通用命令
Redis的命令是有很多的,这里只列举常用的命令,有需要现查即可。
Set
插入一条数据
set key value
Get
查询具体的key所对应的value
get key ------return value
Keys
查询当前服务器上匹配的key,返回所有满足 pattern 的key,以下为统配样式
?: 匹配任意一个字符*:匹配0个或多个任意字符(尽量避免*查询)[abcde]: 匹配该区间内的,如abcde[^e]:排除e,其他都能匹配
如果我们想找关于key为hello / heello,则可以使用:keys h*llo,返回的就是两个key,一个hello,一个heello
Exist
判断key是否存在,返回key存在的个数,可一次性查询多个key
exist key、exist key1 key2
Del
删除指定key,可一次性删除多个
del key、del key1 key2
Expire
给指定key设置过期时间,被赋值的key若超过过期时间,则被自动删除,设置单位是秒 / s
返回值:1 表示设置成功;0表示设置失败。
expire key seconds
Eg:expire key1 30
TTL
TTL总成为Time to live,用来查看当前key的过期时间还剩多少。
返回值:默认为剩余过期时间(s);-1 表示没有关联过过期时间;-2 表示key不存在
TTL拓展
学习网络原理的IP协议时,IP的报头中就有一个字段叫TTL,都是表示过期时间,不过IP的TTL不是用时间衡量的,而是次数。
每次通过路由器转发一次,TTL就 -1,一直减到0,如果还没到达,则被自动丢弃。
过期策略
上述命令讲解中有提到key的过期时间,那么Redis是如何直到这些key是过期需要删除的呢?又是怎么知道哪些key还没过期不会误删?
这就提到Redis的过期策略的实现。
总的来讲,Redis的整体策略有:
-
惰性删除
如其名,就是不主动去找过期的key。等到key被访问,Redis再去查,如果到了过期时间,就把它删了,同时给用户返回一个nil。
这样思路是好的,但如果过期的key太多,没有查询到的key会长时间占用系统内存资源,所以还需要一个定期删除来辅助。
-
定期删除
每次抽取一部分,验证一部分key的过期时间。这样避免全局搜索key的长时间占据系统资源的情况,保证抽取检查的过程足够快,不会消耗太多的时间。
那为什么对定期删除有严格的时间检查要求呢?
答:因为Redis是单线程的程序,主要的任务都是在一个线程执行的(如执行命令,扫描过期key)。如果扫描过期key时间太多了,就可能导致正常请求的命令被阻塞了,毕竟扫描过期key相比于正常的执行命令重要性还是没有这么高的。
-
内存淘汰
定时器实现原理
Redis并没有采用以下两种定时器来实现删除过期key,但我们可以通过Redis来了解定时器,这是重要的部分。
这里介绍两种实现方式
-
基于优先级队列 / 堆的方式
利用优先级队列,自定义优先级:可以通过"过期时间越早,优先级越高",则队首元素就是最早过期的key,优先级高的key就先出队列
堆是特殊的二叉树,利用父节点和两子节点的大小关系(这里就以过期时间的大小为例)和小根堆 / 大根堆的设计,对过期时间早的key删除
实现细节:
-
定时器中分配一个线程去检查队首元素看是否过期,如果队首元素还没有过期则后面的元素一定还没有过期。这样做的好处就是不用遍历所有key,只需要盯着队首的元素即可。
-
定时器扫描的时间间隔也不能太频繁,此时可以根据当前时间与队首的元素的过期时间设置一个等待时间。如:当前时间为12点,设置的key1过期时间是13点,则线程休眠时间就为一小时左右,一小时过后系统再唤醒线程检查key1。
-
如果在线程休眠的时候来了个key2,过期时间为12点半,则可以唤醒刚才的线程,重新检查队首元素,再根据key2重新调整等待时间。
-
时间轮
如其名,将时间抽象成一个轮子的形态,将时间分为很多各小段(如每1s一段),各个小段的粒度要实际分析,如图。
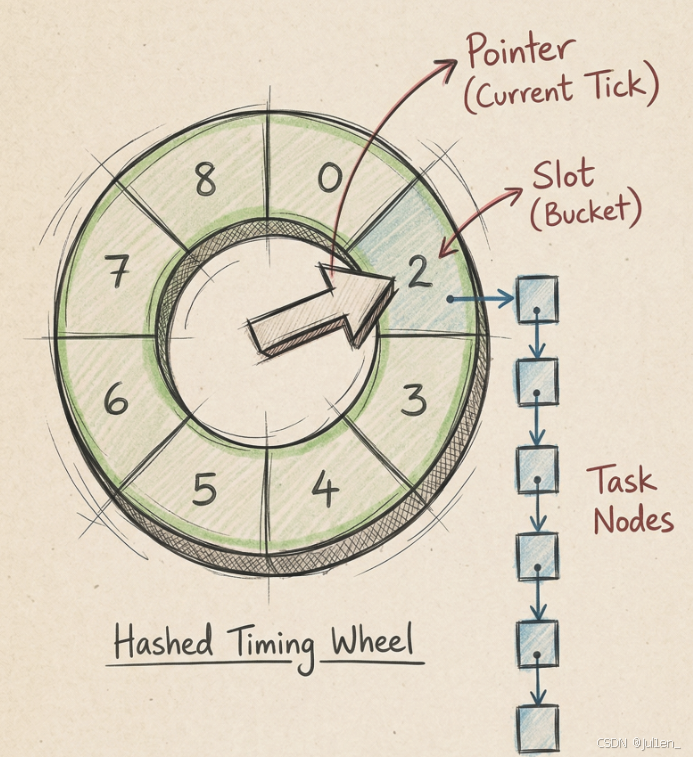
实现细节:
-
从图中能看出,有个指针在中间"转",每隔一个周期(此处是1s)就跑到下一格子中。每个格子中都会挂着一个任务链表,每个链表都代表要执行的任务,链表中再细化每个任务节点。指针每次走到一个格子就会尝试执行将格子上的链表的任务。
-
假设需要添加一个key1在3s后过期,则在时间轮的第3段中,添加一个任务:删除key1。当指针跑到这里的时候就会将过期的key删除。
它主要使用链表和无序链表管理定时事件(基于 aeEventLoop),而非时间轮或堆栈。虽然 Redis 自身底层没有使用复杂的时间轮,但它非常适合用 ZSet(有序集合)来实现基于时间轮思想的分布式延迟队列。
希望对你有帮助,祝你身体健康。