你在风控系统里看到一个IP风险评分85分,系统提示"高风险,建议拦截"。但这个分数到底是怎么来的?是代理IP加了50分,还是因为它命中过垃圾注册标签?如果不理解评分背后的计算逻辑,你就无法判断这个分数是否可信,更无法在业务中合理设置拦截阈值。
IP风险等级评估的核心,是将一个IP地址的多种风险特征,量化为0-100分的综合评分。本文从评分模型的底层逻辑出发,拆解五个评估维度及其权重分配,并给出可落地的计算示例和代码实现。
一、IP风险评分不是单一指标,而是多因子加权
IP风险评分的本质,是构建"IP风险画像"------将模糊的威胁转化为可量化的指标。根据行业公开资料,评分模型通常采用多维度加权的方式,每个维度根据IP在该维度上的表现增减分数。
不同服务商的评分模型略有差异,但核心维度基本一致。参考行业公开的评估体系,常见的五维权重分配如下:
| 评估维度 | 权重 | 核心指标 | 典型加分规则 |
|---|---|---|---|
| 基础可信度 | 30% | IP纯净度(住宅/机房/代理)、地理位置一致性 | 数据中心IP +25分;代理IP +30分;住宅IP不加分 |
| 行为异常度 | 25% | 访问频次、协议特征、时段异常 | 单日访问超500次 +15分;凌晨高频访问 +10分 |
| 历史污点值 | 20% | 黑名单记录、恶意活动标签 | 被3+黑名单收录 +40分;有垃圾注册记录 +30分 |
| 环境风险性 | 15% | 代理穿透、设备指纹异常 | 使用代理/VPN +20分;设备参数篡改 +15分 |
| 动态威胁度 | 10% | 实时攻击特征、流量突发 | 检测到扫描行为 +25分;流量突增300% +20分 |
各维度分值计算后按权重加总,得出最终的风险评分(0-100分,分数越高风险越大)。IP数据云的风险评分就是根据风险证据、风险标签、代理类型发生时间及风险类型综合计算的,并支持根据行业风控需求定制打分。
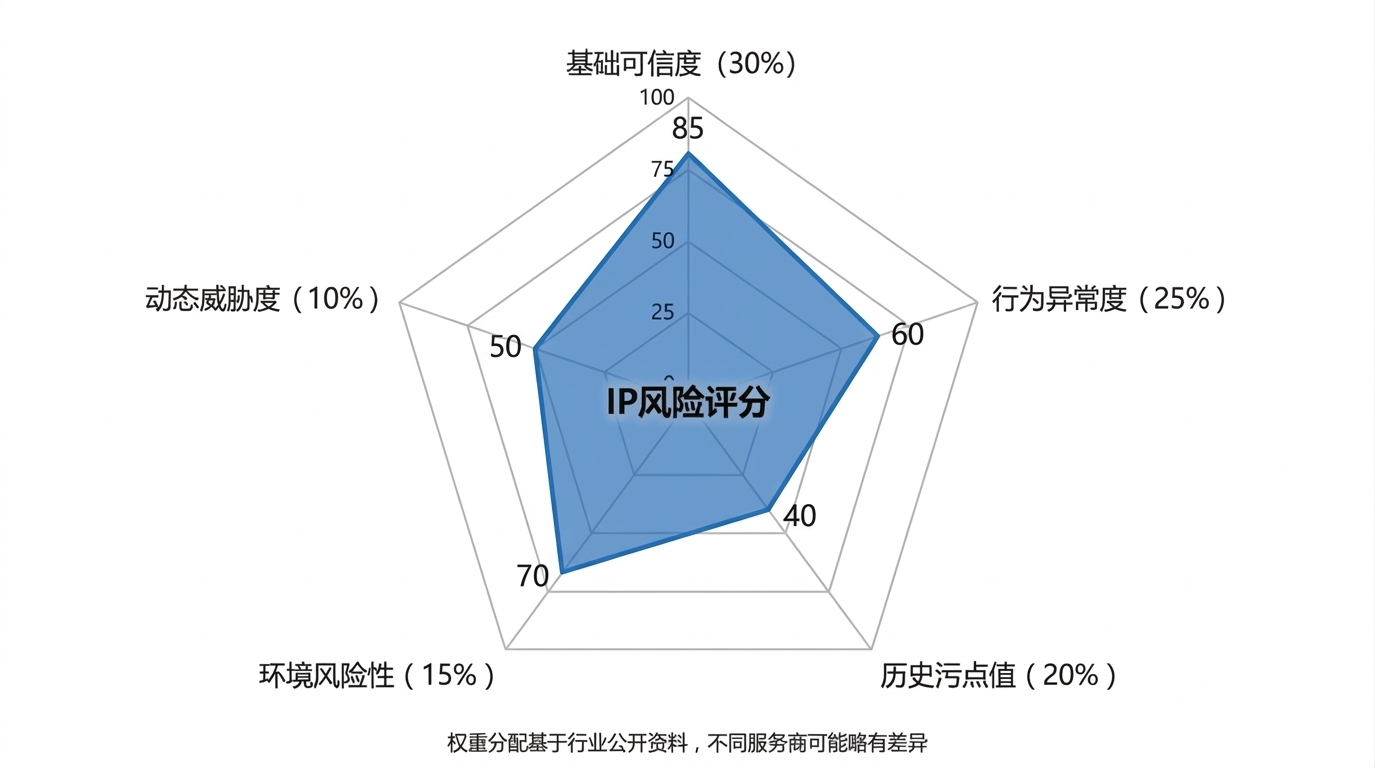 IP风险评分五维权重雷达图:基础可信度30%、行为异常度25%、历史污点值20%、环境风险性15%、动态威胁度10%
IP风险评分五维权重雷达图:基础可信度30%、行为异常度25%、历史污点值20%、环境风险性15%、动态威胁度10%
二、评分计算逻辑:从"基础分"到"加减分"
IP风险评分的计算,通常采用"基础分+风险加分"的模式。以下是完整的评分计算流程:
第一步:确定基础分
-
住宅IP:基础分设为0分(纯净度高,风险低)
-
移动网络IP:基础分设为5分(部分场景存在漂移)
-
数据中心IP:基础分设为25分(机房流量,风险较高)
-
代理IP/VPN:基础分设为30分(隐藏真实身份,风险高)
第二步:叠加各维度加分
以上述权重表为基础,每个维度的加分项叠加计算。例如:
-
某数据中心IP(+25分),同时被3个以上黑名单收录(+40分),且近1小时检测到扫描行为(+25分)
-
合计加分 = 25 + 40 + 25 = 90分
-
最终风险评分 = 90分(满分100封顶)
第三步:输出风险等级
根据最终评分划定风险等级:
| 评分区间 | 风险等级 | 建议操作 |
|---|---|---|
| 0-30分 | 低风险 | 放行,无需额外验证 |
| 31-60分 | 中风险 | 触发二次验证(短信、滑块) |
| 61-80分 | 高风险 | 人工审核或增强验证 |
| 81-100分 | 严重风险 | 直接拦截 |
IP数据云API返回的risk_score字段即为综合风险评分,risk_level字段则对应上述等级划分,企业可根据业务需求定制评级标准。
三、决策流程:评分如何驱动风控动作
基于IP风险评分,风控系统可以构建分级决策流程。下图展示了从IP查询到最终动作的完整链路:
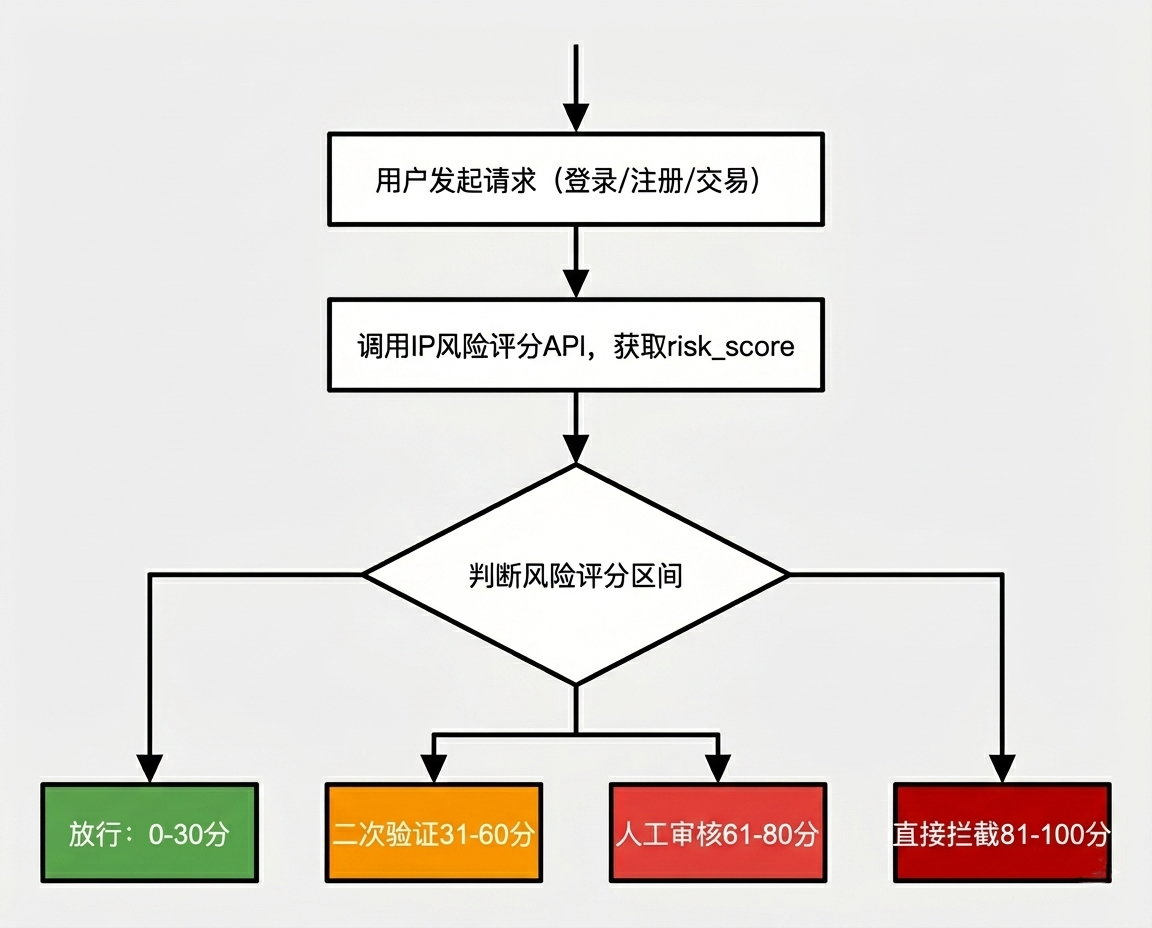 IP风险评分计算流程图:从IP类型确定基础分,叠加行为异常、历史污点、环境风险、动态威胁加分,最终输出风险等级
IP风险评分计算流程图:从IP类型确定基础分,叠加行为异常、历史污点、环境风险、动态威胁加分,最终输出风险等级
四、代码实战:如何调用API获取IP风险评分
以下代码展示了如何在用户注册时,调用IP风险评分API获取多维风险信息,并根据评分执行分级风控策略。
import requests
def register_risk_check(user_ip, user_email):
"""
用户注册时的IP风险检查
user_ip: 注册请求来源IP
user_email: 用户邮箱(用于后续验证)
"""
# 调用IP数据云风险画像API
url = "https://api.ipdatacloud.com/v2/query"
params = {
"ip": user_ip,
"key": "YOUR_API_KEY",
"risk": "true" # 开启风险识别
}
try:
resp = requests.get(url, params=params, timeout=2)
data = resp.json()
if data.get('code') != 200:
return "allow" # 接口异常时放行,避免误杀
result = data['data']
risk_score = int(result['risk'].get('risk_score', 0))
risk_level = result['risk'].get('risk_level', '')
risk_tags = result['risk'].get('risk_tag', [])
proxy_status = result['risk'].get('proxy', '')
# 分级风控策略
if risk_score >= 81:
return "block" # 严重风险:直接拦截
elif risk_score >= 61:
return "manual_review" # 高风险:人工审核
elif risk_score >= 31:
# 中风险:发送短信验证码
send_sms_code(user_email)
return "verify"
else:
return "allow" # 低风险:直接放行
except Exception as e:
return "allow" # 异常降级代码说明:
-
注册场景是最容易遭受批量虚假注册的攻击点,在用户提交注册信息前调用该函数,可以在第一时间识别风险
-
risk_tag字段可返回"垃圾注册""薅羊毛""网络爬虫"等具体标签,帮助理解评分背后的原因 -
评分阈值可根据业务场景灵活调整:获客型业务可适当放宽,高价值交易场景则应收紧
五、总结与实操建议
IP风险等级评估的核心价值,是将模糊的安全威胁转化为可量化、可管理的风险指标。理解评分背后的计算逻辑后,企业在实际应用中可以做到:
-
合理设置阈值:根据不同业务场景的风险容忍度,动态调整拦截线。注册场景可设置70分拦截,支付场景可收紧至50分。建议用A/B测试验证阈值有效性。
-
结合多维度信息 :评分只是参考,应结合
risk_tag中的具体标签(如"数据中心""垃圾注册")做综合判断,避免只看单一数字。例如,一个数据中心IP但无历史污点,可能只是企业办公网络,不应直接拦截。 -
持续数据验证:定期用真实业务数据验证评分准确性,观察误拦率和漏报率,迭代优化阈值。建议每月抽取1000条样本,人工复核被拦截的请求,评估是否合理。
-
建立降级策略:任何外部API都可能超时或异常,必须在风控链路中设计降级逻辑------接口故障时默认放行,避免因风控系统不可用导致业务中断。
-
理解模型边界:IP风险评分对IPv6地址、移动网络漂移、企业专线的识别能力有限。在这些场景下,应降低IP评分的决策权重,引入设备指纹、行为特征等其他信号。
理解评分逻辑,才能用好评分工具;用好评分工具,才能构建既安全又不打扰用户的风控体系。