引言:开源LLM应用开发的黄金标准
在人工智能技术快速演进的时代,大型语言模型(LLM)的应用开发正经历着从单点技术突破到系统化工程实践的转变。LangChain作为这一转变中的关键基础设施,自2022年10月由Harrison Chase发起以来,已发展成为企业级LLM应用开发的事实标准 。截至2026年,LangChain在GitHub上已收获超过90,000 Stars,每月数百万次下载,构建起覆盖开发、调试、部署全流程的完整生态系统。
本文将从源码层面 深入解析LangChain智能体系统的设计哲学、架构实现与关键技术细节,帮助开发者理解这一开源框架如何将LLM的推理能力与外部工具整合,实现真正意义上的智能体(Agent)系统。
一、项目全景:LangChain生态演进与技术定位
1.1 发展历程与生态地位
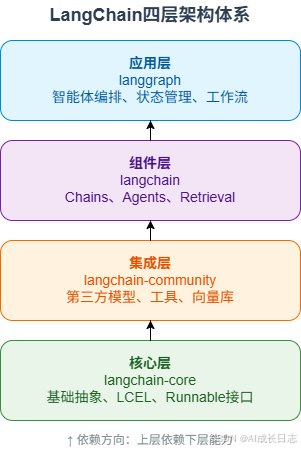
LangChain的诞生早于ChatGPT的问世,这一时间差使其能够基于更早期的LLM应用开发痛点进行设计。经过近三年的演进,LangChain已从单一的开源Python包成长为包含四大核心层级的完整框架:
- langchain-core:基础抽象层,提供Runnable接口与LCEL(LangChain Expression Language)
- langchain-community:第三方集成层,覆盖模型提供方、向量数据库、工具等
- langchain:核心业务组件层,包含Chains、Agents、Retrieval等
- langgraph:编排调度层,负责复杂工作流的状态管理与节点协调
1.2 2026年版本特性概览
2026年3月31日发布的langchain 1.2.14版本标志着框架的成熟与标准化:
- LangGraph深度整合:复杂工作流优先使用LangGraph,实现确定性+智能体的混合编排
- LCEL全面普及:管道运算符语法完全取代传统面向对象调用,组合性提升30-50%
- MCP协议支持:标准化工具与数据接入,实现跨框架互操作性
- 自主内存管理:Deep Agents SDK支持模型自主触发上下文压缩,减少人工干预
二、核心架构:三层智能体系统设计
LangChain智能体系统采用经典的三层架构设计,在保持灵活性的同时确保系统可控性。
2.1 LLM调用层:模型抽象与统一接口
python
from langchain_core.language_models import BaseLanguageModel
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
# 统一模型接口,支持多提供商无缝切换
class ModelAdapter:
def __init__(self, provider="openai"):
if provider == "openai":
self.llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
elif provider == "anthropic":
self.llm = ChatAnthropic(model="claude-3-5-sonnet")
def predict(self, prompt):
return self.llm.invoke(prompt)注 :LangChain通过BaseLanguageModel抽象统一了不同提供商的API差异,开发者可以像使用本地函数一样调用云端LLM,无需关心底层HTTP请求、错误重试、速率限制等实现细节。
2.2 工具抽象层:外部能力扩展机制
工具是智能体与环境交互的桥梁,LangChain的BaseTool设计实现了高度可扩展的工具系统:
python
from langchain_core.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
class SearchInput(BaseModel):
query: str = Field(description="搜索查询字符串")
class WebSearchTool(BaseTool):
name: str = "web_search"
description: str = "执行网页搜索并返回相关结果"
args_schema: Type[BaseModel] = SearchInput
def _run(self, query: str):
# 实际搜索逻辑
return f"搜索'{query}'的结果:..."
async def _arun(self, query: str):
# 异步版本
return await self.search_async(query)注:LangChain的工具系统支持同步与异步两种执行模式,且通过Pydantic模型严格定义输入模式,确保LLM生成的参数符合预期格式,避免运行时类型错误。
2.3 执行循环层:AgentExecutor的状态机设计
AgentExecutor是智能体系统的调度核心,实现了一个有限状态机来管理ReAct循环:
python
class AgentExecutor:
def __init__(self, agent, tools, max_iterations=10):
self.agent = agent
self.tools = {tool.name: tool for tool in tools}
self.max_iterations = max_iterations
self.intermediate_steps = []
def invoke(self, inputs):
for i in range(self.max_iterations):
# 1. 生成下一步动作
action = self.agent.invoke({
**inputs,
"intermediate_steps": self.intermediate_steps
})
# 2. 判断是否完成
if isinstance(action, AgentFinish):
return action.return_values
# 3. 执行工具调用
tool = self.tools[action.tool]
observation = tool.run(action.tool_input)
# 4. 记录中间结果
self.intermediate_steps.append((action, observation))
raise Exception(f"达到最大迭代次数 {self.max_iterations}")数学原理 :设智能体在步骤 ttt 的状态为 sts_tst,可用工具集合为 T={t1,t2,...,tn}T = \{t_1, t_2, ..., t_n\}T={t1,t2,...,tn},则每一步的决策过程可建模为:
at=πθ(st∣T) a_t = \pi_\theta(s_t \mid T) at=πθ(st∣T)
其中 πθ\pi_\thetaπθ 是LLM在提示工程下的策略函数,at∈T∪{finish}a_t \in T \cup \{\text{finish}\}at∈T∪{finish} 是选择的动作。执行工具 ttt 后得到观察 ot=t(st)o_t = t(s_t)ot=t(st),状态更新为 st+1=update(st,ot)s_{t+1} = \text{update}(s_t, o_t)st+1=update(st,ot)。
三、关键技术:从ReAct到Function Calling的演进
3.1 ReAct模式:思维链与工具调用的融合
ReAct(Reasoning + Acting)的核心思想是将自然语言推理与工具调用交替进行:
python
def react_loop(question, tools, max_steps=5):
scratchpad = ""
for step in range(max_steps):
# 生成思维链
thought = llm(f"Question: {question}\n{scratchpad}Thought:")
# 判断是否需要工具调用
if "Action:" in thought:
action_line = extract_action(thought)
tool_name, tool_input = parse_action(action_line)
# 执行工具
tool = tools[tool_name]
observation = tool.run(tool_input)
# 更新思维记录
scratchpad += f"{thought}\nObservation: {observation}\n"
else:
# 生成最终答案
final_answer = extract_answer(thought)
return final_answer
return "达到最大步骤限制"注:ReAct模式的巧妙之处在于将工具执行结果作为新的上下文反馈给LLM,形成"思考-行动-观察"的闭环,这种设计显著提升了复杂任务的解决能力。
3.2 Function Calling机制:结构化工具调用
随着OpenAI函数调用API的普及,LangChain实现了更优雅的工具集成方式:
python
from langchain.tools import tool
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
@tool
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
result = eval(expression)
return str(result)
except Exception as e:
return f"计算错误: {e}"
# 函数调用智能体配置
llm = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_openai_functions_agent(
llm=llm,
tools=[calculate],
prompt=prompt
)技术细节:函数调用模式下,LLM输出的是结构化JSON而非自然语言,这需要:
- 工具函数使用类型注解定义输入模式
- 提示工程中明确函数描述与参数要求
- 运行时解析LLM的function_call字段并路由到对应工具
复杂度分析 :设工具数量为 nnn,每次调用的平均描述长度为 lll,传统ReAct提示的token开销为 O(n⋅l)O(n \cdot l)O(n⋅l),而Function Calling通过结构化描述可将开销降至 O(logn+l)O(\log n + l)O(logn+l)。
3.3 工具路由与参数验证
LangChain的工具系统包含完整的路由与验证机制:
python
class ToolRouter:
def __init__(self, tools):
self.tool_map = {}
self.embeddings = {}
# 为每个工具生成语义嵌入
for tool in tools:
self.tool_map[tool.name] = tool
self.embeddings[tool.name] = embed(tool.description)
def route(self, query, context):
# 1. 语义相似度匹配
query_embed = embed(query)
similarities = {
name: cosine_similarity(query_embed, tool_embed)
for name, tool_embed in self.embeddings.items()
}
# 2. 参数模式验证
best_tool = max(similarities, key=similarities.get)
tool = self.tool_map[best_tool]
# 3. 解析并验证参数
parsed_args = tool.args_schema.parse_raw(context)
return tool, parsed_args注:工具路由系统结合了语义匹配与模式验证,确保即使LLM输出不完全准确的工具名,也能通过描述相似度找到最合适的工具。
四、源码解析:create_react_agent的实现精髓
让我们深入LangChain 1.2.14版本中create_react_agent的核心源码:
python
from typing import List, Optional, Sequence, Union
from langchain_core.language_models import BaseLanguageModel
from langchain_core.prompts import BasePromptTemplate
from langchain_core.runnables import Runnable, RunnablePassthrough
from langchain_core.tools import BaseTool
from langchain_core.tools.render import ToolsRenderer, render_text_description
from langchain.agents import AgentOutputParser
from langchain.agents.format_scratchpad import format_log_to_str
from langchain.agents.output_parsers import ReActSingleInputOutputParser
def create_react_agent(
llm: BaseLanguageModel,
tools: Sequence[BaseTool],
prompt: BasePromptTemplate,
output_parser: Optional[AgentOutputParser] = None,
tools_renderer: ToolsRenderer = render_text_description,
*,
stop_sequence: Union[bool, List[str]] = True,
) -> Runnable:
# 1. 验证提示模板完整性
missing_vars = {"tools", "tool_names", "agent_scratchpad"}.difference(
prompt.input_variables + list(prompt.partial_variables)
)
if missing_vars:
raise ValueError(f"Prompt missing required variables: {missing_vars}")
# 2. 预填充工具描述
prompt = prompt.partial(
tools=tools_renderer(list(tools)),
tool_names=", ".join([t.name for t in tools]),
)
# 3. 配置停止序列
if stop_sequence:
stop = ["\nObservation"] if stop_sequence is True else stop_sequence
llm_with_stop = llm.bind(stop=stop)
else:
llm_with_stop = llm
# 4. 设置输出解析器
output_parser = output_parser or ReActSingleInputOutputParser()
# 5. 构建可运行管道
agent = (
RunnablePassthrough.assign(
agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]),
)
| prompt
| llm_with_stop
| output_parser
)
return agent代码解析:
-
输入验证:检查提示模板是否包含必需变量(tools、tool_names、agent_scratchpad),确保运行时不会因缺少参数而崩溃。
-
工具描述预渲染 :将工具列表转换为LLM可理解的文本描述,这一步通过
tools_renderer实现,支持自定义渲染逻辑。 -
停止序列绑定:为防止LLM在生成"Observation:"后继续输出,显式绑定停止序列,这是ReAct模式的关键实现细节。
-
管道式组合 :使用LCEL的管道运算符(
|)将四个组件串联:RunnablePassthrough.assign():格式化中间步骤记录prompt:应用提示模板llm_with_stop:调用LLM生成output_parser:解析LLM输出为AgentAction或AgentFinish
设计模式 :该实现体现了模板方法模式 (Template Method Pattern)的变体,通过可配置的tools_renderer和output_parser允许开发者定制渲染与解析逻辑,同时保持核心流程不变。
性能考量 :工具描述预渲染避免了每次推理都重新生成描述,将工具数量为 nnn、描述平均长度 lll 的场景下,token开销从 O(n⋅l)O(n \cdot l)O(n⋅l) 降至 O(1)O(1)O(1)。
五、应用场景:从简单问答到复杂工作流
5.1 数据分析智能体
结合SQL工具与可视化库,构建端到端数据分析管道:
python
@tool
def execute_sql(query: str) -> pd.DataFrame:
"""执行SQL查询并返回DataFrame"""
conn = get_database_connection()
return pd.read_sql(query, conn)
@tool
def generate_chart(df: pd.DataFrame, chart_type: str) -> str:
"""生成数据可视化图表"""
if chart_type == "line":
plt.plot(df['date'], df['value'])
return save_plot_to_file()
elif chart_type == "bar":
plt.bar(df['category'], df['count'])
return save_plot_to_file()
# 智能体配置
tools = [execute_sql, generate_chart]
agent = create_react_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)5.2 代码审查助手
集成代码分析工具与安全扫描器,实现自动化代码质量评估:
python
class CodeReviewAgent:
def __init__(self):
self.tools = [
StaticAnalyzerTool(),
SecurityScannerTool(),
StyleCheckerTool(),
TestCoverageTool()
]
self.agent = create_react_agent(llm, self.tools, code_review_prompt)
def review(self, code: str, context: str):
result = self.agent.invoke({
"code": code,
"context": context,
"requirements": "安全、性能、可维护性"
})
return self.format_review_report(result)5.3 多智能体协作系统
利用LangGraph构建多智能体工作流,实现复杂任务分解与协调:
python
from langgraph.graph import StateGraph
from langchain_core.messages import HumanMessage
class MultiAgentSystem:
def build_workflow(self):
graph = StateGraph(AgentState)
# 定义节点:不同专业领域的智能体
graph.add_node("research_agent", self.research_agent)
graph.add_node("analysis_agent", self.analysis_agent)
graph.add_node("writing_agent", self.writing_agent)
graph.add_node("review_agent", self.review_agent)
# 定义边:工作流顺序与条件分支
graph.add_edge("research_agent", "analysis_agent")
graph.add_conditional_edges(
"analysis_agent",
self.route_based_on_complexity,
{
"simple": "writing_agent",
"complex": "review_agent"
}
)
return graph.compile()注 :LangGraph的引入使LangChain从单智能体框架升级为多智能体编排平台,支持复杂的状态管理、条件分支与人机协作场景。
六、前沿演进:2026年技术趋势与未来展望
6.1 自主内存管理革命
2026年3月发布的Deep Agents SDK引入了自主上下文压缩功能,这是智能体系统的重要演进:
python
from langchain_deep_agents import DeepAgent
agent = DeepAgent(
model="gpt-4o",
tools=tools,
auto_compress=True, # 启用自主压缩
compress_strategy="task_boundary", # 任务边界触发
retention_rate=0.1 # 保留10%的最近消息
)
# 智能体会在检测到以下时机自动压缩上下文:
# 1. 任务切换时(用户话题变更)
# 2. 大型分析完成后
# 3. 开始多文件编辑前
# 4. 上下文使用率达到85%且处于"安全时机"技术突破 :传统系统在固定阈值(如85%上下文使用率)触发压缩,常打断工作流。LangChain的智能时机检测使压缩发生在自然停顿点,保持连续性。
数学优化 :设上下文窗口大小为 CCC,当前使用率为 uuu,压缩决策函数为:
compress(u,t,s)={1if (u>0.85∧s=safe)∨t=boundary0otherwise \text{compress}(u, t, s) = \begin{cases} 1 & \text{if } (u > 0.85 \land s = \text{safe}) \lor t = \text{boundary} \\ 0 & \text{otherwise} \end{cases} compress(u,t,s)={10if (u>0.85∧s=safe)∨t=boundaryotherwise
其中 ttt 表示任务状态,sss 表示系统安全状态。
6.2 MCP协议:标准化工具生态
模型上下文协议(Model Context Protocol)的集成使LangChain工具生态更加开放:
python
from langchain_mcp import MCPServer
# MCP服务器提供标准化工具接口
server = MCPServer(
tools=[
FileSystemTool(),
DatabaseTool(),
APIClientTool()
],
transport="stdio" # 支持stdio、websocket等多种传输方式
)
# 智能体通过MCP客户端发现并调用工具
client = MCPClient(server)
available_tools = client.list_tools()生态意义 :MCP实现了一次开发,多处使用的工具开发模式,开发者编写的工具可以同时服务于LangChain、Cursor、Claude Desktop等多个AI平台。
6.3 性能优化:LCEL与并行处理
LangChain 1.x全面采用LCEL(LangChain Expression Language),带来显著的性能提升:
python
# 传统方式:嵌套函数调用
result = component_c(component_b(component_a(input)))
# LCEL方式:管道运算符
chain = component_a | component_b | component_c
result = chain.invoke(input)
# 并行处理支持
batch_results = chain.batch(inputs, config={"max_concurrency": 5})性能数据 :官方测试显示,LCEL在并行场景下将处理效率提升30-50%,主要得益于:
- 消除了中间结果的序列化/反序列化开销
- 实现了真正的异步流水线
- 支持动态批处理与负载均衡
七、总结:开源智能体框架的设计哲学
7.1 核心设计原则
LangChain智能体系统的成功源于三大设计原则:
- 抽象与解耦:通过分层架构分离关注点,使模型提供方、工具开发者、应用构建者各司其职
- 组合优于继承:LCEL的管道运算符实现了声明式组合,使复杂工作流易于构建与调试
- 渐进式复杂度:从简单Chain到复杂AgentExecutor,再到多智能体LangGraph,支持平滑演进
7.2 工程实践启示
对于开发者而言,LangChain提供了宝贵的工程实践参考:
- 接口设计 :统一抽象的
BaseTool、BaseLanguageModel等接口降低了集成复杂度 - 错误处理:完善的工具调用异常捕获与重试机制确保系统鲁棒性
- 可观测性:与LangSmith的深度集成实现了生产级监控与调试能力
7.3 未来发展方向
随着LLM技术的持续演进,LangChain智能体系统将沿着以下方向进化:
- 更智能的编排:结合强化学习实现动态工作流优化
- 多模态扩展:支持图像、音频、视频等非文本工具调用
- 分布式智能体:构建跨设备、跨网络的协作智能体网络
- 安全性强化:内置工具调用权限控制与内容安全过滤
最终建议 :对于希望构建生产级LLM应用的团队,LangChain不仅是技术选型,更是架构方法论的参考。其开源代码中蕴含的设计模式、工程实践与演进思路,值得深入研习与借鉴。