拆解 Hermes Agent 学习闭环,用 LangGraph 实现 Self-Improving Agent 设计模式
Nous Research 的 Hermes Agent(33k+ stars)最核心的不是工具多,而是它的学习闭环------执行完任务自动提取可复用 Skill,下次直接调用并改进。
本文拆解这个架构,并用 LangGraph StateGraph 实现为一个可复用的设计模式。完整代码 ~300 行,可以直接嵌入你的项目。
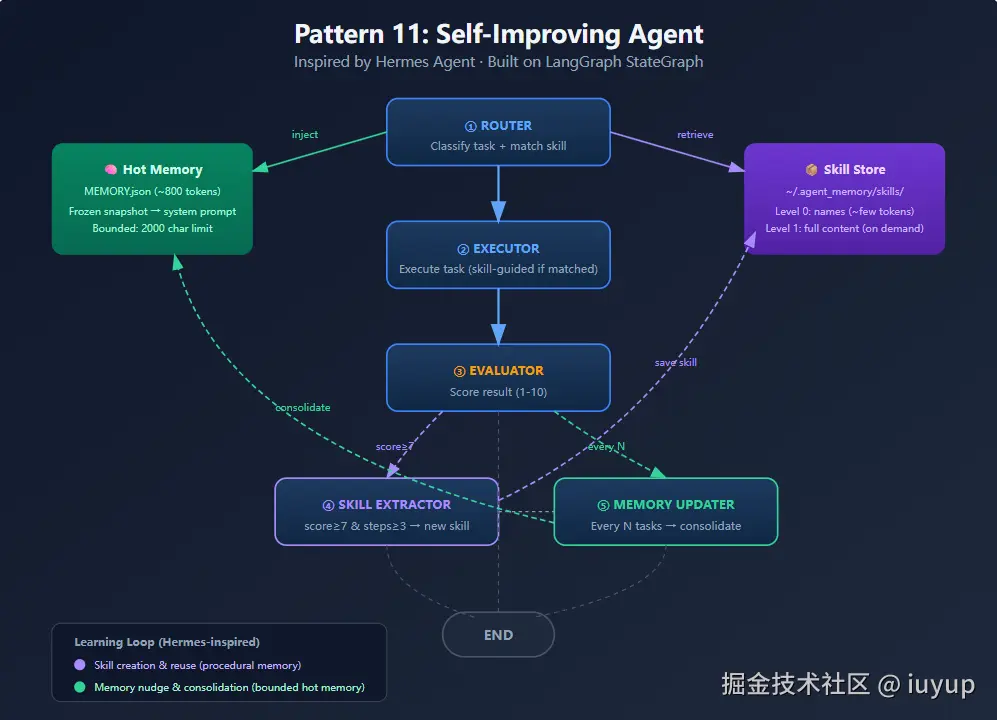
核心问题:Agent 为什么要分层记忆?
传统做法:历史对话全塞 context window → token 线性增长 → 截断丢信息 or 全塞费钱。
Hermes 的做法:按访问频率分层,和 CPU 缓存/内存/磁盘一个道理。
| 层级 | 存储 | 大小 | 加载时机 |
|---|---|---|---|
| L1 | MEMORY.md | ~800 tokens | session 开始,冻结快照注入 system prompt |
| L2 | USER.md | ~500 tokens | 同上,用户偏好 |
| L3 | SQLite FTS5 | 无限 | 按需全文检索 |
| L4 | Skills/ | 渐进加载 | Level 0 名称 → Level 1 全文 |
关键设计决策:
有界 = Feature,不是 Bug。 MEMORY.md 硬限 2200 字符,满了必须整合后才能添加新条目。强制高信噪比。
冻结快照。 session 开始读一次,执行期间不变。配合 Anthropic prompt caching,后续调用命中前缀缓存省 token。
渐进式加载。 643+ skill 不可能全塞 context。默认只加载名称索引(~几百 token),匹配到才加载全文。
学习闭环怎么触发?
javascript
任务完成 → Evaluator 打分(1-10)
→ score ≥ 7 且 steps ≥ 3 且没有复用已有 skill
→ Skill Extractor 提取方法为结构化 JSON
→ 存入 Skill Store
→ 下次 Router 匹配 → Executor 加载 skill 执行 → 根据新评分更新统计每 N 个任务触发 Periodic Nudge:LLM 审视记忆,整合重复,清理过期。
核心:记住方法(Procedural Memory),不是事实。
LangGraph 实现
5 个节点,条件边控制流程:
sql
Router ──→ Executor ──→ Evaluator ──┬──→ Skill Extractor ──→ END
├──→ Memory Updater ──→ END
└──→ ENDState
python
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
task: str
task_type: str
matched_skill: Optional[dict]
execution_steps: list[str]
result: str
evaluation_score: float
should_create_skill: bool
should_update_memory: bool
task_count: intMemoryStore
python
class MemoryStore:
memory_char_limit = 2000 # L1 热记忆硬上限
def get_memory_snapshot(self) -> str:
"""冻结快照注入 system prompt"""
def get_skill_index(self) -> list[dict]:
"""Level 0: 名称 + 描述 + 统计(几百 token)"""
def get_skill(self, name: str) -> Optional[dict]:
"""Level 1: 完整内容(匹配后才调用)"""
def save_skill(self, skill: dict): ...
def update_skill_stats(self, name: str, score: float):
"""滑动平均更新评分,低分 skill 自然淘汰"""
def consolidate_memory(self, entries: list[str]):
"""Nudge: 整合替换所有记忆条目"""触发条件
ini
should_create = (
score >= 7.0 # 高质量
and num_steps >= 3 # 足够复杂
and not state["matched_skill"] # 不是在复用已有 skill
)Skill 数据结构
json
{
"name": "python_code_review",
"description": "Review Python code for bugs, security issues, and style",
"task_type": "code_review",
"procedure": "1. Check security → 2. Check logic → 3. Check performance",
"pitfalls": "Don't just look at syntax, check for race conditions in async code",
"verification": "Ensure every finding has a concrete fix suggestion",
"use_count": 3,
"avg_score": 8.2
}三个关键字段:procedure (方法序列)、pitfalls (踩坑记录)、verification(验证标准)。
Skill 复用
Executor 节点把匹配到的 skill 注入 prompt:
ini
if state.get("matched_skill"):
skill_guidance = f"""
Procedure: {skill['procedure']}
Pitfalls to avoid: {skill['pitfalls']}
Verification: {skill['verification']}
"""
# 注入 prompt 引导执行,LLM 仍可偏离,但质量和一致性显著提高Skill 自我改进
ruby
def update_skill_stats(self, skill_name, score):
skill["use_count"] += 1
skill["avg_score"] = running_average(old_avg, new_score)
# Router 优先匹配高分 skill → 低分自然淘汰 → 简化版"自然选择"条件边路由
perl
def after_evaluator(state):
if state["should_create_skill"]:
return "skill_extractor" # 高分复杂任务
if state["should_update_memory"]:
return "memory_updater" # nudge 周期到了
return END # 普通任务直接结束
graph.add_conditional_edges("evaluator", after_evaluator)大多数任务只走 3 个节点(Router → Executor → Evaluator → END),skill 提取和记忆整合是低频事件。
对比 Hermes 原版
| 特性 | Hermes Agent | AgentFlow 实现 |
|---|---|---|
| 记忆层数 | 4层 + 外部 provider | 2层 |
| 技能格式 | agentskills.io Markdown | JSON |
| 编排引擎 | 同步单循环 9200 行 | LangGraph StateGraph ~300 行 |
| User Modeling | Honcho | 未实现 |
| 定位 | 完整产品 | 可组合设计模式 |
快速使用
python
from self_improving_agent import create_self_improving_agent
from langchain_openai import ChatOpenAI
agent = create_self_improving_agent(
llm=ChatOpenAI(model="gpt-4o-mini"),
storage_dir="./my_agent_memory",
nudge_interval=10,
skill_threshold=7.0,
)
result = agent.invoke({
"messages": [HumanMessage(content="Review this Python code for security issues")],
"task": "Review this Python code for security issues",
"task_type": "",
"matched_skill": None,
"execution_steps": [],
"result": "",
"evaluation_score": 0,
"should_create_skill": False,
"should_update_memory": False,
"task_count": 0,
})总结
Hermes Agent 架构的四个核心原则,适用于任何 Agent 系统:
- 有界热记忆 --- 强制高信噪比,不是越大越好
- 程序性记忆 --- 记住方法,不是事实
- 渐进式加载 --- token 预算换技能规模
- 周期性自省 --- 定期整理,记忆才有质量
完整代码在 AgentFlow,第 11 个设计模式。
🔗 GitHub : github.com/iuyup/Agent...
如果觉得有用,点个赞👍收个藏⭐,GitHub 上也欢迎 star 支持一下。有问题评论区交流。