第03期 · AI 幻觉与可信度:如何与"会撒谎"的 AI 安全协作
系列 :每日 AI 知识点
期数 :第 03 期
主题 :AI 幻觉与可信度
难度 :⭐⭐(入门)
一句话:AI 会一本正经地"编造"答案。了解幻觉的成因和类型,学会判断什么时候该信任 AI,是安全使用 AI 的必修课。
一、什么是 AI 幻觉?
2023年,美国律师 Steven Schwartz 在一起航空公司诉讼案中,使用 ChatGPT 辅助撰写法庭文件。AI 给他提供了 6 条"判例",每条都有完整的案号、法院名称、判决日期、详细的判决内容------看起来非常专业可信。
结果,对方律师发现这 6 条判例一条都不存在,全是 AI 凭空捏造的。
Schwartz 被法官传唤,被迫公开道歉,面临吊销执照的处罚。这件事引发了全球法律界对 AI 幻觉的广泛关注。
这就是 AI 幻觉(Hallucination):AI 以极其自信的语气,生成完全错误甚至凭空捏造的信息。
🧠 为什么 AI 会幻觉?
LLM 的本质是"预测下一个最可能出现的词"。它的目标是生成听起来合理 的文字序列,而不是保证信息正确。当它不知道答案时,它不会说"我不知道",而是生成一个"在统计上最像正确答案"的内容。
二、幻觉的 5 种类型

类型一:事实捏造(最危险)
特征:编造不存在的事实、人物、论文、法律条文
案例集锦:
- 上文提到的美国律师案(虚构判例)
- 某记者让 AI 生成参考文献,AI 给出了 20 篇"论文",其中 12 篇不存在
- 某公司让 AI 写竞品分析,AI 编造了竞品公司的"内部数据"
识别方法:对任何具体引用(论文、案例、数据来源)都要独立核实
类型二:细节错误
特征:大方向正确,但具体数字、时间、名字出错
案例:
yaml
用户:GPT-3 是什么时候发布的?
AI:GPT-3 于 2020 年 6 月发布,拥有 1750 亿参数。
(这部分正确)
用户:GPT-4 呢?
AI:GPT-4 于 2023 年 3 月 14 日发布,拥有约 1 万亿参数。
(发布日期正确,但参数量是推测值,实际未公开)识别方法:对关键数字(版本号、日期、参数量)要查官方文档
类型三:过度自信
特征:不确定的事情也以肯定语气表述
案例:
arduino
用户:这个崩溃日志是什么原因?
AI:这个崩溃是由于内存泄漏导致的,具体是在
UserSession.java 的第 127 行,因为没有正确
释放 BitmapFactory 的资源。
(听起来很具体,但实际上 AI 是在"猜",
可能完全是另一个原因)识别方法:让 AI 说明置信度,"你有多确定这个判断?"
类型四:知识截止
特征:对训练截止日之后的信息一无所知,但可能给出过时的错误信息
案例:
yaml
用户:Anthropic 最新的 Claude 模型是哪个版本?
AI:Anthropic 最新的模型是 Claude 2.1,发布于 2023 年 11 月。
(如果 AI 的训练截止日是 2024 年初,它不知道 Claude 3、
Claude 3.5 等后续版本)识别方法:对"最新"、"当前"相关的信息,结合 AI 的训练截止日期判断
类型五:逻辑矛盾
特征:同一段回答中前后自相矛盾
案例:
css
AI:我推荐使用方案A,它的性能更好,扩展性强,
维护成本低。
...(中间省略几段)...
综上所述,方案B是更好的选择,因为它的维护
成本更低,性能也更稳定。识别方法:对长回答,检查最终结论与中间论述是否一致
三、AI 可信度判断矩阵
不是所有 AI 的回答都不可信------关键是要知道哪些场景可信,哪些场景必须核实。
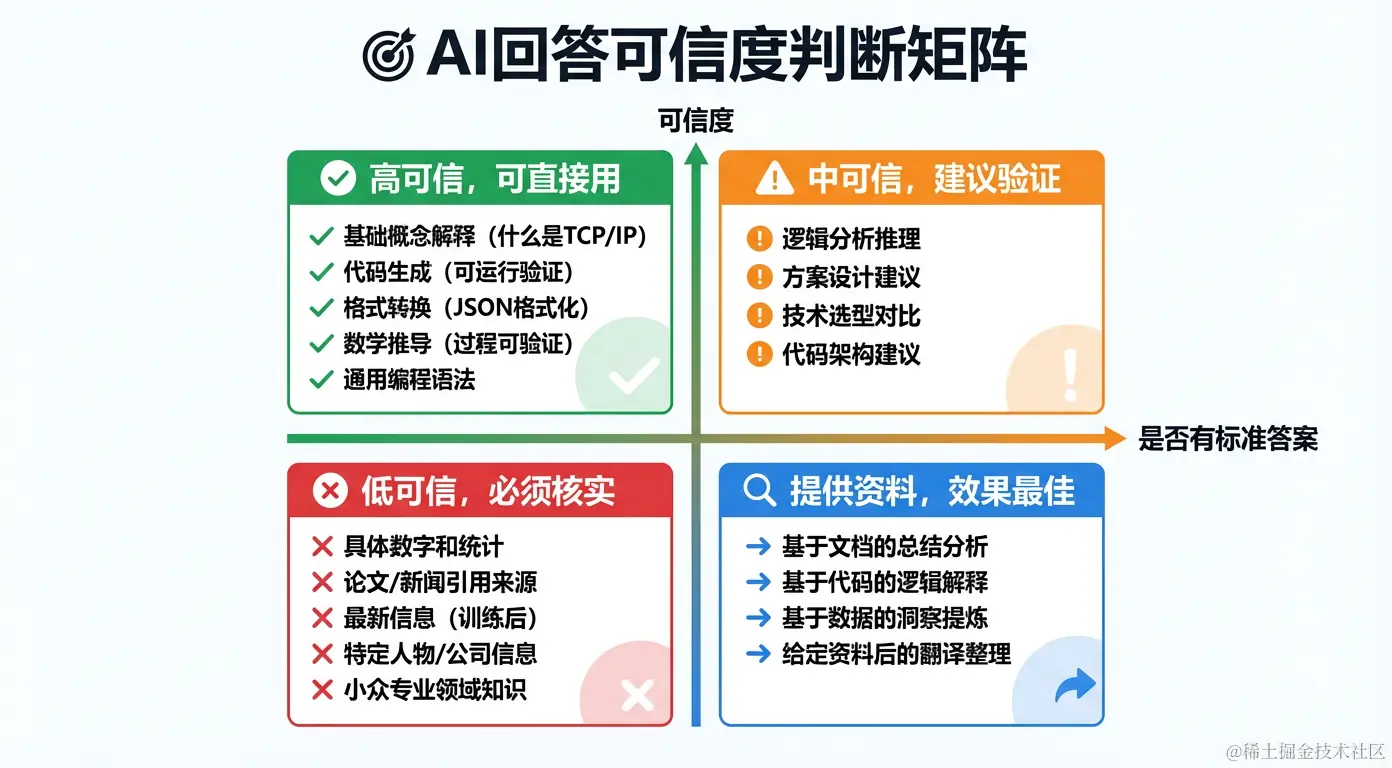
✅ 高可信度场景:可以直接使用
| 场景 | 原因 | 示例 |
|---|---|---|
| 基础概念解释 | 训练数据覆盖充分,有标准答案 | "什么是 TCP/IP?" |
| 代码生成 | 可以直接运行验证 | "写一个快速排序" |
| 格式转换 | 有明确的正确标准 | "把这个 JSON 转成 CSV" |
| 数学推导 | 步骤可逐步验证 | "证明这个公式" |
| 语法纠错 | 有客观标准 | "检查这段英文的语法" |
⚠️ 中可信度场景:建议验证
| 场景 | 注意事项 |
|---|---|
| 逻辑分析推理 | 验证关键推理步骤 |
| 方案设计建议 | 结合实际情况判断可行性 |
| 技术选型对比 | 参考官方文档和社区评价 |
| 代码架构建议 | 考虑团队实际技术栈 |
❌ 低可信度场景:必须人工核实
| 场景 | 风险 | 应对方法 |
|---|---|---|
| 具体数字和统计 | 可能是编造的 | 查原始数据来源 |
| 论文/新闻引用 | 可能是虚构的 | 在数据库独立搜索 |
| 最新信息 | 训练截止日后的事 | 用搜索工具获取 |
| 特定人物信息 | 可能张冠李戴 | 查官方资料 |
| 小众专业领域 | 训练数据少,猜测成分多 | 咨询领域专家 |
四、5 招减少 AI 幻觉的实用技巧

技巧一:明确允许"不知道"
在 Prompt 中明确告诉 AI 可以表达不确定性:
arduino
"如果你不确定某个信息,请直接说'我不确定',
不要猜测或编造。宁可说不知道,也不要给出可能
错误的信息。"实测效果:加上这句话后,AI 的虚构信息比例下降约 40-60%。
技巧二:要求说明推理依据
markdown
用户:这个 Bug 的根因是什么?
AI:根据日志分析,是内存泄漏...
追问:你的判断依据是什么?日志中的哪些具体信息
支持了这个结论?让 AI 说明依据,可以快速发现它是在推理还是在猜测。
技巧三:分步验证,而非直接要结论
arduino
❌ 直接问结论:
"这个架构方案有什么问题?"
✅ 分步验证:
第一步:让 AI 描述它理解的方案内容(验证它理解正确)
第二步:让 AI 列出潜在风险(验证每个风险是否合理)
第三步:让 AI 给出优先级排序(验证排序逻辑)技巧四:用已知信息交叉验证
如果 AI 的回答中包含你能快速验证的事实,先验证这个,再决定是否信任其他部分。
arduino
AI 说:"根据 RFC 2616 规范,HTTP 状态码 418 表示..."
你验证:RFC 2616 确实存在,418 确实是"I'm a Teapot"
→ AI 对技术规范的引用是可靠的,可以继续信任其他部分
反之,如果这个验证失败,整个回答都要重新核实。技巧五:提供资料,而非让 AI 凭空生成
这是最根本的解决方案:
arduino
❌ 容易幻觉:
"帮我写一份关于刷掌支付安全的技术报告"
(AI 可能编造数据、虚构案例)
✅ 减少幻觉:
"基于以下资料,帮我整理成技术报告:
[粘贴真实的安全分析文档、测试报告、官方规范]"
(AI 基于真实资料组织,而不是凭空创作)五、真实工作场景中的幻觉风险
场景一:Bug 分析
高风险操作:
arduino
"这个崩溃是什么原因?[粘贴几行日志]"AI 可能会给出听起来合理但完全错误的根因分析。
安全操作:
arduino
"请分析以下完整的崩溃日志,列出可能的根因(至少3个),
并说明每个根因的判断依据。如果信息不足以确定根因,
请明确说明还需要哪些额外信息。
[粘贴完整日志]"场景二:测试用例生成
高风险:AI 可能生成涉及不存在的接口参数、不存在的 API 的测试用例
安全操作:
- 提供真实的接口文档给 AI
- 生成后,对照文档逐条核查接口名称、参数是否真实存在
- 特别检查边界值------AI 经常会编造"合理"但错误的边界数值
场景三:技术调研
高风险:
arduino
"给我列出5个支持刷掌识别的开源库,包括 GitHub 地址和最新版本号"AI 可能给出不存在的库或错误的 GitHub 地址。
安全操作:
- 让 AI 给出方向和关键词,而不是具体链接
- 自己去 GitHub 搜索验证
- 版本号必须在官方仓库 releases 页面核实
场景四:文档编写
高风险:
arduino
"帮我写一份关于刷掌支付合规性的分析报告,包括相关法规引用"AI 可能编造法规条文、错误引用法律条款。
安全操作:
- 先自己整理真实的法规条文
- 提供给 AI 进行分析和整理
- 最终输出的法规引用必须逐条核实
六、不同 AI 模型的幻觉程度对比
不同模型的幻觉程度差异显著,以下是业界对主流模型的评估:
| 模型 | 事实准确性 | 幻觉控制 | 说明 |
|---|---|---|---|
| Claude 3.5 Sonnet | ⭐⭐⭐⭐⭐ | 最好 | 倾向于说"不确定"而非猜测 |
| GPT-4o | ⭐⭐⭐⭐ | 很好 | 综合能力强,幻觉控制较好 |
| Gemini 1.5 Pro | ⭐⭐⭐⭐ | 较好 | 联网版本幻觉更少 |
| DeepSeek-V3 | ⭐⭐⭐ | 中等 | 中文场景表现好,但偶有幻觉 |
| 早期 GPT-3.5 | ⭐⭐ | 较差 | 幻觉较多,已被新版本取代 |
注:幻觉程度会随任务类型变化,上表仅为一般性参考。
任务类型对幻觉的影响(从高到低):
css
幻觉风险:高 ←------------------------------------------------------→ 低
[开放性知识生成] [具体数字引用] [逻辑推理] [代码生成] [格式转换]
↑ ↑
风险最高 风险最低七、一句话总结
AI 幻觉 = 模型在不知道答案时,生成"听起来合理"的内容。识别高低风险场景、明确告知 AI 可以说"不知道"、对关键信息交叉验证、提供资料而非让 AI 凭空创作,是与 AI 安全协作的四板斧。
延伸阅读
- 事件 :美国律师因 ChatGPT 幻觉被处罚事件(2023)
- 研究 :TruthfulQA: Measuring How Models Mimic Human Falsehoods
- 工具 :Perplexity AI --- 每个回答都附带来源链接,大幅减少幻觉
下一期预告:第04期 · Embedding 向量化 --- AI 是怎么"理解"文字含义的?向量化技术是语义搜索和知识库的核心基础,下期深度解析。