在实际数据分析任务中,往往很少只使用单一工具。一个完整的数据处理流程,通常包括数据生成、数据整理、统计分析和结果展示等多个环节。对于 Python 数据分析而言,NumPy、Pandas 和 Matplotlib 常常协同使用,构成从原始数据到可视化呈现的基础工具链。
其中:
NumPy 更适合生成和处理数值型数组数据;
Pandas 更擅长对表格型数据进行清洗、整理、分组和统计;
Matplotlib 则负责将分析结果以图形方式展示出来。
三者分工明确、衔接自然,因此在教学和实际项目中都具有很强的代表性。
本实例围绕一组模拟用户数据展开,字段包括年龄、收入和学历。通过该案例,可以理解 Pandas 如何在数据分析流程中起到"中间枢纽"的作用:一方面接收 NumPy 生成的数据,另一方面为 Matplotlib 提供整理后的分析结果。
一、理论基础
1、为什么 Pandas 适合处理这类数据
在本实例中,数据包含三个字段:
• 年龄
• 收入
• 学历
这类数据具有典型的表格结构:每一行表示一个样本,每一列表示一个特征。
与 NumPy 的纯数组相比,Pandas 提供了带标签的数据结构,更适合处理这种"既有数值字段,也有类别字段"的数据。因此,当数据已经不只是简单的一组数值,而是具有"列名、字段含义、分组统计需求"的结构化数据时,Pandas 往往比 NumPy 更方便。
2、DataFrame 在流程中的作用
Pandas 中最常用的数据结构是 DataFrame。它可以理解为一张带有行索引和列标签的二维表。
在本实例中,年龄、收入和学历会先被组织成一张表格;随后,异常值处理、分组统计等操作都在这张表上完成;最后,再将整理后的结果交给 Matplotlib 绘图展示。
这说明 DataFrame 不只是"保存数据"的容器,更是连接数据生成、数据分析与结果展示的中间结构。
3、数据预处理的含义
所谓数据预处理,是指在正式分析之前,对原始数据进行整理和修正,使其更适合后续统计与建模。
本实例中的预处理主要包括一项操作:处理异常值。为了演示这一过程,后文会先人为加入少量负收入值,再用收入均值对这些异常值进行替换。常见写法为:
bash
df.loc[df["收入"] < 0, "收入"] = df["收入"].mean()这里体现了 Pandas 的一个重要特点:可以通过"行条件 + 列名"的方式,直接定位并修改满足条件的数据。
4、分组统计的含义
除了清洗数据,Pandas 还非常适合进行分组分析。
本实例按照"学历"这一类别字段,对"收入"进行统计,并计算:
• 平均值
• 标准差
• 样本数
常见写法为:
css
df.groupby("学历")["收入"].agg(["mean", "std", "count"])这里的含义是:
先按"学历"分组;
选取"收入"这一列;
对每个分组计算多个统计指标。
这种"按类别分组,再对数值字段聚合"的方式,是 Pandas 中最常见的分析模式之一。
5、从表格分析到可视化
在数据分析流程中,可视化并不是孤立进行的,而是建立在前面整理和统计的基础之上。
本实例中,Pandas 输出了两类适合可视化的数据:
清洗后的表格数据,可用于绘制年龄与收入的散点图;
按学历分组后的平均收入结果,可用于绘制柱状图。
这说明 Pandas 不仅负责"存数据",更负责把数据整理成适合展示的形式,再交给 Matplotlib 完成图形绘制。
二、任务分析
1、实例目标
本实例展示的是一个"三大工具协同工作流"的完整过程,主要分为三个阶段:
(1)用 NumPy 生成模拟数据;
(2)用 Pandas 进行预处理与分析;
(3)用 Matplotlib 完成可视化展示。
虽然整个案例涉及三个库,但从数据处理流程看,Pandas 处于核心位置:它把前面的数组数据转化为结构化表格,并在此基础上完成清洗和统计。
2、原始数据的构成
本实例使用 NumPy 随机生成了 200 条样本数据,主要包含三个字段:
• 年龄:18 到 59 岁之间的随机整数
• 收入:与年龄正相关,并加入随机噪声
• 学历:从"高中及以下""大专""本科""硕士及以上"中按概率抽样生成
这种构造方式的特点在于:
数据规模适中,便于演示;
字段类型丰富,既有数值型也有类别型;
收入与年龄具有一定相关性,更接近真实业务场景。
3、本实例涉及的 Pandas 知识点
本实例中与 Pandas 直接相关的知识点主要包括以下几类:
(1)创建 DataFrame
ini
df = pd.DataFrame({"年龄": age, "收入": income, "学历": education})这一步完成了从"数组"到"表格"的转换。
(2)条件定位与赋值
bash
df.loc[df["收入"] < 0, "收入"] = df["收入"].mean()这里既包含条件筛选,也包含原地赋值,是 Pandas 处理中异常值的常见方式。
(3)分组统计
css
df.groupby("学历")["收入"].agg(["mean", "std", "count"])这是典型的"分类变量 + 数值变量"分析模式。
(4)排序后的结果用于绘图
cs
df.groupby("学历")["收入"].mean().sort_values(ascending=False)这说明 Pandas 输出的数据不仅可用于文字统计,也可直接作为可视化输入。
4、处理流程设计
本实例按以下顺序完成:
(1)利用 NumPy 生成模拟样本数据;
(2)使用 Pandas 创建 DataFrame;
(3)人为加入少量异常收入值,并进行处理;
(4)按学历分组统计收入特征;
(5)将整理后的结果交给 Matplotlib 绘图展示。
这一流程体现的是一个完整的数据分析基本框架:
数据生成 → 表格构建 → 数据预处理 → 分组分析 → 可视化呈现
三、示例代码
python
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt
# 设置中文plt.rcParams["font.sans-serif"] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = False
# =====================================# 1. 生成模拟数据(NumPy)# 固定随机种子,保证每次运行结果一致,便于教学演示# =====================================np.random.seed(42)
n = 200 # 样本数量
# 生成年龄:18 到 59 岁之间的随机整数age = np.random.randint(18, 60, size=n)
# 生成收入:# 基础收入设为 3000,并让收入与年龄大致正相关# 再加入正态分布噪声,使数据更接近真实情况income = 3000 + 100 * age + np.random.normal(0, 2000, size=n)
# 人为加入少量异常值,便于演示异常值处理流程income[[5, 25, 80]] = [-2000, -1500, -3000]
# 生成学历类别:# 按给定概率从四类学历中随机抽样education = np.random.choice( ["高中及以下", "大专", "本科", "硕士及以上"], size=n, p=[0.2, 0.3, 0.4, 0.1])
# =====================================# 2. 创建 DataFrame(Pandas)# 将多个数组组织成结构化表格数据# =====================================df = pd.DataFrame({ "年龄": age, "收入": income, "学历": education})
# =====================================# 3. 数据预处理# 若收入出现负值,则将其替换为收入均值# 这里使用 loc[条件, 列名] 的形式进行条件定位与赋值# =====================================df.loc[df["收入"] < 0, "收入"] = df["收入"].mean()
# =====================================# 4. 分组统计# 按学历分组,对收入计算均值、标准差和样本数# =====================================edu_stats = df.groupby("学历")["收入"].agg(["mean", "std", "count"])
print("按学历分组的收入统计:")print(edu_stats)
# =====================================# 5. 数据可视化(Matplotlib)# 绘制两个子图:# (1)年龄与收入散点图# (2)不同学历平均收入柱状图# =====================================plt.figure(figsize=(12, 8))
# -------------------------# 子图1:年龄与收入散点图# 用不同颜色区分不同学历# -------------------------plt.subplot(2, 1, 1)
for edu, color in zip( ["高中及以下", "大专", "本科", "硕士及以上"], ["red", "blue", "green", "orange"]): subset = df[df["学历"] == edu] plt.scatter( subset["年龄"], subset["收入"], label=edu, color=color, alpha=0.6 )
plt.title("年龄与收入相关性分析", fontsize=14)plt.xlabel("年龄")plt.ylabel("收入(元)")plt.legend()plt.grid(True, alpha=0.3)
# -------------------------# 子图2:不同学历平均收入柱状图# 先用 Pandas 计算各学历平均收入,再绘图# -------------------------plt.subplot(2, 1, 2)
edu_means = df.groupby("学历")["收入"].mean().sort_values(ascending=False)
plt.bar( edu_means.index, edu_means.values)
plt.title("不同学历平均收入对比", fontsize=14)plt.xlabel("学历")plt.ylabel("平均收入(元)")plt.grid(axis="y", alpha=0.3)
plt.tight_layout()plt.show()四、结果解读
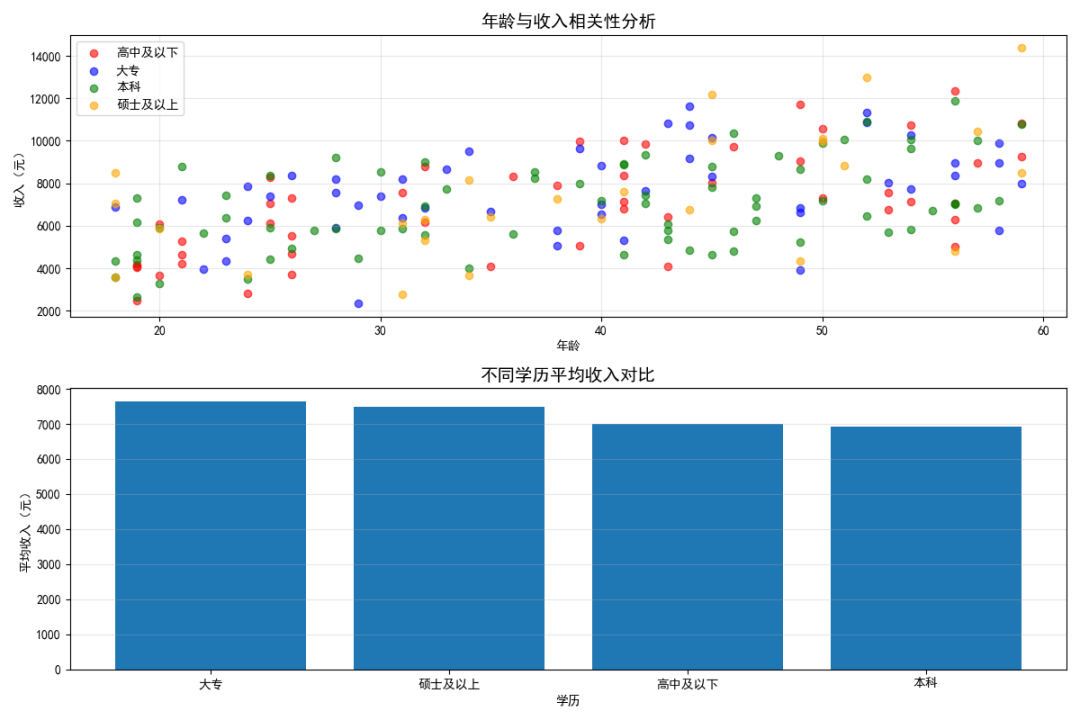
1、从表格统计结果看分组差异
按照学历分组后,可以得到每一类学历对应的收入均值、标准差和样本数量。这表明,不同学历组的平均收入存在一定差异,同时各组内部也有不同程度的波动。
这说明分组统计能够帮助我们从"整体数据"进一步看到"类别之间"的差别,而不仅仅停留在全体样本的平均水平上。
2、从散点图看年龄与收入关系
散点图展示了年龄与收入之间的大致关系。由于数据生成时已经设定收入与年龄正相关,因此图中整体会呈现出"年龄增大时,收入总体上升"的趋势。与此同时,噪声的加入又使点的分布不会过于整齐,从而更接近真实数据。
图中不同颜色对应不同学历类别,这使我们能够在观察年龄与收入关系的同时,进一步区分不同学历样本的大致分布情况。
3、从柱状图看不同学历的平均收入
柱状图将不同学历的平均收入直接进行对比,使组间差异更加直观。与纯文字表格相比,柱状图更适合快速观察"哪一组更高、哪一组更低",也更便于向非技术读者解释分析结果。
这里先对平均收入做了降序排列,因此柱状图更适合突出"大小规律"的比较。
4、从整体流程看 Pandas 的作用
本实例最重要的意义,不只是得到统计表和图形,更在于展示 Pandas 在整个流程中的核心作用:它把 NumPy 生成的数组组织成表格,又在此基础上完成异常值处理、分组统计,并为后续可视化提供结构清晰的数据结果。
也就是说,Pandas 是连接"数据生成"和"结果展示"的关键环节。
📘 小结
本实例展示了一个典型的多工具协同分析流程:先用 NumPy 生成模拟数据,再用 Pandas 构建表格、处理异常值并完成分组统计,最后用 Matplotlib 展示分析结果。其中,Pandas 起到了承上启下的作用,是连接原始数据、统计分析与可视化表达的核心工具。

"点赞有美意,赞赏是鼓励"