不能直接"自动连接",但你可以通过 "手动搬运 + Rehash" 的方式,把它们收编进 pyenv-win 的管理体系中。
由于 pyenv-win 只认自己 versions 文件夹下的结构,
虚拟环境(venv) :如果你以前的项目里已经有 .venv 文件夹,它们内部记录的是旧的绝对路径 。收编后,这些旧的虚拟环境可能会失效。建议直接删掉旧的 .venv 文件夹,用新环境重新生成一个:python -m venv .venv 。
- 更稳妥的方法 :如果原来的 Python 里没装太多复杂的库,最推荐的做法是直接
pyenv install 3.10.11重新装一遍,然后用pip install -r requirements.txt恢复库,这样最干净,不会有路径残留问题。
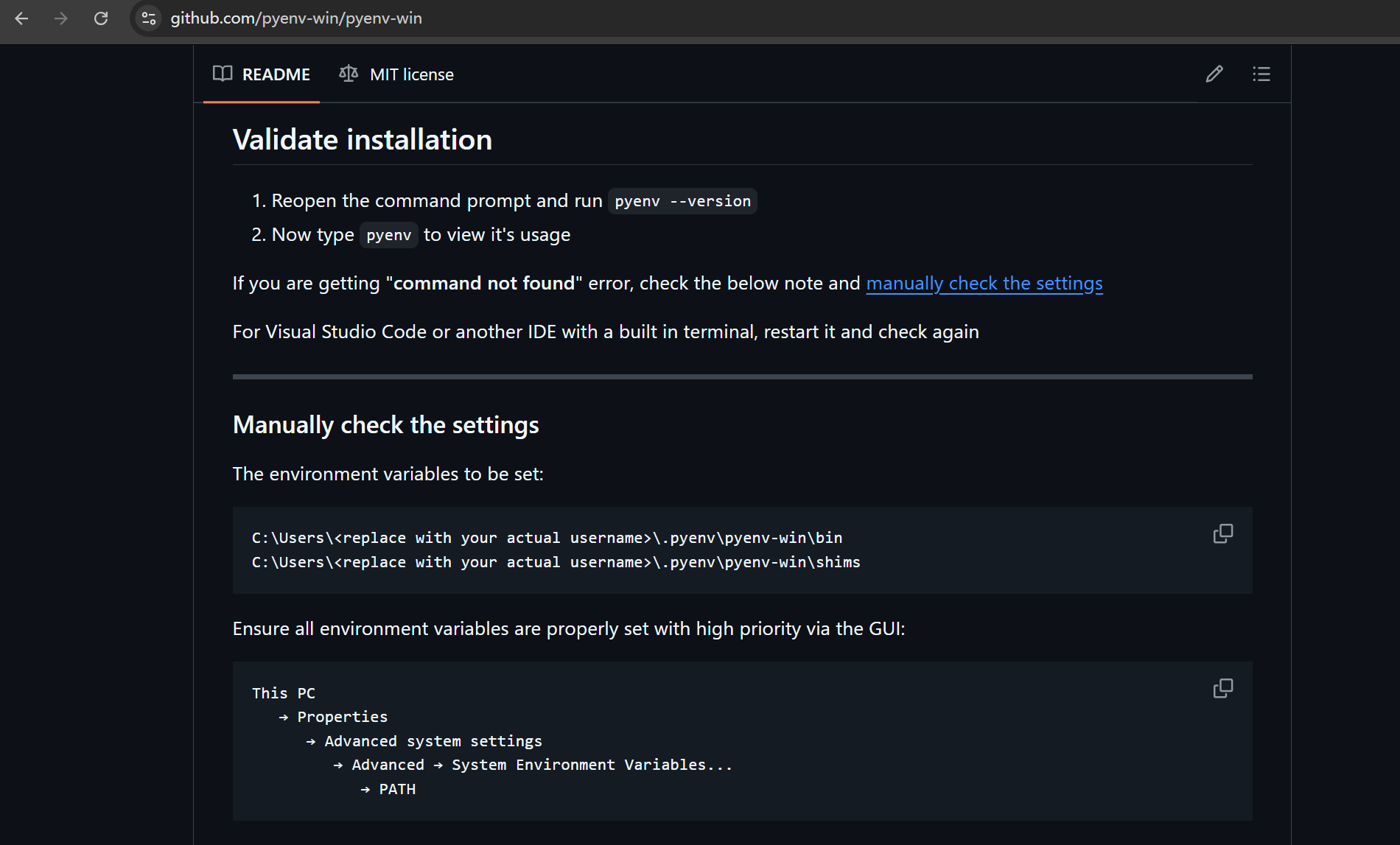
截图要求你将 ...\bin 和 ...\shims 放在 PATH 的最前面(High Priority)。
- 原因 :Windows 寻找
python命令是按PATH列表从上到下挨个找的。 - 风险 :如果你以后安装了其他软件(比如某些 IDE 或工具)也带了 Python,或者你没卸载干净旧 Python,它们的路径可能会排在
pyenv前面。
- 如果你以后安装了其他软件(比如某些 IDE 或工具)也带了 Python,或者你没卸载干净旧 Python,它们的路径可能会排在
pyenv前面。 - 后果 :到时候你敲
python,系统会跳过pyenv去执行别的 Python,导致pyenv global失效,让你抓狂。
也是好事啊,ue里就内置python,总不能抢占了吧,所以这些都是为掌控欲强的用户设计的,
为了不让大脑过载,你只需要记住这 5 个 核心动作:
| 动作 | 命令 | 什么时候用? |
|---|---|---|
| 安装 | pyenv install 3.x.x |
想要一个新版本时。 |
| 查看 | pyenv versions |
忘了自己装了啥,或者确认当前在用谁。 |
| 全局切 | pyenv global 3.x.x |
想改全电脑默认的 Python 时。 |
| 项目切 | pyenv local 3.x.x |
最常用! 进入项目文件夹后,锁定该项目版本。 |
| 刷新 | pyenv rehash |
救命药! 发现命令不灵、或者刚装完新版本/插件时,敲一下。 |
- 一个终极原则(避坑指南)
只要你用了pyenv,请刻在脑子里:
永远不要再通过.exe安装包去官网下载 Python 了!
所有的下载、删除、切换,全部交给pyenv这一间办公室处理。
在环境变量里没有看到pyenv额外加python的什么环境变量,为什么不用担心?
这正是
pyenv-win 设计最精妙的地方!你之所以在环境变量里看不到每一个具体 Python 版本的路径(比如 ...\versions\3.12.0 ), 是因为它使用了 "以一抵百"的垫片(Shims)机制 。
为什么不需要额外的环境变量?
传统的安装方式是把每一个 Python 的 bin 目录都塞进 Path 。但 pyenv 只在你的 Path 里塞了 两个固定的位置:
...\.pyenv\pyenv-win\bin(存放pyenv命令本身)...\.pyenv\pyenv-win\shims(存放垫片程序)
关键点: 无论你安装了 5 个还是 10 个 Python 版本,你的系统 Path 永远只需要这两行,保持得非常干净。
"垫片 (Shims)" 是如何工作的?
当你输入 python 命令时,系统并不知道你具体要用哪个版本,它只会在 Path 里找到 shims 文件夹下的一个名为 python.bat (或 .exe )的伪装程序:
- 拦截 :你敲
python,实际上运行的是shims里的那个"伪装者"。 - 判断 :这个伪装者会立刻问
pyenv:"嘿,当前用户是在哪个文件夹?他有没有设置local版本?或者有没有global版本?" - 转发 :一旦确定是 3.12,它就瞬间把你的指令转发给
...\versions\3.12.0\python.exe。
所以: 你不需要为每个版本加环境变量,因为 Shims 文件夹已经代表了所有版本。
什么是 Shim(垫片/填隙片)?
在机械工程中, Shim 是一种塞进缝隙里的小垫片,用来对齐零件。在计算机软件中,它指的是 "透明拦截层"。
rehash vs. refresh 有什么区别?
pyenv rehash(核心命令)
- 字面意思:重新哈希/重新扫描。
- 它在做什么 :它会扫描你所有已安装的 Python 版本(
versions文件夹),看看里面有没有新的可执行文件(比如你刚装了pip插件带的命令)。 - 什么时候用 :
- 你刚用
pyenv install装了一个新 Python 版本。 - 你刚用
pip install装了一个带有命令行工具的库 (比如pytest、flake8、black)。
- 你刚用
- 效果 :它会在
shims文件夹里生成对应的"管家"文件。如果你不rehash,你可能敲pytest会提示"找不到命令",尽管你已经装了它。
Refresh(通常指刷新环境变量/终端)
指重启你的 PowerShell/CMD 窗口 或者手动让 Windows 重新读取 PATH 变量。
没有 LFS 时?
Git 对所有文件(不管文本还是二进制)都是一视同仁:
每次修改 → 生成一个完整的新 blob(对象)
git gc 时尝试 delta 差量压缩(找相似对象做 diff)
但二进制文件(图片、视频、PSD、模型文件、exe 等)几乎无法有效 delta(改 1 个像素,整文件就变了)
结果就是:
仓库 .git/objects/ 和 packfile 里塞满巨大 blob
每次 push / pull / gc 都要读写海量数据 → 磁盘 IO 爆满、CPU 狂转
几百人同时提交 → git服务器直接卡死("磁盘IO卡死"就是这个场景)
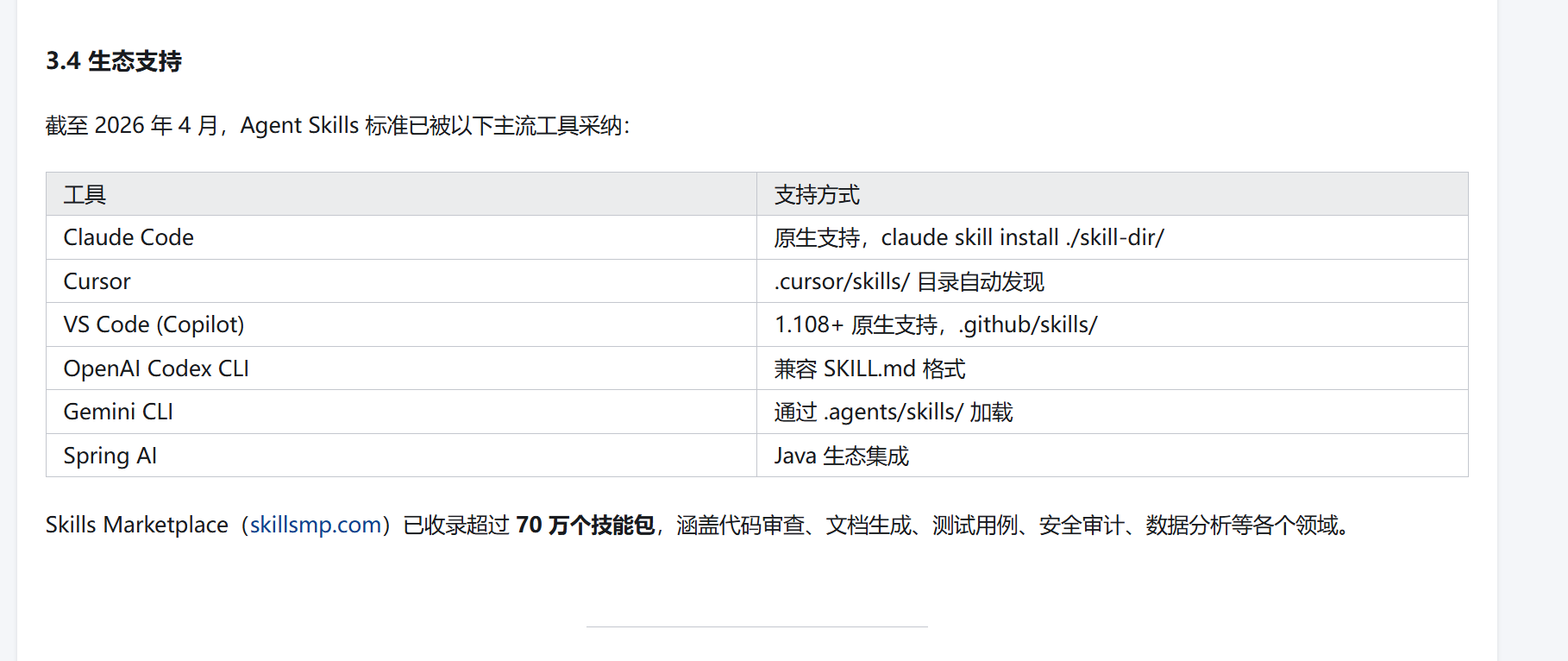
Skills Marketplace(http://skillsmp.com)已收录超过 70 万个技能包,涵盖代码审查、文档生成、测试用例、安全审计、数据分析等各个领域。
Content 的本质 :Content 文件夹里的 .uasset 和 .umap 是二进制文件。AI 无法像阅读代码那样"阅读"模型或材质的内部数据,更无法直接修改它们。
在虚幻引擎(UE)中,
.uasset 资源文件是二进制格式的,Aider 无法像修改代码那样直接编辑它们。要实现"修改材质实例参数"或"绑定图片"的自动化,最高效的源码级流程是利用 UE Python API。
你可以让 Aider 编写一段 Python 脚本,然后在 UE 编辑器中运行该脚本来完成修改。
核心实现流程
- 准备工作
确保你的 UE 项目已启用以下插件:
- Python Editor Script Plugin
- Editor Scripting Utilities
-
让 Aider 编写 Python 自动化脚本
你可以直接给 Aider 下达类似这样的指令:
"编写一个 UE Python 脚本,修改路径为/Game/Materials/MI_Test的材质实例。要求:将标量参数Roughness设为0.5,并将纹理参数BaseTexture绑定到/Game/Textures/T_Color。"
如何在 UE 中执行 -
在 Aider 中生成文件 :让 Aider 将上述代码保存为
update_mi.py。 -
在 UE 中运行 :
- 方法 A:打开 UE 菜单 Tools > Control Assets > Python Console ,输入
py "你的脚本完整路径"。 - 方法 B:直接将脚本文件拖入 UE 界面(如果安装了相关辅助工具)。
- 方法 A:打开 UE 菜单 Tools > Control Assets > Python Console ,输入
适用场景 :纯 C++ 插件开发,或者使用外部同步工具(如 Perforce, PlasticSCM, 或网盘)来同步 Content 文件夹。
是的,Unreal Engine (UE) 项目根目录下的
Config 文件夹存储的是项目设置(Project Settings)以及引擎的配置文件。它采用 .ini 格式,用于控制项目配置、输入绑定、插件设置和打包选项,是版本控制中必须纳入的关键目录。
.aider.tags.cache.v4(文件夹):这是 Aider 最关键的缓存。它存储了项目代码的"代码标签(Tags)"索引。Aider 靠它来理解代码之间的引用关系,从而即使不把所有文件加入对话,也能定位到相关的函数定义。.aider.chat.history.md:这是 Aider 自动记录的聊天日志。它以 Markdown 格式保存了你和 AI 之间的所有对话记录和修改历史。.gitignore中的内容(可能) :如果你在启动 Aider 时它发现没有 Git 仓库,它会建议初始化并可能自动在.gitignore中加入上述两个缓存文件的路
.ignore 是 Aider 生成的吗?
结论:不是由 Aider 默认生成的。
- Aider 规范 :Aider 默认使用 Git 进行版本控制,并严格遵循
.gitignore的规则。 .ignore的来源 :这个文件通常由 IDE 插件 (如 VS Code 的 "Ignore" 插件)或者某些 特定的 CLI 工具 生成。在你的截图中,它被识别为 "IGNORE 文件",且修改日期(4/5)早于.gitignore的最近修改日期(4/7)。- 注意 :在 Git 的逻辑中,
.ignore文件本身并没有官方效力,除非它是某些特定同步工具(如 Syncthing)的配置文件。
.sln 是一个派生文件 (Derived File)。只要你有 .uproject 和 Source/ 文件夹,你随时可以右键点击 .uproject 选择 "Generate Visual Studio project files" 来重新生成它。
Aider 默认只在检测到 Git 仓库时才允许大规模操作。这是为了确保每一行 AI 生成的代码都有 Git 提交记录,方便你随时回滚(Undo)。
"You can
/addany file in your project to the chat, even if it's not yet tracked by git. Once added, Aider can read and edit that file."
(你可以将项目中任何文件/add到对话中,即使它尚未被 Git 追踪。一旦添加,Aider 就能读取并编辑该文件。)
Repo-map: using 4096 tokens 表示 Aider 已经扫描了你的项目结构,并创建了一个"代码地图",这样 AI 就能知道不同文件之间的引用关系,而不需要读取每一个文件的全文。
aider --model openrouter/openai/gpt-4o
aider --models openrouter/In-chat Commands
启动时切换 (CLI Flags)
在终端启动 Aider 时,通过参数直接指定模型:
aider --model <模型名称>:指定主模型。aider --list-models <搜索词>:在启动前列出匹配的模型名称。
最新版本的 Aider 支持为不同任务指定不同的模型以优化成本和性能:
--editor-model:专门用于代码编辑的模型。--weak-model:用于简单任务(如生成 commit 信息、总结历史)的廉价模型。--thinking-tokens:针对 Claude 3.7 Sonnet 等推理模型,可以设置思维链(thinking)的 token 预算,例如--thinking-tokens 4k。
/models <搜索词>:如果你不确定完整的模型 ID,可以用此指令搜索可用模型。- 示例 :
/models claude会列出所有包含 "claude" 字符的模型全称。
- 示例 :
/think-tokens <数量>(针对推理模型):在切换到如 Claude 3.7 Sonnet 等支持推理的模型后,可用此指令设置"思考"部分的 Token 预算。-
- 示例 :
/think-tokens 4k。
- 示例 :
/reasoning-effort <等级>(针对 o1 系列):控制推理模型的思考强度(如low,medium,high)
输入 /tokens 可以查看当前生效的模型信息、剩余上下文窗口以及计费标准。
针对
Silicon Flow (硅基流动) 这种兼容 OpenAI 接口的自定义 API,Aider 目前 无法直接在会话内 (in-chat) 通过一条指令同时修改 Base URL 和 API Key。
你需要先通过环境变量配置好 API 信息,然后在启动或会话内指定模型。以下是具体操作步骤:
会话内切换 (In-chat)
如果你已经按上述步骤启动了 Aider,想在会话中切换到 Silicon Flow 上的其他模型,直接使用 /model 指令:
/model openai/deepseek-ai/DeepSeek-R1/model openai/Pro/deepseek-ai/DeepSeek-V3(根据 Silicon Flow 具体的模型 ID 填写)
别名建议 :如果你觉得每次输入太长,可以在启动时设置别名:
aider --alias sf:openai/deepseek-ai/DeepSeek-V3
之后在会话内只需输入 /model sf 即可快速切换。
使用 .env 本地文件(最推荐)
在你的项目根目录下创建一个名为 .env 的文件,将 Silicon Flow 的配置写进去:
bash
OPENAI_API_BASE=https://siliconflow.cn
OPENAI_API_KEY=你的SiliconFlow_API_KEY优点: Aider 启动时会自动读取当前目录下的 .env 。你甚至可以为不同的项目设置不同的 Key,互不干扰。
使用 Aider 专用的 yaml 配置文件
在项目根目录创建 .aider.conf.yml ,直接定义模型和 API 行为:
yaml
model: openai/deepseek-ai/DeepSeek-V3
openai-api-base: https://siliconflow.cn
openai-api-key: 你的SiliconFlow_API_KEY优点: 连启动命令都省了,直接输入 aider 就能自动加载 Silicon Flow 的配置。
Editor Model (編輯模型) ------ 「代碼打字員」
這是一個比較特殊的角色,通常在主模型 無法穩定生成正確的代碼差異 (diff) 時被激活。
-
職責: 專門負責將主模型的「意圖」轉化為具體的「代碼修改指令」。
-
用途: 如果主模型很聰明但不太會寫 Aider 指定的
diff格式,Aider 會請一個專門擅長寫diff的模型來幫忙完成最後的「寫入」動作。 -
現狀: 對於
Claude 3.5 Sonnet或GPT-4o這種強大模型,它們通常自己就能兼任 Editor,所以你可能看不到獨立的 Editor Model。/model
Aider v0.86.2
Main model: openrouter/anthropic/claude-sonnet-4 with diff edit format, infinite output
Weak model: openrouter/anthropic/claude-3-5-haiku
Git repo: .git with 0 files
Repo-map: using 4096 tokens, auto refresh
命令行参数的优先级高于配置文件。如果你在 .aider.conf.yml 中默认配置了 gpt-4o ,但想临时换用 claude-3-5-sonnet ,直接在启动时指定:
bash
aider --model claude-3-5-sonnet-20240620默认 开启的 (默认即生效)
stream: true:默认会流式输出字符。pretty: true:默认会使用彩色终端和表情符号。check-update: true:默认启动时会检查是否有新版本。show-diffs: true:默认在修改代码后会显示差异(Diff)。
默认 关闭的 (需要你在配置文件中手动开启)
auto-commits: false:这是最关键的 。默认情况下,Aider 修改完代码后会问你"是否提交?",只有你输入/commit或设置true后才会自动提交。architect: false:默认进入的是code模式(直接写代码)。最新的"先思考再写"模式(Architect)需要手动开启或启动时加参数。chat-language:默认跟随系统环境(通常是英文)。如果你希望 AI 始终回中文,建议手动设为zh。cache-prompts: false:由于不是所有 API 供应商都支持(目前 Anthropic 和 DeepSeek 官方支持较好),Aider 默认不强制开启缓存。dirty-commits: false:如果你的 Git 仓库有未提交的改动,Aider 默认会警告你,甚至拒绝运行。
流做法是將 OpenCV 作為圖像輸入的橋樑,核心識別則依賴 MediaPipe。
本质上是一个连续信号问题,不是离散状态问题。摄像头里的人脸位置本来就是连续变化的,最后你还要做平滑、死区、灵敏度调节、阈值判断。这个时候直接输出:
-
HorizontalOffset∈[-1, 1] -
VerticalOffset∈[-1, 1]
是最干净的底层接口。
Actor 比 Component 更适合第一版落地 。
第一版目标是先把整条链跑通,不是做最终最优架构。独立 Actor 的优点是:
-
放进关卡就能跑
-
生命周期清晰
-
调试方便
-
不需要先考虑挂到谁身上
-
便于可视化和快速验证
Component 当然在长期架构上更灵活,但第一版会引入更多设计问题:
-
挂在哪个 Actor 上
-
是否要求宿主必须有 Tick
-
多实例管理怎么做
-
与摄像机/角色耦合边界怎么划
把核心检测和计算逻辑抽到 UObject / Component / Subsystem
这时再考虑复用性和架构收敛。
我给你一个很明确的判断:
-
想要最快做成、后面不吃亏 → 选 归一化数值 + Actor
-
想要最省脑但后面很快重构 → 方向标签版
-
想要架构更漂亮但当前开发更慢 → Component 版
USTRUCT 是 Unreal 的反射宏。给结构体加上它以后,这个结构体就能被 UE 的反射系统识别,进而支持蓝图、序列化、编辑器显示、网络复制等一部分能力。
USTRUCT(...) 是给 UE 看的,不是普通 C++ 关键字。
用了 USTRUCT 的结构体,通常还要配 GENERATED_BODY()。
结构体里的成员如果想暴露给蓝图或编辑器,一般还要写 UPROPERTY(...)。
这个头文件通常还要包含对应的 xxx.generated.h,并且放在最后一个 #include。
#pragma once
#include "CoreMinimal.h"
#include "FaceTrackerTypes.generated.h"
USTRUCT(BlueprintType)
struct FFaceTrackerResult
{
GENERATED_BODY()
UPROPERTY(BlueprintReadOnly, EditAnywhere)
bool bFaceVisible = false;
};
加了像 USTRUCT、UCLASS、UPROPERTY、UFUNCTION 这些宏之后,UE 就会把它登记到自己的系统里。
就可能出现在:
编辑器 Details 面板里,能手动改值;
Blueprint 里,能读、能写、能连线调用;
序列化/保存加载/网络复制这些 UE 功能里。
这个变量能在 Unreal Editor 里显示出来,比如你点中某个 Actor,在右边 Details 面板里能看到这个变量,并且可能可以直接改。
UPROPERTY(EditAnywhere)
float Speed = 100.f;
这通常表示这个值可以在编辑器里改。
你把某个蓝图类、Actor 实例选中后,可能就能在 Details 面板看到 Speed。
可以让它间接调用你写的 HLSL,
Custom Material Expression 支持写自定义 HLSL,并且有 Include File Paths 这类能力,说明它本来就支持把代码组织到外部 include 文件里
.usf 更像 shader 源文件/实现文件 ,.ush 更像 shader 头文件/include 文件。
明确把 .usf 叫 Unreal Shader files ,用于存放引擎使用的着色器代码;而在社区官方教程里也直接把 .usf / .ush 分别解释成 Unreal Shader File 和 Unreal Shader Header。
"生成出来的 HLSL"通常是:
-
引擎内部编译产物/中间结果
-
混有大量 UE 材质模板、宏、平台适配代码
-
不是给你当成干净的、可长期维护的
.usf/.ush源文件直接回写工程用的。
Material Parameter / Material Instance Parameter 跟 Sequencer 联动,所以视频里才会提到参数命名、唯一名之类的事。因为 Sequencer 要知道它到底驱动哪个参数。
FFaceTrackingResult 里的 F 表示它是一个 struct/value type 这一类的 UE 类型前缀 。更准确说,这是 Epic 的历史命名约定,不是标准 C++ 语法要求,也不是反射系统硬性要求必须这样写。
F:普通结构体 / 值类型 / 非 UObject 基础类型
S:Slate 相关类型里很常见
-
FFaceTrackingResult:一个结构体结果数据 -
AFaceTrackerActor:一个 Actor -
UFaceTrackerComponent:如果以后写组件,通常这么命名 -
EFaceTrackingMode:如果以后做枚举,通常这么命名 -
IFaceTrackerProvider:如果以后做接口,通常这么命名
读代码时类型类别一眼可见 。
看到 Axxx,你知道这是场景对象。
看到 Uxxx,你知道这是 UObject 体系。
看到 Fxxx,你知道它更像一个数据包、数学类型、描述结构,而不是需要 GC 管理的对象。
UE 里很多经典类型都是 F:
-
FVector -
FVector2D -
FTransform -
FRotator -
FHitResult -
FColor -
FString -
FName
这些都不是 Actor,也不是普通 UObject 资源对象,而是"值型数据"。
F 类型
:
-
常常可以按值传递或作为成员保存
-
一般不走
UObject的 GC 生命周期 -
不是通过
NewObject/SpawnActor这种方式实例化 -
更像普通 C++ 数据结构
FFaceTrackingResult,就非常适合做:
-
一帧检测结果
-
Blueprint 输出参数
-
当前追踪状态缓存
虽然 USTRUCT(BlueprintType) 理论上不强制你一定叫 F...,但 Unreal 社区和官方代码都默认 struct 这么命名。
你如果不用这套约定,代码也许能编,但别人一看会觉得别扭,而且你自己以后读大型 UE 代码也会更混乱。
跟 UHT/反射生态配合时更清晰。
Editor 界面本身,大量都是用 Slate 画出来的。
-
Slate
底层原生 UI 框架,主要给 Editor、工具、插件、自定义面板用。
-
UMG
Unreal Motion Graphics。它是更高层、更面向游戏开发者的 UI 系统。
你在蓝图里拖按钮、图片、文本,大多是在用 UMG。
-
Slate / SlateCore
UMG 底下很多能力最终还是建立在 Slate 上。
-
反射系统 提供"有什么属性、什么函数、什么类型"的元数据
-
Details 面板系统 + Slate 决定"这些东西在 Editor 里怎么画出来"
比如一个 UPROPERTY(EditAnywhere):
-
反射系统说:这里有个 float,可编辑
-
Property Editor 模块说:这个 float 应该显示在 Details 面板
-
Slate 负责真正画出那个数值输入框、分类折叠栏、标签文字
定义模块 ZMDRender 的构建规则。
PublicDependencyModuleNames.AddRange(new string\[\]
{
"Core", "CoreUObject", "Engine", "InputCore"
});
虚幻引擎(UE)的架构中,"一切皆模块"。你的项目 ZMDRender 确实是以一个外部模块的形式挂载到引擎中运行的。
Runtime 核心运行时模块 ( Engine/Source/Runtime )
这是引擎最核心的部分,包含了游戏运行所需的所有基础功能。
- Core : 最底层的模块,包含基础数据类型、内存管理、容器(如
TArray,TMap)等。 - CoreUObject: 实现了虚幻的反射系统(UObject、UClass 等)。
- Engine: 包含了 Actor、Component、世界逻辑、物理、网络等最常用的游戏框架。
- Renderer : 渲染器的核心逻辑(你现在的
ZMDRender应该是与这个模块配合工作的)。 - Slate / SlateCore: 虚幻的底层 UI 框架。
- RHI (Rendering Hardware Interface): 硬件渲染接口,负责对接 DirectX, Vulkan, Metal 等底层 API。
Editor 编辑器模块 (Engine/Source/Editor )
这些模块只在编辑器环境下存在,负责处理我们在 UE 界面上看到的一切。
- UnrealEd: 编辑器的核心模块。
- BlueprintGraph: 处理蓝图节点、编译和逻辑。
- LevelEditor: 场景编辑器的核心逻辑。
- PropertyEditor: 负责你在"细节"面板看到的属性调节界面。
Developer 开发者工具模块 ( Engine/Source/Developer )
提供给开发者在开发阶段使用的工具,通常不打入发布包。
- TargetPlatform: 处理不同平台的打包逻辑。
- ShaderCompilerCommon: 负责着色器编译。
- FunctionalTesting: 自动化测试相关。
Plugins 插件模块 ( Engine/Plugins )
UE 的很多高级功能其实也是以"插件"形式存在的模块。
- Niagara: 粒子系统插件。
- Chaos: 物理破碎系统插件。
- EnhancedInput: 增强输入系统。
Programs 独立程序 ( Engine/Source/Programs )
这些是独立于引擎本体运行的辅助程序。
- UnrealHeaderTool (UHT) : 扫描你代码里的
UCLASS()等宏并生成.gen.cpp文件。 - UnrealBuildTool (UBT) : 也就是你正在写的
.Build.cs文件所服务的构建系统。
导出 Shipping(发行) 版本的游戏时,这些模块会被 UBT(Unreal Build Tool)自动排除,以减小安装包体积。
- 你的模块需要在手机端运行,不能 在
PublicDependencyModuleNames中依赖这些模块,否则打包会报错。
决定了引擎如何编译代码、渲染画面、压缩资产以及最终如何封装生成该平台可执行文件。
具体细节如下:
- 编译与资产处理:确定目标平台架构(如 x64, ARM64)和资产优化策略(如纹理压缩格式 ASTC/DXT)。
- 特性与限制:依据硬件能力启用或禁用渲染特性(光追、移动端优化)和功能模块。
- 平台特定规则:处理签名、应用包结构(如 APK/IPA)、权限定义和存储限制。
构建系统集成 :它与 UnrealBuildTool (UBT) 紧密配合,决定了编译时使用的 C++ 编译器宏、链接库以及输出的可执行文件格式(.exe, .apk, .ipa 等)。
不同性能等级的设备(如移动端 vs 主机端),TargetPlatform 允许配置不同的 HLOD(层次细节) 策略或网格体简化程度,以确保在低配硬件上也能流畅运行。
定义不同硬件设备(如 Windows, iOS, Android, PS5 等)的各项参数与限制。
规定了特定平台支持的图形 API(如 DirectX 12, Vulkan, Metal)、纹理压缩格式、最大内存限制以及特定的着色器模型。
**平台覆盖(Platform Overrides)**来实现。
资产级的压缩设置
项目级的纹理组(Texture Group) 以及**平台覆盖(Platform Overrides)**来实现。
资产级:手动指定压缩类型 (Compression Settings)
在纹理编辑器(Texture Editor)的 Details 面板中,你可以直接为每张图片选择 Compression Settings。
- Default (DXT1/5, BC1/3):适用于普通颜色贴图。
- Normalmap (BC5):专门用于法线贴图,通过丢弃蓝色通道并保留高精度的 RGBA 以减少伪影。
- Masks (sRGB 禁用):适用于金属度、粗糙度或 AO 等遮罩贴图。
- UserInterface2D:适用于 UI,通常不压缩或使用低损耗格式以保证文字清晰。
- Grayscale:适用于单通道灰度图,节省空间。
项目级:纹理组配置 (Texture Group / Device Profiles)
虚幻引擎根据图片的用途将其分类为"纹理组"(如 World , Character , UI , Sky )。
- 全局规则 :在
DefaultDeviceProfiles.ini或项目设置中,你可以为每个组定义特定平台的默认压缩和分辨率限制。 - LOD Group :在纹理设置中选择一个
LOD Group,引擎在烘焙(Cooking)时会自动应用该组对应的平台压缩策略。
平台级:特定格式覆盖 (Platform Overrides)
对于跨平台项目,同一个资源可以根据目标硬件采取完全不同的策略:
- 移动端特殊处理 :例如,你可以设置项目在打包 Android 时,普通贴图强制转为 ASTC 4x4 格式以平衡质量与内存,而在 PC 端则保持 BC7。
- 分辨率缩减 (Downscale) :在纹理编辑器中,可以利用
Downscale选项针对特定平台(如移动端)进一步降低分辨率,而无需修改原始资产。
自动化处理:纹理编码与 RDO
对于需要极致优化容量的项目:
- Oodle 压缩 :UE5 集成了 Oodle Texture ,可以开启 RDO (Rate Distortion Optimization)。这允许你在项目设置中全局调节纹理的压缩强度(Lambda 值),甚至可以针对单个纹理覆盖该强度,以在几乎不损失肉眼视觉质量的情况下显著减小安装包大小。
在虚幻引擎(Unreal Engine)中,每个模块(Module)都必须有且仅有一个唯一的 .Build.cs 文件。