1.仿射变换
python
import cv2
import numpy as np
img = cv2.imread('img.png')
height,width = img.shape[:2]
mat_src = np.float32([[0,0],[0,height-1],[width-1,0]])
mat_dst = np.float32([[0,0],[100,height-100],[width-100,100]])
M=cv2.getAffineTransform(mat_src,mat_dst)
#数warpAffine(src,M, dsize,dst=None, flags=None, borderMode=None, borderValue=None)# src:输入图像
# M:运算矩阵,2行3列的,
# dsize:运算后矩阵的大小,也就是输出图片的尺寸
# dst:输出图像
# flags:插值方法的组合,与resize函数中的插值一样,可以查看cv2.resize# borderMode:像素外推方法,详情参考官网
# borderValue:在恒定边框的情况下使用的borderValue值:默认情况下,它是0
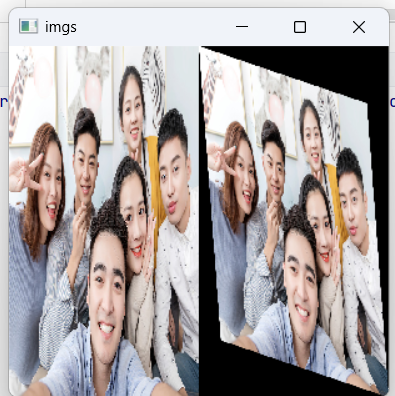
dst = cv2.warpAffine(img,M,(width,height))
imgs = np.hstack([img,dst])
cv2.namedWindow('imgs',cv2.WINDOW_NORMAL)
cv2.imshow("imgs",imgs)
cv2.waitKey(0)img:

仿射变换后的结果:
2.换脸技术
penCV + Dlib 实现经典的人脸交换算法,无需深度学习模型,通过人脸关键点检测、仿射变换、肤色归一化、图像掩膜融合四大核心步骤,完成自然的换脸效果。
- 人脸检测:定位图片中的人脸区域
- 关键点提取:获取 68 个人脸特征点(眼睛、眉毛、鼻子、嘴巴)
- 仿射变换:计算人脸 B 到人脸 A 的变换矩阵,实现五官精准对齐
- 肤色归一化:统一两张人脸的肤色,消除色差
- 掩膜融合:通过蒙版实现无缝拼接,让换脸效果更自然
- 下载 Dlib 官方 68 点人脸关键点检测模型:shape_predictor_68_face_landmarks.dat
代码
python
"""------------换脸术的实现-----------------"""
# 导入核心库
import cv2 # 图像处理:读取、变换、融合、显示
import dlib # 人脸检测 + 68关键点定位
import numpy as np # 数值计算:矩阵运算、数组处理
# ===================== 1. 定义Dlib 68个人脸关键点分组 =====================
# Dlib标准68关键点索引划分,按五官区域分类
JAW_POINTS = list(range(0, 17)) # 下巴轮廓
RIGHT_BROW_POINTS = list(range(17, 22)) # 右眉毛
LEFT_BROW_POINTS = list(range(22, 27)) # 左眉毛
NOSE_POINTS = list(range(27, 35)) # 鼻子区域
RIGHT_EYE_POINTS = list(range(36, 42)) # 右眼
LEFT_EYE_POINTS = list(range(42, 48)) # 左眼
MOUTH_POINTS = list(range(48, 61)) # 嘴巴
FACE_POINTS = list(range(17, 68)) # 脸部轮廓(不含下巴)
# 筛选换脸需要的核心关键点:眉毛+眼睛+鼻子+嘴巴(换脸核心对齐区域)
POINTS = [LEFT_BROW_POINTS + RIGHT_EYE_POINTS +
LEFT_EYE_POINTS +RIGHT_BROW_POINTS + NOSE_POINTS + MOUTH_POINTS]
# 转换为元组,方便后续索引调用,提升代码稳定性
POINTStuple=tuple(POINTS)
# ===================== 2. 生成人脸掩膜函数 =====================
# 功能:根据人脸关键点,生成脸部透明蒙版,用于后续无缝融合
def getFaceMask(im, keyPoints):
# 创建与原图大小一致的全黑单通道图像
im = np.zeros(im.shape[:2], dtype=np.float64)
# 遍历核心关键点,生成脸部凸包
for p in POINTS:
points = cv2.convexHull(keyPoints[p]) # 计算关键点的凸包(闭合区域)
cv2.fillConvexPoly(im, points, color=1) # 填充凸包,值为1(白色区域)
# 将单通道蒙版转换为3通道,匹配彩色图像格式
im = np.array([im, im, im]).transpose((1, 2, 0))
# 高斯模糊:柔化蒙版边缘,让换脸无拼接痕迹(参数可调整)
im = cv2.GaussianBlur(im,(25,25), 0)
return im
# ===================== 3. 计算仿射变换矩阵 =====================
# 功能:计算人脸B 对齐到 人脸A 的变换矩阵M(核心数学算法)
def getM(points1, points2):
# 转换为浮点型,避免计算精度丢失
points1 = points1.astype(np.float64)
points2 = points2.astype(np.float64)
# 关键点归一化:减去均值,消除位置偏移
c1 = np.mean(points1, axis=0)
c2 = np.mean(points2, axis=0)
points1 -= c1
points2 -= c2
# 计算标准差,归一化尺度,消除人脸大小差异
s1 = np.std(points1)
s2 = np.std(points2)
points1 /= s1
points2 /= s2
# 奇异值分解(SVD):计算最优旋转/缩放/平移矩阵
U, S, Vt = np.linalg.svd(points1.T * points2)
R = (U * Vt).T
# 组合最终的仿射变换矩阵
return np.hstack(((s2/s1)*R, c2.T-(s2/s1)*R*c1.T))
# ===================== 4. 提取人脸68关键点函数 =====================
# 功能:输入图像,输出人脸68个关键点坐标
def getKeyPoints(im):
rects = detector(im, 1) # 检测人脸框
shape = predictor(im, rects[0]) # 预测68关键点
s= np.matrix([[p.x, p.y] for p in shape.parts()]) # 转换为矩阵格式
return s
# ===================== 5. 肤色归一化函数 =====================
# 功能:将人脸B的肤色调整为人脸A的肤色,消除色差
def normalColor(a, b):
ksize=(51,51) # 大尺寸高斯核,平滑肤色
aGauss = cv2.GaussianBlur(a, ksize, 0) # 对原图A做高斯模糊
bGauss = cv2.GaussianBlur(b, ksize, 0) # 对图B做高斯模糊
weight= aGauss/ bGauss # 计算肤色调整权重
where_are_inf = np.isinf(weight)
weight[where_are_inf] = 0 # 处理除零异常
return b * weight
# ===================== 主程序执行流程 =====================
# 1. 读取两张待换脸的图片
a=cv2.imread("hg.png") # 背景图A(被换脸的目标图)
b=cv2.imread("pyy1.png") # 人脸图B(要贴上去的人脸)
# 可选:解决B图尺寸过大问题(取消注释即可使用)
# scale = 0.35
# b = cv2.resize(b,None,fx=scale,fy = scale,interpolation=cv2.INTER_CUBIC)
# 2. 初始化Dlib检测器 + 关键点模型
detector = dlib.get_frontal_face_detector() # 人脸检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")# 关键点模型
# 3. 提取两张图片的人脸68关键点
aKeyPoints = getKeyPoints(a)
bKeyPoints = getKeyPoints(b)
# 4. 生成两张人脸的蒙版(用于融合)
aMask = getFaceMask(a, aKeyPoints)
cv2.imshow("aMask", aMask)
cv2.waitKey()
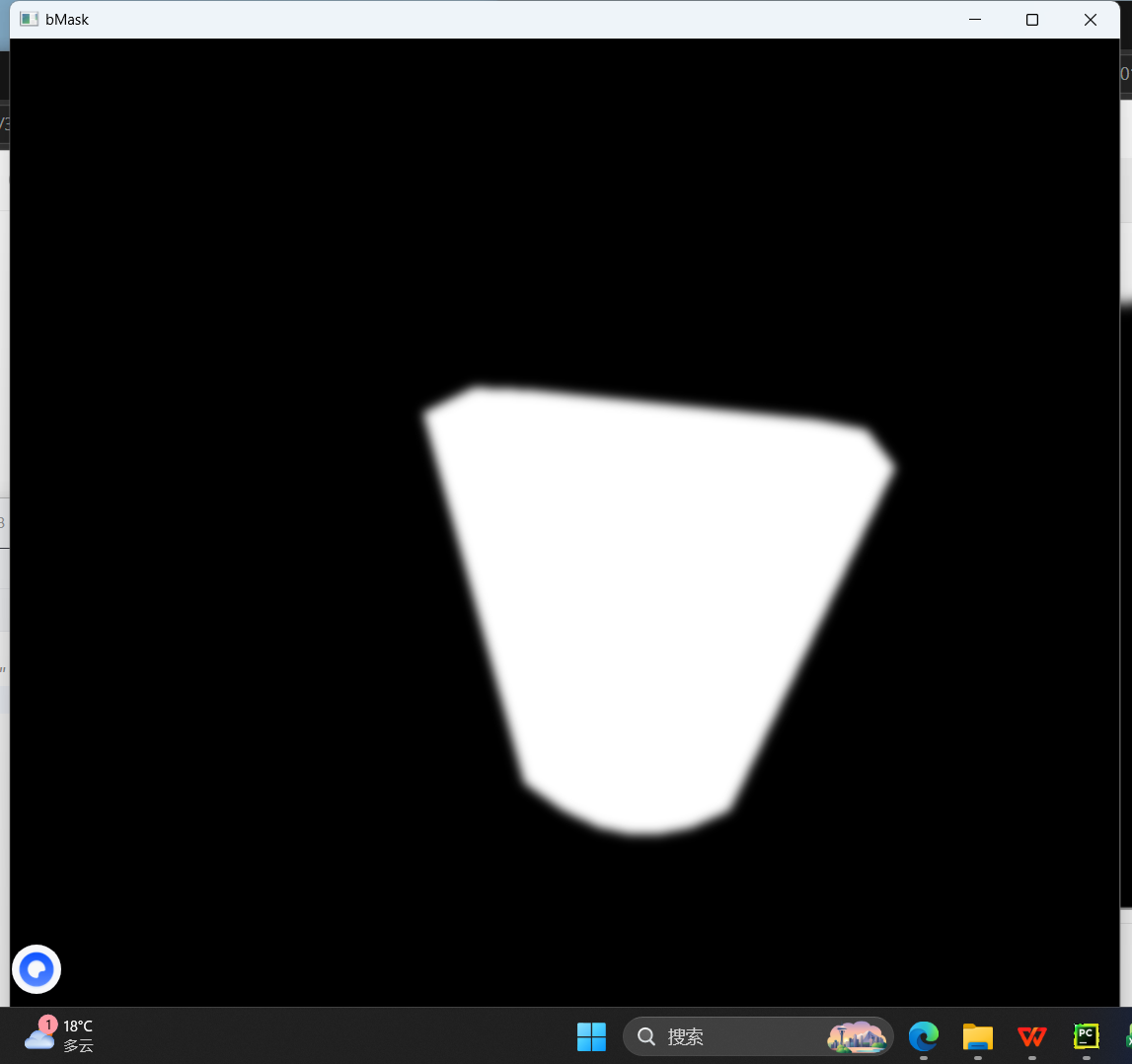
bMask = getFaceMask(b, bKeyPoints)
cv2.imshow("bMask", bMask)
cv2.waitKey()
# 5. 计算B脸对齐A脸的仿射变换矩阵
M = getM(aKeyPoints[POINTStuple],bKeyPoints[POINTStuple])
# 6. 对B脸蒙版执行仿射变换,匹配A脸的位置/大小
dsize=a.shape[:2][::-1] # 获取输出尺寸(宽,高)
bMaskWarp=cv2.warpAffine(bMask, M, dsize,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP)
cv2.imshow("bMaskWarp",bMaskWarp)
cv2.waitKey()
# 7. 融合两张蒙版,取最大值保证脸部区域完整
mask = np.max([aMask, bMaskWarp],axis=0)
cv2.imshow("mask",mask)
cv2.waitKey()
# 8. 对B脸原图执行仿射变换,对齐到A脸位置
bWrap =cv2.warpAffine(b, M, dsize,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP)
cv2.imshow("bWrap",bWrap)
cv2.waitKey()
# 9. 调整B脸肤色,匹配A脸
bcolor = normalColor(a, bWrap)
cv2.imshow("bcolor",bcolor)
cv2.waitKey()
# 10. 最终融合:蒙版区域用B脸,非蒙版区域用A脸
out = a * (1.0 - mask) + bcolor * mask
# 11. 显示结果
cv2.imshow("a",a)
cv2.imshow("b",b)
cv2.imshow("out",out/255) # 归一化到0-1,解决浮点数显示异常
cv2.waitKey()
cv2.destroyAllWindows()- 人脸关键点定义
Dlib 的 68 关键点是换脸的核心依据,我们只选择眉毛、眼睛、鼻子、嘴巴这些核心五官,因为换脸只需要对齐五官,无需全脸轮廓。
- 掩膜生成 getFaceMask
通过关键点生成人脸蒙版:
蒙版白色区域 = 人脸,黑色区域 = 背景
高斯模糊柔化边缘,避免换脸出现生硬的拼接痕迹

- 仿射变换 getM
这是换脸的核心数学逻辑:
自动计算旋转、缩放、平移参数
让 B 脸的五官完美贴合 A 脸的五官位置


- 肤色归一化 normalColor
解决肤色色差问题:
自动将 B 脸的肤色调整为 A 脸的肤色
让换脸效果更真实,不出现 "两张肤色"

- 图像融合
公式:最终图 = A图背景 + B脸肤色通过蒙版精准控制融合区域,实现无缝换脸。

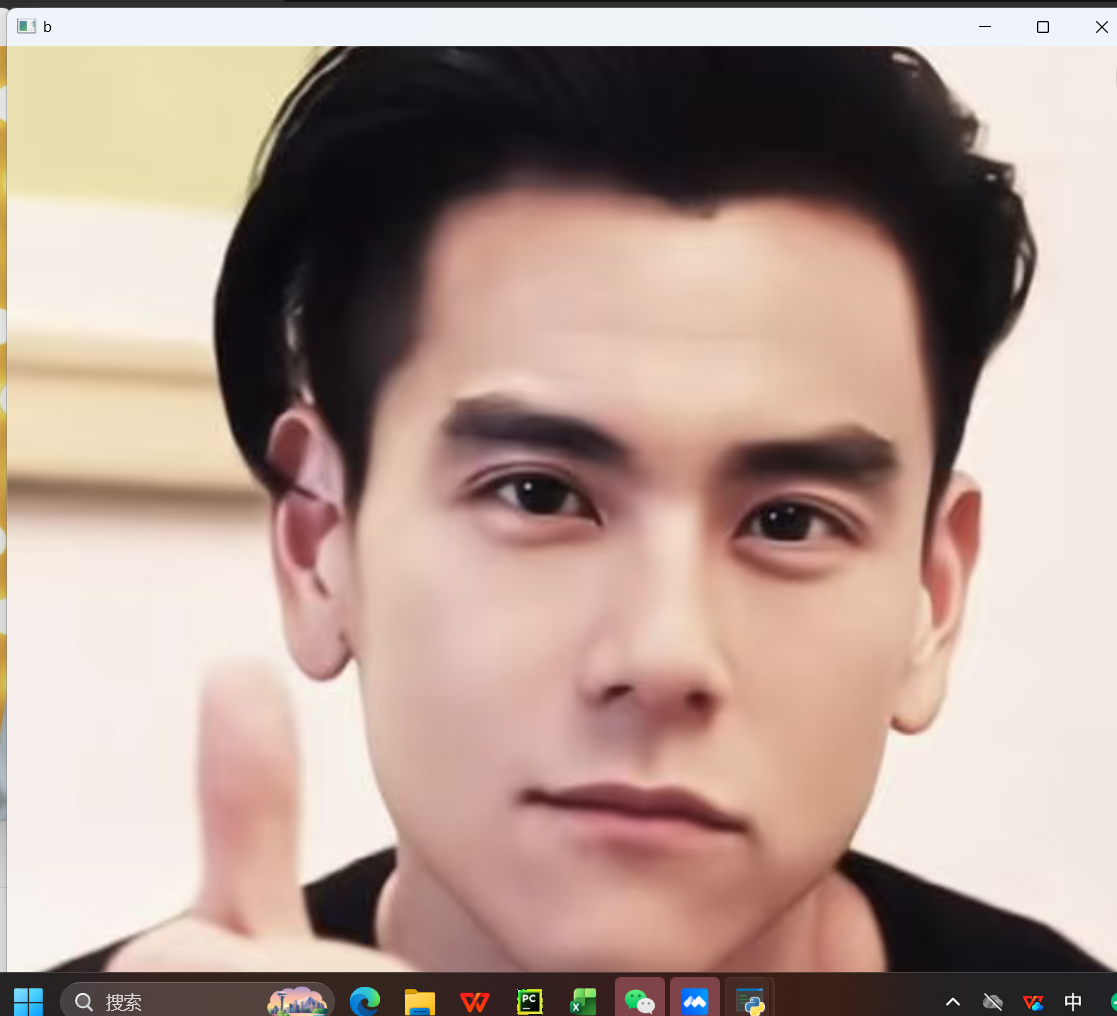
最终结果:
v
3.手部检测
这是一个零门槛、易上手的实时手部关键点识别实现方案,基于 Google 开源的 MediaPipe 框架和 OpenCV 库,无需复杂模型训练,几行代码就能实现摄像头实时手部 21 个关键点检测与可视化。
MediaPipe 手部识别的核心逻辑:通过预训练模型检测图像中的手部区域,再回归出手部 21 个关键点的三维坐标(x,y,z),同时支持关键点之间的骨骼连接绘制,我们只需调用封装好的 API 即可快速实现功能。
代码
python
import cv2
import mediapipe as mp
# 正确的导入语法!修复SyntaxError
from mediapipe import solutions
'''
mp.solutions.drawing_utils是一个绘图模块,将识别到的手部关键点信息绘制道cv2图像中,mp.solutions.drawing_style定义了绘制的风格。
mp.solutions.hands是mediapipe中的手部识别模块,可以通过它调用手部识别的api,然后通过调用mp_hands.Hands初始化手部识别类。
mp_hands.Hands中的参数:
1)static_image_mode=True适用于静态图片的手势识别,Flase适用于视频等动态识别,比较明显的区别是,若识别的手的数量超过了最大值,
True时识别的手会在多个手之间不停闪烁,而False时,超出的手不会识别,系统会自动跟踪之前已经识别过的手。默认值为False;
2)max_num_hands用于指定识别手的最大数量。默认值为2;
3)min_detection_confidence 表示最小检测信度,取值为[0.0,1.0]这个值约小越容易识别出手,用时越短,但是识别的准确度就越差。越大识别的越精准,
但是响应的时间也会增加。默认值为0.5;
4)min_tracking_confience 表示最小的追踪可信度,越大手部追踪的越准确,相应的响应时间也就越长。默认值为0.5。
'''
mp_drawing = solutions.drawing_utils
mp_hands = solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
h,w=frame.shape[:2]# 获取画面宽高
# 图像格式转换:BGR→RGB(MediaPipe仅支持RGB格式)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 因为摄像头是镜像的,所以将摄像头水平翻转
# 不是镜像的可以不翻转
frame = cv2.flip(frame, 1)
results = hands.process(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# print('hand_landmarks:', hand_landmarks)
# 计算关键点的距离,用于判断手指是否伸直
for i in range(len(hand_landmarks.landmark)):
x = hand_landmarks.landmark[i].x
y = hand_landmarks.landmark[i].y
z = hand_landmarks.landmark[i].z
print(f'关键点{i}:',x,y,z)
cv2.putText(frame, str(i), (int(x*w),int(y*h)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0),2)
# 关键点可视化
mp_drawing.draw_landmarks(frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)
cv2.imshow('MediaPipe Hands', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()1.MediaPipe 要求输入图像为 RGB 格式,而 OpenCV 默认读取 BGR 格式,必须做格式转换;
-
摄像头画面默认是镜像的,通过cv2.flip水平翻转后,视觉效果更符合日常习惯;
-
模型输出的关键点坐标是归一化值(0~1),需要乘以画面宽高转换为实际像素坐标;
-
代码中会为每个关键点标注 0~20 的编号,方便后续基于关键点坐标开发手势判断逻辑。
运行效果:
运行代码后,程序会自动调用电脑摄像头,实时识别画面中的双手,绿色数字标注 21 个关键点编号,同时绘制手部骨骼连接线。你可以随意移动双手,模型能保持实时、稳定的追踪效果,无明显卡顿。
如图所示:
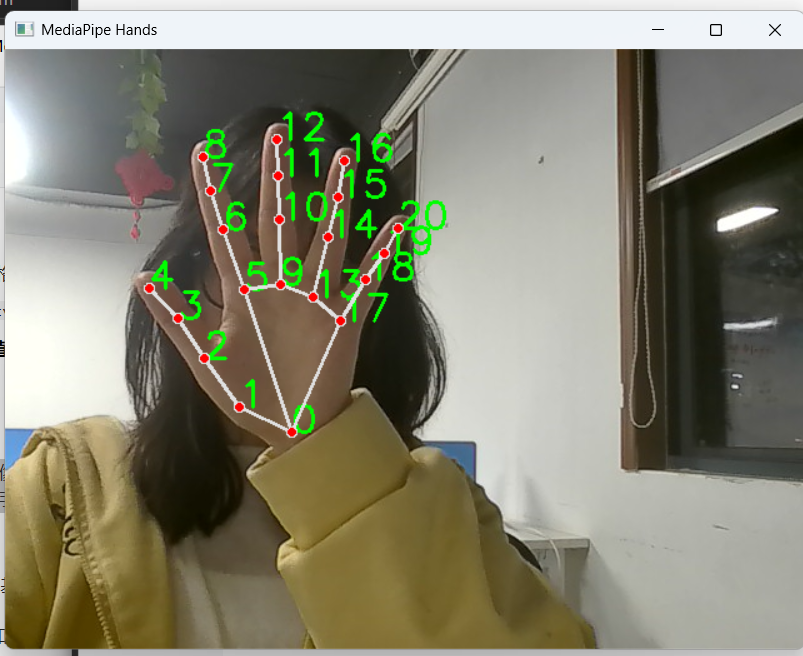
4.手势识别
在人机交互、智能控制、趣味互动项目中,手势识别是最直观、最常用的交互方式。今天我将带大家用MediaPipe 手部关键点检测+OpenCV,实现一个能实时识别数字 0~10 的手势识别系统,代码轻量、运行流畅,无需深度学习训练,直接开箱即用!
本文基于手部 21 个关键点坐标计算,通过关键点距离判断实现手指伸直 / 弯曲检测,最终完成数字手势的精准识别。
- MediaPipe 手部关键点:精准定位手部 21 个关键点坐标,我们只需要提取拇指、食指、中指、无名指、小指的指尖与手掌基准点的距离;
- 距离判断逻辑:计算指尖与手掌关键点的相对距离,设定阈值判断手指是否伸直,每伸直一根手指计数 + 1;
- 数字手势映射:根据伸直手指的总数量,映射为 0~10 的数字手势(包含特殊手势如六、七、八、九、十)。
代码
1.首先导入依赖库,定义手势名称列表和手势标记变量:
python
import cv2
import mediapipe as mp
# 定义识别的手势列表:0~10 对应数字手势
gesture = ["none", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"]
flag = 0 # 手势标记:记录伸直的手指数量
# 初始化MediaPipe绘图工具与手部识别模块
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands- 初始化手部识别模型
配置 MediaPipe 手部识别参数,适配实时视频流识别:
python
# 初始化手部识别模型
hands = mp_hands.Hands(
static_image_mode=False, # 动态视频模式
max_num_hands=2, # 支持双手识别
min_detection_confidence=0.75, # 最小检测置信度
min_tracking_confidence=0.75 # 最小追踪置信度
)static_image_mode=False:专门用于摄像头 / 视频实时识别,追踪更稳定;
置信度设为 0.75,兼顾识别精度与运行速度。
- 摄像头实时识别主逻辑
打开摄像头,循环读取视频帧,完成图像预处理、关键点推理、手势判断与画面绘制:
python
# 打开默认摄像头
cap = cv2.VideoCapture(0)
while True:
flag = 0 # 每一帧重置手势标记
ret, frame = cap.read()
# 格式转换:OpenCV默认BGR → MediaPipe要求RGB
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 水平翻转:修正摄像头镜像问题
frame = cv2.flip(frame, 1)
# 手部关键点推理
results = hands.process(frame)
# 转回BGR格式用于OpenCV展示
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)- 核心:基于关键点距离的手势判断
这是整个项目的核心!通过计算手掌基准点(0 号点、5 号点) 与各指尖关键点的距离,判断手指是否伸直,并统计数量匹配数字手势:
python
# 检测到手部时执行逻辑
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# -------------------------- 1. 提取关键点坐标 --------------------------
# 手掌基准点
p0_x, p0_y = hand_landmarks.landmark[0].x, hand_landmarks.landmark[0].y
p5_x, p5_y = hand_landmarks.landmark[5].x, hand_landmarks.landmark[5].y
# 各指尖关键点
p4_x, p4_y = hand_landmarks.landmark[4].x, hand_landmarks.landmark[4].y # 拇指
p8_x, p8_y = hand_landmarks.landmark[8].x, hand_landmarks.landmark[8].y # 食指
p12_x, p12_y = hand_landmarks.landmark[12].x, hand_landmarks.landmark[12].y # 中指
p16_x, p16_y = hand_landmarks.landmark[16].x, hand_landmarks.landmark[16].y # 无名指
p20_x, p20_y = hand_landmarks.landmark[20].x, hand_landmarks.landmark[20].y # 小指
# -------------------------- 2. 计算关键点距离 --------------------------
distance_0_5 = pow(p0_x - p5_x, 2) + pow(p0_y - p5_y, 2)
base = distance_0_5 / 0.6 # 动态基准阈值(自适应不同手型)
distance_5_4 = pow(p5_x - p4_x, 2) + pow(p5_y - p4_y, 2) # 拇指距离
distance_0_8 = pow(p0_x - p8_x, 2) + pow(p0_y - p8_y, 2) # 食指距离
distance_0_12 = pow(p0_x - p12_x, 2) + pow(p0_y - p12_y, 2)# 中指距离
distance_0_16 = pow(p0_x - p16_x, 2) + pow(p0_y - p16_y, 2)# 无名指距离
distance_0_20 = pow(p0_x - p20_x, 2) + pow(p0_y - p20_y, 2)# 小指距离
# -------------------------- 3. 判断手指是否伸直 --------------------------
if distance_0_8 > base: flag += 1 # 食指伸直
if distance_0_12 > base: flag += 1 # 中指伸直
if distance_0_16 > base: flag += 1 # 无名指伸直
if distance_0_20 > base: flag += 1 # 小指伸直
if distance_5_4 > base * 0.3: flag += 1 # 拇指伸直
if flag >= 10: flag = 10 # 限制最大标记为10
# 绘制手部关键点与连接线
mp_drawing.draw_landmarks(frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)- 绘制识别结果与窗口展示
在画面左上角实时显示识别到的数字手势,按 ESC 键退出程序:
python
# 在画面绘制识别结果
cv2.putText(frame, gesture[flag], (50, 50), 0, 1.3, (0, 0, 255), 3)
# 显示窗口
cv2.imshow('MediaPipe Hands Gesture Recognition', frame)
# 按ESC键退出
if cv2.waitKey(1) & 0xFF == 27:
break
# 释放摄像头与窗口
cap.release()
cv2.destroyAllWindows()运行效果
运行代码后,程序自动调用摄像头:
-
实时绘制手部骨骼关键点;
-
画面左上角红色大字显示当前识别的数字手势(none/one~ten);
-
手势切换流畅,识别响应速度快,支持双手、不同手型识别。
如下图所示:

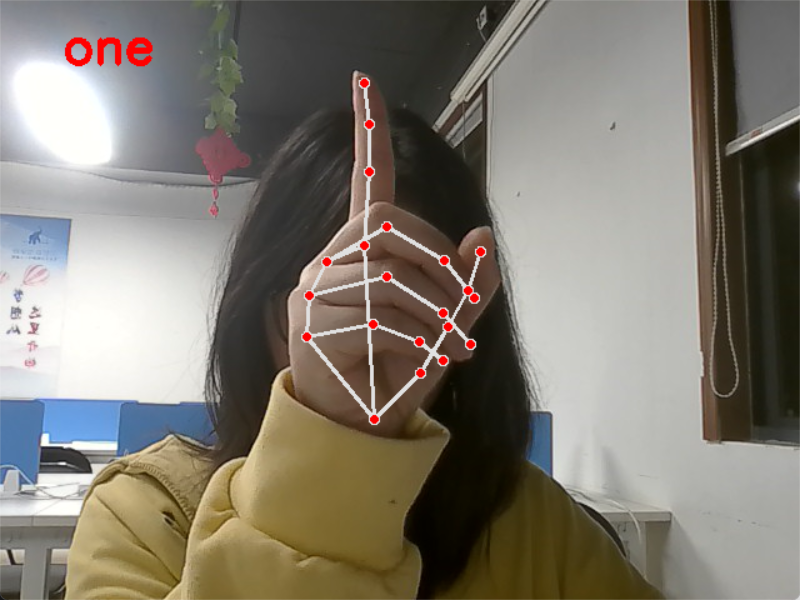
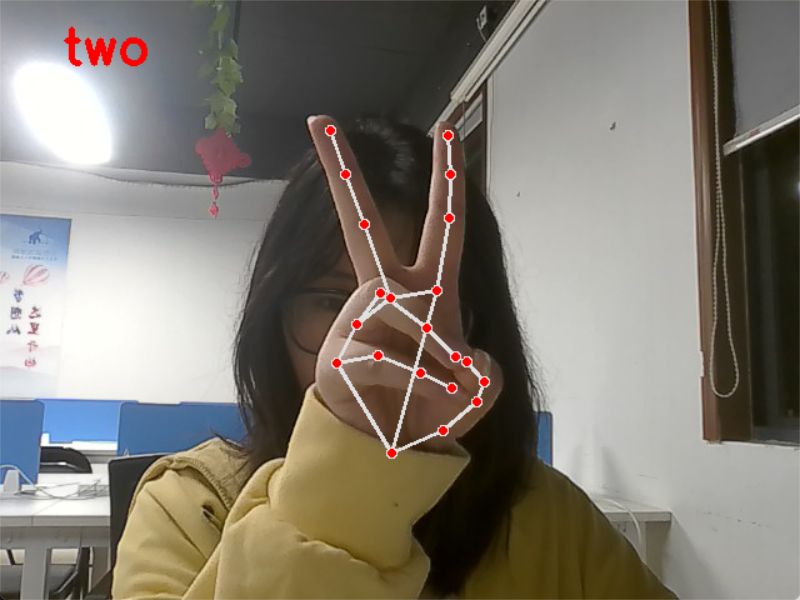
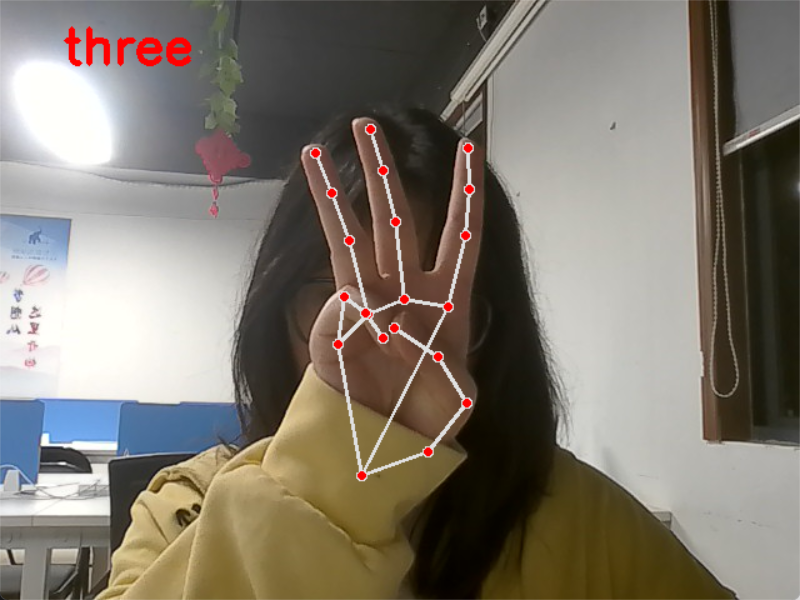
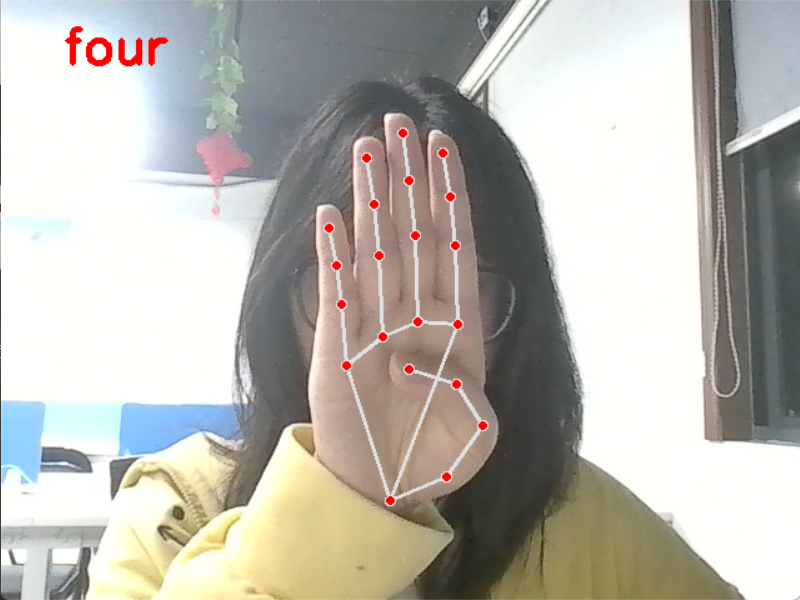

等等。。。一直到ten
5.手势数据采集工具
基于 MediaPipe 的手势数据采集工具
1.自动提取关键点:实时获取手部 21 个三维(x,y,z)关键点坐标,无需手动标注;
-
一键保存数据:按数字键 0-4 即可保存对应手势数据,自动生成 JSON 文件;
-
结构化存储:按手势类别分文件夹保存,包含类别、索引、坐标、时间戳信息;
-
实时可视化:画面显示手部骨架 + 已采集样本数量,直观易用;
-
轻量高效:CPU 实时运行,无需 GPU,新手零门槛上手。
代码
- 库导入与全局配置
python
import cv2
import mediapipe as mp
import numpy as np
import os
import json
# 初始化MediaPipe手部检测
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
# 自定义手势类别(可自由增删)
GESTURE_CLASSES = {
0: "fist", # 拳头
1: "open_hand", # 张开的手
2: "point", # 指向
3: "peace", # 剪刀手
4: "ok" # OK手势
}
DATA_DIR = "gesture_data" # 数据集保存根目录
# 自动为每个手势创建文件夹
for cls in GESTURE_CLASSES.values():
os.makedirs(os.path.join(DATA_DIR, cls), exist_ok=True)导入依赖库,定义手势类别、存储路径,自动创建数据集文件夹:
- 核心数据采集函数
封装采集逻辑,实现摄像头读取、关键点检测、数据保存一体化功能:
python
def collect_gesture_data():
"""采集手势数据,提取21个关键点的三维坐标"""
cap = cv2.VideoCapture(0) # 打开默认摄像头
# 控制台打印手势说明
print("手势类别:")
for key, value in GESTURE_CLASSES.items():
print(f"{key}: {value}")
print("按对应的数字键收集数据,按q退出")
# 样本计数器
counters = {cls: 0 for cls in GESTURE_CLASSES.values()}
# 初始化手部检测模型
with mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.7) as hands:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("无法获取摄像头画面")
break
# 格式转换:BGR→RGB(适配MediaPipe)
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(image)
# 转回BGR用于显示
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)- 关键点提取与可视化
检测到手部后,实时绘制骨架,并提取 21 个三维关键点坐标:
python
# 检测到手部时处理
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 绘制手部关键点连线
mp_drawing.draw_landmarks(
image, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# 提取21个关键点 x,y,z 坐标
landmarks = []
for lm in hand_landmarks.landmark:
landmarks.append([lm.x, lm.y, lm.z])
# 画面实时显示样本采集数量
info_text = " | ".join([f"{cls}: {count}" for cls, count in counters.items()])
cv2.putText(image, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)- 键盘控制与数据保存
按数字键保存对应手势,自动生成 JSON 文件,按q退出程序:
python
# 显示窗口
cv2.imshow('Gesture Collection (Press number key to save, q to exit)', image)
# 键盘操作
key = cv2.waitKey(5) & 0xFF
if key == ord('q'): # 按q退出
break
# 按0-4保存对应手势数据
elif chr(key) in [str(k) for k in GESTURE_CLASSES.keys()]:
cls_idx = int(chr(key))
cls_name = GESTURE_CLASSES[cls_idx]
# 仅检测到手部时保存
if results.multi_hand_landmarks:
counters[cls_name] += 1
# 构建标准化数据格式
data = {
"class": cls_name,
"class_index": cls_idx,
"landmarks": landmarks,
"timestamp": str(np.datetime64('now'))
}
# 保存为JSON文件
filename = f"{cls_name}_{counters[cls_name]}.json"
filepath = os.path.join(DATA_DIR, cls_name, filename)
with open(filepath, 'w') as f:
json.dump(data, f, indent=2)
print(f"已保存 {cls_name} 样本 #{counters[cls_name]}")
else:
print("未检测到手部,请将手放在摄像头前")
# 释放资源
cap.release()
cv2.destroyAllWindows()
# 打印采集结果
print("\n数据收集完成!")
print("样本数量统计:")
for cls, count in counters.items():
print(f"{cls}: {count}个样本")- 程序入口
python
if __name__ == "__main__":
collect_gesture_data()使用方法
1.运行代码,自动打开摄像头;
-
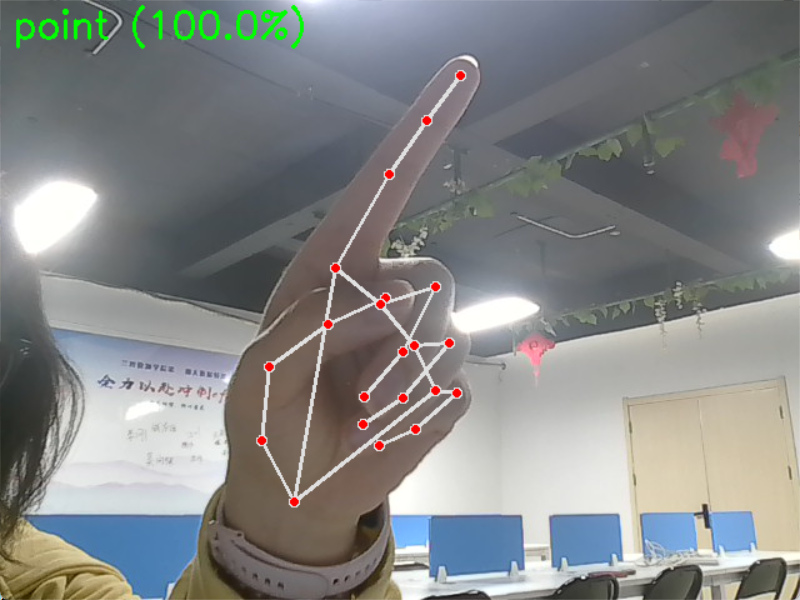
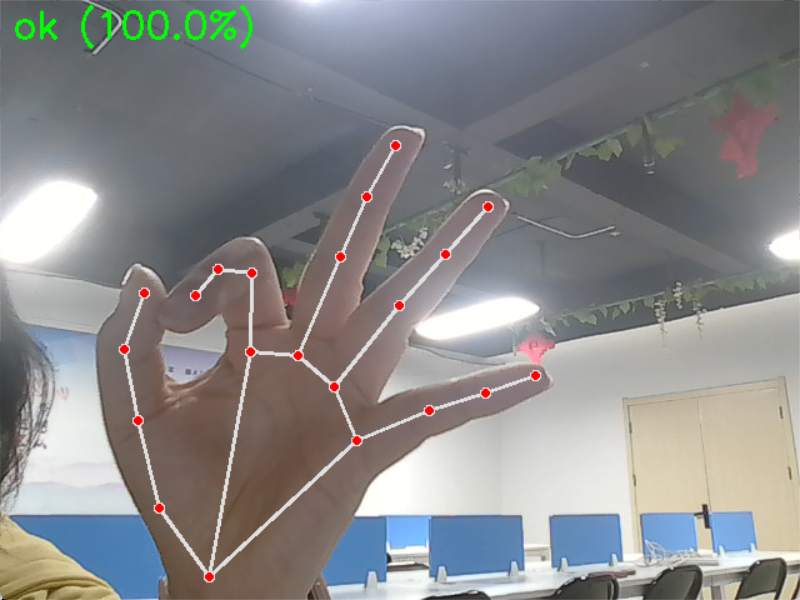
做出对应手势(0 - 拳头、1 - 手掌、2 - 指向、3 - 剪刀手、4-OK);
-
按对应数字键,自动保存该手势的关键点数据;
-
画面左上角实时显示各手势已采集样本数;
-
按q退出程序,数据集自动保存在gesture_data文件夹。
这款基于 MediaPipe 的手势数据采集工具,解决了手势识别项目中数据难获取、标注耗时间的核心问题,代码简洁、功能完整,一键生成高质量关键点数据集。
数据集格式说明
bash
gesture_data/
├── fist/
│ ├── fist_1.json
│ ├── fist_2.json
├── open_hand/
├── point/
├── peace/
└── ok/单条 JSON 数据包含:
• class:手势类别名称
• class_index:类别数字索引
• landmarks:21 个关键点三维坐标列表
• timestamp:采集时间戳
6.建完整手势识别系统:数据采集→模型训练→实时部署
1.加载已采集的手势关键点数据(JSON 格式)
-
数据预处理(特征展平、标准化、数据集划分)
-
训练 4 种经典机器学习模型
KNN
SVM
决策树
随机森林
-
自动选择准确率最高的模型并保存
-
生成混淆矩阵直观查看分类效果
-
实时摄像头手势识别
代码:
- 库导入与全局配置
python
import os
import json
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import joblib
import seaborn as sns
# 数据目录与手势类别(必须与采集程序一致)
DATA_DIR = "gesture_data"
GESTURE_CLASSES = {
0: "fist", # 拳头
1: "open_hand", # 张开手
2: "point", # 指向
3: "peace", # 剪刀手
4: "ok" # OK
}- 加载手势数据集
自动读取所有 JSON 关键点,将 21 个关键点 × 3 维坐标 → 63 维特征向量。
python
def load_gesture_data():
X = [] # 特征
y = [] # 标签
for cls_idx, cls_name in GESTURE_CLASSES.items():
cls_dir = os.path.join(DATA_DIR, cls_name)
if not os.path.exists(cls_dir):
print(f"警告:{cls_name} 文件夹不存在")
continue
for filename in os.listdir(cls_dir):
if filename.endswith(".json"):
with open(os.path.join(cls_dir, filename), 'r') as f:
data = json.load(f)
# 展平为 63 维特征
feature_vector = []
for lm in data["landmarks"]:
feature_vector.extend(lm)
X.append(feature_vector)
y.append(cls_idx)
print(f"共加载 {len(X)} 个样本,特征维度:{len(X[0]) if X else 0}")
return np.array(X), np.array(y)- 训练模型 & 自动选择最优模型
同时训练 KNN、SVM、决策树、随机森林,自动保存准确率最高的模型。
python
def train_and_evaluate_models():
X, y = load_gesture_data()
if len(X) == 0:
print("请先采集数据!")
return
# 划分训练集/测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
joblib.dump(scaler, "scaler.pkl")
# 定义模型
models = {
"K近邻": KNeighborsClassifier(5),
"支持向量机": SVC(kernel='rbf', probability=True),
"决策树": DecisionTreeClassifier(max_depth=10),
"随机森林": RandomForestClassifier()
}
best_acc = 0
best_model = None
best_name = ""
print("\n===== 模型训练结果 =====")
for name, model in models.items():
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
acc = accuracy_score(y_test, y_pred)
print(f"\n{name} 准确率:{acc:.4f}")
print(classification_report(y_test, y_pred, target_names=GESTURE_CLASSES.values()))
if acc > best_acc:
best_acc = acc
best_model = model
best_name = name
# 保存最佳模型
joblib.dump(best_model, "best_gesture_model.pkl")
print(f"\n最佳模型:{best_name},准确率:{best_acc:.4f}")
# 绘制混淆矩阵
y_pred_best = best_model.predict(X_test_scaled)
cm = confusion_matrix(y_test, y_pred_best)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=GESTURE_CLASSES.values(),
yticklabels=GESTURE_CLASSES.values())
plt.xlabel("预测")
plt.ylabel("真实")
plt.title(f"{best_name} 混淆矩阵")
plt.savefig("confusion_matrix.png")
print("混淆矩阵已保存")- 实时摄像头手势识别
加载训练好的模型,实现摄像头实时推理。
python
def real_time_recognition():
import cv2
import mediapipe as mp
# 加载模型
try:
model = joblib.load("best_gesture_model.pkl")
scaler = joblib.load("scaler.pkl")
except:
print("请先训练模型!")
return
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
cap = cv2.VideoCapture(0)
with mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.7
) as hands:
while cap.isOpened():
ret, frame = cap.read()
if not ret: break
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(image)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hlm in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(image, hlm, mp_hands.HAND_CONNECTIONS)
# 构造特征
lm_list = []
for lm in hlm.landmark:
lm_list.extend([lm.x, lm.y, lm.z])
# 预测
lm_scaled = scaler.transform([lm_list])
pred = model.predict(lm_scaled)
cls = GESTURE_CLASSES[pred[0]]
# 显示置信度
prob = model.predict_proba(lm_scaled)[0]
text = f"{cls} ({max(prob)*100:.1f}%)"
cv2.putText(image, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,255,0), 2)
cv2.imshow("Gesture Recognition", image)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()- 主程序入口(命令行模式)
python
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='手势识别系统')
parser.add_argument('--train', action='store_true', help='训练模型')
parser.add_argument('--recognize', action='store_true', help='实时识别')
args = parser.parse_args()
if args.train:
train_and_evaluate_models()
elif args.recognize:
real_time_recognition()
else:
print("使用方法:")
print(" 训练:python 文件名.py --train")
print(" 识别:python 文件名.py --recognize")运行方法
- 训练模型
python
python gesture_train.py --train项目输出文件
运行后会自动生成:
best_gesture_model.pkl→ 最优模型scaler.pkl→ 标准化器confusion_matrix.png→ 混淆矩阵图- 控制台输出:各模型精确率、召回率、F1 分数
先用上面手势收集的工具收集0 - 拳头、1 - 手掌、2 - 指向、3 - 剪刀手、4-OK各35个,一共 175 个样本
运行结果:
bash
加载完成! 共 175 个样本,每个样本 63 维特征
模型训练和评估结果:
K近邻分类器 准确率: 0.8571
分类报告:
precision recall f1-score support
fist 0.88 1.00 0.93 7
open_hand 0.75 0.86 0.80 7
point 1.00 0.71 0.83 7
peace 0.71 0.71 0.71 7
ok 1.00 1.00 1.00 7
accuracy 0.86 35
macro avg 0.87 0.86 0.86 35
weighted avg 0.87 0.86 0.86 35
支持向量机 准确率: 0.9714
分类报告:
precision recall f1-score support
fist 1.00 1.00 1.00 7
open_hand 1.00 1.00 1.00 7
point 1.00 0.86 0.92 7
peace 0.88 1.00 0.93 7
ok 1.00 1.00 1.00 7
accuracy 0.97 35
macro avg 0.97 0.97 0.97 35
weighted avg 0.97 0.97 0.97 35
决策树 准确率: 1.0000
分类报告:
precision recall f1-score support
fist 1.00 1.00 1.00 7
open_hand 1.00 1.00 1.00 7
point 1.00 1.00 1.00 7
peace 1.00 1.00 1.00 7
ok 1.00 1.00 1.00 7
accuracy 1.00 35
macro avg 1.00 1.00 1.00 35
weighted avg 1.00 1.00 1.00 35
随机森林 准确率: 1.0000
分类报告:
precision recall f1-score support
fist 1.00 1.00 1.00 7
open_hand 1.00 1.00 1.00 7
point 1.00 1.00 1.00 7
peace 1.00 1.00 1.00 7
ok 1.00 1.00 1.00 7
accuracy 1.00 35
macro avg 1.00 1.00 1.00 35
weighted avg 1.00 1.00 1.00 35
最佳模型是: 决策树,准确率: 1.0000
最佳模型已保存为 best_gesture_model.pkl
特征标准化器已保存为 scaler.pkl混淆矩阵:
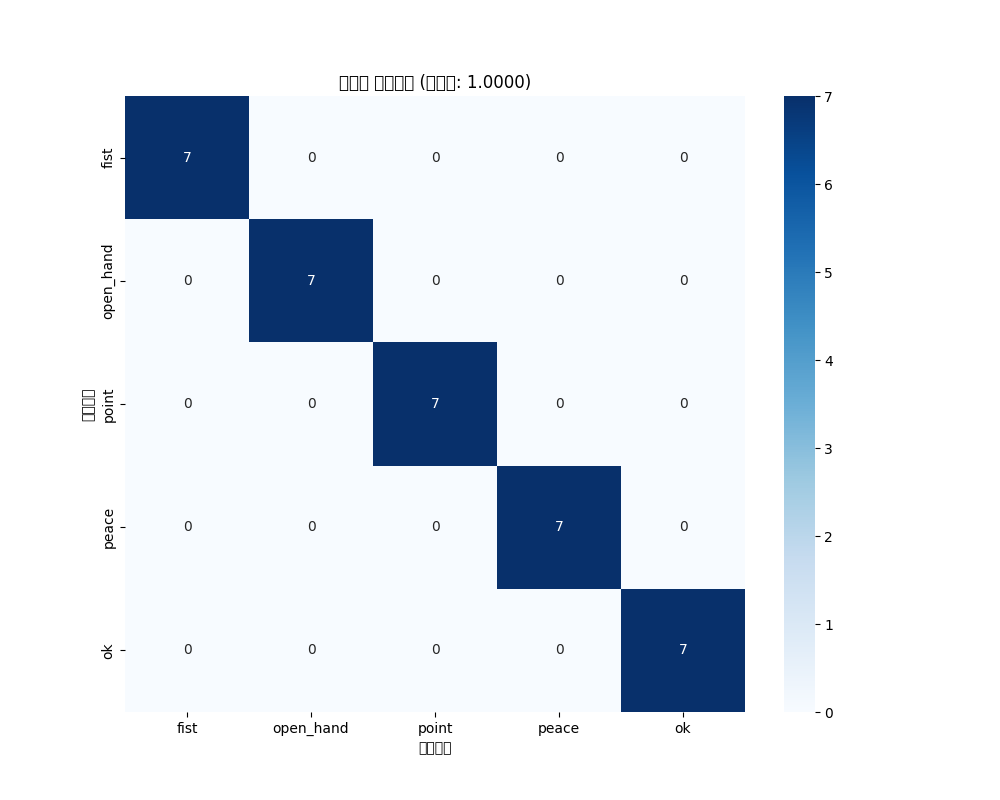
- 实时手势识别
python
python gesture_train.py --recognize