1.乔姆斯基文法
(1)基础数学定义

(2)乔姆斯基文法四元组


对于VN,语言学家会预定义一套符号,比如:
S代表句子
NP代表名词短语(Noun Phrase)
VP代表动词短语(Verb Phrase)
对于P,也是专家定义的一系列规则,是根据语法定义的 如:S->NP VP
(3)乔姆斯基层次结构

2.上下文无关文法(CFG)


如果对于左侧是NP的规则,后续的选择有很多,这里可以循环来尝试
课件中的另一个例子:
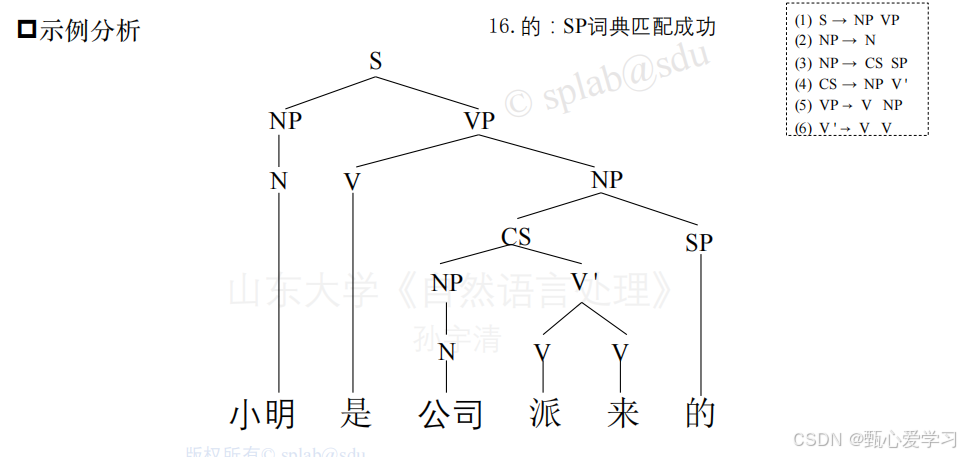
3.乔姆斯基范式(CNF)
Chomsky Normal Form
注意,CNF是CFG的子集
严格规则定义:

比如

| 特性 | 普通 CFG (2 型文法) | CNF (乔姆斯基范式) |
|---|---|---|
| 灵活性 | 极高,右边可以随心所欲组合 | 极低,只能是 BC 或 a |
| 语法树形状 | 任意形状的多叉树 | 标准二叉树 |
| 算法支持 | 较难直接进行高效自动化解析 | 完美适配 CYK 等动态规划算法 |
| 地位 | 语言学的描述工具 | 计算机 NLP 的运算工具 |
CYK算法是判断句子是否符合文法的经典算法,它要求文法必须是CNF格式
对于长度为n的句子,在CNF文法下,推导过程正好需要2n-1步
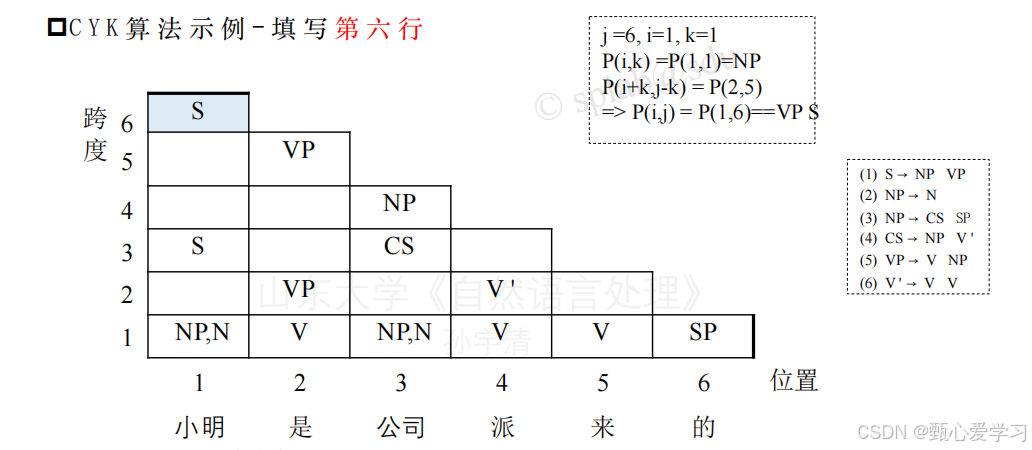
CYK算法
CYK核心是一个自底向上的动态规划过程
目标是:给定一个句子和一个 CNF 文法,填满一个三角形的表格,最终看顶格是否包含开始符号 S
用一个例子来看:
填写第一行的时候,注意也要使用规则,每个格可能有好几种表示
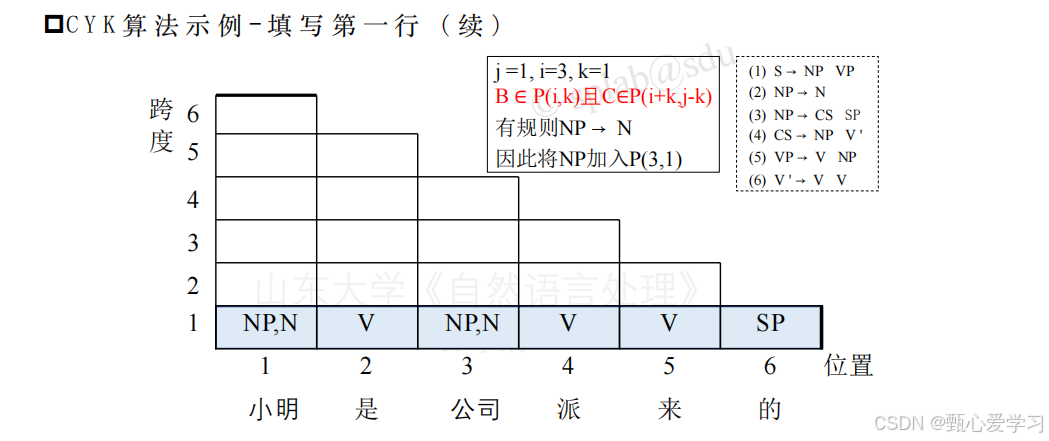
填写第二行时候,如果是12拼成的,第二行要写在1的位置
在下图中,VP->V NP是根据2、3格的出来的,也就是要写在2的位置

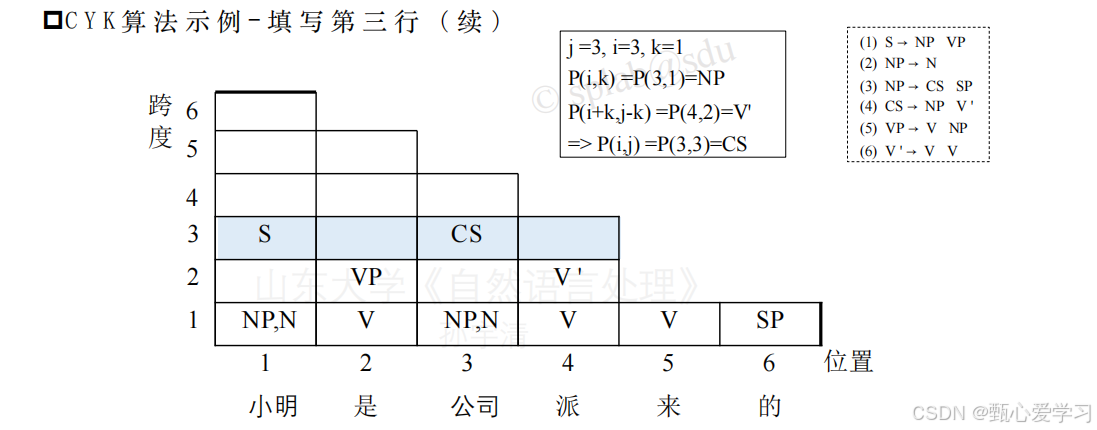
在填写第3行的时候,可以自由的组合,比如可以1+23,12+3,23+4等等都可以,把符合的写出来即可,如下图
比如其中第三行的1位置,是由1+23得到的(S -> NP VP)
4.概率上下文无关法
在传统的 CFG 中,一个句子往往能推导出多棵语法树(这就是所谓的歧义性)
在概率上下文无关法中,对于同一个非终结符(左手边相同),其所有可能的推导规则概率之和必须等于 1,比如

引入概率后,之前的 CYK 算法 就进化成了 概率 CYK 算法:
-
填表内容变了:以前格子里只写 {NP, VP},现在要写 {(NP, 0.5), (VP, 0.2)}。
-
组合逻辑变了:当你合并两个格子时,不再是简单的拼接,而是要进行乘法运算:
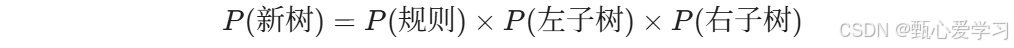
-
目标变了 :不再是"填满就行",而是在填表过程中,如果同一个格子里出现了多个相同的非终结符(比如两个不同的推导都得到了 NP),只保留概率最大的那一个(类似于 Viterbi 算法的思想)


三个问题:(类似HMM中的三个问题)


