反向传播
网络结构 运算过程
输入 x=x0,x1 w = \[w11,w12,w21,w22]
全连接层 (转置知道就行,算的时候就不用太在意转不转置)np.dot(x,w) = x0\*w11+x1\*w21,x0\*w12+x1\*w22
sigmoid sigmoid(wx) = sig(x0\*w11+x1\*w21),sig(x0\*w12+x1\*w22)
均方差损失 (sigmoid(wx)-y)**2 /n =(y_pred\[0-y0)**2/n,(y_pred1-y1)**2/n]
loss值 偏导

优化器 - Adam

a 为步长也就是学习率
β1,β2属于[0,1) 晚点说
f(θ): 目标函数,也就是模型,θ则是训练的参数
θ0: 初始的参数
m0 : 开始等于0
v0 : 开始等于0
t : 开始等于0
当模型没有训练好之前进行循环,循环的内容如下:
t = t+1 起到一个计数器的作用
gt = 偏导f(θt-1)
mt = β1*mt-1 + (1-β1)* gt 相当于历史轮梯度的累加
vt = β2*vt-1 + (1-β2)* gt**2 相当于历史轮梯度的平方的累加
然后就是这俩,我们要知道,俩β都是属于[0,1)之间的数字,随着循环次数地增加也就是t地不断变大,这项不断地变小,那么分母不断地变大,总的来说值会变小,
这样就保证训练速度先快后慢
最后地那个符号是个偏量,值很小,它地存在就是为了防止分母为0,我们可以不用看
1.实现简单,计算高效,对内存需求少
超参数具有很好的解释行,且通常无需调整或仅需很少的微调
更新的步长能够被限制在大致的范围内(初始学习率)
能够表现出自动调整学习率
5.很适合应用于大模型的数据及参数的场景
适用于不稳定目标函数
适用于梯度系数或梯度存在很大噪声的问题
NLP任务
任务: 字符串分类 - 判断字符串中是否出现了指定字符
例:
指定字符:a
样本: abcd 正样本
bcde 负样本
"abcd" ---- 每个字符转化成向量 -------> 4* 5矩阵
4*5 矩阵 ---- 向量求平均--------> 1 *5 向量
1*5 向量 ---- wx+b线性公式 ----> 实数
实数 ---- sigmoid 归一化函数 ------> 0-1之间实数
Embedding层
Embedding矩阵是可训练得参数,一般会在模型构建时随机初始化也可以使用预训练得词向量来做出初始化,此时也可以选择不训练Embedding层中得参数
输入得整数序列可以重复,但取值不能超过Embedding矩阵得列数
核心价值:将离散值转化为向量
在npl任务和各类特征工程中应用广泛
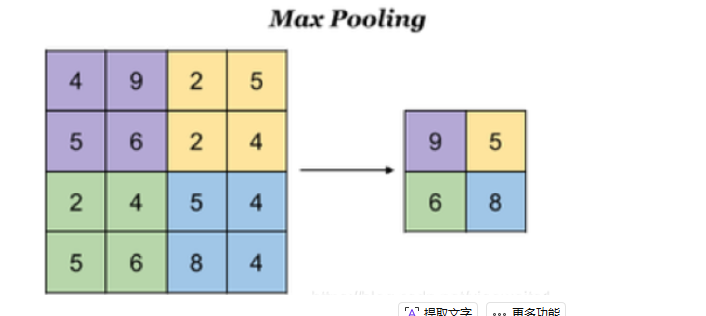
池化层
降低了后续网络层的输入维度,缩减模型大小,提高计算速度
提高了特征的鲁棒性,防止过拟合
为什么要池化
假如一个 4*4的x 那么w一定要是4*n的,但是如果x进行池化压缩成2*2,那w就能变成2*n的,当然参数量很多的时候,这个效果就会很明显
具有一定的不变性,从下面的区域可以看出,哪怕部分出现变动比如一些位置的数换换位置,也依旧不影响池化后的结果,提高了模型的健壮性,防止过拟合(只认识自己见到过的数据)
池化怎么个法
就比如
竖着加起来池化,还是横着加起来池化好呢
这里是竖着池化,因为横着池化的话跟没池化没什么区别,因为我们的初衷是向量化,每个字符能用高维向量来表示

import torch import torch.nn as nn """ pooling层的处理 """ # pooling操作默认对于输入张量大的最后一维进行 # 入参5,代表把五维池化为一维 layer = nn.AvgPool1d(4) # 随机生成一个维度为3*4*5的张量 # 我们个理解成 3条,文本长度为4,向量长度为5的样本 x = torch.rand([3,4,5]) print(x) print(x.shape) x = x.transpose(1,2) # 这个我们为什么要进行交换,因为我们要对最后一个维度进行 #缩,也就是如上面的我们要进行列的压缩,而不是行,拿上面的例子来说,文本长度为4,因为我们要#弱化字与字之间的关系,我们才把它进行向量化成长度为5的样本,也可以是其他长度,如果我们不交换之间进行layer,那么我们做的向量化就是无效的了 print(x.shape,"交换后") print(x) y = layer(x) print(y) print(y.shape) # squeeze方法去掉值为1的维度, y = y.squeeze() print(y) print(y.shape)AvgPool1d 就是最后一个维度进行压缩,2d则是最后两个维度 ,何为最后的维度
3,4,5 那么最后一个维度就是5那个维度
但是上面的那些模型无法解决语序的问题,你打了我,我打了你,把每个字都向量化成5维向量,照上面的求法结果是一样那么大模型就会把你打我和我打你理解成同一句,但是很明显这俩不是一个句子,怎么解决这个问题呢
解决这个问题的方法就是网络结构-RNN
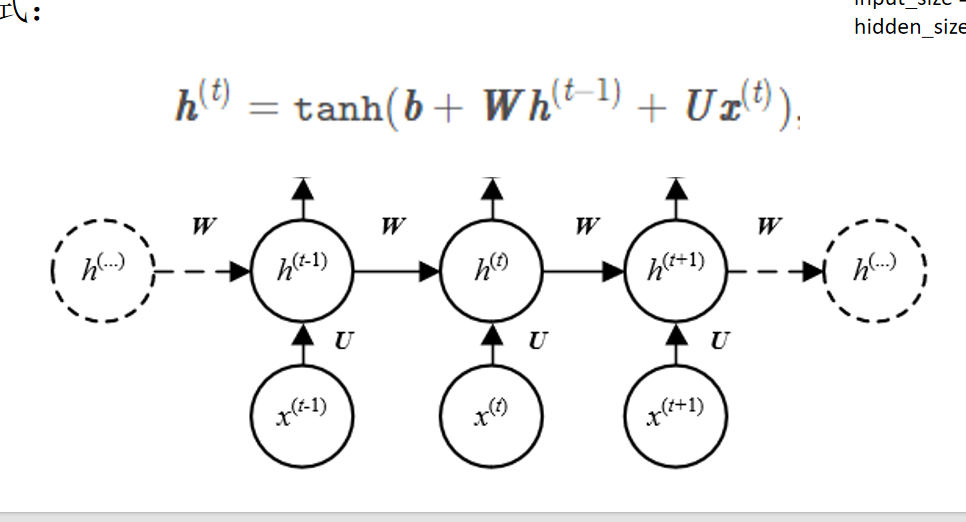
循环神经网络
主要思想: 将整个序列划分成多个时间步,将每一个时间步的信息依次输入模型,同时将模型输出的结果传给下一个时间步
RNN公式:
h(t) = tanh(b+Wh(t-1)+Ux(t)) W和U一样都是权重阵,而h(0) 是全零初始化
这个公式我们可以看到,最后一个h可以代表整个信息,因为它存储了其他字的信息
h的名称叫隐向量
RNN的弊端:
可能出现梯度消失和爆炸
RNN的实现:
import numpy as np import torch import torch.nn as nn """ 手动实现简单的神经网络 """ class TorchRNN(nn.Module): def __init__(self,input_size,hidden_size): super(TorchRNN,self).__init__() self.layer = nn.RNN(input_size,hidden_size, bias=False, batch_first=True) batch_size= True 就是告诉我x传的第一维就是batch_size def forward(self,x): return self.layer(x) # 自定义RNN模型 class DiyModel: def __init__(self,w_ih,w_hh,hidden_size): """ ht = tanh(xt * Wih + ht-1 * Whh +b) w_ih = input_size w_hh = output_size hidden_size = hidden_size :param w_ih: :param w_hh: :param hidden_size: """ """ w_ih为(input_size,hidden_size) w_hh为(hidden_size,hiiden_size) """ self.w_ih = w_ih self.w_hh = w_hh self.hidden_size = hidden_size def forward(self,x): ht = np.zeros((self.hidden_size)) #上来的 output = [] for xt in x: ux = np.dot(self.w_ih,xt) wh = np.dot(self.w_hh,ht) ht_next = np.tanh(ux+wh) output.append(ht_next) ht = ht_next return np.array(output),ht x = np.array([[1,2,3], [3,4,5], [5,6,7]]) #网络输入 # torch实验 hidden_size = 4 torch_model = TorchRNN(input_size=3,hidden_size=hidden_size) # print(torch_model.state_dict()) w_ih = torch_model.state_dict()["layer.weight_ih_l0"] w_hh = torch_model.state_dict()["layer.weight_hh_l0"] print(torch_model.state_dict()) print(w_ih,w_ih.shape) print(w_hh,w_hh.shape) torch_x = torch.FloatTensor([x]) output,h = torch_model.forward(torch_x) print(h) print(output.detach().numpy(), "torch模型预测结果") print(h.detach().numpy(), "torch模型预测隐含层结果") print("---------------") diy_model = DiyModel(w_ih, w_hh, hidden_size) output, h = diy_model.forward(x) print(output, "diy模型预测结果") print(h, "diy模型预测隐含层结果")
网络结构 - CNN
以卷积操作为基础的网络结构,每个卷积核可以看成一个特征提取器
接下来还有一些网络组件(了解)
Normalization
Dropout层:
作用: 减少过拟合
按照指定概率, 随机丢弃一些神经元(将其化为零)
其余元素乘以1/(1-p)进行放大 保证矩阵去除一些神经元后,就是变0后,不变0的放大倍数,有助于保证内积一样
import torch import torch.nn as nn import numpy as np x = torch.Tensor([1,2,3,4,5,6,7,8,9]) dp_layer = torch.nn.Dropout(0.9) dp_x = dp_layer(x) print(dp_x)这段代码乘以放大了 1/(1-0.9) 倍数后

其中model.eval() 如果模型中有Dropout层,它就会取消Dropout的随机丢弃,哪怕你写,它也不会丢弃
而model.tarin() 则是随机丢弃