第05期 · RAG 检索增强生成:给 AI 配一个实时可查的外部大脑
系列 :每日 AI 知识点
期数 :第 05 期
主题 :RAG 检索增强生成
难度 :⭐⭐⭐(进阶)
一句话:RAG 让 AI 从"闭卷考试"变成"开卷考试",基于真实文档回答问题,是企业 AI 落地最重要的技术路线。
一、为什么需要 RAG?
普通 LLM 的三大硬伤
硬伤一:知识截止日期
GPT-4 的训练数据截止于 2023 年,它不知道 2024 年以后发生的任何事情。你问它"最新的 iOS 版本是什么",它会给出一个过时的答案。
硬伤二:无法访问私有数据
你的公司内部文档、产品手册、测试规范、历史 Bug 库------LLM 训练时根本没有见过这些数据,自然无法基于它们回答问题。
硬伤三:幻觉风险
当 LLM 不知道答案时,它不会说"我不知道",而是会"编造"一个听起来合理的答案(第03期详细讲过)。
RAG 的解决思路
RAG(Retrieval-Augmented Generation,检索增强生成) 的核心思路很简单:
与其让 AI 从记忆中回答,不如让 AI 先去查资料,再基于查到的资料回答。
这就像考试的区别:
- 普通 LLM = 闭卷考试:只能靠训练时记住的内容
- RAG = 开卷考试:可以实时翻阅参考资料
二、RAG vs 普通 LLM:直观对比
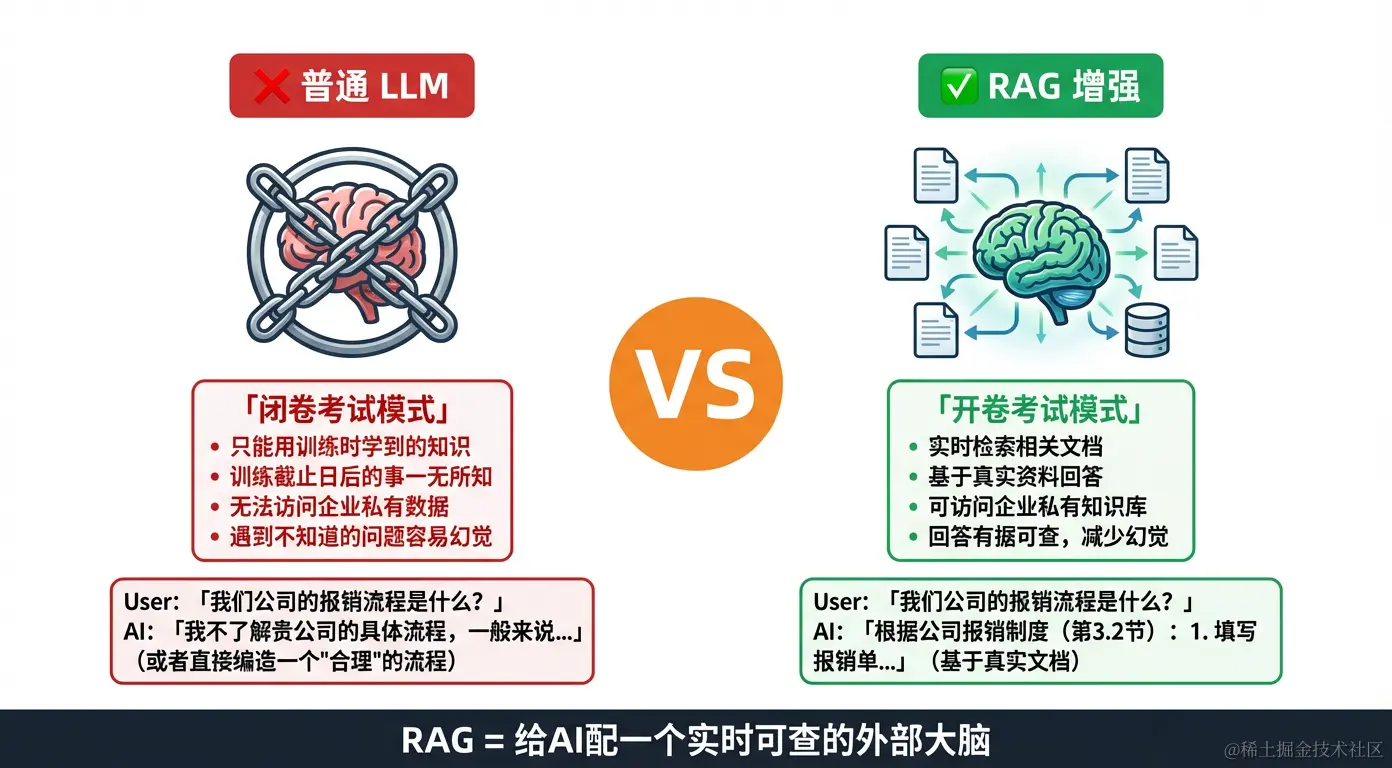
真实场景对比:
markdown
问题:「我们公司刷掌终端的报警处理流程是什么?」
普通 LLM 的回答:
「一般来说,IoT 设备的报警处理流程包括:
1. 告警接收和分类
2. 影响评估
3. 响应处理
...(全是通用流程,没有公司特定信息)」
RAG 增强后的回答:
「根据《刷掌终端运维手册 v2.3》第4章:
1. 当设备触发P0告警时,系统自动推送到值班群
2. 值班工程师需在5分钟内响应确认
3. 根据告警类型执行对应的处理SOP(见附录A)
...(基于真实文档,精准可信)」三、RAG 完整工作流程
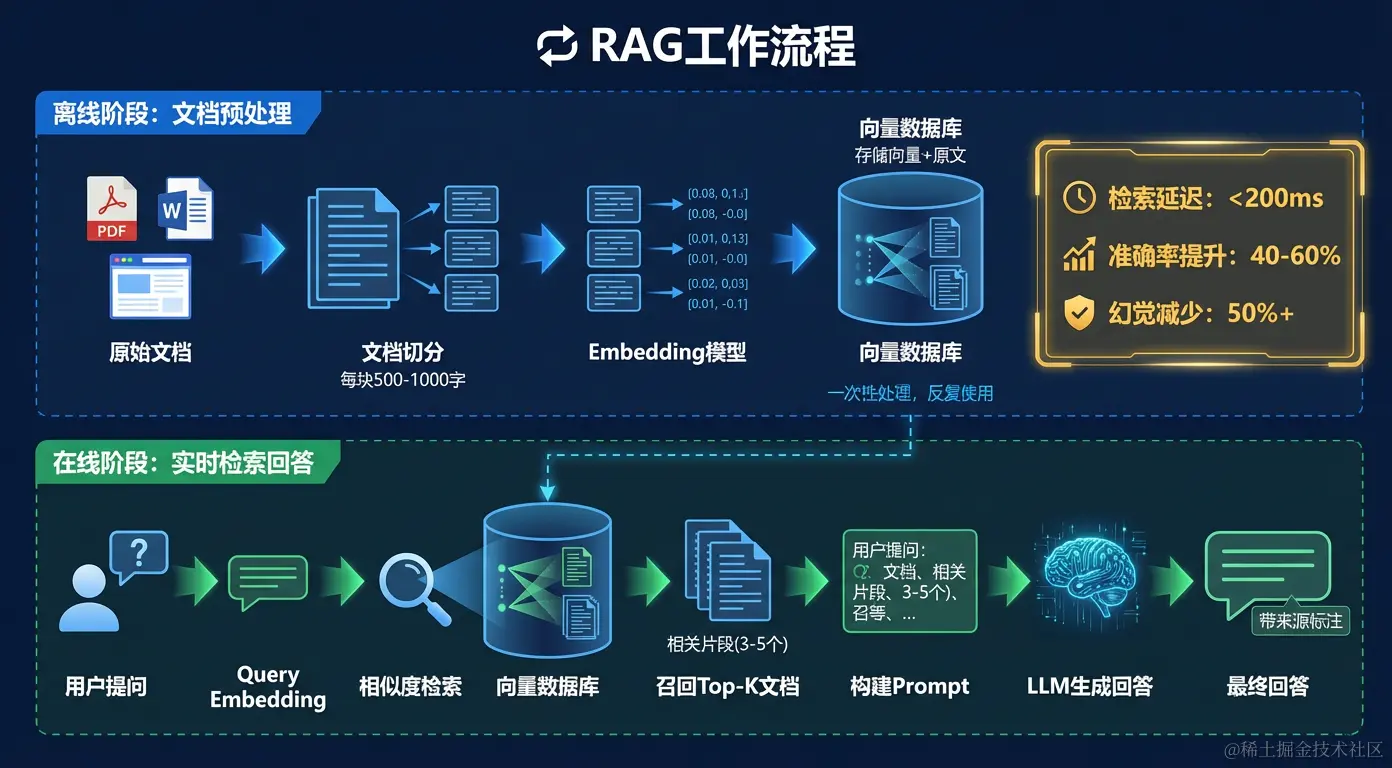
RAG 系统分两个阶段运行:
阶段一:文档入库(离线处理)
这个阶段在系统搭建时执行,之后文档有更新时重新执行:
步骤1:文档收集
收集所有需要纳入知识库的文档
(PDF、Word、Markdown、网页、代码等)
步骤2:文档解析
提取纯文本,去除格式标记
处理表格、图片中的文字(OCR)
步骤3:文本切分
将长文档切成小块(Chunk)
每块通常 300-800 字,保持语义完整性
步骤4:向量化
用 Embedding 模型将每个文本块转成向量
步骤5:存入向量数据库
向量 + 原始文本 + 元数据(来源、时间等)一起存储阶段二:在线问答(实时处理)
用户每次提问时实时执行:
ini
步骤1:问题向量化
用同样的 Embedding 模型将用户问题转成向量
步骤2:相似度检索
在向量数据库中找最相近的文本块(Top-K)
通常 K=3~10,取相似度最高的几块
步骤3:结果重排序(可选)
用 Reranker 模型对召回结果精排,提升精度
步骤4:构建 Prompt
将检索到的文本块 + 用户问题组合成完整 Prompt:
「基于以下文档回答问题:
[文档片段1]
[文档片段2]
...
问题:[用户问题]」
步骤5:LLM 生成回答
LLM 基于提供的文档片段生成回答
步骤6:返回结果
回答 + 来源引用(让用户知道答案来自哪里)四、RAG 优化的三个关键环节
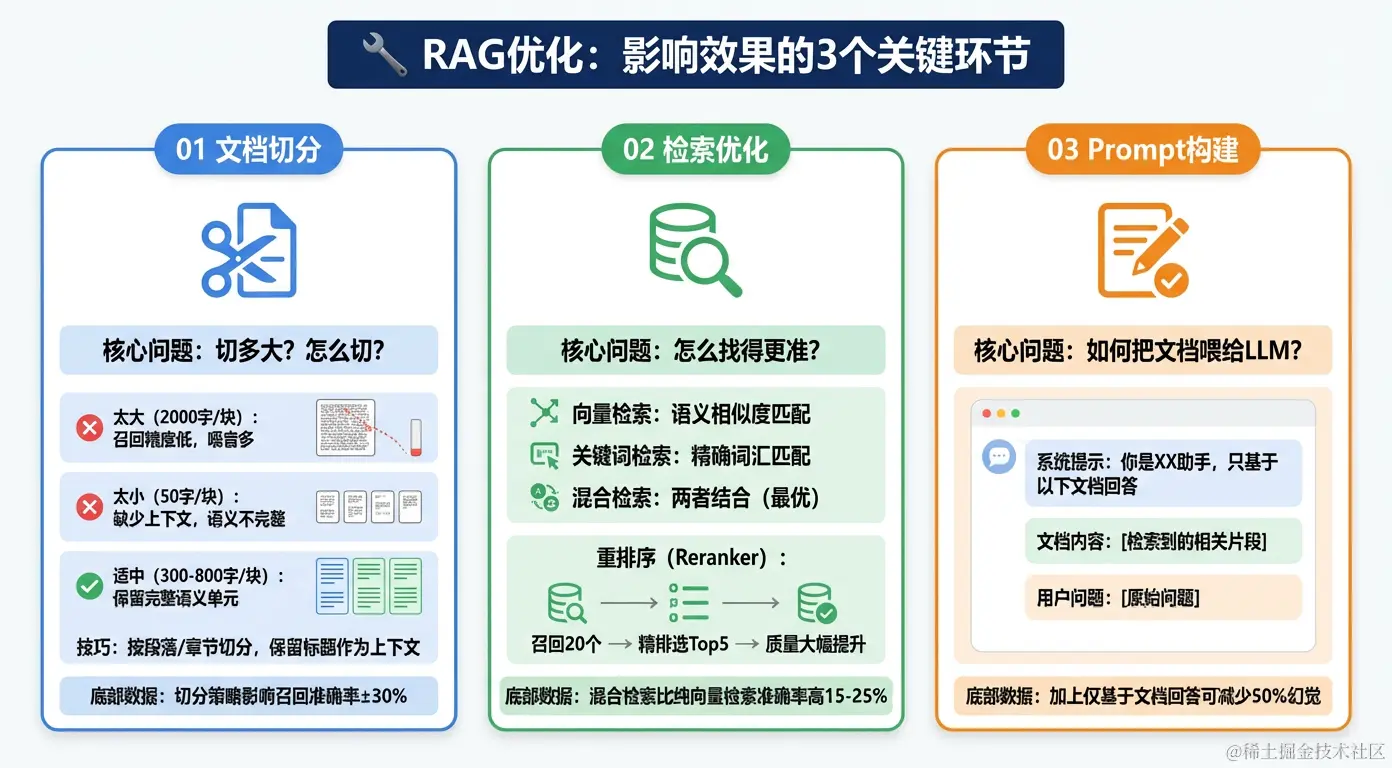
关键一:文档切分策略
切分策略直接影响召回质量,是 RAG 系统中最容易被忽视但影响最大的环节。
常见切分方案对比:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定大小(500字) | 简单快速 | 可能截断语义 | 均匀文档 |
| 按段落切分 | 语义完整 | 块大小不均 | 通用文档 |
| 语义切分 | 效果最好 | 成本高 | 高精度需求 |
| 层级切分 | 兼顾精度和上下文 | 实现复杂 | 有结构的文档 |
最佳实践:
python
# 推荐的切分配置
chunk_size = 500 # 每块约500字
chunk_overlap = 100 # 相邻块重叠100字(保留上下文连续性)
separator = ["\n\n", "\n", "。"] # 优先按段落、句子切分
# 保留元数据
metadata = {
"source": "刷掌终端运维手册v2.3.pdf",
"chapter": "第4章 告警处理",
"page": 23,
"update_time": "2024-01-15"
}重叠区域的重要性:
css
文档:...前半段内容[关键信息在这里]后半段内容...
不重叠切分:
块1:...前半段内容
块2:后半段内容...
→ 关键信息被切断,两块都无法完整回答
有重叠切分:
块1:...前半段内容[关键信息在这里]
块2:[关键信息在这里]后半段内容...
→ 至少有一块包含完整的关键信息关键二:检索优化
纯向量检索的局限:
向量检索擅长语义匹配,但对精确关键词(如产品型号、错误码、人名)的匹配效果差。
arduino
用户问:"错误码 ERR_PALM_TIMEOUT_003 是什么意思?"
纯向量检索:找到"网络超时"相关的文档(语义相近)
但可能找不到包含精确错误码"ERR_PALM_TIMEOUT_003"的文档
混合检索:
向量检索结果 + 关键词精确匹配结果 → 合并排序
→ 能同时找到语义相关和精确匹配的文档Reranker 精排:
css
初步召回:Top-20 个相关文档(速度快但精度一般)
↓
Reranker 精排:用更强的模型重新评分(精度高但慢)
↓
最终结果:Top-5 个最相关文档(质量大幅提升)
实测效果:加入 Reranker 后准确率提升 15-25%关键三:Prompt 构建
基础模板:
yaml
系统提示:
你是一个专业的AI助手,只基于以下提供的文档内容回答问题。
如果文档中没有相关信息,请明确说明"根据现有文档,无法回答此问题",
不要编造或猜测。
参考文档:
---
[文档片段1 - 来源:xxx手册第3章]
...
---
[文档片段2 - 来源:xxx规范v2.0]
...
---
用户问题:{用户的具体问题}
请基于以上文档内容回答,并在回答末尾标注信息来源。关键约束:"只基于以下文档回答"这句话至关重要,它能将幻觉比例降低约 50%。
五、RAG 的进阶优化技术
技术一:HyDE(假设文档嵌入)
问题:用户的问题和文档的表述方式可能差异很大,导致语义匹配不准。
HyDE 方案:
markdown
原始问题:「刷掌设备网络超时怎么处理?」
HyDE 流程:
1. 让 LLM 先生成一个"假设的答案":
「当刷掌设备出现网络超时时,需要检查网络连接状态...」
2. 用这个假设答案去检索文档(而不是原始问题)
3. 假设答案的表述方式更接近文档的写作方式,检索效果更好
效果:召回准确率提升 10-20%技术二:查询扩展(Query Expansion)
diff
原始问题:「刷掌识别失败」
扩展后:
- 「掌纹识别失败」
- 「生物特征验证错误」
- 「palm recognition error」
- 「ERR_PALM_MATCH_FAILED」
用多个扩展问题分别检索,合并结果
效果:召回率提升 15-30%技术三:对话历史感知
arduino
第一轮:用户问「刷掌支付的流程是什么?」
第二轮:用户问「那异常情况怎么处理?」
如果只用第二轮的问题检索,"异常情况"指代不明确
需要结合对话历史,理解为"刷掌支付的异常情况处理"六、RAG 在实际项目中的落地案例
案例一:刷掌终端故障排查知识库
背景:刷掌终端运维团队每天接到大量重复的故障排查咨询,大量时间花在回答相同问题上。
方案:
- 收集历史故障案例(3000+条)、运维手册、设备规格书
- 用 RAG 构建故障排查知识库
- 工程师输入告警现象,AI 自动匹配历史案例和处理方案
效果:
- 常见问题自动解答率:75%
- 平均故障处理时间:从 45 分钟降至 12 分钟
- 新人上手时间:从 3 个月降至 2 周
案例二:企业内部政策问答
背景:HR 部门每天收到大量关于报销、假期、福利政策的重复咨询。
方案:将公司所有 HR 政策文档、员工手册纳入 RAG 知识库,员工自助查询。
效果:HR 重复咨询量减少 70%,员工满意度提升(随时可查,不需要等待人工回复)。
案例三:代码库智能问答
背景:新加入团队的工程师需要大量时间理解遗留代码库。
方案:将代码注释、设计文档、架构说明、API 文档全部纳入 RAG 知识库,工程师可以直接问"这个函数是干什么的"、"支付流程的入口在哪里"。
效果:新人代码熟悉时间从 3 个月降至 3 周。
七、RAG 的局限性与适用边界
不适合 RAG 的场景
| 场景 | 原因 | 替代方案 |
|---|---|---|
| 需要全局理解整个文档 | RAG 只能检索片段 | 直接用长上下文 LLM |
| 需要复杂跨文档推理 | 片段检索难以覆盖 | 知识图谱 + RAG |
| 实时数据(股价、天气) | 需要实时 API | 工具调用(第08期) |
| 高度结构化数据查询 | 向量检索不如 SQL | 文本转 SQL |
RAG 的三大挑战
挑战一:文档质量决定上限
- 垃圾进,垃圾出(Garbage In, Garbage Out)
- 文档质量差、格式混乱、信息过时,RAG 效果再好也无法弥补
挑战二:召回的"长尾"问题
- 对于常见问题,RAG 效果很好
- 对于边缘问题(文档中没有覆盖),RAG 可能给出错误答案
挑战三:维护成本
- 文档更新需要重新 Embedding
- 需要持续监控召回质量
- 需要定期清理过期文档
八、一句话总结
RAG = 检索(找到相关文档)+ 增强(将文档加入 Prompt)+ 生成(基于文档回答)。它让 AI 从"靠记忆回答"变成"查资料再回答",是解决 LLM 知识截止和私有数据访问问题的最主流技术方案。
延伸阅读
- 论文 :Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020) --- RAG 的奠基论文
- 框架 :LangChain | LlamaIndex --- 最流行的 RAG 开发框架
- 向量数据库 :Chroma(开源)| Pinecone(云服务)| Milvus(企业级)
下一期预告:第06期 · 知识库工程实践 --- 知道了 RAG 原理,如何在实际项目中构建一个高质量的企业知识库?文档处理、质量评估、持续优化的完整实践指南。