AMSFusion:一种基于注意力机制的自适应多尺度红外与可见光图像融合网络
AMSFusion: An Adaptive Multi-Scale Infrared and Visible Image Fusion Network Based on Attention Mechanisms
作者: Qimin Yang , Kan Ren , and Qian Chen
发表期刊: IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY
论文地址: https://ieeexplore.ieee.org/document/11114909/
摘要------图像融合的目标是生成一幅新图像,该图像包含源图像中的所有高质量特征,例如红外图像的显著特征和可见光图像的纹理细节。现有的图像融合方法主要关注深层特征提取,往往忽略了浅层特征的重要性。此外,严重依赖人工干预的融合策略会导致特征信息的丢失,并限制深度学习的性能。为了解决这些问题,我们提出了一种基于注意力机制的自适应多尺度融合网络,命名为 AMSFusion。我们方法的自编码器组件基于 U-Net 架构,并设计了不同的模块来处理浅层和深层的多尺度特征,从而在保持计算效率的同时提高特征处理质量。融合网络组件采用通道-空间注意力模块(CSA)为异构特征分配适当的权重,并应用移位窗口注意力和卷积混合 Transformer(SWACmixT)对它们进行融合,增强了网络自适应融合不同尺度特征的能力。在我们的实现中,自编码器和融合网络分别进行独立训练,并各自配置了不同的损失函数,这进一步增强了该方法在特征编码、解码和融合方面的能力。在多个数据集上的定性和定量实验证明了我们的方法与最先进算法相比的优越性。此外,在目标检测任务上的实验验证了我们的方法能够有效地促进高级计算机视觉任务。
关键词------红外与可见光图像融合,深度学习,自编码器,注意力机制,自适应融合。
I. 引言
图像融合是一种利用硬件设备或软件算法结合不同图像信息,生成具有更高内容质量的新图像的技术。近年来,红外和可见光图像采集设备在军事侦察、安全监控和火灾预警系统等领域变得越来越普遍,从而使得红外与可见光图像融合技术得到了广泛的应用。红外图像和可见光图像是两种常见且具有高度互补性的图像类型。可见光图像通常包含丰富的细节和高对比度,但在光照条件较差的情况下难以生成。另一方面,红外图像依赖于发射的热辐射,使其能够避免低光照的挑战。然而,生成的图像可能缺乏景深和详细的纹理信息。因此,融合图像可以利用这两种类型的优势,提供更全面的场景信息。
目前的红外与可见光图像融合技术大致可分为两类:传统方法和基于深度学习的方法。在深度学习成熟之前,主要使用传统方法来实现这一目的。这些传统方法可以根据其理论基础进一步分类,包括基于多尺度变换的方法 1, 2, 3, 4、基于稀疏表示的方法 5, 6, 7 和基于子空间的方法 8, 9, 10。传统方法构建效率高,并且在特征提取和融合设计中的人工干预允许快速适应特定的融合需求,在工业应用中保持着相关性。尽管传统方法在计算效率和实现简单性方面具有优势,但它们仍然面临着重大挑战,例如过度依赖人工设计的融合策略以及难以兼顾多模态图像特征之间的差异。
随着深度学习的逐步发展,这些局限性得到了部分缓解。Liu 等人 11 首次将卷积神经网络(CNNs)引入红外与可见光图像融合任务,标志着深度学习在这一领域应用的开端。基于深度学习的方法现在分为四类:基于 CNN 的方法、基于自编码器(AE)的方法、基于生成对抗网络(GAN)的方法以及基于 Transformer 的方法。在早期阶段,由于 CNN 高效的处理性能和直接的架构,基于深度学习的方法主要依赖 CNN 进行主干网络设计,在大多数融合任务中取得了优异的结果。近期,Transformer 技术的演进促使其在红外与可见光图像融合中得到了广泛应用。视觉 Transformer 擅长提取全局特征信息,克服了 CNN 感受野的局限性,尽管代价是增加了计算开销。因此,实现 CNN 和 Transformer 的有效结合已成为红外与可见光图像融合发展的一个关键方向。

本文提出了一种基于注意力机制的自适应多尺度融合网络,称为 AMSFusion。我们方法的动机是设计一个自编码器网络,在尽可能保证高计算效率的同时,优先提高融合性能。为了实现这一目标,我们设计了一个类 U-Net 模型,采用不同的模块来处理浅层和深层特征以处理多尺度信息。这种方法确保了高质量的特征提取,同时降低了计算复杂度。此外,我们开发了一个自适应融合网络,利用通道-空间注意力机制(CSA)为异构特征分配权重,并通过自注意力机制对这些特征进行整合。这种方法减少了融合策略设计过程中的人工干预,从而增强了模型的泛化能力。整体模型采用两阶段训练策略,为自编码器和融合网络分别配置不同的损失函数,以确保它们在特征处理中发挥各自的作用。如图 1 所示,我们的融合结果成功地保留了红外图像中墙壁的显著特征以及可见光图像中树木的纹理细节。我们的主要贡献可以概括为以下四个方面:
• 在自编码器中,我们设计了一个双分支 TransformerDense 模块,用于提取小尺度深层特征。该模块利用 DenseNet 分支来增强局部特征的传输和重用效率,同时 Swin Transformer 分支确保高效提取全局特征和长距离依赖关系。通过沿通道维度拼接双分支的编码结果,该模块改善了模型在下采样期间对小尺度特征的处理。
• 我们提出了一种可学习的自适应特征融合网络,利用 CSA 为红外和可见光特征分配不同的通道连接权重。然后由 SWACmixT 对加权连接的特征进行融合。该网络在不同尺度上为红外和可见光特征分配合理的融合权重,同时有效地整合了 CNN 和自注意力的编码优势。与传统融合策略相比,它更有效地保留了红外图像的显著性和可见光图像的纹理细节。
• 我们引入了两阶段训练策略,并为融合网络的训练设计了一种新的损失函数。该损失函数在图像内容层面对全局强度和纹理进行约束,并在特征层面对结构和显著性信息进行约束,增强了网络在红外和可见光特征融合过程中结合强度、细节、结构和显著性信息的能力。
本文的其余部分结构如下。第二节回顾了相关工作。第三节介绍了提出的 AMSFusion 算法。第四节对实验进行了详细分析。最后,第五节总结了我们的工作。
II. 相关工作
在本节中,我们对现有基于深度学习的图像融合方法进行了分类和介绍。
A. 基于 CNN 的融合方法
基于 CNN 的图像融合的主要方法解决了三个关键挑战:特征提取、融合和重建。损失函数和网络架构的设计至关重要,因为两者都极大地影响着融合性能。IFCNN 12 采用全卷积端到端训练方法,消除了大量的后处理过程。然而,其浅层网络结构和人工定义的融合规则限制了融合质量。U2Fusion 13 解决了灾难性遗忘、存储和计算问题,实现了一个模型处理多个任务。尽管如此,其基于自适应梯度的损失函数未能完全捕捉不同融合子任务的重要性。为了提高可解释性,AUIF 14 使用神经网络分离低频基础和高频细节信息。但是,其融合过程未能有效平衡低频和高频分量的权重。SeAFusion 15 为高级视觉任务提出了一种轻量级的、语义感知的融合框架,利用梯度残差密集块来改善细粒度特征表示。然而,其卓越的性能主要在语义丰富的场景中才有效。SCGAFusion 16 采用群卷积注意力块来捕获局部特征和长距离依赖关系。但是,其对多个注意力模块的依赖导致了很高的计算成本。虽然基于 CNN 的融合方法有效地保留了局部细节、对比度和强度,但它们未能提取跨模态的深层全局依赖关系。此外,其过于简单的架构也经常导致过拟合和泛化能力差。
B. 基于自编码器的融合方法
基于自编码器的方法利用编码器进行特征提取,应用人工设计的或可学习的融合策略,并使用解码器重建融合图像。自编码器简单、灵活且易于构建。DenseFuse 17 和 UNFusion 18 都使用密集连接来整合各层的特征编码结果,防止了中间信息的丢失。UNFusion 通过引入多尺度编码,将不同尺度的特征融入融合层,从而实现了更好的性能。然而,它们人工设计的融合策略限制了性能,并且在训练期间都没有考虑到红外和可见光图像特征编码的差异。SEDRFuse 19 和 MTDFusion 20 分别使用注意力图和多层三重密集网络来改善细节表示。尽管如此,这两种方法在融合过程中都未能有效地对来自不同源的特征进行加权。RFN-Nest 21 用可学习的残差融合网络替换了 NestFuse 22 中人工设计的融合模块。然而,其多级融合模块大幅增加了计算成本。CS2Fusion 23 利用补偿感知网络来捕获相对于可见光图像的互补红外特征,有效地整合了互补信息。但是,其对这些特征的映射受到 DeVries 和 Taylor 24 提出的增强技术的限制。MPCFusion 25 中的并行交叉注意力和跨域注意力模块有效地保留了浅层和深层特征中的纹理细节和边缘信息。尽管如此,过度关注纹理细节会导致忽略对显著目标的保留。BTSFusion 26 引入了一种采用传统融合方法作为损失函数的新型训练机制。通过整合引导滤波(Guided Filter)和潜在低秩表示(Latent Low-Rank Representation),它有效地平衡了纹理和显著性的保留。未来的工作应优化网络架构,以更好地与所提出的损失函数保持一致。为了减轻复杂场景中的噪声干扰,LiMFusion 27 引入了一种结合传统分解策略和注意力机制的融合方法,提高了感兴趣区域的信息保留度。但是,该模型的计算复杂度要求对架构轻量化进行进一步研究。基于自编码器的方法通常通过复杂的网络结构和多次训练迭代来提升融合性能,这也导致了高昂的训练和计算成本。
C. 基于 GAN 的融合方法
基于 GAN 的方法通过对抗学习优化模型的学习过程,其中判别器监督生成器的学习过程以生成融合图像。FusionGAN 28 率先将 GAN 用于红外和可见光图像融合。然而,其生成器强调可见光特征而忽略了红外特征。DDcGAN 29 采用双判别器来约束融合图像与红外及可见光图像的相似度。尽管如此,平衡这些对抗性损失极具挑战性,从而导致目标特征失真。MFEIF 30 通过密集上下文化的空洞网络提取多尺度特征。然而,它在分解过程中未考虑特征差异,可能导致特征冗余或信息丢失。DCDR-GAN 31 采用自适应实例归一化将模态特征注入到内容特征重建中。虽然这种方法减少了互斥特征的干扰,但其在颜色校正和细节增强方面的性能仍有待提高。DUGAN 32 通过双融合路径和 U 型判别器学习全局和局部差异,从而增强了去噪性能。然而,其双路径设计和额外的分支极大地增加了训练计算成本。GAN-GA 33 通过不同的细节和内容编码联合建模局部和全局信息。梯度惩罚机制减轻了融合输出中的强度不一致性。尽管该模型针对红外与可见光图像融合进行了优化,但可以扩展到更广泛的多源应用中。总之,基于 GAN 的融合方法通过判别器约束融合结果,减轻了生成器的负担。平衡不同类型的判别器仍然是其未来实际应用中的一项关键挑战。
D. 基于 Transformer 的融合方法
受 Transformer 在自然语言处理中取得成功的启发,Alexey 等人提出了视觉 Transformer(Vision Transformer),为提取全局图像依赖关系提供了一种有效的方法。最近,利用视觉 Transformer 的图像融合方法迅速涌现。例如,YDTR 34 使用动态 Transformer 模块捕获局部特征和关键上下文信息。然而,其 Y 型分支未能在特征融合过程中平衡来自不同源的特征比例。基于 Swin Transformer 36 的 SwinFusion 35 利用跨域注意力模块有效整合互补信息并实现全局交互。尽管具有这些优势,SwinFusion 的多层 Transformer 结构导致了较长的运行时间。类似地,DATFuse 37 利用 Swin Transformer 并结合了双注意力残差和 Transformer 模块,以提取局部显著特征和全局依赖关系。但是,它在编码过程中忽略了来自不同源的特征之间的差异。TFIV 38 通过引入可学习的注意力权重来动态估计其相关性,从而改善了模态内和模态间的标记(token)交互。尽管如此,它忽略了局部特征在图像融合中的作用。TCCFusion 39 的双分支特征提取模块克服了感受野的限制,并有效地建模了长距离依赖关系。虽然该模块保留了互补信息,但其准确融合所提取特征的能力仍然有限。MMIFEMMA 40 引入了一种使用等变成像先验(equivariant imaging priors)的自监督学习方法,以提高融合质量并支持下游任务。然而,其特征提取和重建模块忽略了在处理不同尺度特征时的差异。CFNet 41 采用多通道损失和基于变分自编码器的图像压缩技术,在压缩过程中保持融合质量的同时减少冗余。未来的工作应整合更多的特征级语义信息,以提高融合图像的语义完整性。总之,基于 Transformer 的方法在提取全局深层特征方面表现出色,但计算成本很高。未来的研究将侧重于在保持处理效率的同时降低计算复杂度。
III. 方法
在本节中,我们详细介绍 AMSFusion。首先,我们简要分解红外与可见光图像融合任务。接下来,我们分析 AMSFusion 的结构,然后详细描述设计的损失函数。
A. 问题描述
给定一对配准的红外图像IirI_{ir}Iir和可见光图像IviI_{vi}Ivi,我们的目标是利用模型从IirI_{ir}Iir和IviI_{vi}Ivi中提取充足的图像特征,然后将它们结合起来生成融合图像IfI_fIf。首先,编码器EEE从源图像中提取特征:
{Fir1,...,FirN}=Eir(Iir),(1) \{F_{ir}^1, \dots, F_{ir}^N\} = E_{ir}(I_{ir}), \tag{1} {Fir1,...,FirN}=Eir(Iir),(1)
{Fvi1,...,FviN}=Evi(Ivi),(2) \{F_{vi}^1, \dots, F_{vi}^N\} = E_{vi}(I_{vi}), \tag{2} {Fvi1,...,FviN}=Evi(Ivi),(2)
其中EirE_{ir}Eir和EviE_{vi}Evi分别表示红外和可见光图像编码器,而FirF_{ir}Fir和FviF_{vi}Fvi表示提取的红外和可见光特征图。NNN表示编码器输出的特征图数量。然后,融合模块Φ\PhiΦ结合这些特征:
{Ff1,...,FfN}={Φ1(Fir1,Fvi1),...,ΦN(FirN,FviN)},(3) \{F_f^1, \dots, F_f^N\} = \{\Phi^1(F_{ir}^1, F_{vi}^1), \dots, \Phi^N(F_{ir}^N, F_{vi}^N)\}, \tag{3} {Ff1,...,FfN}={Φ1(Fir1,Fvi1),...,ΦN(FirN,FviN)},(3)
其中FfF_fFf表示融合后的特征图。最后,解码器DDD生成融合图像IfI_fIf:
If=D(Ff1,...,FfN).(4) I_f = D(F_f^1, \dots, F_f^N). \tag{4} If=D(Ff1,...,FfN).(4)
B. 网络架构
我们的模型基于自编码器架构:一个双流对称编码器、一个解码器和一个融合网络。整体网络结构如图2所示。
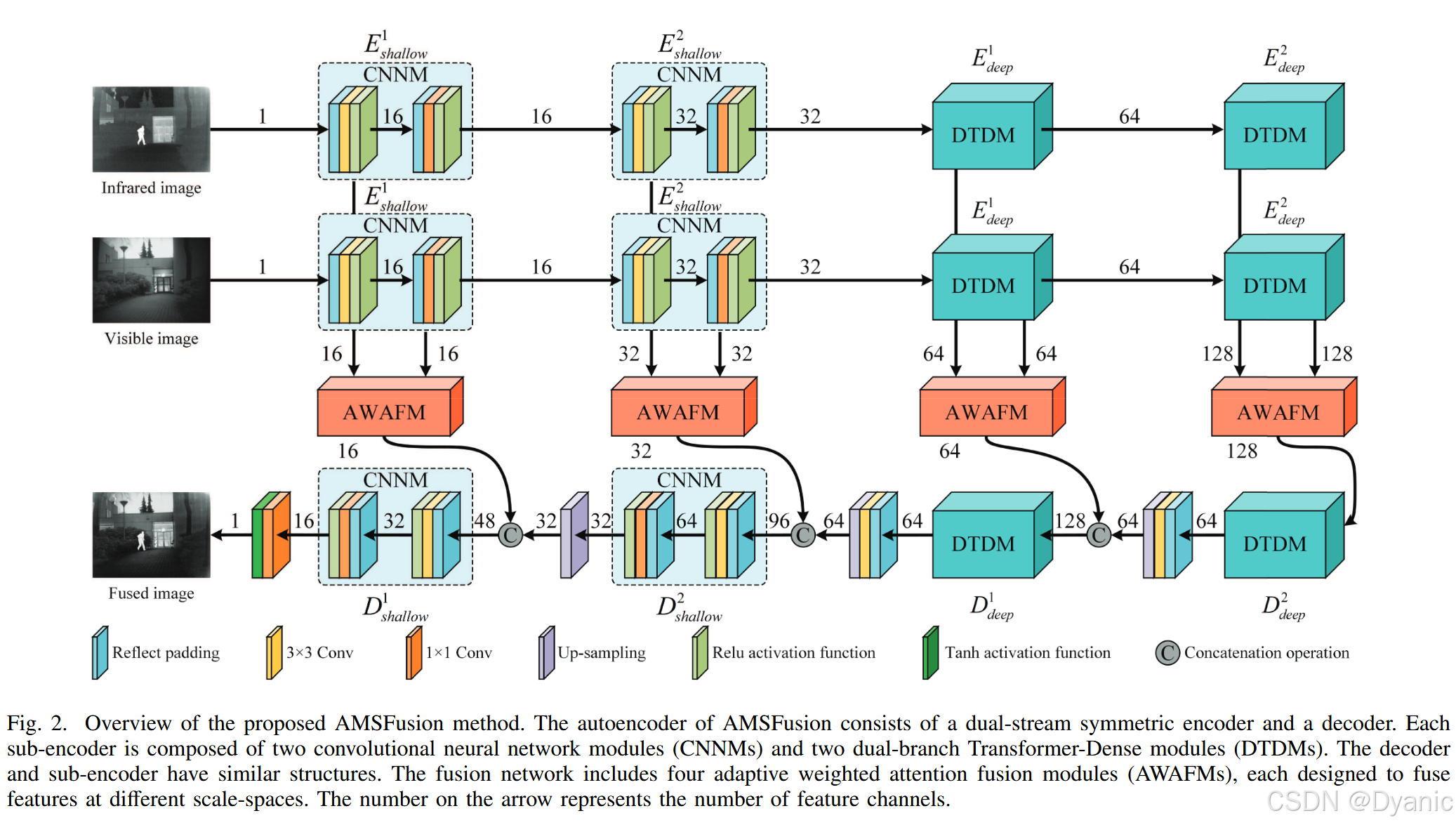
1. 编码器:
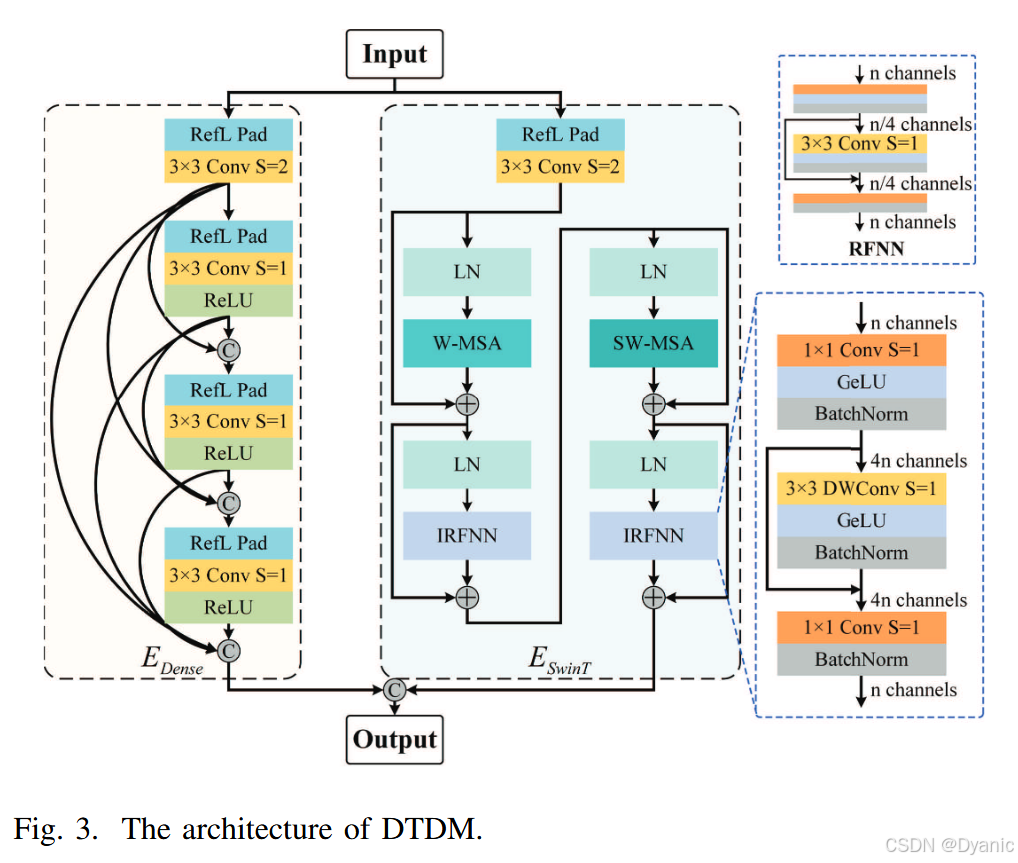
编码器的主要任务是处理源红外和可见光图像的特征,将具有显著目标的红外信息和具有纹理细节的可见光信息转换为特征图。由于红外和可见光图像由不同的传感器捕获并包含不同的特征,因此使用双流对称编码器对图像进行分别编码。每个子编码器由两个浅层特征编码模块Eshallowi,i∈{1,2}E_{shallow}^i, i \in \{1, 2\}Eshallowi,i∈{1,2}和两个深层特征编码模块Edeepi,i∈{1,2}E_{deep}^i, i \in \{1, 2\}Edeepi,i∈{1,2}组成。如图2所示,EshallowE_{shallow}Eshallow使用CNNM提取浅层特征。EdeepE_{deep}Edeep采用DTDM进行局部和全局特征编码,它由一个DenseNet分支EDenseE_{Dense}EDense和一个Swin Transformer分支ESwinTE_{SwinT}ESwinT组成,以提取深层特征,如图3所示。EDenseE_{Dense}EDense主要使用密集连接来增强特征在不同层级之间的交互和特征重用。它采用CNN构建密集块,以捕获特征图中的局部信息。ESwinTE_{SwinT}ESwinT利用Transformer结合自注意力机制,实现特征图中的全局长距离注意力。如图3所示,ESwinTE_{SwinT}ESwinT具有两层Transformer编码结构。每层由一个层归一化(LN)、一个多头自注意力(MSA)、一个LN和一个倒残差前馈网络(IRFFN)组成。子层之间应用残差连接,例如在LN和MSA之间。为了提高计算效率,在第一层和第二层Transformer中,分别用基于窗口的多头自注意力(W-MSA)和基于移位窗口的多头自注意力(SW-MSA)替换传统的MSA。如图3所示,IRFFN类似于倒残差块42。IRFFN与传统RFFN的主要区别在于结构内的通道变化:IRFFN首先增加通道数然后减少,而RFFN则相反。具体而言,IRFFN采用高效的深度卷积神经网络(DWCNN)替换传统卷积43来进行局部特征提取。此外,IRFFN中的跳跃连接增强了层之间的信息传播并防止了信息丢失。IRFFN的具体过程如下:
P1=BN(GeLU(Conv1×1(Fin))),(5) P_1 = \text{BN}(\text{GeLU}(\text{Conv}_{1\times1}(F^{in}))), \tag{5} P1=BN(GeLU(Conv1×1(Fin))),(5)
P2=P1+BN(GeLU(DWConv3×3(P1))),(6) P_2 = P_1 + \text{BN}(\text{GeLU}(\text{DWConv}_{3\times3}(P_1))),\tag{6} P2=P1+BN(GeLU(DWConv3×3(P1))),(6)
Fout=BN(Conv1×1(P2)),(7) F^{out} = \text{BN}(\text{Conv}_{1\times1}(P_2)), \tag{7} Fout=BN(Conv1×1(P2)),(7)
其中BN和GeLU分别表示批量归一化和高斯误差线性单元激活函数。Conv1×1\text{Conv}{1\times1}Conv1×1表示核大小为1×1的CNN,DWConv3×3\text{DWConv}{3\times3}DWConv3×3表示核大小为3×3的DWCNN。
MSA是我们Transformer架构的核心组件,旨在从不同角度捕获信息。在自注意力中,查询QQQ、键KKK和值VVV的设计旨在计算输入序列中不同位置之间的关系,从而生成每个位置的加权表示。具体来说,QQQ和KKK用于计算注意力权重,代表序列中不同位置之间的相关性。VVV提供与每个位置相关联的信息,然后根据注意力权重对其进行加权求和,以产生最终输出。注意力机制定义为:
{Q,K,V}={XWQ,XWK,XWV},(8) \{Q, K, V\} = \{XW^Q, XW^K, XW^V\},\tag{8} {Q,K,V}={XWQ,XWK,XWV},(8)
Attention(Q,K,V)=SoftMax(QKTdk+B)V,(9) \text{Attention}(Q, K, V) = \text{SoftMax}\left(\frac{QK^T}{\sqrt{d_k}} + B\right)V,\tag{9} Attention(Q,K,V)=SoftMax(dk QKT+B)V,(9)
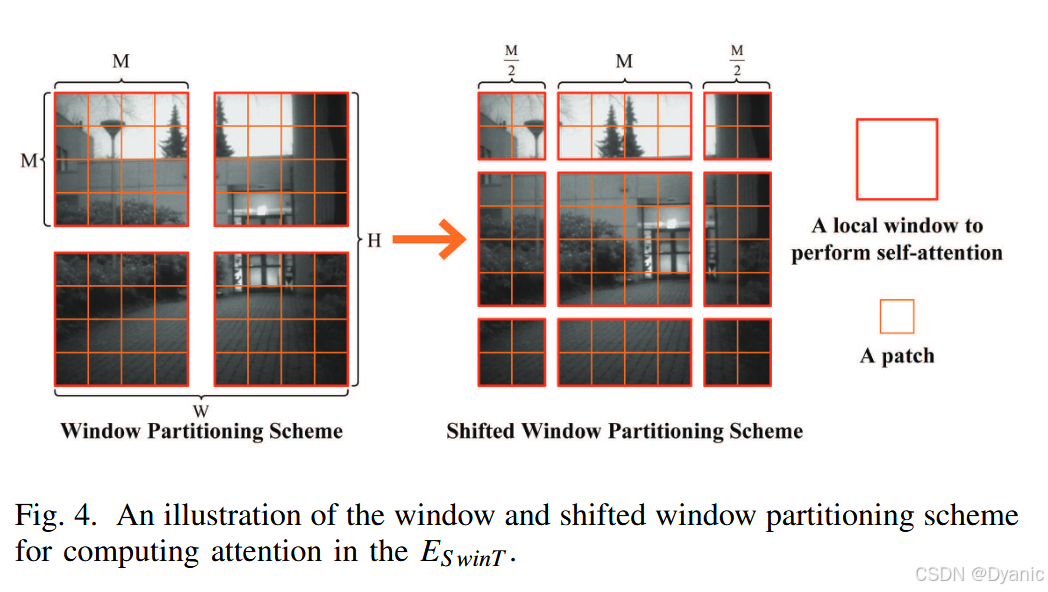
其中X∈RM2×CX \in \mathbb{R}^{M^2 \times C}X∈RM2×C表示局部窗口特征,WQ∈RC×CW^Q \in \mathbb{R}^{C \times C}WQ∈RC×C、WK∈RC×CW^K \in \mathbb{R}^{C \times C}WK∈RC×C和WV∈RC×CW^V \in \mathbb{R}^{C \times C}WV∈RC×C分别表示可学习的权重矩阵。dkd_kdk是键的维度,BBB是可学习的相对位置编码,而SoftMax表示软最大值激活函数。如图4所示,在窗口划分方案中,对于尺寸为H×W×CH \times W \times CH×W×C的特征,窗口机制将输入划分为不重叠的M×MM \times MM×M局部窗口,从而得到尺寸为HWM2×M2×C\frac{HW}{M^2} \times M^2 \times CM2HW×M2×C,其中HWM2\frac{HW}{M^2}M2HW表示局部窗口的数量。然后在每个窗口内应用MSA。在移位窗口划分方案中,遵循Liu等人36的方法,通过将窗口位置移动(M2,M2)(\frac{M}{2}, \frac{M}{2})(2M,2M)的距离来实现跨窗口连接。这确保了移位窗口层中的局部窗口包含窗口层中相邻的区域,从而建立了窗口特征之间的连接。
2.解码器:
为了增强解码器在不同深度解码特征并保留浅层特征的能力,我们设计了一种基于U-Net架构的结构。如图2所示,该结构依次解码深层和浅层特征,最终将它们还原为图像。为了保留前面层的特征,我们使用通道维度拼接来结合来自不同层的特征,并通过上采样将特征尺度恢复到与较低层特征相匹配。由于解码器中不需要下采样,因此解码器所有模块中第一个卷积层的步长从2更改为1。
3. 融合网络:
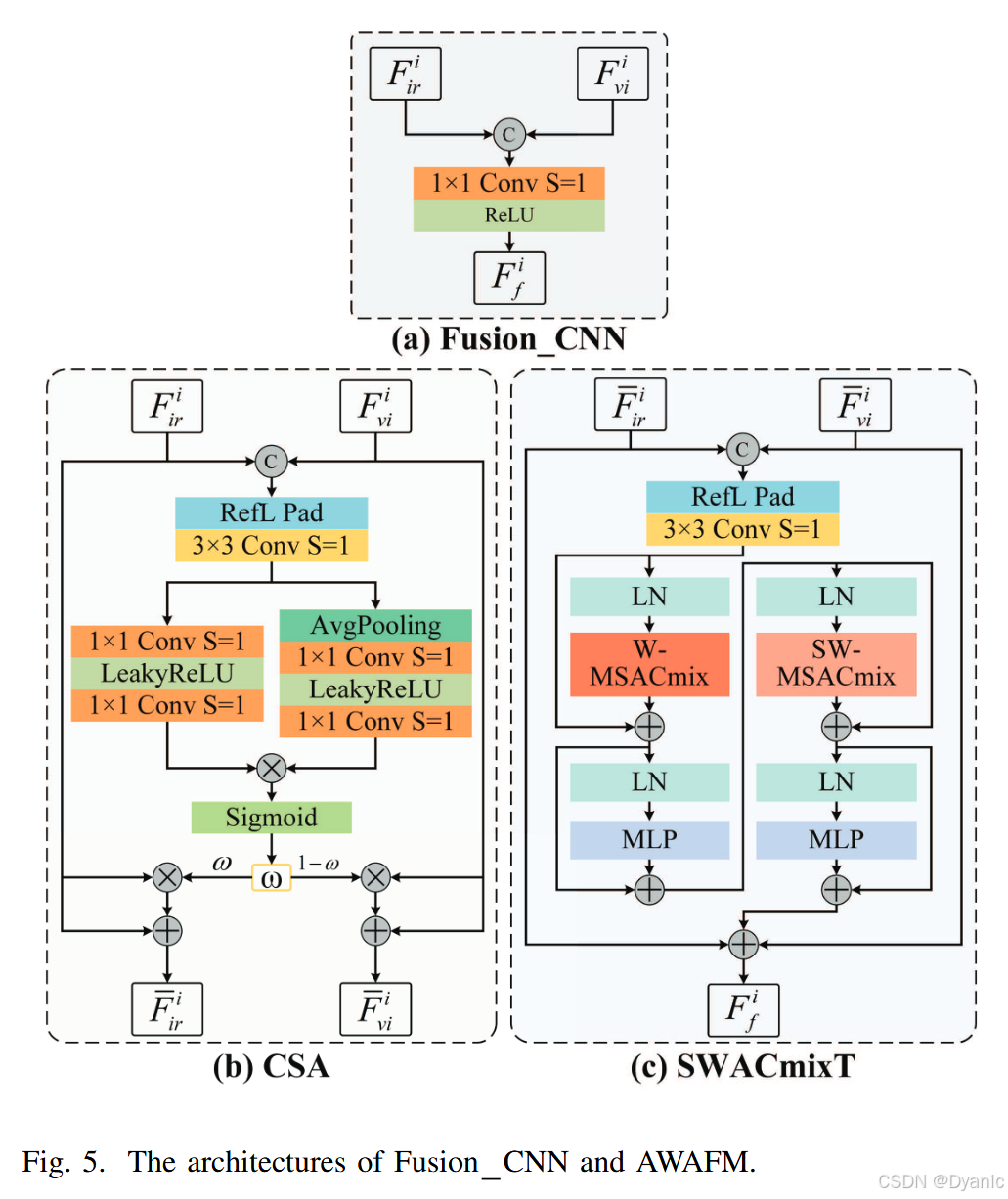
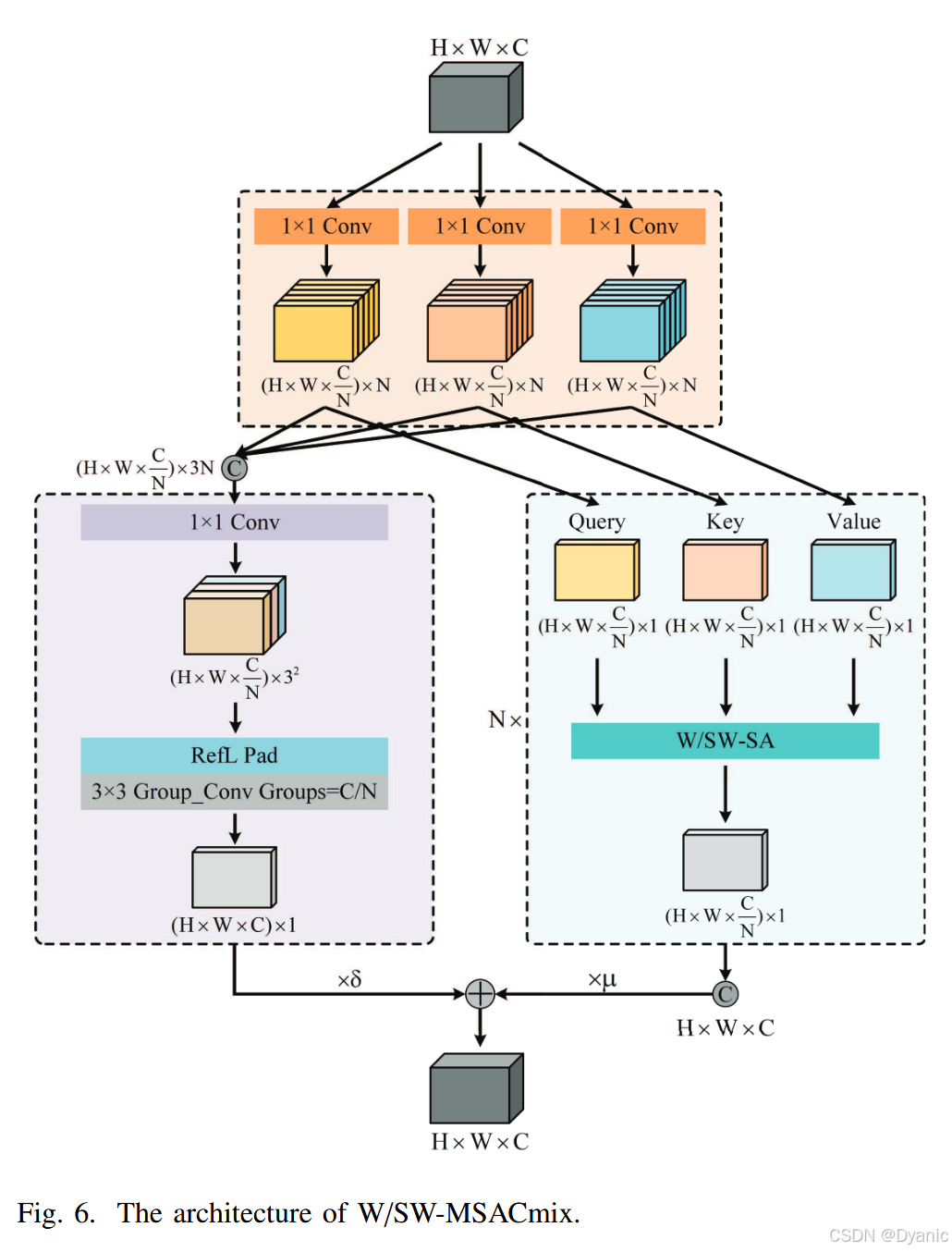
图5(a)展示了基于神经网络的基本可学习融合模块。它沿通道维度拼接红外和可见光特征,并使用CNN降维,从而实现特征融合。然而,它忽略了融合结果中不同特征的比例,并且由于依赖CNN而在全局特征编码方面存在困难。为了解决这个问题,我们提出了AWAFM,它通过CSA为红外和可见光特征分配不同的权重,确保在拼接过程中有合适的强度比例。随后,SWACmixT对拼接的特征进行高效融合,结合了CNN和自注意力的编码优势。融合网络包含四个AWAFM,每个处理不同通道维度和尺度空间上的特征融合。如图5(b)所示,CSA使用Sigmoid函数计算所获得的通道和空间注意力结果。该过程为输入的红外和可见光特征分配不同的权重,在随后的融合过程中调整红外和可见光图像信息的比例。经过自适应权重分配后,红外和可见光特征被输入到SWACmixT中进行特征融合。如图5©所示,它与ESwinTE_{SwinT}ESwinT非常相似,将W/SW-MSA修改为基于窗口或移位窗口的多头自注意力与卷积混合块(W/SW-MSACmix)44,并将IRFFN替换为多层感知机(MLP)。W/SW-MSACmix网络结构如图6所示,由三个阶段组成。在第一阶段,三个独立的1×1 CNN将输入特征通道CCC扩展三倍,并将它们折叠成NNN组。第二阶段包含两个并行分支:卷积分支使用1×1卷积扩展特征通道,获取多个偏移方向的特征,然后通过3×3分组卷积进行移位和聚合。自注意力分支将第一阶段每组特征划分为QQQ、KKK和VVV以进行W/SW-SA,形成NNN个自注意力结构。这NNN组的结果沿通道维度进行合并。在第三阶段,自注意力和卷积分支的输出被求和,分支权重由可学习的标量控制。这种结构高效地整合了CNN和W/SW-MSA,结合了它们的局部和全局特征编码优势,同时降低了计算成本。
C. 两阶段训练策略
处理红外图像中显著性信息和可见光图像中纹理细节的能力直接影响融合图像的视觉质量和后续应用。为了确保有效的特征提取和图像重建,我们分别训练自编码器和融合网络。第一阶段是训练自编码器以重建输入图像,随后训练融合网络,以确保其能够适应不同尺度的红外和可见光特征的融合。两阶段训练策略的细节如下:
1. 自编码器的训练:
由于红外和可见光图像的不同特性,模型需要分别从它们中提取显著性和纹理细节特征。因此,采用双流对称编码器对红外和可见光图像分别进行编码。由于解码器基于融合特征重建图像,因此要求解码器具有通用的图像重建能力。在自编码器训练过程中,针对红外和可见光特征训练了一个统一的解码器。自编码器网络中各层的输入和输出通道配置如图2所示。网络执行过程如下:
{Fir1,Fir2,Fir3,Fir4}=Eir(Iir),(10) \{F_{ir}^1, F_{ir}^2, F_{ir}^3, F_{ir}^4\} = E_{ir}(I_{ir}), \tag{10} {Fir1,Fir2,Fir3,Fir4}=Eir(Iir),(10)
{Fvi1,Fvi2,Fvi3,Fvi4}=Evi(Ivi),(11) \{F_{vi}^1, F_{vi}^2, F_{vi}^3, F_{vi}^4\} = E_{vi}(I_{vi}), \tag{11} {Fvi1,Fvi2,Fvi3,Fvi4}=Evi(Ivi),(11)
Iirre=D(Fir1,Fir2,Fir3,Fir4),(12) I_{ir}^{re} = D(F_{ir}^1, F_{ir}^2, F_{ir}^3, F_{ir}^4), \tag{12} Iirre=D(Fir1,Fir2,Fir3,Fir4),(12)
Ivire=D(Fvi1,Fvi2,Fvi3,Fvi4),(13) I_{vi}^{re} = D(F_{vi}^1, F_{vi}^2, F_{vi}^3, F_{vi}^4), \tag{13} Ivire=D(Fvi1,Fvi2,Fvi3,Fvi4),(13)
其中Fir1,Fir2,Fir3,Fir4{F_{ir}^1, F_{ir}^2, F_{ir}^3, F_{ir}^4}Fir1,Fir2,Fir3,Fir4和Fvi1,Fvi2,Fvi3,Fvi4{F_{vi}^1, F_{vi}^2, F_{vi}^3, F_{vi}^4}Fvi1,Fvi2,Fvi3,Fvi4分别表示编码器EirE_{ir}Eir和编码器EviE_{vi}Evi输出的特征。IirreI_{ir}^{re}Iirre和IvireI_{vi}^{re}Ivire表示解码器DDD使用编码特征重建的红外和可见光图像。用于训练自编码器的损失函数LautoL_{auto}Lauto如下:
Lauto=Lcontent+αLdecomp,(14) L_{auto} = L_{content} + \alpha L_{decomp}, \tag{14} Lauto=Lcontent+αLdecomp,(14)
其中LcontentL_{content}Lcontent表示重建图像与原图像之间强度和结构差异的损失函数,而LdecompL_{decomp}Ldecomp表示编码特征的损失函数。α\alphaα是一个平衡LcontentL_{content}Lcontent和LdecompL_{decomp}Ldecomp之间比例的超参数。内容损失LcontentL_{content}Lcontent定义为:
Lcontent=Lint+βLssim,(15) L_{content} = L_{int} + \beta L_{ssim}, \tag{15} Lcontent=Lint+βLssim,(15)
Lint=Lintir+Lintvi,(16) L_{int} = L_{int}^{ir} + L_{int}^{vi},\tag{16} Lint=Lintir+Lintvi,(16)
Lintx=1HW∥Ixout−Ix∥1,(17) L_{int}^x = \frac{1}{HW} \|I_x^{out} - I_x\|_1, \tag{17} Lintx=HW1∥Ixout−Ix∥1,(17)
Lssim=2−SSIM(Iirout,Iir)−SSIM(Iviout,Ivi),(18) L_{ssim} = 2 - \text{SSIM}(I_{ir}^{out}, I_{ir}) - \text{SSIM}(I_{vi}^{out}, I_{vi}), \tag{18} Lssim=2−SSIM(Iirout,Iir)−SSIM(Iviout,Ivi),(18)
SSIM(X,Y)=(2μXμY+C1)(2σXY+C2)(μX2+μY2+C1)(σX2+σY2+C2),(19) \text{SSIM}(X, Y) = \frac{(2\mu_X\mu_Y + C_1)(2\sigma_{XY} + C_2)}{(\mu_X^2 + \mu_Y^2 + C_1)(\sigma_X^2 + \sigma_Y^2 + C_2)}, \tag{19} SSIM(X,Y)=(μX2+μY2+C1)(σX2+σY2+C2)(2μXμY+C1)(2σXY+C2),(19)
其中LintL_{int}Lint用于计算重建图像的强度损失,而LssimL_{ssim}Lssim计算图像重建后的结构相似度损失。β\betaβ是一个平衡它们之间比例的超参数。HHH和WWW分别表示图像的高度和宽度。IxoutI_x^{out}Ixout表示由自编码器从IxI_xIx重建的图像,∣⋅∣1|\cdot|1∣⋅∣1表示L1范数,μ\muμ和σ\sigmaσ表示均值和标准差。σXY\sigma{XY}σXY表示图像XXX和YYY之间的协方差,而C1C_1C1和C2C_2C2是稳定性系数。随着编码的加深,提取的红外和可见光特征之间的差异逐渐增大。LdecompL_{decomp}Ldecomp用于训练编码器,使其在浅层从红外和可见光图像中获取相似的特征,同时在深层能够提取截然不同的特征。LdecompL_{decomp}Ldecomp的计算公式如下:
Ldecomp=(CC(Fir4,Fvi4))2CC(Fir2,Fvi2)+ϵ,(20) L_{decomp} = \frac{(\text{CC}(F_{ir}^4, F_{vi}^4))^2}{\text{CC}(F_{ir}^2, F_{vi}^2) + \epsilon}, \tag{20} Ldecomp=CC(Fir2,Fvi2)+ϵ(CC(Fir4,Fvi4))2,(20)
其中CC(⋅)\text{CC}(\cdot)CC(⋅)是相关系数运算符,范围为−1,1-1, 1−1,1,并且ϵ\epsilonϵ被设置为1.01以确保该项始终为正。FiriF_{ir}^iFiri和FviiF_{vi}^iFvii分别是EirE_{ir}Eir和EviE_{vi}Evi中第iii个模块的输出。
2. 融合网络的训练:
在自编码器训练完成后,训练融合网络以合并由编码器输出的具有相同尺寸和维度的红外和可见光特征。然后将融合后的特征作为解码器的输入,用于重建融合图像。融合网络应该能够结合来自红外和可见光图像的相似特征和相异特征。融合网络模块的输入和输出通道如图2所示,它们的训练过程与第三节A部分保持一致。由于编码器和解码器是预训练的,这里仅训练融合网络。为融合网络设计的损失函数LfusionL_{fusion}Lfusion如下:
Lfusion=Ltexture+γLstructure,(21) L_{fusion} = L_{texture} + \gamma L_{structure}, \tag{21} Lfusion=Ltexture+γLstructure,(21)
其中LtextureL_{texture}Ltexture表示融合图像中强度和细节的损失函数,而LstructureL_{structure}Lstructure表示显著性和结构特征的损失函数。γ\gammaγ是一个平衡LtextureL_{texture}Ltexture和LstructureL_{structure}Lstructure之间比例的超参数。LtextureL_{texture}Ltexture定义为:
Ltexture=Lgrad+Lmse,(22) L_{texture} = L_{grad} + L_{mse}, \tag{22} Ltexture=Lgrad+Lmse,(22)
Lgrad=∥∇If−max∇(Iir),∇(Ivi)∥1,(23) L_{grad} = \|\nabla I_f - \max\\nabla(I_{ir}), \\nabla(I_{vi})\|_1,\tag{23} Lgrad=∥∇If−max∇(Iir),∇(Ivi)∥1,(23)
Lmse=∥If,maxIir,Ivi∥2,(24) L_{mse} = \|I_f, \maxI_{ir}, I_{vi}\|_2, \tag{24} Lmse=∥If,maxIir,Ivi∥2,(24)
其中∇\nabla∇表示Sobel算子,max⋅\max\\cdotmax⋅表示逐像素最大值选择,∥⋅∥2\|\cdot\|2∥⋅∥2表示L2范数,LgradL{grad}Lgrad用于训练融合网络以结合红外图像的显著边缘与可见光图像的纹理信息,而LmseL_{mse}Lmse用于在融合期间保留红外和可见光图像的像素强度分布。LstructureL_{structure}Lstructure定义为:
Lstructure=Lssim+Lspa,(25) L_{structure} = L_{ssim} + L_{spa},\tag{25} Lstructure=Lssim+Lspa,(25)
Lssim=2−SSIM(If,Iir)−SSIM(If,Ivi),(26) L_{ssim} = 2 - \text{SSIM}(I_f, I_{ir}) - \text{SSIM}(I_f, I_{vi}), \tag{26} Lssim=2−SSIM(If,Iir)−SSIM(If,Ivi),(26)
L_{spa} = \\frac{1}{M} \\sum_{i=1}\^M \\sum_{j\\in\\Omega(i)} \\left( (\|I_{f,i} - I_{f,j}\| - \|I_{ir,i} - I_{ir,j}\|)\^2 \\ * (\|I_{f,i} - I_{f,j}\| - \|I_{vi,i} - I_{vi,j}\|)\^2 \\right), \\tag{27}
其中MMM表示局部区域的数量,Ω(i)\Omega(i)Ω(i)表示以像素iii为中心的四个相邻区域。局部区域的大小凭借经验设置为4×4。LssimL_{ssim}Lssim用于训练融合特征以保留红外和可见光图像的结构特征,而LspaL_{spa}Lspa用于在融合结果中保留源图像的显著目标特征。
IV. 实验
A. 实现细节
我们实验中使用的数据集包括 TNO 45、RoadScene 13、LLVIP 46 和 M3FD 47。M3FD 数据集既用作图像融合训练数据集,又用作目标检测数据集。为了证明我们方法的泛化能力,TNO、RoadScene 和 LLVIP 被用作图像融合测试数据集。我们将 M3FD 数据集按 8:1:1 的比例随机划分为训练集、验证集和测试集。训练集用于训练我们的方法。所有划分的集合均用于后续的目标检测实验。关于图像融合测试数据集,我们从每个数据集中随机选取 20 对图像进行测试。所有实验均在 3.40GHz Core™ i7-14700KF CPU、NVIDIA GeForce RTX 4090 D GPU 和 MATLAB R2022b 上完成。我们的代码基于 PyTorch 平台实现。训练的 epoch 数量设置为 400,其中第一阶段和第二阶段分别进行 300 和 100 个 epoch。我们使用 Adam 优化器,学习率设为 1e-5,批量大小(batch size)设为 4,并将超参数 α\alphaα、β\betaβ 和 γ\gammaγ 分别设置为 2、10 和 0.1。为了防止图像裁剪影响全局语义信息,所有训练图像均调整为 224 × 224 大小。此外,所有输入的彩色图像均被转换为 YCbCr 格式,并将 Y 通道与红外图像进行融合以获得最终的融合图像。
B. 对比方法与评估指标
我们通过将提出的方法与十二种最先进的(SOTA)红外与可见光图像融合方法进行比较来验证其性能:GTF 48、MDLatLRR 2、EgeFusion 4、DenseFuse 17、IFCNN-MAX 12、RFN-Nest 21、MTDFusion 20、YDTR 34、SwinFusion 35、DATFuse 37、MPCFusion 25 和 MMIF-EMMA 40。这些方法均使用其发表论文中指定的默认参数进行评估。我们使用图像融合领域广泛认可的八种质量评估指标来评估融合性能:熵(EN)49、平均梯度(AG)50、空间频率(SF)51、标准差(SD)52、相关差异和(SCD)53、总边缘信息(QAB/F)54、视觉信息保真度(VIF)55 和结构相似度(SSIM)56。
C. TNO 数据集上的结果
1. 定性比较:
在 TNO 数据集中,我们通过两个典型场景直观地评估了我们的方法。图像中的显著目标区域和纹理细节区域分别用红框和绿框标出。图 7 主要描绘了丛林中被烟雾遮挡的人类。GTF、MDLatLRR、DenseFuse、IFCNN-MAX、RFN-Nest、MTDFusion 和 YDTR 的融合结果清楚地显示了人类目标,但缺乏显著的环境细节。相比之下,SwinFusion、DATFuse 和 MMIF-EMMA 的融合结果包含丰富的环境细节,但人类目标不易识别。虽然 EgeFusion 和 MPCFusion 同时保留了细节和目标,但它们表现出明显的失真。我们的融合结果在不影响人类目标可识别性的情况下,在环境细节和视觉信息保真度方面优于其他方法。在图 8 中,GTF、MDLatLRR、DenseFuse、RFN-Nest、YDTR 和 DATFuse 的融合结果表现出较低的场景对比度。EgeFusion 和 MPCFusion 显示出一定的失真。IFCNN-MAX、MTDFusion 和 SwinFusion 的结果强调了人类目标,但缺乏灌木丛的纹理。MMIF-EMMA 和我们的方法在场景对比度和灌木丛细节方面均表现出色,但我们的方法在人类目标显著性方面超过了 MMIF-EMMA。总之,我们的方法在视觉信息保真度、有效突出目标以及保留融合图像中的环境细节方面取得了优异的性能。这些特征归功于我们设计的浅层和深层特征提取网络,该网络有效地捕获了图像的浅层细节特征和深层结构特征。此外,CSA 能够自适应地为异构特征分配权重,使得结果能够保留红外图像中的显著信息和可见光图像中的纹理细节。
2. 定量比较:
表 I 呈现了 TNO 数据集上的定量分析结果。我们的方法在八个指标中均排名前三。EN 指标上的结果表明,我们的方法保留了更大量的信息。这归功于我们类 U-Net 的网络结构,它在解码过程中保留了对称位置的特征融合信息。我们为红外和可见光图像分别训练了独立的编码分支,为每种图像提供了具有特征性的编码信息。这使得融合结果能够从两幅图像中获取高质量特征,从而解释了我们在 AG 和 SF 上优越的性能。SD 值表明,我们的方法在融合图像中保持了高对比度,确保了关键目标的突出,同时提高了视觉质量。这归因于我们网络训练过程中使用了与强度相关的损失函数。QAB/F 上的结果证明,由于我们的网络中红外和可见光特征的自适应融合,我们的方法保留了源图像中更多的视觉信息。SCD 和 VIF 上的结果证明,我们的方法在保留源图像信息和提升视觉体验方面同样表现出色。SSIM 结果证明了我们的算法在保留源图像结构信息方面的优势。综上所述,TNO 数据集的定量分析表明,我们的方法满足军事和监控场景中多波段红外和可见光图像融合的要求,在比较中展现出明显优于其他 SOTA 方法的性能优势。
D. RoadScene 数据集上的结果
1. 定性比较:
RoadScene 是一个专注于道路场景的数据集。图 9 和图 10 分别对应其中白天和夜间道路的两个典型场景。在图 9 中,GTF、MDLatLRR、DenseFuse 和 RFN-Nest 的结果在描绘人物和环境细节方面表现不佳。相比之下,IFCNN-MAX、YDTR、SwinFusion 和 DATFuse 的融合结果提高了关键热目标的可见度,但未能保留植物的纹理细节。MPCFusion 提升了场景纹理细节的丰富度,但图像对比度较低,未能充分突出关键目标。EgeFusion 在环境细节和人物显著性方面表现出色,但缺乏视觉保真度。MTDFusion、MMIF-EMMA 和我们的模型在突出人与车辆的重要性以及场景植物和文字的纹理细节方面表现出强大的性能。然而,MTDFusion 在细节区域的对比度方面存在轻微问题,而 MMIF-EMMA 的结果显示人物部分存在一定的模糊。在图 10 中,DATFuse 是效果最差的方法,因为它未能解决眩光问题,同时导致融合后人物背部的细节严重丢失。虽然 GTF 解决了眩光问题,但严重丢失了环境细节。MDLatLRR、DenseFuse、RFN-Nest 和 MTDFusion 减轻了眩光,但产生了低对比度,阻碍了环境信息的识别。YDTR、SwinFusion 和 MMIF-EMMA 提高了图像对比度并显著改善了关键目标的可见度,但它们并未解决眩光问题。EgeFusion 和 MPCFusion 有效解决了眩光问题并能识别环境信息,但融合图像缺乏平滑度并含有噪声。IFCNN-MAX 和我们的模型在眩光问题和环境纹理之间保持了良好的平衡。此外,我们的方法在图像对比度方面表现出色,使融合图像具有卓越的视觉体验。总之,我们的方法在白天和夜间道路场景中均表现出优异的性能。它保留了场景纹理细节和显著目标,同时确保了融合结果的高对比度,增强了场景元素的识别度。具体而言,在夜间,它减少了由眩光引起的场景元素丢失。这是通过融合网络的损失函数实现的,该函数在训练期间对纹理细节和结构特征进行约束。它确保了每个区域场景元素的高识别度,并利用红外图像的抗干扰特性来减轻眩光的影响。
2. 定量比较:
表 II 呈现了 RoadScene 数据集的定量分析结果,表明我们的方法在六个指标中排名前三。与 TNO 数据集相比,我们的模型在 SF 和 VIF 上的排名有所提升。这一成功归因于网络训练过程中损失函数对图像强度、显著性和结构特征施加的约束,以及通过适当的超参数对 LtextureL_{texture}Ltexture 和 LstructureL_{structure}Lstructure 进行的有效平衡。这些策略解决了 RoadScene 数据集中夜间眩光场景的融合问题。在保留眩光元素的同时,它们增强了眩光区域物体的结构和纹理,显著改善了视觉体验。虽然我们的方法在 SCD 和 SSIM 指标上并非最出色,但其排在前半部分,满足了对光谱和结构特征的常规要求。RoadScene 数据集上的实验结果最终证明,我们的方法非常适合白天和夜间条件下的道路场景图像融合任务。
E. LLVIP 数据集上的结果
1. 定性比较:
对于 LLVIP 数据集,我们选择了两组具有代表性的测试图像进行展示。图 11 和图 12 分别对应夜间正常光照和弱光条件下的道路场景。在图 11 中,MDLatLRR、DenseFuse、RFN-Nest、MTDFusion、DATFuse 和 MPCFusion 在表现弱光区域的车辆方面表现不佳。GTF 和 YDTR 改善了车辆细节和对比度,但丢失了行人和路面细节。EgeFusion、IFCN-MAX、SwinFusion、MMIF-EMMA 和我们的方法在阴影和明亮区域都平衡了目标细节和显著性。然而,在表现人行道细节方面,IFCN-MAX 和 SwinFusion 逊色于 EgeFusion、MMIF-EMMA 和我们的方法。在图 12 中,GTF、DenseFuse、MTDFusion、YDTR、DATFuse 和 MMIF-EMMA 较差地保留了人行道信息,导致严重的纹理丢失。MDLatLRR、IFCNN-MAX、RFN-Nest 和 MPCFusion 保留了可见的地面纹理,但受到阴影区域的阻碍,导致人物模糊或对比度低。EgeFusion、SwinFusion 和我们的方法在显著性和场景细节方面均表现出色,但 EgeFusion 在细节丰富度上超过了 SwinFusion 和我们的方法。总之,我们的方法有效地利用了红外图像的抗干扰特性,在阴影区域提供显著的目标信息。同时,它捕获了照明区域中可见光图像的纹理细节,提供了车辆、人员和路面等环境元素的详细特征。
2. 定量比较:
LLVIP 数据集上的定量分析结果呈现在表 III 中。我们的方法在六个指标中排名前二。具体而言,EN、SD、SCD、QAB/F、VIF 和 SSIM 的结果表明,我们的方法在提供最佳视觉体验的同时保留了源图像充足的原始特征。虽然 AG 和 SF 的结果并非最突出,但它们排在前半部分,表明我们的模型在保留纹理细节方面仍然表现良好。综上所述,实验结果表明我们的方法非常适合光照变化显著的夜间场景中的图像融合。融合结果有效地突出了关键目标信息,适合人类视觉观察。
F. 消融实验
1. 自编码器分析:
如图 13 所示,用 DTDM 完全替换 CNNM 会显著降低纹理细节表现,因为 DTDM 在编码局部浅层特征方面效果较差。相反,用 CNNM 完全替换 DTDM 会导致最差的对比度表现,因为 CNNM 难以编码全局特征。这些变化与表 IV 中的指标变化一致。当 DTDM 仅保留 EDenseE_{Dense}EDense 时,与最终模型的视觉差异很小,但大多数指标下降,仅有 QAB/F 和 VIF 略有改善,如表 IV 所示。仅保留 ESwinTE_{SwinT}ESwinT 改善了细节区域的融合,但降低了关键区域的显著性。在 ESwinTE_{SwinT}ESwinT 中,将图 3 中的 IRFNN 替换为 RFNN 会降低细节和显著性特征,而将 IRFNN 替换为 MLP 则会提高显著性,但由于引入了过多的红外特征而降低了视觉保真度。当采用单流编码器时,模型在栅栏的显著性方面取得了更好的融合结果,保留了更多的红外图像信息。然而,在场景细节方面的表现下降,因为依赖单一编码器难以实现红外和可见光特征的平衡编码。如表 IV 所示,与这些模型相比,最终模型在五个指标上取得了领先的结果,其中 QAB/F 和 VIF 接近最优。定性和定量结果均证实了我们自编码器结构设计的必要性。
2. 融合网络分析:
如图 14 所示,可学习的融合网络在保留人物显著性方面优于手动方法,但在图像对比度方面表现较差。手动方法在地面植被中保留了过多的红外特征,导致细节丢失和视觉效果不佳。表 V 显示,max、sum 和 L2-norm 融合在 SD 和 SCD 指标上表现出色,但在 AG、SF、QAB/F 和 VIF 上落后于可学习网络。与图 5(a) 中的 Fusion CNN 相比,我们的融合网络在保留环境细节方面表现出色,同时保持了相似的关键热目标显著性。如图 14 所示,当 AWAFM 不使用 CSA 进行特征权重分配或不使用 SWACmixT 进行特征融合时,它并没有显著降低保留显著信息的能力,但削弱了纹理细节和全局对比度。表 V 的结果显示,没有 CSA 或 SWACmixT 的 AWAFM 在 AG、SF 和 SD 指标上显著下降,这与图 14 中的发现一致。SWACmixT 整合了 CNN 和自注意力的优势,在编码全局特征方面提供了优于 CNN 的性能。因此,没有 SWACmixT 的 AWAFM 在全局对比度上的下降更为明显。
3. 损失函数分析:
由于自编码器和融合网络是分别使用独立的损失函数进行训练的,因此在针对 LautoL_{auto}Lauto 的消融实验中固定了 LfusionL_{fusion}Lfusion 的超参数,在针对 LfusionL_{fusion}Lfusion 的消融实验中固定了 LautoL_{auto}Lauto 的超参数。自编码器的损失函数涉及在训练期间设置超参数 α\alphaα 和 β\betaβ。如图 15 所示,随着 α\alphaα 的增加,融合图像中的人物显著性变得更加突出,当 α\alphaα 达到 2 时趋于稳定。随着 β\betaβ 的增加,灌木丛和招牌等环境细节变得更加明显,在 β=10\beta = 10β=10 时达到顶峰。超过此值,灌木丛细节会失真,招牌清晰度下降。表 VI 的结果显示,随着 α\alphaα 和 β\betaβ 的增加,模型平衡了各项指标,在 α=2\alpha = 2α=2 且 β=10\beta = 10β=10 时达到最佳融合,在六个指标中排名前二。融合网络的损失函数涉及在训练期间设置超参数 γ\gammaγ。在图 16 中,当 γ\gammaγ 太小时,对图像显著性的约束会减弱,导致长椅的识别度不足。当 γ\gammaγ 达到 0.1 时,对纹理细节和显著性的约束达到平衡,在优化灌木丛细节的同时保持了较高的长椅识别度。在表 VII 中,当 γ=0.1\gamma = 0.1γ=0.1 时,模型在所有指标中均排名前二,进一步支持了先前的分析结论。总之,设置 α=2\alpha = 2α=2、β=10\beta = 10β=10 和 γ=0.1\gamma = 0.1γ=0.1 可实现最佳的融合结果。
4. 训练策略分析:
在这部分中,我们采用一阶段训练策略,并结合融合网络的损失函数对模型进行重新训练。如图 14 所示,采用一阶段策略的模型在融合图像的显著性和细节方面均有所下降,其中细节的模糊更为明显。在表 VIII 中,与最终模型相比,一阶段训练策略在 QAB/F 和 VIF 上有所提升。在一阶段策略中,解码器使用融合特征进行训练,这更好地符合解码器重建融合图像的作用。因此,它生成了视觉上更好的融合图像。一阶段策略未能严格区分网络中各组件的作用,这降低了组件(尤其是编码器)的训练有效性。结果,模型在 EN、AG、SF、SD 和 SCD 方面出现了显著下降,最终性能不如采用两阶段训练策略的模型。
5. 下采样分析:
为了证明下采样策略的优势,我们移除了它并重新训练模型。如图 14 所示,没有下采样的模型在人物显著性和树木纹理上表现均较差,纹理表现尤为欠缺。在表 VIII 中,没有下采样的模型在所有指标上均出现下降。这是因为在训练 epoch 数量有限的情况下,DTDM 难以有效处理大尺度特征。此外,没有下采样的模型运行时间显著增加。因此,采用下采样策略的模型在性能和可用性方面均优于替代方案。
G. 计算复杂度
如表 IX 所示,与传统方法相比,我们的方法具有显著的运行时间优势。然而,与不使用 Transformer 的方法相比,它逊色于使用人工设计融合策略的 DenseFuse 和 IFCNN-MAX,这赋予了它们在运行时间上的优势。在基于 Transformer 的方法中,DATFuse 因其更简单的 Transformer 结构而在运行时间上表现出色,但牺牲了融合质量。相比之下,我们的方法平衡了融合质量和运行时间。在基于 Transformer 的方法中,我们的方法在三个数据集的运行时间均排在前半部分,这归因于我们的下采样策略:CNNM 处理大尺度特征,而 DTDM 处理小尺度特征。为了调查
H. 目标检测评估
为了证明我们的方法在高级计算机视觉任务上的有效性,我们在目标检测方面进行了实验。实验中使用的目标检测模型是 SOTA 检测器 YOLOv5,使用 mAP@0.5 指标来评估检测性能。实验数据集 M3FD 包含六个目标类别:公交车、汽车、路灯、摩托车、行人和卡车。实验环境与融合实验一致。训练进行 400 个 epoch,批量大小为 8,使用 SGD 优化器,初始学习率为 1e-2。使用这些设置,YOLOv5 分别在融合结果和源图像上进行训练。
1. 定性比较:
三个典型场景的目标检测结果涵盖了 M3FD 数据集中的所有标注目标,证明了各种方法对目标检测任务的增强效果。图 17 显示了在简单道路场景下的 YOLOv5 目标检测结果。所有的融合方法都能在这种设置下检测出人和车辆目标。与源图像的结果相比,所有方法的检测概率均有所提高。值得注意的是,使用我们方法的融合图像中所有目标的检测概率至少为 0.9,表明我们的方法相对稳定地改善了目标检测。图 18 显示了在复杂道路场景下的目标检测结果。只有 YDTR 和我们的融合图像正确识别了公交车两侧的汽车,且我们的结果实现了更高的检测置信度。这凸显了我们的方法在融合小物体和被遮挡物体方面的优势,确保了其基本特征得以保留。图 19 显示了具有近距离目标的道路场景。对于近距离重叠的目标,RFN-Nest、YDTR 和 MMIF-EMMA 的融合图像出现了误检。与其他方法相比,我们的方法显示出更高的平均检测概率,表明它在融合近距离和重叠目标方面取得了更好的效果。
2. 定量比较:
如表 X 所示,我们的方法在提高道路场景中小机动车辆(尤其是汽车和摩托车)的检测能力方面表现出色。虽然它在其他目标上并未取得最佳结果,但优于大多数类别的最差结果,证明了其对各种目标的稳定融合。这一优势确保了在不同检测场景下的高级视觉任务中保持一致的性能,同时将小型机动目标的漏检或误检降至最低。在所有类别的目标检测中处于领先的 mAP@0.5 进一步支持了这一结论。
V. 结论
在本文中,我们提出了一种基于注意力机制的自适应多尺度红外与可见光图像融合网络,称为 AMSFusion。具体而言,我们设计了 CNNM、DTDM 和跳跃连接,以增强模型的特征提取、特征重建和计算效率。然后,我们使用由 CSA 和 SWACmixT 组成的融合网络实现了不同尺度特征的自适应融合。最后,我们采用两阶段训练策略来提高模型提取和融合多尺度特征的能力。通过在多个数据集上的大量实验,我们证明了我们的方法与十二种 SOTA 方法相比,在性能、泛化能力和可用性方面的优势。此外,目标检测中的实验证明我们的方法显著增强了高级计算机视觉任务的性能。在未来的工作中,我们计划探索该方法在其他领域的应用,如星光条件下的红外与可见光图像融合、多曝光以及多焦点图像融合。