一文读懂NLP范式演进、Fine-Tuning与Prompt-Tuning的核心原理
前言
随着ChatGPT、GPT-4等大模型的爆火,Prompt-Tuning技术逐渐成为学术界和工业界关注的焦点。本文将系统介绍NLP任务的四种发展范式,深入剖析Fine-Tuning和Prompt-Tuning的核心原理,并带你了解面向超大规模模型的先进微调技术。
微调方法对比一览表
| 方法 | 是否训练 | 更新什么参数 | 是否需要标注数据 | 算力消耗 | 核心原理 | 适用场景 | 一句话总结 |
|---|---|---|---|---|---|---|---|
| 传统全参微调 | ✅ 是 | 全部权重W | ✅ 需要 | 极高 | 直接修改模型所有参数适配任务 | 任务与预训练差异大、数据充足 | 动全身,算力爆炸 |
| 传统下游微调 | ✅ 是 | 最后几层+分类头 | ✅ 需要 | 中等 | 只改任务相关层,冻结其他层 | 资源有限、任务较简单 | 局部调整,省一点 |
| LoRA | ✅ 是 | 旁路矩阵A、B | ✅ 需要 | 低 | 权重更新量低秩分解,原模型冻结 | 通用首选,资源受限场景 | 加插件,原模原样 |
| Hard Prompt (PET) | ✅ 是 | 全部权重W | ✅ 需要 | 中等 | 用MASK将任务伪装成MLM | 小样本分类任务 | 加掩码,伪装填空 |
| Soft Prompt | ✅ 是 | Prompt向量P | ✅ 需要 | 低 | 可学习的连续向量作为提示 | 大模型快速适配 | 学暗号,向量引导 |
| In-Context Learning | ❌ 否 | 无 | ❌ 不需要 | 极低(仅推理) | 给示例让模型"现学" | 超大规模模型(>10B) | 给范例,现学现卖 |
一、NLP任务四种范式
学术界一般将NLP任务的发展分为四个阶段:
| 范式 | 特征工程 | 数据需求 | 模型类型 | 典型任务 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| 第一范式 | 需要 | 标注数据 | 传统机器学习 | 文本分类、NER | 可解释性强 | 特征工程耗时 |
| 第二范式 | 不需要 | 标注数据 | 深度学习 | 机器翻译 | 自动学习特征 | 需要大量标注数据 |
| 第三范式 | 不需要 | 未标注+标注数据 | 预训练模型 | 几乎所有NLP任务 | 泛化能力强 | 预训练成本高 |
| 第四范式 | 不需要 | 少量/无标注数据 | 预训练模型 | 分类、生成、推理 | 少样本/零样本学习 | 提示设计复杂 |
样本示例 - 同一任务四种范式的实现差异:
python
// 任务:判断邮件是否为垃圾邮件
// 第一范式(传统机器学习)
{
"特征工程": "提取TF-IDF特征、关键词频率",
"输入": "[0.23, 0.45, 0.12, ...] (特征向量)",
"模型": "朴素贝叶斯分类器",
"输出": "spam"
}
// 第二范式(深度学习)
{
"输入": "恭喜您获得一等奖!点击领取",
"模型": "Word2Vec + LSTM",
"输出": "spam",
"特点": "自动提取特征,无需人工构造"
}
// 第三范式(预训练+微调)
{
"预训练": "BERT在海量文本上训练",
"微调数据": "1000条标注邮件",
"输入": "[CLS] 恭喜您获得一等奖![SEP]",
"输出": "spam",
"特点": "少量数据即可训练出好模型"
}
// 第四范式(Prompt)
{
"预训练": "GPT-3在海量文本上训练",
"模板": "这条消息是垃圾邮件吗?[文本] 答案:[MASK]",
"输入": "恭喜您获得一等奖!",
"输出": "是",
"特点": "无需标注数据,直接推理"
}二、Fine-Tuning(传统微调)
2.1 基本原理
Fine-Tuning是一种迁移学习方式,采用已在大量文本上训练好的预训练语言模型,在小规模任务特定数据上继续训练。
预训练模型(大量通用数据)→ 微调(少量任务数据)→ 适配下游任务
2.2 完整样本示例
训练语料 - 情感分类任务:
python
# 预训练阶段(BERT)
预训练数据 = [
"The movie [MASK] really good.", # 预测: is
"I [MASK] to the store yesterday.", # 预测: went
"She is a [MASK] doctor.", # 预测: great/good/best
# ... 海量无标注文本
]
# 下游微调阶段(情感分类)
训练数据 = [
{"text": "I love this movie!", "label": "positive"},
{"text": "This film is terrible.", "label": "negative"},
{"text": "The acting was amazing.", "label": "positive"},
{"text": "What a waste of time!", "label": "negative"},
{"text": "Absolutely fantastic!", "label": "positive"},
# ... 通常需要500-1000条标注数据
]微调过程示意:
python
# 传统微调的代码逻辑
class BERTWithClassifier(nn.Module):
def __init__(self):
self.bert = BertModel.from_pretrained("bert-base") # 预训练权重
self.classifier = nn.Linear(768, 2) # 新增分类层
def forward(self, input_ids):
# 1. BERT编码
cls_vector = self.bert(input_ids)["pooler_output"] # [batch, 768]
# 2. 分类
logits = self.classifier(cls_vector) # [batch, 2]
return logits
# 训练时更新全部参数
for param in model.parameters():
param.requires_grad = True # 1.1亿参数全部更新!输入输出示例:
python
{
"输入": "[CLS] I love this movie! [SEP]",
"BERT编码": "[0.23, -0.45, 0.67, ...] (768维向量)",
"分类层输出": "[0.85, 0.15]",
"最终输出": "positive"
}2.3 存在的问题
| 问题 | 说明 | 示例 |
|---|---|---|
| 语义偏差 | 预训练任务(MLM)与下游任务(分类)目标不同 | MLM要预测MASK,分类要判断类别 |
| 过拟合风险 | 小样本场景下容易过拟合 | 100条数据训练1.1亿参数 → 记住样本而非学习规律 |
| 资源消耗大 | 每个任务需要存储完整模型副本 | 10个任务 = 10个完整的BERT模型 |
三、Prompt-Tuning(提示微调)
3.1 什么是Prompt?
Prompt就是你给大型语言模型的所有输入,目的是引导它生成你想要的输出。
样本示例 - Prompt的组成:
python
{
"基础Prompt": "请翻译成英文:你好",
"包含指令": "请将以下中文翻译成英文,只输出翻译结果不要解释:你好",
"包含上下文": "用户对话历史:... 当前用户说:你好",
"包含角色": "你是一位专业的翻译官,请翻译:你好",
"包含格式": "请以JSON格式输出:{\"input\": \"你好\", \"output\": \"hello\"}",
"包含范例": "示例:再见→goodbye\n你好→",
"包含约束": "翻译结果不超过10个字母:你好",
"包含思维链": "让我们一步步思考:1.识别语言 2.查找对应 3.输出结果"
}3.2 核心理念对比
Fine-Tuning : 模型迁就任务(改变模型本身)
Prompt-Tuning: 任务迁就模型(改变输入方式)
比喻示例:
python
{
"Fine-Tuning": "让一个只会中文的人学英语 → 改变人本身",
"Prompt-Tuning": "让一个人用中文回答问题 → 改变提问方式"
}3.3 工作原理示例
以情感二分类为例:
python
# ========== 传统Fine-Tuning ==========
输入 = "[CLS] I like this film. [SEP]"
↓
BERT → [CLS]向量 (768维)
↓
新加的分类器 → positive/negative
# ========== Prompt-Tuning ==========
输入 = "[CLS] I like this film. [SEP] It was [MASK]. [SEP]"
↓
BERT → 预测[MASK]位置的词
↓
Verbalizer映射: great→positive, terrible→negative四、Prompt-Tuning主要方法
4.1 In-Context Learning(上下文学习)
特点:不训练模型,只给提示
Zero-shot(零样本)
python
{
"输入": "这个任务要求将中文翻译为英文. 销售→",
"模型输出": "sell",
"特点": "只给任务描述,不给示例"
}One-shot(单样本)
python
{
"输入": "这个任务要求将中文翻译为英文. 你好→hello, 销售→",
"模型输出": "sell",
"特点": "给1个示例"
}Few-shot(少样本)
python
{
"输入": "这个任务要求将中文翻译为英文. 你好→hello, 再见→goodbye, 购买→purchase, 销售→",
"模型输出": "sell",
"特点": "给10-100个示例"
}适用条件:模型参数 > 100亿
4.2 Hard Prompt(离散提示/PET)
核心思想:用MASK完形填空代替分类任务
完整样本示例
python
# ========== 原始数据 ==========
原始数据 = {
"text": "I love this movie!",
"label": "positive"
}
# ========== Pattern模板设计 ==========
模板1 = "{text} It was [MASK]."
模板2 = "{text} I felt [MASK]."
模板3 = "The movie is [MASK]. {text}"
# ========== Verbalizer标签映射 ==========
verbalizer = {
"positive": ["great", "amazing", "wonderful", "good", "fantastic"],
"negative": ["terrible", "awful", "bad", "poor", "horrible"]
}
# ========== 转换后的训练样本 ==========
训练样本 = {
"输入": "[CLS] I love this movie! [SEP] It was [MASK]. [SEP]",
"目标词": "great", # 而不是直接预测positive
"标签": "positive"
}
# ========== 推理过程 ==========
测试样本 = "This film is boring."
输入 = "[CLS] This film is boring. [SEP] It was [MASK]. [SEP]"
↓ BERT
预测[MASK]: P(great)=0.1, P(amazing)=0.05, P(terrible)=0.6, P(awful)=0.2
↓ Verbalizer聚合
P(positive) = 0.1 + 0.05 = 0.15
P(negative) = 0.6 + 0.2 = 0.8
↓
输出: negativePET三步法
python
# 步骤1:用少量标注数据微调多个模型
模型1 = 用模板1微调BERT
模型2 = 用模板2微调BERT
模型3 = 用模板3微调BERT
# 步骤2:用微调后的模型标注无标注数据
无标注数据 = ["OK movie", "Not bad", "So so", ...]
软标签 = 模型集成预测(无标注数据)
# 例: "OK movie" → 0.6 positive, 0.4 negative
# 步骤3:用硬标签+软标签训练最终模型
最终模型 = 训练(标注数据 + 无标注数据)4.3 Soft Prompt(连续提示)
核心思想:将模板转换为可学习的连续向量
Hard Prompt vs Soft Prompt对比
python
# ========== Hard Prompt(离散) ==========
hard_prompt = "It was [MASK]."
# 每个词都是固定的真实token
token_ids = tokenizer.encode("It was [MASK].")
# 输出: [1332, 1106, 103] # 固定的
# ========== Soft Prompt(连续) ==========
soft_prompt = [v1, v2, v3, v4, v5] # 5个伪标记
# 每个vi是一个可学习的向量(768维)
# 初始化方式1:随机初始化
v1 = torch.randn(768) # 正态分布随机
# 初始化方式2:从词表复制
v1 = embedding["great"] # 使用已有词的embedding
# 初始化方式3:使用label word
v1 = embedding["positive_class_token"]
# 训练后,v1成为任务特定的"隐形提示"Prompt Tuning完整示例
python
# ========== 配置 ==========
num_virtual_tokens = 10 # 10个伪标记
hidden_size = 768 # BERT-base维度
# ========== 输入构造 ==========
原始文本 = "I like this film."
文本tokens = tokenizer.encode(原始文本) # [101, 1045, 2066, 2023, 3231, 1012, 102]
# 拼接伪标记
输入 = [v1, v2, ..., v10] + [101, 1045, 2066, 2023, 3231, 1012, 102]
# └──可学习参数──┘ └────────固定不变────────┘
# ========== 训练 ==========
训练配置 = {
"可训练参数": "只有10个伪标记的embedding(10×768=7680个)",
"冻结参数": "BERT全部1.1亿参数",
"训练数据": "100条标注样本",
"优化器": "Adam",
"学习率": "1e-4"
}
# ========== 推理 ==========
# 训练好的伪标记变成该任务的"通关密码"
输入 = 训练好的伪标记 + "This movie is great!"
输出 = model(输入) # 预测[MASK]三种初始化方式对比
python
# 方式1:随机初始化
P_random = torch.randn(10, 768) # 从零开始学
# 方式2:从词表复制
P_copy = embedding[["the", "a", "an", "this", "that"]] # 用常见词初始化
# 方式3:从label word复制
P_label = embedding[["great", "good", "fantastic"]] # 用标签词初始化五、各方法完整对比表
| 方法 | 训练方式 | 更新参数 | 标注数据需求 | 算力 | 样本示例 |
|---|---|---|---|---|---|
| 传统微调 | 全参数更新 | 全部W | 1000+条 | 极高 | 输入:"好电影"+标签→训练 |
| PET | 全参数更新 | 全部W | 100+条 | 中 | "好电影 It was [MASK]" |
| Prompt Tuning | 只训练提示 | 提示向量P | 100+条 | 低 | [v1][v2]好电影[MASK] |
| P-Tuning | 只训练提示 | 提示向量P | 100+条 | 低 | 任意位置插入[v_i] |
| In-Context | 不训练 | 无 | 0条 | 极低 | 给例子→现学→推理 |
六、进阶PEFT方法
6.1 LoRA(Low-Rank Adaptation)
核心思想:权重更新量ΔW是低秩的,可分解为B×A
python
# ========== 传统微调 =========#
W_output = W_input @ W_original # 更新全部W
# ========== LoRA微调 ==========
W_output = W_input @ (W_original + B @ A)
# └─冻结不动─┘ └─只训练B和A─┘
# 参数对比示例(d=4096, k=4096, r=8)
W_original参数 = 4096 × 4096 = 16,777,216
A矩阵参数 = 8 × 4096 = 32,768
B矩阵参数 = 4096 × 8 = 32,768
LoRA总参数 = 65,536 # 减少99.6%!完整代码示例:
python
from peft import LoraConfig, get_peft_model
# 配置LoRA
lora_config = LoraConfig(
r=8, # 低秩维度
lora_alpha=16, # 缩放因子
target_modules=["q_proj", "v_proj"], # 在Q和V层加LoRA
lora_dropout=0.1,
task_type="SEQ_CLS"
)
# 应用LoRA
model = AutoModelForSequenceClassification.from_pretrained("bert-base")
lora_model = get_peft_model(model, lora_config)
# 查看可训练参数
lora_model.print_trainable_parameters()
# 输出: trainable params: 294,912 || all params: 110,000,000 || trainable%: 0.27%6.2 QLoRA
核心思想:4-bit量化 + LoRA
python
from transformers import BitsAndBytesConfig
# 4-bit量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
# 加载4-bit模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b",
quantization_config=bnb_config # 70B模型只需48GB显存!
)七、完整任务示例对比
任务:情感分类(判断评论是积极/消极)
python
// ========== 方法1:传统微调 ==========
{
"训练数据": [
{"text": "This movie is fantastic!", "label": "positive"},
{"text": "I hate this film", "label": "negative"},
{"text": "The acting was amazing", "label": "positive"},
{"text": "What a waste of time", "label": "negative"},
"... (500-1000条)"
],
"模型": "BERT + 分类头",
"训练方式": "更新全部1.1亿参数",
"推理输入": "This movie is great!",
"推理输出": "positive"
}
// ========== 方法2:PET ==========
{
"训练数据": [
{
"输入": "This movie is fantastic! It was [MASK].",
"目标": "great",
"标签": "positive"
},
"... (100-200条)"
],
"模型": "BERT (复用MLM head)",
"训练方式": "更新全部参数,但任务形式接近预训练",
"推理输入": "This movie is great! It was [MASK].",
"推理过程": "预测[MASK]=great → 映射到positive",
"推理输出": "positive"
}
// ========== 方法3:Prompt Tuning ==========
{
"训练数据": [
{
"输入": "[v1][v2][v3][v4][v5] This movie is fantastic! [MASK]",
"目标": "great",
"标签": "positive"
},
"... (100-200条)"
],
"可训练参数": "只有[v1-v5]的embedding",
"推理输入": "[v1][v2][v3][v4][v5] This movie is great! [MASK]",
"推理输出": "positive"
}
// ========== 方法4:In-Context Learning ==========
{
"推理输入": "判断情感:\n'This is great' → 积极\n'I hate this' → 消极\n'This movie is fantastic!' →",
"推理输出": "积极",
"训练数据": "不需要!"
}八、选择决策树
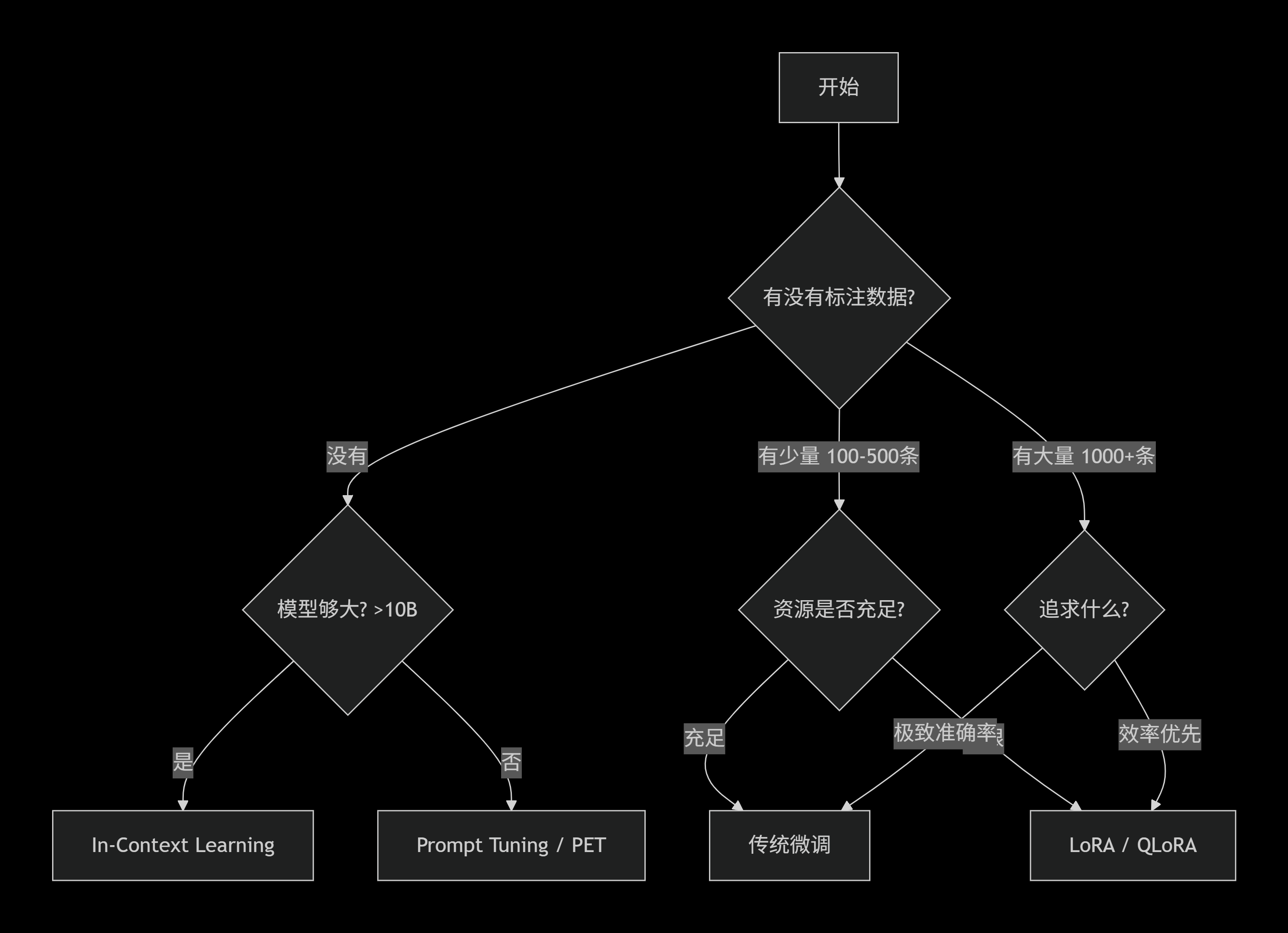
九、技术演进时间线
python
2018: BERT + Fine-tuning (第三范式)
↓
2020: GPT-3 + In-Context Learning (第四范式开端)
↓
2021: PET (Hard Prompt) + Prompt Tuning (Soft Prompt)
↓
2022: P-Tuning v1/v2 + Instruction-Tuning
↓
2023: LoRA + QLoRA (参数高效微调)
↓
现在: RAG + Agent (应用落地)十、总结
| 维度 | 核心要点 |
|---|---|
| NLP四范式 | 传统ML → 深度学习 → 预训练微调 → 提示学习 |
| 传统微调 | 模型迁就任务,更新全部参数,算力大 |
| Prompt-Tuning | 任务迁就模型,冻结模型参数,只调输入 |
| Hard Prompt | 用MASK伪装成完形填空 |
| Soft Prompt | 学连续向量作为隐形提示 |
| In-Context | 给例子让模型现学,不训练 |
| LoRA | 低秩分解,99.6%参数减少 |
| QLoRA | 4-bit量化,消费级显卡跑大模型 |
| 最佳实践 | 大模型用LoRA,小模型考虑全微调 |
📌 记忆口诀:
传统微调动全身,每个任务都分身;
LoRA旁路加插件,原模原样不费神;
Hard Prompt加MASK,伪装填空训模型;
Soft Prompt学暗号,向量引导最聪明;
In-Context给范例,现学现卖是推理。
本文为技术学习笔记,欢迎交流讨论!