
本文对比了四种主流PDF转Markdown工具(PaddleOCR-VL-1.5、MinerU、HunyuanOCR和MonkeyOCR)的性能表现。测试基于OmniDocBench和MDPBench数据集,评估维度包括文本块识别、阅读顺序、表格和公式处理等结构化要素。结果显示PaddleOCR-VL-1.5综合表现最优,在两个数据集上都保持稳定性能,特别在表格和公式处理方面表现突出。HunyuanOCR在复杂文档解析上单集表现优异但部署门槛高,MinerU工程系统能力强但分数略低,MonkeyOCR轻量但稳定性不足。结论建议将PaddleOCR-VL-1.5作为默认生产方案,其他工具可根据特定需求选择。
**前言:**PDF 转 Markdown 的本质
在进入具体对比之前,我们先来看看PDF 转 Markdown的本质:
- 本质上不是格式互转,而是给 LLM 准备结构化输入的前置工程。 场景落在 RAG、知识库构建和大模型应用上。
- 真正有价值的是保住结构,而不是抽出文字。 标题层级、列表、表格、公式、图片、阅读顺序这些信息,Markdown 明显优于纯文本。
- 评价维度高度一致: 复杂版面、多栏、跨页表格、公式、扫描件 OCR、处理速度、批量能力、隐私、本地部署、许可证和成本。
- 结论都不是 " 谁全能 " ,而是 " 谁更适合哪类文档 " 。
在大模型应用里,PDF 转 Markdown 早就不是"能不能转"的问题,而是"转出来的内容能不能直接喂给 RAG、Agent 和知识库"的问题。真正决定结果上限的,不只是 OCR 精度,而是标题层级、表格结构、公式、图片、阅读顺序,以及跨页重组能力能否保住。除此之外,还得考虑谁是最值得被放进默认生产主通道、承担大多数页面解析任务的开源基线。它不等于单项冠军,而等于综合收益最大、长期维护成本最低的默认选择。
|------------|---------------------------------------------------|
| 维度 | 为什么它决定 " 主力方案 " |
| 跨场景稳定性 | 默认解析器必须覆盖数字 PDF、扫描件、手机拍照件与混合语种,而不只是干净文档。 |
| 结构保真度 | 标题层级、阅读顺序、表格、公式与列表能否稳定落回 Markdown,是下游 RAG 和重建的关键。 |
| 输出控制度 | 除了 Markdown,本地 JSON、坐标、表格单元格信息和后处理能力也决定了工程可控性。 |
| 部署经济性 | 吞吐、显存、CPU/GPU 兼容性和多后端支持,决定它能否成为长期基线。 |
| 授权可落地性 | 主力方案通常会被深度集成进产品或平台,许可边界越清晰,长期维护成本越低。 |
**1.**官方定位先看一遍
1.1 PaddleOCR-VL-1.5
飞桨官方把 PaddleOCR-VL 定位为一条先进的文档解析产线。官方文档明确写到:
- PaddleOCR-VL-1.5 在 OmniDocBench v1.5 上达到 94.5%
- 支持异形框定位
- 在扫描、倾斜、弯折、屏幕拍摄和复杂光照场景下表现更好
- 统一入口是 paddleocr doc_parser
- CLI 和 Python API 都支持,生产环境还支持接推理服务
Githup链接:
一句话概括:PaddleOCR-VL-1.5 是飞桨当前偏"高质量通用文档解析"的主力方案。
1.2 MinerU
MinerU 官方 GitHub README 把它定位为:
- 高精度文档解析引擎
- 面向 LLM / RAG / Agent workflows
- 可把 PDF、Word、PPT、图片、网页转成 Markdown / JSON
- 支持 公式 -> LaTeX、表格 -> HTML
- 支持扫描文档、手写、多栏、跨页表格合并
- 自带 CLI / REST API / Docker
- 官方还强调它的 pipeline backend 可以跑在 CPU or GPU
官方链接:
一句话概括:MinerU 更像一条工程味很强、部署形态丰富的文档解析系统。
1.3 HunyuanOCR
腾讯官方 README 把 HunyuanOCR 定位为:
- 端到端 OCR 专家型 VLM
- 1B 参数
- 支持 100+ 语言
- 单指令、单次推理完成复杂 OCR 与文档解析
- 覆盖文本检测识别、复杂文档解析、开放域抽取、字幕提取、拍照翻译等
但官方也明确写了部署要求:
- 操作系统:Linux
- Python:3.12+
- CUDA:12.9
- 推荐 vLLM
- 显存:20GB (for vLLM)
Githup链接:
一句话概括:HunyuanOCR 很像一条"单模型端到端"的 VLM 路线,能力强,但官方推荐部署门槛也更高。
1.4 MonkeyOCR
MonkeyOCR 官方 README 把它定位为:
- A lightweight LMM-based Document Parsing Model
- 支持中英文文档解析
- 本地端到端调用是 python parse.py input_path
- 支持输出 Markdown、布局 PDF 和中间 JSON
- 单任务模式可以单独跑 text / formula / table
官方 README 同时给了一个重要限制:
- 目前还不完全支持拍照文本
- 不完全支持手写内容
- 不完全支持繁体中文
- 不完全支持多语言文本
Githup链接:
一句话概括:MonkeyOCR 更偏研究型、轻量级 LMM 文档解析路线,官方自己也明确写了当前适用范围和限制。
**2.**从部署角度看,谁更好上手
|------------------|-------------------------------|------------------------------------|-----------------------------|
| 工具 | 官方入口 | 官方部署特点 | 我对部署门槛的判断 |
| PaddleOCR-VL-1.5 | paddleocr doc_parser | CLI、Python API、推理服务都支持 | 最均衡,官方文档最完整,落地路径最清楚 |
| MinerU | mineru / mineru-api | CLI、REST API、Docker、CPU/GPU、多后端 | 工程集成能力最强,但系统更重 |
| HunyuanOCR | vllm serve tencent/HunyuanOCR | 官方推荐 Linux + CUDA 12.9 + 20GB vLLM | 本地门槛最高,不适合老显卡和 Windows 轻量部署 |
| MonkeyOCR | python parse.py input_path | 本地脚本、Docker、FastAPI、Windows guide | 研究体验不错,但生产一致性要自己多验证 |
如果只从"最快落地"看:
- PaddleOCR-VL-1.5
- MinerU
- MonkeyOCR
- HunyuanOCR
3. benchmark****排序
可以去我的github仓库去看详细的代码:
GitHub - PrayerQX/doc-parsing-benchmark
我从OmniDocBench和MDPBench 两大数据集里面分别分层抽样了一个小而简的样本集,而且做了统一输出格式和 official scorer wrapper,从方法上更接近可复用 benchmark。
本文里用到的排序分 rank_score 不是官方单一指标,而是本地为了方便排序做的聚合分:
|-------------------------------------------------------------------------------------|
| Plaintext ((1 - text_block) + (1 - reading_order) + table_teds + (1 - formula)) / 4 |
其中:
- rank_score 越高越好,理论满分 1.0
- text_block 越低越好
- reading_order 越低越好
- table_teds 越高越好
- formula 越低越好
所以它适合做"同机、同脚本、同样本"的快速排序,不适合作为官方唯一结论。
**4.**本次 lite benchmark 结果
4.1 OmniDocBench Lite
|----|------------------|------------|------------|---------------|------------|---------|
| 排名 | 模型 | Rank Score | Text Block | Reading Order | Table TEDS | Formula |
| 1 | HunyuanOCR | 0.9537 | 0.0534 | 0.0000 | 0.9869 | 0.1186 |
| 2 | PaddleOCR-VL-1.5 | 0.9274 | 0.0416 | 0.0361 | 0.9027 | 0.1155 |
| 3 | MinerU | 0.8967 | 0.0700 | 0.0581 | 0.9189 | 0.2042 |
| 4 | MonkeyOCR | 0.8818 | 0.0738 | 0.0803 | 0.8996 | 0.2183 |
4.2 MDPBench Lite
|----|------------------|------------|------------|---------------|------------|---------|
| 排名 | 模型 | Rank Score | Text Block | Reading Order | Table TEDS | Formula |
| 1 | PaddleOCR-VL-1.5 | 0.7690 | 0.2248 | 0.1604 | 0.7988 | 0.3375 |
| 2 | MinerU | 0.6279 | 0.3214 | 0.2697 | 0.6563 | 0.5536 |
| 3 | HunyuanOCR | 0.5390 | 0.3581 | 0.3648 | 0.3797 | 0.5006 |
| 4 | MonkeyOCR | 0.4869 | 0.3931 | 0.3299 | 0.2508 | 0.5800 |
在 OmniDocBench Lite 上 HunyuanOCR 领先,在 MDPBench Lite 上 PaddleOCR-VL 领先,而总体最稳定的仍然是 PaddleOCR-VL。对"主力方案"而言,这种跨 benchmark 的稳定性往往比单次局部第一更重要。
关于我的benchmark,如果后续有时间,可以尝试将OmniDocBench和MDPBench两个数据集全跑了来看看现在模型的偏差,跑全之后,重点补足场景切片、工程指标和系统组合实验。
或者大家也可以参考这两个做过的数据:
https://arxiv.org/abs/2603.28130、https://github.com/opendatalab/OmniDocBench
这样做的意义是:不仅比较模型,还比较谁更适合进生产。
4.3****只看四个主流工具的综合印象
如果只看 PaddleOCR-VL-1.5 / MinerU / HunyuanOCR / MonkeyOCR 这四个主流工具:
- PaddleOCR-VL-1.5 是这次本机 lite benchmark 的综合第一
- HunyuanOCR 在 OmniDocBench Lite 单集最强
- MinerU 两个数据集都不差,但都不是第一,更像稳定第二梯队
- MonkeyOCR 在修正接入方式后,OmniDocBench Lite 已经明显回升,但跨数据集稳定性依然偏弱
如果把两套 lite 数据的 rank_score 简单取均值,四个主流工具的本机综合排序是:
- PaddleOCR-VL-1.5: 0.8482
- MinerU: 0.7623
- HunyuanOCR: 0.7464
- MonkeyOCR: 0.6844
**5.**怎么理解这组结果
5.1 PaddleOCR-VL-1.5**:最稳的综合选手**
它在这次数据里的特点很清楚:
- 两个数据集都进入前二
- MDPBench Lite 直接第一
- 文本块、表格、公式整体都比较均衡
- 既没有像 HunyuanOCR 那样在第二个数据集明显掉队,也没有像 MinerU 那样在公式上吃亏
如果你不想为不同文档类型准备不同路线,PaddleOCR-VL-1.5 是最像"默认推荐项"的。
5.2 MinerU**:工程能力很强,但这次本机分数略低于** PaddleOCR-VL
从官方定位看,MinerU 的优势不是只拼单一页级得分,而是:
- 多格式输入
- 多种输出格式
- CPU/GPU 可跑
- CLI / REST API / Docker / SDK 齐全
- 对 RAG、Agent、私有部署很友好
而从这次本机 lite benchmark 看:
- 它并不差
- 但在两个数据集上都没有超过 PaddleOCR-VL-1.5
- MDPBench Lite 上和 PaddleOCR-VL-1.5 差距更明显
所以它更像:工程系统能力很强,但在这次本机 lite 分数里不是第一。
5.3 HunyuanOCR**:单集爆发力强,但部署门槛高、跨集波动更大**
HunyuanOCR 在 OmniDocBench Lite 这次是第一,这说明它在复杂文档解析上确实有很强的单集表现。
但问题也很明显:
- 到了 MDPBench Lite 掉到第四
- 官方推荐部署环境是 Linux + CUDA 12.9 + 20GB GPU
- 对普通本地机和 Windows 用户不够友好
所以它更像:
- 你愿意接受更高部署门槛
- 想要一条端到端单模型路线
- 并且更关注特定复杂文档集上的强表现
那就值得试。
但如果你更在意"总体稳、好部署、通用性",这次还是 PaddleOCR-VL-1.5 更合适。
5.4 MonkeyOCR**:修正接入后明显回升,但跨场景稳定性仍然不足**
这块需要单独说清楚。
官方 README 里,MonkeyOCR 的介绍和公开 benchmark 很强:
- 官方强调它是轻量级 LMM 文档解析路线
- 官方 end-to-end parse 能输出 markdown、tables、formulas 和 middle json
- 官方自己的 README 里也给了和多种方法的 benchmark 对比
但在我这次 benchmark 里,MonkeyOCR 一开始因为接入方式只走了 text-only 路线,结果被明显低估。修正为完整 parse 路线后,结果有了明显改善,尤其:
- OmniDocBench Lite 的 Table TEDS 从 0.0000 提升到了 0.8996
- OmniDocBench Lite 的 rank_score 从 0.4620 提升到了 0.8818
- 它在 OmniDocBench Lite 上已经超过了 PP-StructureV3
这里我更倾向于做一个谨慎解释:
- 之前那组 0 分表格结果,根因在于 repo 接入方式,而不是模型天生没有表格能力
- 修正后,它的结构化恢复能力已经能在 OmniDocBench Lite 上体现出来
- 但它在 MDPBench Lite 上仍然只拿到 0.4869,而且 24 页里有 1 页失败
所以更合理的表述是:
- MonkeyOCR 不是"没有表格能力",之前是接入方式有误
- 修正接法后,它在结构化文档上的潜力已经体现出来
- 但在更复杂、更多语言、更偏拍照场景的 MDPBench Lite 上,稳定性仍然明显不如 PaddleOCR-VL-1.5
**6.**这些工具各自更适合什么场景
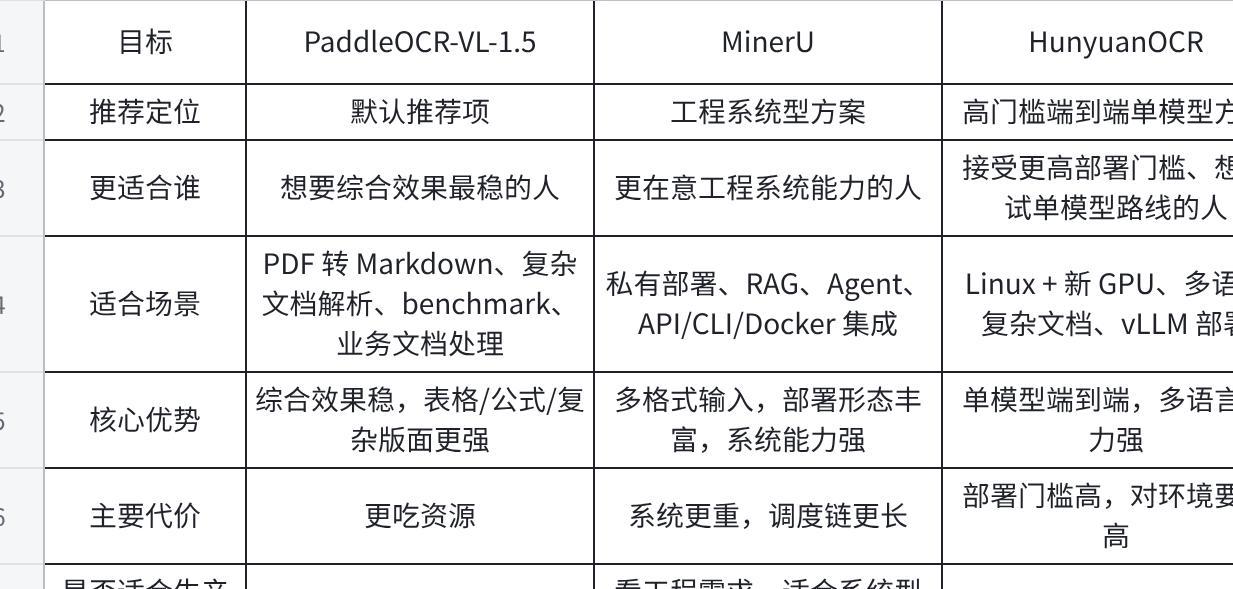
点击图片可查看完整电子表格
**7.**一句话结论
如果只给一句结论:
- 想要 综合效果 + 部署清晰 + 实测最稳,优先选 PaddleOCR-VL-1.5
- 想要 工程系统能力和私有部署形态,看 MinerU
- 想要 单模型端到端 + 多语言强项,可以重点试 HunyuanOCR
- 想要 研究型轻量 LMM 路线,可以看 MonkeyOCR;但如果要直接做稳定生产基线,它目前仍然不如 PaddleOCR-VL-1.5
总结:
从这次对比可以看出, PDF 转 Markdown 的核心早已不是 " 能不能识别文字 " ,而是 " 能否把结构、顺序和可复用性一起保留下来 " ,从而真正服务于 RAG 、知识库和大模型应用。在本次 lite benchmark 中, PaddleOCR-VL-1.5 的优势最明显,它不是每一项都绝对第一,但在两个数据集上都保持了很强的综合表现,尤其在表格、公式、复杂版面和跨场景稳定性上更均衡,因此最适合作为默认生产主通道。所以当前更推荐 PaddleOCR-VL-1.5 ;如果目标是针对特定工程体系或研究方向做差异化选择,再考虑 MinerU 、 HunyuanOCR 和 MonkeyOCR 会更合适。