目录:
一、自定义小CNN实现手机分类
1、代码示例
适合苹果/华为/小米 3分类手机识别,你可以直接改类别数适配你的任务:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
# --------------------------
# 第一步:定义自定义小CNN (就是我们说的3-4层卷积)
# 结构:输入(3, 224, 224) → 卷积1 → ReLU → 池化 → 卷积2 → ReLU → 池化 → 卷积3 → ReLU → 池化 → 全连接1 → ReLU → 全连接输出
# --------------------------
class SmallPhoneCNN(nn.Module):
def __init__(self, num_classes=3):
"""
num_classes: 你要分的手机类别数,默认3类(苹果/华为/小米)
"""
super(SmallPhoneCNN, self).__init__()
# 1. 卷积层部分:3层卷积,符合你说的3-4层,参数量极小
# 输入是RGB图片,3通道,所以第一层in_channels=3
self.conv1 = nn.Conv2d(
in_channels=3, # 输入RGB三通道
out_channels=16, # 提取16种特征,小任务足够用
kernel_size=3, # 3×3卷积核,最常用
padding=1 # 填充保证卷积后大小不变
)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 池化,把尺寸缩小一半
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1) # 输入16通道,输出32种特征
self.pool2 = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # 输入32通道,输出64种特征
self.pool3 = nn.MaxPool2d(2, 2)
# 2. 全连接层部分:把卷积提取的特征,转成分类输出
# 计算一下:输入224×224,经过3次池化,每次缩小一半:224 → 112 → 56 → 28
# 所以最后特征大小是 64通道 × 28 × 28 = 64*28*28 = 50176
self.fc1 = nn.Linear(64 * 28 * 28, 128) # 卷积特征转128维隐藏向量
self.fc2 = nn.Linear(128, num_classes) # 最后输出:128维转成类别数,就是我们要的结果
# 3. 按照规则做初始化:ReLU用Kaiming初始化
self._initialize_weights()
def _initialize_weights(self):
# 所有卷积和全连接都用Kaiming初始化,符合我们之前说的规则
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
# 前向传播,定义数据怎么走
def forward(self, x):
# x形状:[batch_size, 3, 224, 224] → 一批图片,3通道,大小224×224
x = self.pool1(F.relu(self.conv1(x))) # 第一层卷积+激活+池化 → 输出[batch,16,112,112]
x = self.pool2(F.relu(self.conv2(x))) # 第二层 → 输出[batch,32,56,56]
x = self.pool3(F.relu(self.conv3(x))) # 第三层 → 输出[batch,64,28,28]
# 把四维特征拉成一维,给全连接层:[batch,64,28,28] → [batch, 64*28*28]
x = x.flatten(1)
x = F.relu(self.fc1(x)) # 全连接第一层+激活
x = self.fc2(x) # 最后一层,输出logits,不用加softmax,训练时候交叉熵会处理
return x
# --------------------------
# 第二步:自定义数据集,加载你的手机图片
# 数据存放要求:和之前一样,每个类别一个文件夹:
# ./phone_data/train/
# ├── apple/ (苹果手机图片)
# ├── huawei/ (华为手机图片)
# └── xiaomi/ (小米手机图片)
# ./phone_data/test/ 同理放测试集
# --------------------------
class PhoneDataset(Dataset):
def __init__(self, data_root, transform=None):
self.data_root = data_root
self.transform = transform
# 读取所有类别,生成映射
self.class_names = sorted(os.listdir(data_root))
self.class_to_idx = {cls: i for i, cls in enumerate(self.class_names)}
# 收集所有图片+标签
self.img_paths = []
for cls_name in self.class_names:
cls_dir = os.path.join(data_root, cls_name)
for img_name in os.listdir(cls_dir):
self.img_paths.append((os.path.join(cls_dir, img_name), self.class_to_idx[cls_name]))
def __len__(self):
return len(self.img_paths)
def __getitem__(self, idx):
img_path, label = self.img_paths[idx]
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
return img, label
# --------------------------
# 第三步:训练配置+训练流程
# --------------------------
if __name__ == '__main__':
# 超参数
NUM_CLASSES = 3 # 改成你自己的类别数
BATCH_SIZE = 8
EPOCHS = 15
LR = 1e-3
# 数据预处理
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # 直接resize到224,小模型不用复杂增强
transforms.RandomHorizontalFlip(), # 随机翻转,增加数据多样性
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = PhoneDataset("./phone_data/train", transform=train_transform)
test_dataset = PhoneDataset("./phone_data/test", transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
class_names = train_dataset.class_names
print(f"分类类别:{class_names},总训练样本:{len(train_dataset)}")
# 初始化模型、损失、优化器
model = SmallPhoneCNN(num_classes=NUM_CLASSES)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 多分类交叉熵,和之前讲的完全一样,不用改
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
# 打印模型参数量,看看有多小:
total_params = sum(p.numel() for p in model.parameters())
print(f"模型总参数量:{total_params/1000:.1f}K ≈ {total_params/1000000:.2f}M")
# 输出:大概6.5M,比MobileNet还小,CPU都能轻松跑
# --------------------------
# 开始训练
# --------------------------
for epoch in range(EPOCHS):
model.train()
train_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 前向+算损失
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向+更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
# 计算平均损失
train_loss = train_loss / len(train_dataset)
# 测试集评估准确率
model.eval()
correct = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
correct += torch.sum(preds == labels.data)
acc = correct.double() / len(test_dataset)
print(f"Epoch [{epoch+1}/{EPOCHS}] 训练损失:{train_loss:.4f} 测试准确率:{acc:.4f}")
# --------------------------
# 第四步:单张图片预测测试
# --------------------------
def predict_single_image(img_path):
# 1. model.eval():PyTorch的nn.Module自带方法,切换模型到推理模式,不用自己写
model.eval()
# 2. Image.open():PIL库自带方法,打开图片,不用自己写
# 3. .convert('RGB'):PIL自带,把图片转成三通道RGB,处理透明图/灰度图,自带的
img = Image.open(img_path).convert('RGB')
# 4. test_transform:我们自己定义的数据预处理,就是几个torchvision自带变换的组合,所有变换都是自带的,我们只需要组合,不用自己实现
# 5. .unsqueeze(0):PyTorch张量自带方法,给张量加一个batch维度,自带的
# 6. .to(device):PyTorch张量自带方法,把张量放到GPU/CPU,自带的
img_tensor = test_transform(img).unsqueeze(0).to(device)
# 7. torch.no_grad():PyTorch自带上下文管理器,关闭梯度计算,自带的
with torch.no_grad():
outputs = model(img_tensor) # model本身我们已经定义好了,调用也是自带的
# 8. F.softmax:torch.nn.functional自带函数,自带的,不需要实现
probs = F.softmax(outputs, dim=1)
# 9. torch.max:PyTorch自带函数,找最大值和索引,自带的
top_prob, top_idx = torch.max(probs, dim=1)
# 10. top_idx[0].item():PyTorch张量自带方法,把张量里的单个值转成Python数字,自带的
pred_cls = class_names[top_idx[0].item()]
confidence = top_prob[0].item()
print(f"\n预测结果:输入图片 = {img_path}")
print(f"分类结果:{pred_cls},置信度:{confidence:.4f}")
return pred_cls, confidence
# 替换成你自己的测试图片
predict_single_image("./test_apple.jpg")2、代码解析
Q:SmallPhoneCNN卷积层参数是怎么来的?
A:
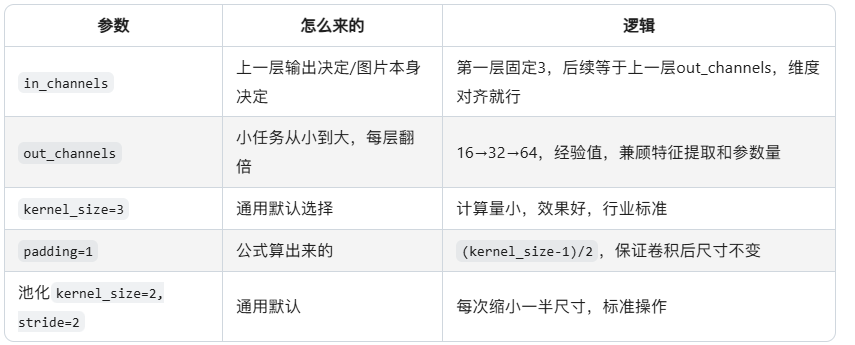
待完善。。。。。。