今日,智谱正式开源新一代大模型 GLM 5.1。作为智谱 GLM 系列的最新力作,GLM-5.1 的整体能力得到了全面提升。尤其在代码能力上:在最接近真实软件开发的 SWE-bench Pro 基准测试中,GLM-5.1 超过 GPT-5.4、Claude Opus 4.6,刷新全球最佳成绩。此外,GLM-5.1 还在长程任务(Long Horizon Task)处理能力上实现了显著突破,有别于当前以分钟级交互为主的模型,GLM-5.1 可在单次任务中持续、自主地工作长达 8 小时,凭借自主规划、执行与迭代进化,最终交付完整的工程级成果。
百度百舸基于昆仑芯硬件平台第一时间完成了 GLM-5.1 的模型适配与集群部署,助力最新开源大模型快速投入生产环境的大规模应用。
百度百舸基于 Prefill-Decode 分离架构,使用 CP (Context Parallelism) 上下文并行策略有效降低 128K 以上序列的计算负载和显存压力,从而使得 GLM-5.1 能够更好的支撑 AI Agent、Coding 场景的长上下文与高并发需求。
目前,百度百舸与昆仑芯已具备「极速模型适配 - 全链路性能提升 - 高效规模化部署 - 超大规模集群落地」的完备能力。
极速模型适配
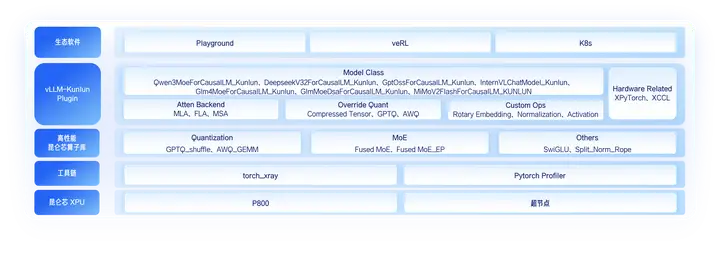
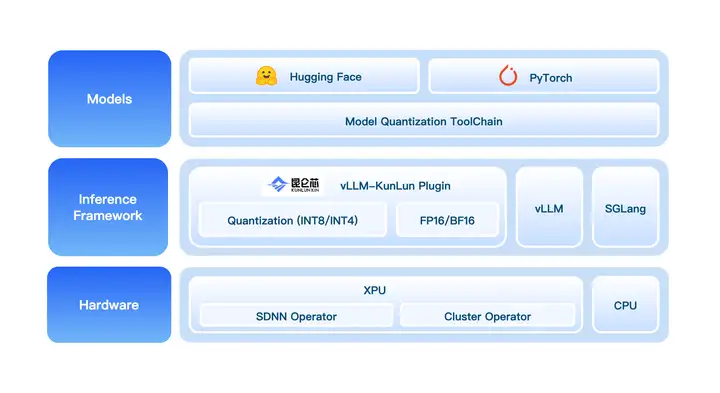
为实现高性能模型的快速开发与适配,百度百舸联合昆仑芯开发了 vLLM-Kunlun Plugin,将 vLLM 社区版与昆仑芯 XPU 后端完全解耦。用户通过 vLLM-Kunlun Plugin,快速适配主流开源模型。
依托 CUDA-like 特性,vLLM-Kunlun Plugin 在软件层面「抹平」了硬件差异,使开发者能够像使用通用 GPU 一样便捷地使用昆仑芯。同时,vLLM-Playground 已全面支持昆仑芯,即便是初学者也能通过直观的 Web UI 一键完成模型配置与推理。
在适配效率上,基于昆仑芯成熟的高性能算子库,针对无新增算子的新模型(如从 GLM-5.0 版本迭代至 GLM-5.1)可实现 Day0 极速适配,针对有新增算子的新模型,也可在极短时间内完成新算子的开发与模型适配。再配合 torch_xray 精度对齐工具与 PyTorch Profiler 性能分析工具,百度百舸为模型跑对与性能表现提供了全方位保障。
全链路性能提升
为了使国产模型充分发挥昆仑芯硬件算力,百度百舸从算子、Kernel Launch、框架及系统等不同维度开展全链路优化 ------ 依据昆仑芯硬件单元特性为各类算子制定专属优化策略,借助 CUDA Graph 消除 CPU 调度开销显著降低 Kernel Launch 耗时,针对框架原生的性能瓶颈开发了昆仑芯定制算子,并在系统层面上大幅提升并行计算能力。
同时,在量化层面,百度百舸推出了「模型层 - 框架层 - 硬件层」的端到端的量化体系------通过昆仑芯自研量化工具链实现高精度、高效率的模型量化,对不同来源的 INT8 / INT4 量化模型实现最佳模型部署与量化推理,并基于昆仑芯 XPU 的计算特性,定制化开发高性能量化专用算子库。在实际部署时,采用 INT4 混合精度量化,仅用单机昆仑芯 P800,即可实现 754B 超大参数模型的 64K 长序列支持,并将推理性能提升 20%。
高效规模化部署
在完成模型适配并实现性能提升的基础上,百度百舸依托 PD 分离架构进一步优化集群推理效能,并提供针对标准 8 卡与超节点硬件平台的标准化部署方案。
- 在传统 8 卡服务器场景中,通过 TP/EP 扩展,仅需 6 台昆仑芯 P800 便可实现 GLM-5.0 模型 200K 的超长序列推理;
- 在超节点场景中,相较同卡数的单机 8 卡场景,Prefill 阶段性能提升超 16%,Decode 阶段提升超 17%。
同时,百度百舸构建了精细化的 KV Cache 调度与加速引擎,实现高达 80% ~ 90% 的缓存命中率,将 64K 序列的 TTFT 缩短 6.2 倍,为 AI Agent 及复杂 Coding 等高并发、极长文本业务提供了稳健的响应保障。
此外,针对业务流量波动,百度百舸对昆仑芯集群的弹性扩缩容能力进行了系统性优化,将实例拉起时间从分钟级压缩至秒级。
3.2 万卡集群与天池超节点
目前,百度智能云已自建完成多个大规模国产算力基础设施。
- 2025 年 2 月,百度智能云成功点亮昆仑芯 P800 万卡集群,这是国内首个正式点亮的自研万卡 AI 集群。同年 4 月,该集群规模进一步扩展至 3.2 万卡,并已支撑百度千帆、百度蒸汽机等多个千卡级大模型训练任务。
- 2025 年 4 月,百度发布基于昆仑芯的天池超节点方案,采用 32 卡一层点对点全互联架构,通信延迟低至 1.5 μs;方案兼容现有机房环境,支持单人运维,并依托昆仑芯与百度百舸的持续软硬协同优化,实现极致的每 Token 成本。
截至目前,百度百舸基于昆仑芯完成了 GLM、Qwen、DeepSeek、MiniMax、Kimi、MiMo 等最新大模型的部署和应用,让顶尖 AI 能力转化为产业发展动能。