大模型学习笔记------微调之LoRA
LoRA(Low-Rank Adaptation,低秩自适应) 是目前大模型微调领域最火、应用最广的"平民化"技术。
1、背景知识
1.1 为什么不能"全量微调"
大模型(如 Llama-3 70B)有几百亿个参数。如果进行全参数微调(Full Fine-Tuning),如图1中的左图,可能出现的情况:
- 显存爆炸:你需要存储模型权重、梯度、优化器状态。微调一个 70B 模型可能需要几块甚至十几块昂贵的 A100/H100 显卡。
- 存储灾难:每针对一个任务(比如写代码、写诗)微调一次,就要保存一个几十 GB 的完整模型文件。
- 效率低下:训练时间长,更新速度慢。
1.2 矩阵的秩(rank)
LoRA是低秩自适应,因此在讲解之前需要直接讲解一些关于"秩"的知识。在理解大语言模型(LLM)时,"矩阵的秩(Rank)"代表了信息的密度、冗余度以及模型微调的本质。
在数学上,秩代表一个矩阵中线性独立的行或列的最大数量。在大模型中,一个权重矩阵 W W W(比如维度是4096×4096)理论上最大秩是 4096。如果这个矩阵是满秩的,意味着它的每一个参数都在表达不同的、独立的信息。
经研究发现,预训练好的大模型权重矩阵往往是低秩(Low-rank)的,或者说具有强烈的低秩趋向。这意味着模型虽然参数极多,但内部存在大量的信息冗余。很多参数实际上是在重复表达相似的特征。这就像一篇 1000 字的文章,可能缩写成 100 字核心大意也不丢失信息。
2、LoRA原理
2.1 计算原理
LoRA是在LLM的矩阵 W ∈ R d × k W \in \mathbb{R}^{d \times k} W∈Rd×k中并行添加新的权值矩阵 Δ W ∈ R d × k \Delta W \in \mathbb{R}^{d \times k} ΔW∈Rd×k。由于上述大模型低秩性的存在,我们可以将 Δ W \Delta W ΔW拆分成降维矩阵 A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k和升维矩阵 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r,如图1右侧所示,其中 r ≤ min ( d , k ) r \leq \min(d, k) r≤min(d,k),从而实现了以极小的参数数量训练LLM。
在训练时将LLM或是VLM的参数冻结只训练矩阵 A A A和 B B B。根据公式(1),在模型训练完成之后,我们可以直接将 A A A和 B B B加到原参数上,从而在推理时不会产生额外的推理时延。
h = W 0 x + Δ W x = ( W 0 + Δ W ) x = W x + B A x ( 1 ) h = W_0x + \Delta Wx = (W_0 + \Delta W)x = Wx + BAx (1) h=W0x+ΔWx=(W0+ΔW)x=Wx+BAx(1)
原理具体让如下图所示:
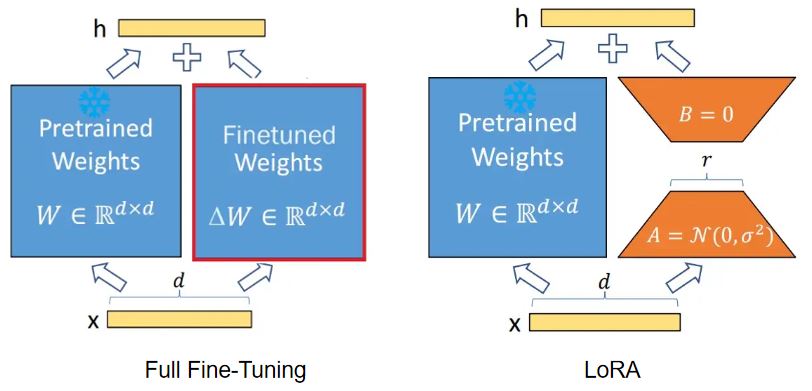
图1 全量微调与LoRA
2.2 初始化的小策略(精妙之处)
- 矩阵 A A A:使用高斯分布初始化(随机噪音);
- 矩阵 B B B:初始化为全 0;
- 结果 :在训练开始的第一秒, B ⋅ A = 0 B \cdot A = 0 B⋅A=0。这意味着 LoRA 插件对模型没有任何干扰。模型从原始状态开始平滑学习,不会出现"一上来就练废了"的情况。
3、LoRA的思考
3.1 优势与局限性
LoRA的优势如下:
- 需要的显存骤减
由于只训练 A A A和 B B B参数(通常不到总量的 0.1%),不需要保存原始模型的梯度和优化器状态。原本需要 80G 显存的任务,LoRA 可能只需要 16G 甚至更少,同时,效果能追平全量微调。 - 推理无延迟(权重合并)
在部署时可以将 LoRA 的权重直接加回到原始权重中。这样,推理速度和原始模型一模一样,没有任何额外开销。 - 灵活切换(插件化)
针对不同垂直领域进行LoRA训练,如"法律"、"医疗"、"遥感"训练三个不同的 LoRA。主模型(几十GB)只存一份,三个 LoRA 插件(几十MB)可以随时切换。
LoRA的局限性如下:
- 知识容量有限
如果想让模型学习海量的全新知识(比如学习一门从未见过的外语),LoRA 的参数量可能不够"装",这时候可能需要全量微调或更大秩的 LoRA。 - 秩的选择
r r r选多大是个玄学,选小了学不会,选大了容易过拟合。
3.2 秩的其他意义
1)LoRA微调中秩的大小代表了任务的复杂程度
任务越难,需要的秩通常越高:简单的分类任务可能r=4就够了,复杂的逻辑推理任务可能需要r=64或更高。
2)LoRA微调中秩代表了模型能力的过滤器
在微调过程中,秩的大小决定了你允许模型学习多少"新东西"。
- 低秩(Low r r r)的作用 :
去噪 :低秩迫使模型只关注最核心、最显著的特征变化,忽略微小的噪声。
防过拟合:因为参数量极少,模型很难死记硬背训练数据,从而被迫学习通用的规律。 - 高秩(High r r r)的作用 :
增加容量 :如果你要让模型学习全新的知识,低秩可能"装不下"这些信息,这时需要提高秩。
精细化:高秩允许模型捕捉更细微、更复杂的参数扰动。
3)LoRA微调中是计算成本与性能的平衡木
在工程实践中,秩直接对应了显存占用和计算开销。一个 d×d的矩阵(如 4096×4096≈1600万个参数)。如果用 LoRA 分解为两个 d ∗ r d*r d∗r的矩阵(如 r r r=8),参数量变为 4096×8×2≈6.5万个。参数量压缩了 250 倍!
在实际项目中,并不是秩越大越好。实验表明,当 r r r增加到一定程度后(如从 64 增加到 512),模型性能的提升会迅速进入边际效用递减区间,但显存开销却在直线线性上升。
总结:矩阵的秩在大模型中的实际意义是:它量化了模型在处理特定任务时,真正起作用的"核心变量"的数量。通过利用低秩特性,我们得以用极小的代价(LoRA 等技术)去操控和适配庞大的 AI 模型。