一.库的操作
1.1 创建数据库
创建数据库:create database db_name;本质就是在 /var/lib/mysql 创建一个目录
sql
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name说明:
- 大写的表示关键字
- \[\] 是可选项
- CHARACTER SET: 指定数据库采用的字符
- COLLATE: 指定数据库字符集的校验规则
创建数据库案例的指令
创建名为 db1 的数据库
create database db1;
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_general_ci
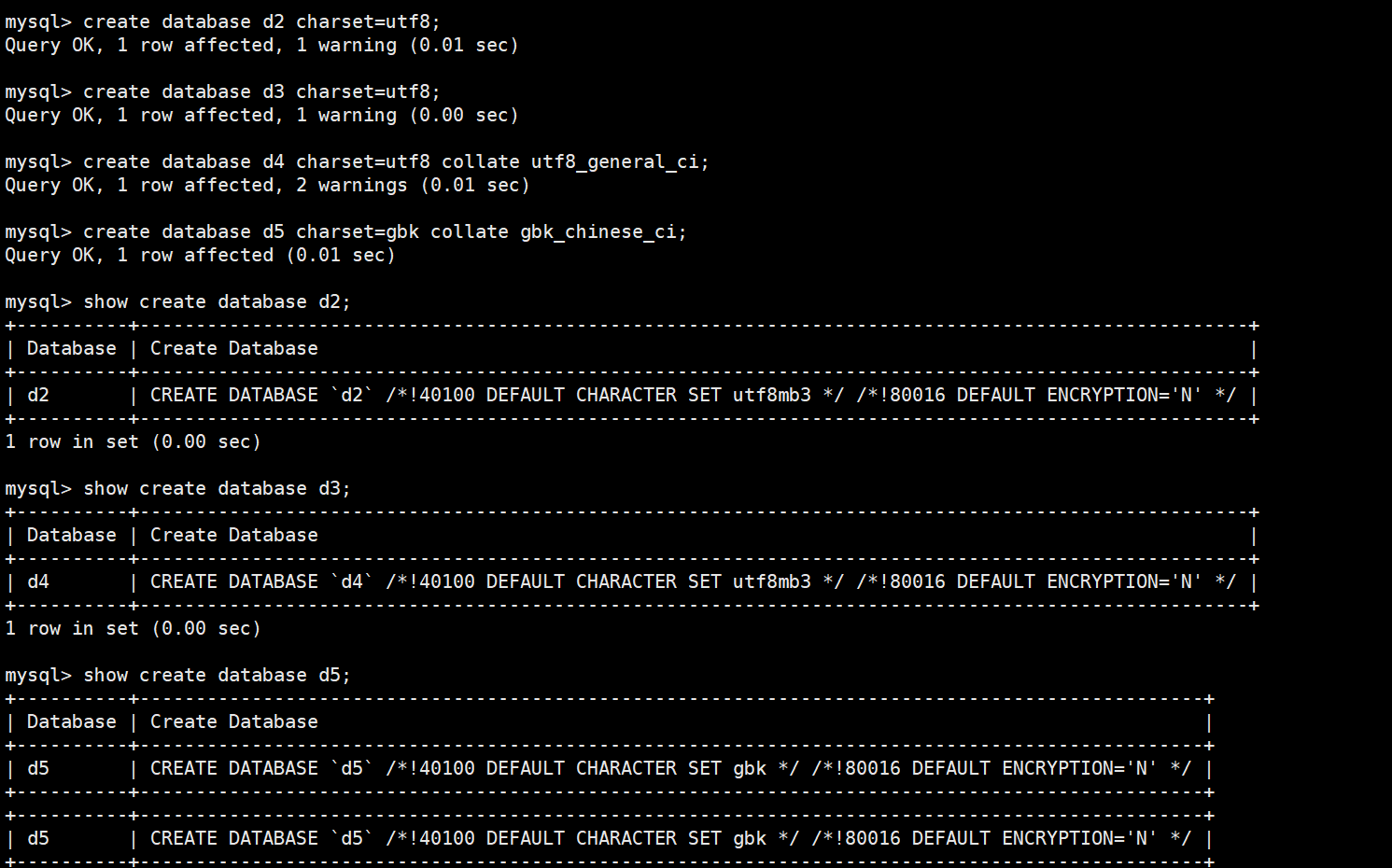
创建一个使用utf8字符集的db2数据库
create database db2 charset=utf8;
创建一个使用utf字符集,并带校对规则的db3数据库。
create database db3 charset=utf8 collate utf8_general_ci;
我最初创建的例子
1-2删除数据库
sql
DROP DATABASE [IF EXISTS] db_ name;执行删除之后的结果:
数据库内部看不到对应的数据库
对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意:不要随意删除数据库
1-3认识mysql的编码
创建数据库的时候,有两个编码集:
数据库编码集 ------ 数据库未来存储数据
数据库校验集 ------ 支持数据库进行字段比较使用的编码,本质也是一种读取数据库中数据所采用的编码格式
数据库无论对数据做任何操作,都必须保证操作和编码是一致的!
1-3-1字符集和校验规则
查看系统默认字符集以及校验规则
sql
show variables like 'character_set_database';
show variables like 'collation_database';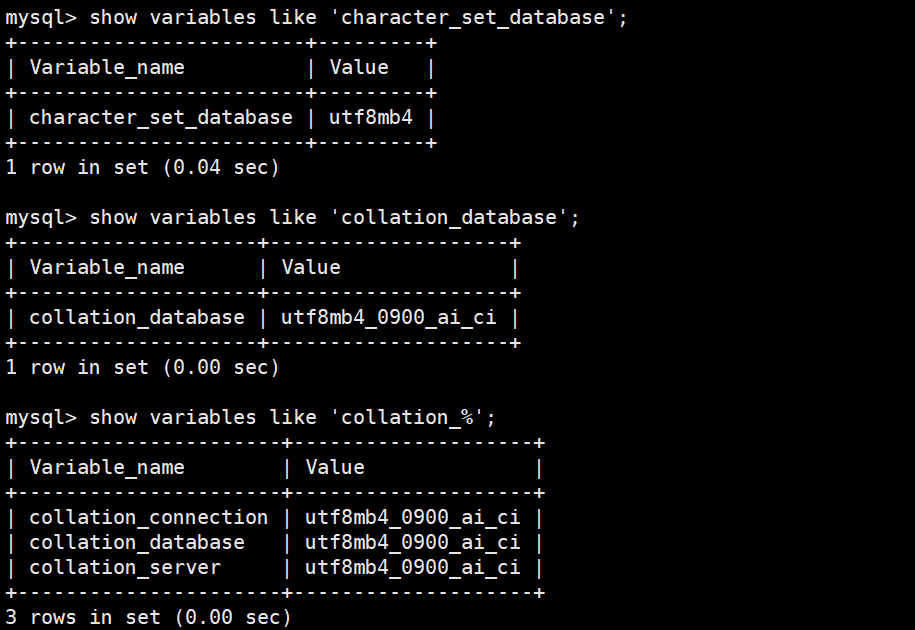
|------------------------|--------------|
| collation_connection | 当前连接使用的校验规则 |
| collation_database | 当前数据库的默认校验规则 |
| collation_server | 服务器级别的默认校验规则 |
utf8mb4_0900_ai_ci的含义:
utf8mb4:编码集(支持完整Unicode,包括emoji)
0900:基于Unicode 9.0标准
ai:口音不敏感(accent insensitive)
ci:大小写不敏感(case insensitive
show variables like 'collation_database';,这条指令用于查看当前数据库的校验规则。show variables like 'collation_%';,这条指令用于查看所有以collation开头的系统变量。这里的%是一个通配符,代表任意字符,所以它会显示出包括连接、数据库、服务器等各级别的校验规则。
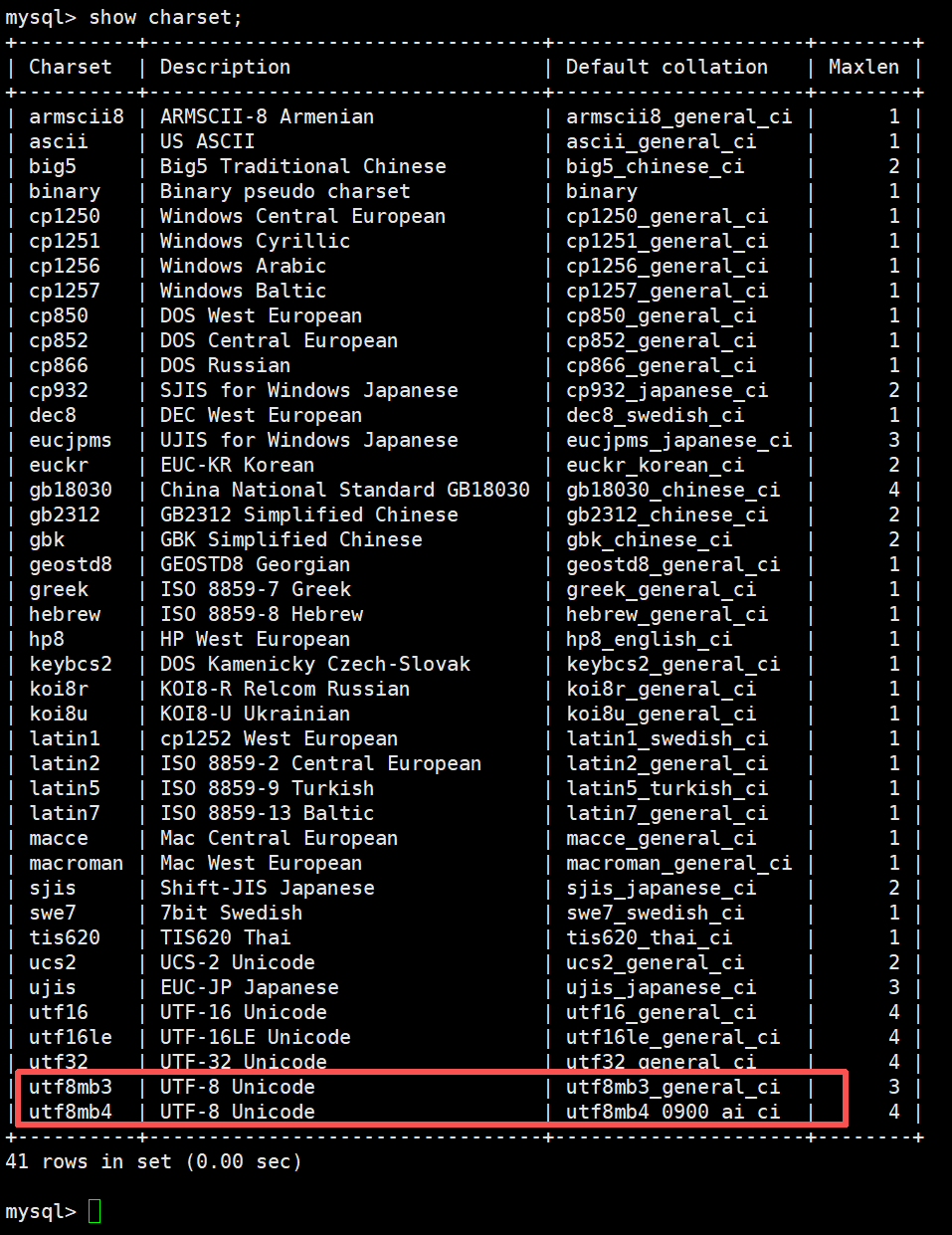
1-3-2查看数据库支持的字符集
sql
show charset;字符集主要是控制用什么语言。比如utf8就可以使用中文。
1-3-3查看数据库支持的字符集校验规则
sql
show collation;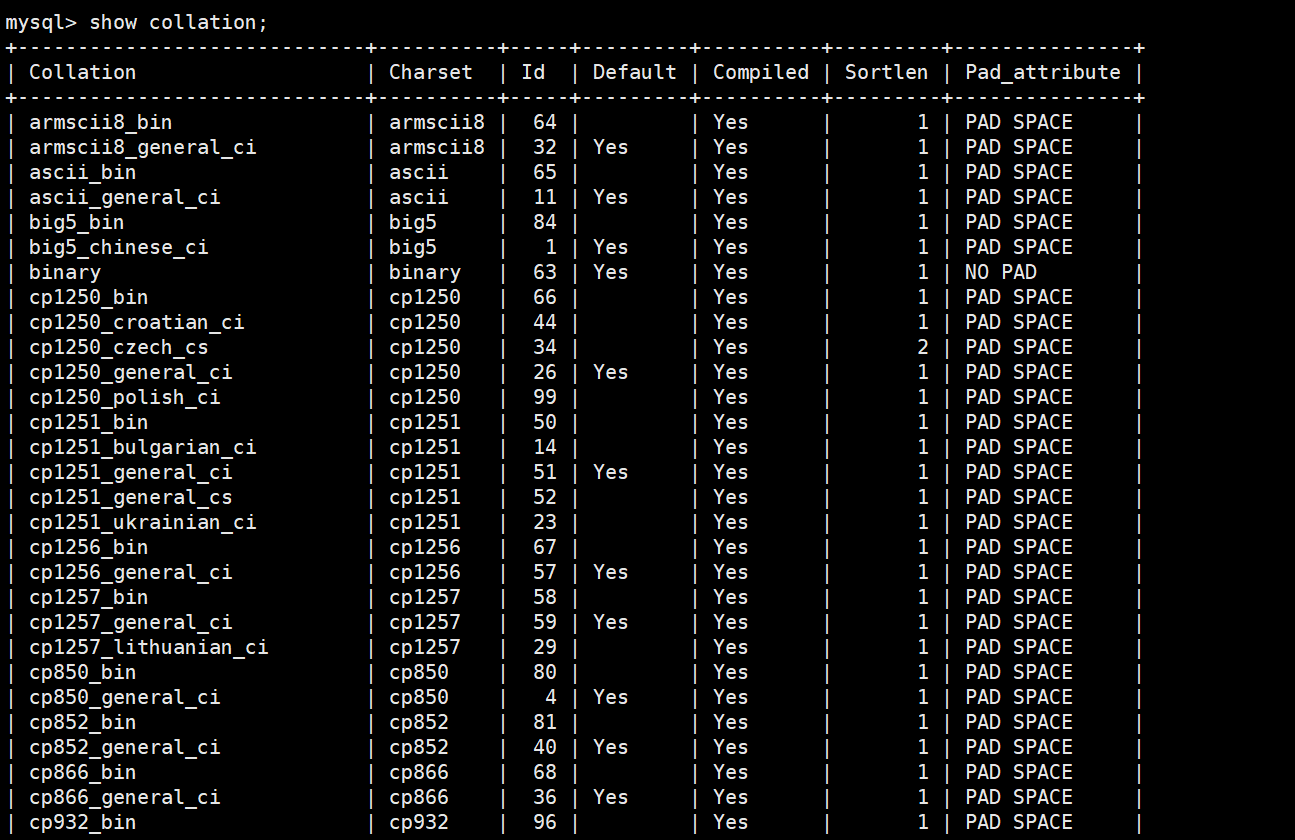
1-4创建数据库时的编码设置
1. 默认创建(不指定编码)
sql
create database d1;当创建数据库没有指定字符集和校验规则时:
系统使用默认字符集:
utf8校验规则是:
utf8_general_ci
在 Linux 底层,MySQL 会在 /var/lib/mysql/ 目录下创建对应的数据库文件夹,里面会生成一个 db.opt 文件记录编码信息:
centos7
bash
[root@VM-8-5-centos mysql]# cat d1/db.opt
default-character-set=utf8
default-collation=utf8_general_ci2. 指定字符集创建数据库
sql
create database d2 charset=utf8;
create database d3 charset=utf8;两种写法效果相同,查看底层文件:
bash
[root@VM-0-3-centos mysql]# cat d2/db.opt
default-character-set=utf8
default-collation=utf8_general_ci3. 指定字符集和校验规则创建数据库
sql
create database d4 charset=utf8 collate utf8_general_ci;4. 使用 GBK 字符集创建数据库
sql
create database d5 charset=gbk collate gbk_chinese_ci;查看 GBK 编码的数据库配置:
bash
[root@VM-0-3-centos mysql]# cat d5/db.opt
default-character-set=gbk
default-collation=gbk_chinese_ciubbuntu22.04
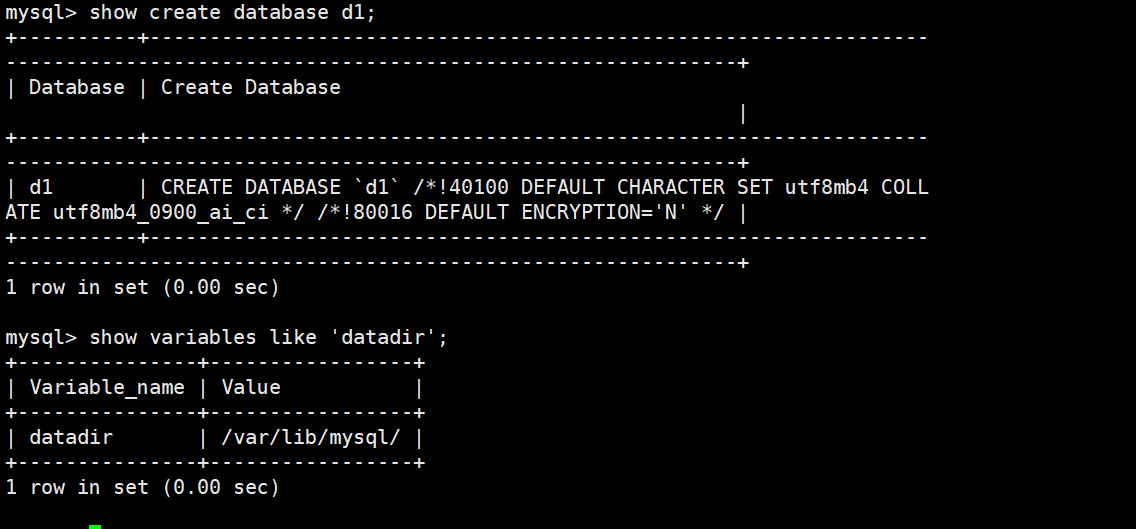
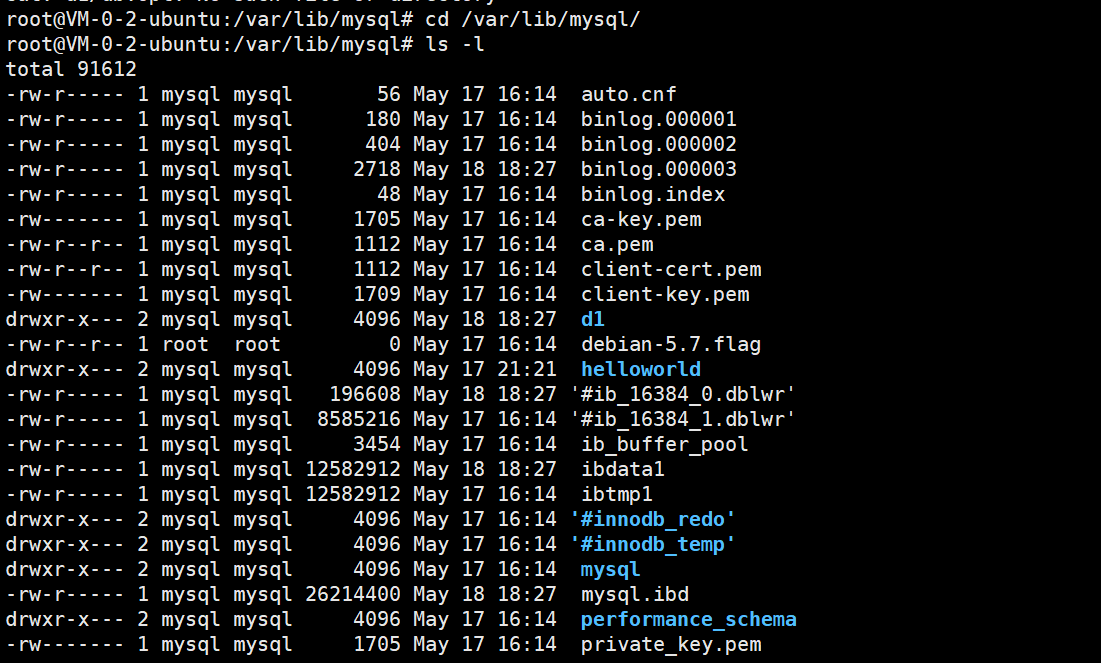
ubuntu22.04不能进行cat操作,所以我选用的是mysql操作这个可以进行
MySQL数据库 db.opt 文件缺失问题排查(CentOS7 vs Ubuntu 22.04)
问题背景
我在学习MySQL数据库时,执行 CREATE DATABASE d1; 创建了数据库,想通过查看 /var/lib/mysql/d1/db.opt 文件来确认字符集和校验规则,但在Ubuntu 22.04环境中遇到了问题:
MySQL中 SHOW DATABASES 能看到 d1 ,且数据库内有数据、可正常使用
Bash中 /var/lib/mysql/ 下存在 d1 目录,但目录内没有 db.opt 文件
修改目录权限也无法解决,而CentOS 7环境中可以正常看到该文件
环境差异说明
环境 MySQL版本 系统特性 db.opt 文件表现
CentOS 7中的MySQL 5.7 传统发行版,MySQL数据目录权限严格 创建数据库后自动生成 db.opt
Ubuntu 22.04 MySQL 5.7(或8.0+) Debian系发行版,MySQL默认配置有差异 可能出现 db.opt 未生成的情况
补充:MySQL 8.0+版本彻底取消了 db.opt 文件,字符集配置统一存储在系统表 mysql.schemata 中,这是Ubuntu 22.04默认安装MySQL 8.0时的常见情况。
原因分析
核心原因
db.opt 是MySQL 5.7及之前版本中,创建数据库时自动生成的物理文件,用于记录该数据库的默认字符集和校验规则。
CentOS 7中MySQL 5.7的默认安装流程完整,创建数据库时会正常生成该文件
Ubuntu 22.04中可能因为安装配置差异、权限初始化问题、创建时异常中断,导致 db.opt 未生成,即使 db.opt 缺失, SHOW DATABASES 从系统表读取数据,所以仍能显示数据库存在
d1 不是系统自带数据库,是手动创建的,不会默认生成 db.opt
修改权限无法生成 db.opt ,因为该文件仅在创建数据库时自动生成,后期权限调整不会触发重新生成
解决方案
方案1:用SQL命令直接查看字符集(无需依赖 db.opt )
这是最稳妥、跨版本通用的方法,无论是否有 db.opt 都能生效
-查看d1数据库的字符集和校验规则
sql
SHOW CREATE DATABASE d1;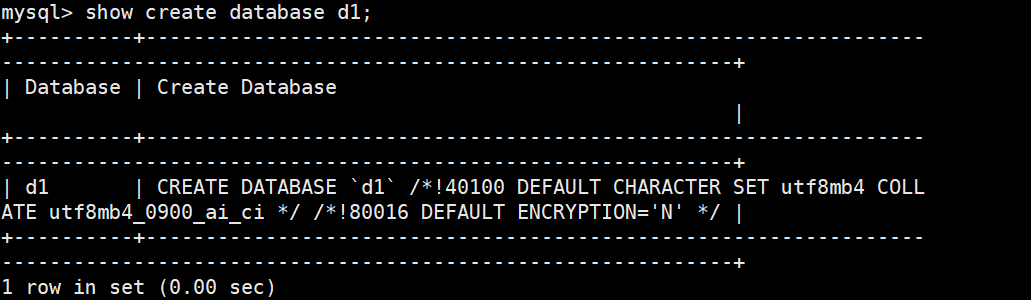
方案2:手动创建 db.opt 文件(MySQL 5.7适用)
如果需要恢复 db.opt 文件,可以手动创建并配置权限:
bash
# 进入d1数据库目录
cd /var/lib/mysql/d1
# 写入字符集配置
echo "default-character-set=utf8" > db.opt
echo "default-collation=utf8_general_ci" >> db.opt
# 修正文件权限(必须为mysql:mysql,否则MySQL无法读取)
chown mysql:mysql db.opt
chmod 660 db.opt
# 重启MySQL服务生效
systemctl restart mysql方案3:重建数据库(适合有数据备份的情况)
bash
# 1. 备份d1数据库数据
mysqldump -u root -p d1 > d1_backup.sql
# 2. 登录MySQL删除d1
mysql -u root -p
DROP DATABASE d1;
# 3. 重新创建d1(指定字符集,确保生成db.opt)
CREATE DATABASE d1 CHARACTER SET utf8 COLLATE utf8_general_ci;
# 4. 恢复数据
mysql -u root -p d1 < d1_backup.sql总结:
版本差异:MySQL 8.0+不再生成 db.opt ,字符集查看请用 SHOW CREATE DATABASE
环境差异:CentOS和Ubuntu的MySQL安装配置不同,可能导致 db.opt 生成异常
最佳实践:优先使用SQL命令查看字符集,避免依赖物理文件; db.opt 缺失不影响数据库正常使用
思路:先确认数据库逻辑存在→再查物理目录→最后针对性解决
1-5校验规则对数据库的影响
- 不区分大小写
创建一个数据库,校验规则使用utf8_ general_ ci不区分大小写
sql
create database test1 collate utf8_general_ci;
use test1;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');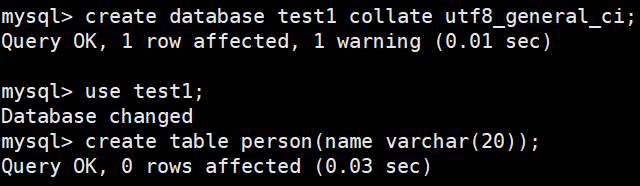
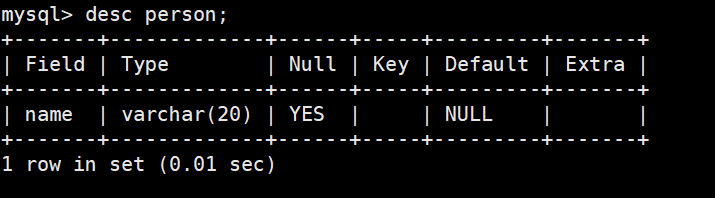
不区分大小写的查询以及结果
sql
mysql> use test1;
mysql> select * from person where name='a';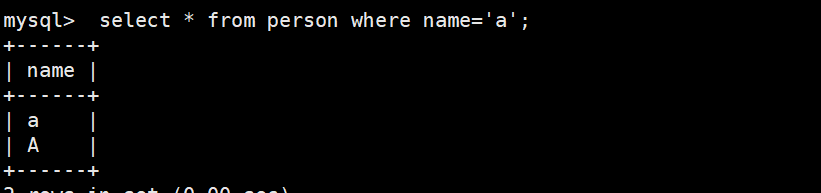
- 插入数据并查询数据
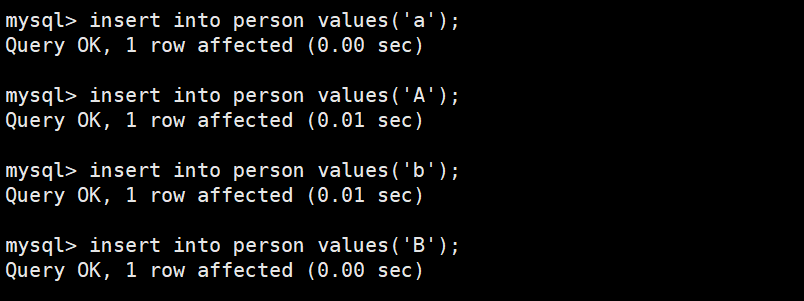
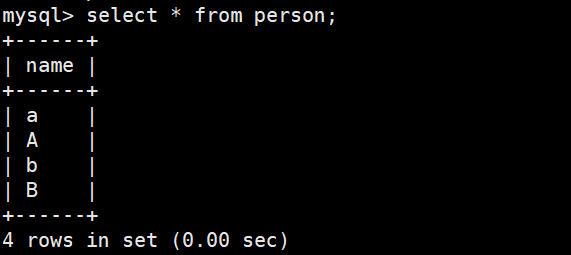
- 结果排序
不区分大小写排序以及结果:
sql
mysql> use test1;
mysql> select * from person order by name;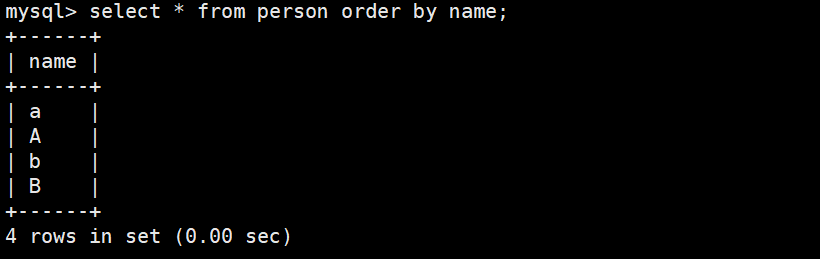
select是从表里查询数据,通配符*代表将表里的所有列数据都显示出来。插入 的本质是存储数据,采用
default-character-set=utf8,也就是插入数据时所用的编码格式。查询的本质是按照校验集的要求来查找和比较数据。具体来说:
插入数据时:使用编码集将数据编码后存入磁盘
查询数据时:使用校验集 的规则来比较字段(如
where条件、order by排序、group by分组等)两者必须匹配:如果插入时用的编码集和查询时用的校验集不兼容,就会导致比较结果出错,甚至查不到本该存在的数据。
- 区分大小写
创建一个数据库,校验规则使用utf8_ bin区分大小写
sql
create database test2 collate utf8_bin;
use test2
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');- 进行查询
区分大小写的查询以及结果
sql
mysql> use test2;
mysql> select * from person where name='a';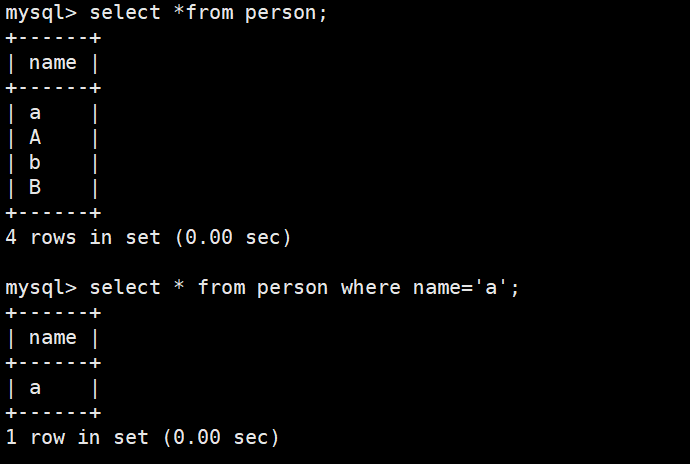
- 结果排序
区分大小写排序以及结果:
sql
mysql> use test2;
mysql> select * from person order by name;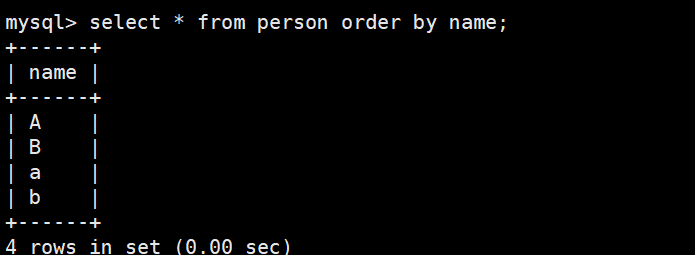
注意:这里一般默认是升序排序。
1-6数据库的删改查
数据库删除
sql
DROP DATABASE [IF EXISTS] db_ name;
执行删除之后的结果:
数据库内部看不到对应的数据库
对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意:不要随意删除数据库
显示创建语句
sql
show create database 数据库名;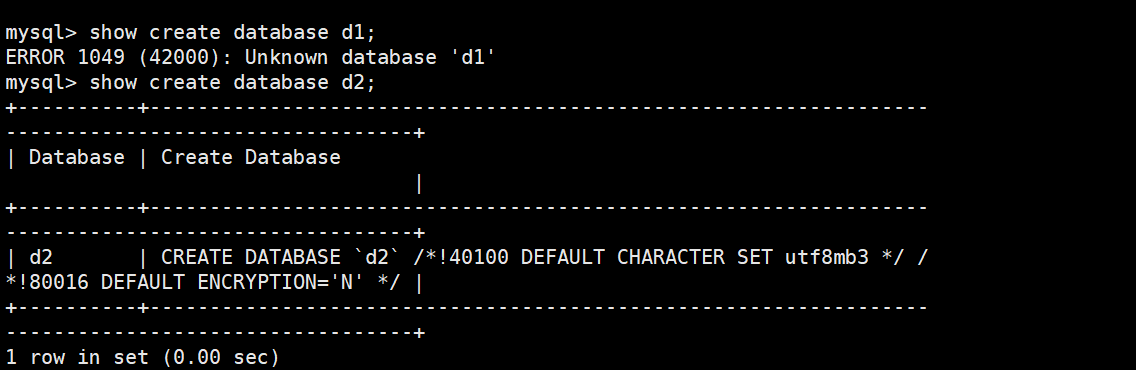
说明:
MySQL 建议我们关键字使用大写,但是不是必须的。
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
有点版本比较低有这个情况/*!40100 default.... */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
修改数据库
sql
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name- 将 test2 数据库字符集改成 gbk
这个是在centos5.7下运行的可以用cat查到
sql
mysql> alter database test2 charset=gbk collate gbk_chinese_ci;
Query OK, 1 row affected (0.00 sec)
bash
[root@VM-0-3-centos mysql]# cat test2/db.opt
default-character-set=utf8
default-collation=utf8_bin
[root@VM-0-3-centos mysql]# cat test2/db.opt
default-character-set=gbk
default-collation=gbk_chinese_ciubuntu22.04直接在mysql上查
sql
-- 查看当前数据库的字符集和校验规则
show variables like 'character_set_database';
show variables like 'collation_database';
-- 或者查看数据库的创建语句(会显示编码信息)
show create database test2;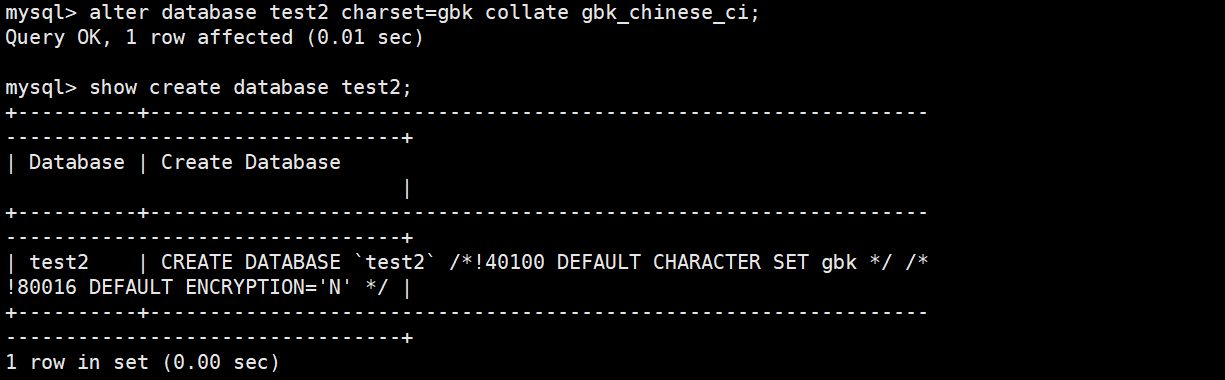
说明:
对数据库的修改主要指的是修改数据库的字符集,校验规则
查看数据库
sql
show databases;
查询当前所在数据库:
select database();
1-7数据库备份和恢复
1.备份
语法:
# mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径;
sql
# -P 端口号(大写P,默认3306可省略)
# -p 密码(小写p,直接跟密码,中间没有空格)
mysqldump -P3306 -u root -p123456 -B test1 > test1.sql
为了避免密码暴露在命令行中(会被 history 记录),更安全的做法是:
# 不写密码,执行后会提示交互式输入
mysqldump -P3306 -u root -p -B test1 > D:/test1.sql
# 然后系统会提示:Enter password: 你输入密码(不显示)我们将test1进行备份

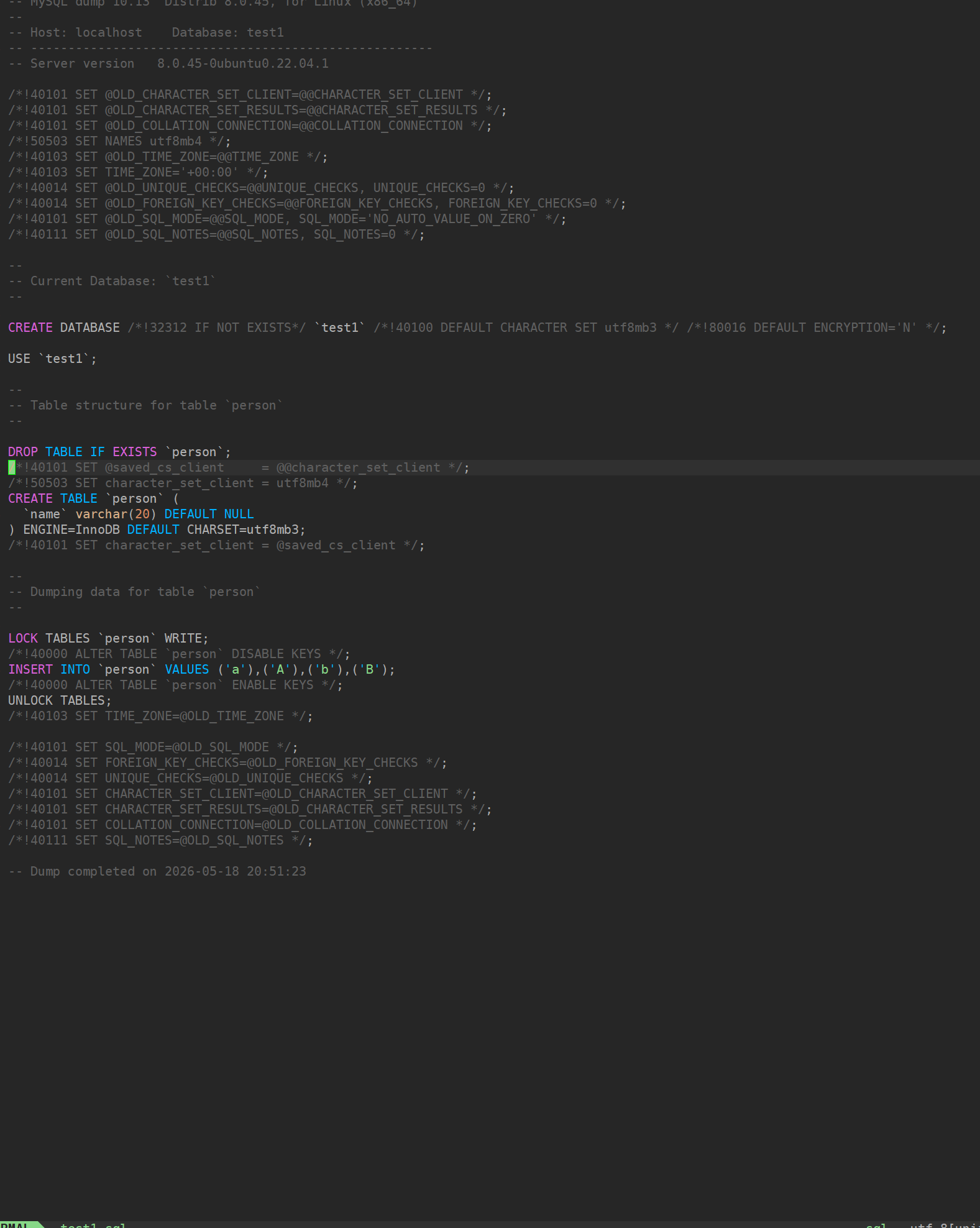
这个文件实际上就是把我们的数据库相关的所有数据,以及表等放到这个文件当中也可以称为物理文件
2.还原
语法:
sql
mysql> source /root/MySQL/test1.sql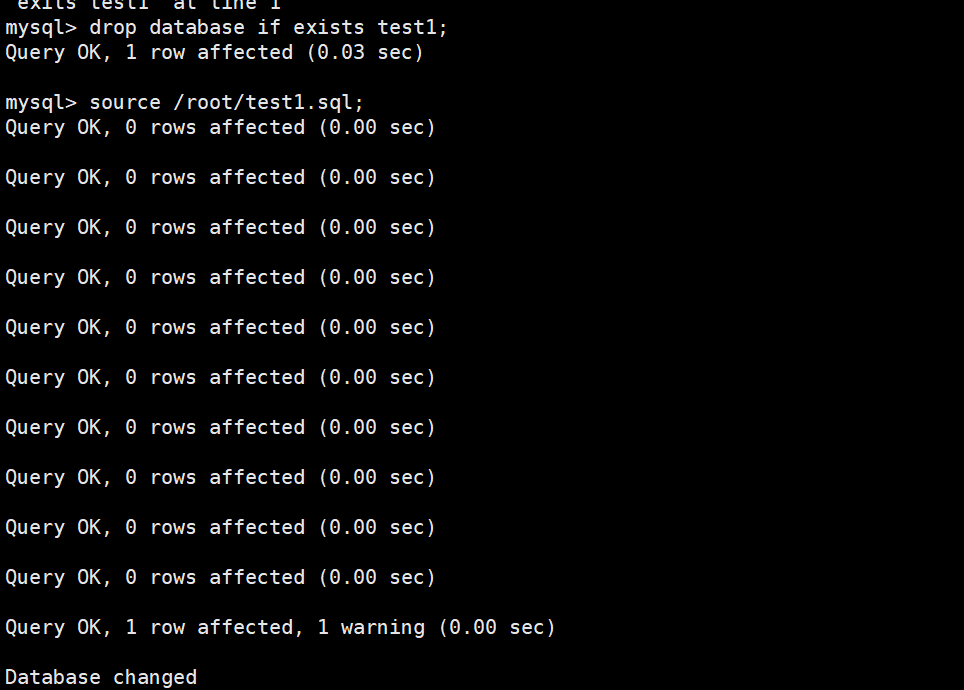
我刚直接输入指令西显示没有文件存在,我就先if了一下,确定恢复时没有先确保没有任何数据库占用冲突,你直接
source的时候,如果test1数据库已经存在,可能会报错或者跳过。
两种恢复方式的区别
情况一:备份时带了 -B
bash
mysqldump -u root -p -B test1 > test1.sql;恢复时直接:
sql
source /root/MySQL/mytest.sql;不需要先建库、不需要 use,因为文件里已经有 CREATE DATABASE 和 USE 语句。
情况二:备份时没带 -B
sql
mysqldump -u root -p test1 > test1.sql;恢复时必须先手动创建数据库:
sql
create database mytest;
use mytest;
source /root/MySQL/mytest.sql;如果你直接 source 而没有先建库和 use,就会出问题。
3. 注意事项
如果备份的不是整个数据库,**而是其中的一张表,**怎么做?
sql
mysqldump -u root -p 数据库名 表名1 表名2 > test1.sql;同时备份多个数据库
sql
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径;如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原。
4. 查看连接情况
语法:
sql
show processlist;
| 列名 | 含义 | 你的例子中的具体值解读 |
|---|---|---|
| Id | 连接的线程ID,唯一标识一个客户端连接 | 5、23、27 |
| User | 连接所用的用户名 | event_scheduler(系统内部事件调度器)、root(你的管理员账户) |
| Host | 客户端连接来源 | localhost 表示本机连接;localhost:57982 表示本机的某个端口 |
| Db | 当前连接正在使用的数据库(如果已选中) | test1 表示正在使用 test1 库;NULL 表示没有选中任何库 |
| Command | 当前连接正在执行的命令类型 | Daemon(后台守护进程)、Sleep(空闲)、Query(正在执行查询) |
| Time | 当前状态持续的时间(秒) | 5 秒、5545 秒(约1.5小时)、0 秒 |
| State | 线程当前的状态 | Waiting on empty queue(等待任务)、NULL、init(初始化) |
| Info | 正在执行的SQL语句(如果Command是Query) | show processlist 就是你刚执行的这条命令 |
二.表的操作
2-1创建表
语法:
sql
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;说明:
field 表示列名
datatype 表示列的类型
character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
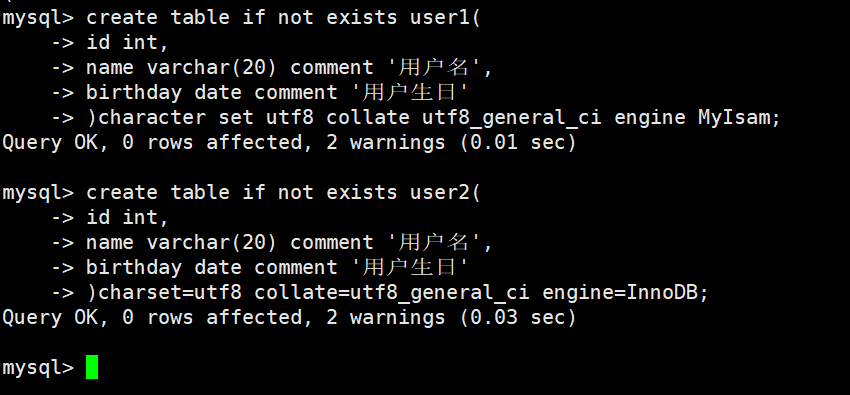
说明:
不同的存储引擎,创建表的文件不一样。
users 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
users.frm:表结构
users.MYD:表数据
users.MYI:表索引
示例(MySQL 5.7)
不同的存储引擎,创建表的文件不一样。
(1) user1 表存储引擎是 MyISAM
在数据目录中有三个不同的文件;
bash
[root@VM-0-3-centos user_db]# ll
total 128
-rw-r--r-- 1 mysql mysql 61 May 19 9:00 db.opt
-rw-r--r-- 1 mysql mysql 8645 May 19 9:02 user1.frm
-rw-r--r-- 1 mysql mysql 0 May 19 9:02 user1.MYD
-rw-r--r-- 1 mysql mysql 1024 May 19 9:02 user1.MYI
user1.frm:表结构
user1.MYD:表数据
user1.MYI:表索引
(2) user2 表存储引擎是 InnoDB
在数据目录中有两个不同的文件:
bash
[root@VM-0-3-centos user_db]# ll
total 128
-rw-r--r-- 1 mysql mysql 61 May 19 9:00 db.opt
-rw-r--r-- 1 mysql mysql 8645 May 19 9:02 user1.frm
-rw-r--r-- 1 mysql mysql 0 May 19 9:02 user1.MYD
-rw-r--r-- 1 mysql mysql 1024 May 19 9:02 user1.MYI
-rw-r--r-- 1 mysql mysql 8645 May 19 9:02 user2.frm
-rw-r--r-- 1 mysql mysql 98304 May 19 9:02 user2.ibd
user2.frm:表结构
user2.ibd:表数据和索引
创建 user3 表(默认存储引擎)
sql
mysql> create table if not exists user3(name char(32));
Query OK, 0 rows affected (0.02 sec)查看文件:
bash
[root@VM-0-3-centos user_db]# ll
total 236
-rw-r--r-- 1 mysql mysql 61 May 19 9:02 db.opt
-rw-r--r-- 1 mysql mysql 8645 May 19 9:02 user1.frm
-rw-r--r-- 1 mysql mysql 0 May 19 9:02 user1.MYD
-rw-r--r-- 1 mysql mysql 1024 May 19 9:02 user1.MYI
-rw-r--r-- 1 mysql mysql 8645 May 19 9:02 user2.frm
-rw-r--r-- 1 mysql mysql 98304 May 19 9:02 user2.ibd
-rw-r--r-- 1 mysql mysql 8560 May 19 9:03 user3.frm
-rw-r--r-- 1 mysql mysql 98304 May 19 9:03 user3.ibd表默认的存储引擎是 InnoDB。
ubuntu
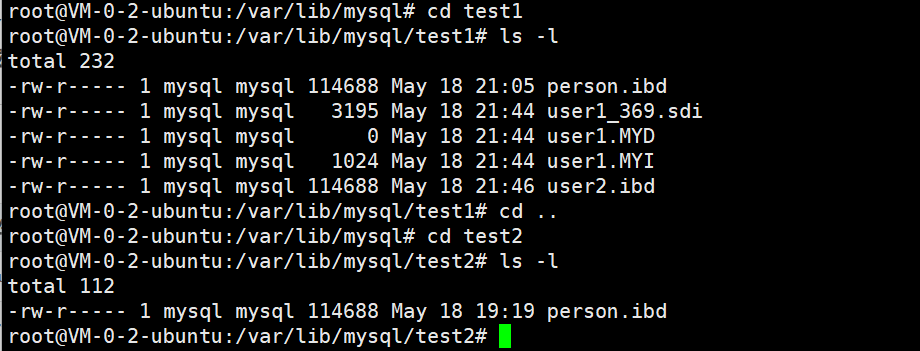
Ubuntu 输出可以看到:
user1表同时存在user1.MYD、user1.MYI和user1_369.sdi文件
user2表只有user2.ibd文件
这说明:
在 MySQL 8.0 中,即使你指定 engine=MyISAM 创建了表,它依然会生成一个 .sdi 文件(替代旧版的 .frm),同时也会生成 .MYD 和 .MYI 文件。但默认存储引擎是 InnoDB,所以不指定引擎时创建的表(如 user3、person)只会生成 .ibd 文件。
你实际看到的文件对应关系
| 表名 | 存储引擎 | 生成的文件 |
|---|---|---|
| user1 | MyISAM | user1.MYD + user1.MYI + user1_369.sdi |
| user2 | InnoDB | user2.ibd |
| person | InnoDB(默认) | person.ibd |
为什么 user1 没有 .frm 而是 .sdi?
Ubuntu 装的是 MySQL 8.0 ,而笔记里的 CentOS 是 MySQL 5.7。
MySQL 5.7 及之前:表结构存在
.frm文件MySQL 8.0:表结构存在数据字典中,同时导出为
.sdi(序列化字典信息)文件所以找不到
user1.frm是正常的,8.0 里对应的是user1_369.sdi。
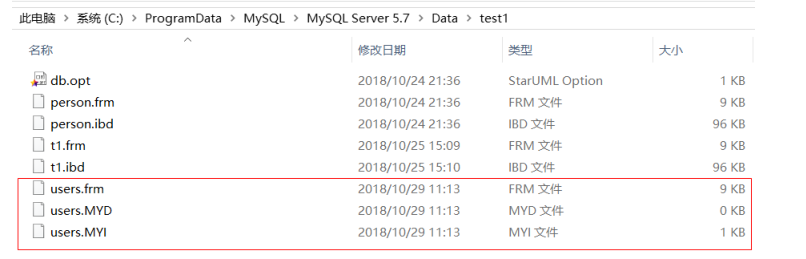
备注:创建一个engine是innodb的数据库,观察存储目录
2-2查看表
查看表结构
desc 表名;

显示表的详细信息
show create table user1;
show create table user1 \G;(\G:格式化显示,把不需要的符号去掉。)
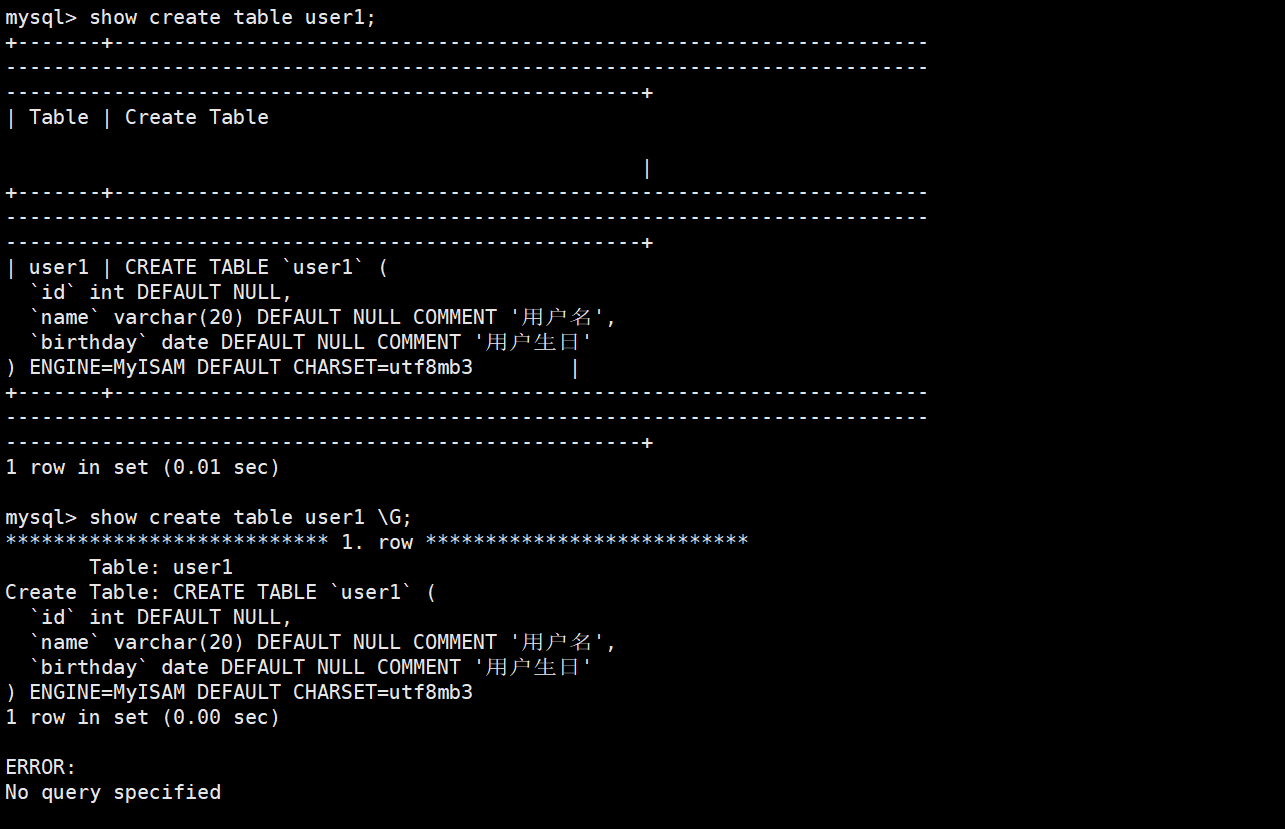
\G:格式化显示,去掉不需要的符号。
2-3修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
语法:
sql
LTER TABLE tablename ADD (column datatype [DEFAULT expr][,column
datatype]...);
ALTER TABLE tablename MODIfy (column datatype [DEFAULT expr][,column
datatype]...);
ALTER TABLE tablename DROP (column);- 将user1改为user(to可以省略)

- 在表中添加记录
insert into tablename values (插入各项内容 );
- 在表中添加一个字段
alter table tablename add (column datatype DEFAULT expr,column datatype...);
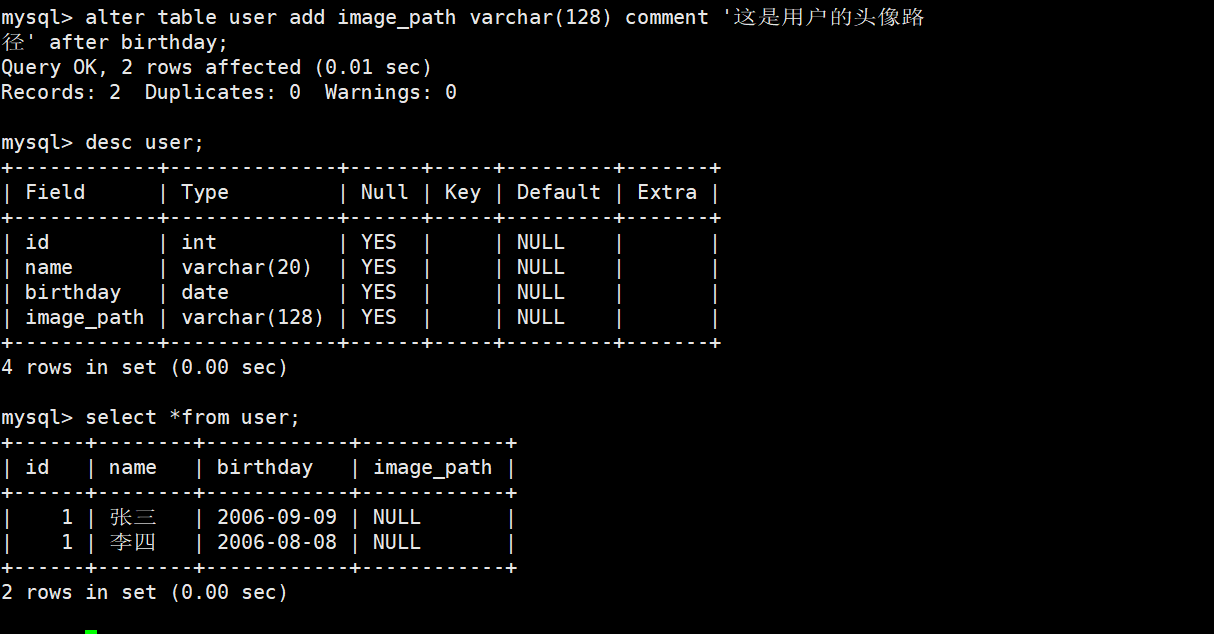
插入新字段后,对原来表中的数据没有影响:
2-4修改属性
alter table tablename modify (column datatype DEFAULT expr,column datatype...);
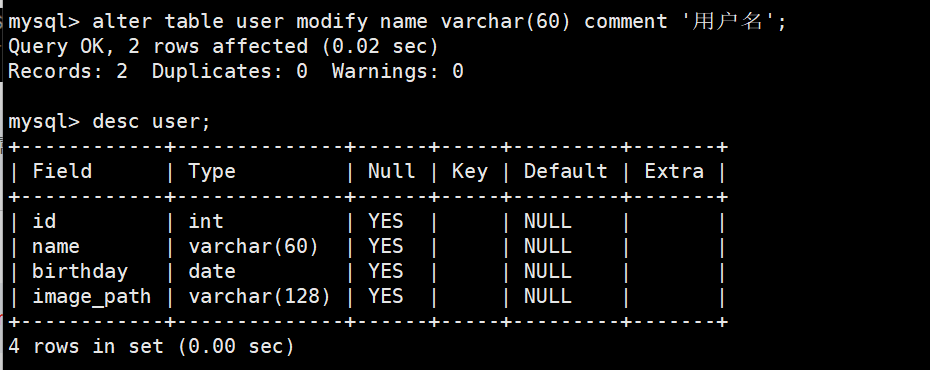
不是指定进行修改,所以要将所修改属性后面的内容也加上 ,否则将直接覆盖原有内容。
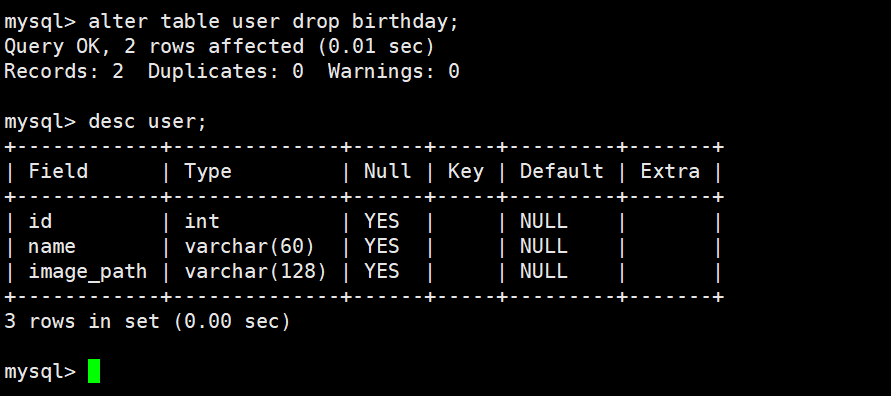
2-5删除password列
注意:删除字段一定要小心,删除字段及其对应的列数据都没了
alter table tablename drop (column );
2-6修改列名
alter table tablename change (column newcolumn datatype DEFAULT expr,column datatype...);
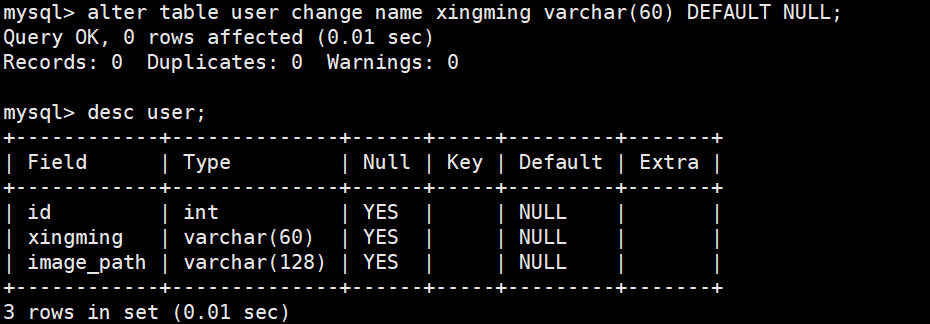
新字段需要完整定义,属性也要带上
2-7删除表
语法格式:
DROP TEMPORARY TABLE IF EXISTS tbl_name , tbl_name ...