针对生成式推荐这一新兴范式,以及其在对时延、收益、商业价值有极致要求的广告场景中的落地难题,快手技术团队发布了一篇开创性的论文,系统性地介绍了自研的生成式广告推荐系统GR4AD。该论文详尽阐述了生成式推荐在大规模广告场景下的全链路重构方案,创新性地提出了从表征、学习到服务三位一体的推荐原生设计。目前,该系统已在快手广告平台全量上线,服务超4亿用户,并取得显著业务收益。

- 论文标题:Generative Recommendation for Large-Scale Advertising
- 论文链接:arxiv.org/pdf/2602.22...
一、引言:"推荐该怎么做"的新范式
过去十年,深度学习推荐模型(DLRM)几乎统治了整个工业界的推荐系统------从召回到排序,从特征交叉到序列建模,它们构建了一套成熟而稳固的技术栈。然而,当大语言模型(LLM)的浪潮席卷而来,一个大胆的问题被抛了出来:能不能像生成文本一样,直接"生成"推荐结果?
这就是生成式推荐(Generative Recommendation)的核心思想。以TIGER、OneRec为代表的一系列工作,已经在自然推荐场景中验证了这一范式的可行性。但当战场转移到大规模广告系统------这个对时延、收益、商业价值都有极致要求的领域------事情变得远没有那么简单。
本篇论文正是对这一问题交出的一份工业级答卷,提出了GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统。目前,该系统已全量部署在快手广告平台,服务超过4亿用户。
二、问题与挑战:广告场景下的三大挑战
我们发现,将LLM的训练和推理范式搬到广告推荐上是行不通的。具体来说,广告场景存在三个独有的核心挑战:
- 挑战一:广告物料的Token化------多元信息的统一编码
广告不是普通的短视频。一条广告背后融合了视频创意、商品详情、广告主B端元数据等多模态、多粒度信息。更棘手的是,平台还提供了转化类型、广告账户等关键业务信号,这些信号具备强烈的商业价值但几乎没有"语义内容"可言。如何为广告物料打造一套既能捕获语义内容、又能编码业务信息的统一Token体系?
- 挑战二:学习范式------面向商业价值的列表级优化
广告推荐的优化目标不是"猜中用户会点哪个"那么简单,而是要在eCPM排序、NDCG等列表级指标下最大化商业价值。现有的生成式推荐方法大多沿用LLM的分阶段训练方式,不完全适配大规模推荐场景的持续在线学习,且缺乏面向排序的、列表级的学习设计。
- 挑战三:实时服务------多候选生成的算力困局
不同于LLM聊天场景中"解码一条回复、容忍较长延迟"的模式,广告系统需要在极高QPS和极低延迟(<100ms)下,通过Beam Search同时生成大量高质量候选。这是一个与LLM不同的推理优化问题。
三、方法:全链路协同设计的破局之道
GR4AD的方法论可以用一句话概括:"表征-学习-推理"三位一体的推荐原生设计,下面逐一拆解。
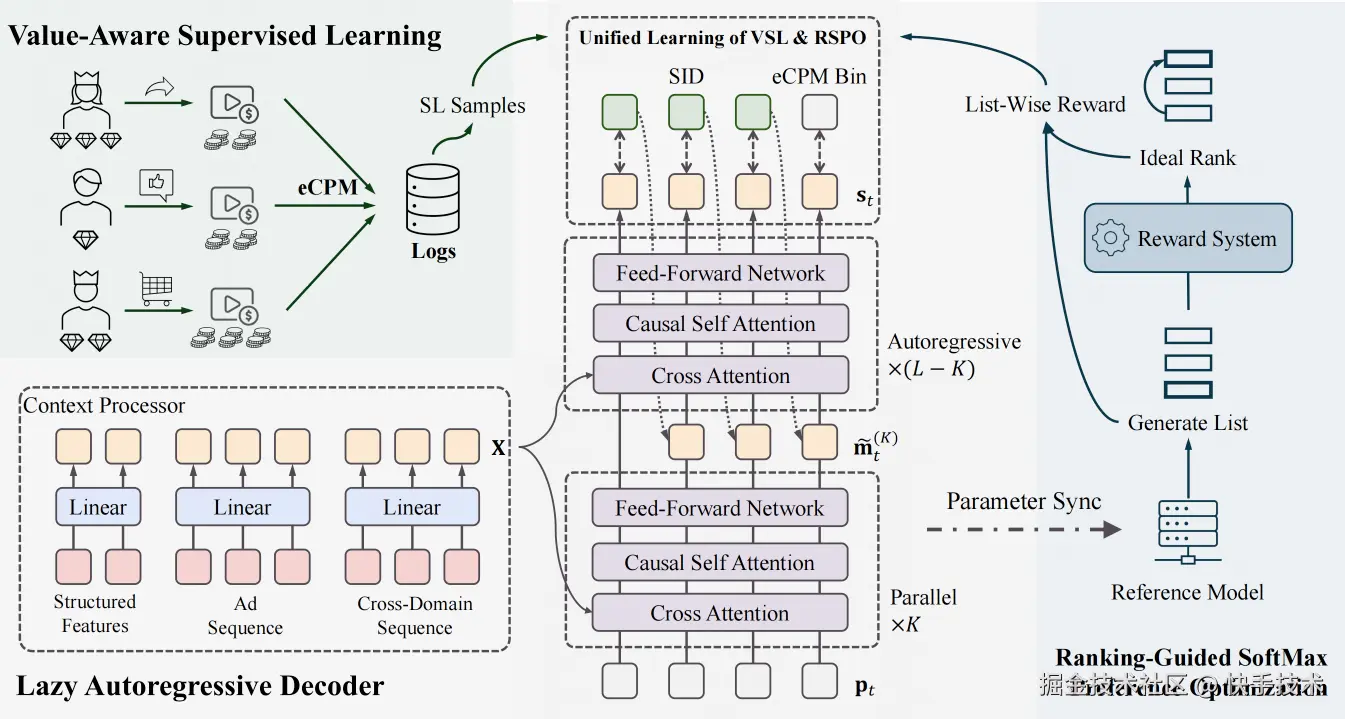
3.1 统一广告语义ID(UA-SID):给广告一个"身份证"
核心思想:用一个端到端微调的多模态大模型(MLLM)为每条广告生成统一嵌入,再通过精心设计的量化方法将其编码为离散Semantic ID。
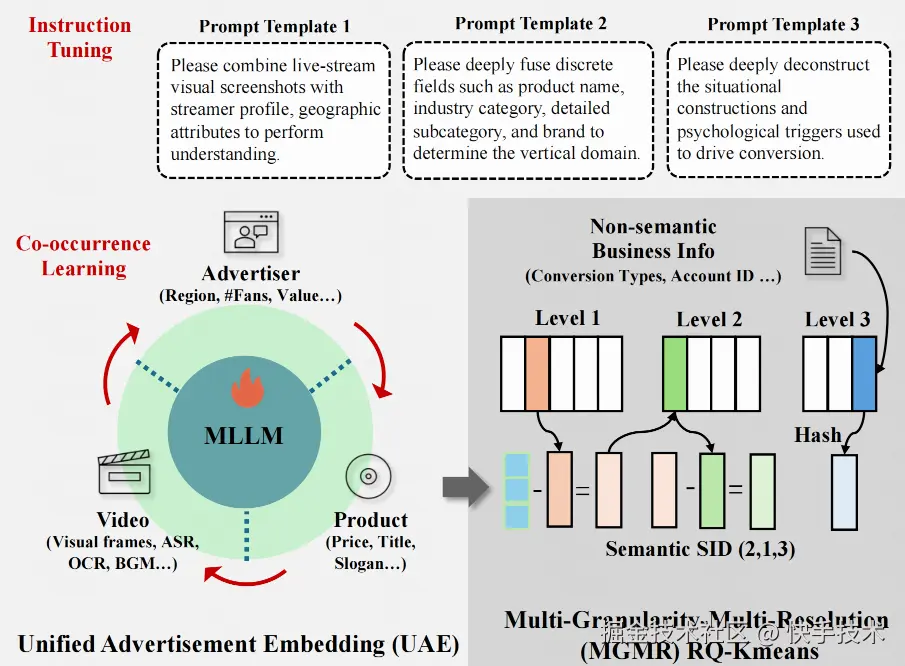
第一步:统一广告嵌入(UAE)
-
指令微调(Instruction Tuning):针对快手广告的6种典型形态(直播、商品、达人等),设计了6套提示模板,引导MLLM从不同视角理解广告内容。比如对直播类广告,引导模型分析主播画像和地域特征;对外部投放广告,则聚焦产品行业和品牌信息。
-
共现学习(Co-occurrence Learning):用户行为中的共现关系蕴含了丰富的协同信号。论文使用Swing方法估计物料共现强度,并采用InfoNCE对比学习目标将其注入表征:
LNCE(i)=−log∑k=iexp(zi⊤zk/τ)∑j∈Piexp(zi⊤zj/τ)
第二步:MGMR RQ-Kmeans量化
这是UA-SID的"杀手锏"。论文提出了多粒度-多分辨率(Multi-Granularity-Multi-Resolution)的RQ-Kmeans量化策略:
-
多分辨率(MR):低层级使用更大的码本捕获主导语义因子,高层级用较小码本建模低熵残差,有效提升码本利用率。
-
多粒度(MG):在最后一层用基于非语义特征的哈希映射替代向量量化------将转化类型、账户ID等业务信号直接编码进SID,一举解决"相同内容、不同投放策略"导致的SID碰撞问题。
最终每个广告物料被映射为一个离散UA-SID序列:
y=(s1,s2,...,sT)
3.2 LazyAR:懒惰解码器的大智慧
生成式推荐在推理时需要通过Beam Search生成多个候选SID序列。标准自回归解码要求每一层都依赖上一步的输出,这在Beam数很大时造成了巨大的计算瓶颈。
本论文的一个关键观察是:第一层SID最难学、损失最大,但它的Beam只有1(从BOS开始);后续层级更容易,Beam却呈指数级膨胀。 大部分计算被浪费在了"简单的事情"上。
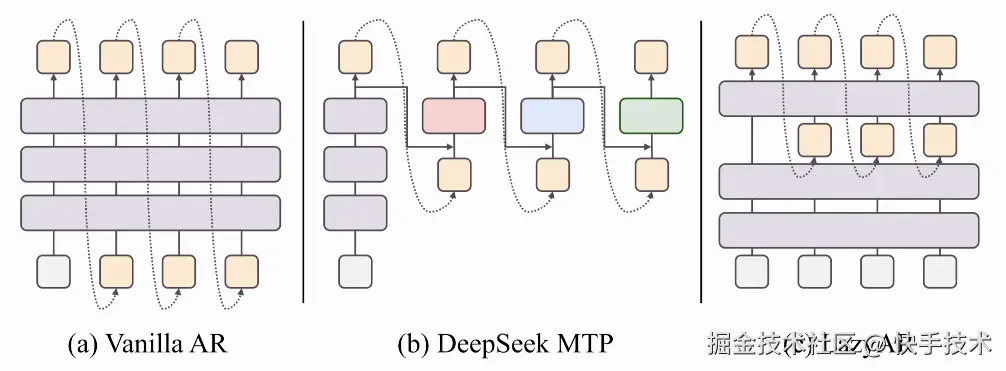
LazyAR的核心操作: 将对上一步token的依赖"延迟"到中间某一层(第K层)注入:
-
前K层(并行层):不依赖上一步token,仅基于位置编码和上下文X进行计算,所有层级和所有Beam可以并行计算并共享。
-
后L-K层(自回归层):注入上一步SID嵌入后进行标准自回归解码。
为什么LazyAR有效?
-
第一层SID的解码过程完全不受影响(从BOS经过全部L层)。
-
前K层在潜空间中进行推理,能编码关于候选token的有用信号。
-
引入MTP辅助损失,强制前K层即使没有上一步token也能学到足够信息。
-
K是可调超参,提供灵活的精度-效率权衡。实验中 K=32L在保持推荐质量的同时将推理吞吐量翻倍。
论文特别指出:这个设计是推荐原生的,不适用于标准LLM解码------因为LLM解码通常不用Beam Search,且后续token的预测难度不一定下降。
3.3 价值感知的监督学习(VSL)
在广告场景中,不同样本的商业价值天差地别。VSL围绕"价值感知"做了三件事:
- SID+eCPM联合预测:在标准SID交叉熵损失之外,将eCPM离散化为桶并追加为额外的预测token:
LNTP=LSID+λeLeCPM
-
价值感知样本加权:每个样本的权重 w=wuser⋅wbehavior,高广告价值用户和深度交互行为(如购买)获得更高权重。
-
MTP辅助损失:配合LazyAR,强制前K层并行解码的表征质量。
最终VSL目标:
LVSL=EDw(LNTP+λmtpLMTP)
3.4 排序引导的强化学习(RSPO):从"学分布"到"优排序"
VSL能拟合历史数据分布,但它不直接优化下游排序目标,也不支持对未知标签分布的探索。论文因此引入了RSPO(Ranking-Guided Softmax Preference Optimization),一个面向列表级NDCG优化的RL算法。
RSPO的核心loss:
LRSPO=−E log2σ −logyj∈Ei∑Mijexp(βlogpref(yj∣X)Cijpθ(yj∣X)−βlogpref(yi∣X)Cijpθ(yi∣X))
其中 Mij遵循Lambda框架,论文证明了RSPO是NDCGcost的上界,从理论上保证了对排序指标的直接优化。
几个精妙的工程设计:
-
参考模型的可靠性门控 Cij:样本来源多样(有些来自GR4AD自身、有些来自其他pipeline), pref不总是可靠的。当模型与参考分布偏差过大时,自动关闭参考约束,避免噪声正则化。
-
VSL与RSPO的统一在线训练:通过样本级对齐分数动态调整两个目标的权重------模型排序与奖励排序偏差大时加重VSL(学好基础分布),偏差小时加重RSPO(精细化价值优化)。
四、线上部署:工业级系统的全闭环设计
GR4AD(0.16B参数)已全量部署于快手广告系统,实现了一套"奖励估计 → 在线学习 → 实时索引 → 实时服务"的完整闭环。 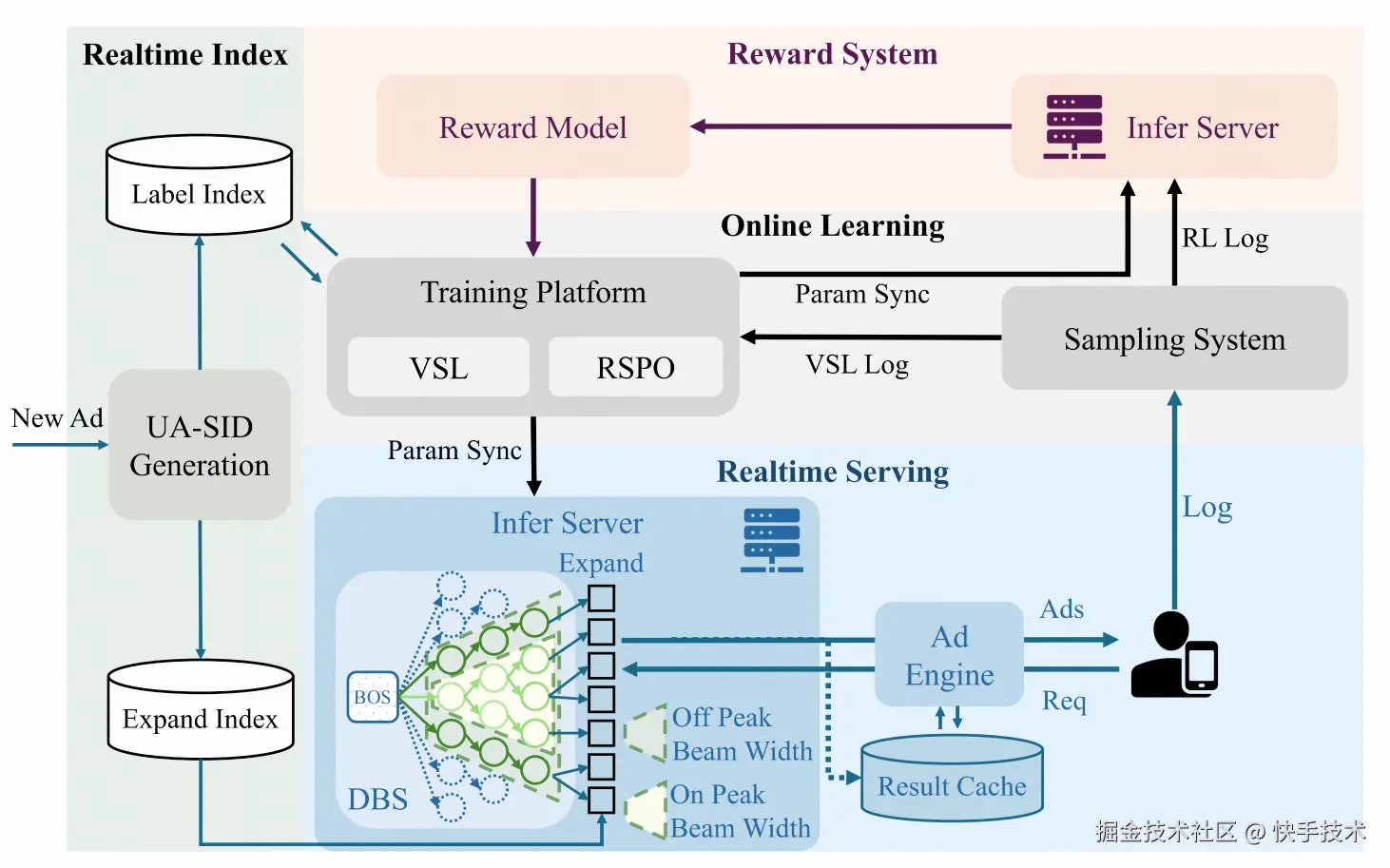
4.1 四大核心模块
-
奖励系统(Reward System):训练独立的Reward Model对GR4AD生成的候选集进行eCPM评分,在放松延迟约束的环境下进行更大Beam的探索,为RL训练提供高质量信号。
-
在线学习模块:实时构建VSL和RL两种训练信号,持续进行mini-batch更新,实时推送参数到推理服务。
-
实时索引模块:用SID替代传统嵌入索引。新物料到达时只需计算UA-SID并更新双向索引(UA-SID ↔ Item ID),秒级生效,大幅改善冷启动覆盖和时效性。
-
实时服务引擎:处理用户请求并返回排序广告列表。
4.2 推理效率优化:把算力用在刀刃上
动态Beam服务(DBS)是本文的又一亮点,包含两个子机制:
-
动态Beam宽度(DBW):用递增的Beam调度(如128→256→512)替代固定宽度(512→512→512),在不损失最终候选质量的前提下大幅削减中间层计算。
-
流量感知自适应Beam搜索(TABS):根据实时QPS自动调整Beam规模------低峰期加大Beam提升推荐质量,高峰期收缩Beam保障延迟和吞吐。
此外,还有一系列工程优化,具体如下:
-
Beam共享KV Cache:将Beam从batch维度转移至序列维度进行组织,实现KV Cache的共享,显著提升内存访问效率(+212.5% QPS)。
-
TopK预裁剪:先并行选取每个Beam的K个候选结果,再对聚合候选集进行全局Top-K 选择,在有效缩减搜索空间的同时保证准确性(+184.8% QPS)、FP8低精度推理(+50.3% QPS)、短TTL结果缓存(+27.8% QPS)。
最终效果:<100ms延迟,500+ QPS/L20 GPU。
五、实验效果:广告收入和推理性能的双赢
5.1 总体性能与消融实验
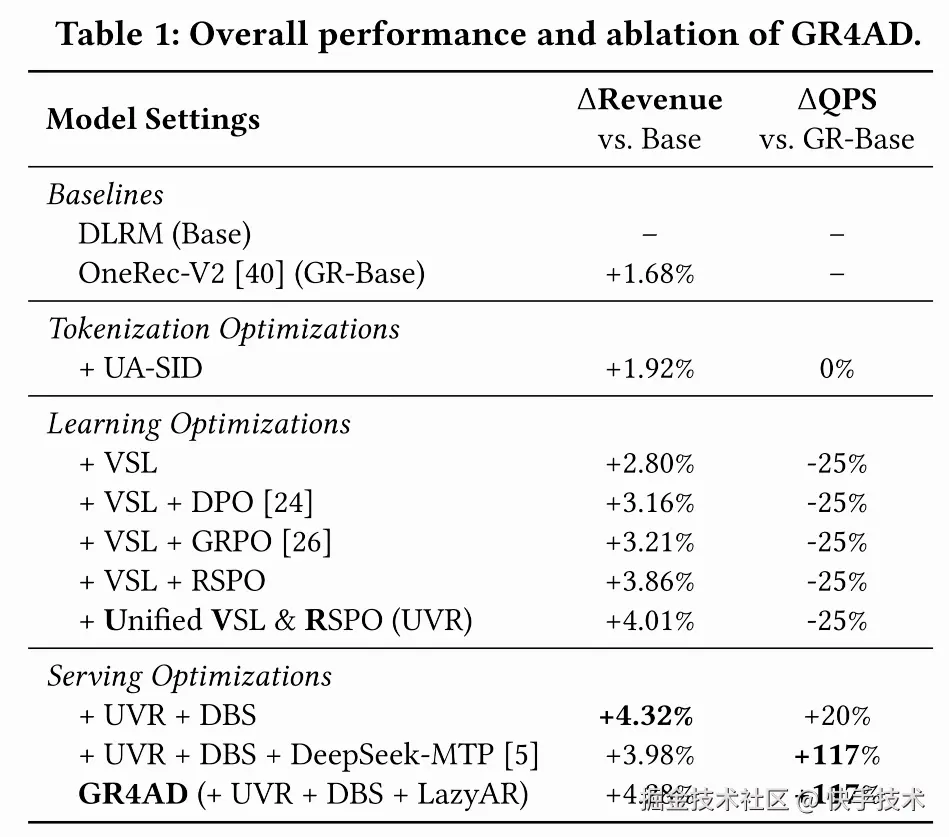
几个关键发现:
-
RSPO是所有优化中增益最大的单一组件,显著优于DPO和GRPO,验证了列表级RL在广告场景的不可替代性。
-
LazyAR以极微小的精度代价换来了吞吐量翻倍,实际部署的关键使能技术,优于DeepSeek-MTP。
-
DBS在不损失收益的前提下进一步提升了效率,TABS机制在低峰期还能反向提升收入。
5.2 Scaling Law
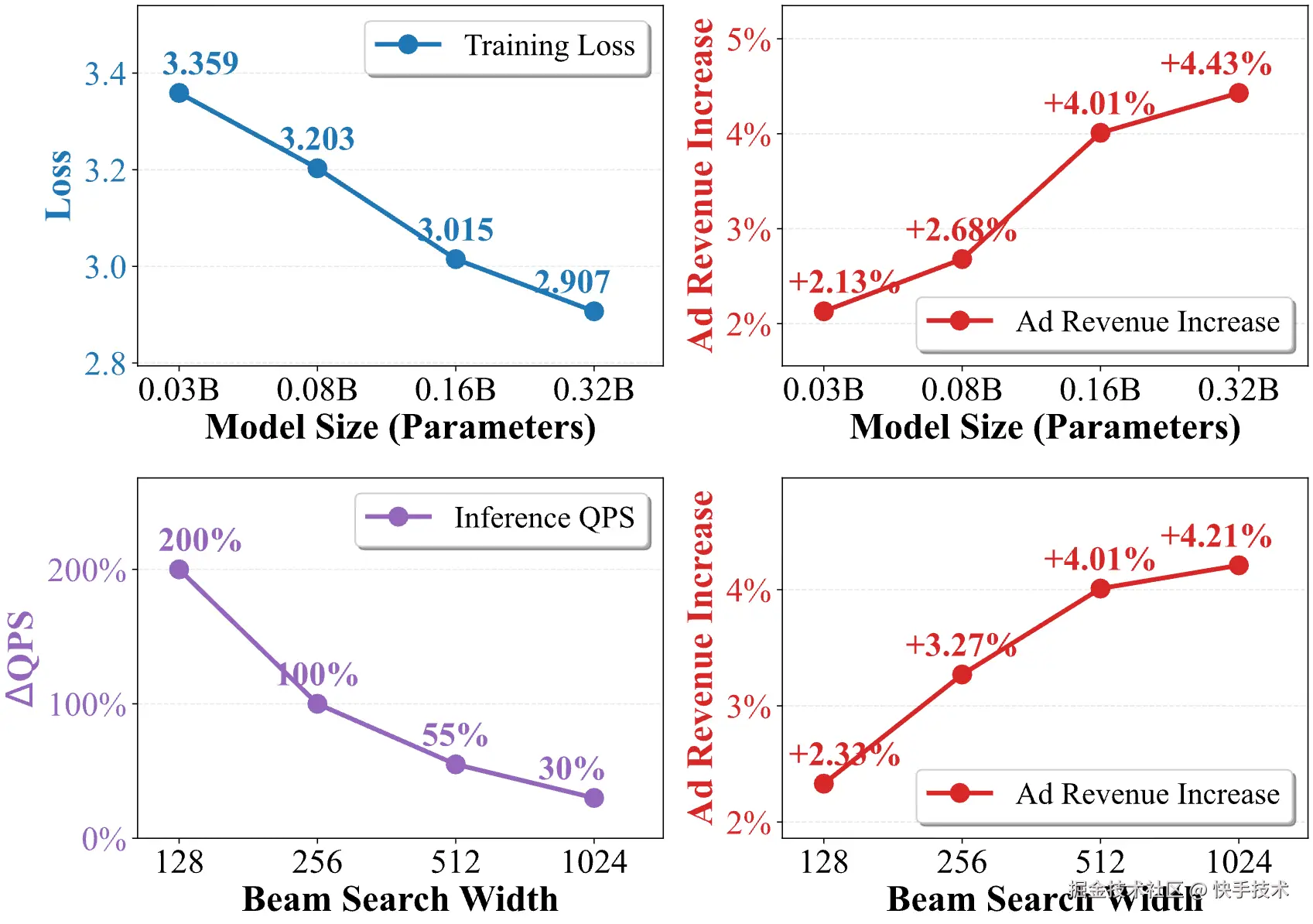
-
模型规模方向:从0.03B到0.32B,收入提升从+2.13%单调增长到+4.43%,训练损失也持续下降。生成式广告推荐的Scaling Law是成立的。
-
推理规模方向:Beam宽度从128增加到1024,收入从+2.33%提升到+4.21%。这意味着更强的推理时搜索能进一步释放模型潜力------这与当前LLM领域Test-time Scaling的趋势遥相呼应。
5.3 UA-SID质量
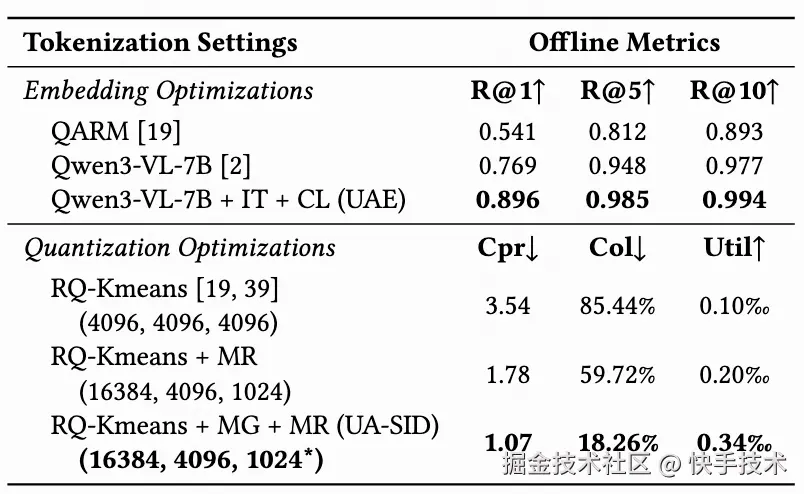
在嵌入质量评估(photo-to-photo recall)中,经过指令微调和共现学习的UAE达到了R@1=0.896,远超基线QARM(0.541)和原始Qwen3-VL-7B(0.769)。MGMR量化将SID碰撞率从85.44%降至18.26%,码本利用率提升3倍以上。
5.4 商业指标的全面胜利
-
商业化广告收入4.2%+
-
中小广告主投放量提升17.5%
-
广告转化率提升10.17%
-
低活用户转化率提升7.28%
基于内容的SID带来的更强泛化能力和更实时的索引对冷启动物料的更好支持,实现了平台、广告主、用户的三方共赢。
六、总结与思考
本篇论文的价值不仅在于实现了4.2%的收入提升,更在于系统性地回答了一个关键问题:在广告这一最"硬核"的工业场景中,生成式推荐究竟应该如何设计与落地?
答案是:不要照搬LLM,要做推荐原生的设计。
-
Token化不能只看内容语义,要把业务信号编码进去(UA-SID + MGMR)。
-
训练不能只做单点概率生成,要做价值感知的列表级优化(VSL + RSPO)。
-
推理不能只套用LLM加速技巧,要针对"短序列、多候选、Beam Search"的推荐特性做专门设计(LazyAR + DBS)。
-
系统不能离线批处理,要做实时索引、在线学习、闭环反馈的全链路打通。
GR4AD是生成式推荐走向广告工业核心场景的一个重要里程碑。快手用超过4亿用户的真实流量验证了这条路径的可行性。可以预见,这一范式将引发行业的广泛跟进与演进。