安装 Flink Kafka SQL Connector
需要把 Flink 的 Kafka SQL Connector JAR 包,放到 $FLINK_HOME/lib 目录下。
以本系列示例使用的 Flink 1.20.1 + Kafka 3.4.0-1.20 为例,可以这样操作:
-
确认你的 Flink 安装目录(假设为
/opt/flink):export FLINK_HOME=/opt/flink
-
下载 Kafka SQL Connector JAR 到 Flink 的
lib目录:cd $FLINK_HOME/lib wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka/3.4.0-1.20/flink-sql-connector-kafka-3.4.0-1.20.jar如果你是 Windows + WSL2,可以在 WSL2 里执行同样的命令;或者用浏览器下载后手动拷贝到
lib目录。 -
如果你使用的是独立集群或远程集群,需要重启 Flink 集群,让新 JAR 在 JobManager/TaskManager 上生效:
cd $FLINK_HOME bin/stop-cluster.sh bin/start-cluster.sh如果只是本地直接运行
bin/sql-client.sh启动内嵌 mini-cluster,则只需重启 SQL Client 即可。 -
启动 Flink SQL Client,然后执行本文后续的建表与查询示例:
cd $FLINK_HOME bin/sql-client.sh
准备 Kafka 中的示例数据表
我们假设已经从 Kafka 中读取两条流:
orders:订单流payments:支付流
并在建表时定义了事件时间和水位线:
CREATE TABLE orders (
order_id STRING,
user_id STRING,
order_amount DECIMAL(10, 2),
order_time TIMESTAMP_LTZ(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'properties.group.id' = 'flink-orders',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);
CREATE TABLE payments (
pay_id STRING,
order_id STRING,
pay_amount DECIMAL(10, 2),
pay_time TIMESTAMP_LTZ(3),
WATERMARK FOR pay_time AS pay_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'payments',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'properties.group.id' = 'flink-payments',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);有了时间字段和水位线,Flink 才能在流模式下安全地做双流 JOIN,并在「时间窗」关闭后清理状态。
使用 Kafka Console Producer 造测试数据
上面的 DDL 建好了 orders 和 payments 两张表,对应的是 Kafka 中的两个 Topic。接下来我们用 Kafka 自带的命令行工具写入几条 JSON 测试数据。
假设你已经在 WSL2 的 Ubuntu 中启动好了 Kafka(包括 ZooKeeper 或 KRaft),进入 Kafka 安装目录,执行:
1. 往订单 Topic 写入数据
bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic orders在命令行中输入几条 JSON 数据(按回车发送一条):
{"order_id":"o_1","user_id":"u_1","order_amount":100.00,"order_time":"2026-02-16T14:41:00Z"}
{"order_id":"o_2","user_id":"u_2","order_amount":200.00,"order_time":"2026-02-16T14:42:00Z"}
{"order_id":"o_3","user_id":"u_1","order_amount":150.00,"order_time":"2026-02-16T14:45:00Z"}2. 往支付 Topic 写入数据
新开一个终端,同样进入 Kafka 安装目录,执行:
bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic payments输入对应的支付 JSON 数据:
{"pay_id":"p_1","order_id":"o_1","pay_amount":100.00,"pay_time":"2026-02-16T14:41:00Z"}
{"pay_id":"p_2","order_id":"o_2","pay_amount":200.00,"pay_time":"2026-02-16T14:42:00Z"}这里的字段名、时间格式都要和前面建表时定义的一致,这样 Flink 才能正确反序列化 JSON 并进行双流 JOIN。
四、基于时间条件的普通双流 JOIN
先来看最直观的一种写法:同时指定「关联键」和「时间范围」。
**需求:**统计订单在下单后 15 分钟内完成支付的记录。
SELECT
o.order_id,
o.user_id,
o.order_amount,
o.order_time,
p.pay_id,
p.pay_amount,
p.pay_time
FROM orders AS o
JOIN payments AS p
ON o.order_id = p.order_id
AND p.pay_time BETWEEN o.order_time AND o.order_time + INTERVAL '15' MINUTE;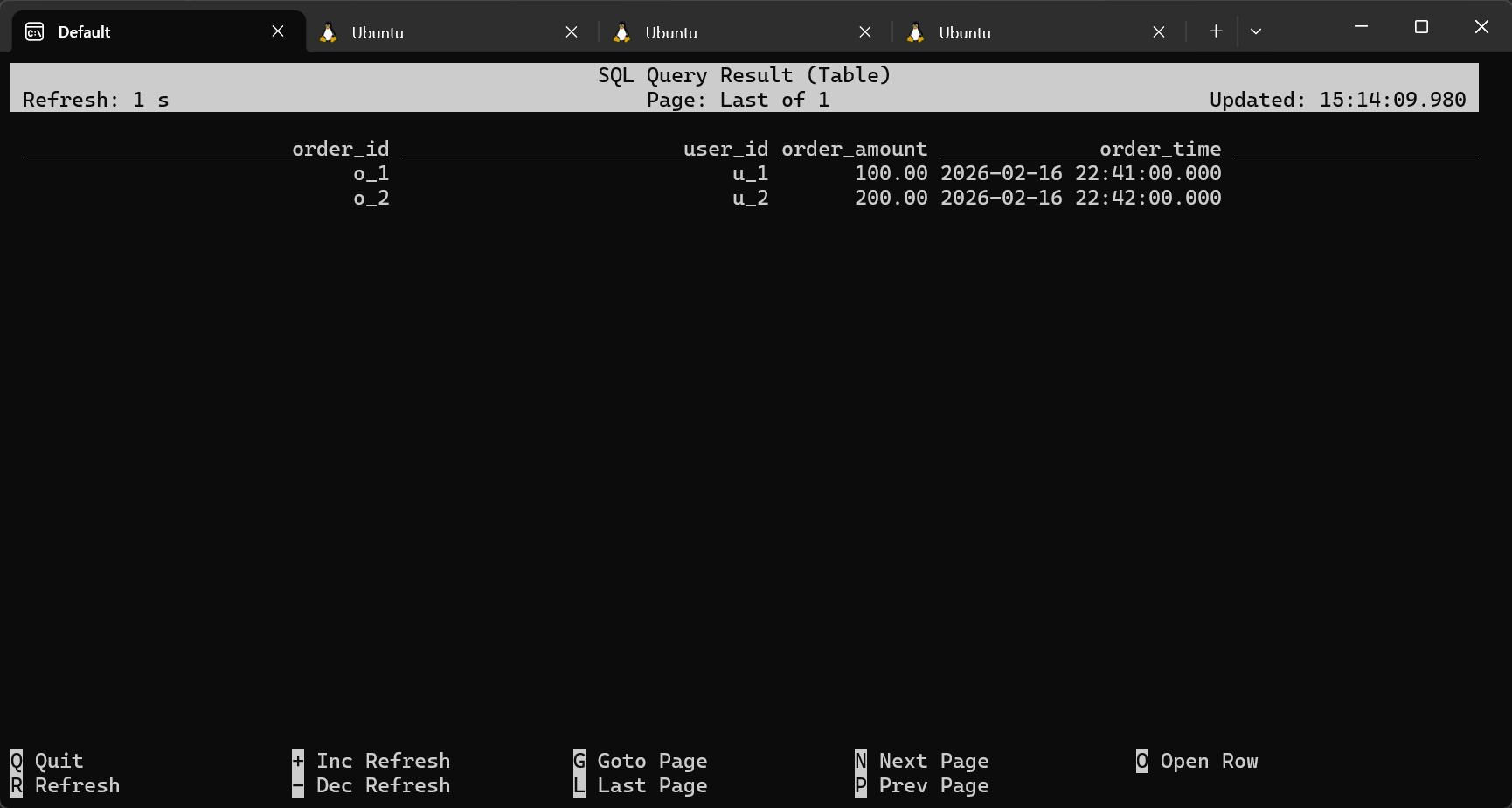
这里有几点非常关键:
o.order_id = p.order_id:以订单号作为两条流的业务主键pay_time BETWEEN order_time AND order_time + INTERVAL '15' MINUTE:明确限定"下单后 15 分钟内支付"这类时间约束- 使用事件时间字段配合水位线,可以在保证计算正确性的前提下控制状态大小,并处理一定范围内的迟到数据
如果你希望保留那些下单了但超时未支付 的记录,可以将上面的 JOIN 改为 LEFT JOIN,然后在下游以 p.pay_id IS NULL 作为"未支付/超时"的判断条件。
五、Interval Join:显式时间区间的双流 JOIN
普通 JOIN 中的时间条件本质上就是一种「区间约束」。
在 Flink Table API 中,有一个更明确的概念:Interval Join。
等价的 Interval Join 写法大致如下(Table API 伪代码,仅作为概念理解):
SELECT
o.order_id,
o.order_time,
p.pay_id,
p.pay_time
FROM orders AS o
JOIN payments AS p
ON o.order_id = p.order_id
AND p.pay_time BETWEEN o.order_time AND o.order_time + INTERVAL '15' MINUTE;无论是普通 JOIN 还是 Interval Join,本质上都是:
- 以某个时间字段作为「对齐基准」
- 设定一个前后允许的时间区间
- 在这个区间内匹配到的记录会输出为 JOIN 结果
六、迟到数据与状态清理
在流式 JOIN 中,最容易被忽略但又非常重要的一点就是:状态会不断累积。
Flink 会根据时间条件和水位线来决定:
- 某条历史事件是否还有可能再匹配到另一条流的事件
- 超出时间范围且水位线已推进时,可以安全地清理对应状态
设计双流 JOIN 时,建议考虑:
- 时间窗口不要设置得过大,否则状态会膨胀
- 根据业务的真实延迟来设置水位线与时间区间
- 对于极端迟到的数据,是丢弃、旁路输出,还是通过补偿机制处理
七、一个完整的小结
通过本文,你需要记住下面几点:
- 双流 JOIN 场景非常常见,本质是两条事实流在时间上的匹配
- 流式 JOIN 一定要依赖事件时间 + 水位线来控制状态和迟到数据