引言
任务激励、订单补贴等营销策略是业务增长的重要手段,与之相伴的往往是高并发、大额资金与复杂策略配置。一旦出现数据异常或配置错误,若发现不及时,很容易放大为业务风险。因此,除了把业务逻辑做对,还需要一套能实时发现异常、快速归因并辅助决策的监控体系。
如何在海量并发、复杂多变的业务场景下,实时捕捉每一个"细微"的异常点?如何在运营配置错误或系统逻辑漏洞导致问题前,拉响第一道警报?
本文介绍 数据质量告警平台的设计思路与落地实践:如何通过实时 Binlog 监听、配置化接入与细粒度维度分析,构建高效率、低成本的异常发现与防控能力;同时结合AI大模型做异常归因与风险研判,将告警与"发现---分析---决策"的智能链路打通,让异常能被及时发现、有效处置。
背景与挑战:为什么需要数据质量告警平台?
营销侧任务的一般流程
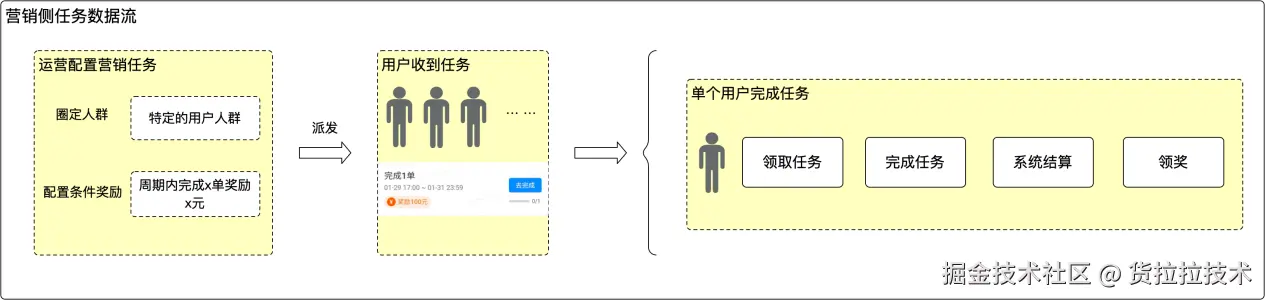
- 配置策略:运营在后台配置任务规则,如完成类型、达标条件等等。
- 派发:系统根据策略与画像,向符合条件的用户下发任务。
- 参与完成:用户领取任务并按要求完成,业务侧记录完成状态。
- 核销发放:用户达标后发起领取,系统核销并发放补贴
整条链路上,任一环节出现数据异常(如派发量异常、核销量突增、某用户维度数据异常)都可能带来风险,因此需要在策略、派发、核销等关键节点做细粒度、实时的监控与告警。
传统的监控手段在精细化的防控场景下有如下局限性:
- 宏观监控的局限性:传统的监控平台更擅长宏观数据的整体波动监控,但在涉及"单个用户"、"特定营销策略"等细粒度维度时,往往难以做到精准覆盖。
- 埋点上报的高成本:传统的埋点方案需要研发人员侵入式编写代码。一个简单的告警逻辑,从开发、测试到上线往往需要 2-3 人日,且灵活性差,无法即配即生效。
- 资损发现的延迟性:T+1 的离线分析虽然准确,但无法应对"预算瞬时超支"、"运营配置错误"等需要实时干预的场景。资损防控,贵在"实时"。
基于这些痛点,数据质量告警平台应运而生。它致力于提供实时、细粒度、零代码的业务数据监控能力。
核心设计:基于 Binlog 的实时监控体系 + AI 决策建议中枢
告警平台通过监听业务数据库的 Binlog(基于 Canal 采集),将数据变化转化为实时流式指标,实现了对业务逻辑的非侵入式监控。AI 决策中枢,把传统告警系统从"发现问题"升级为"理解问题、判断风险、指导止损"。
1. 架构概览
平台的核心流程可以概括为:数据采集与识别 -> 实时指标加工 -> 告警规则校验 -> 自动化归因与触达->AI 智能分析与决策建议 -> 闭环处理。
通过前台配置化注册的数据源与规则,会实时驱动核心计算引擎对流式数据进行处理。
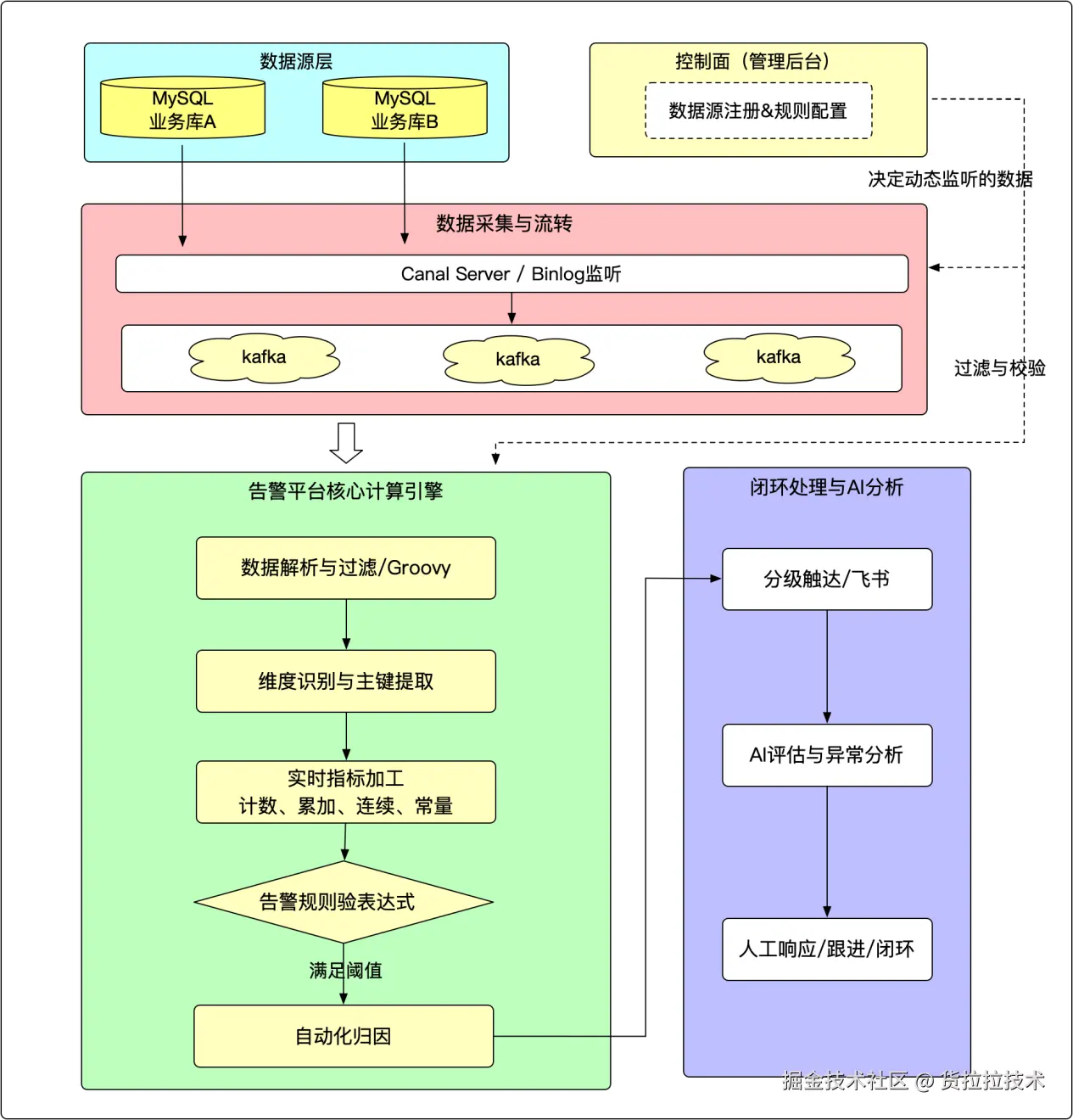
- 非侵入式采集:基于 Binlog(Canal)监听业务库变更,无需在业务代码里打点或埋点。新表、新字段接入只需在平台配置数据源与表名,即可把库表变更转为实时流,对业务无侵入、接入成本低,且数据延迟在秒级。
- 配置即生效的实时计算:指标与告警规则全部在平台配置完成,支持按表、按条件过滤(含 Groovy 表达式)以及多种计算类型(计数、累加、常量、连续等)。配置发布后即时生效,无需发版;从数据写入库到指标更新、规则触发,全链路流式处理,满足"实时发现"的诉求。
- 多维度聚合与灵活加工:同一份数据可按不同维度做聚合------例如按单个用户看当日累计核销、按单条策略看完成率。复杂逻辑可通过 Groovy 脚本扩展,既支持简单计数/累加,也支持与业务含义强相关的自定义指标,便于做细粒度监控。
- 规则触发后的自动归因:平台支持配置归因脚本,在触发时自动执行二次核对(如查对照表、补全现场信息),用于降噪或补充上下文,让推送到人的告警更可操作;再结合闭环与 AI 分析,形成"发现 → 归因 → 处置"的完整链路。
2. 闭环处理与 AI 决策中枢
告警不只是"告知",更重要的是"响应"与"解决"。平台通过飞书动态卡片等能力,把告警产生、跟进、处置串成一条线,形成从发现到闭环的完整链路。
在很多监控系统里,AI 往往只是一个"告警后的分析插件";而在数据质量告警平台中,AI 被设计为规则引擎之后的智能决策建议中枢。也就是说,规则负责高效发现异常候选,AI 负责进一步理解业务语义、关联上下文信息、判断是否是真风险,并输出更可执行的处置建议。这样一来,平台完成的就不再是"报警",而是"从发现到判断,再到处置"的完整闭环。
(1) 告警响应与闭环处理
平台提供交互式响应能力。研发或值班人员可通过快捷按钮进行跟进 、识别风险 或发起异常分析。未处理告警会自动汇总并定期提醒,避免重要告警被遗漏,确保每条告警都能被跟进闭环。
(2) AI 智能分析:从"发现异常"到"理解异常"
结合大语言模型(LLM),平台沉淀了两类最有价值的 AI 能力:
- 系统异常诊断:针对代码执行异常,自动抓取堆栈、线程、上下文信息并给出问题摘要,辅助研发秒级定位故障链路和代码位置。
- 业务风险研判:针对营销策略冲突、人群交集、配置异常、奖励异常等复杂业务场景,AI 会基于规则命中结果继续做语义判断,识别"是真风险、低风险还是无风险",减少误报和人工巡检成本。
核心概念解析:告警是如何运作的?
为了实现精准且低成本的监控,平台抽象出了几个核心概念。理解这些概念是高效使用平台的关键。
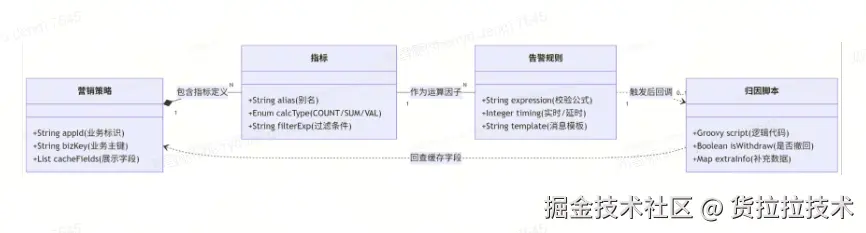
1. 营销策略 (Strategy)
营销策略是业务行为的载体(如:司机任务 A)。注册策略时,平台会缓存关键的业务主键和字段,为后续指标聚合提供上下文。
2. 指标 (Indicator)
指标是告警的"最小单元"。它决定了我们"关注什么数据"。
例子:累计完成任务数、当日核销金额
聚合 Key:可以是司机 ID(细粒度)或任务 ID(策略粒度)
3. 告警规则 (Rule)
规则定义了"什么时候该报警"。它由指标和运算符组成(如:完成任务数 / 派发任务数 > 50%)。
4. 自动归因脚本 (Attribution Script)
当规则满足时,系统会自动运行一段脚本进行"二次核对"。
降噪:发现风险较低,自动调低告警风险等级
提效:自动查询对照表,补充告警现场的关联信息,让排查不再像"大海捞针"
告警配置与接入流程
得益于全配置化的设计,研发人员在接入新的告警需求时,只需在平台界面完成简单的四步走配置。
1. 关键配置项说明
| 配置项 | 核心目的 | 关键参数 |
|---|---|---|
| 营销策略 | 注册业务主体 | appId、业务主键字段(如 taskId)、需要缓存展示的业务字段 |
| 指标注册 | 定义监控维度 | canal 数据源配置、数据过滤表达式(Groovy)、计算类型(累加/计数/常量/连续) |
| 告警规则 | 设置风险阈值 | 指标校验表达式、告警时机(实时或延时 10min 等)、消息模板、风险等级 |
| 触达 & 归因 | 闭环策略 | 飞书群 Webhook、告警接收人(值班规则)、归因脚本(用于二次判断/降噪) |
2. 配置流程图

如何平衡告警粗细粒度与人工处理效率?
粒度越细,覆盖越全面,但告警量随之激增,人工处理效率急剧下降,甚至引发"告警疲劳"------值班人员开始习惯性忽略告警;粒度越粗,噪声虽少,但容易漏掉关键风险。如何在这两者之间找到平衡点,是平台持续优化的核心命题。我们在实践中沉淀了以下几个策略:
- 分层告警:按风险等级划分处理:P0 资金类高危告警可细粒度配置、分钟级响应;P1 策略级异常群内跟进、小时级处理;P2 宏观趋势类则以日报汇总巡检。把有限的人力放在业务异常、资金安全这条红线上,其余层级逐步放宽粒度和响应时效。
- 聚合收敛:同策略、同规则的告警在时间窗口内可配置合并为一条摘要,附带影响范围与趋势(如"近 5 分钟触发 120 次"),避免同一根因引发的批量告警逐条轰炸值班人员。
- 归因前置:告警推送前自动执行二次核对------对照业务表验证一致性、补全现场关联信息,低风险自动降级静默,让推到人手里的告警都"带着结论来"。
- AI 智能决策:在规则触发后、推送到人之前,插入一层大模型研判。平台将告警现场数据、策略配置等组装为结构化 Prompt,由大模型输出风险定性(高风险/低风险/疑似误报)、推理摘要及处置建议。低风险自动静默,高风险附带行动建议,让人只需处理 AI 也拿不准的那部分。人工对判定结果的采纳或纠正会回流优化 Prompt 与示例库,形成越用越准的正循环。
- 闭环反馈:每次人工处理结果(确认/误报/忽略)被记录,定期输出告警质量报告(准确率、响应时长、闭环率),驱动规则持续迭代。
总结来说,平衡的关键不是选择"细"或"粗",而是构建一套分层、聚合、智能过滤的机制,让不同粒度的告警流向不同的处理通道------机器处理确定性高的,AI 辅助判断模糊的,人工聚焦真正需要决策的。
典型应用场景
数据质量告警平台已在多个业务线落地,配置了大量实时告警规则。
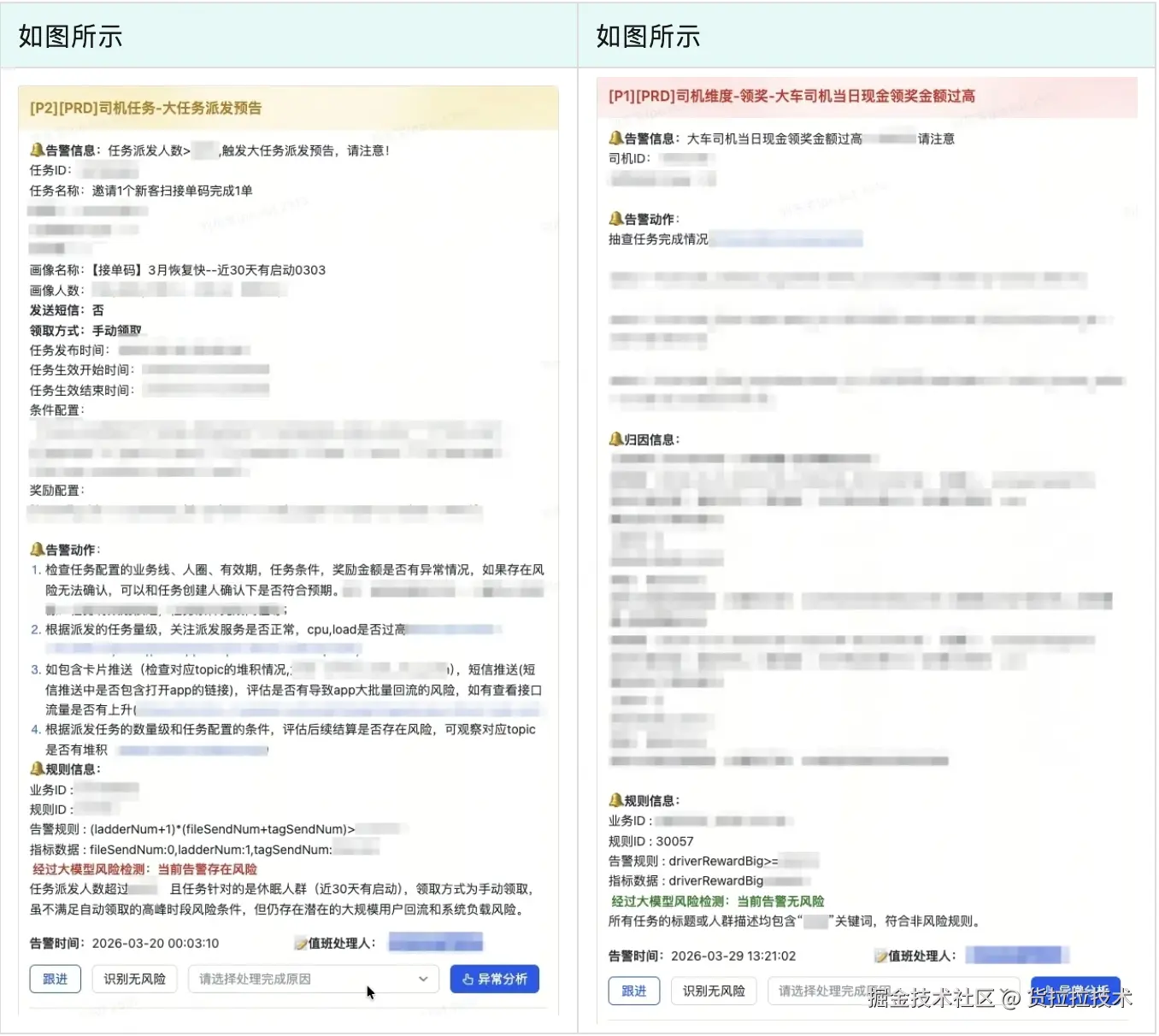
场景一:司机任务资损防控
异常识别:司机当日累计派发任务数 > n,或单个司机核销金额异常超标。
效果监控:监控任务完成率,若发现某些任务完成率瞬时达到 100%(可能是策略漏洞或作弊),立即预警。
场景二:运营配置校验
错误纠偏:运营上线补贴策略后,若 10 分钟内无任何记录产出,或画像配置过期导致派发人数为 0,平台会第一时间通知运营负责人检查。
场景三:系统逻辑漏洞捕获
兜底保障:在系统重构或新功能发布后,通过配置关键数据的核对规则,发现如"重复派发"、"状态刷新延迟"等潜在的系统性风险。
平台收益:人效与价值的双重提升
数据质量告警平台的上线,为研发和业务带来了显著的收益:
研发人效飞跃 :单个告警策略的接入时间从原来的 2-3 人日缩短至 1 小时以内。即配即生效,无需打包发布。
资损及时止付:通过实时监控预算核销情况,多次在资损扩大前帮助业务侧及时关停异常策略,有效守卫了资产安全。
精细化运营支持:实时通知运营关心的核心指标(如预算消耗进度),不仅是告警工具,更是业务决策的"辅助仪表盘"。
结语与展望
数据质量告警平台已在 Binlog 实时采集、配置化规则与 AI 辅助分析上形成闭环。后续会继续在告警智能化(用 AI 做异常模式识别与根因推荐,降误报、漏报)和归因自动化(把常见排查动作沉淀成脚本或工作流,让告警"带结论、带建议")上深耕;同时探索规则与阈值的智能推荐、多数据源与多业务场景的复用,让监控能力随业务扩展而自然延伸。