本文讲解两种非纯手补环境的方法------自动化和jsdom模块
自动化(包括但不限于selenium)
我们都知道selenium, DP这种自动化可以实现整个浏览器的模拟,所以模拟时会包含整个浏览器的环境,我们可以通过这种来运行js代码直接产生结果,理论可行开始实践:
- 首先需要将js文件写在html文件中方便selenium访问:

- 然后写selenium脚本(后面有源代码):
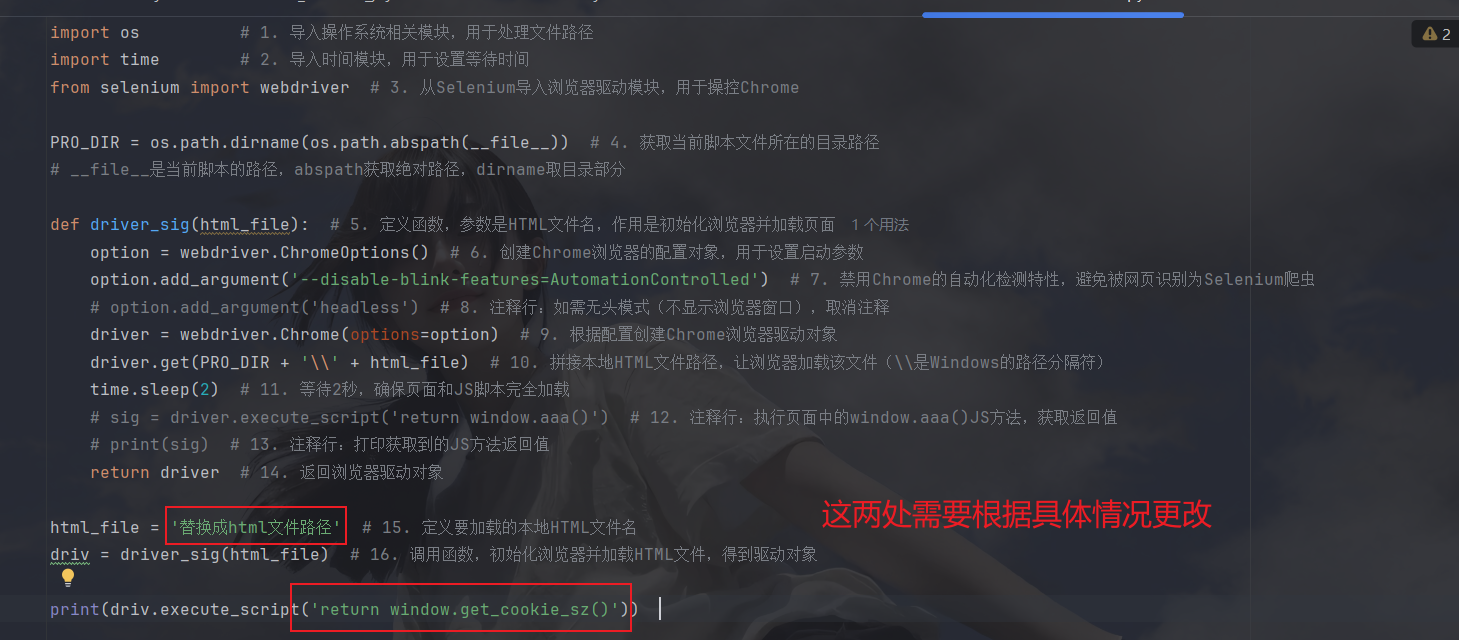
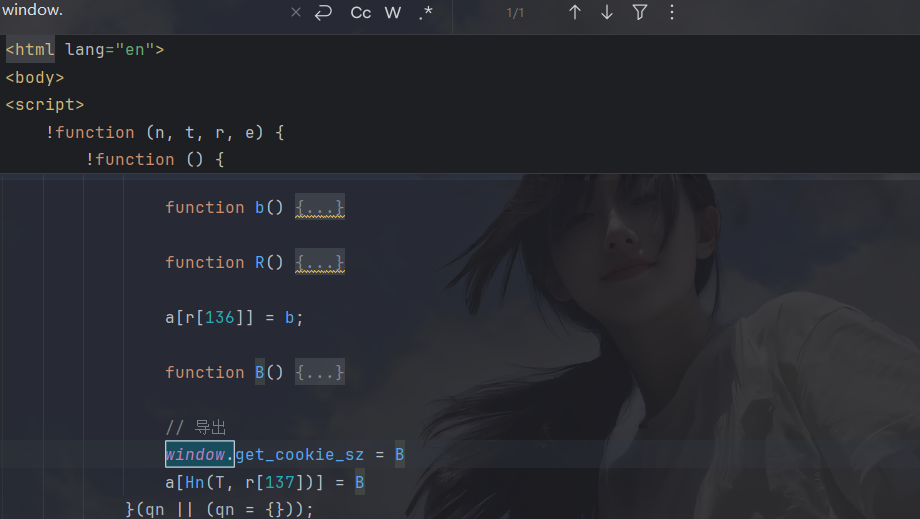
- 然后更改的第一处就是html文件的文件名(上面图片标注有点问题,同一目录下填文件名即可)第二处这样改------找到加密函数的位置,上一文就已经讲解就是B函数,然后导出即可:
- 然后运行py就能得到(我没有安装浏览器驱动,所以就不给大家展示结果了)
Selenium代码:
python
import os # 1. 导入操作系统相关模块,用于处理文件路径
import time # 2. 导入时间模块,用于设置等待时间
from selenium import webdriver # 3. 从Selenium导入浏览器驱动模块,用于操控Chrome
PRO_DIR = os.path.dirname(os.path.abspath(__file__)) # 4. 获取当前脚本文件所在的目录路径
# __file__是当前脚本的路径,abspath获取绝对路径,dirname取目录部分
def driver_sig(html_file): # 5. 定义函数,参数是HTML文件名,作用是初始化浏览器并加载页面
option = webdriver.ChromeOptions() # 6. 创建Chrome浏览器的配置对象,用于设置启动参数
option.add_argument('--disable-blink-features=AutomationControlled') # 7. 禁用Chrome的自动化检测特性,避免被网页识别为Selenium爬虫
# option.add_argument('headless') # 8. 注释行:如需无头模式(不显示浏览器窗口),取消注释
driver = webdriver.Chrome(options=option) # 9. 根据配置创建Chrome浏览器驱动对象
driver.get(PRO_DIR + '\\' + html_file) # 10. 拼接本地HTML文件路径,让浏览器加载该文件(\\是Windows的路径分隔符)
time.sleep(2) # 11. 等待2秒,确保页面和JS脚本完全加载
# sig = driver.execute_script('return window.aaa()') # 12. 注释行:执行页面中的window.aaa()JS方法,获取返回值
# print(sig) # 13. 注释行:打印获取到的JS方法返回值
return driver # 14. 返回浏览器驱动对象
html_file = '替换成html文件路径' # 15. 定义要加载的本地HTML文件名
driv = driver_sig(html_file) # 16. 调用函数,初始化浏览器并加载HTML文件,得到驱动对象
print(driv.execute_script('return window.get_cookie_sz()'))下面写一下DrissionPage的吧,让大家看看效果:
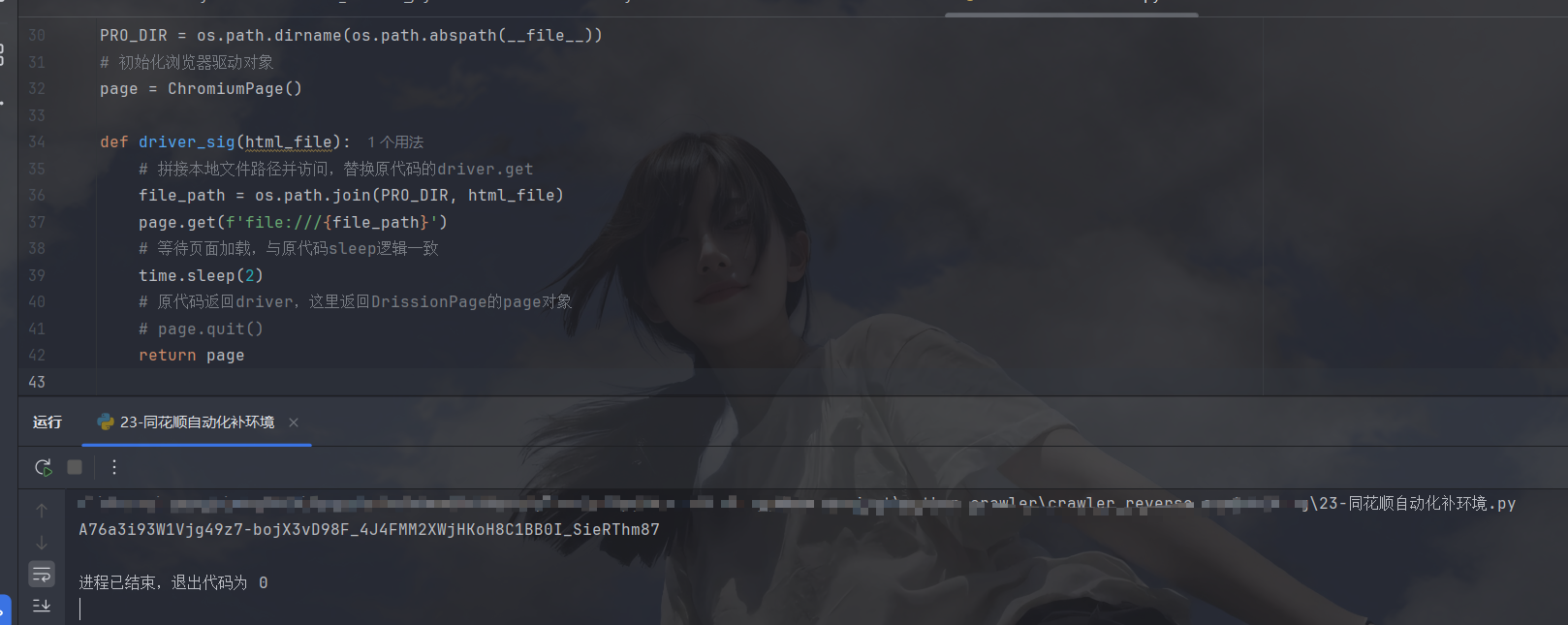
源码:
python
# DP补环境
import os
import time
from DrissionPage import ChromiumPage
# 获取当前文件所在目录,与原代码PRO_DIR逻辑一致
PRO_DIR = os.path.dirname(os.path.abspath(__file__))
# 初始化浏览器驱动对象
page = ChromiumPage()
def driver_sig(html_file):
# 拼接本地文件路径并访问,替换原代码的driver.get
file_path = os.path.join(PRO_DIR, html_file)
page.get(f'file:///{file_path}')
# 等待页面加载,与原代码sleep逻辑一致
time.sleep(2)
# 原代码返回driver,这里返回DrissionPage的page对象
# page.quit()
return page
# 定义HTML文件名称,与原代码一致
html_file = 'xxx'
# 调用函数获取page对象,对应原代码的driv
driv = driver_sig(html_file)
# 执行JS脚本并打印结果,对应原代码的execute_script
print(driv.run_js('return window.get_cookie_sz()'))
page.quit()这样就拿到cookie加密值了,这种方法只适合救急用或者不考虑效率的时候用
jsdom
最开始是给js前端开发人员使用的,作用是使node能直接测试浏览器里的js代码,这里面封装了常见的浏览器环境(冷门的还需要靠我们逆向工程师自己补啊/(ㄒoㄒ)/~~),先来看一下效果:
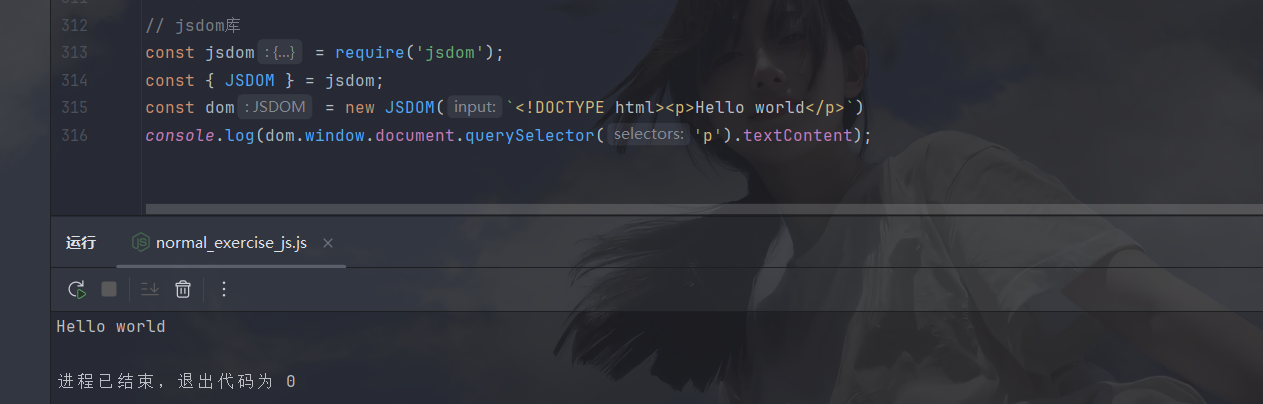
这里我们完全没有document这个对象吧,但是就是能使用里面的方法取出文本,因为dom中有document的封装,现在我们来尝试一下原来的案例,初始就是这样:

然后运行:
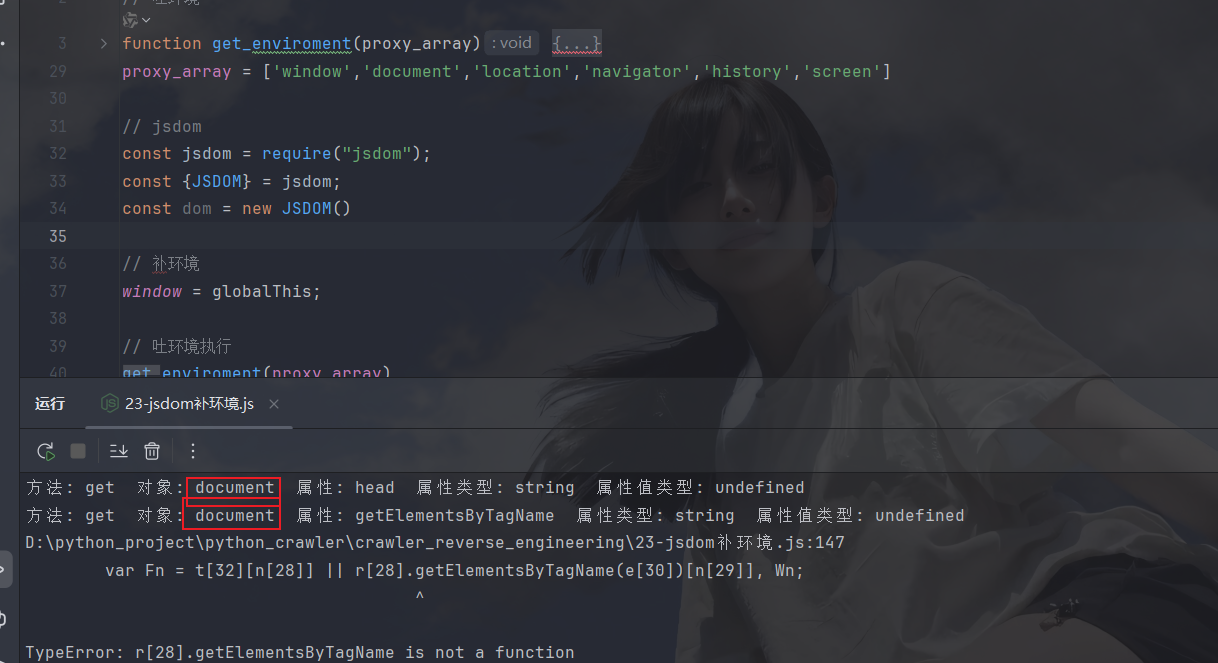
缺document,刚说了dom中存在,咱就直接这样补:

再运行:
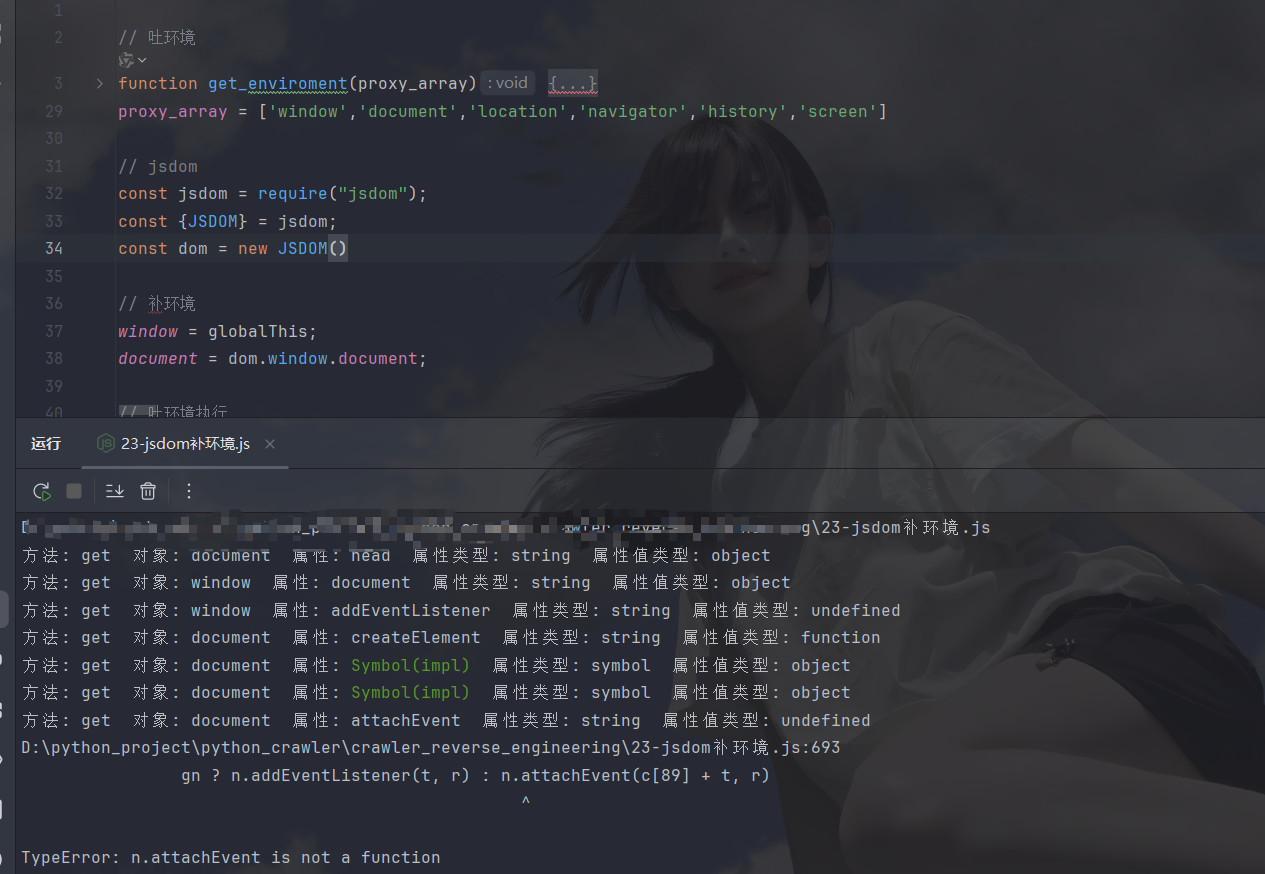
大部分就补上了,然后我们把globalThis也换成dom中的window更贴合浏览器环境:
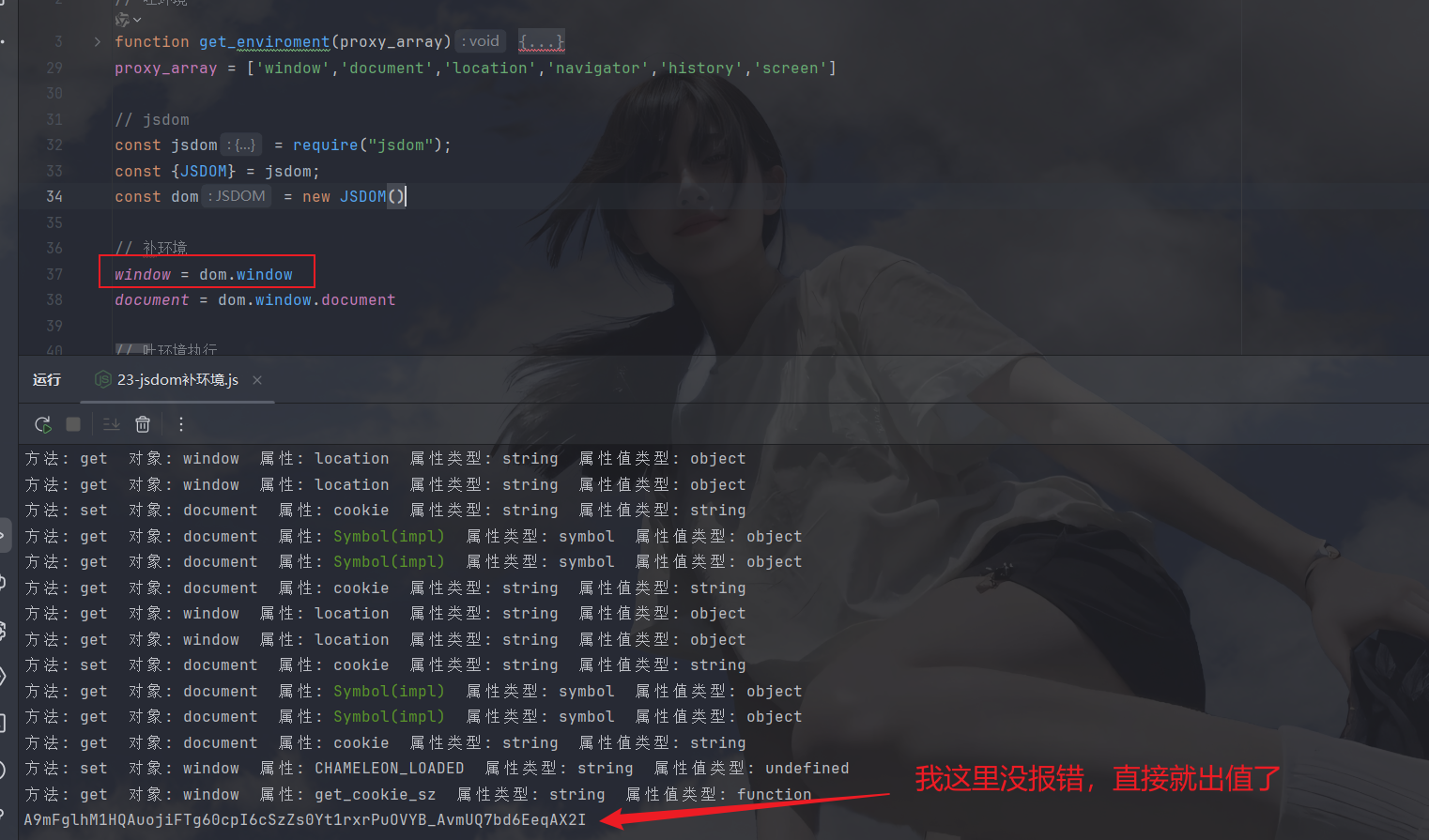
但是这个值不一定能用,里面有try,我没又让其中的错误报出来
需要注意的是:如果缺location就手动去补,因为需要设置dom而且很多情况下设置不上,其他的就这样补即可(比如:window, navigator)
小结
本文到此就结束了,有这两种方法应急和简单网站处理都可以有方法了,但是不急而且网站还比较难的话就还是需要自己手动补,OK,文章如有问题请及时提出,加油加油