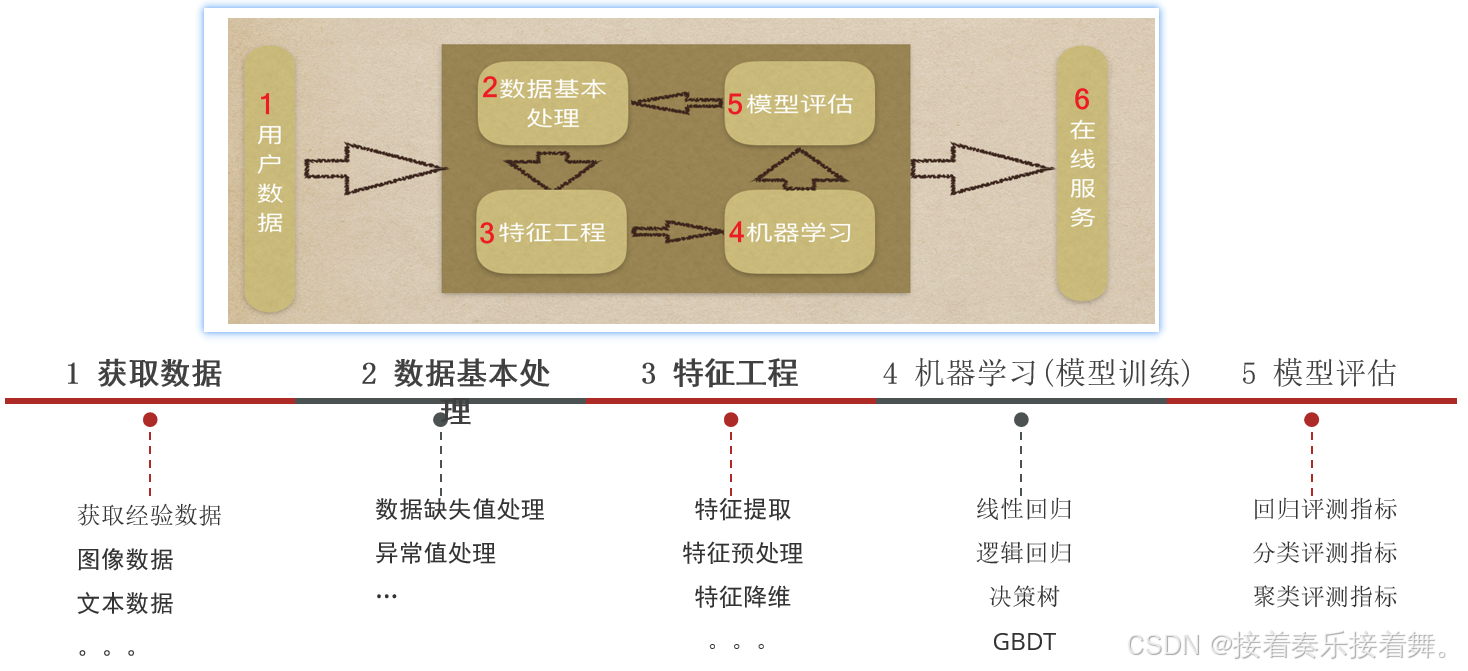
1.一个标准的机器学习项目流程(一定要记住顺序)
很多新手觉得乱,是因为没按流程想问题。做任何项目,脑子里要有这根"流水线":
-
定义问题 → 是分类还是回归还是聚类?业务目标是什么?
-
获取数据 → 数据从哪来?
-
探索与清洗(EDA) → 看分布、找缺失、除异常(这一步最花时间)
-
特征工程 → 把原始数据变成模型爱吃的"饭"(归一化、编码、组合特征)
-
拆分数据 → 训练集 / 验证集 / 测试集
-
选模型训练 → 先跑一个简单的基准模型(如逻辑回归),再尝试复杂的
-
调参与评估 → 看准确率、召回率、AUC,调整参数避免 过拟合 和 欠拟合
-
部署与监控 → 模型上线后表现如何
2.定义问题详解
一共4种情况:第一种:有监督学习,数据中有标签且标签是连续的则为回归任务,比如薪资、房价这种数字;不是连续的也就是离散的就是分类任务,像健康情况,电影类别;可以看到区分回归和分类其实很简单,像标签的个数是有限的几个就是分类,像薪资这种的数值非常多的是回归,可以联想到一根直线上的无数点;**第二种,无监督学习,数据中没有标签,主要是聚类任务,比如一堆图片中找出一直大象;第三种,半监督学习,数据中部分有标签部分没有标签;第四种强化学习,**为了达到最大化累积奖励,通过不断的在环境中试错类学会做出最优决策
3 获取数据
这就是我们需要处理的数据,不做赘述,一般用pandas来读取文件
python
# 1.读取文件获取数据
data = pd.read_csv('data/breast-cancer-wisconsin.csv', sep=',')
print(data.shape, data.ndim) # 形状:(699, 11) 维度:24 探索与清洗(EDA)
缺失值处理
-
删除:缺失率 > 70% 的列直接删;缺失行较少可删行。
-
填充:均值/中位数/众数;复杂场景用模型预测填充。
-
【补充】业务含义填充 :例如"上月消费金额"为空,填 0 和填均值业务含义完全不同。要先判断是"没记录"还是"没发生"。
异常值处理
-
原则:不要无脑删。
-
方法:3-Sigma 原则、箱线图 (IQR)。
-
【补充】对异常值的态度 :金融欺诈检测中,异常值往往就是我们要抓的坏人,不能删,只能做分箱或变换。
python
# 2.数据预处理
# 2.0 注意: 数据中有"?"无效字符,需要先转换为numpy中的nan,然后使用dropna()删除或者fillna()填充
new_data = data.replace('?', np.nan).dropna()
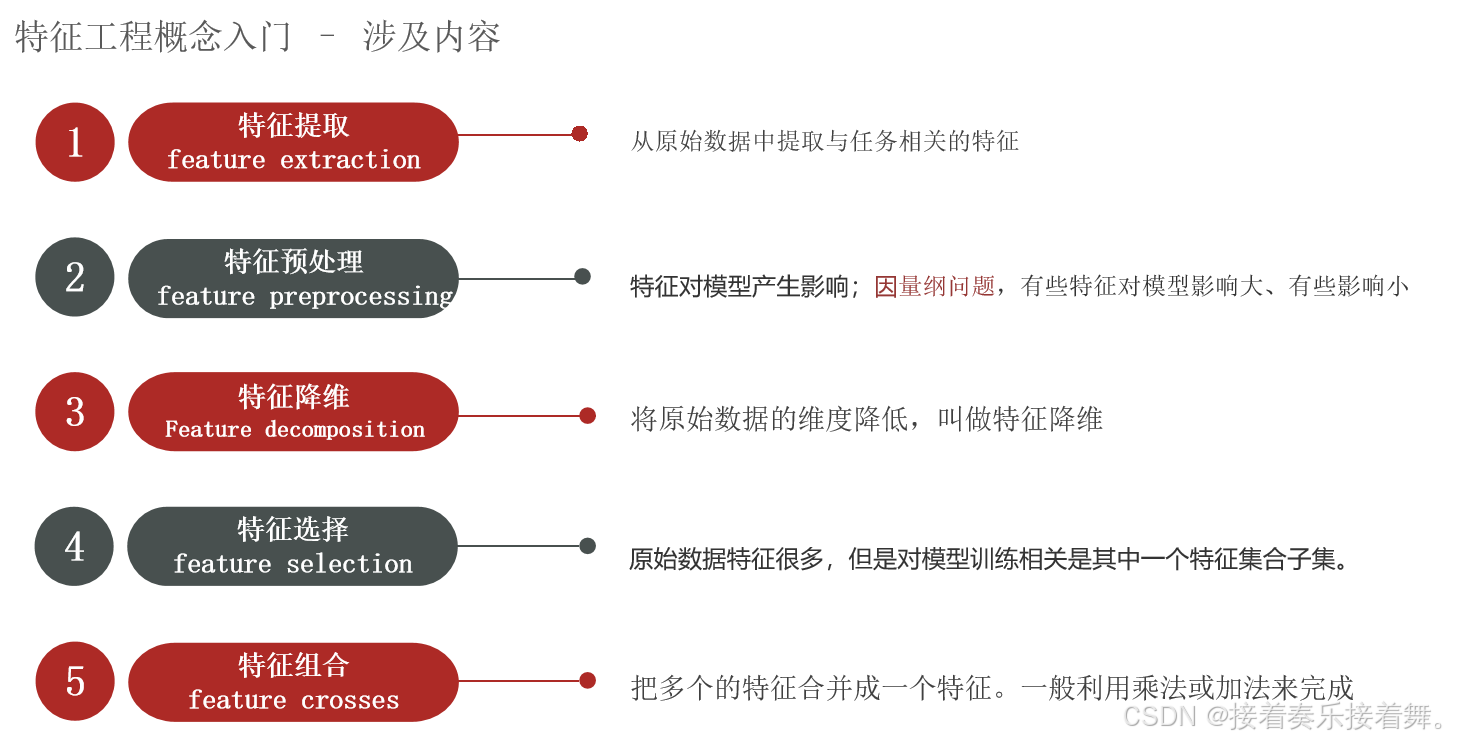
print(new_data.shape, new_data.ndim) # 形状:(683, 11) 维度:25 特征工程
特征变换(无量纲化)
-
归一化:将数据缩放到 0, 1 区间。
-
公式:X' = \\frac{X - X_{min}}{X_{max} - X_{min}}
-
【补充】使用时机 :涉及距离计算 (KNN、神经网络、K-Means)必须做 ;树模型不需要。
-
-
标准化:将数据变为均值为 0,标准差为 1 的分布。
-
公式:X' = \\frac{X - \\mu}{\\sigma}
-
【补充】使用时机:假设数据服从正态分布时效果更好。
-
特征编码(文字转数字)
-
独热编码 :把类别变成互相独立的 0/1 列。缺点是维度爆炸。
-
【补充】目标编码 :用该类别对应的标签均值来代替。工业界处理高基数类别特征的利器。
特征构造(企业核心竞争力)
-
时间特征:把时间戳拆成"星期几"、"是否节假日"、"距今天数"。
-
交叉特征:身高/体重 = BMI。
-
统计特征:用户过去 7 天平均点击次数。
python
# 2.1 分别获取特征和标签
# 拓展: iloc格式 : 数据.iloc[行索引,列索引]
x = new_data.iloc[:, 1:-1]
y = new_data.iloc[:, -1]
print(x.shape, x.ndim) # 形状:(683, 9) 维度:2
print(y.shape, y.ndim) # 形状:(683,) 维度:16 拆分数据
-
基础划分:训练集 (80%) vs 测试集 (20%)。
-
【补充】标准工业级划分:
-
训练集 (Train):学习模型参数 W, b。
-
验证集 (Validation) :专门用来调参选模型。
-
测试集 (Test) :最终只用一次,评估泛化能力。
-
-
【补充】黄金法则:
-
时间序列严禁随机切分(用过去预测未来)。
-
不均衡样本必须分层抽样(防止验证集里全是负样本)
-
python
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state=666) # 同一个种子,同一份随机数据7 选模型训练
K 近邻算法
-
核心:近朱者赤,近墨者黑。
-
距离度量:默认欧氏距离。
-
缺点:预测极慢(需计算所有样本距离),企业级高并发场景基本不用。
线性回归
-
任务:回归。
-
核心思想 :找到一条线,使得预测值与真实值的误差平方和最小(最小二乘法)。
-
求解方式对比(企业选型重点):
| 方法 | 核心思想 | 优点 | 缺点 |
|---|---|---|---|
| 正规方程 | 求导等于 0 一步算出 | 简单,无需调学习率 | 数据量大时矩阵运算极慢 |
| 梯度下降 | 沿着负梯度方向小步迭代 | 适合海量数据 | 需调学习率,可能陷入局部最优 |
- 【补充】企业常用变体 :
SGDRegressor(随机梯度下降回归器),适合流式数据在线学习。
逻辑回归
-
任务 :分类(虽然名字带回归)。
-
核心流程 :线性回归的结果 z → 塞进 Sigmoid 函数 → 输出概率 P → 与阈值比较(如 0.5)得类别。
-
【补充】底层损失函数 :交叉熵损失,而非线性回归的 MSE。
K-Means 聚类
-
任务:无监督聚类。
-
核心流程:选 K 个中心 → 分配点 → 重算中心 → 迭代。
-
缺点:K 值难定,对初始点敏感。
【补充】工业界真正常用的算法家族
-
树模型家族:
-
随机森林:并行训练多棵树投票,不易过拟合。
-
XGBoost / LightGBM :目前结构化数据表格赛道的王者。GBDT 的工程优化版,面试必问,工作必用。
-
8 调参与评估
回归任务的评估
-
MAE (平均绝对误差):对异常值不敏感。
-
MSE (均方误差) :对异常值惩罚极重(平方放大)。
分类任务的评估------混淆矩阵
这是企业汇报时的核心仪表盘,必须烂熟于心。
| 真实 \ 预测 | 预测为 Positive | 预测为 Negative |
|---|---|---|
| 真 Positive | TP (真阳性) | FN (假阴性/漏报) |
| 真 Negative | FP (假阳性/误报) | TN (真阴性) |
-
准确率 :(TP+TN) / Total ------ 样本不均衡时最没用的指标。
-
精确率 :TP / (TP+FP) ------ 预测正类中有多少是对的(宁缺毋滥)。
-
召回率 :TP / (TP+FN) ------ 真实正类有多少被找出来了(宁枉勿纵)。
-
F1-Score:精确率和召回率的调和平均。
过拟合与欠拟合(企业调参的指挥棒)
| 状态 | 训练集表现 | 测试集表现 | 解决方案 |
|---|---|---|---|
| 欠拟合 | 差 | 差 | 增加特征交互项、换复杂模型、减小正则化。 |
| 过拟合 | 极好 | 差 | 增加数据量、加正则化(L1/L2)、早停法、集成学习。 |
【补充】交叉验证
-
概念:把训练集切成 K 份,轮流用 K-1 份训练,1 份验证。
-
目的:更稳定地评估模型性能,充分利用数据,防止因单次划分运气好而选错模型。
9 部署与监控
-
模型上线:转化为 PMML 文件、ONNX 格式,或封装为 API 接口。
-
线上监控:
-
性能监控:API 响应时间、QPS。
-
【补充】数据漂移监控 :监控输入特征的均值和方差 。如果线上用户突然从年轻人变成老年人,模型准确率会断崖式下跌,需要触发自动重训练。
-
总结:给未来复习的自己
-
回归 和分类 的区别,不要看名字看标签类型。
-
特征工程 是投入产出比最高的环节,树模型不需要归一化。
-
面试/汇报时,谈到分类模型,一定先问一句:"数据均衡吗?看准确率还是 F1?"
-
XGBoost 和 LightGBM 是工业界处理表格数据的首选,不要只会用逻辑回归。
-
"部署上线不是毕业典礼,而是开学典礼。你要开始操心这玩意儿明天会不会挂掉、下周准不准、下个月还能不能用了。"
名词备忘录:
1. 梯度下降
是什么:一种"摸着石头下山"的走法。你在山顶,雾很大看不见路,只能靠脚底感受坡度,哪儿往下倾斜就往哪儿走一步,反复这样,最终走到山谷最低处。
有什么用:让计算机自动找到让预测最准的那条线的位置。
怎么记:
> 盲人下山:看不见路,但能感觉到脚下哪里最陡。每走一步都用脚探一下,朝最陡的下坡方向走一小步。重复这个动作,直到脚下变平,就知道到谷底了。
2. 学习率
是什么:梯度下降时**每一步迈多大**。
有什么用:控制找最低点的速度。太大容易跨过去,太小走得太慢。
怎么记:
> 下山时步子太小:走了一万步还在半山腰。
> 下山时步子太大:一脚迈出去,直接从山谷这边跨到那边,完美错过最低点。
3. 参数(w 和 b)
是什么:就是你初中数学里直线方程的**斜率和截距**。
有什么用:决定了那条预测线的具体位置。
怎么记:
> 直线公式 y = 2x + 3 里,2 就是斜率,3 就是截距。
> 机器学习里只不过把 2 叫成 w,把 3 叫成 b。**换了个名字而已,本质一模一样。
4. 损失函数
是什么:一把**误差尺子**,专门量"预测值和真实值差了多少"。
有什么用:告诉计算机,当前这条线画得有多烂。差得越多,损失数值越大。
怎么记:
> 你扔飞镖,飞镖落点离靶心越远,你心里越"失落"。
> 损失函数就是那个给你打分的人,扔得越偏,扣分越多。
5. 过拟合
*是什么*:**死记硬背,不懂变通。**
有什么用:这是我们最怕的情况,说明模型学傻了。
怎么记:
> 考试前你把练习册答案全背下来了,连印刷错误都背了。
> 考试时题目稍微换个问法,你照着背的答案往上写,结果全错。
> **表现**:作业(训练集)全对,考试(测试集)不及格。
6. 欠拟合
是什么**:**根本没学进去,连作业都不会做。**
*有什么用**:说明模型太简单,或者根本没学到东西。
怎么记**:
> 上课全程睡觉,考试时连题目都看不懂,交白卷。
> **表现**:作业(训练集)和考试(测试集)分数都极低。
---
7. 正则化
是什么**:给模型**戴上一个紧箍咒**,不让它太放肆、太复杂。
有什么用**:专门治**过拟合**的。让模型别把细节当真理。
怎么记**:
> 你复习时,老师不让你去背那些偏题怪题,要求你只抓重点。
> 正则化就是那个老师,它会给那些过于复杂的记忆方式"扣分",逼你只记住最核心的规律。
---
8. 归一化 / 标准化
是什么**:把不同单位的数据**统一拉到同一个尺度里**。
*有什么用**:防止某个特征因为数值太大,把其他特征的话筒抢了。
*怎么记**:
> 一个班要评"综合分",规则是把身高和体重加起来。
> 身高是 170cm,体重是 70000g(70kg)。
> 如果不统一单位,体重那一项直接决定了总分,身高完全没用了。
> **归一化就是统一换单位,比如都换成"在同班同学中的排名百分比"。**
---
9. Sigmoid 函数
是什么**:一个能把任何数字**压扁到 0 到 1 之间**的 S 形曲线。
有什么用**:把预测分数变成概率。比如 500 分压成 0.99,20 分压成 0.01。
怎么记**:
> 它是一个**概率换算器**。
> 你考了 500 分,别人不知道这算好还是差。
> 放进 Sigmoid,它告诉你:"你赢的概率是 99%"。
---
10. 混淆矩阵
是什么**:一张**对错记账表**。
有什么用**:告诉你模型**错在哪儿了**。
怎么记(警察抓小偷版)**:
| 真实情况 | 警察判断 | 叫什么 | 大白话 |
| 是小偷 | 抓了 | TP | **抓对了** |
| 是好人 | 放了 | TN | **放对了** |
| 是好人 | 抓了 | FP | **冤枉好人** |
| 是小偷 | 放了 | FN | **放跑坏人** |
11. 精确率
是什么**:你说"抓到了贼",这里面**真的有几个人是贼**?
有什么用**:衡量**抓得准不准**。要求"宁可放过,不可抓错"。
怎么记**:
> 你指着 10 个人说他们都是小偷。
> 精确率 90% 意思是:里面 9 个是真的,1 个是被冤枉的。
12. 召回率
是什么**:真正的 100 个小偷里,**你抓到了几个**?
有什么用**:衡量**抓得全不全**。要求"宁可抓错,不可放过"。
怎么记**:
> 商场里有 100 个真小偷。
> 召回率 80% 意思是:你抓住了 80 个,漏了 20 个。
---
13. F1 分数
是什么**:精确率和召回率的**调和平均值**。
有什么用**:当你既想抓得准、又想抓得全时,看这个指标。
怎么记**:
> 精确率和召回率像跷跷板两头,一个高另一个就低。
> F1 就是告诉你,跷跷板平衡了没有。如果 F1 很高,说明你两手都抓了。
14. 交叉验证
是什么**:把一份练习册**撕成五份**,轮流用四份当练习题、一份当测验题。
有什么用**:检验你是不是真学会了,而不是碰巧蒙对了一套卷子。
怎么记**:
> 你不能只做一套模拟卷就上高考考场。
> 你要做十套不同学校的模拟卷,如果每套都考得好,说明你是真学霸。