLAIN SELECT * FROM t_user_order WHERE user_id = 1001 OR remark = '测试';type=ALL,索引完全失效。
正确改写 :使用UNION ALL替代OR
sql
EXPLAIN
SELECT * FROM t_user_order WHERE user_id = 1001
UNION ALL
SELECT * FROM t_user_order WHERE remark = '测试';前半部分命中索引,后半部分仅扫描符合条件的行,整体性能远高于全表扫描。
❝
注意:如果
OR两边的列都建有索引,MySQL会使用index merge索引合并优化,同时命中两个索引,不会失效。
3.6 优化器选错索引
底层原理:MySQL优化器基于成本估算选择索引,会计算每个索引的扫描成本、回表成本,选择成本最低的索引。但当表的统计信息不准确、索引区分度过低时,会导致优化器选错索引,甚至放弃合适的索引选择全表扫描。
常见根因:
- 表数据大量插入、删除、更新后,未及时更新统计信息
- 索引列区分度过低,优化器认为回表成本高于全表扫描
- 查询结果集占表总行数比例过高,回表IO开销过大
解决方案:
- 手动更新表统计信息:
ANALYZE TABLE t_user_order; - 优化索引为覆盖索引,避免回表操作
- 极端场景可使用
FORCE INDEX强制指定索引,不推荐长期使用
3.7 负向查询导致索引失效
底层原理 :NOT IN、!=、<>、NOT EXISTS等负向查询,无法利用B+树的有序性快速定位数据,优化器通常会选择全表扫描。
错误示例:
sql
EXPLAIN SELECT * FROM t_user_order WHERE user_id != 1001;
EXPLAIN SELECT * FROM t_user_order WHERE user_id NOT IN (1001,1002);通常会索引失效,type=ALL。
优化方案 :小范围负向查询可改写为正向IN查询;大范围查询可使用覆盖索引减少IO开销。
3.8 关联查询字符集不匹配导致隐式转换
底层原理 :关联查询时,两个表的关联字段字符集不一致,例如一个是utf8mb4,一个是utf8,MySQL会对索引列做字符集转换,相当于在索引列上执行函数,导致索引失效,是线上非常隐蔽的慢SQL坑。
示例 :a表order_no为utf8mb4,b表order_no为utf8,关联查询ON a.order_no = b.order_no,a表的索引会完全失效。
解决方案 :统一关联表的字符集为utf8mb4,确保关联字段类型、字符集完全一致。
3.9 索引列使用IS NOT NULL的边界场景
很多开发者认为IS NULL/IS NOT NULL会导致索引失效,这是错误的。MySQL 8.0中,IS NULL可以正常命中索引,IS NOT NULL在大多数场景下也能命中索引,只有当查询结果集占表总行数比例过高时,优化器才会放弃索引选择全表扫描。
有效示例:
sql
-- pay_time允许NULL,建有索引,可正常命中
EXPLAIN SELECT * FROM t_user_order WHERE pay_time IS NULL;3.10 重复索引与冗余索引
重复索引与冗余索引不会直接导致索引失效,但会增加优化器的索引选择成本,同时大幅降低插入、更新、删除的性能,间接引发慢SQL。
- 重复索引:例如已有唯一索引
uk_order_no,又重复创建了索引idx_order_no - 冗余索引:例如已有联合索引
idx_userid_status (user_id, order_status),又创建了索引idx_user_id (user_id),联合索引已满足最左前缀匹配,属于冗余索引
四、SQL改写的8大实战技巧
定位到性能瓶颈后,SQL改写是成本最低、见效最快的优化手段。下面拆解线上最高频的8大慢SQL场景,配合前后改写对比,实现性能量级提升。
4.1 深分页优化
线上最高发的慢SQL场景之一,limit 100000, 20这类深分页查询,越往后翻页性能越差。因为MySQL需要扫描前100020行,然后丢弃前100000行,仅返回20行,扫描行数巨大,IO开销极高。
错误示例:
sql
SELECT * FROM t_user_order WHERE order_status = 1 ORDER BY create_time DESC LIMIT 100000, 20;正确改写1:书签式分页(推荐) 利用上一页的最大排序值过滤数据,避免扫描前面的无效行,是目前性能最优的分页方案。
sql
SELECT * FROM t_user_order
WHERE order_status = 1 AND create_time < '上一页最后一条的create_time'
ORDER BY create_time DESC LIMIT 20;type=range,仅需扫描目标20行附近的数据,扫描行数减少数万倍。
正确改写2:子查询先查主键,再关联回表 适用于无法使用书签式分页的场景,先通过覆盖索引查到目标主键,再关联回表查询数据,避免全表回表扫描。
sql
SELECT a.* FROM t_user_order a
INNER JOIN (SELECT id FROM t_user_order WHERE order_status = 1 ORDER BY create_time DESC LIMIT 100000, 20) b
ON a.id = b.id;子查询使用覆盖索引,无需回表,仅需扫描索引树,性能大幅提升。
4.2 子查询改JOIN优化
MySQL 5.5及之前的版本,WHERE IN子查询会被改写为相关子查询,性能极差;MySQL 8.0虽做了优化,但多表关联场景下,JOIN的执行计划依然更稳定,性能更优。
错误示例:
sql
SELECT * FROM t_user_order WHERE user_id IN (SELECT user_id FROM t_user_order WHERE order_status = 2);正确改写:
css
SELECT DISTINCT a.* FROM t_user_order a
INNER JOIN t_user_order b ON a.user_id = b.user_id
WHERE b.order_status = 2;优化器可自主选择驱动表与被驱动表,利用索引优化关联查询,避免子查询的临时表开销。
4.3 消除Using filesort与Using temporary
Using filesort文件排序与Using temporary临时表,是SQL性能的两大杀手,核心优化原则是:让GROUP BY、ORDER BY的字段顺序与联合索引的顺序完全匹配,利用索引的天然有序性,避免额外的排序与临时表操作。
错误示例:
vbnet
-- 排序字段不在索引中,产生Using filesort
SELECT * FROM t_user_order WHERE user_id = 1001 ORDER BY order_status, create_time;现有联合索引idx_userid_status (user_id, order_status),create_time不在索引中,无法利用索引排序,产生文件排序。
优化方案:调整联合索引,将排序字段加入索引,完全匹配查询顺序。
scss
-- 创建适配的联合索引
CREATE INDEX idx_userid_status_create ON t_user_order(user_id, order_status, create_time);调整后,WHERE与ORDER BY完全符合最左前缀原则,Using filesort完全消除。
4.4 避免SELECT *,使用覆盖索引
SELECT *是开发中最常见的坏习惯,会导致无法使用覆盖索引,必须回表查询聚簇索引的完整行数据,IO开销大幅增加。
错误示例:
ini
SELECT * FROM t_user_order WHERE user_id = 1001 AND order_status = 1;虽命中索引,但需要回表查询所有列,无Using index覆盖索引标识。
正确改写:仅查询业务需要的列,将查询列加入索引,实现覆盖索引。
sql
-- 仅查询需要的列
SELECT user_id, order_status, order_no, order_amount FROM t_user_order WHERE user_id = 1001 AND order_status = 1;
scss
-- 创建覆盖索引
CREATE INDEX idx_userid_status_cover ON t_user_order(user_id, order_status, order_no, order_amount);改写后,Extra出现Using index,无需回表,性能提升10倍以上。
4.5 去重优化,避免DISTINCT滥用
DISTINCT需要对结果集进行排序去重,会产生额外的CPU与内存开销,甚至临时表,多表关联场景下,使用EXISTS替代DISTINCT,性能更优。
错误示例:
css
SELECT DISTINCT a.user_id FROM t_user_order a JOIN t_user_order b ON a.user_id = b.user_id WHERE b.order_status = 2;正确改写:
css
SELECT a.user_id FROM t_user_order a WHERE EXISTS (SELECT 1 FROM t_user_order b WHERE a.user_id = b.user_id AND b.order_status = 2);EXISTS找到匹配行后立即返回,无需全量去重,执行效率远高于DISTINCT。
4.6 JOIN查询优化
MySQL的JOIN默认使用Nested Loop Join嵌套循环算法,核心优化原则是小表驱动大表,驱动表的行数越少,循环次数越少,性能越好。
核心优化规范:
- 确保被驱动表的关联字段建有索引,这是JOIN优化的基础
- 避免超过3个表的JOIN,表关联越多,优化器执行计划选择的偏差越大
- 关联查询前先过滤数据,减少参与JOIN的行数,避免大表全量关联
4.7 批量操作优化,避免循环执行SQL
线上高频性能坑:在Java代码的循环中,每次循环执行一条INSERT/UPDATE/SELECT语句,导致大量数据库网络交互,连接开销巨大,同时产生大量慢SQL。
错误示例:循环单条插入
sql
INSERT INTO t_user_order (order_no, user_id, order_status, order_amount) VALUES ('ORD001', 1001, 1, 99.00);
INSERT INTO t_user_order (order_no, user_id, order_status, order_amount) VALUES ('ORD002', 1002, 1, 199.00);
INSERT INTO t_user_order (order_no, user_id, order_status, order_amount) VALUES ('ORD003', 1003, 1, 299.00);正确改写:批量插入
sql
INSERT INTO t_user_order (order_no, user_id, order_status, order_amount)
VALUES
('ORD001', 1001, 1, 99.00),
('ORD002', 1002, 1, 199.00),
('ORD003', 1003, 1, 299.00);批量操作仅需一次数据库交互,性能提升数十倍。批量操作建议每次批量1000条以内,避免SQL过长导致解析开销过大。
4.8 用CTE优化复杂子查询
MySQL 8.0支持WITH CTE(公共表达式),可将复杂的多层子查询拆分为多个清晰的CTE,代码可读性更高,同时优化器可对CTE进行更好的优化,避免多层子查询的临时表嵌套。
示例:
vbnet
WITH user_order_stats AS (
SELECT user_id, COUNT(*) AS order_count, SUM(order_amount) AS total_amount
FROM t_user_order
WHERE order_status = 1
GROUP BY user_id
)
SELECT * FROM user_order_stats WHERE order_count > 10;五、表结构设计:慢SQL优化的根源性解决方案
80%的慢SQL,根源都在于不合理的表结构设计。不合理的字段类型、错误的主键设计、冗余的大字段,会导致索引效率低下、IO开销巨大,仅靠SQL改写与索引优化无法从根本上解决问题。
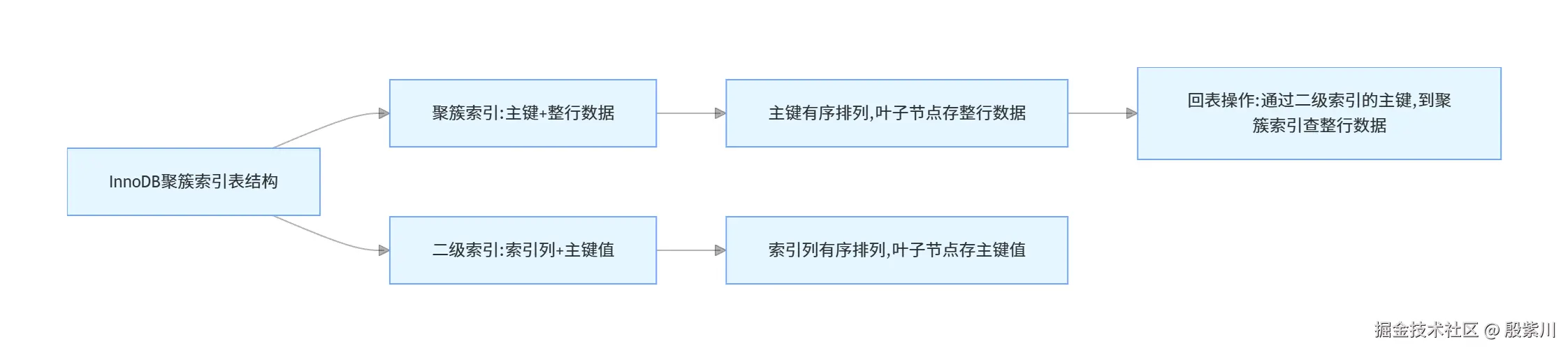
InnoDB是索引组织表,聚簇索引的叶子节点就是完整的行数据,表结构设计直接决定了索引的效率与查询性能。下面拆解核心设计规范,从根源上规避慢SQL。
5.1 主键设计规范
主键是InnoDB表的核心,直接决定了聚簇索引的结构,设计错误会引发页分裂、索引膨胀、插入性能下降等一系列问题。
核心规范:
- 必须显式定义主键,禁止无主键的表。无主键的表,InnoDB会隐式生成一个6字节的行ID作为主键,无法控制,同时会导致主从同步异常。
- 优先使用自增
bigint作为主键,禁止使用UUID、字符串作为主键。UUID是无序的,插入时会导致聚簇索引频繁页分裂,性能极差,同时索引体积巨大。 - 禁止使用业务字段作为主键。业务字段可能发生变更,主键变更会导致聚簇索引重构,所有二级索引都需要同步更新,开销巨大。
- 分布式场景下,优先使用雪花算法等有序分布式ID,避免无序ID。
5.2 字段类型选择规范
字段类型选择的核心原则是越小越好,越简单越好。字段类型越小,占用的磁盘空间越少,索引体积越小,内存可缓存的索引数据越多,IO开销越少,性能越好。
核心规范:
- 整数类型 :能用
tinyint就不用smallint,能用int就不用bigint。例如状态字段仅有0-10个枚举值,使用tinyint(1字节),不要使用int(4字节);用户ID、订单ID等可能超过int范围的字段,使用bigint。 - 字符串类型 :优先使用
varchar,避免char定长字符串浪费空间;varchar长度尽量控制在255以内,超过255会使用2个字节存储长度,同时无法使用前缀索引;禁止使用text/blob存储短文本,大字段会导致无法使用内存临时表,只能使用磁盘临时表,性能极差。 - 时间类型 :优先使用
datetime,禁止使用timestamp与字符串存储时间。timestamp存在2038年问题,范围仅支持1970-2038;datetime范围支持1000-9999,MySQL 5.6+后支持毫秒精度,仅占用5字节;字符串存储时间无法使用时间函数,无法利用索引排序,性能极差。 - 小数类型 :金额字段必须使用
decimal,禁止使用float/double。float/double存在精度丢失问题,decimal(M,D)可精准控制精度,适合金额类字段。 - 字符集 :统一使用
utf8mb4字符集,支持完整的Unicode字符,包括emoji,避免字符集转换导致的索引失效。
5.3 索引设计规范
索引不是越多越好,而是越精准越好。过多的索引会导致插入、更新、删除的性能下降,同时增加优化器的索引选择成本,容易引发执行计划偏差。
核心规范:
- 单表索引数量控制在5个以内,单个联合索引的列数控制在3个以内,最多不超过5个。
- 优先创建联合索引,而非多个单列索引。联合索引可通过最左前缀原则,满足多个查询场景,索引利用率更高。
- 索引列必须选择区分度高的字段。区分度计算公式:
COUNT(DISTINCT 列名)/COUNT(*),区分度低于0.1的字段,不建议单独建索引,例如性别、状态字段,优化器通常会放弃使用这类低区分度索引。 - 禁止给小表建索引。行数少于1000的小表,全表扫描的性能远高于索引扫描。
- 避免重复索引与冗余索引,定期通过
sys.schema_unused_indexes清理未使用的索引。 - 优先设计覆盖索引,减少回表操作,这是索引优化的核心目标。
5.4 大字段与冷热数据分离
大字段与海量历史数据是表体积膨胀的核心原因,表体积越大,查询需要扫描的磁盘页越多,IO开销越大,性能越差。
核心规范:
- 大字段拆分:不常用的大字段(如长文本、详情、备注),单独拆分为附表,通过主键与主表关联。仅当业务需要时,才查询附表,避免主表查询时加载大字段,减少主表的IO开销。
- 冷热数据分离:超过一定时间的历史冷数据,很少被查询,单独迁移到历史表中,主表仅保留近期的热数据。例如订单表,主表保留近1年的订单,1年前的历史订单迁移到订单历史表,主表体积大幅缩小,查询性能提升10倍以上。
六、Java业务层的慢SQL防控最佳实践
很多慢SQL并非SQL本身的问题,而是业务代码的不规范使用导致的。下面给出符合规范的Java业务层实现,从开发阶段规避慢SQL风险,基于JDK 17、Spring Boot 3.2、MyBatis-Plus 3.5.7实现。
6.1 核心依赖配置
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.2.5</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.4.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.52</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.1.0-jre</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<version>3.2.5</version>
</dependency>
</dependencies>6.2 实体类定义
kotlin
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
/**
* 用户订单实体类
* @author ken
*/
@Data
@TableName("t_user_order")
@Schema(description = "用户订单实体")
public class UserOrder {
@TableId(type = IdType.AUTO)
@Schema(description = "主键ID", example = "1")
private Long id;
@Schema(description = "订单编号", example = "ORD202401010001")
private String orderNo;
@Schema(description = "用户ID", example = "1001")
private Long userId;
@Schema(description = "订单状态:0-待付款,1-已付款,2-已取消", example = "1")
private Integer orderStatus;
@Schema(description = "订单金额", example = "99.00")
private BigDecimal orderAmount;
@Schema(description = "支付时间")
private LocalDateTime payTime;
@Schema(description = "创建时间")
private LocalDateTime createTime;
@Schema(description = "更新时间")
private LocalDateTime updateTime;
@Schema(description = "备注", example = "正常订单")
private String remark;
}6.3 Mapper接口与XML
less
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.UserOrder;
import org.apache.ibatis.annotations.Param;
import java.time.LocalDateTime;
import java.util.List;
/**
* 用户订单Mapper接口
* @author ken
*/
public interface UserOrderMapper extends BaseMapper<UserOrder> {
/**
* 书签式分页查询订单
* @param lastCreateTime 上一页最后一条的创建时间
* @param orderStatus 订单状态
* @param pageSize 分页大小
* @return 订单列表
*/
List<UserOrder> selectByPageBookmark(@Param("lastCreateTime") LocalDateTime lastCreateTime,
@Param("orderStatus") Integer orderStatus,
@Param("pageSize") Integer pageSize);
/**
* 批量插入订单
* @param orderList 订单列表
* @return 插入行数
*/
int batchInsert(@Param("orderList") List<UserOrder> orderList);
}
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jam.demo.mapper.UserOrderMapper">
<resultMap id="BaseResultMap" type="com.jam.demo.entity.UserOrder">
<id column="id" property="id" jdbcType="BIGINT"/>
<result column="order_no" property="orderNo" jdbcType="VARCHAR"/>
<result column="user_id" property="userId" jdbcType="BIGINT"/>
<result column="order_status" property="orderStatus" jdbcType="TINYINT"/>
<result column="order_amount" property="orderAmount" jdbcType="DECIMAL"/>
<result column="pay_time" property="payTime" jdbcType="TIMESTAMP"/>
<result column="create_time" property="createTime" jdbcType="TIMESTAMP"/>
<result column="update_time" property="updateTime" jdbcType="TIMESTAMP"/>
<result column="remark" property="remark" jdbcType="VARCHAR"/>
</resultMap>
<select id="selectByPageBookmark" resultMap="BaseResultMap">
SELECT * FROM t_user_order
WHERE order_status = #{orderStatus}
<if test="lastCreateTime != null">
AND create_time < #{lastCreateTime}
</if>
ORDER BY create_time DESC
LIMIT #{pageSize}
</select>
<insert id="batchInsert">
INSERT INTO t_user_order (order_no, user_id, order_status, order_amount, pay_time, remark)
VALUES
<foreach collection="orderList" item="item" separator=",">
(#{item.orderNo}, #{item.userId}, #{item.orderStatus}, #{item.orderAmount}, #{item.payTime}, #{item.remark})
</foreach>
</insert>
</mapper>6.4 服务层实现
ini
package com.jam.demo.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.google.common.collect.Lists;
import com.jam.demo.entity.UserOrder;
import com.jam.demo.mapper.UserOrderMapper;
import com.jam.demo.service.UserOrderService;
import com.jam.demo.vo.OrderQueryVO;
import com.jam.demo.vo.PageResultVO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import java.util.List;
/**
* 用户订单服务实现类
* @author ken
*/
@Slf4j
@Service
public class UserOrderServiceImpl extends ServiceImpl<UserOrderMapper, UserOrder> implements UserOrderService {
private final UserOrderMapper userOrderMapper;
private final PlatformTransactionManager transactionManager;
public UserOrderServiceImpl(UserOrderMapper userOrderMapper, PlatformTransactionManager transactionManager) {
this.userOrderMapper = userOrderMapper;
this.transactionManager = transactionManager;
}
@Override
public PageResultVO<UserOrder> pageByBookmark(OrderQueryVO queryVO) {
if (ObjectUtils.isEmpty(queryVO)) {
return new PageResultVO<>(0L, Lists.newArrayList());
}
List<UserOrder> orderList = userOrderMapper.selectByPageBookmark(
queryVO.getLastCreateTime(),
queryVO.getOrderStatus(),
queryVO.getPageSize()
);
long total = this.count(lambdaQuery().eq(UserOrder::getOrderStatus, queryVO.getOrderStatus()));
return new PageResultVO<>(total, orderList);
}
@Override
public boolean batchCreateOrder(List<UserOrder> orderList) {
if (CollectionUtils.isEmpty(orderList)) {
return false;
}
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setTimeout(30);
TransactionStatus status = transactionManager.getTransaction(def);
try {
List<List<UserOrder>> partitionList = Lists.partition(orderList, 1000);
for (List<UserOrder> partition : partitionList) {
userOrderMapper.batchInsert(partition);
}
transactionManager.commit(status);
return true;
} catch (Exception e) {
transactionManager.rollback(status);
log.error("批量创建订单失败", e);
return false;
}
}
}6.5 慢SQL拦截器配置
ini
package com.jam.demo.config;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.Interceptor;
import org.apache.ibatis.plugin.Intercepts;
import org.apache.ibatis.plugin.Invocation;
import org.apache.ibatis.plugin.Signature;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.springframework.stereotype.Component;
/**
* 慢SQL拦截器
* @author ken
*/
@Slf4j
@Component
@Intercepts({
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class SlowSqlInterceptor implements Interceptor {
private static final long SLOW_SQL_THRESHOLD = 1000;
@Override
public Object intercept(Invocation invocation) throws Throwable {
long startTime = System.currentTimeMillis();
try {
return invocation.proceed();
} finally {
long costTime = System.currentTimeMillis() - startTime;
if (costTime > SLOW_SQL_THRESHOLD) {
MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];
Object parameter = invocation.getArgs()[1];
BoundSql boundSql = mappedStatement.getBoundSql(parameter);
String sql = boundSql.getSql().replaceAll("\s+", " ");
log.warn("慢SQL告警,执行时间:{}ms,SQL:{},参数:{}", costTime, sql, parameter);
}
}
}
}七、慢SQL优化核心原则总结
- 先定位,再优化:先通过慢查询日志、APM工具精准定位高频慢SQL,避免盲目优化。
- 先看执行计划,再改SQL :
EXPLAIN执行计划是优化的核心抓手,先看懂执行计划,找到瓶颈点,再针对性改写。 - 优化优先级:索引优化 > SQL改写 > 表结构调整 > 架构改造,优先选择成本最低、见效最快的优化方案。
- 覆盖索引是银弹:尽量通过覆盖索引避免回表操作,减少IO开销,是性能提升最显著的优化手段。
- 核心优化目标:减少扫描行数、减少IO次数、减少数据库交互次数。
- 预防大于治理:在开发阶段就做好表结构设计、索引设计、SQL规范,建立慢SQL监控与拦截机制,避免慢SQL上线。
慢SQL优化不是一劳永逸的操作,而是一个持续的过程。需要结合业务场景的变化,持续监控、持续优化,才能保障数据库的稳定高性能运行。