来源:程序员老廖
第1章 项目概览与运行配置
1.1 项目背景与定位
为什么需要这个项目?
voice_ai_chat 是一个端到端语音对话系统,它将两大核心能力串联:
| 模块 | 技术 | 运行位置 | 职责 |
|---|---|---|---|
| ASR (语音识别) | Whisper.cpp | 本地运行 | 麦克风采集 → 实时转文本 |
| LLM (大语言模型) | Kimi API | 云端调用 | 文本 → 流式生成回复 |
核心价值:
-
隐私优先:语音数据本地处理,不上传云端
-
低延迟:本地 ASR 避免网络传输延迟
-
低成本:Whisper 本地免费运行,只消耗 LLM API 费用
典型应用场景
-
语音助手/智能客服原型
-
实时会议记录与 AI 摘要
-
无障碍辅助工具开发
-
本地隐私敏感的语音交互应用
1.2 项目结构一览
ai-sdk-cpp-laoliao/applications/voice_ai_chat/
├── main.cpp # 程序入口:参数解析、初始化、主循环
├── voice_ai_chat.h # 核心类定义与配置结构
├── voice_ai_chat.cpp # 核心实现:LLM 工作线程、队列管理
├── CMakeLists.txt # 编译配置
└── README.md # 项目文档依赖关系:
main.cpp
├── voice_ai_chat.h/cpp (AI 对话层)
├── realtime_coordinator.h (ASR 协调层)
├── audio_capture.h (音频采集)
├── endpoint_detector.h (VAD 端点检测)
└── asr_worker.h (Whisper 识别工作线程)项目源码领取:全网首发!C++实现Whisper+Kimi端到端AI智能语音助手
1.3 编译与运行
编译步骤
# 1. 确保依赖已安装
sudo apt-get install -y libsdl2-dev pkg-config # Ubuntu/Debian
# 或
brew install sdl2 pkg-config # macOS
# 2. 进入项目目录
cd ai-sdk-cpp-laoliao
# 3. 创建构建目录
mkdir -p build && cd build
# 4. 编译
cmake ..
make -j$(nproc) voice_ai_chat运行前的必要配置
必须设置环境变量:
export MOONSHOT_API_KEY="your-moonshot-api-key-here"获取方式:访问 Moonshot AI 开放平台 注册并创建 API Key。
可选环境变量:
export WHISPER_MODEL_PATH="/path/to/your/model.bin" # 指定模型路径
export VOICE_AI_LOG_LEVEL=debug # 设置日志级别1.4 运行参数详解
基础运行命令
# 方式1:纯文本模式(调试 LLM 链路)
./applications/bin/voice_ai_chat --stdin
# 方式2:语音模式(指定模型路径)
./applications/bin/voice_ai_chat ../../../models/ggml-small.bin
# 方式3:语音模式 + 完整参数
./applications/bin/voice_ai_chat \
../../../models/ggml-small.bin \
--mode balanced \
--vad-threshold 0.06 \
--threads 8参数分类速查表
A. 模式选择参数
| 参数 | 说明 | 可选值 | 默认值 |
|---|---|---|---|
| --stdin | 文本输入模式(不走语音) | - | 关闭 |
| --mode | ASR 速度/质量模式 | fast/balanced/quality | balanced |
B. 模型与路径参数
| 参数 | 说明 | 示例 |
|---|---|---|
| model_path | Whisper 模型文件路径(位置参数) | ../../../models/ggml-small.bin |
| --ai-model | 大模型名称 | kimi-k2.5, kimi-k1.5 |
C. VAD (语音检测) 参数
| 参数 | 说明 | 建议范围 | 默认值 |
|---|---|---|---|
| --vad-threshold | 语音检测阈值(越小越灵敏) | 0.03 ~ 0.15 | 0.06 |
| --poll-interval-ms | VAD 检测间隔(毫秒) | 100 ~ 500 | 250 |
| --max-segment-ms | 单次送识别最大音频长度 | 1000 ~ 5000 | 2200 |
D. 性能参数
| 参数 | 说明 | 建议范围 | 默认值 |
|---|---|---|---|
| --threads | ASR 推理线程数 | 4 ~ 16 | 8 |
| --llm-queue-size | LLM 请求队列长度 | 4 ~ 16 | 8 |
E. 文本优化参数
| 参数 | 说明 | 示例 |
|---|---|---|
| --prompt-file | 加载自定义提示词文件 | --prompt-file ../prompts/tech.txt |
| --hotwords-file | 加载热词列表 | --hotwords-file ../hotwords/tech.txt |
| --lexicon-file | 加载词库纠错 | --lexicon-file ../lexicons/common.txt |
| --replacements-file | 加载术语替换规则 | --replacements-file ../replacements/tech.txt |
F. Partial 预览参数(建议关闭)
| 参数 | 说明 | 建议范围 | 默认值 |
|---|---|---|---|
| --enable-partial | 开启说话过程中的临时预览 | - | 关闭 |
| --partial-interval-ms | partial 刷新周期 | 400 ~ 700 | 700 |
| --partial-min-segment-ms | partial 最短音频 | 500 ~ 800 | 900 |
| --partial-max-segment-ms | partial 最长音频 | 1200 ~ 2200 | 1600 |
G. 设备与日志参数
| 参数 | 说明 |
|---|---|
| --list-input-devices | 列出可用输入设备并退出 |
| --input-device | 指定输入设备(名称或索引) |
| --log-level | 日志级别:debug/info/warn/error |
1.5 模型选择与推理速度
Whisper 模型对比
Whisper.cpp 支持多种模型,模型越大准确率越高,但速度越慢。
| 模型 | 参数量 | 文件大小 | 实时因子 (RTF) | 适用场景 | 推荐指数 |
|---|---|---|---|---|---|
| tiny | 39M | ~75MB | ~0.1x | 极简设备、高实时要求 | ⭐⭐⭐ |
| base | 74M | ~142MB | ~0.3x | 平衡选择、移动端 | ⭐⭐⭐⭐ |
| small | 244M | ~466MB | ~1.0x | 推荐默认、PC端实时 | ⭐⭐⭐⭐⭐ |
| medium | 769M | ~1.5GB | ~3-5x | 质量优先、短句 | ⭐⭐⭐⭐ |
| large-v3 | 1.5B | ~2.9GB | ~8-15x | 非实时、高质量需求 | ⭐⭐ |
RTF (Real-Time Factor): 处理1秒音频需要的实际秒数。RTF < 1 才能实时。
硬件配置建议
CPU 要求
| 模型 | 最低 CPU | 推荐 CPU | 内存需求 |
|---|---|---|---|
| tiny | 2核 | 4核 | 2GB |
| base | 2核 | 4核 | 4GB |
| small | 4核 | 8核+ | 6GB |
| medium | 8核 | 16核+ | 12GB |
| large-v3 | 16核 | 32核+ | 16GB |
模式选择指南
根据你的 CPU 性能和实时性要求选择 --mode:
# 场景1:强实时、短句命令(如语音输入框)
--mode fast --threads 8 --max-segment-ms 1600
# 特点:延迟最低,准确率略低
# 场景2:普通对话、平衡选择(推荐)
--mode balanced --threads 8 --max-segment-ms 2200
# 特点:速度与质量兼顾
# 场景3:长句、质量优先(会议记录)
--mode quality --threads 8 --max-segment-ms 2600
# 特点:准确率最高,延迟较大模式内部参数详解
| 模式 | max_len | max_tokens | audio_ctx | beam/best_of | 适用 |
|---|---|---|---|---|---|
| fast | 32/40 | 24/32 | 256/384 | best_of=1 | 实时命令 |
| balanced | 32/72 | 24/0 | 256/512 | best_of=2 | 日常对话 |
| quality | 32/96 | 24/0 | 256/640 | beam=4 | 精确转录 |
格式说明:partial参数/final参数。max_tokens=0 表示不限制。
1.6 推荐配置组合
配置 A:极速实时(短句命令)
./voice_ai_chat ../../../models/ggml-small.bin \
--mode fast \
--vad-threshold 0.05 \
--poll-interval-ms 200 \
--threads 8 \
--max-segment-ms 1600适用:语音输入框、快速命令、即时响应场景
配置 B:平衡模式(推荐日常使用)
./voice_ai_chat ../../../models/ggml-small.bin \
--mode balanced \
--vad-threshold 0.06 \
--poll-interval-ms 250 \
--threads 8 \
--max-segment-ms 2200 \
--prompt-file ../prompts/general.txt \
--lexicon-file ../lexicons/common.txt适用:日常对话、办公场景
配置 C:质量优先(会议记录)
./voice_ai_chat ../../../models/ggml-medium.bin \
--mode quality \
--vad-threshold 0.06 \
--poll-interval-ms 300 \
--threads 8 \
--max-segment-ms 2600 \
--prompt-file ../prompts/general.txt \
--replacements-file ../replacements/tech.txt适用:会议记录、访谈转录、质量优先场景
配置 D:低资源设备
./voice_ai_chat ../../../models/ggml-base.bin \
--mode fast \
--vad-threshold 0.08 \
--poll-interval-ms 300 \
--threads 4 \
--max-segment-ms 1800适用:嵌入式设备、旧电脑、树莓派等
1.7 常见问题诊断
Q1: 说话但没有文本输出?
排查步骤:
-
检查日志级别:--log-level debug
-
确认 VAD 是否检测到语音:看 VAD-DEBUG 日志
-
检查音频设备:--list-input-devices 确认使用正确设备
-
调整 VAD 阈值:--vad-threshold 0.05(更灵敏)
Q2: 推理速度太慢?
优化建议(按优先级):
-
换小模型:large → medium → small → base
-
用 fast 模式:--mode fast
-
缩短片段:--max-segment-ms 1600
-
增加线程:--threads 8(不超过物理核心数)
-
检查 CPU:是否在运行其他占用 CPU 的程序?
Q3: 出现很多繁体字?
解决方案:
-
使用 --prompt-file 加载简体提示词
-
使用 --lexicon-file 加载词库纠错
-
后续可考虑集成 OpenCC 进行繁转简
Q4: 输出中出现"常见术语包括"等 prompt 内容?
这是 prompt 泄漏,说明提示词太长。解决方法:
-
改用短提示词:../prompts/general.txt
-
停用 --hotwords-file,改用 --replacements-file
第2章 架构设计与数据流
2.1 整体架构概览
四层架构设计
┌─────────────────────────────────────────────────────────────────────┐
│ Voice AI Chat │
│ (应用层 / 协调层) │
├─────────────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ ASR层 │───▶│ Final文本 │───▶│ LLM层 │ │
│ │ (本地Whisper)│ │ 队列 │ │ (云端Kimi) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ │
│ │ VAD层 │───▶│ 端点检测器 │ │
│ │ (语音检测) │ │ │ │
│ └─────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ │
│ │ 采集层 │ SDL2 + 环形缓冲区 │
│ │ (麦克风) │ │
│ └─────────────┘ │
└─────────────────────────────────────────────────────────────────────┘设计哲学:解耦与异步
为什么这样分层?
| 旧版问题 | 当前解决方案 |
|---|---|
| VAD、分段、ASR 都在主循环 | 各层独立,通过队列通信 |
| ASR 阻塞导致音频丢失 | ASR 在独立 Worker 线程 |
| 无法扩展 partial/final 双通道 | 回调机制便于扩展 |
| 难接入 LLM(网络阻塞) | 独立 LLM Worker 线程 |
2.2 数据流详解
阶段1:音频采集层
// AudioCapture 核心职责
class AudioCapture {
// 1. SDL2 初始化音频设备
// 2. 音频回调写入环形缓冲区
// 3. 提供 GetAudioRange() 供 VAD 读取
};关键设计:
-
Ring Buffer:避免内存分配,支持实时读取
-
绝对时间戳:每个采样都有全局时间,便于切片
阶段2:VAD 端点检测层
// EndpointDetector 核心职责
class EndpointDetector {
// 1. 定时从 AudioCapture 读取音频窗口
// 2. 调用 whisper_vad_segments() 检测语音概率
// 3. 判断语音开始/结束,生成 utterance 区间
};状态流转:
静音状态 ──(vad_prob > threshold)──▶ 说话中 ──(vad_prob < threshold 持续 N ms)──▶ 静音状态
│ │
▼ ▼
触发 "speech started" 触发 "speech ended"
生成 utterance阶段3:ASR 识别层
// AsrWorker 核心职责(独立线程)
class AsrWorker {
// 1. 从队列取出 utterance job
// 2. 调用 whisper_full_with_state() 识别
// 3. 输出识别结果(partial / final)
};背压控制:
utterance queue (有界队列)
┌──────────────────────────────────┐
│ [job1] [job2] [job3] ... │
└──────────────────────────────────┘
▲ ▼
EndpointDetector AsrWorker
(生产者) (消费者)队列满时的策略:丢弃最旧的 job,保证实时性
阶段4:LLM 对话层
// VoiceAIChat 核心职责(独立线程)
class VoiceAIChat {
// 1. 通过回调接收 final 文本
// 2. LLM Worker 线程消费文本队列
// 3. 流式调用 Kimi API
// 4. 管理对话历史
};数据流向:
ASR final output
│
▼
┌──────────────────┐
│ final_text_queue │ (双端队列,mutex 保护)
└──────────────────┘
│
▼
┌──────────────────┐
│ LLM Worker Loop │ (condition_variable 等待)
└──────────────────┘
│
▼
┌──────────────────┐
│ Kimi stream_text │ (HTTP SSE 流式)
└──────────────────┘
│
▼
控制台输出2.3 时序图
完整交互时序
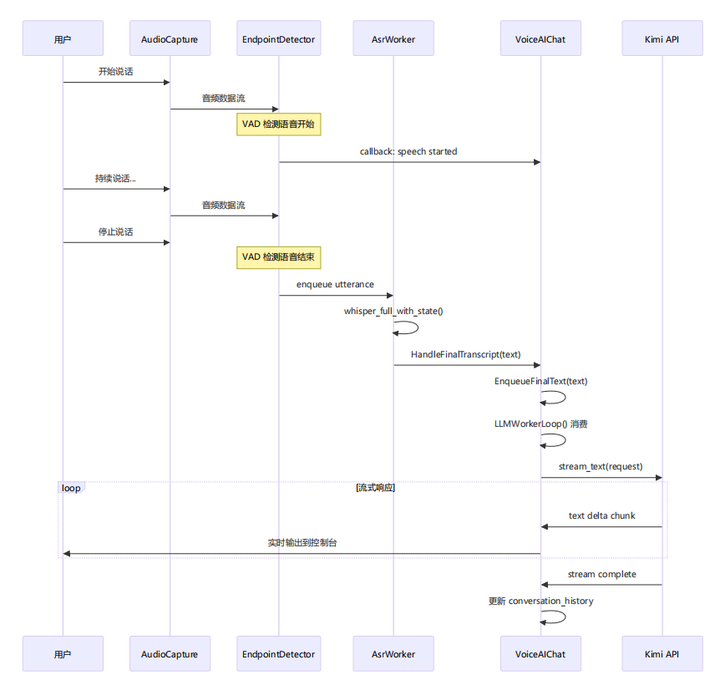
2.4 线程模型
线程分布图
主线程 (main)
├── AudioCapture 线程 (SDL2 音频回调线程)
├── AsrWorker 线程 (Whisper 推理)
├── LLM Worker 线程 (VoiceAIChat)
└── 主循环 (coordinator.Run())线程职责与同步
| 线程 | 职责 | 同步机制 |
|---|---|---|
| 主线程 | 初始化、信号处理、协调器主循环 | - |
| SDL 音频线程 | 采集音频写入 ring buffer | 无锁 ring buffer |
| AsrWorker | 消费 utterance 队列,执行识别 | std::deque + std::mutex |
| LLM Worker | 消费 final 文本队列,调用 API | std::deque + std::mutex + std::condition_variable |
关键同步代码
// LLM Worker 等待队列(voice_ai_chat.cpp)
void VoiceAIChat::LLMWorkerLoop() {
while (true) {
std::string user_text;
{
std::unique_lock<std::mutex> lock(queue_mutex_);
queue_cv_.wait(lock, [this]() {
return !running_.load() || !final_text_queue_.empty();
});
if (!running_.load() && final_text_queue_.empty()) {
return; // 退出信号
}
user_text = std::move(final_text_queue_.front());
final_text_queue_.pop_front();
} // 解锁
ProcessWithAI(user_text); // 处理请求
}
}
// 生产者入队
void VoiceAIChat::EnqueueFinalText(const std::string& text) {
{
std::lock_guard<std::mutex> lock(queue_mutex_);
if (final_text_queue_.size() >= config_.max_pending_final_texts) {
final_text_queue_.pop_front(); // 背压:丢弃最旧
}
final_text_queue_.push_back(text);
}
queue_cv_.notify_one(); // 通知消费者
}2.5 为什么 Partial 不进 LLM?
Partial vs Final
| 特性 | Partial | Final |
|---|---|---|
| 触发时机 | 说话过程中定期输出 | 一句话说完后输出 |
| 稳定性 | 频繁变化、可能回滚 | 稳定、确定 |
| 用途 | 屏幕预览给用户看 | 正式送 LLM 处理 |
如果把 Partial 送进 LLM 会怎样?
用户说话:"今天天气怎么样"
时间线:
T1: partial -> "今天天" ──┐
T2: partial -> "今天天气怎" ──┼── 都送进 LLM?
T3: partial -> "今天天气怎么样" ──┘
T4: final -> "今天天气怎么样"
问题:
1. 上下文污染:LLM 看到 3 次重复请求
2. Token 浪费:多次请求消耗 API 额度
3. 过早触发:话没说完就生成回复推荐策略
┌─────────────────────────────────────┐
│ ASR 层 (Realtime) │
│ ┌─────────┐ ┌─────────────┐ │
│ │ Partial │─────▶│ 屏幕显示 │ │ (不送 LLM)
│ └─────────┘ └─────────────┘ │
│ ┌─────────┐ ┌─────────────┐ │
│ │ Final │─────▶│ LLM Worker │ │ (正式处理)
│ └─────────┘ └─────────────┘ │
└─────────────────────────────────────┘2.6 扩展设计:未来方向
阶段 2 规划
当前架构 目标架构
────────── ──────────
┌────────┐ ┌────────┐
│ ASR │ │ ASR │
│ small │ │ tiny/ │──▶ Partial (预览)
└────┬───┘ │ small │
│ └────┬───┘
▼ │
┌────────┐ ▼
│ LLM │ ┌────────┐
│ (Kimi) │ │ LLM │
└────────┘ │ (Kimi) │
└────────┘
新增:
• 双模型策略 (tiny + small)
• TTS 回播
• Barge-in (打断检测) 可能的架构演进
// 未来可能的多级架构
class VoiceAIChat {
// 层1:ASR (本地)
// 层2:理解/意图 (本地轻量模型或规则)
// 层3:LLM (云端或本地大模型)
// 层4:TTS (本地或云端)
};2.7 本章小结
核心要点:
-
四层架构:采集 → VAD → ASR → LLM,各层解耦
-
异步设计:ASR 和 LLM 都有独立 Worker 线程
-
队列通信:生产者-消费者模式,有界队列背压
-
Partial 策略:仅用于预览,不进 LLM
关键代码路径:
-
数据流:AudioCapture → EndpointDetector → AsrWorker → VoiceAIChat → Kimi
-
同步点:std::mutex 保护队列,std::condition_variable 唤醒 Worker
思考题:
-
为什么要用双端队列 (std::deque) 而不是普通队列?
-
如果 LLM 响应很慢,如何设计才能不阻塞新的 ASR 结果?
-
如何实现 "Barge-in"(用户打断 AI 说话)功能?
第3章 核心模块源码解析
3.1 VoiceAIChat 类概览
类定义(voice_ai_chat.h)
namespace voice_ai {
struct VoiceAIConfig {
std::string moonshot_base_url = "https://api.moonshot.cn";
std::string ai_model = "kimi-k2.5";
std::string ai_system_prompt = "你是 Kimi,一个中文优先...";
std::string moonshot_api_key;
bool enable_streaming = true;
size_t max_pending_final_texts = 8;
realtime::LogLevel log_level = realtime::LogLevel::kInfo;
};
class VoiceAIChat {
public:
explicit VoiceAIChat(const VoiceAIConfig& config);
~VoiceAIChat();
// 禁止拷贝(资源管理语义)
VoiceAIChat(const VoiceAIChat&) = delete;
VoiceAIChat& operator=(const VoiceAIChat&) = delete;
// 生命周期
bool Init();
void Stop();
// 回调设置(用于外部集成)
void SetTranscriptionCallback(TranscriptionCallback callback);
void SetAIResponseCallback(AIResponseCallback callback);
// 输入接口
void SendTextMessage(const std::string& text); // 文本模式
void HandleFinalTranscript(const std::string& text); // ASR 回调
private:
// 内部实现...
};
} // namespace voice_ai设计模式分析
| 设计要点 | 实现方式 | 目的 |
|---|---|---|
| 配置集中 | VoiceAIConfig 结构体 | 参数统一管理 |
| 资源安全 | = delete 拷贝构造 | 防止资源重复释放 |
| 延迟初始化 | std::optional<ai::Client> | 延迟创建 API 客户端 |
| 回调机制 | std::function | 支持外部扩展 |
3.2 初始化流程
Init() 方法
bool VoiceAIChat::Init() {
if (!InitAIClient()) { // 步骤1:初始化 AI 客户端
return false;
}
StartLLMWorker(); // 步骤2:启动工作线程
return true;
}InitAIClient() 详解
bool VoiceAIChat::InitAIClient() {
// 设置日志(只显示警告和错误)
ai::logger::install_logger(
std::make_shared<ai::logger::ConsoleLogger>(
ai::logger::LogLevel::kLogLevelWarn));
// 获取 API Key(环境变量优先)
const auto api_key = config_.moonshot_api_key.empty()
? GetEnvOrDefault("MOONSHOT_API_KEY", "")
: config_.moonshot_api_key;
if (api_key.empty()) {
realtime::AppLogger::Instance().Error(
"MOONSHOT_API_KEY environment variable not set");
return false;
}
// 创建客户端(使用 std::optional 延迟初始化)
ai_client_.emplace(
ai::openai::create_client(api_key, config_.moonshot_base_url));
if (!ai_client_->is_valid()) {
realtime::AppLogger::Instance().Error("AI client init failed");
return false;
}
// 初始化对话历史(系统提示词)
conversation_history_ = {
ai::Message::system(config_.ai_system_prompt),
};
return true;
}关键点:
-
环境变量 MOONSHOT_API_KEY 必须设置
-
std::optional 实现延迟初始化,避免构造时出错
-
系统提示词在初始化时加入对话历史
3.3 LLM Worker 线程
线程生命周期
void VoiceAIChat::StartLLMWorker() {
bool expected = false;
// compare_exchange_strong: 原子 CAS 操作
// 确保只有一个线程能成功启动
if (!running_.compare_exchange_strong(expected, true)) {
return; // 已经在运行
}
llm_thread_ = std::thread(&VoiceAIChat::LLMWorkerLoop, this);
}
void VoiceAIChat::StopLLMWorker() {
const bool was_running = running_.exchange(false);
queue_cv_.notify_all(); // 唤醒所有等待的线程
if (was_running && llm_thread_.joinable()) {
llm_thread_.join(); // 等待线程结束
}
}Worker 主循环(生产者-消费者模式)
void VoiceAIChat::LLMWorkerLoop() {
while (true) {
std::string user_text;
size_t pending_after_pop = 0;
{
// 1. 获取锁
std::unique_lock<std::mutex> lock(queue_mutex_);
// 2. 条件等待(原子释放锁并等待)
queue_cv_.wait(lock, [this]() {
// 唤醒条件:停止信号 或 队列非空
return !running_.load() || !final_text_queue_.empty();
});
// 3. 检查退出条件
if (!running_.load() && final_text_queue_.empty()) {
return; // 优雅退出
}
// 4. 消费消息
user_text = std::move(final_text_queue_.front());
final_text_queue_.pop_front();
pending_after_pop = final_text_queue_.size();
} // 5. 自动解锁
// 6. 处理(在锁外执行,避免阻塞入队)
ai_processing_ = true;
ProcessWithAI(user_text);
ai_processing_ = false;
}
}入队方法(生产者)
void VoiceAIChat::EnqueueFinalText(const std::string& text) {
{
std::lock_guard<std::mutex> lock(queue_mutex_);
// 背压控制:队列满时丢弃最旧的消息
if (final_text_queue_.size() >= config_.max_pending_final_texts) {
realtime::AppLogger::Instance().Warn(
"final 文本队列已满,丢弃最旧的一条");
final_text_queue_.pop_front();
}
final_text_queue_.push_back(text);
} // 锁释放
queue_cv_.notify_one(); // 通知一个等待的消费者
}为什么用 notify_one 而不是 notify_all?
-
只有一个 LLM Worker 线程
-
notify_one 更高效(只唤醒一个线程)
3.4 调用 Kimi API
ProcessWithAI() 主流程
void VoiceAIChat::ProcessWithAI(const std::string& user_text) {
// 1. 检查客户端状态
if (!ai_client_.has_value()) {
return;
}
// 2. 添加到对话历史(User 消息)
{
std::lock_guard<std::mutex> lock(mutex_);
conversation_history_.push_back(ai::Message::user(user_text));
}
// 3. 准备请求参数
ai::GenerateOptions generate_options;
{
std::lock_guard<std::mutex> lock(mutex_);
generate_options.model = config_.ai_model;
generate_options.messages = conversation_history_;
}
// 4. 打印 AI 前缀(带颜色)
{
std::lock_guard<std::mutex> lock(output_mutex_);
std::cout << kAnsiAssistantColor << "Kimi> " << std::flush;
}
// 5. 流式调用
if (config_.enable_streaming) {
ProcessStreaming(generate_options);
} else {
ProcessNonStreaming(generate_options);
}
}流式处理详解
void VoiceAIChat::ProcessStreaming(ai::GenerateOptions& options) {
ai::StreamOptions stream_options(std::move(options));
auto stream = ai_client_->stream_text(stream_options);
std::string assistant_reply;
bool stream_failed = false;
for (const auto& event : stream) {
if (event.is_text_delta()) {
// 收到文本片段
assistant_reply += event.text_delta;
// 外部回调
if (ai_response_callback_) {
ai_response_callback_(event.text_delta, true);
}
// 实时输出
std::lock_guard<std::mutex> lock(output_mutex_);
std::cout << event.text_delta << std::flush;
} else if (event.is_error()) {
// 流错误处理
stream_failed = true;
realtime::AppLogger::Instance().Error(
"Kimi stream error: " + event.error.value_or("unknown"));
break;
}
}
// 完成处理
std::lock_guard<std::mutex> lock(mutex_);
if (stream_failed || assistant_reply.empty()) {
// 失败时回退 User 消息(对话不保存)
conversation_history_.pop_back();
} else {
// 成功,添加 Assistant 回复到历史
conversation_history_.push_back(
ai::Message::assistant(assistant_reply));
}
}流式响应的优势:
-
用户体验好:边生成边显示
-
感知延迟低:不需要等全部生成完
-
与 ChatGPT 等产品体验一致
3.5 主程序入口
main() 函数结构(main.cpp)
int main(int argc, char** argv) {
try {
// 1. 配置解析
voice_ai::VoiceAIConfig config;
realtime::RuntimeOptions realtime_options;
ParseArguments(argc, argv, config, realtime_options);
// 2. 环境变量覆盖
ApplyEnvironmentVariables(config, realtime_options);
// 3. 加载外部文件(提示词、词库等)
LoadExternalFiles(realtime_options);
// 4. 初始化日志
realtime::AppLogger::Instance().SetLevel(config.log_level);
// 5. 列出设备(如果指定)
if (realtime_options.list_input_devices) {
return realtime::AudioCapture::ListInputDevices() ? 0 : 1;
}
// 6. 创建应用实例
voice_ai::VoiceAIChat app(config);
// 7. 信号处理(Ctrl+C 优雅退出)
std::signal(SIGINT, HandleSignal);
if (!app.Init()) {
return 1;
}
// 8. 模式选择:文本模式 或 语音模式
if (stdin_mode) {
RunStdinMode(app);
} else {
RunVoiceMode(app, realtime_options);
}
} catch (const std::exception& e) {
std::cerr << "Exception: " << e.what() << "\n";
return 1;
}
}语音模式初始化
void RunVoiceMode(voice_ai::VoiceAIChat& app,
const realtime::RuntimeOptions& options) {
// 1. 创建协调器
realtime::RealtimeCoordinator coordinator(options);
// 2. 设置 ASR final 回调(核心集成点)
coordinator.SetFinalTextCallback(
[&app](const std::string& text) {
app.HandleFinalTranscript(text);
});
// 3. 初始化并运行
if (!coordinator.Init()) {
std::cerr << "[MAIN] realtime coordinator init failed\n";
return 1;
}
coordinator.Run(); // 阻塞直到停止
}核心集成点:SetFinalTextCallback 将 ASR 层和 LLM 层连接起来。
3.6 参数解析详解
命令行解析逻辑
for (int i = 1; i < argc; ++i) {
const std::string arg = argv[i];
if (arg == "--stdin") {
stdin_mode = true;
}
else if (arg == "--ai-model" && i + 1 < argc) {
config.ai_model = argv[++i]; // 后置递增,先取值再移动
}
else if (arg == "--llm-queue-size" && i + 1 < argc) {
config.max_pending_final_texts =
static_cast<size_t>(std::stoul(argv[++i]));
}
// ... 更多参数
else if (!arg.empty() && arg[0] != '-') {
cli_model_path = arg; // 位置参数:模型路径
}
}环境变量优先级
// 环境变量优先级高于命令行
if (const char* env = std::getenv("WHISPER_MODEL_PATH");
env != nullptr && !std::string(env).empty()) {
realtime_options.model_path = env;
} else if (!cli_model_path.empty()) {
realtime_options.model_path = cli_model_path;
}
// 日志级别
if (const char* env = std::getenv("VOICE_AI_LOG_LEVEL"); env != nullptr) {
config.log_level = realtime::AppLogger::ParseLevel(env);
}优先级规则:
-
环境变量(最高优先级)
-
命令行参数
-
默认值
3.7 信号处理与优雅退出
全局指针(用于信号处理)
namespace {
voice_ai::VoiceAIChat* g_app = nullptr;
realtime::RealtimeCoordinator* g_coordinator = nullptr;
}信号处理器
void HandleSignal(int sig) {
if (sig == SIGINT) { // Ctrl+C
std::cout << "\n[MAIN] stopping...\n";
// 按依赖顺序停止
if (g_coordinator != nullptr) {
g_coordinator->Stop(); // 先停采集和 ASR
}
if (g_app != nullptr) {
g_app->Stop(); // 再停 LLM(完成正在进行的请求)
}
}
}注册信号处理
int main(...) {
// ...
voice_ai::VoiceAIChat app(config);
g_app = &app;
std::signal(SIGINT, HandleSignal); // 注册处理器
// ...
}为什么先停 Coordinator 再停 VoiceAIChat?
-
Coordinator 停止后不再产生新的 final 文本
-
VoiceAIChat 可以继续处理队列中的剩余请求
-
避免请求丢失
第4章 关键技术点剖析
4.1 线程安全设计
多线程访问的共享资源
class VoiceAIChat {
// 需要同步保护的成员
std::deque<std::string> final_text_queue_; // LLM 队列
ai::Messages conversation_history_; // 对话历史
std::optional<ai::Client> ai_client_; // API 客户端
// 同步原语
std::mutex mutex_; // 保护 conversation_history_
std::mutex queue_mutex_; // 保护 final_text_queue_
std::mutex output_mutex_; // 保护控制台输出顺序
std::condition_variable queue_cv_; // 队列非空通知
};锁粒度设计
细粒度锁策略:
// Good: 不同资源用不同锁
std::mutex queue_mutex_; // 只保护队列
std::mutex history_mutex_; // 只保护对话历史
std::mutex output_mutex_; // 只保护输出
// Bad: 一把大锁保护所有
std::mutex big_lock_; // 避免!会造成不必要的阻塞代码示例:
void VoiceAIChat::ProcessWithAI(const std::string& user_text) {
// 操作1:修改对话历史(需要锁)
{
std::lock_guard<std::mutex> lock(mutex_);
conversation_history_.push_back(ai::Message::user(user_text));
} // 锁立即释放
// 操作2:准备请求参数(不需要锁,因为 conversation_history_ 已复制)
ai::GenerateOptions generate_options;
{
std::lock_guard<std::mutex> lock(mutex_);
generate_options.messages = conversation_history_;
} // 锁立即释放
// 操作3:网络请求(不需要锁,避免阻塞其他线程)
auto stream = ai_client_->stream_text(stream_options);
// 操作4:输出响应(需要 output_mutex_ 保证输出顺序)
for (const auto& event : stream) {
std::lock_guard<std::mutex> lock(output_mutex_);
std::cout << event.text_delta << std::flush;
}
}死锁避免
原则:
-
锁顺序一致:多个锁时,始终以相同顺序获取
-
避免锁嵌套:尽量使用独立锁,减少嵌套
-
使用 std::lock_guard:RAII 自动释放,避免忘记解锁
// 安全的嵌套锁(如果需要)
void SomeFunction() {
std::lock_guardstd::mutex lock_a(mutex_a_);
{
std::lock_guardstd::mutex lock_b(mutex_b_);
// 操作
} // lock_b 先释放
} // lock_a 后释放// 危险:不同函数锁顺序不一致会导致死锁
void FunctionA() {
std::lock_guardstd::mutex a(mutex_a_);
std::lock_guardstd::mutex b(mutex_b_); // 顺序:a -> b
}void FunctionB() {
std::lock_guardstd::mutex b(mutex_b_); // 顺序:b -> a ❌
std::lock_guardstd::mutex a(mutex_a_);
}
4.2 背压控制 (Backpressure)
问题场景
用户快速说话 ASR 识别 LLM 处理
│ │ │
▼ ▼ ▼
句子1 ──────────▶ 文本1 ────────▶ 请求1 (慢)
句子2 ──────────▶ 文本2 ──────▶ 请求2 (等待中)
句子3 ──────────▶ 文本3 ──▶ 请求3 (堆积...)
句子4 ──────────▶ 文本4
...
问题:LLM 处理慢,队列无限增长 → 内存溢出、延迟累积解决方案:有界队列 + 丢弃策略
void VoiceAIChat::EnqueueFinalText(const std::string& text) {
std::lock_guard<std::mutex> lock(queue_mutex_);
// 背压控制:队列满时丢弃最旧的消息
if (final_text_queue_.size() >= config_.max_pending_final_texts) {
realtime::AppLogger::Instance().Warn(
"final 文本队列已满,丢弃最旧的一条");
final_text_queue_.pop_front(); // 丢弃最旧
}
final_text_queue_.push_back(text); // 加入最新
}背压策略对比
| 策略 | 实现 | 适用场景 |
|---|---|---|
| 丢弃最旧 | pop_front() + push_back() | 实时性优先(本项目使用) |
| 丢弃最新 | 拒绝入队 | 完整性优先 |
| 阻塞入队 | 队列满时阻塞生产者 | 吞吐优先 |
| 动态扩容 | 队列自动增长 | 内存充足场景 |
为什么选"丢弃最旧"?
-
语音对话场景:用户更关心最新说的话
-
旧消息可能已经"过时"(上下文已变)
-
避免延迟累积,保证实时响应
4.3 回调机制设计
回调类型定义
// ASR 结果回调
using TranscriptionCallback =
std::function<void(const std::string& text, bool is_final)>;
// AI 响应回调
using AIResponseCallback =
std::function<void(const std::string& text, bool is_streaming_chunk)>;回调注册与调用
class VoiceAIChat {
public:
// 设置回调(支持外部扩展)
void SetTranscriptionCallback(TranscriptionCallback callback) {
transcription_callback_ = std::move(callback);
}
void SetAIResponseCallback(AIResponseCallback callback) {
ai_response_callback_ = std::move(callback);
}
private:
void HandleTranscription(const std::string& text, bool is_final) {
// 调用外部注册的回调
if (transcription_callback_) {
transcription_callback_(text, is_final);
}
}
TranscriptionCallback transcription_callback_;
AIResponseCallback ai_response_callback_;
};使用示例
// 主程序中注册回调
voice_ai::VoiceAIChat app(config);
// 回调1:收到 ASR 结果时打印日志
app.SetTranscriptionCallback(
[](const std::string& text, bool is_final) {
if (is_final) {
LOG_INFO << "Final transcription: " << text;
}
});
// 回调2:收到 AI 响应时发送到 WebSocket
app.SetAIResponseCallback(
[&websocket](const std::string& chunk, bool is_streaming) {
websocket.Send(chunk); // 实时推送到前端
});Lambda 捕获注意事项
// 危险:捕获局部变量的引用
void Dangerous() {
voice_ai::VoiceAIChat app(config);
std::string prefix = "User: ";
app.SetTranscriptionCallback(
[&prefix](const std::string& text, bool) { // ❌ 引用捕获
std::cout << prefix << text << "\n"; // Dangerous 返回后 prefix 失效
});
} // prefix 被销毁,回调变成悬空引用
// 安全:值捕获 或 捕获指针
void Safe() {
auto app = std::make_shared<voice_ai::VoiceAIChat>(config);
std::string prefix = "User: ";
app->SetTranscriptionCallback(
[prefix, app](const std::string& text, bool) { // ✅ 值捕获
std::cout << prefix << text << "\n"; // 安全,有独立的拷贝
});
}4.4 条件变量使用模式
生产者-消费者完整模式
template<typename T>
class BoundedQueue {
public:
explicit BoundedQueue(size_t capacity) : capacity_(capacity) {}
// 生产者
void Push(T item) {
std::unique_lock<std::mutex> lock(mutex_);
// 等待队列有空位
not_full_.wait(lock, [this] {
return queue_.size() < capacity_;
});
queue_.push_back(std::move(item));
not_empty_.notify_one(); // 通知消费者
}
// 消费者
T Pop() {
std::unique_lock<std::mutex> lock(mutex_);
// 等待队列有数据
not_empty_.wait(lock, [this] {
return !queue_.empty();
});
T item = std::move(queue_.front());
queue_.pop_front();
not_full_.notify_one(); // 通知生产者
return item;
}
private:
std::deque<T> queue_;
size_t capacity_;
std::mutex mutex_;
std::condition_variable not_empty_;
std::condition_variable not_full_;
};本项目中的变体(无界队列 + 丢弃)
void VoiceAIChat::LLMWorkerLoop() {
while (true) {
std::string user_text;
{
std::unique_lock<std::mutex> lock(queue_mutex_);
// 条件等待:停止信号 或 队列非空
queue_cv_.wait(lock, [this] {
return !running_.load() || !final_text_queue_.empty();
});
// 检查退出条件
if (!running_.load() && final_text_queue_.empty()) {
return; // 优雅退出
}
// 消费
user_text = std::move(final_text_queue_.front());
final_text_queue_.pop_front();
} // 解锁
ProcessWithAI(user_text); // 处理(在锁外)
}
}关键点:
-
wait() 会自动释放锁并阻塞,被唤醒时重新获取锁
-
使用 lambda 谓词防止虚假唤醒 (spurious wakeup)
-
处理逻辑在锁外执行,减少临界区
4.5 流式 HTTP 处理
SSE (Server-Sent Events) 基础
HTTP 请求
│
▼
POST /v1/chat/completions
Headers:
Authorization: Bearer {api_key}
Accept: text/event-stream ← 关键:请求流式响应
响应(流式):
data: {"choices":[{"delta":{"content":"Hello"}}]}
data: {"choices":[{"delta":{"content":" world"}}]}
data: {"choices":[{"delta":{"content":"!"}}]}
data: [DONE]流式处理代码
void VoiceAIChat::ProcessStreaming(ai::GenerateOptions& options) {
// 1. 创建流式选项
ai::StreamOptions stream_options(std::move(options));
// 2. 发起流式请求
auto stream = ai_client_->stream_text(stream_options);
// 3. 逐块处理
for (const auto& event : stream) {
if (event.is_text_delta()) {
// 收到文本片段
const std::string& chunk = event.text_delta;
// 实时输出
std::cout << chunk << std::flush;
// 累加完整回复
assistant_reply += chunk;
} else if (event.is_error()) {
// 错误处理
HandleError(event.error);
stream_failed = true;
break;
}
}
// 4. 流结束,更新对话历史
if (!stream_failed) {
conversation_history_.push_back(
ai::Message::assistant(assistant_reply));
}
}流式 vs 非流式对比
| 特性 | 流式 (streaming) | 非流式 (blocking) |
|---|---|---|
| 首字延迟 | 低(毫秒级) | 高(等待全部生成) |
| 用户体验 | 边生成边看 | 等待后一次性显示 |
| 实现复杂度 | 高(需处理分片) | 低(一次请求响应) |
| 取消支持 | 可中断 | 需等待完成 |
| 适用场景 | 对话、长文本 | 短文本、简单查询 |
4.6 配置加载优先级
三级配置体系
┌─────────────────────────────────────────┐
│ Level 1: 代码硬编码默认值 │
│ (最低优先级) │
├─────────────────────────────────────────┤
│ Level 2: 命令行参数 │
│ (./voice_ai_chat --mode fast ...) │
├─────────────────────────────────────────┤
│ Level 3: 环境变量 │
│ (export WHISPER_MODEL_PATH=...) │
│ (最高优先级) │
└─────────────────────────────────────────┘实现代码
// 优先级:环境变量 > 命令行 > 默认值
std::string GetModelPath(const std::string& cli_path) {
// 1. 检查环境变量(最高优先级)
if (const char* env = std::getenv("WHISPER_MODEL_PATH")) {
if (!std::string(env).empty()) {
return env;
}
}
// 2. 使用命令行参数
if (!cli_path.empty()) {
return cli_path;
}
// 3. 使用默认值
return "../../../models/ggml-small.bin";
}
// 应用示例
realtime_options.model_path = GetModelPath(cli_model_path);为什么要这样设计?
| 配置来源 | 适用场景 | 优势 |
|---|---|---|
| 环境变量 | 敏感信息(API Key)、全局默认 | 不暴露在命令行历史,便于容器化部署 |
| 命令行 | 临时调整、脚本调用 | 灵活、可见、易于文档化 |
| 默认值 | 快速开始、示例 | 零配置启动 |
4.7 日志系统设计
日志级别
enum class LogLevel {
kDebug, // 详细调试信息(开发用)
kInfo, // 一般信息(运行状态)
kWarn, // 警告(需要注意但非致命)
kError // 错误(功能受影响)
};日志使用示例
// 不同级别的日志
AppLogger::Instance().Debug("queue size=" + std::to_string(size));
AppLogger::Instance().Info("AI client initialized");
AppLogger::Instance().Warn("队列已满,丢弃旧消息");
AppLogger::Instance().Error("API request failed: " + error);运行时调整日志级别
# 方式1:命令行
./voice_ai_chat --log-level debug
# 方式2:环境变量
export VOICE_AI_LOG_LEVEL=debug
./voice_ai_chat生产环境建议
| 环境 | 推荐级别 | 原因 |
|---|---|---|
| 开发调试 | debug | 查看详细数据流 |
| 测试环境 | info | 关注运行状态 |
| 生产环境 | warn | 减少日志量,只关注问题 |
第5章 实验演示
5.1 环境准备
检查清单
| 项目 | 检查命令 | 预期结果 |
|---|---|---|
| API Key | echo $MOONSHOT_API_KEY | 显示有效 key |
| 编译产物 | ls build/applications/bin/voice_ai_chat | 文件存在 |
| 模型文件 | ls models/ggml-small.bin | 文件存在 |
| 音频设备 | arecord -l 或 ./voice_ai_chat --list-input-devices | 显示设备列表 |
快速编译脚本
#!/bin/bash
# build.sh - 一键编译脚本
cd ai-sdk-cpp-laoliao
mkdir -p build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j$(nproc) voice_ai_chat
echo "编译完成,二进制位置:"
echo " ./applications/bin/voice_ai_chat"5.2 实验1:文本模式验证 LLM 链路
目的
在不涉及语音的情况下,先验证 AI 对话功能正常。
步骤
# 1. 设置 API Key
export MOONSHOT_API_KEY="your-api-key"
# 2. 启动文本模式
./applications/bin/voice_ai_chat --stdin
# 3. 输入测试
=== Voice AI Chat (stdin mode) ===
输入文本后回车,输入 /exit 退出。
你好,请介绍一下你自己
Kimi> 你好!我是 Kimi,一个 AI 助手...
今天的天气怎么样?
Kimi> 我无法获取实时天气信息...
/exit预期输出
你(ASR)> 你好,请介绍一下你自己
Kimi> 你好!我是 Kimi,一个 AI 助手。我可以帮助你解答问题、写作...
你(ASR)> 今天的天气怎么样?
Kimi> 我无法获取实时天气信息...故障排查
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| MOONSHOT_API_KEY not set | 环境变量未设置 | export MOONSHOT_API_KEY=xxx |
| AI client init failed | API Key 无效 | 检查 Key 是否正确 |
| 连接超时 | 网络问题 | 检查网络,或尝试 ping api.moonshot.cn |
| 返回乱码 | 终端编码 | export LANG=en_US.UTF-8 |
5.3 实验2:基础语音模式
目的
验证完整的语音输入 → ASR → LLM 流程。
步骤
# 1. 列出设备(确认麦克风可用)
./applications/bin/voice_ai_chat --list-input-devices
# 预期输出:
# Input Device 0: HDA Intel PCH: ALC257 Analog (hw:0,0)
# Input Device 1: USB Audio Device: USB Audio (hw:1,0)
# 2. 基础语音模式(使用默认配置)
./applications/bin/voice_ai_chat \
../../../models/ggml-small.bin
# 3. 说话测试(建议中文短句)
# 示例:"你好"、"今天星期几"、"讲个笑话"观察要点
-
VAD 检测:看到 ENDPOINT speech started 表示检测到语音开始
-
识别输出:看到 TEXT #1 xxx 表示 ASR 成功
-
LLM 响应:看到 Kimi> xxx 表示 AI 正在回复
预期完整输出
[VAD-DEBUG] max_prob=0.821, segments=1, speech=yes
[ENDPOINT] speech started
...
[ENDPOINT] speech ended
[QUEUE] enqueue utterance #1 start_ms=... end_ms=...
[ASR-WORKER] processing utterance #1 samples=...
[TEXT] #1 你好
你(ASR)> 你好
Kimi> 你好!很高兴见到你...5.4 实验3:模型速度对比
目的
对比不同模型的推理速度,选择合适的模型。
测试脚本
#!/bin/bash
# benchmark.sh - 模型速度对比
MODELS=("tiny" "base" "small")
TEST_AUDIO="test.wav" # 准备一段 5 秒测试音频
echo "=== 模型速度对比测试 ==="
for model in "${MODELS[@]}"; do
echo ""
echo "测试模型: $model"
echo "模型大小: $(ls -lh models/ggml-$model.bin | awk '{print $5}')"
# 使用 time 统计时间
time ./applications/bin/voice_ai_chat \
models/ggml-$model.bin \
--mode fast \
--threads 8 \
2>&1 | grep -E "(real|user|sys|RTF)"
done预期结果参考
| 模型 | 大小 | 理论 RTF | 实测延迟 |
|---|---|---|---|
| tiny | 75MB | ~0.1x | 0.3-0.5s |
| base | 142MB | ~0.3x | 0.8-1.2s |
| small | 466MB | ~1.0x | 1.5-2.5s |
| medium | 1.5GB | ~3-5x | 4-8s |
选择建议
# 低配设备(4核以下)
./voice_ai_chat models/ggml-base.bin --mode fast --threads 4
# 标准配置(8核,推荐)
./voice_ai_chat models/ggml-small.bin --mode balanced --threads 8
# 高配设备(追求质量)
./voice_ai_chat models/ggml-medium.bin --mode quality --threads 165.5 实验4:VAD 参数调优
目的
找到适合你麦克风和环境的 VAD 参数。
测试命令
# 测试1:高灵敏度(适合安静环境、远场语音)
./applications/bin/voice_ai_chat \
../../../models/ggml-small.bin \
--mode fast \
--vad-threshold 0.03 \
--poll-interval-ms 150
# 测试2:默认灵敏度
default: --vad-threshold 0.06 --poll-interval-ms 250
# 测试3:低灵敏度(适合嘈杂环境、近场语音)
./applications/bin/voice_ai_chat \
../../../models/ggml-small.bin \
--mode fast \
--vad-threshold 0.12 \
--poll-interval-ms 300调优指南
| 场景 | VAD 阈值 | 轮询间隔 | 原因 |
|---|---|---|---|
| 安静办公室 | 0.03-0.05 | 150-200ms | 灵敏检测,快速响应 |
| 普通家庭 | 0.06-0.08 | 250ms | 默认平衡 |
| 嘈杂环境 | 0.10-0.15 | 300-400ms | 减少误触发 |
| 近场麦克风 | 0.08-0.10 | 200-250ms | 避免过度灵敏 |
观察指标
# 好的 VAD 表现
[VAD-DEBUG] max_prob=0.921, speech=yes # 说话时有高概率
[ENDPOINT] speech started # 快速检测到开始
...
[VAD-DEBUG] max_prob=0.012, speech=no # 结束后低概率
[ENDPOINT] speech ended # 准确检测结束
# 不好的 VAD 表现(需要调参)
[VAD-DEBUG] max_prob=0.051, speech=no # 说话但检测为静音(阈值太高)
[VAD-DEBUG] max_prob=0.211, speech=yes # 环境噪音误触发(阈值太低)5.6 实验5:模式参数对比
目的
理解 fast、balanced、quality 三种模式的区别。
测试方法
# 准备一段测试音频(建议 5-10 秒中文)
# 或者使用相同的一句话重复测试
# 测试 fast 模式
echo "=== Fast Mode ==="
time ./voice_ai_chat models/ggml-small.bin --mode fast \
--threads 8 2>&1 | grep -E "(real|TEXT)"
# 测试 balanced 模式
echo "=== Balanced Mode ==="
time ./voice_ai_chat models/ggml-small.bin --mode balanced \
--threads 8 2>&1 | grep -E "(real|TEXT)"
# 测试 quality 模式
echo "=== Quality Mode ==="
time ./voice_ai_chat models/ggml-small.bin --mode quality \
--threads 8 2>&1 | grep -E "(real|TEXT)"参数对比实验
# 实验:max-segment-ms 对延迟的影响
for ms in 1600 2200 3000; do
echo "max-segment-ms = $ms"
time ./voice_ai_chat models/ggml-small.bin \
--mode balanced \
--max-segment-ms $ms \
--threads 8
done结果分析
| 模式 | 准确率 | 延迟 | 适用场景 |
|---|---|---|---|
| fast | ⭐⭐⭐ | 最低 | 命令词、短句 |
| balanced | ⭐⭐⭐⭐ | 中等 | 日常对话 |
| quality | ⭐⭐⭐⭐⭐ | 较高 | 长句、专业内容 |
5.7 实验6:文本优化功能
目的
测试热词、词库、替换规则对识别准确率的提升。
实验6.1:热词提示词
# 1. 创建热词文件
cat > hotwords_tech.txt << EOF
实时性
延迟
吞吐
模型推理
量化
神经网络
EOF
# 2. 使用热词运行
./voice_ai_chat models/ggml-small.bin \
--mode balanced \
--hotwords-file hotwords_tech.txt
# 3. 测试:说出这些技术术语,观察识别准确率实验6.2:术语替换
# 1. 创建替换规则文件
cat > replacements_tech.txt << EOF
实实性 => 实时性
推力 => 推理
模形 => 模型
量化 => 量化
EOF
# 2. 使用替换规则运行
./voice_ai_chat models/ggml-small.bin \
--mode balanced \
--replacements-file replacements_tech.txt
# 3. 测试:故意说错词,观察是否被纠正实验6.3:词库纠错
# 1. 创建词库文件
cat > lexicon_office.txt << EOF
# 标准词 <TAB> 别名1,别名2,...
带饭 带翻,代饭
报销 报消
工牌 工牌子
邮箱 油香
EOF
# 2. 使用词库运行
./voice_ai_chat models/ggml-small.bin \
--mode balanced \
--lexicon-file lexicon_office.txt
# 3. 测试:说出"带翻",观察输出是否为"带饭"5.8 实验7:调试与日志
目的
学习使用日志排查问题。
开启详细日志
# debug 级别会显示所有内部状态
./voice_ai_chat models/ggml-small.bin \
--mode balanced \
--log-level debug \
2>&1 | tee voice_ai_debug.log关键日志解读
# 过滤关键日志
# 1. VAD 检测
grep "VAD-DEBUG" voice_ai_debug.log
# 2. 端点事件
grep "ENDPOINT" voice_ai_debug.log
# 3. 队列操作
grep "QUEUE" voice_ai_debug.log
# 4. ASR 处理
grep "ASR-WORKER" voice_ai_debug.log
# 5. 最终文本
grep "TEXT" voice_ai_debug.log常见问题日志模式
问题1:VAD 检测不到语音
# 现象:没有 speech started
[VAD-DEBUG] max_prob=0.021, segments=0, speech=no
# 解决:降低阈值 --vad-threshold 0.03问题2:队列堆积
[QUEUE] enqueue utterance #10 ...
[QUEUE] skip utterance: too short ...
# 或
[QUEUE] skip utterance: empty audio range
# 解决:检查音频设备,或降低 max-segment-ms问题3:LLM 队列满
[warn] final 文本队列已满,丢弃最旧的一条
# 解决:增加 --llm-queue-size,或检查网络5.9 综合实验:配置你的最佳参数
实验目标
通过系统测试,找到适合你的硬件和场景的最佳参数组合。
测试矩阵
#!/bin/bash
# optimization.sh - 参数优化测试
MODELS=("base" "small")
MODES=("fast" "balanced")
THRESHOLDS=(0.04 0.06 0.08)
for model in "${MODELS[@]}"; do
for mode in "${MODES[@]}"; do
for threshold in "${THRESHOLDS[@]}"; do
echo ""
echo "=========================================="
echo "Model: $model, Mode: $mode, Threshold: $threshold"
echo "=========================================="
# 运行测试(建议录制一段标准测试语音)
timeout 30 ./voice_ai_chat \
models/ggml-$model.bin \
--mode $mode \
--vad-threshold $threshold \
--threads 8 \
--log-level info
done
done
done评估维度
| 维度 | 评估方法 | 目标值 |
|---|---|---|
| 延迟 | 说完话到看到 Kimi> 的时间 | < 3s |
| 准确率 | 正确识别字数 / 总字数 | > 90% |
| 误触发 | 环境噪音触发次数 | < 1次/分钟 |
| 丢字率 | 未检测到的说话次数 | < 5% |
| CPU 占用 | top/htop 观察 | < 70% |
学习资源推荐
Whisper.cpp 相关
TTS 相关
LLM 本地部署
C++ 并发编程
-
《C++ Concurrency in Action》(Anthony Williams)
-
cppreference.com 的并发部分