前言
如果你最近在搞具身智能或者VLA(视觉-语言-动作)模型,那你一定绕不开DINOv2。这个来自Meta AI的视觉编码器,几乎成了所有开源VLA模型的标配------OpenVLA用它,Octo用它,小米的Xiaomi-Robotics-0也用它。为什么大家都这么爱DINOv2?因为它做到了一件前无古人的事:完全不需要任何标注,只靠看图片,就能学到和弱监督CLIP相当甚至更好的通用视觉特征。而且这些特征拿过来就能用,不需要微调,简直是视觉界的"万能钥匙"。今天我们就来深度拆解这篇神作,看看DINOv2到底是怎么炼成的。
论文信息
- 标题:DINOv2: Learning Robust Visual Features without Supervision
- 会议:Transactions on Machine Learning Research (TMLR) 2024
- 单位:Meta AI Research, Inria
- 代码:github.com/facebookresearch/dinov2
- 论文:arxiv.org/abs/2304.07193
一、为什么我们需要DINOv2?
在NLP领域,大语言模型已经证明了:只要给足够多的无标注文本,就能学到通用的语言表示。这些表示可以直接用于各种下游任务,不需要针对每个任务重新训练。但在计算机视觉领域,这个梦想直到DINOv2出现才真正实现。
之前的视觉预训练方法主要有两条路:
- 监督预训练:用ImageNet这种标注好的数据集训练。但标注成本极高,而且学到的特征只能在类似的数据集上好用,泛化能力差。
- 弱监督预训练:用CLIP这种图文对训练。虽然泛化能力强了,但需要大量的图文对齐数据,而且文本描述只能捕捉图片的部分信息,很多像素级的细节(比如深度、边缘)都学不到。
- 自监督预训练:只靠图片自己学习。理论上最完美,但之前的方法要么只能在小数据集上训练,要么用了大量未整理的网络图片,结果特征质量很差。
DINOv2的核心贡献就是:证明了只要有足够多、足够好的无标注图片,自监督学习完全可以学到和弱监督方法相当甚至更好的通用视觉特征。它训练了一个11亿参数的ViT-g模型,在几乎所有视觉任务上都超过了之前的自监督方法,甚至在很多任务上超过了OpenCLIP-G。
二、好数据出好模型------DINOv2的数据炼金术
DINOv2成功的第一秘诀,就是它花了巨大的精力构建了一个高质量的无标注数据集LVD-142M。Meta的工程师们没有直接用网上爬来的12亿张杂乱无章的图片,而是设计了一套精妙的数据处理流水线,从这12亿张图片中精选出了1.42亿张高质量、多样化的图片。
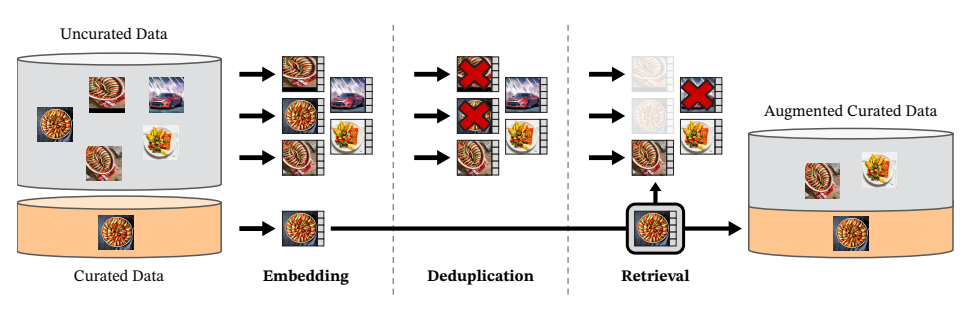
图1:DINOv2的数据处理流水线(出处:原文Figure 3)
2.1 数据处理三步曲
- 数据收集:先收集一批高质量的"种子数据集",包括ImageNet-22k、Google Landmarks等,总共约1400万张图片。这些就像是老师手里的"标准教材"。
- 去重:用自监督模型给所有12亿张图片生成特征,然后去掉重复的图片。这一步就像是把教材里的重复章节删掉,避免浪费时间。
- 检索增强:对于种子数据集中的每一张图片,从12亿张未标注图片中检索出最相似的4张图片。这就像是给每本标准教材配上了4本相关的参考书,让模型能学到更多样的知识。
2.2 数据质量有多重要?
我们来看一个实验,对比不同数据源训练出来的模型性能:
| 训练数据 | ImageNet-1k | ImageNet-A | ADE-20k | Oxford-M |
|---|---|---|---|---|
| ImageNet-22k | 85.9 | 73.5 | 46.6 | 62.5 |
| 随机未整理数据 | 83.3 | 59.4 | 48.5 | 54.3 |
| LVD-142M | 85.8 | 73.9 | 47.7 | 64.6 |
表1:不同数据源的性能对比(出处:原文Table 2)
从表中可以清楚地看到:
- 用随机未整理的数据训练,虽然数据量一样大,但性能全面下降,尤其是在分布外的ImageNet-A上,准确率直接掉了14.1%。这就像是给学生看一堆乱七八糟的漫画,虽然看得多,但学不到有用的知识。
- 用LVD-142M训练的模型,在ImageNet-1k上和ImageNet-22k相当,但在其他所有任务上都更好。这说明多样化的高质量数据能显著提升模型的泛化能力。
三、三位一体的训练秘方------DINO+iBOT+KoLeo
有了好数据,还需要好的训练方法。DINOv2没有发明全新的自监督方法,而是巧妙地结合了之前三个最优秀的方法:DINO、iBOT和KoLeo,再加上一些工程上的改进,最终得到了远超单个方法的效果。
3.1 基础框架:教师-学生架构
DINOv2采用了经典的教师-学生(Teacher-Student)架构。简单来说,就是有两个一模一样的网络:
- 学生网络:正常训练,参数不断更新。
- 教师网络 :参数是学生网络参数的指数移动平均(EMA)。也就是说,教师网络的参数更新得很慢,就像一个经验丰富的老师,总是比学生更稳定、更准确。
训练的目标就是让学生网络的输出尽可能接近教师网络的输出。这种架构的好处是,教师网络能提供更稳定的监督信号,避免学生网络在训练过程中"跑偏"。
3.2 图像级损失:DINO损失
DINO损失是在图像层面的对比损失,它让同一图片的不同视角(裁剪、翻转等)在特征空间中尽可能接近,不同图片的特征尽可能远离。
LDINO=−∑ptlogps\mathcal{L}_{DINO} = -\sum p_t \log p_sLDINO=−∑ptlogps
- LDINO\mathcal{L}_{DINO}LDINO:DINO损失函数值,越小表示学生和教师的输出越接近
- ptp_tpt:教师网络对输入图片的预测概率分布
- psp_sps:学生网络对同一图片不同视角的预测概率分布
通俗解释:这就像是老师给学生看同一道题的不同解法,让学生学会不管题目怎么变,都能得到正确的答案。
3.3 补丁级损失:iBOT损失
只有图像级的损失还不够,因为很多下游任务(比如分割、深度估计)需要像素级的特征。DINOv2加入了iBOT损失,在补丁(patch)层面进行监督。
iBOT损失的思想和DINO类似,但有一个关键区别:学生网络的输入会随机mask掉一些补丁,而教师网络的输入是完整的。训练目标是让学生网络预测出被mask掉的补丁的特征。
LiBOT=−∑iptilogpsi\mathcal{L}{iBOT} = -\sum{i} p_{ti} \log p_{si}LiBOT=−i∑ptilogpsi
- LiBOT\mathcal{L}_{iBOT}LiBOT:iBOT损失函数值
- ptip_{ti}pti:教师网络对第iii个补丁的预测概率分布
- psip_{si}psi:学生网络对被mask掉的第iii个补丁的预测概率分布
通俗解释:这就像是老师给学生看一幅画,然后遮住一部分,让学生猜遮住的地方是什么。通过这种方式,模型能学会理解图片的局部结构和上下文关系。
3.4 正则化神器:KoLeo损失
为了让学到的特征在空间中均匀分布,避免很多特征挤在一起,DINOv2加入了KoLeo正则化。
Lkoleo=−1n∑i=1nlog(dn,i)\mathcal{L}{koleo} = -\frac{1}{n} \sum{i=1}^{n} \log \left(d_{n,i}\right)Lkoleo=−n1i=1∑nlog(dn,i)
- Lkoleo\mathcal{L}_{koleo}Lkoleo:KoLeo正则化损失值
- nnn:一个batch中的样本数量
- dn,id_{n,i}dn,i:第iii个样本和batch中其他所有样本的最小欧氏距离
通俗解释:这就像是老师把学生均匀地安排在教室里,避免大家都挤在一个角落。这样每个学生(特征)都有自己独特的位置,能提供独特的信息。
3.5 其他关键技巧
- Sinkhorn-Knopp中心化:替代了原来的简单中心化,让教师网络的输出分布更均匀,训练更稳定。
- 高分辨率微调:在训练的最后阶段,把图片分辨率从224×224提高到518×518,再训练1万步。这样能显著提升密集任务的性能,而计算成本只增加了一点点。
四、让11亿参数模型跑起来的工程魔法
训练一个11亿参数的ViT模型,即使在A100上也是一个巨大的挑战。Meta的工程师们用了一系列工程优化,让DINOv2的训练速度比iBOT快了2倍,内存只用了1/3。
4.1 核心优化技术
- FlashAttention:重新实现了FlashAttention,大幅提升了自注意力层的速度和内存效率。
- 序列打包:把不同长度的token序列(来自不同大小的图片裁剪)打包成一个长序列,一次性输入Transformer。这避免了多次前向传播,提升了GPU利用率。
- 高效随机深度:改进了随机深度的实现,直接跳过被丢弃的残差块的计算,而不是计算后再mask掉。
- FSDP(Fully-Sharded Data Parallel):把模型参数、优化器状态都分片到不同的GPU上,让单GPU的内存需求从16GB降到了几GB。
4.2 核心代码:序列打包的简单实现
python
import torch
import torch.nn as nn
from xformers.ops import memory_efficient_attention
def sequence_packing(images, crops_sizes):
"""
将不同大小的图片裁剪打包成一个长序列
Args:
images: 不同大小的图片裁剪列表
crops_sizes: 每个裁剪的大小 [(h1, w1), (h2, w2), ...]
Returns:
packed_tokens: 打包后的token序列
attention_mask: 块对角注意力掩码
"""
tokens_list = []
attention_mask = torch.zeros((1, 0, 0), dtype=torch.bool)
for img, (h, w) in zip(images, crops_sizes):
# 将图片转换为patch tokens
tokens = patch_embed(img) # [1, num_patches, embed_dim]
num_patches = h // patch_size * w // patch_size
# 更新注意力掩码
new_mask = torch.ones((1, num_patches, num_patches), dtype=torch.bool)
attention_mask = torch.block_diag(attention_mask, new_mask)
tokens_list.append(tokens)
# 打包所有tokens
packed_tokens = torch.cat(tokens_list, dim=1)
return packed_tokens, attention_mask五、用数据说话------每个组件都在发光
DINOv2的作者们做了非常详尽的消融实验,证明了每个组件的贡献。我们来看最关键的一个实验:从iBOT到DINOv2的逐步改进。
| 方法 | ImageNet-1k k-NN | ImageNet-1k linear |
|---|---|---|
| iBOT | 72.9 | 82.3 |
| +我们的复现 | 74.5 (+1.6) | 83.2 (+0.9) |
| +LayerScale, Stochastic Depth | 75.4 (+0.9) | 82.0 (-1.2) |
| +128k prototypes | 76.6 (+1.2) | 81.9 (-0.1) |
| +KoLeo | 78.9 (+2.3) | 82.5 (+0.6) |
| +SwiGLU FFN | 78.7 (-0.2) | 83.1 (+0.6) |
| +Patch size 14 | 78.9 (+0.2) | 83.5 (+0.4) |
| +Teacher momentum 0.994 | 79.4 (+0.5) | 83.6 (+0.1) |
| +Tweak warmup schedules | 80.5 (+1.1) | 83.8 (+0.2) |
| +Batch size 3k | 81.7 (+1.2) | 84.7 (+0.9) |
| +Sinkhorn-Knopp | 81.7 (=) | 84.7 (=) |
| +Untying heads = DINOv2 | 82.0 (+0.3) | 84.5 (-0.2) |
表2:从iBOT到DINOv2的逐步改进(出处:原文Table 1)
从表中可以看到,每个组件都带来了稳定的提升。其中贡献最大的是:
- KoLeo正则化:k-NN准确率提升了2.3%
- 增大batch size到3k:线性准确率提升了0.9%
- 把patch size从16改成14:线性准确率提升了0.4%
我们再来看KoLeo和iBOT损失分别对什么任务有帮助:
| KoLeo | ImageNet-1k | ImageNet-A | ADE-20k | Oxford-M |
|---|---|---|---|---|
| ✗ | 85.3 | 70.6 | 47.2 | 55.6 |
| ✓ | 85.8 | 72.8 | 47.1 | 63.9 |
表3:KoLeo损失的影响(出处:原文Table 3a)
| MIM (iBOT) | ImageNet-1k | ImageNet-A | ADE-20k | Oxford-M |
|---|---|---|---|---|
| ✗ | 85.3 | 72.0 | 44.2 | 64.3 |
| ✓ | 85.8 | 72.8 | 47.1 | 63.9 |
表4:iBOT损失的影响(出处:原文Table 3b)
结论非常清晰:
- KoLeo损失:对图像检索任务(Oxford-M)帮助最大,mAP提升了8.3%。因为它让特征在空间中分布更均匀,检索更准确。
- iBOT损失:对密集预测任务(ADE-20k分割)帮助最大,mIoU提升了2.9%。因为它让模型学到了更好的patch级特征。
六、横扫所有视觉任务的通用特征
DINOv2在几乎所有视觉任务上都取得了SOTA的结果,而且都是用冻结的特征+线性分类器得到的,不需要微调。这才是"通用特征"的真正含义。
6.1 整体性能概览
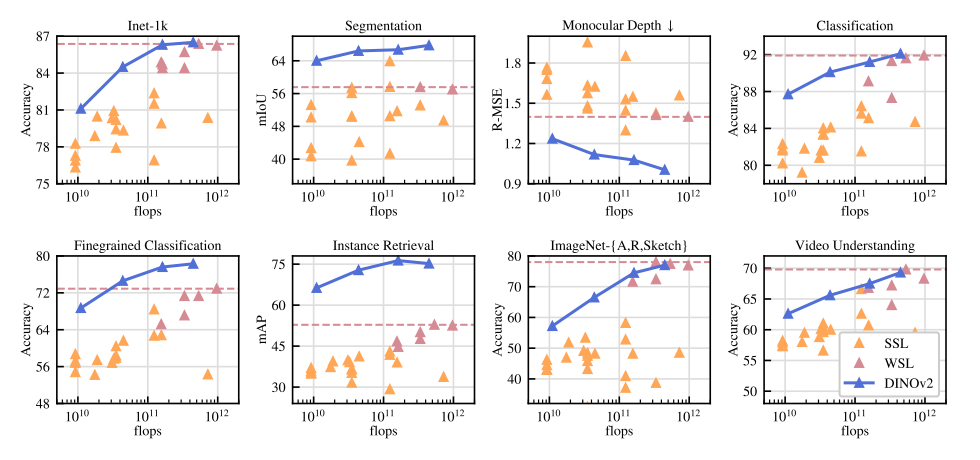
图2:不同任务上的性能随模型大小的变化(出处:原文Figure 2)
从图中可以看到,随着模型大小的增加,DINOv2的性能在所有任务上都稳步提升。而且在大多数任务上,DINOv2都超过了之前的自监督方法,和弱监督的OpenCLIP相当。
6.2 图像分类:和CLIP平起平坐
| 方法 | 监督类型 | ImageNet-1k linear | ImageNet-V2 |
|---|---|---|---|
| OpenCLIP-G | 弱监督 | 86.2 | 77.2 |
| EVA-CLIP-g | 弱监督 | 86.4 | 77.4 |
| DINOv2-g | 自监督 | 86.5 | 78.4 |
表5:ImageNet上的线性评估结果(出处:原文Table 4)
DINOv2-g的线性准确率达到了86.5%,超过了OpenCLIP-G和EVA-CLIP-g。更重要的是,在分布外的ImageNet-V2上,DINOv2的优势更大,领先EVA-CLIP-g 1.0%。这说明DINOv2的泛化能力更强。
6.3 密集任务:全面碾压CLIP
在语义分割和深度估计这些密集任务上,DINOv2的优势更加明显。这是因为CLIP是用图文对训练的,文本描述很难包含像素级的细节信息,而自监督的DINOv2能直接从图片中学到这些信息。
| 方法 | ADE-20k mIoU | CityScapes mIoU | NYUd RMSE |
|---|---|---|---|
| OpenCLIP-G | 39.3 | 60.3 | 0.541 |
| iBOT-L | 44.6 | 64.8 | 0.417 |
| DINOv2-g | 49.0 | 71.3 | 0.344 |
表6:密集任务性能对比(出处:原文Table 10、11)
我们再来看定性的结果:

图3:分割和深度估计的定性结果对比(出处:原文Figure 7)
从图中可以清楚地看到:
- OpenCLIP-G的分割结果有很多 artifacts,边缘模糊,很多小物体都识别不出来。
- DINOv2-g的分割结果边缘清晰,物体完整,深度估计也更平滑、更准确。
七、DINOv2的"超能力"------那些意想不到的性质
DINOv2学到的特征不仅在标准任务上表现好,还展现出了一些非常神奇的"涌现性质",这些性质是模型自动学到的,没有任何监督。
7.1 PCA自动分割前景背景

图4:patch特征的PCA可视化(出处:原文Figure 1)
如果我们对DINOv2输出的patch特征做PCA,会发现一个惊人的现象:第一个主成分就能自动把前景和背景分开!而且其他主成分对应物体的不同部分,比如鸟的头、翅膀、身体。
更神奇的是,这种对应关系在不同的图片之间是一致的。比如,所有鸟的翅膀在特征空间中都对应同一个主成分,所有飞机的翅膀也对应同一个主成分。
7.2 跨物体的patch匹配

图5:跨图片的patch匹配(出处:原文Figure 10)
如果我们计算不同图片之间patch特征的相似度,会发现DINOv2能自动匹配语义上相似的部分,即使它们来自完全不同的物体。比如:
- 鸟的翅膀 ↔ 飞机的翅膀
- 大象的腿 ↔ 桌子的腿
- 汽车的轮子 ↔ 自行车的轮子
这说明DINOv2学到了真正的语义概念,而不仅仅是像素的统计规律。这种能力对于VLA模型来说至关重要,因为机器人需要理解不同物体之间的相似性,才能把在一个物体上学到的技能迁移到另一个物体上。
八、不完美的DINOv2------公平性与环境影响
DINOv2虽然很强大,但也不是完美的。作者们在论文中专门用了两个章节讨论它的局限性,这是非常值得称赞的。
8.1 地理和收入偏见
DINOv2在不同地区和收入水平的图片上表现差异很大:
- 在欧洲的图片上准确率是89.7%,在非洲只有74.0%,差了15.7%。
- 在高收入家庭的图片上准确率是90.5%,在低收入家庭只有67.4%,差了23.1%。
这是因为训练数据中西方和高收入地区的图片占比过高。未来的工作需要构建更多样化的数据集,来解决这个问题。
8.2 环境影响
训练一个DINOv2-g模型需要22016个A100 GPU小时,大约排放3.7吨二氧化碳。这相当于一辆普通汽车行驶1.5万公里的排放量。不过,和训练同样大小的CLIP模型相比,DINOv2的碳排放量要低得多,因为它不需要训练文本编码器。
九、为什么DINOv2是VLA的最佳视觉编码器?
现在我们终于明白,为什么所有的VLA模型都选择DINOv2作为视觉编码器了:
- 通用特征:不需要微调,就能在各种场景和物体上提取高质量的特征。这对于VLA来说至关重要,因为机器人需要在未知的环境中操作未知的物体。
- 鲁棒性强:对光照、视角、遮挡的变化非常鲁棒。真实世界的环境是复杂多变的,机器人的视觉系统必须能应对这些变化。
- 密集特征好:在分割、深度估计这些密集任务上表现优异。机器人需要理解场景的3D结构,才能准确地抓取和操作物体。
- 开源免费:Meta完全开源了所有的模型和代码,任何人都可以免费使用。这极大地推动了VLA领域的发展。
十、动手实践------5行代码用DINOv2提取特征
最后,我们来写几行代码,体验一下DINOv2的强大。用Hugging Face的Transformers库,只需要5行代码就能提取特征:
python
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import torch
# 加载模型和处理器
processor = AutoImageProcessor.from_pretrained("facebook/dinov2-giant")
model = AutoModel.from_pretrained("facebook/dinov2-giant")
# 加载图片
image = Image.open("robot.jpg")
# 预处理图片
inputs = processor(images=image, return_tensors="pt")
# 提取特征
with torch.no_grad():
outputs = model(**inputs)
features = outputs.last_hidden_state # [1, num_patches+1, 1536]
# 得到全局特征(CLS token)
global_feature = features[:, 0, :] # [1, 1536]
# 得到patch级特征
patch_features = features[:, 1:, :] # [1, 1369, 1536]就是这么简单!你可以用这些特征来做图像检索、分类、分割,或者作为VLA模型的视觉输入。
总结
DINOv2是计算机视觉领域的一个里程碑式的工作。它证明了自监督学习完全可以学到和弱监督方法相当的通用视觉特征,为视觉基础模型的发展指明了方向。对于VLA领域来说,DINOv2就像是给机器人装上了一双"慧眼",让它们能真正理解这个复杂的物理世界。
未来,随着模型更大、数据更多、方法更好,我们相信自监督视觉模型会变得越来越强大,最终实现真正的通用视觉智能。而DINOv2,就是这条道路上最重要的一步。