文章目录
-
- [一、 引言:为什么 Chunking 是 RAG 系统的"基本盘"?](#一、 引言:为什么 Chunking 是 RAG 系统的“基本盘”?)
-
- [1.1 什么是文档分块?](#1.1 什么是文档分块?)
- [1.2 分块质量如何决定 RAG 的成败?](#1.2 分块质量如何决定 RAG 的成败?)
- [1.3 Spring AI 提供的核心抽象组件](#1.3 Spring AI 提供的核心抽象组件)
- [二、 核心博弈:分块的关键参数解析](#二、 核心博弈:分块的关键参数解析)
-
- [2.1 Chunk Size(分块大小):大与小的双刃剑](#2.1 Chunk Size(分块大小):大与小的双刃剑)
- [2.2 Chunk Overlap(重叠度):保持语义连贯的粘合剂](#2.2 Chunk Overlap(重叠度):保持语义连贯的粘合剂)
- [三、 基础分块策略与 Spring AI 代码实战](#三、 基础分块策略与 Spring AI 代码实战)
-
- 策略一:固定长度分块 (Fixed-size Chunking)
- [策略二:带有 Overlap 的滑动窗口分块](#策略二:带有 Overlap 的滑动窗口分块)
- [四、 进阶分块策略:保留文档的"骨架"](#四、 进阶分块策略:保留文档的“骨架”)
- [五、 提升检索命中的"黑科技":Metadata (元数据) 增强](#五、 提升检索命中的“黑科技”:Metadata (元数据) 增强)
-
- [5.1 为什么分块后必须附加 Metadata?](#5.1 为什么分块后必须附加 Metadata?)
- [5.2 Spring AI 代码演示:注入元数据与 Metadata Filtering](#5.2 Spring AI 代码演示:注入元数据与 Metadata Filtering)
- [六、 检索之后的"二次抢救":重排 (Rerank) 技术](#六、 检索之后的“二次抢救”:重排 (Rerank) 技术)
-
- [6.1 什么是重排?](#6.1 什么是重排?)
- [6.2 为什么要用 Rerank?](#6.2 为什么要用 Rerank?)
- [七、 总结与最佳实践](#七、 总结与最佳实践)
-
- [7.1 没有银弹:如何根据业务场景选择策略?](#7.1 没有银弹:如何根据业务场景选择策略?)
打通大模型应用的任督二脉:Spring AI 语境下的 RAG 分块策略全景图
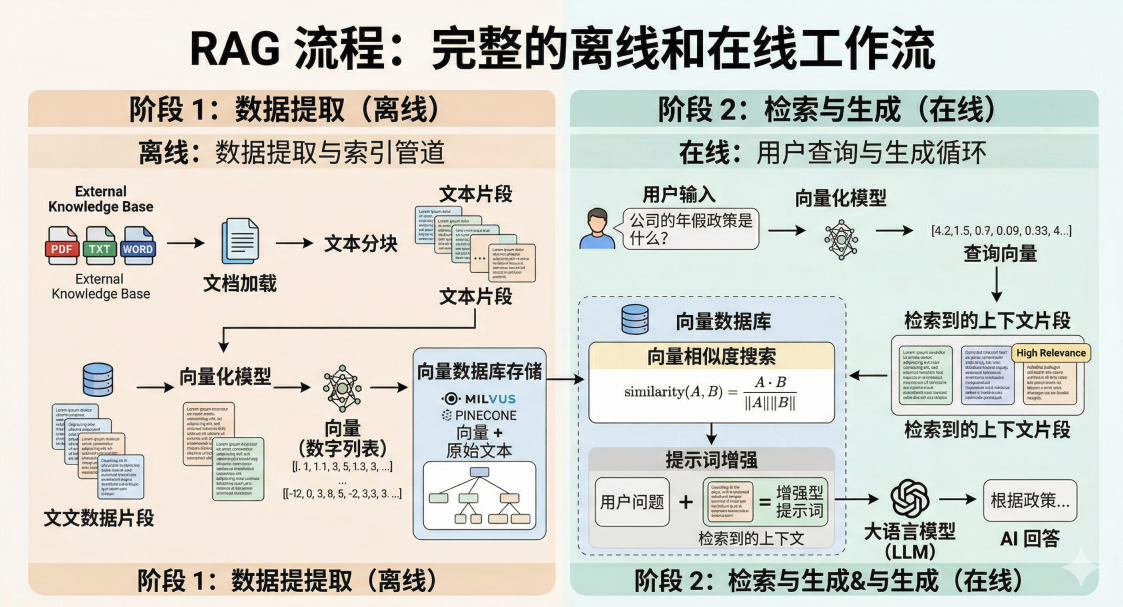
在上一篇探讨了 RAG 的基本概念后,我们知道要把私有数据喂给大模型,必不可少的一步是"文档入库"。但在现实中,我们不可能把一整本几十万字的电子书直接扔进向量数据库(Vector Store)。这时候,就必须祭出构建 RAG 系统最基础也是最关键的一步:文档分块(Chunking)。
本文将结合 Spring AI,深入剖析 RAG 中的 Chunking 策略,带你手把手打通大模型应用的"任督二脉"。
一、 引言:为什么 Chunking 是 RAG 系统的"基本盘"?
1.1 什么是文档分块?
受限于大语言模型(LLM)的上下文窗口限制(Token Limit),以及向量模型在长文本提取核心语义时的局限性,我们需要将长篇大论的长文档"切碎",变成一段段独立且短小精悍的文本块。这就是文档分块(Chunking)。这就好比在图书馆里找资料,我们找的不是某一本书,而是书中对应具体知识点的那几页。
1.2 分块质量如何决定 RAG 的成败?
在 RAG 的世界里有一句名言:"Garbage In, Garbage Out" (垃圾进,垃圾出)。
- 检索准确率:如果分块过大,这块内容的意思就会变得复杂而模糊,向量相似度匹配时可能什么都匹配不上(大海捞针捞不到)。
- 上下文连贯性 :如果分块过小,极易破坏完整的句子甚至词组,大模型拿到这样残缺不全的面包屑,往往会产生严重的幻觉(Hallucination)。
1.3 Spring AI 提供的核心抽象组件
在 Spring AI 框架中,为了优雅地处理数据入库,抽象出了两个核心概念:
Document:文档的载体。它不仅包含了文本内容 (content),还包含了一个重要的 Map 用于存储元数据 (metadata)。TextSplitter:分块器接口。它的核心职责就是接收一大堆初始Document,然后经过切分、处理,返回一批全新的、更小的Document列表。
二、 核心博弈:分块的关键参数解析
无论是哪种分块策略,通常都绕不开两个核心参数的博弈:
2.1 Chunk Size(分块大小):大与小的双刃剑
- 过大:单块包含太多冗余信息,不仅稀释了核心语义,在送给大模型生成时,还会白白浪费珍贵的 Token。
- 过小:丢失了必要的上下文语境。比如"这个功能",如果切分时脱离了前文的主语,大模型根本不知道"这个"指代什么。
2.2 Chunk Overlap(重叠度):保持语义连贯的粘合剂
- 为什么需要重叠? 分块往往是机械切分的,极有可能把一句连贯的话从中间一刀切断。此时,让前后两个文本块保持一部分重叠的内容,就像是砌砖时的砂浆,能强制保留上下文段落之间的联系。
- 如何设置合理比例? 经验法则上,通常建议 Overlap 比例设定在文档块大小的
10% - 20%之间。
三、 基础分块策略与 Spring AI 代码实战
下面我们进入大家最喜欢的实战环节。在 Spring Boot 工程中,我们来看看最基础的切分是怎么玩转的。
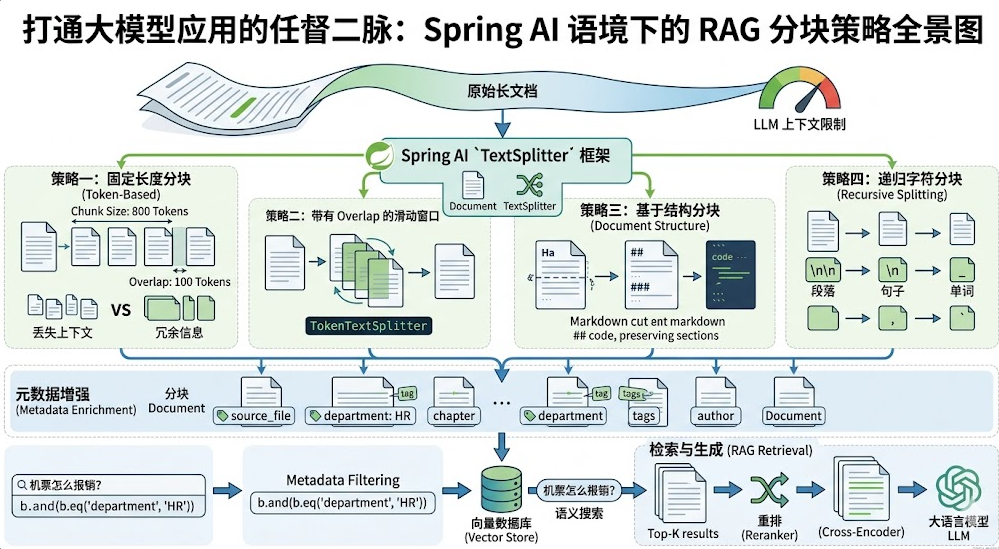
策略一:固定长度分块 (Fixed-size Chunking)
原理:简单粗暴地按字符数量或 Token 数量进行"一刀切"。
Spring AI 代码实战 :使用官方提供的 TokenTextSplitter 进行切分。
java
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import java.util.List;
// 假设 documents 是你刚刚通过 TextReader 读取出的整篇原始文档
List<Document> documents = loadMyDocuments();
// 实例化一个 Token 文本分块器
// 参数含义 (示例):
// defaultChunkSize: 800 (期望每个块大约800个token)
// minChunkSizeChars: 350 (最小字符数限制)
// minChunkLengthToEmbed: 100 (小于这个长度的碎片可能直接丢弃)
// maxNumChunks: 100 (最多切多少块限制)
// keepSeparator: true (是否保留分隔符,比如换行符)
TokenTextSplitter splitter = new TokenTextSplitter(800, 350, 100, 100, true);
// 执行切分动作
List<Document> chunks = splitter.apply(documents);
// (补充说明)最后将这些 chunks 存入向量数据库即可
// vectorStore.add(chunks);策略二:带有 Overlap 的滑动窗口分块
原理 :在上述固定长度的基础之上,引入一个"滑动窗口",使得分块之间有所交集。
Spring AI 的 TokenTextSplitter 在深层源码中对边界处理和保留分隔符 (KeepSeparator) 时其实默认考虑了段落边界,但如果我们需要极致地控制 Overlap,一般会结合特定的自定义分块器,或者直接在参数上限定重叠尺寸。
四、 进阶分块策略:保留文档的"骨架"
业务复杂起来后,单纯的机械切分就不够看了,我们需要一些尊重"语言结构"的高级玩法。
策略三:基于结构的分块 (Document-Structure Based Chunking)
原理 :尊重原文的 Markdown、HTML 标签或 PDF 段落结构进行自然切分。
场景:带有大量标题、列表和代码块的技术文档。如果把一个代码块劈成两半,大模型绝对会发疯。
Spring AI 实战思路 :在切分前进行预处理。我们可以结合 MarkdownDocumentReader (Spring AI 内置机制或使用 Tika 等引擎扩展),在送给 TokenTextSplitter 前,先按 ##、### 等标题层级进行粗粒度的划分,保证每个段落都是完整的逻辑单元。
策略四:递归字符分块 (Recursive Character Splitting)
原理 :设定一个分隔符优先级列表(如:段落 \n\n -> 句子 \n -> 单词 ),逐级往下尝试切分,直到恰好满足目标 Chunk Size。这是目前最强大也最均衡的分块法。
实现思路 :目前可以通过继承或实现 Spring AI 的 DocumentTransformer 接口,仿写递归逻辑,打造符合自己团队规范的自定义 Splitter。
五、 提升检索命中的"黑科技":Metadata (元数据) 增强
只有纯文本的 Chunk 往往是苍白无力的。
5.1 为什么分块后必须附加 Metadata?
假设你搜"报销流程",向量库返回了 5 个文本块。但如果没有元数据,你不知道这些规定是 2023 年的还是 2024 年的,是属于"北京分公司"还是"上海分公司"的。必须让文本知道它的身世(来源、时间、章节、作者)!
5.2 Spring AI 代码演示:注入元数据与 Metadata Filtering
分块前/后向 Document 注入元数据是一种非常好的工程习惯:
java
import org.springframework.ai.document.Document;
// 在分块处理或文档加载时遍历 Document
for (Document doc : chunks) {
// 追加额外的业务元数据
doc.getMetadata().put("source_file", "2024年员工手册.pdf");
doc.getMetadata().put("department", "HR");
doc.getMetadata().put("chapter", "报销指南");
// ID等元信息默认也可被自动管理
}
// 存入 VectorStore
vectorStore.add(chunks);真正能发挥 Metadata 威力的是在**检索(Retrieval)**阶段,它可以借助如 PgVector 等支持元数据过滤的底层数据库,实现强大的 Metadata Filtering(先过滤,再做向量运算,极大提升准确率):
java
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
// 构建带 Metadata 过滤的强力检索请求
FilterExpressionBuilder b = new FilterExpressionBuilder();
SearchRequest request = SearchRequest.query("机票怎么报销?")
.withTopK(3)
// 黑科技:只在 HR 部门且文件是 2024版的数据里搜,彻底杜绝拿过期旧制度胡说八道!
.withFilterExpression(b.and(
b.eq("department", "HR"),
b.eq("source_file", "2024年员工手册.pdf")
).build());
List<Document> accurateResults = vectorStore.similaritySearch(request);六、 检索之后的"二次抢救":重排 (Rerank) 技术
当你的文档分块做得再好,有时候也会遇到一个尴尬的问题:向量相似度极高,但实际上跟业务根本不挨边(字面相似但语义无关)。为了解决这个问题,我们在拿回 Top-K 的粗排结果后,会引入**重排(Reranker)**机制。
6.1 什么是重排?
如果说向量检索是"海选",为了效率通常选出几十个候选者(如 Top 20);那么重排就是"终面"。它会引入精细度更高、但性能开销稍大的交叉编码器模型(Cross-Encoder,如 BGE-Reranker 或 Cohere Rerank),对这几十个候选者结合用户的 Query 进行重新精细打分和排序。最后只留下最精准的 3-5 个,才真正拼接进 Prompt 交给大模型。
6.2 为什么要用 Rerank?
- 打破上下文噪点:大模型处理越多的无用文本块,就越容易分心(Lost in the Middle 现象),且浪费 Token 费用。Rerank 负责取其精华。
- 提升最终生成准确率:让真正与问题强相关的知识排在 Prompt 的前列,这就相当于给大模型的参考书画好了红线重点,大幅度削减幻觉。
七、 总结与最佳实践
7.1 没有银弹:如何根据业务场景选择策略?
- 智能客服 / FAQ 问答库 :每个知识点都很独立,尽量使用较小的 Chunk Size,确保一击必中。
- 长篇研报分析 / 小说总结 :上下文跨度很大,需要偏大的 Chunk Size,配合较高的 Overlap,甚至是将大块提炼出的 Summary 作为 Metadata 补充进去。
- 代码库/技术文档检索 :基于结构的分块绝对是首选,宁可每块长度不一,也决不能破坏代码块(Code Block)的完整性。