探索Vite深入 Rollup 分块插件:从零实现一个智能分包工具
告别正则匹配的硬编码,用规则引擎优雅管理代码分割
引言
在 Rollup 打包配置中,manualChunks 是最强大也最容易被误用的选项之一。社区常见的做法是写一堆 if (id.includes('node_modules')) 或正则表达式,把第三方库一股脑打入 vendor 块。这种方案在项目初期看似简单,但随着迭代,很容易出现:
- chunk 体积失控:一个 vendor 文件动辄几 MB。
- 缓存失效频繁:任何依赖更新都会导致整个 vendor 重新下载。
- 代码复用不佳:被多个入口共享的公共模块无法独立拆分。
为了解决这些问题,我们开发了 rollup.plugin.robin-build 插件(纯 JS/TS 版本,下文简称"本插件")。它提供了一套声明式的分块规则配置,支持路径匹配、引用次数阈值、优先级排序等高级特性,让代码分割变得可预测、可维护。
插件概览
本插件导出两个主要部分:
output对象:标准的 Rollup 输出配置,定义了文件命名与分类规则。createSplitChunks函数 :接收用户配置,返回一个符合manualChunks签名(moduleId, { getModuleInfo }) => string | void的函数。
插件本身不依赖任何外部库,仅使用 Node.js 内置模块 path。其核心思路是:用户以对象形式定义多个"规则组",每个规则组包含匹配条件(路径字符串或正则)、目标 chunk 名称、优先级以及最小引用次数。插件在构建时遍历每个模块,按优先级匹配规则,决定模块归属的 chunk。
第一部分:输出配置(output)
typescript
export const output = {
entryFileNames: 'js/robin-[hash].js',
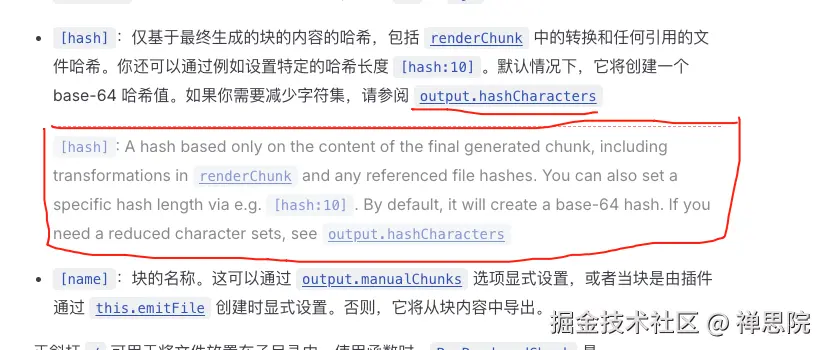
hashCharacters: 'hex', // 减少字符集,见下图1
experimentalMinChunkSize: 20 * 1024,
chunkFileNames: (chunkInfo) => {
if(chunkInfo.name && chunkInfo.name.startsWith('vendor-')){
return 'js/[name]-[hash].js'
}
return 'js/chunk-[hash].js'
},
assetFileNames: (info) => { ... }
}
1.1 entryFileNames 与 hash 配置
entryFileNames:入口 chunk 的文件名模板。这里使用app-[hash].js,并放入js/目录。hashCharacters: 'hex':指定 hash 编码方式为十六进制(Rollup 5.0+ 支持)。experimentalMinChunkSize:设置最小 chunk 大小(20KB),Rollup 会尝试合并小于此阈值的 chunk,减少 HTTP 请求数量。
1.2 chunkFileNames 动态命名
chunkFileNames 可以是函数,接收 chunkInfo 对象。插件判断如果 chunk 名称以 vendor- 开头(通常是通过规则生成的 vendor 块),则保留原名称,例如 vendor-react-[hash].js;否则统一命名为 chunk-[hash].js。
这样做的好处是:vendor 块名称可读性高,便于调试和 CDN 缓存策略区分。
1.3 assetFileNames 按扩展名分类
assetFileNames 根据文件扩展名将静态资源归类到不同子目录:
| 扩展名类型 | 输出目录 |
|---|---|
.css |
asset/css/ |
.wasm |
asset/wasm/ |
.json, .map |
asset/data/ |
.txt, .xml, .pdf |
asset/docs/ |
| 图片格式 | asset/img/ |
| 音视频格式 | asset/media/ |
| 字体格式 | asset/fonts/ |
| 其他 | asset/other/ |
这种细粒度分类对于大型项目尤其重要:运维可以针对不同资源类型设置不同的 CDN 缓存头(例如图片缓存一年,JSON 缓存五分钟)。
第二部分:核心分块引擎 createSplitChunks
createSplitChunks 是整个插件的灵魂。它接收一个配置对象,返回 manualChunks 函数。我们先看它的完整实现:
typescript
export const createSplitChunks = (config = {}) => {
if(!isObject(config)) return null
const list = []
Object.keys(config).forEach((key) => {
const test = config[`${key}`].test
if(!(isRegExp(test) || isString(test))) {
throw new Error('test 必须为正则表达式或字符串')
}
if (isString(test) && !path.isAbsolute(test)) {
throw new Error(`test 路径必须为绝对路径,实际获取到的是: ${test}`)
}
if (isRegExp(test) && test.global) {
throw new Error('正则表达式测试不得使用 /g 标志')
}
list.push({
...config[key],
chunk_name: `${key.startsWith('vendor') ? key : `vendor-${key}`}`,
type: isRegExp(test) ? 'regexp' : 'string'
})
})
list.sort((a, b) => (b.priority || 0) - (a.priority || 0))
return (disk_path, { getModuleInfo }) => {
const moduleInfo = getModuleInfo(disk_path)
const target = list.find(item=> {
if(item['minChunks'] && moduleInfo){
const static_count = moduleInfo['importers'] ? moduleInfo['importers'].length : 0
const dynamic_count = moduleInfo['dynamicImporters'] ? moduleInfo['dynamicImporters'].length : 0
const total = static_count + dynamic_count
if (total < item['minChunks']) return false
}
if(item.type === 'regexp') return item.test.test(disk_path)
return disk_path.startsWith(item.test)
})
if(target && isNull(target.name)) return null
if(target) return target.name || target.chunk_name
return null
}
}2.1 配置解析与校验
插件期望 config 是一个对象,其每个 key 代表一个规则组的名称,value 必须包含 test 字段(字符串绝对路径或正则表达式)。此外还可以包含:
name:自定义 chunk 名称(如果未提供,会自动生成vendor-${key})。priority:优先级(数字越大越先匹配)。minChunks:最小引用次数,只有模块被引用的总次数 ≥ 该值时才匹配。
首先进行严格的类型校验:
- 使用
toString.call来判断数据类型(因为typeof null === 'object',需要区分)。 - 对于字符串类型的
test,要求必须是绝对路径(通过path.isAbsolute验证)。这确保了匹配的确定性,避免相对路径在不同工作目录下产生歧义。 - 对于正则表达式,禁止使用
g全局标志,因为test方法在全局标志下会有状态残留,导致不可预期的行为。
2.2 构建规则列表与优先级排序
解析后的每个规则对象会被扩展两个内部字段:
chunk_name:自动生成的备用名称(如vendor-react)。type:标记匹配方式('regexp'或'string')。
然后将规则数组按 priority 降序排序。没有指定优先级的规则默认为 0。排序保证了高优先级规则先被匹配,避免低优先级规则"抢走"本应归属高优先级规则的模块。
2.3 manualChunks 回调逻辑
manualChunks 接收两个参数:disk_path(模块在磁盘上的绝对路径)和上下文对象 { getModuleInfo }。getModuleInfo 可以获取模块的依赖关系信息。
对于每个模块,插件会:
- 获取模块的引用信息 :
moduleInfo.importers(静态导入该模块的模块列表)和dynamicImporters(动态导入该模块的模块列表)。两者的长度之和就是该模块被其他模块引用的总次数total。 - 遍历规则列表 :按照优先级顺序查找第一个匹配的规则。
- 如果规则定义了
minChunks,则检查total >= minChunks,不满足则跳过该规则。 - 根据规则类型,用
test匹配disk_path。
- 如果规则定义了
- 决定 chunk 名称 :
- 如果匹配到的规则中
name字段为null,则返回null(表示不强制放入任何特定 chunk,由 Rollup 默认处理)。 - 否则返回
name或自动生成的chunk_name。
- 如果匹配到的规则中
- 未匹配任何规则则返回
null,让 Rollup 按照默认算法处理(通常是基于模块共享度自动拆分)。
2.4 设计亮点
优先级机制解决规则冲突
当多个规则都能匹配同一个模块时,优先级决定了最终归属。例如:
javascript
{
"vue-vendor": {
test: /[\\/]node_modules[\\/](vue|vue-router|vue-i18n)[\\/]/,
priority: 10
},
"node-vendor": {
test: /[\\/]node_modules[\\/]/,
priority: 0
}
}vue 、vue-i18n 、vue-router 会进入 vue-vendor 块,而其他 npm 包则进入 node-vendor。如果没有优先级,node-vendor 可能会先匹配,导致 Vue 也被打入通用 vendor。
minChunks 避免过度拆分
一个模块如果被很多地方引用(例如工具函数 debounce),独立成 chunk 是有益的;但如果只被一个入口使用,则应该合并到该入口的 chunk 中,减少 HTTP 请求。minChunks 参数允许开发者设置阈值,只有达到引用次数的模块才独立打包。
路径匹配的两种模式
- 字符串绝对路径 :适用于明确知道模块所在目录的场景,例如
'/app/shared/utils'。 - 正则表达式 :更灵活,可以匹配
node_modules中的特定包名,例如/node_modules\/lodash-es/。
自定义 chunk 名称与 null 返回值
允许规则返回 null 可以让某些模块"逃逸"出规则体系,由 Rollup 默认算法处理。这在使用第三方插件或有特殊分块需求时非常有用。
第三部分:类型判断辅助函数
插件开头定义了几个类型判断函数:没有引入loadsh-es,个人感觉没有必要,所以简化写一下
typescript
const toString = Object.prototype.toString
const isObject = (data) => toString.call(data) === '[object Object]'
const isNull = (data) => toString.call(data) === '[object Null]'
const isRegExp = (data) => toString.call(data) === '[object RegExp]'
const isString = (data) => toString.call(data) === '[object String]'为什么不直接用 typeof 或 instanceof?
typeof null === 'object',无法区分 null 和普通对象。- 在 Rollup 插件环境中,
moduleInfo等对象可能来自不同的上下文,instanceof可能失效。而Object.prototype.toString返回的是内部[[Class]]属性,跨框架可靠。
第四部分:使用示例
4.1 基础配置
javascript
// rollup.config.js
import { createSplitChunks, output } from 'rollup-plugin-robin-build';
export default {
input: 'src/main.js',
output: {
dir: 'dist',
...output,
manualChunks: createSplitChunks({
// 规则1:vue 全家桶单独打包
vue: {
test: /[\\/]node_modules[\\/](vue|vue-router|vue-i18n)[\\/]/,
priority: 10,
minChunks: 1
},
// 规则2:antd 组件库单独打包
antd: {
test: /[\\/]node_modules[\\/]antd[\\/]/,
priority: 9
},
// 规则3:其他 node_modules 打入 vendor
vendor: {
test: /[\\/]node_modules[\\/]/,
priority: 0
},
// 规则4:src/utils 下的公共工具,引用次数 >=3 时独立
utils: {
test: path.resolve(__dirname, 'src/utils'),
minChunks: 3,
name: 'shared-utils'
}
})
}
}4.2 配合动态导入
Rollup 能识别动态导入(import()),getModuleInfo 中的 dynamicImporters 会记录哪些模块动态引入了当前模块。因此,minChunks 同样适用于动态导入的场景。
4.3 高级:跳过某些模块
如果某个模块我们不想受任何规则影响,可以在规则中设置 name: null:
javascript
{
exclude: {
test: /[\\/]src[\\/]legacy[\\/]/,
name: null, // 让 Rollup 默认处理
priority: 100
}
}第五部分:性能考量
5.1 时间复杂度
每个模块都会遍历规则列表(最坏 O(m·n)),其中 m 为模块数,n 为规则数。对于大型项目(几千个模块,几十条规则),遍历开销仍然可控。但如果规则数量膨胀到上百条,可以考虑将正则表达式编译一次并缓存结果,或使用 Trie 树优化字符串前缀匹配。
5.2 使用 getModuleInfo 的开销
getModuleInfo 是 Rollup 内部维护的模块图查询函数,调用开销极小。我们只在需要检查 minChunks 时才调用,且仅访问 importers 和 dynamicImporters 属性,性能影响可忽略。
5.3 避免重复计算
插件没有做缓存,因为 manualChunks 函数在构建过程中会被多次调用(每个模块一次)。如果规则中包含复杂的自定义函数,可以考虑在外层 memoize。不过本插件完全基于配置,没有用户自定义函数,所以不需要缓存。
第六部分:与其他方案的对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 原生 manualChunks + 硬编码 | 简单直接 | 规则硬编码,难以维护;无法基于引用次数动态拆分 |
| SplitChunksPlugin (Webpack) | 功能强大,支持 cacheGroups | 配置复杂,且 Webpack 与 Rollup 生态不同 |
| 本插件 | 声明式配置,支持优先级、minChunks,轻量无依赖 | 需要手动编写规则;无法像 Webpack 那样自动提取公共模块 |
本插件更适合那些希望将分块规则集中管理、且对 Rollup 生态有强依赖的项目。配合 experimentalMinChunkSize 和 Rollup 自带的 Tree Shaking,可以获得接近 Webpack 的代码分割体验。
第七部分:扩展建议
虽然当前插件已经满足大多数场景,但还可以进一步增强:
- 支持函数形式的 test :允许用户传入
(id) => boolean,实现更灵活的匹配逻辑。 - 支持异步规则:例如根据模块内容的大小或依赖关系动态决策。
- 提供内置预设 :例如
preset: 'vue'自动配置 Vue 相关的分块规则。 - 集成 bundle 分析器:生成分块报告,帮助用户调整规则。
结语
代码分割是前端性能优化的核心环节之一,但往往被忽视或粗暴处理。通过本插件,我们可以用声明式的规则引擎精细控制每个模块的去向,实现:
- 更合理的缓存策略:稳定依赖单独 chunk,业务代码频繁更新不影响第三方库缓存。
- 更快的首屏加载:避免一次性加载巨大的 vendor 文件。
- 更清晰的构建产物:每个 chunk 有明确的命名和用途。
希望这篇文章能帮助你理解 manualChunks 的高级用法,并启发你构建属于自己的分块工具。如果你对插件有任何疑问或改进建议,欢迎在评论区交流。
对比
vue 全家桶单独打包 我在项目中走CDN啦! 默认分包 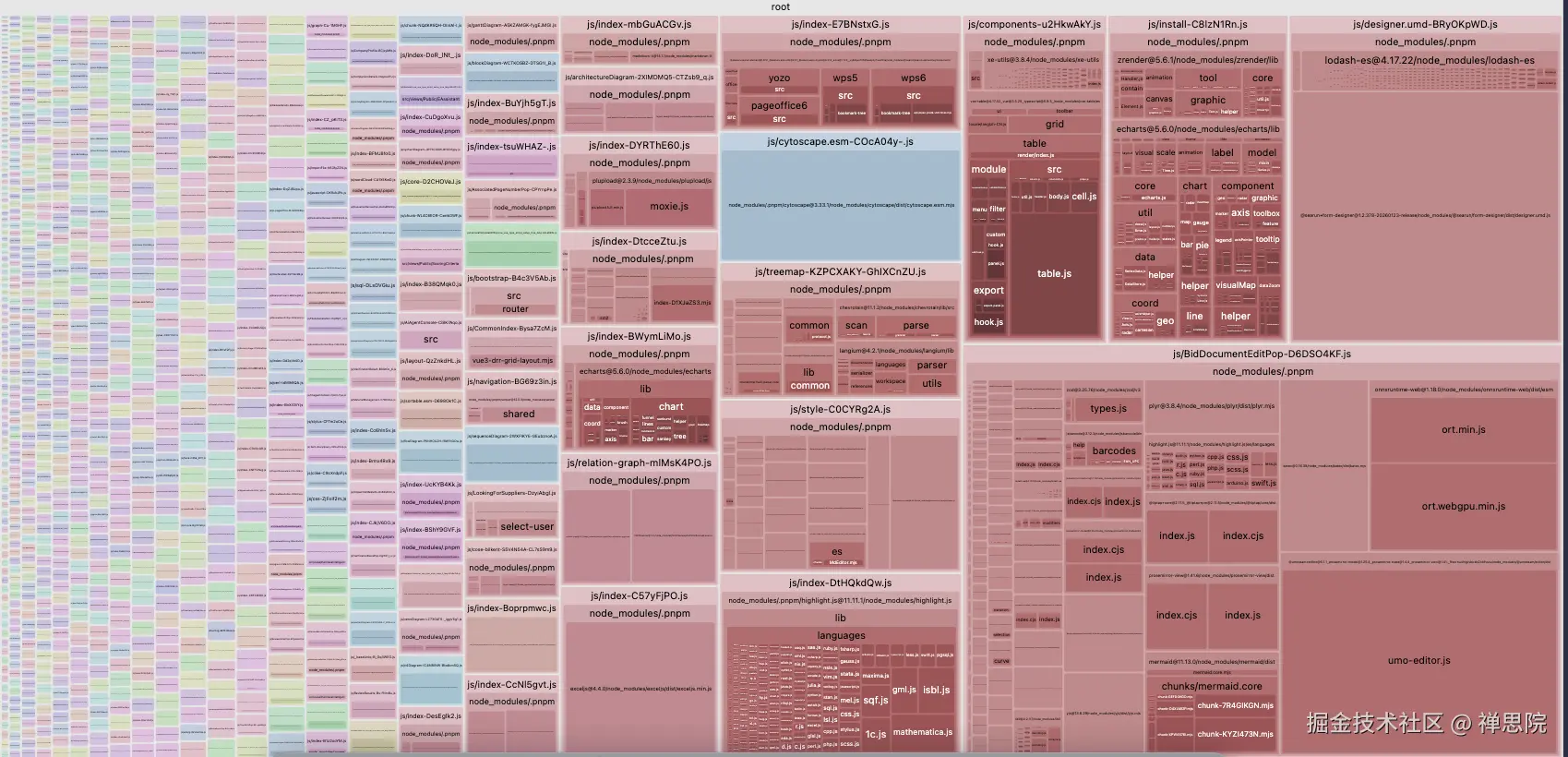 只用插件分包
只用插件分包  很明显有很大的差别!
很明显有很大的差别!