1.YOLO
1.1 简介
YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位的回归问题结合起来,从而做到了高效、灵活和泛化性能好,所以在工业界也十分受欢迎.
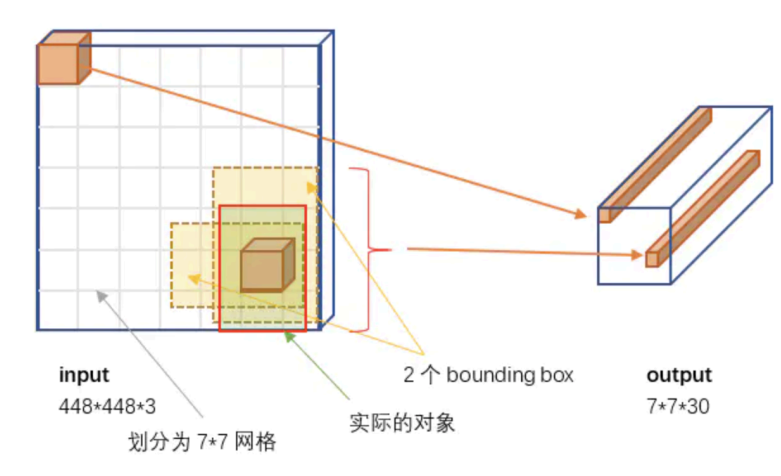
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别,整个系统如下图所示:

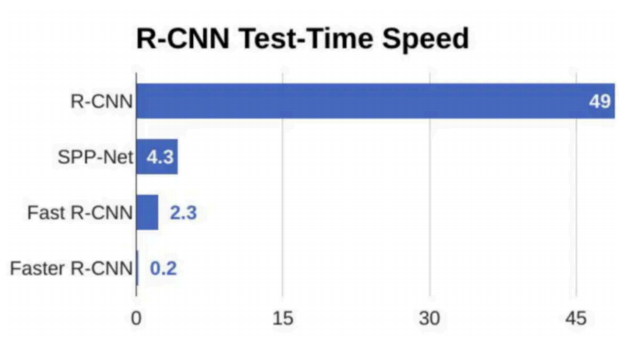
首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快。
在介绍Yolo算法之前,我们回忆下RCNN模型,RCNN模型提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右,然后对每个候选区进行对象识别,但处理速度较慢。
Yolo意思是You Only Look Once,它并没有真正的去掉候选区域,而是创造性的将候选区和目标分类合二为一,看一眼图片就能知道有哪些对象以及它们的位置。
Yolo模型采用预定义预测区域的方法来完成目标检测,具体而言是将原始图像划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共49x2=98 个bounding box。我们将其理解为98个预测区,很粗略的覆盖了图片的整个区域,就在这98个预测区中进行目标检测。

1.2 YOLO的网络结构
YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接,从网络结构上看,与前面介绍的CNN分类网络没有本质的区别,最大的差异是输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示:
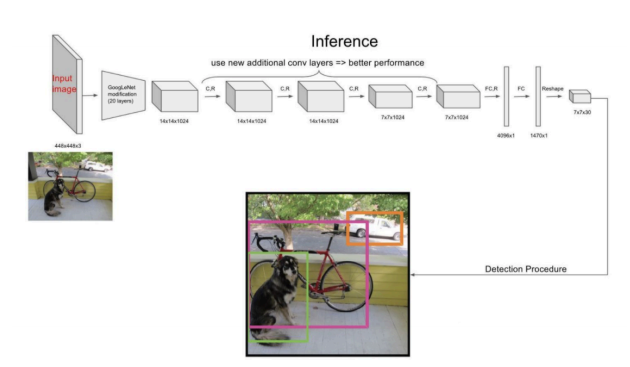
网络结构比较简单,重点是我们要理解网络输入与输出之间的关系。
网络输入
网络的输入是原始图像,唯一的要求是缩放到448x448的大小。主要是因为Yolo的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以Yolo的输入图像的大小固定为448x448。
网络输出
网络的输出就是一个7x7x30 的张量(tensor)。
根据YOLO的设计,输入图像被划分为 7x7 的网格(grid),输出张量中的 7x7 就对应着输入图 像的 7x7 网格。或者我们把 7x7x30 的张量看作 7x7=49个30维的向量,也就是输入图像中的每 个网格对应输出一个30维的向量。如下图所示,比如输入图像左上角的网格对应到输出张量中左 上角的向量。
30维的向量包含:2个bbox的位置和置信度以及该网格属于20个类别的概率
1.3 YOLO的训练
在进行模型训练时,我们需要构造训练样本和设计损失函数,才能利用梯度下降对网络进行训练。
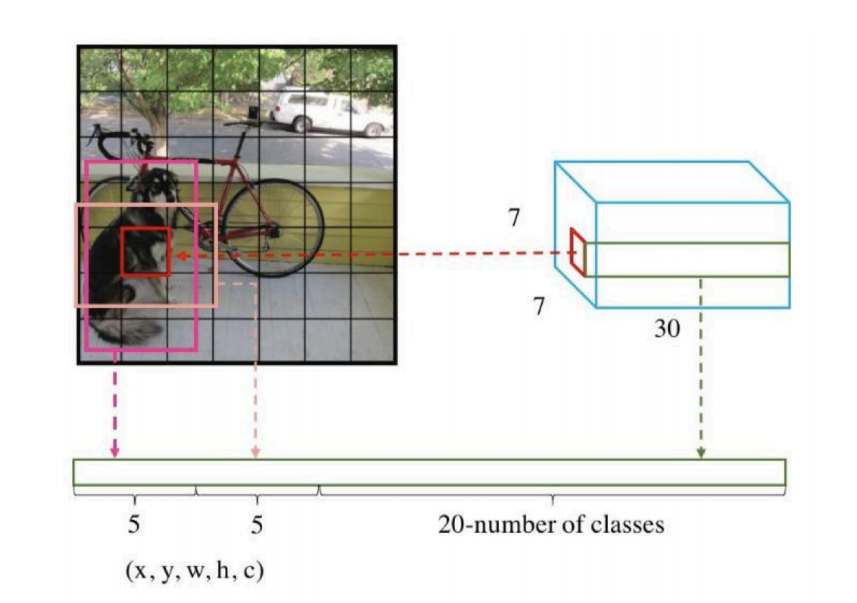
将一幅图片输入到yolo模型中,对应的输出是一个7x7x30张量,构建标签label时对于原图像中 的每一个网格grid都需要构建一个30维的量。对照下图我们来构建目标向量:

20个对象分类的概率
对于输入图像中的每个对象,先找到其中心点。比如上图中自行车,其中心点在黄色圆点位置, 中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率是1,其它对象的 概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在 的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写
2个bounding box的位置
训练样本的bbox位置应该填写对象真实的位置bbox,但一个对象对应了2个bounding box,该填 哪一个呢?需要根据网络输出的bbox与对象实际bbox的IOU来选择,所以要在训练过程中动态决 定到底填哪一个bbox。
1.4 总结
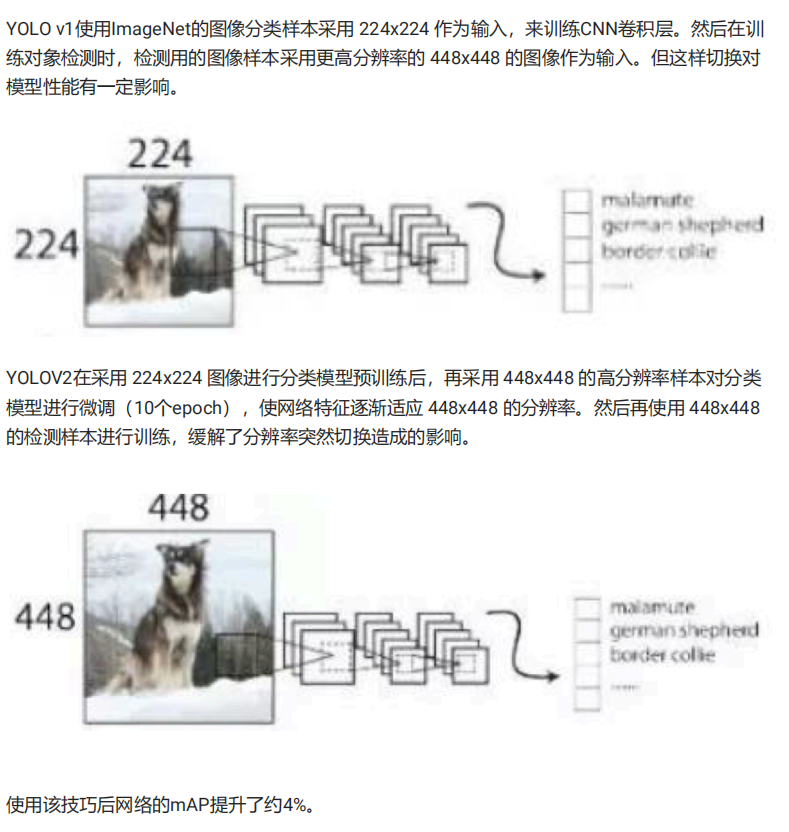
Yolo先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练。 Yolo的最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了drop out和数据增强 (data augmentation)来防止过拟合。
将图片resize成448x448的大小,送入到yolo网络中,输出一个 7x7x30 的张量(tensor)来表示 图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度 (置信度)。在采用NMS(Non-maximal suppression,非极大值抑制)算法选出最有可能是目 标的结果。
优点
- 速度非常快,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps
- 训练和预测可以端到端的进行,非常简便
缺点
- 准确率会打折扣
- 对于小目标和靠的很近的目标检测效果并不好
1.5 YOLO V2
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快 (Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展 到能够检测9000种不同对象,称之为YOLO9000。 下面我们看下yoloV2的都做了哪些改进?
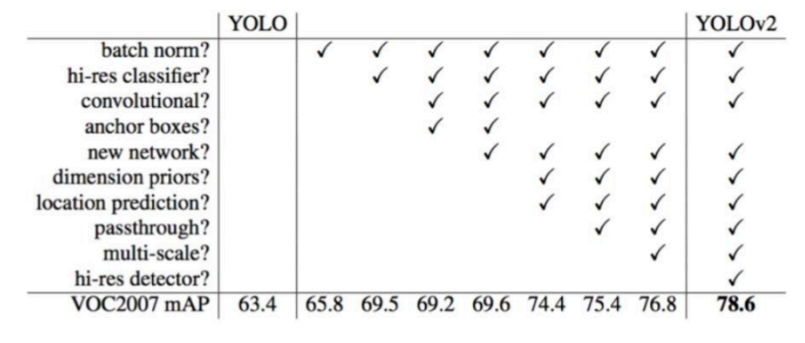
批标准化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数的敏感性, 并且每个batch分别进行归一化的时候,起到了一定的正则化效果,从而能够获得更好的收敛速度和收敛效果。在yoloV2中卷积后全部加入Batch Normalization,网络会提升2%的mAP。
YOLO1并没有采用先验框,并且每个grid只预测两个bounding box,整个图像98个。YOLO2如果 每个grid采用5个先验框,总共有13x13x5=845个先验框。通过引入anchor boxes,使得预测的 box数量更多(13x13xn)。
图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中,较小的对象可 能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需 要保留一些更细节的信息。 YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最 后一个pooling之前,特征图的大小是26x26x512,将其1拆4,直接传递(passthrough)到 pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。
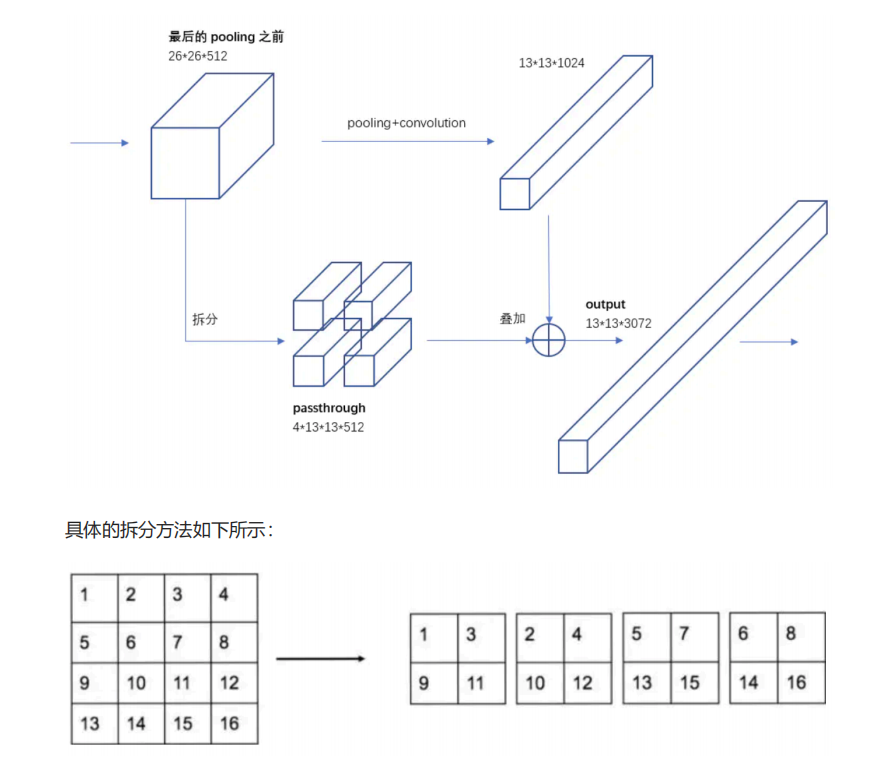
多尺度训练
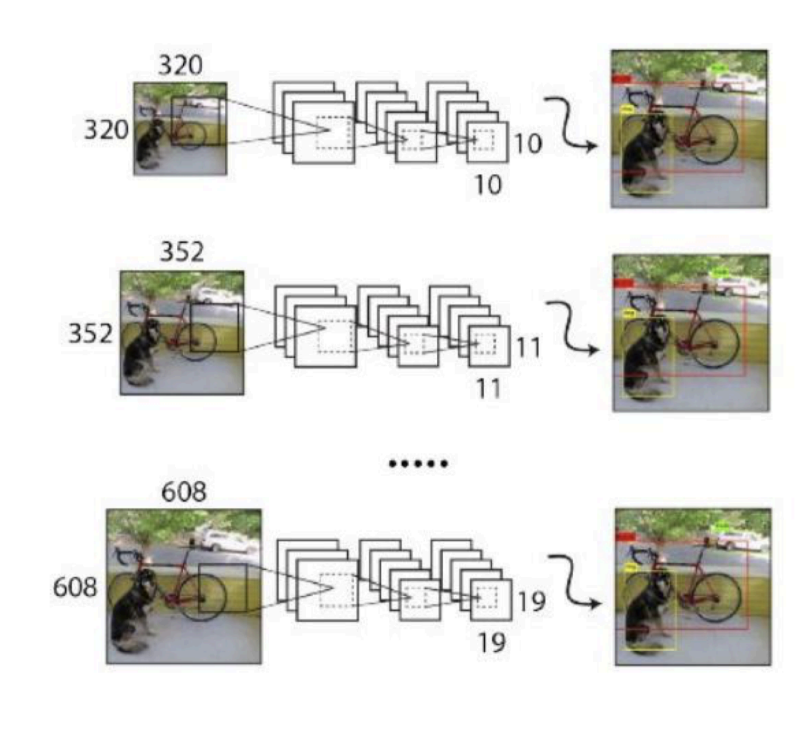
YOLO2中没有全连接层,可以输入任何尺寸的图像。因为整个网络下采样倍数是32,采用了 {320,352,...,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是 {10,11,...19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
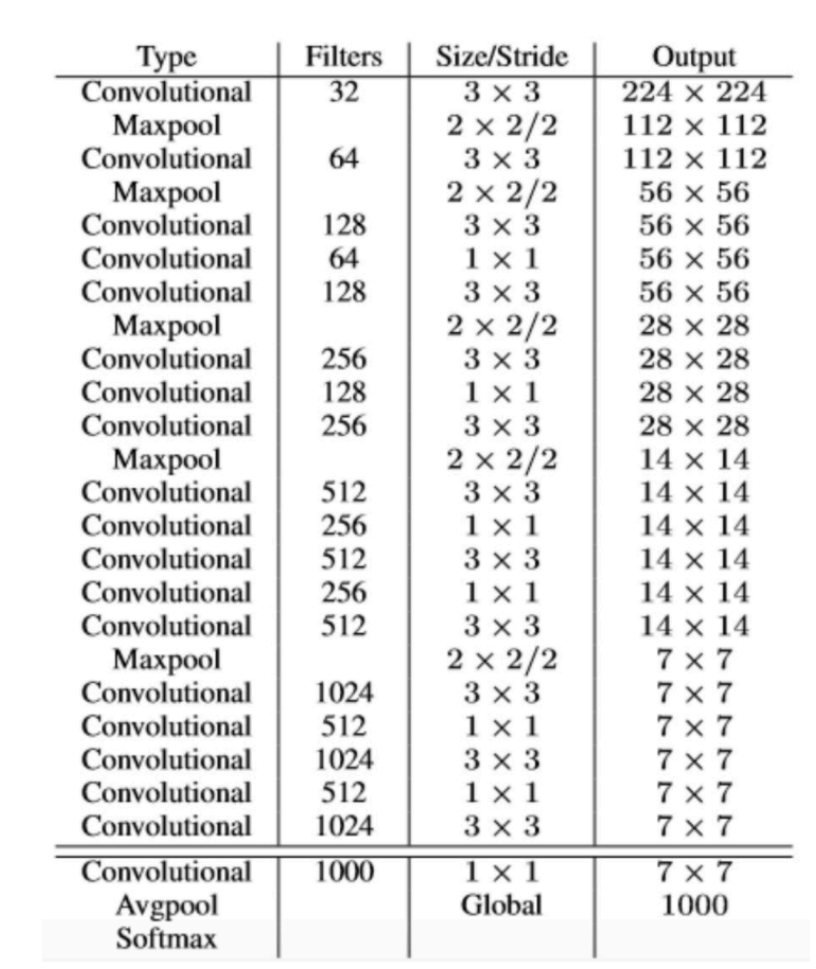
yoloV2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构作为特征提取网络。 DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约⅕,以保证更快的运 算速度。
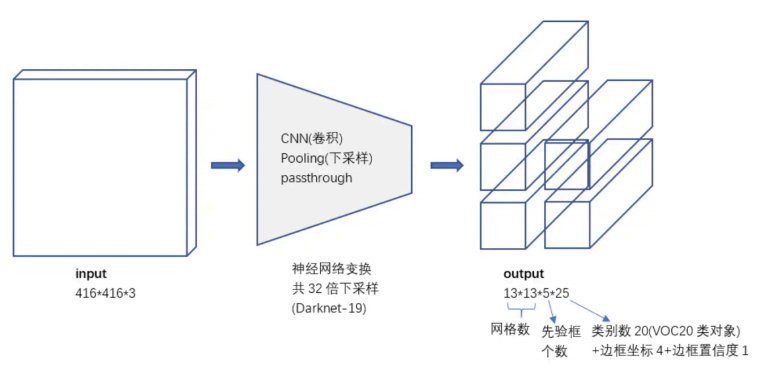
yoloV2的网络中只有卷积+pooling,从416x416x3 变换到 13x13x5x25。增加了batch
normalization,增加了一个passthrough层,去掉了全连接层,以及采用了5个先验框,网络的输 出如下图所示:
VOC数据集可以检测20种对象,但实际上对象的种类非常多,只是缺少相应的用于对象检测的训 练样本。YOLO2尝试利用ImageNet非常大量的分类样本,联合COCO的对象检测数据集一起训 练,使得YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。
1.6 YOLO V3
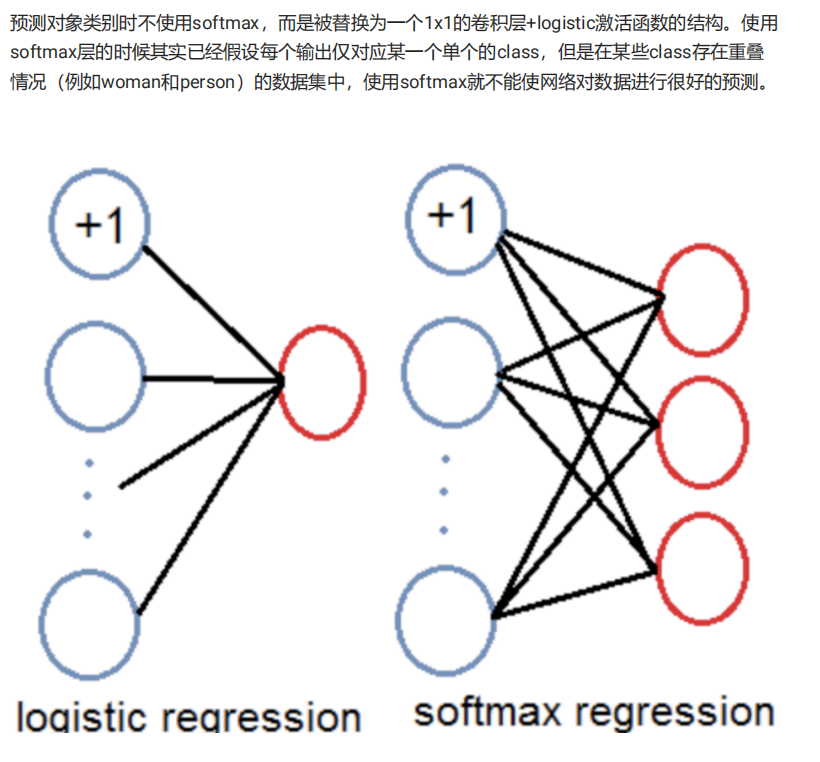
yoloV3以V1,V2为基础进行的改进,主要有:利用多尺度特征进行目标检测;先验框更丰富; 调整了网络结构;对象分类使用logistic代替了softmax,更适用于多标签分类任务。
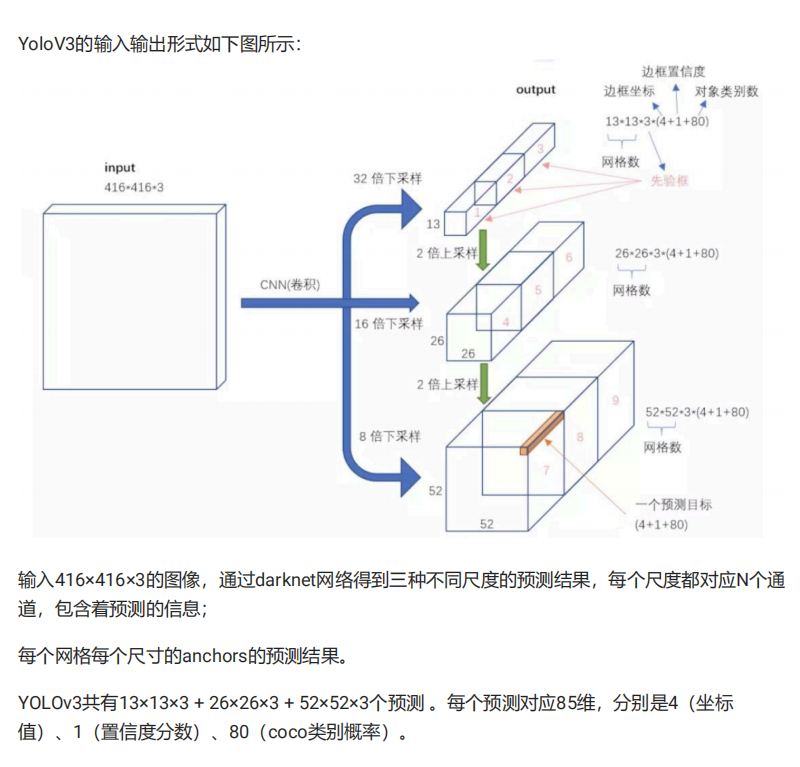
yoloV3的流程如下图所示,对于每一幅输入图像,YOLOv3会预测三个不同尺度的输出,目的是 检测出不同大小的目标。
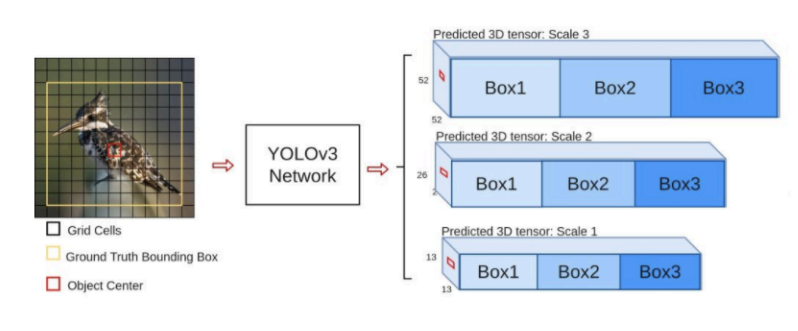
多尺度检测
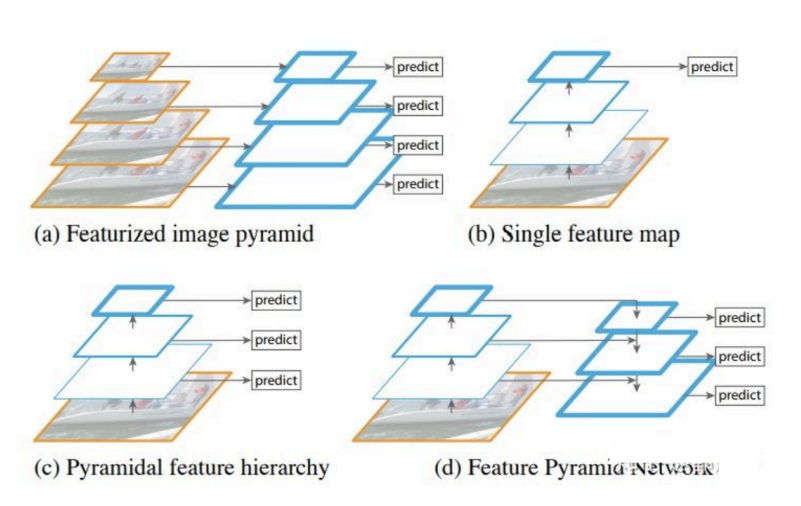
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体 同时检测出来。因此,网络必须具备能够"看到"不同大小的物体的能力。因为网络越深,特征图 就会越小,所以网络越深小的物体也就越难检测出来。 在实际的feature map中,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物 体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信 息:狗,猫,汽车等等)。因此在不同级别的feature map对应不同的scale,所以我们可以在不 同级别的特征图中进行目标检测。如下图展示了多种scale变换的经典方法。

网络模型结构
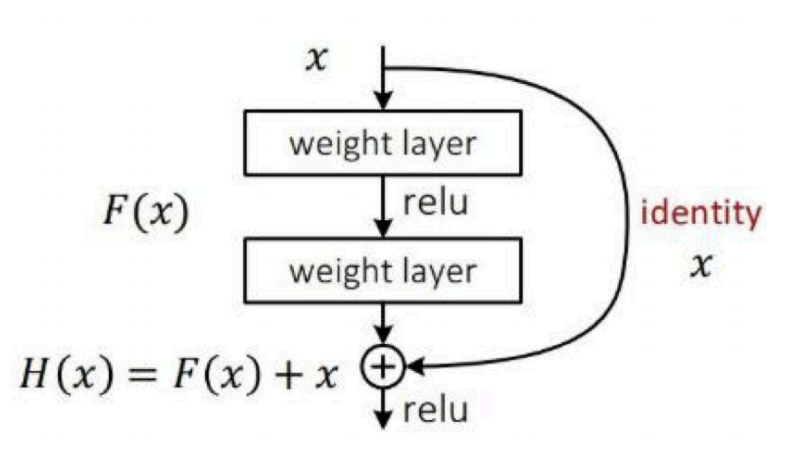
在基本的图像特征提取方面,YOLO3采用了Darknet-53的网络结构(含有53个卷积层),它借鉴 了残差网络ResNet的做法,在层之间设置了shortcut,来解决深层网络梯度的问题,shortcut如 下图所示:包含两个卷积层和一个shortcut connections。
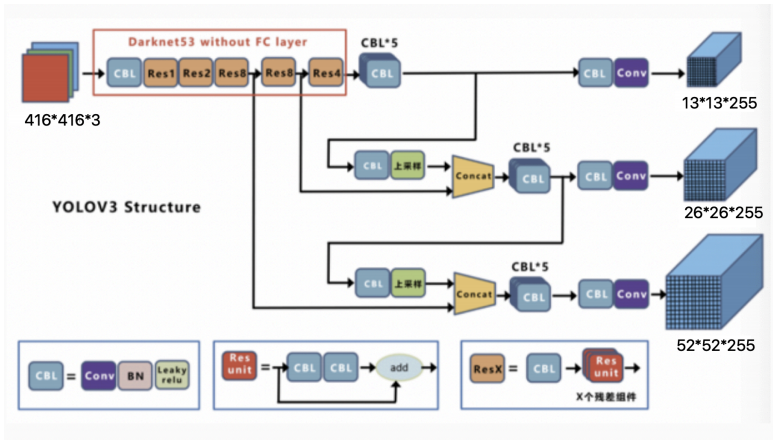
yoloV3的模型结构如下所示:整个v3结构里面,没有池化层和全连接层,网络的下采样是通过设 置卷积的stride为2来达到的,每当通过这个卷积层之后图像的尺寸就会减小到一半。


先验框

** logistic回归**
yoloV3模型的输入与输出
2.卡尔曼滤波
卡尔曼滤波(Kalman)⽆论是在单⽬标还是多⽬标领域都是很常⽤的⼀种算法, 我们将卡尔曼滤波看做⼀种运动模型,⽤来对⽬标的位置进⾏预测,并且利⽤预测 结果对跟踪的⽬标进⾏修正,属于⾃动控制理论中的⼀种⽅法。
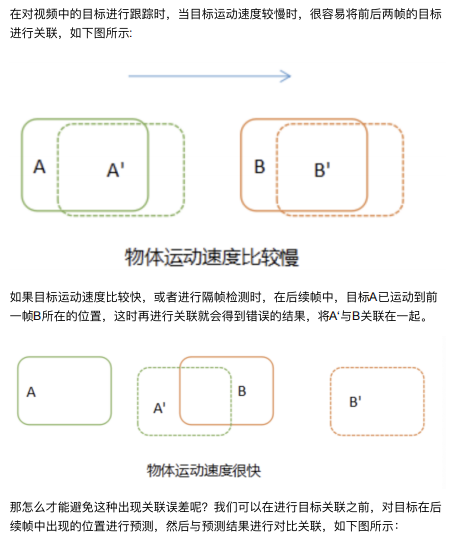
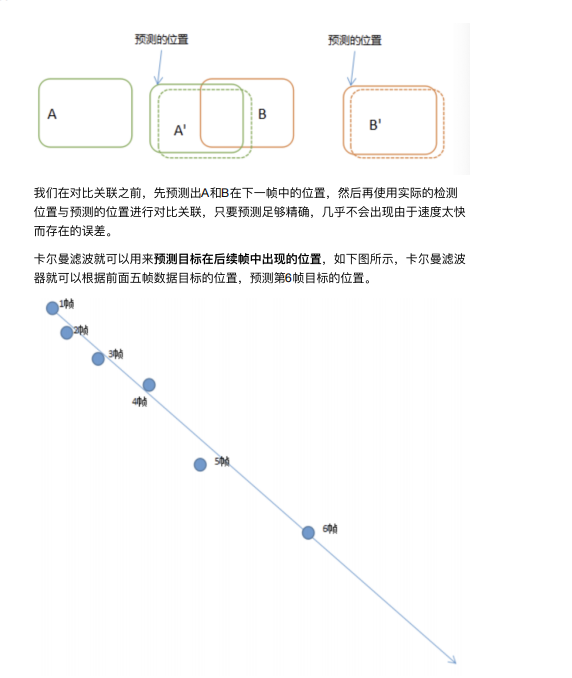
卡尔曼滤波器最⼤的优点是采⽤递归的⽅法来解决线性滤波的问题,它只需要当前 的测量值和前⼀个周期的预测值就能够进⾏状态估计。由于这种递归⽅法不需要⼤ 量的存储空间,每⼀步的计算量⼩,计算步骤清晰,⾮常适合计算机处理,因此卡 尔曼滤波受到了普遍的欢迎,在各种领域具有⼴泛的应⽤前景。
3.匈牙利算法
匈⽛利算法(Hungarian Algorithm)与KM算法(Kuhn-Munkres Algorithm)是⽤ 来解决多⽬标跟踪中的数据关联问题,匈⽛利算法与KM算法都是为了求解⼆分图 的最⼤匹配问题。
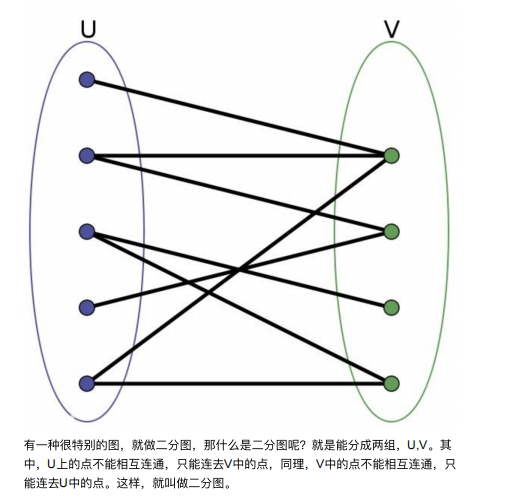
可以把⼆分图理解为视频中连续两帧中的所有检测框,第⼀帧所有检测框的集合称 为U,第⼆帧所有检测框的集合称为V。同⼀帧的不同检测框不会为同⼀个⽬标, 所以不需要互相关联,相邻两帧的检测框需要相互联通,最终将相邻两帧的检测框 尽量完美地两两匹配起来。⽽求解这个问题的最优解就要⽤到匈⽛利算法或者KM算法。
匈⽛利算法是⼀种在多项式时间内求解任务分配问题的组合优化算法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈⽛利算法,是因为算法 很⼤⼀部分是基于以前匈⽛利数学家Dénes Kőnig和Jenő Egerváry的⼯作之上创建 起来的。
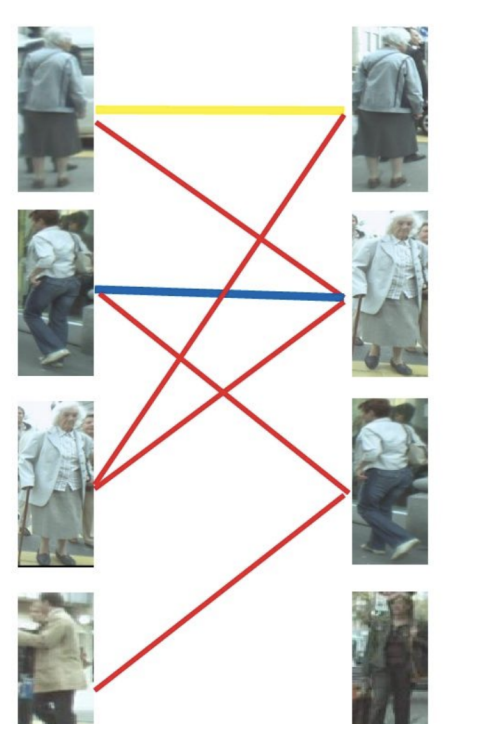
我们以⽬标跟踪的⽅法介绍匈⽛利算法,以下图为例,假设左边的四张图是我们在 第N帧检测到的⽬标(U),右边四张图是我们在第N+1帧检测到的⽬标(V)。红 线连起来的图,是我们的算法认为是同⼀⾏⼈可能性较⼤的⽬标。由于算法并不是 绝对理想的,因此并不⼀定会保证每张图都有⼀对⼀的匹配,⼀对⼆甚⾄⼀对多, 再甚⾄多对多的情况都时有发⽣。这时我们怎么获得最终的⼀对⼀跟踪结果呢?我 们来看匈⽛利算法是怎么做的。

-
⾸先给左1进⾏匹配,发现第⼀个与其相连的右1还未匹配,将其配对,连上⼀条蓝线。

-
接着匹配左2,发现与其相连的第⼀个⽬标右2还未匹配,将其配对

-
接下来是左3,发现最优先的⽬标右1已经匹配完成了,怎么办呢? 我们给之前右1的匹配对象左1分配另⼀个对象。(⻩⾊表示这条边被临时拆掉)
可以与左1匹配的第⼆个⽬标是右2,但右2也已经有了匹配对象,怎么办呢? 我们再给之前右2的匹配对象左2分配另⼀个对象(注意这个步骤和上⾯是⼀样的, 这是⼀个递归的过程)。

此时发现左2还能匹配右3,那么之前的问题迎刃⽽解了,回溯回去。 左2对右3,左1对右2,左3对右1
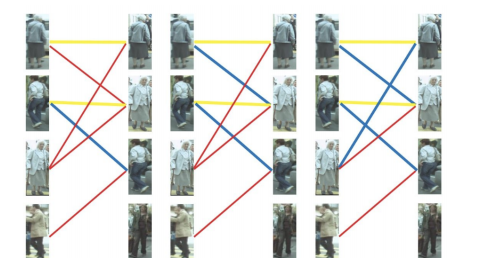
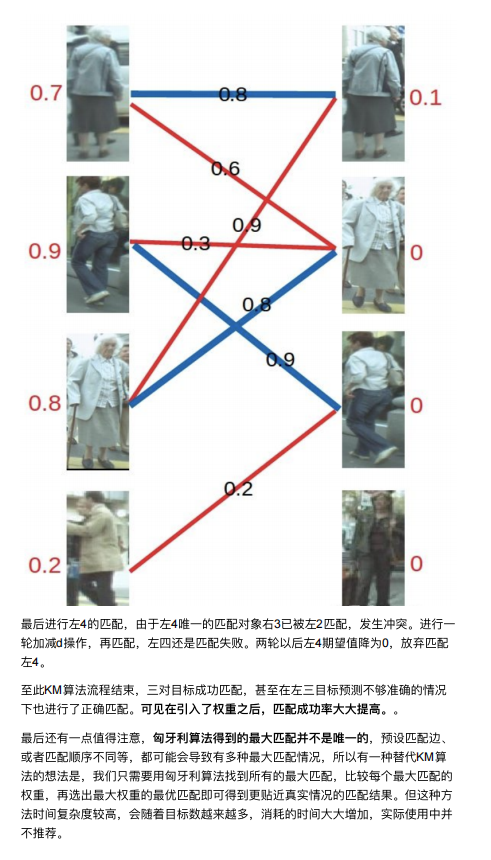
- 最后是左4,很遗憾,按照第三步的节奏我们没法给左4腾出来⼀个匹配对象,只能 放弃对左4的匹配,匈⽛利算法流程⾄此结束。蓝线就是我们最后的匹配结果
⾄此我们找到了这个⼆分图的⼀个最⼤匹配。最终的结果是我们匹配出了三对⽬标, 由于候选的匹配⽬标中包含了许多错误的匹配红线(边),所以匹配准确率并不 ⾼。可⻅匈⽛利算法对红线连接的准确率要求很⾼,也就是要求我们运动模型、外 观模型等部件必须进⾏较为精准的预测,或者预设较⾼的阈值,只将置信度较⾼的 边才送⼊匈⽛利算法进⾏匹配,这样才能得到较好的结果。
3.1 KM算法
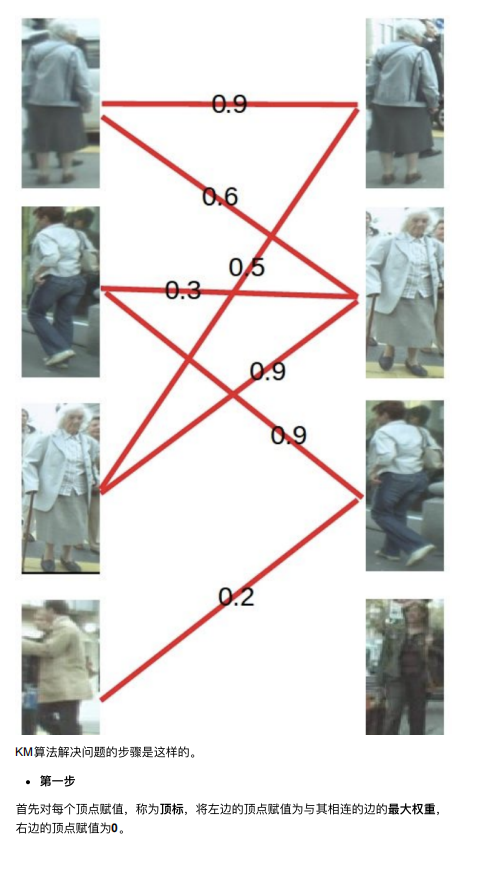
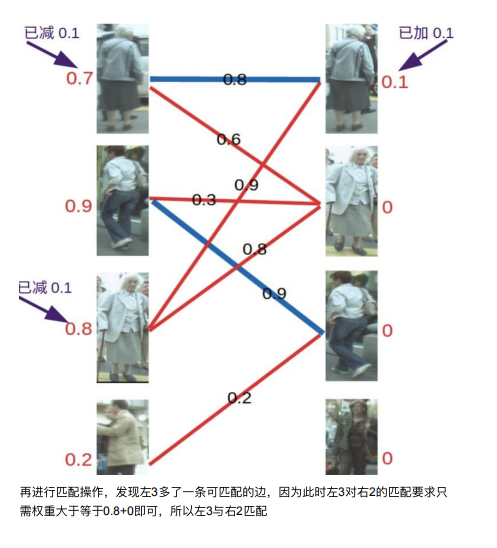
KM算法解决的是带权⼆分图的最优匹配问题。 还是⽤上⾯的图来举例⼦,这次给每条连接关系加⼊了权重,也就是我们算法中其 他模块给出的置信度分值。