基础的图像操作
python
"""
图像分类:
二值图 1通道,每个像素点由0,1组成
灰度图 1通道,每个像素点范围[0,255]
索引图 1通道,每个像素点范围[0,255],像素点表示颜色表的索引
RGB真彩图 3通道,Red,Green,Blue,红绿蓝
"""
import numpy as np
import matplotlib.pyplot as plt
import torch
# 定义函数绘制全黑或全白
def dm01():
# HWC 高度 宽度 通道
img1 = np.zeros((200,200,3))
plt.imshow(img1)
plt.show()
img2 = torch.full(size=(200,200,3),fill_value=255)
plt.imshow(img1)
plt.axis(off) # 坐标轴隐藏的情况下,白色无法显示
plt.show()
# 定义函数加载图片
def dm02():
# 加载图片
img1 = plt.imread()
print(f'img1:{img1}')
print(f'img1.shape:{img1.shape}')
# 保存图片
plt.imsave('./data/img_copy.png',img1)
plt.imshow(img1)
plt.show()
python
"""
卷积层API,用于提取图像的局部特征,获取特征图(Feature Map)
卷积神经网络(Convolutional neural netword)
卷积层(Convolutional)用于提取图像的局部特征,结合卷积核(每个卷积核=一个神经元)实现,处理后的结果叫特征图
池化层(Pooling)用于降维、降采样
全连接层(Full Connected,fc,linear)用于预测结果,并输出结果
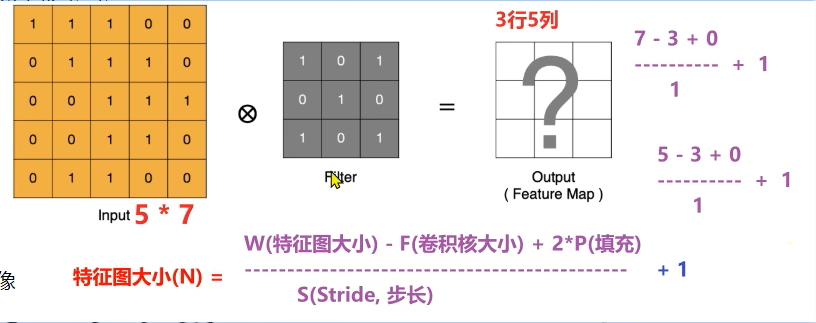
特征图计算方式:N = (W - F + 2 * P)/S + 1
W 输入图像的大小
F 卷积核的大小
P 填充的大小
S 步长
N 输出图像的大小(特征图大小)
"""
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
def dm01():
# 1.加载RGB真彩图
img = plt.imread('./data/img.jpg')
print(f'img:{img},shape:{img.shape}') # HWC(640,640,3)
# 2.图像形状从HWC->CHW img-张量-转换维度
img2 = torch.tensor(img,dtype=torch.float)
img2 = img2.permute(2,0,1) # CHW(3,640,640)
# 3.这里只有1张图片,所以增加1个维度,从CHW(1,C,H,W),1张3通道的640*640像素的图
img3 = img2.unsqueeze(dim=0) #
# 4.创建卷积层对象,提取特征图
conv = nn.Conv2d(3,4,3,2,0)
conv_img = conv(img3) # 具体的卷积计算
# 5.打印卷积后的结果
print(f'conv_img:{conv_img},shape:{conv_img.shape}')
# 6.查看提取到的4个特征图
img4 = conv_img[0]
print(f'img4:{img4},shape:{img.shape}') # ->(4,319,319)
# 7.将上述的CHW->HWC
img5 = img4.permute(1,2,0)
print(f'img5:{img5},shape:{img5.shape}')
# 8.可视化第1个通道的特征图
feature1 = img[:,:,0].detach().numpy() # 第0通道(319,319)像素图
plt.imshow(feature1)
plt.show()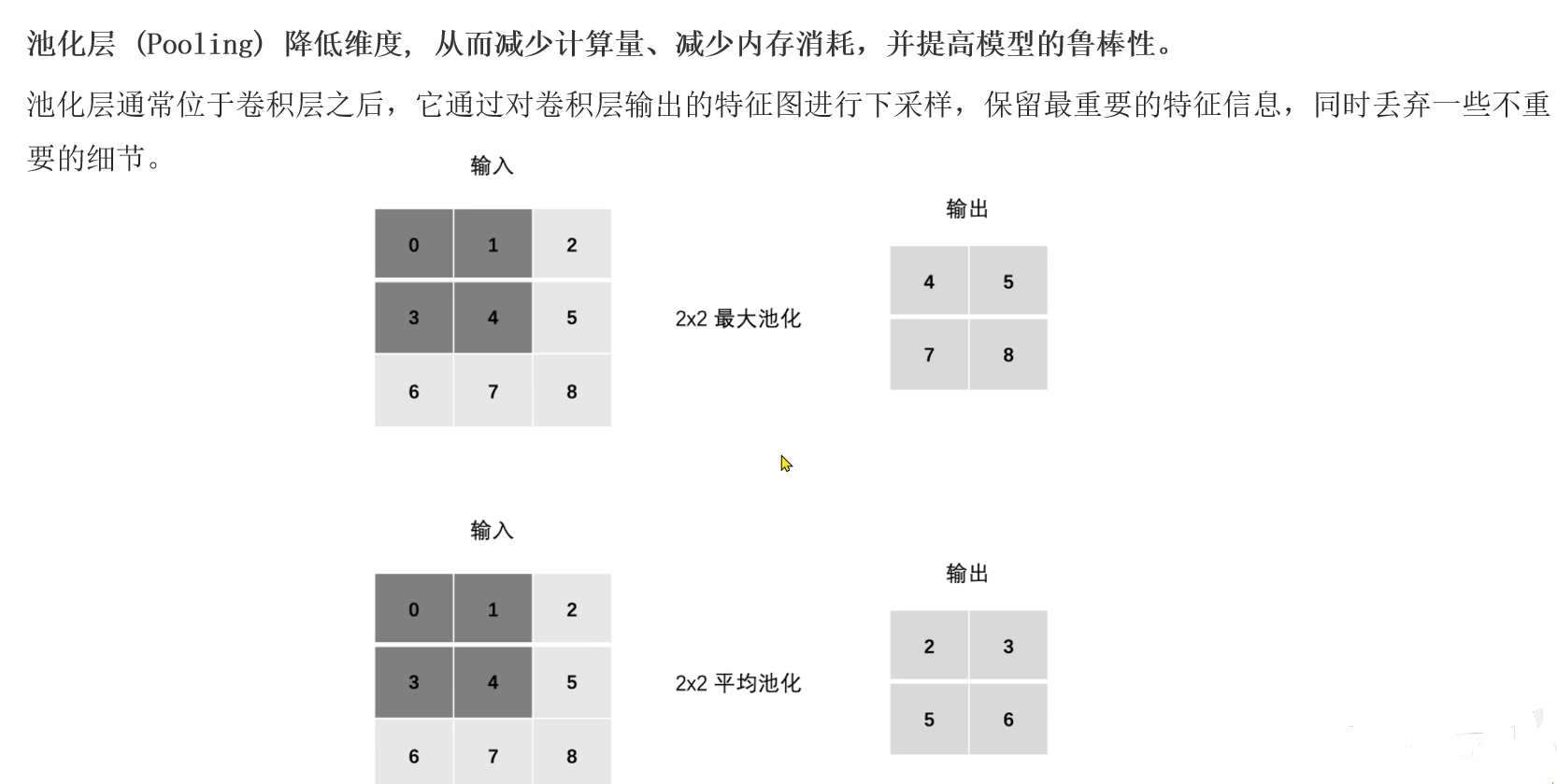
python
"""
池化目的是降维
最大池化
平均池化
不会改变数据的通道数
"""
import torch
import torch.nn as nn
# 单通道池化
def dm01():
# 1.创建1个通道 3x3的二维矩阵
inputs = torch.tensor([ # 1 通道C
[ # 3 高度H
[1,2,3], # 3 宽度W
[3,4,5],
[6,7,8]
]
])
print(f'inputs:{inputs},shape:{inputs.shape}') # (1,3,3)
# 2.创建最大池化层
# 参数一:池化核(池化窗口大小) 参数二:补偿 参数三:填充
pool1 = nn.MaxPool2d(2,1,0)
outputs = pool1(inputs)
# 3.创建平均池化层
pool2 = nn.AvgPool2d(2,1,0)
outputs = pool2(inputs)
# 多通道池化
def dm02():
inputs = torch.tensor([ # 3 通道C
[ # 3 高度H
[1,2,3], # 3 宽度W
[3,4,5],
[6,7,8]
],
[ # 通道2,HW 3,3
[10,20,30],
[40,50,60],
[70,80,90]
],
[ # 通道3,HW 3,3
[11,22,33],
[44,55,66],
[77,88,99]
]
])CNN图像分类案例
python
"""
CNN图像分类
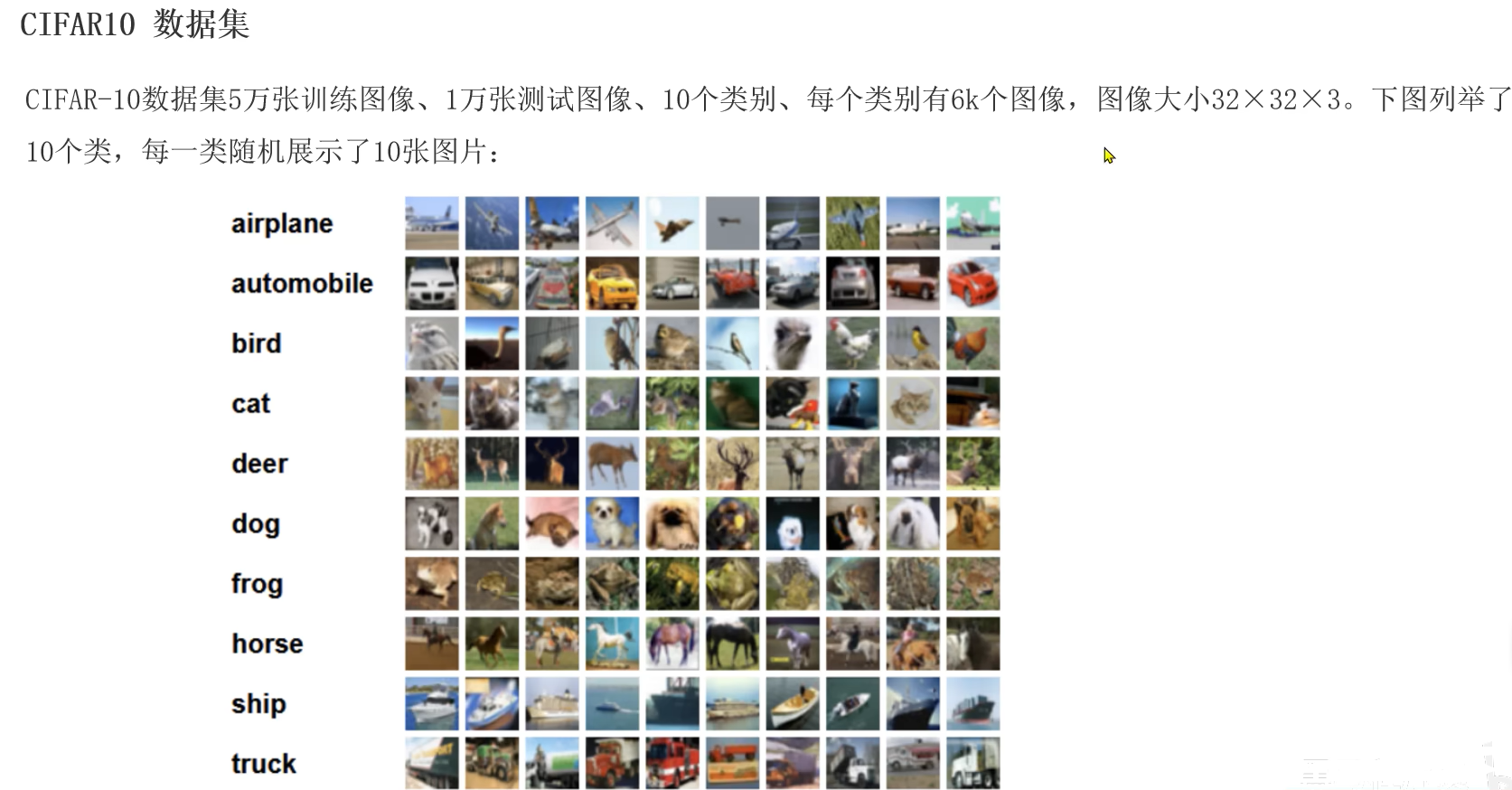
1.准备数据,使用计算机视觉模块torchvision自带的CIFAR10数据集,包含6w张图片(5W张训练姐,1W张测试集,10个分类,每个分类6K张图片)
2.搭建卷积神经网络
3.模型训练
4.模型测试
卷积层:提取图像局部特征->特征图(Feature Map),计算方式:N = (W-F+2P)//S+1,每个卷积核都是一个神经元
池化层:降维,最大池化和平均池化,降维只在HW上微调整,通道上不改变
"""
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor # pip install torchvision -i https://mirrors.aliyun.com/pypi/simple
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
# 每批次样本数
Batch_SIZE = 8
# 准备数据集
def create_dataset():
# 参数一:数据集路径 参数二:是否训练集 参数三:数据预处理->张量数据 参数四:是否联网下载
train_dataset = CIFAR10(root='./data',train=true,transform=ToTensor(),download=True)
test_dataset = CIFAR10(root='./data',train=False,transform=ToTensor(),download=True)
return train_dataset,test_dataset
# 搭建卷积神经网络
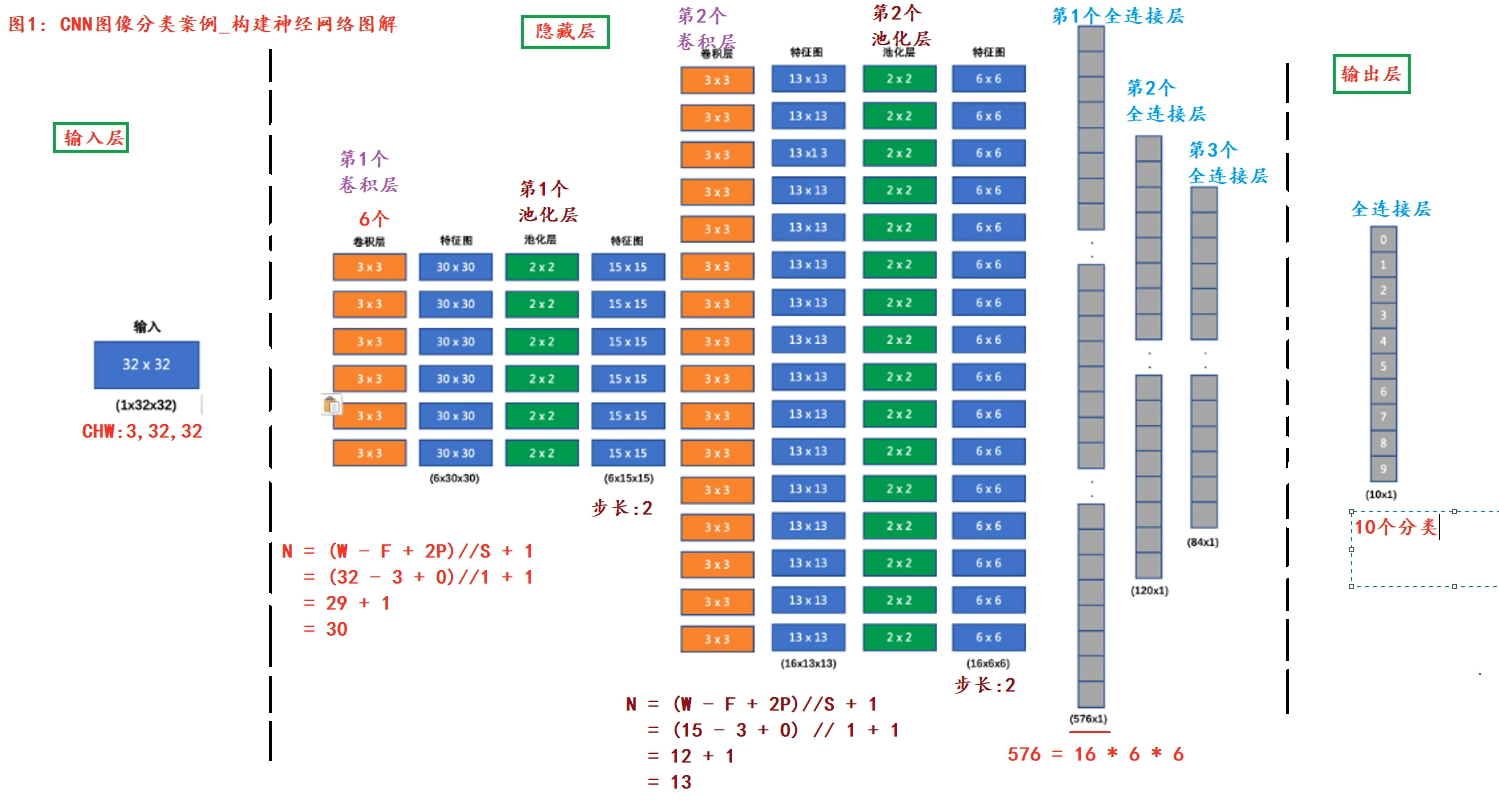
class ImageModel(nn.Module):
# 1.初始化父类成员,搭建神经网络
def __init__(self):
super().__init__(self)
# 第1个卷积层:输入3通道,输出6通道,卷积核大小3,步长1,填充0
self.conv1 = nn.Conv2d(3,6,3,1,0)
# 第1个池化层:窗口大小2*2,步长2,填充0
self.pool1 = nn.MaxPool2d(2,2,0)
# 第2个卷积层和第2个池化层
self.conv2 = nn.Conv2d(6,16,3,1,0)
self.pool2 = nn.MaxPool2d(2,2,0)
# 第1个隐藏层(全连接层)输入576,输出120
self.linear1 = nn.Linear(576,120)
# 第2个隐藏层
self.linear2 = nn.Linear(120,84)
self.output = nn.Linear(84,10)
# 前向传播
def forward(self,x):
# 卷积层+激励层(激活函数)+池化层(降维)
x = self.pool1(torch.relu(self.conv1(x)))
x = self.pool2(torch.relu(self.conv2(x)))
# 全连接层(只能处理二维)+激活函数
# 参数一:样本数(行数),参数二:列数(特征数),-1自动计算
x = x.reshape(x.size(0),-1)
# 第3层:全连接层(加权求和)+激励层(激活函数)
x = torch.relu(self.linear1(x))
# 第4层:全连接层(加权求和)+激励层(激活函数)
x = torch.relu(self.linear2(x))
# 第5层:全连接层(加权求和)+输出层
return self.output(x) # 后续用多分类交叉熵损失函数CrossEntropyLoss = Softmax()激活函数+损失函数
# 模型训练
def train(train_dataset):
dataloader = DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True)
model = ImageModel()
# 创建损失函数对象
criterion = nn.CrossEntropyLoss()
# 创建优化器对象
optimizer = optim.Adam(model.parameters(),lr=1e-3)
epochs = 10
for epoch_idx in range(epochs):
# 总损失 总样本数量 预测正确样本个数 训练还是时间
total_loss,total_samples,total_correct,start = 0.0,0,0,time.time()
# 遍历数据加载器,获取到每批次的数据
for x,y in dataloader:
model.train()
y_pred = model(x)
loss = criterion(y_pred,y) # 计算损失
# 梯度清零+反向传播+参数更新
optimizer.zero_grad()
loss.backword()
optimizer.step()
# 统计预测正确的样本个数
print(y_pred)
print(torch.argmax(y_pred,dim=-1)) # -1表示行 预测分类
print(y) # 真实分类
print(torch.argmax(y_pred,dim=-1) == y) # 是否预测正确
print((torch.argmax(y_pred,dim=-1) == y).sum()) # 预测正确的样本个数
total_correct += (torch.argmax(y_pred,dim=-1) == y).sum()
# 统计当前批次的总损失
total_loss += loss.item() * len(y) # 第一批总损失+第2批总损失+......
# 统计当前批次的总样本个数
total_samples += len(y)
# 一轮训练完毕,打印概论的训练信息
print(f'epoch:{epoch_idx + 1},loss:{total_loss / total_samples:.5f},acc:{totao_correct / total_samples:.2f},time:{time.time()-start.2f}')
# 保存模型
torch.save(model.state_dict(),'./model/image_model.pth')
# 模型测试
def evaluate(test_dataset):
# 1.创建测试集,数据加载器
dataloader = DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=False)
# 2.创建模型对象
model = ImageModel()
# 3.加载模型参数
model.load_state_dict(torch.load('./model/image_model.pth'))
# 4.定义变量统计,预测正确的样本个数,总样本数
total_correct,total_samples = 0,0
# 5.遍历数据加载器,获取到每批次的数据
for x,y in dataloader:
model.eval() # 切换模型模式
y_pred = model(x)
# 因为训练的时候用了CrossEntropyLoss,所以搭建神经网络没有加softmax()激活函数,这里要用argmax()来模拟
# argmax()功能,返回最大值对应的索引,充当改图偏的预测分类
y_pred = torch.argmax(y_pred,dim=-1) # -1 表示行
# 统计预测正确的样本个数
total_correct += (torch.argmax(y_pred,dim=-1)==y).sum()
# 统计总样本个数
total_samples += len(y)
# 打印正确率
print(f'Acc:{total_correct / total_samples:.2f}')
if __name__ == '__main__':
train_dataset,test_dataset = create_dataset()
print(f'训练集:{train_dataset.data.shape}') # (50000,32,32,3)
print(f'测试集:{test_dataset.data.shape}') # (10000,32,32,3)
print(f'数据类别:{train_dataset.class_to_idx}')
# 图像展示
plt.figure(figsize=(2,2))
plt.imshow(train_dataset.data[1111]) # 索引为1111的图像
plt.title(train_dataset.targets[1111])
plt.show()
# 搭建神经网络
model = ImageModel()
#查看模型参数,参数一:模型 参数二:输入维度(CHW 通道 高 宽) 参数三:批次大小
summary(model,(3,32,32),batch_size=BATCH_SIZE)
# 模型训练
train(train_dataset)
# 模型评估
evaluate(test_dataset)模型参数如下:

案例增加优化思路
- 增加卷积核的输出通道(卷积核的数量)
- 增加全连接层的参数量
- 调整学习率
- 调整优化方法(optimizer...)
- 调整激活函数
- ......
根据提供的数据结构,建立CNN模型,识别图片中的猫/狗,计算预测准确率
从网站下载猫/狗图片,进行预测
python
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGnerator(rescale=1./255)
training_set = train_datagen.flow_from_directory('./dataset/training_set',target_size=(50*50),batch_size=32,class_mode='binary')
python
#建立cnn模型
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Flatten,Dense
model = Sequential()
#增加卷积层
model.add(Conv2D(32,(3,3),input_shape=(50*50*3),activation='relu'))
#增加池化层
model.add(MaxPool2D(pool_size=(2,2)))
#卷阶层
model.add(Conv2D(32,(3,3),activation='relu'))
#池化层
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=128,activation='relu'))
model.add(Dense(units=1,activation='sigmoid'))
python
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
model.summary() #查看模型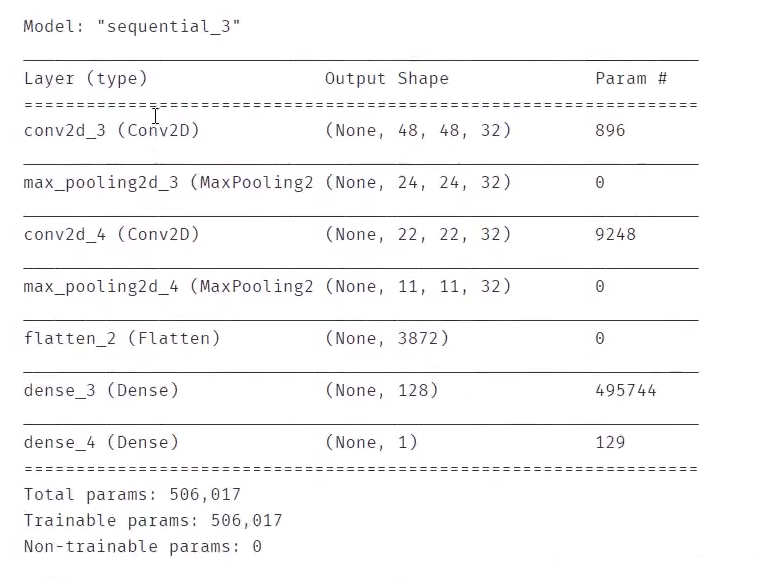
python
#模型训练
model.fit_generator(training_set,epochs=25)
python
#训练数据预测
accuracy_train = model.evaluate_generator(training_set)
print(accuracy_train)
#测试数据预测
test_set = train_datagen.flow_from_directory('./dataset/training_set',target_size=(50*50),batch_size=32,class_mode='binary')
accuracy_test = model.evaluate_generator(test_set)
print(accuracy_test)
python
#加载单张图片进行预测
from keras.preprocessing.image import load_img,img_to_arry
pic_dog = 'dog.jpg'
pic_dog = load_img(pic_dog,target_size(50,50))
pic_dog = img_to_array(pic_dog)
pic_dog = pic_dog/255
pic_dog = img.reshape(1,50,50,3)
result = model.predict_classes(pic_dog)
print(result)使用VGG16的结构提取图像特征,再根据特征建立mlp模型,实现猫狗图像识别,训练、测试数据dataset\data_vgg
- 对数据进行分离,计算测试数据预测准确率
- 从网站下载猫狗图片,对其进行预测
mlp模型是一个隐藏层,10个神经元
python
from keras.preprocessing.image import load_img,img_to_array
img_path = '1.jpg'
img = load_img(img_path,target_size=(224,224))
img = imt_to_array(img)
type(img)
python
from keras.applications.vgg16 import VGG15
from keras.applications.vgg16 import preprocess_input
import numpy as np
model_vgg = VGG16(weights='imagenet',include_top=False)
x = np.expand_dims(img,axis=0)
x = preprocess_input(x)
print(x.shape)
python
#轮廓特征提取
features = model_vgg.predict(x)
print(features.shape)
python
featurws = features.reshape(1,7*7*512)
print(features.shape)
python
%matplotlib inline
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(5,5))
img = load_img(img_path,target_size(224,224))
plt.imshow(img)
python
#数据分离
from sklearn.model_selection import train_test_test_split
X_train,X_test,y_train,y_test train_test_split(X,y,test_size=0.3,random_state=50)
print(X_train.shape,X_test.shape,X.shape)
python
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(units=10,activation='relu',input_dim=25088))
model.add(Dense(units=1,activation='sigmoid'))
model.summary()
python
#配置模型,并训练模型
model.compile(optimizer='adam',loss='binary_crossnetropy',metrics=['accuracy'])
model.fit(X_train,y_train,epochs=50)
python
from sklearn.metrics import accuracy_score
y_train_predict = model.predict_classes(X_train)
accuracy_train = accuracy_score(y_train,y_train_predict)
print(accuracy_train)
#测试准确率
y_test_predict = model.predict_classes(X_test)
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_test)
python
img_path = 'dog.jpg'
img = load_img(img_path,target_size(224,224))
img = img_to_array(img)
X = np.wxpand_dims(img,axis=0)
X = preprocess_input(X)
features = model_vgg.predict(x)
features = model_reshape(1,7*7*512)
result = model.predict_classes(features)
print(result)