大多数 AI 应用在刚开始时,都会在代码中硬编码一个模型。对于原型开发来说,这运行得很好,但一旦单个端点需要处理多个复杂的任务类别,这种模式就会分崩崩离析。分类、紧急程度评分、面向客户的草稿以及长篇总结,这些任务由于成本、延迟或质量要求各不相同,都能够从不同的模型选择中获益。
支持工单的分流(Support Triage)就是最典型的例子。当用户输入"如何重置密码?"时,你为每个 Token 支付的费用,与处理一个粘有海量日志、来自企业客户的多段落升级工单是一样的。你当然可以在应用代码中根据工单类型进行分支判断,并为每个分支选择不同的模型,但这样一来,你的模型选择逻辑就混在了业务处理程序中,你的兜底策略(Fallback Strategy)变成了 try/except 代码块,而且每次价格变动都意味着需要重新部署应用。其后果就是:你可能会用一个 70B 的模型去对只有几个词的工单进行分类;当该模型变慢时没有任何兜底方案;以及每次价格调整时都必须重新部署代码。
在本教程中,我们将使用通过 DigitalOcean 推理路由器(Inference Router)实现的无服务器推理(Serverless Inference) ,轻松快速地构建一个 FastAPI 支持工单分流端点,一次性解决所有这些问题。到最后,你将能够自动将分类、紧急程度评分、客户回复和升级总结路由到最适合的模型上------这一切都是自动完成的,内置了兜底机制,且应用代码中不会出现任何一个具体的模型名称。最终,你将拥有一个生产级别的 API,其成本比在单一前沿模型上运行所有任务要便宜 71%。
构筑目标
让我们构建一个单一的端点:POST /triage,它接收工单数据并返回:
- 分类(Classification):问题类别(账单、Bug、指南、账户等)
- 紧急程度 + 情感(Urgency + Sentiment):严重程度评分以及对客户情绪的解读
- 回复草稿(Drafted Reply):简短的、面向客户的回复
- 升级总结(Escalation Summary):为人工客服提供的结构化简报(仅在工单足够复杂、需要升级时才会生成)
架构演变如下:
应用 → 硬编码模型(一个模型处理所有任务)转变为:
应用 → 通过推理路由器进行无服务器推理 → 每个任务匹配最合适的模型正是这个推理路由器,使得第二种架构成为可能,而你的应用甚至不需要知道存在哪些模型。
无服务器推理与 DigitalOcean 推理路由器
推理路由器 允许你定义任务(Tasks)和模型池(Model Pools),然后根据这些任务定义和选择策略,将输入的提示词(Prompts)路由到最合适的模型。任务是一个带有描述的命名工作,例如:classify_ticket。模型池是路由器可以为该任务挑选的候选模型集合,由选择策略(最低成本、最低延迟、手动设置的排名或兜底顺序)来控制。你只需在路由器层配置一次,应用就会调用路由器,而不是任何特定的模型。
无服务器推理让你无需创建 AI 智能体(Agent)或操心基础设施管理,即可向模型发送 API 请求。这能让你快速上手,无需管理推理端点背后的任何组件。
该 API 接口与 OpenAI 兼容。基础 URL(Base URL)为 https://inference.do-ai.run/v1/,单个模型访问密钥(Model Access Key)即可同时覆盖基座模型和路由器。
项目初始化
要继续后续步骤,你需要 Python 3.10+、一个启用了无服务器推理的 DigitalOcean 账户 以及一个模型访问密钥。为了方便起见,我们已经在这个 GitHub 仓库 中配置好了完整的项目。但建议你跟随接下来的章节一起动手构建自己的 API 版本,以此了解我们为该 API 做出特定选择的原因。
注:如果你是新注册DigitalOcean的用户,无服务器推理中的Claude、OpenAI 暂时无法使用,可以直接与卓普云(aidroplet.com)联系,申请开通这两种商业模型的权限。
项目布局刻意保持得非常精简:
bash
support-triage/
├── main.py
├── sample_tickets.json
├── requirements.txt
└── .envmain.py 存放应用代码,requirements.txt 包含所需的依赖包,sample_tickets.json 是用于测试路由器的样本数据,而 .env 则存放必需的密钥、访问凭证和基础 URL 值。
首先,将仓库克隆到你的本地机器上,并在终端中粘贴以下代码来安装所有内容:
bash
git clone https://github.com/Jameshskelton/triage_app
cd triage_app
python3 -m venv venv_triage
source venv_triage/bin/activate
pip install -r requirements.txtOpenAI SDK 可以直接用于 DigitalOcean 的无服务器推理:你只需要将 base_url 和 api_key 指向 DigitalOcean,而不是 OpenAI。
步骤 1:基准线------直接调用模型
在开始接触路由器之前,我们先写一个大多数开发者最先会写出来的版本:硬编码一个模型,让它处理所有四项工作。接下来的几个步骤章节概述了我们构建应用演示所做的工作。如果你只想测试最终版本,可以直接查看我们存放该项目的仓库。
首先,我们创建 main.py:
python
import os
import re
from openai import OpenAI
from fastapi import FastAPI
from pydantic import BaseModel
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url=os.environ["DO_INFERENCE_BASE_URL"],
api_key=os.environ["DO_MODEL_ACCESS_KEY"],
)
MODEL = "llama3.3-70b-instruct" # 一个模型处理所有任务
app = FastAPI()
class Ticket(BaseModel):
subject: str
body: str
def call_model(system: str, user: str) -> str:
resp = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
)
return resp.choices[0].message.content.strip()
@app.post("/triage")
def triage(ticket: Ticket):
text = f"Subject: {ticket.subject}\n\n{ticket.body}"
category = call_model(
"Classify this support ticket into one of: billing, bug, how-to, account, other. Reply with one word.",
text,
)
urgency = call_model(
"Score urgency from 1 (low) to 5 (critical) and note sentiment. Reply as 'score: N, sentiment: X'.",
text,
)
reply = call_model(
"Write a short, professional reply to this customer. Maximum 4 sentences.",
text,
)
summary = call_model(
"Summarize this ticket for a human agent. Include the problem, what's been tried, and recommended next steps.",
text,
)
return {
"category": category,
"urgency": urgency,
"reply": reply,
"escalation_summary": summary,
}如果我们正确设置了包含相应 API 密钥和数值的 .env 文件,就可以使用以下代码运行它:
css
uvicorn main:app --reload让我们用两个工单(一个简单的,一个复杂的)来测试它,并审计其结果。
测试输入 1:
vbnet
curl -X POST localhost:8000/triage -H "Content-Type: application/json" -d '{
"subject": "Password reset",
"body": "How do I reset my password?"
}'测试输出 1:
json
{
"category": "account",
"urgency": "score: 1, sentiment: neutral",
"reply": "You can reset your password by selecting the Forgot password link on the sign-in page and following the email instructions. If you do not receive the reset email, check your spam folder or contact support for help.",
"escalation_summary": "The customer is asking how to reset their password. No signs of account compromise, outage, or escalation risk. Recommended next step: provide standard password reset instructions."
}测试输入 2:
vbnet
curl -X POST localhost:8000/triage -H "Content-Type: application/json" -d '{
"subject": "Production outage on enterprise account",
"body": "Our team has been unable to access the dashboard since 09:14 UTC. We have ~200 internal users blocked. Attached are logs showing 502s from the API gateway..."
}'这将为我们返回类似如下的测试输出 2:
json
{
"category": "bug",
"urgency": "score: 5, sentiment: frustrated",
"reply": "Thank you for reporting this. We understand that a production dashboard outage affecting around 200 users is urgent, and we are escalating this to our engineering team immediately. Please continue to share any relevant logs or timestamps while we investigate.",
"escalation_summary": "Enterprise customer reports a production dashboard outage beginning at 09:14 UTC. Approximately 200 internal users are blocked. Logs indicate 502 responses from the API gateway. Recommended next steps: escalate to engineering, inspect gateway and upstream service health, correlate errors around 09:14 UTC, and provide the customer with frequent status updates."
}两个回复都很有用。这也正是为什么这种硬编码的基准方案非常具有诱惑力。
但看看刚刚发生了什么:同一个 70B 的模型处理了所有事情。模型将"如何重置我的密码?"分类到一个简单的类别中,给紧急程度打分,起草了简短的回复,还写了一份该工单根本不需要的升级总结。然后,它处理了企业停机故障,而在这种场景下使用较大的模型才真正合乎逻辑。
这就是问题所在。简单的工单和生产环境的停机事故在成本、延迟和质量上有极大的不同,但应用却将它们一视同仁。你正在为简单的工作支付昂贵的溢价,如果模型变慢或不可用,应用没有任何兜底方案,而且任何模型选择的变更都意味着修改应用代码并重新部署。让我们来解决这个问题。
步骤 2:配置推理路由器
在 DigitalOcean 控制面板 中,使用左侧边栏导航至"Inference Router(推理路由器)"。然后,创建一个新的推理路由器。为你的路由器命名,并对其功能进行描述。例如,我们将我们的路由器命名为 triage-router,并将其描述为"Demo Triage API for DO tutorial"。
接着,路由器需要创建四个任务,每个任务都需要包含描述以及带有选择策略的模型池。具体配置如下表所示。如果你想复制它们来重现这个实验,可以将这些值逐个复制并粘贴到路由器的各个任务中。这将产生与我们类似的概率性结果。
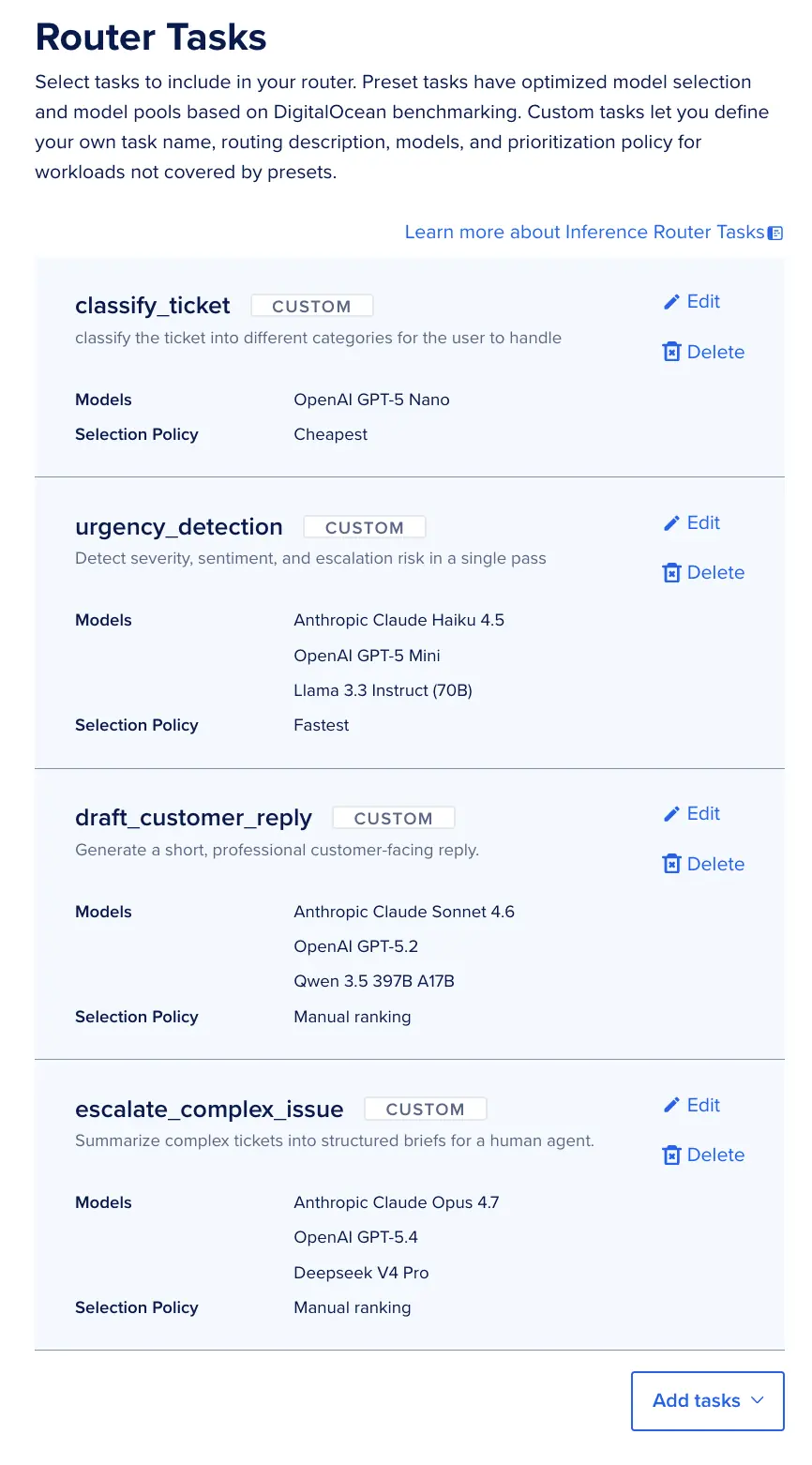
| 任务名称 | 描述(输入给路由器) | 模型池策略 |
|---|---|---|
| classify_ticket | 讲简短的支持消息归类为问题类型(账单、Bug、指南、账户)。 | 最低成本 (Lowest cost) |
| urgency_detection | 单次运行中检测严重程度、情感和升级风险。 | 最低延迟 (Lowest latency) |
| draft_customer_reply | 生成简短、专业的面向客户的回复。 | 手动排名 (Manual ranking) |
| escalate_complex_issue | 将复杂工单总结为供人工客服查看的结构化简报。 | 手动排名 (Manual ranking) |
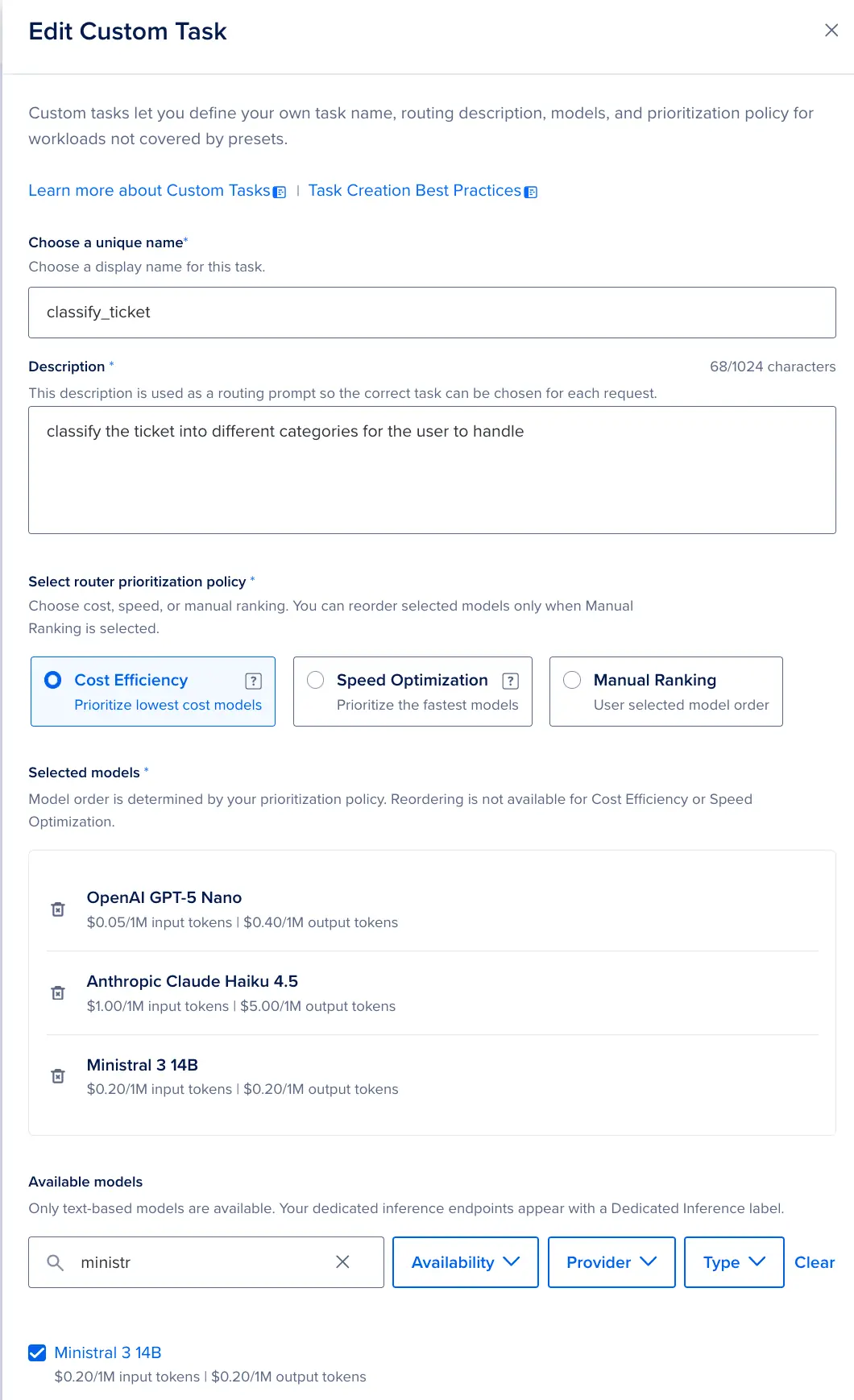
在创建描述、选择路由器优先级策略以及选择模型时,我们需要考虑想要完成的确切任务,以优化我们的结果。以下是几点值得注意的事项:
- 任务描述至关重要。路由器利用它们将传入的请求与正确的任务进行匹配。请具体描述任务的作用、期望接收什么样的输入以及输出的格式。
- 每个模型池中至少放入两个模型。只有一个模型的模型池是单点故障。即使是你的"最低成本"池,也应该有一个兜底模型,以防主模型不可用。
- 选择策略是在池内部执行 supply 的,而不是跨池执行。"最低成本"指的是"该模型池中当前健康的最便宜模型",而不是"整个平台里最便宜的模型"。
路由器保存成功后,你将获得一个路由器 ID(Router ID)。这就是你的应用后续要调用的目标。
步骤 3:重构应用以使用路由器
现在到了让人身心愉悦的部分。将硬编码的 MODEL 常量替换为路由器 ID,并通过请求传入任务名称。以下是一个具体实现的示例,虽然这与我们最终发布的版本不完全相同,但能很好地说明其工作原理。
python
ROUTER = "your-router-id" # 来自 DigitalOcean 控制面板
def parse_urgency(urgency_text: str) -> int:
"""从 'score: N, sentiment: X' 中提取整数评分。如果无法解析,默认返回 3。"""
match = re.search(r"score:\s*(\d)", urgency_text, re.IGNORECASE)
return int(match.group(1)) if match else 3
def call_router(task: str, system: str, user: str) -> dict:
resp = client.chat.completions.create(
model=ROUTER,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
extra_body={"task": task}, # 路由器利用此字段来挑选模型池
)
return {
"content": resp.choices[0].message.content.strip(),
"served_by": resp.model, # 路由器实际挑选的模型
}
@app.post("/triage")
def triage(ticket: Ticket):
text = f"Subject: {ticket.subject}\n\n{ticket.body}"
category = call_router(
"classify_ticket",
"Classify this support ticket into one of: billing, bug, how-to, account, other. Reply with one word.",
text,
)
urgency = call_router(
"urgency_detection",
"Score urgency from 1 (low) to 5 (critical) and note sentiment. Reply as 'score: N, sentiment: X'.",
text,
)
reply = call_router(
"draft_customer_reply",
"Write a short, professional reply to this customer. Maximum 4 sentences.",
text,
)
# 仅在紧急程度需要人工介入时才进行升级总结
urgency_score = parse_urgency(urgency["content"])
summary = None
if urgency_score >= 4:
summary = call_router(
"escalate_complex_issue",
"Summarize this ticket for a human agent. Include the problem, what's been tried, and recommended next steps.",
text,
)
return {
"category": category["content"],
"urgency": urgency["content"],
"urgency_score": urgency_score,
"reply": reply["content"],
"escalation_summary": summary["content"] if summary else None,
"routing": {
"classify_ticket": category["served_by"],
"urgency_detection": urgency["served_by"],
"draft_customer_reply": reply["served_by"],
"escalate_complex_issue": summary["served_by"] if summary else None,
},
}这就是全部的改动。我们在 GitHub 版本中已经为你处理好了这些,因此无需你亲自动手手动修改。
现在,应用的任何地方都不再包含具体模型的名称。路由器会根据你配置的策略,决定由哪个模型来处理每个任务。如果下个月你想更换 draft_customer_reply 底层的模型,你只需要在路由器中操作,而无需修改此文件。
应用不再要求一个模型同时处理所有事情,而是将一个工单拆分为更小的 AI 任务来进行分流。当你调用 POST /triage 时,main.py 会构建工单文本,然后向路由器发送独立的调用:
classify_ticket:决定工单类别,如账单、Bug、指南、账户或其他。urgency_detection:对严重程度进行 1 到 5 的评分并检测情感;代码利用该评分来决定是否需要升级。draft_customer_reply:编写一封简短的面向客户的回复。escalate_complex_issue:在紧急程度评分达到 4 或 5 时触发升级总结;较低的评分会直接跳过此步骤,这也是大部分成本节省的来源。
核心关键在于:应用始终将 .env 中的 DigitalOcean 路由器 ID 作为"model"进行调用,而由路由器去决定应该由哪个底层模型来处理每个提示词。
步骤 4:通过路由器运行混合工单
将路由器接入后,我们来测试一下。当向端点输入简单和复杂交织的混合示例时,其展现出的行为非常有趣。以下是 sample_tickets.json 中包含的一小批涵盖简单到复杂的示例:
css
[ {"subject": "Password reset", "body": "How do I reset my password?"}, {"subject": "Invoice question", "body": "Why was I charged twice on invoice INV-3382?"}, {"subject": "This is ridiculous", "body": "Third time this week your dashboard has gone down during our standup. We're seriously evaluating alternatives."}, {"subject": "Dashboard weird", "body": "the dashboard is weird since yesterday"}, {"subject": "Production outage", "body": "Our team has been unable to access the dashboard since 09:14 UTC. ~200 internal users blocked. Logs attached show 502s from the API gateway, traced to..."}, {"subject": "Feature request + complaint", "body": "Can you add bulk export? Also the existing export is too slow and crashes on >10k rows."}, {"subject": "API auth", "body": "Getting 401s after rotating my key. Following the docs at /auth/rotate but the new key returns invalid."}]为了方便按顺序测试它们,我们提供了 run_batch.py 来辅助测试。你可以运行以下命令来亲自执行:
css
python3 run_batch.py sample_tickets.json --json循环跑完这些数据,你会看到路由器完美地各司其职。只有一行的"如何重置我的密码?"在分类时触发了最低成本池,并在处理紧急程度时匹配了一个小型、快速的模型。带有流失风险的愤怒消息会迅速被标记为高紧急度,但由于该回复是要发给真实客户的,因此生成的回复草稿来自更高质量的模型池。生产环境停机事故则被路由到高质量模型池来生成升级总结,因为这份总结是给值班工程师在 UTC 09:15 分阅读的。
因为 call_router 将 resp.model 作为 served_by 暴露了出来,现在每个响应都会明确告诉你究竟是哪个模型处理了对应的任务。以下是生产环境停机工单返回的内容:
json
{
"category": "bug",
"urgency": "score: 5, sentiment: frustrated",
"urgency_score": 5,
"reply": "Thank you for reporting this...",
"escalation_summary": "Enterprise customer reports a production dashboard outage...",
"routing": {
"classify_ticket": "openai-gpt-5-nano",
"urgency_detection": "anthropic-claude-haiku-4.5",
"draft_customer_reply": "anthropic-claude-sonnet-4.6",
"escalate_complex_issue": "anthropic-claude-opus-4.7"
}
}一次请求,动用了四种不同的模型,而在你的应用代码里不着一字(没有一个模型名)。便宜的分类器处理了单字分类的决定,Haiku 快速单次跑出紧急程度评分,Sonnet 起草了面向客户的回复,而 Opus 生成了供值班工程师阅读的简报。如果你去跑密码重置工单,routing.escalate_complex_issue 字段返回的结果将是 null ------ 因为紧急度评分没有跨过阈值,而这个 null 省下来的可是真金白银。
推理路由究竟能为你省下多少钱
让我们用数字说话。假设平均一张工单包含 300 个输入 Token,输出 Token 因任务而异(分类 40 个、紧急度 30 个、回复 150 个、升级总结 250 个)。在我们的 7 个工单样本中,有 2-3 个分数高到触发升级;我们使用 20% 作为平稳状态下的预估比例。
基于 DigitalOcean 官方公布的无服务器推理费率:
| 任务 | 模型 | 单张工单成本 |
|---|---|---|
| classify_ticket | GPT-5 Nano | $0.000031 |
| urgency_detection | Claude Haiku 4.5 | $0.000450 |
| draft_customer_reply | Claude Sonnet 4.6 | $0.003150 |
| escalate_complex_issue(约 20% 的工单触发) | Claude Opus 4.7 | $0.007750 |
在每月 100,000 张工单的规模下,三种策略的成本对比:
| 策略 | 每月成本 |
|---|---|
| 所有任务硬编码使用 Llama 3.3 70B | $109 |
| 路由器(成本感知型) | $518 |
| 所有任务硬编码使用 Claude Opus 4.7 | $1,775 |
坦白来说:路由器并不是最省钱的方案。硬编码使用 Llama 70B 才是。但代价是让 Llama 70B 去撰写你面对企业级停机事故时的客户回复。你之所以省了钱,是因为你把一个具有流失风险的工单和密码重置工单放在了同等水平去对待。
真正公平的对比,应该和更务实的替代方案进行切磋:一旦你判定 Llama 编写的客户回复质量达不到要求,你的选择要么是"全盘皆用 Opus",要么是使用路由器。路由器比全盘使用 Opus 便宜了 71%,它只在真正需要高昂成本的 Opus 4.7 模型的工单上才进行路由。
在做出决定之前,不妨先在自己的工单构成比例上算一算这笔账。简单工单与复杂工单的比例是影响结果的最大杠杆:一个有 80% 密码重置工单的队列,比一个有 80% 升级工单的队列能省下多得多的钱。
生产环境清单
在将此方案推向真实工单之前,请确认以下事项:
- 记录每一次调用的任务类型、延迟、Token 使用量和所选模型。无法度量就无法调优,没有针对每个任务的指标,路由器的价值将变得不可见。
- 为每个任务构建一个小型评估集。比如每个任务准备 20 个已知输出良好的工单。在更改模型池组合之前运行该评估集。路由器的核心意义就在于你可以在不改动代码的情况下更换模型,但你依然需要知道这次更换是否带来了改进。
- 确保每个模型池中至少保留一个兜底模型。只有一个模型的池直接让使用路由器的初衷折损了一半。
- 使用直接模型调用来进行受控的基准测试。当你在测量某一特定模型的行为时,你不希望路由器介入导致基准测试变得具有不确定性。
- 每季度重新审视路由规则。模型的价格和质量一直在变。六个月前属于"最低成本"的池,今天可能就不是了。
- 将任务描述视为生产配置。对它们进行版本控制,审查其变更,绝不要在没有任何记录的情况下直接在 UI 界面中进行修改。
结语
你最终得到的应用并没有比刚开始时的庞大,它反而变得更加精简,因为模型选择的逻辑已经从代码中剥离,移入到了路由器中。路由器承担了过去由 match 或 if-else 语句编写的工作:将任务与模型进行匹配、在某些模型不可用时进行兜底,并为你提供了一个更改策略的单一控制点。通过 DigitalOcean 推理路由器实现的无服务器推理,为你的应用赋予了更高的灵活性和效率,同时免去了硬编码架构带来的种种麻烦。
从此出发,接下来的几个自然延伸步骤包括:将 draft_customer_reply 任务以流式(Stream)形式返回给客户端,以便客服人员在文本生成结束前就能开始阅读;将升级总结接入到你真实的工单系统中;或者为另一个毫不相干的工作流启动第二个路由器,并复用同一个访问密钥。
完整的示例代码可在配套仓库中获取,而在 DigitalOcean 控制面板 中配置好路由器大概只需要 5 分钟。
如果遇到Claude、OpenAI大模型调用疑问,或希望进一步了解DigitalOcean GPU 云服务器产品,可联系卓普云(aidroplet.com)。