Agent 工程化系列 · 第 13 篇
Agent 的安全与可靠性如何保障?
Agent 最危险的不是回答错,而是执行错
开篇定位
前面我们已经讲过:LLM 是能力核心,Agent 是执行系统;Function Call 让模型能够调用工具;MCP 负责连接工具生态;A2A 负责 Agent 之间协作;Memory 让 Agent 具备连续上下文。
到了这一篇,要进入一个更现实的问题:Agent 能不能安全、稳定地上线?
很多 Agent Demo 看起来很厉害:会查资料、会写代码、会调用工具、会自动执行任务。但一旦进入真实业务环境,问题马上变得复杂。
因为 Agent 不只是回答问题,它可能会读文件、写数据库、发邮件、调接口、改代码、下单、审批、甚至操作生产系统。
所以这篇不是讲"如何让 Agent 更聪明",而是讲另一个工程问题:
如何让 Agent 在会做事的同时,不乱做事?
目录
- 01 为什么 Agent 比 Chatbot 更危险?
- 02 Agent 的风险来自哪里?
- 03 第一条防线:权限最小化
- 04 第二条防线:工具调用前后校验
- 05 第三条防线:Human-in-the-loop
- 06 可靠性不是安全,但同样重要
- 07 一个可落地的安全可靠性架构
- 08 最后总结
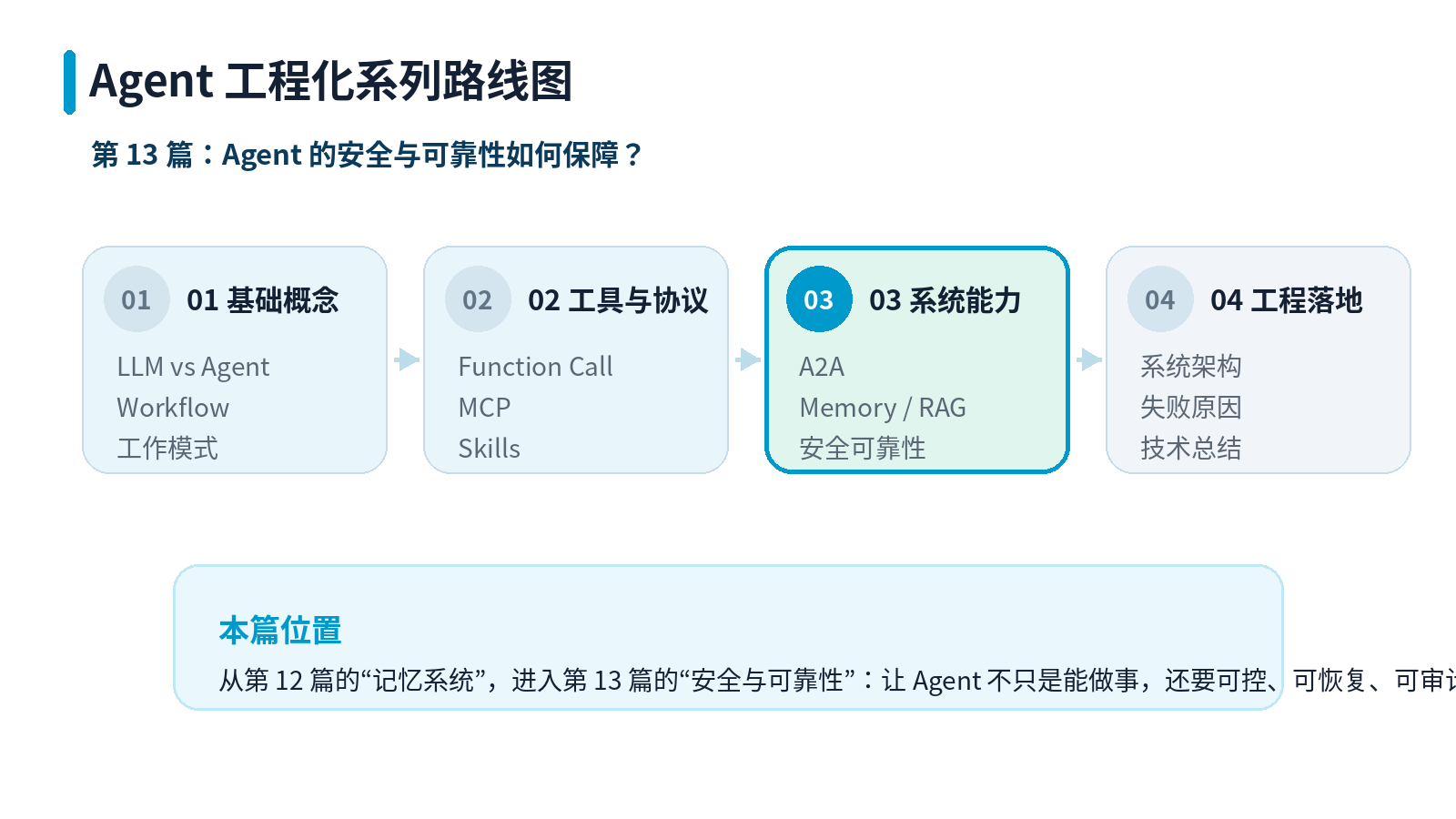
01 为什么 Agent 比 Chatbot 更危险?
普通聊天机器人回答错了,最多是给了一段错误信息。
但 Agent 不一样。Agent 通常连接了工具和外部系统,一旦判断错,可能真的会执行动作。
比如:
用户只是想让它"整理一下文件",它可能误删目录。
用户只是想让它"总结邮件",它可能把隐私内容转发出去。
用户只是想让它"修复一个问题",它可能直接改动生产配置。
这就是 Agent 和普通 LLM 应用最大的安全差异。
一个核心判断
安全风险不是从"回答"开始的,而是从"行动"开始的。
只要 Agent 能调用工具、访问文件、写数据库、发送消息、执行命令,它就不再只是一个文本生成系统,而是一个带执行能力的软件系统。
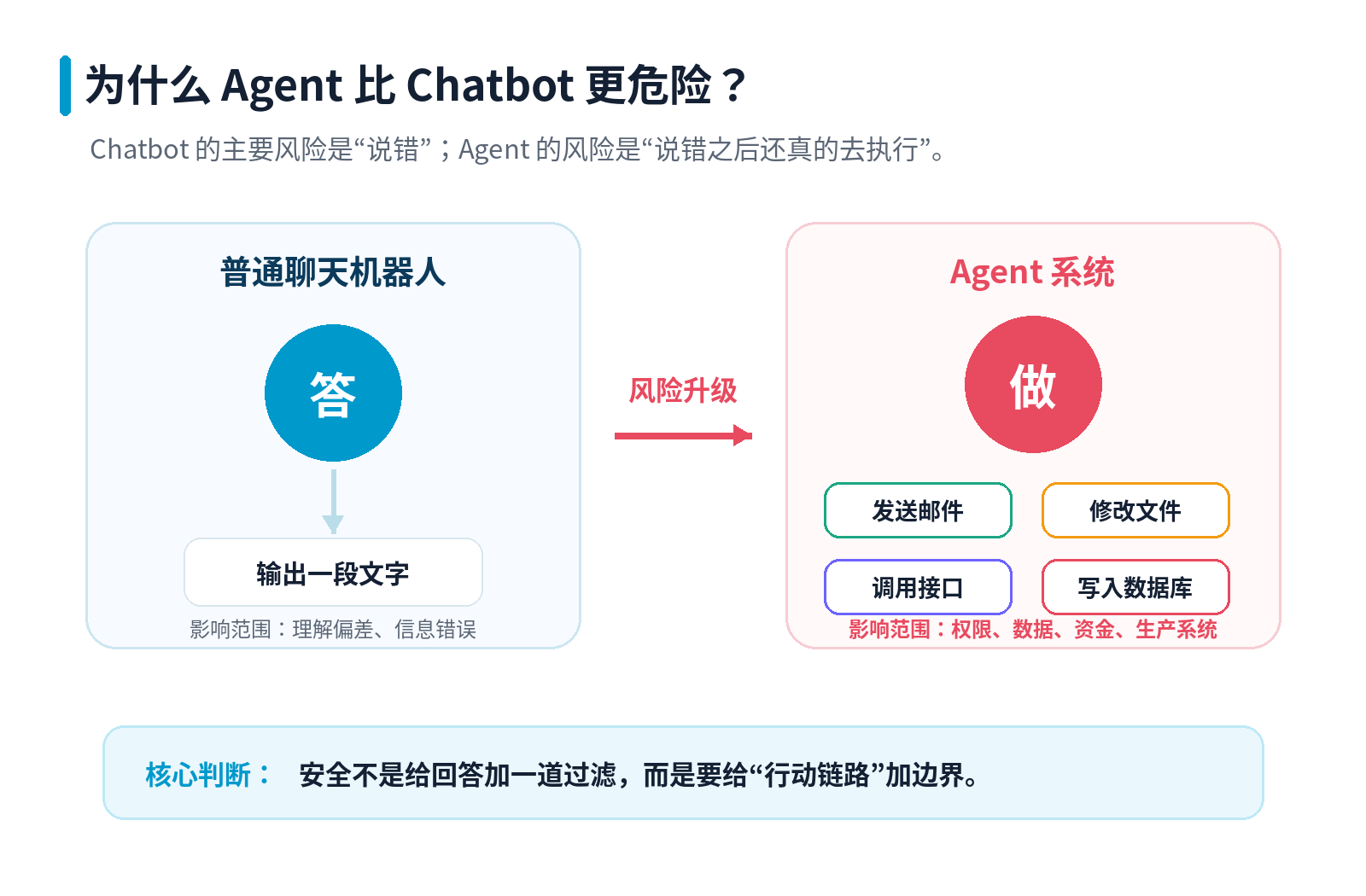
02 Agent 的风险来自哪里?
Agent 的风险通常不是单点问题,而是一条链路问题。
一个用户输入、一段网页内容、一个工具返回结果、一次错误权限配置,都可能影响 Agent 下一步动作。
常见风险可以分成五类。
第一类:提示词注入
提示词注入就是外部输入改变模型行为。
它可能来自用户直接输入,也可能藏在网页、邮件、PDF、图片、代码注释、工具返回结果里。
这类风险对 Agent 特别危险,因为 Agent 会把外部内容放进上下文,再基于这些内容决定下一步动作。
OWASP 对 Prompt Injection 的定义也强调:攻击者可以通过输入改变 LLM 的行为或输出,甚至影响关键决策、诱导未授权访问和连接系统中的命令执行。
第二类:权限过大
很多 Agent 出问题,不是因为模型太差,而是因为系统给了它太大的权限。
本来只需要读文件,却给了读写删权限。
本来只需要查数据库,却给了更新和删除权限。
本来只需要在测试环境执行,却给了生产环境访问权限。
这就是 OWASP 所说的 Excessive Agency:功能过多、权限过大、自治程度过高,都会让 LLM 系统执行破坏性动作。
第三类:工具污染
工具返回的内容也不一定可信。
比如搜索网页返回了一段隐藏提示词,邮件内容里藏了"忽略前面的规则",MCP Server 返回了带指令的文本。
如果 Agent 不区分"数据"和"指令",就可能把工具结果里的恶意文本当成新的系统命令。
第四类:敏感信息泄露
Agent 经常需要访问用户文件、企业知识库、邮件、客户数据和系统日志。
如果没有权限隔离、脱敏、输出检查,它可能把不该展示的信息带到回答里,或者传给不该调用的外部工具。
第五类:执行循环失控
Agent 不是一次调用就结束,它可能循环执行:思考、调用工具、读取结果、再调用工具。
如果没有终止条件、超时、预算和错误收敛机制,就会出现无限循环、成本飙升、接口打爆、任务卡死。
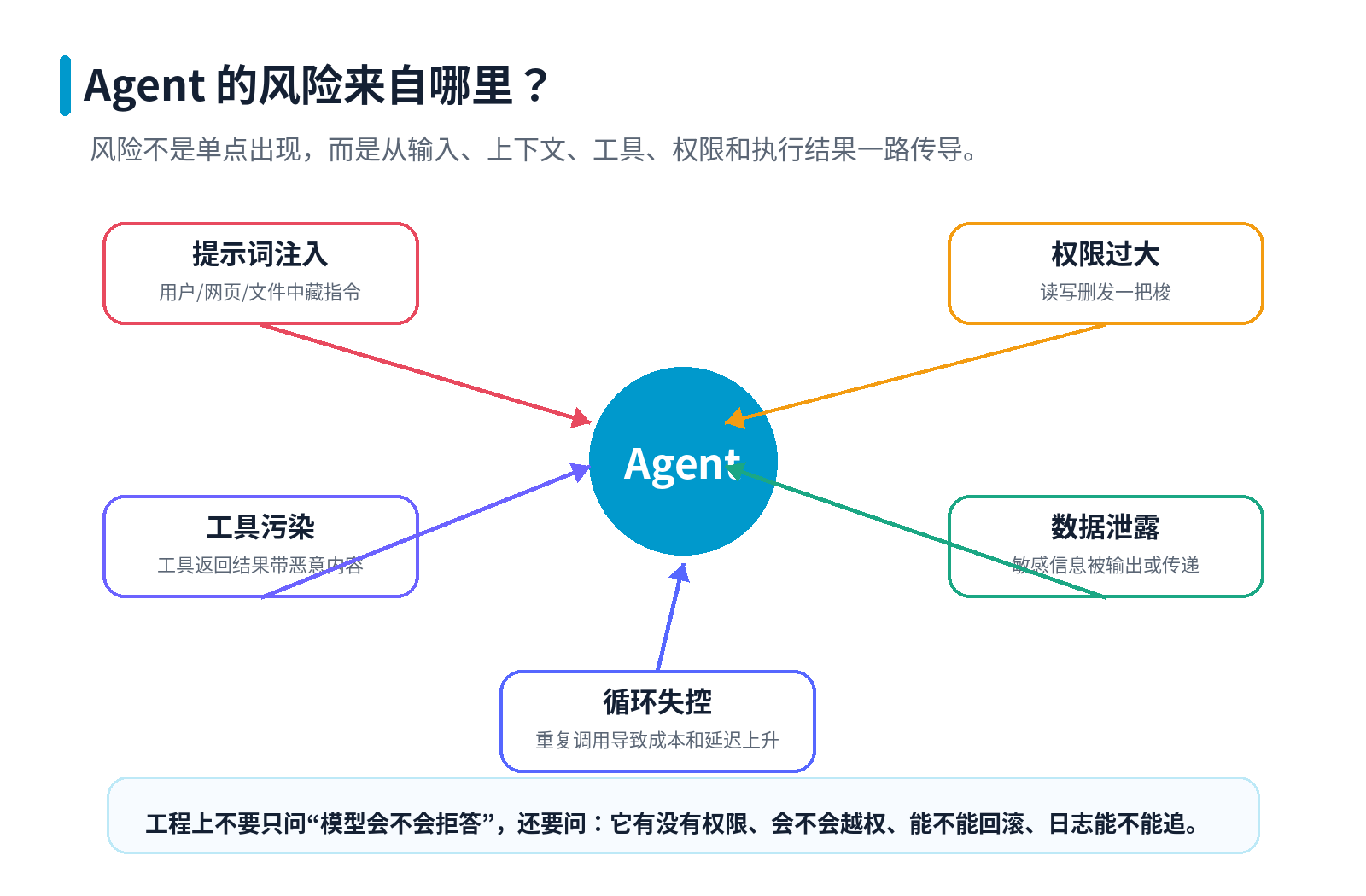
03 第一条防线:权限最小化
Agent 安全的第一原则,不是"让模型更听话",而是:不给它不该有的能力。
工程上要先把能力拆开,再按任务授权。
比如文件工具,不应该只有一个"操作文件"的大工具,而应该拆成:读取文件、列目录、写入新文件、修改文件、删除文件。
其中读取可以低风险,删除必须高风险审批。
再比如数据库工具,不应该让 Agent 直接拿一个高权限账号连接数据库。查询类任务只给 SELECT 权限,更新类任务需要单独授权,删除类任务最好不要直接暴露给 Agent。
权限最小化的四个层次
| 层次 | 要控制什么 | 工程做法 |
|---|---|---|
| 工具最小化 | 只暴露必要工具 | 不需要的工具不注册给 Agent |
| 功能最小化 | 工具只做一件事 | 不用一个万能 Shell 代替专用工具 |
| 权限最小化 | 只给必要权限 | 读写分离、按用户身份执行 |
| 自治最小化 | 高风险动作不自动执行 | 删除、发送、付款、上线必须审批 |
这几个原则听起来朴素,但非常关键。
因为一旦模型判断错,真正决定损失大小的,往往不是模型本身,而是它能碰到什么系统、能做什么动作。
04 第二条防线:工具调用前后校验
只做权限控制还不够。
Agent 调工具之前,要校验参数;工具执行之后,也要校验结果。
OpenAI Agents SDK 的 Guardrails 文档把防护分成输入、输出和工具相关的校验。其中 Tool Guardrails 可以在函数工具执行前后运行:执行前可以跳过、替换结果或触发中断,执行后也可以替换输出或触发中断。
这对 Agent 很重要。因为很多风险不是发生在最终回答,而是发生在工具调用那一刻。
工具调用前要检查什么?
第一,参数格式是否合法。
比如 city 是否是字符串,amount 是否是正数,file_path 是否在允许目录内。
第二,参数内容是否越权。
比如用户只能访问自己的订单,却请求查询别人的订单。
第三,动作风险等级是否过高。
比如 delete、send、pay、deploy、update_permission 这类动作,不能静默执行。
第四,是否存在注入风险。
比如 Shell 命令、SQL 参数、URL、文件路径,都要做白名单和转义处理。
工具执行后要检查什么?
第一,工具返回是否包含敏感信息。
第二,返回结果是否可信。
第三,是否包含新的恶意指令。
第四,是否需要摘要、脱敏、截断后再给模型。
一个重要原则
不要把所有安全责任都压到 Agent Prompt 里。
Prompt 可以提醒模型不要越权,但真正可靠的安全边界,应该放在代码、权限、网关、沙箱和审批流程里。
05 第三条防线:Human-in-the-loop
Human-in-the-loop 不是为了降低自动化水平,而是为了把高风险动作控制在可接受范围内。
一个成熟 Agent 系统应该区分三类动作。
第一类是低风险动作,可以自动执行。
比如读取公开资料、查询天气、生成草稿、总结文档。
第二类是中风险动作,可以自动准备,但需要用户确认。
比如修改文件、创建日程、发送内部消息。
第三类是高风险动作,必须强制审批。
比如删除数据、外发邮件、付款、发布生产环境、修改权限、执行 Shell 命令。
OpenAI 的 Guardrails and Human Review 文档中也描述了类似的审批生命周期:工具调用需要审查时,系统记录审批中断,返回 interruptions 和可恢复 state,应用批准或拒绝后,再从同一 state 继续运行。
这说明审批不是"重新开始一次对话",而是 Agent 执行链路中的一个状态暂停点。
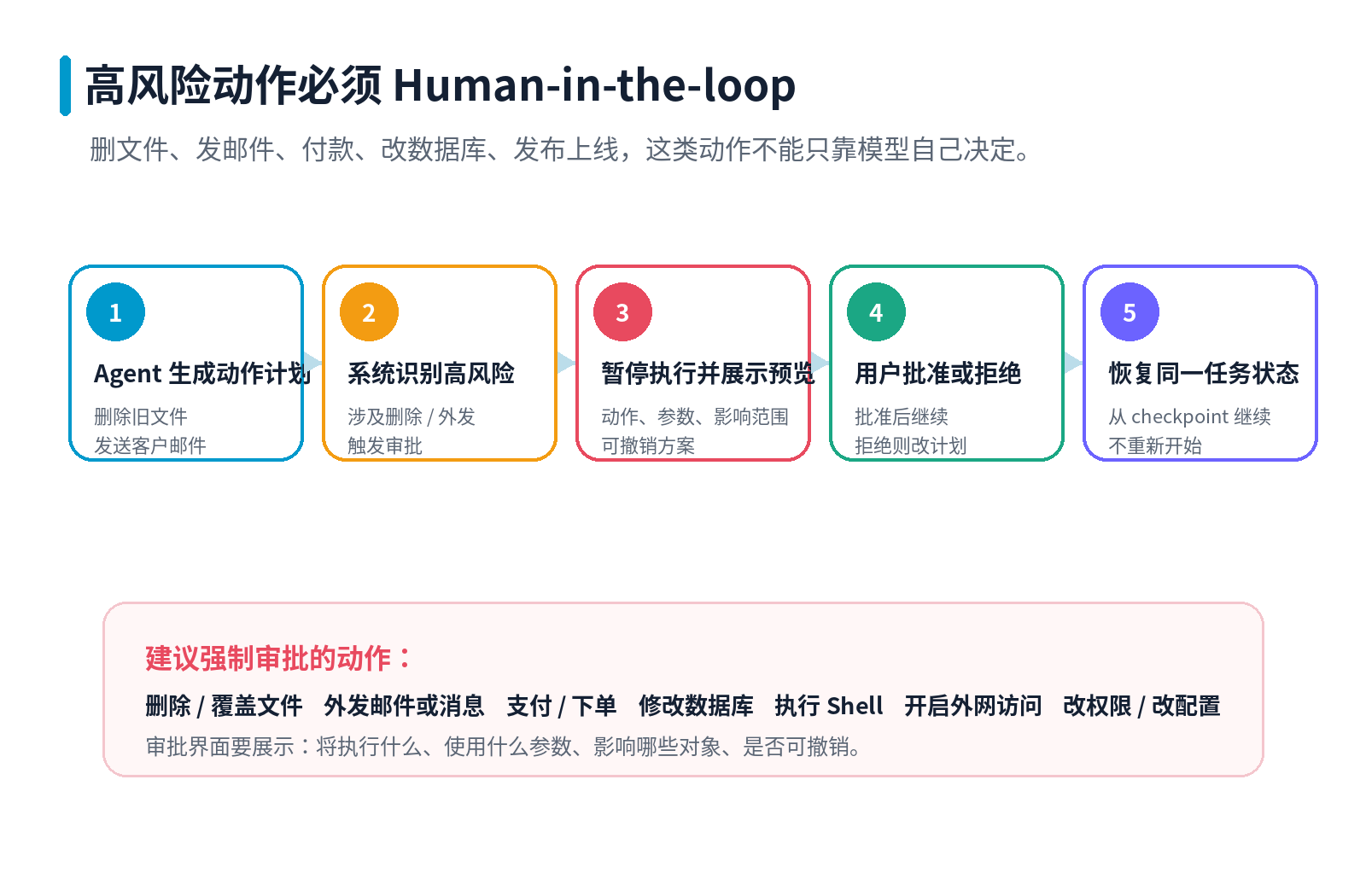
审批界面应该展示什么?
不要只给用户一个"是否同意"的按钮。
审批界面至少要展示:
- Agent 准备做什么动作
- 使用了哪些参数
- 会影响哪些对象
- 是否可撤销
- 如果不批准,替代方案是什么
- 这次动作由哪个用户、哪个任务、哪个工具触发
只有这样,用户才是在做有效审批,而不是机械地点"同意"。
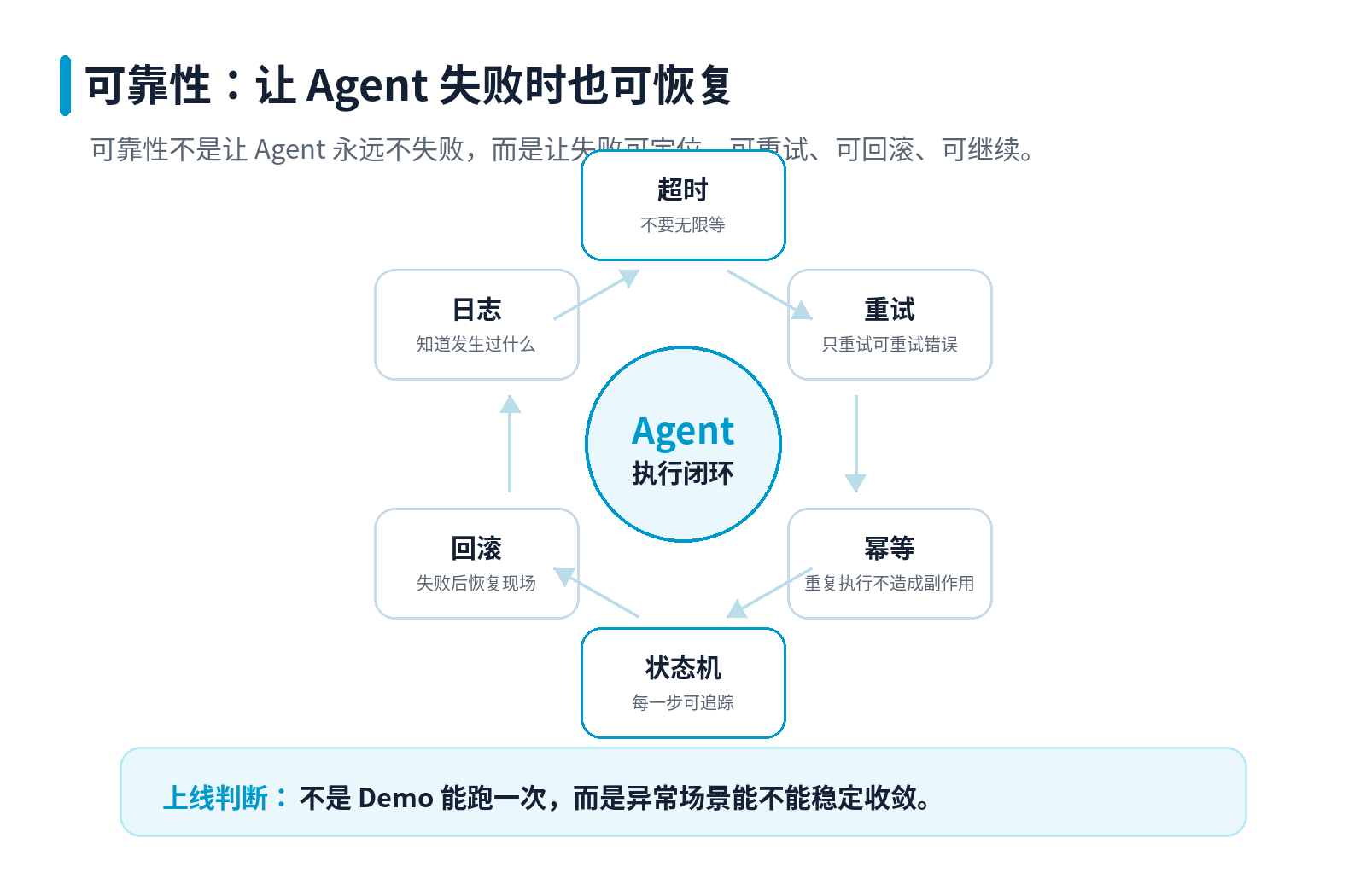
06 可靠性不是安全,但同样重要
安全解决的是:Agent 不要做危险的事。
可靠性解决的是:Agent 做事时,不要卡死、乱重试、重复执行、失败不可恢复。
这两者经常被混在一起,但工程上要分开设计。
Agent 可靠性的六个关键点
第一,超时
每次模型调用、工具调用、外部 API 调用都要有超时。
没有超时,Agent 就可能一直等下去。
第二,重试
重试只能用于临时失败,比如网络抖动、限流、服务短暂不可用。
不能对所有失败都盲目重试。比如参数错误、权限错误、业务规则不满足,重试多少次都没用。
第三,幂等
只要动作有副作用,就要考虑幂等。
比如创建订单、发送邮件、写数据库、触发流程,如果 Agent 因为超时重试,不能造成重复下单、重复发送、重复扣款。
第四,状态机
复杂任务不要只存在模型上下文里。
应该把任务拆成明确状态:待开始、执行中、等待审批、已完成、失败、已回滚。
这样任务失败后才能知道卡在哪一步。
第五,回滚
不是所有动作都能回滚,但至少要知道哪些动作可以撤销,哪些动作不可撤销。
不可撤销动作更应该强制审批。
第六,日志与追踪
Agent 每一次计划、工具调用、审批、失败、重试、输出,都应该留下日志。
否则一旦出问题,你很难回答三个问题:它为什么这么做?调用了什么工具?影响了哪些数据?
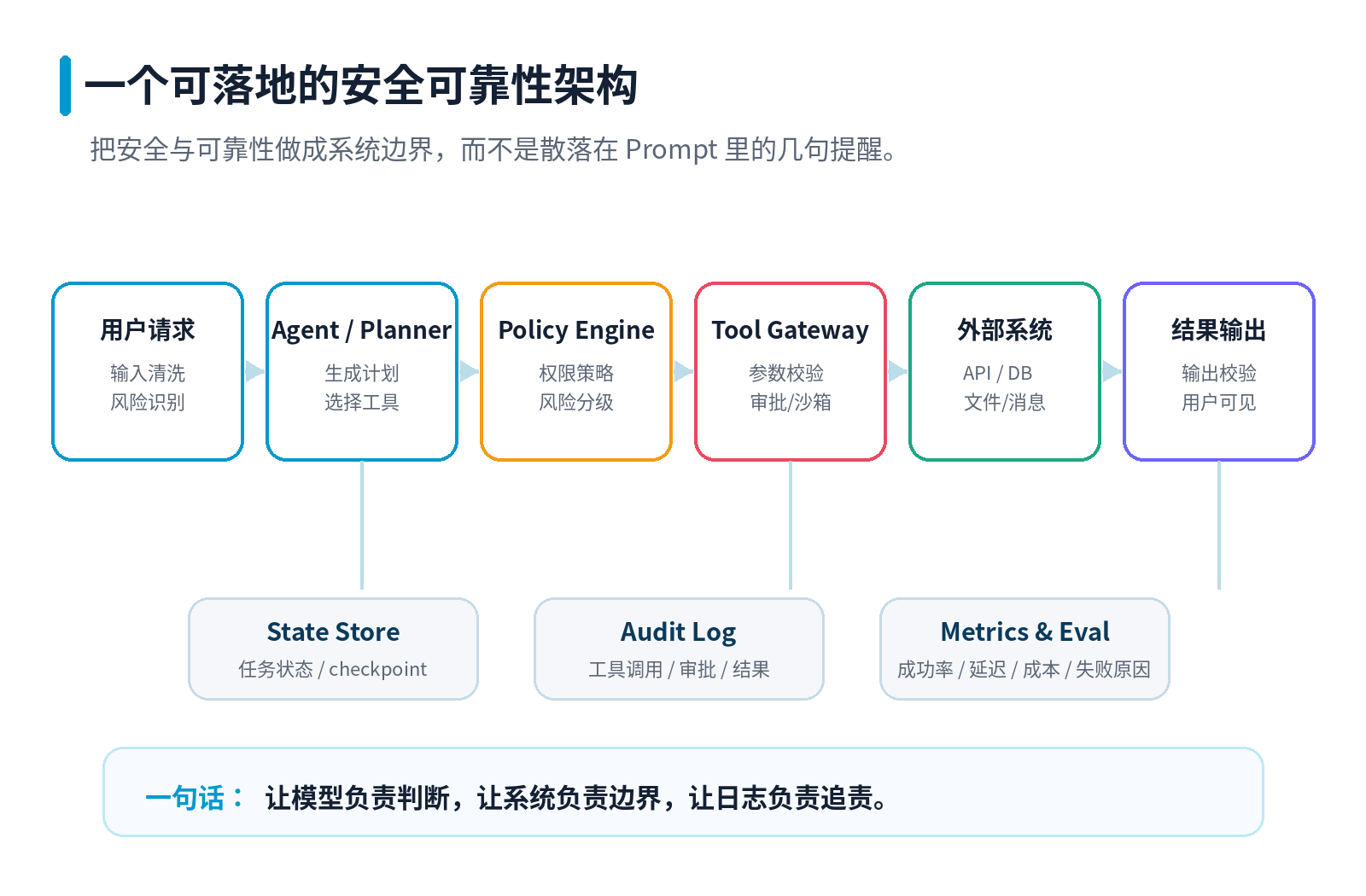
07 一个可落地的安全可靠性架构
如果把前面的内容落成架构,可以拆成七层。
第一层是输入边界,负责输入清洗、风险识别、上下文来源标记。
第二层是 Agent / Planner,负责理解目标、制定计划、选择工具。
第三层是 Policy Engine,负责判断当前用户、当前任务、当前工具调用是否有权限。
第四层是 Tool Gateway,负责参数校验、工具白名单、限流、超时、重试、审计和审批触发。
第五层是 Sandbox / External System,负责把高风险动作限制在可控环境内。
第六层是 Output Checker,负责敏感信息过滤、格式校验、结果一致性检查。
第七层是 Observability,负责日志、指标、追踪、评估和告警。
最小可落地版本
如果你现在只是做一个早期 Agent 产品,不一定要一次性做完所有能力。
但至少应该先做到这五件事:
- 工具分级:读、写、删、发、付、执行命令分开
- 权限隔离:按用户、项目、租户控制访问范围
- 高危审批:删除、外发、付款、上线必须暂停确认
- 状态持久化:复杂任务能暂停、恢复、重试
- 日志审计:每次工具调用都能追踪到用户、参数和结果
这五件事做完,Agent 才开始具备工程上线的基础。
08 最后总结
Agent 的安全与可靠性,不是给模型多写几句"请谨慎操作"。
真正的安全来自边界设计:最小权限、工具校验、风险分级、人工审批、沙箱隔离、输出检查、日志审计。
真正的可靠性来自执行设计:超时、重试、幂等、状态机、checkpoint、回滚、可观测性。
如果说前面几篇讲的是 Agent 如何获得能力,那么这一篇讲的是:
能力必须被关进工程边界里,Agent 才能从 Demo 走向生产。
下一篇,我们会继续讲一个和 Agent 落地密切相关的问题:RAG 和 Agent 到底是什么关系。
参考技术资料
- OpenAI Agents SDK - Guardrails:输入、输出和工具级 Guardrails 的执行边界与触发机制。
- OpenAI API - Guardrails and Human Review:高风险工具调用的审批中断、state 恢复和继续执行机制。
- OWASP Top 10 for LLM Applications:Prompt Injection、Insecure Output Handling、Excessive Agency 等 LLM 应用风险。
- OWASP LLM06:2025 Excessive Agency:功能过多、权限过大、自治过高会导致破坏性动作。
- Anthropic - Claude Code Security:权限系统、沙箱、网络请求审批、提示词注入防护和审计建议。
- Anthropic - Mitigating Prompt Injection in Browser Use:浏览器 Agent 面临更大的不可信内容攻击面,提示词注入仍不是已解决问题。