在这篇文章【机器学习算法】一文搞定 SVM ------ 从 MMC 到 SVC,再到 SVM-CSDN博客中,我们通过"几何直觉(容忍点越过超平面)"引入了松弛变量 \\epsilon_i,构建了 SVC 的目标函数。随后引入核函数讲解了 SVM。
但实际上,对 SVM 的解释,机器学习界还有另一种完全等价的、更具普适性的视角:"损失函数 + 正则化" 视角。
1、从带约束条件到无约束形式的推导
回顾 SVC 原始的数学模型:
\\min_{\\beta, b, \\epsilon} \\quad \\frac{1}{2} \\\|\\beta\\\|\^2 + C \\sum_{i=1}\^n \\epsilon_i
约束条件: y\^{(i)}(\\beta\^T x\^{(i)} + b) \\ge 1 - \\epsilon_i 且 \\epsilon_i \\ge 0。
为了方便,我们记 z_i = y\^{(i)}(\\beta\^T x\^{(i)} + b)。
将约束条件稍微变形,我们可以得到 \\epsilon_i 的下界:
-
因为约束一:\\epsilon_i \\ge 1 - z_i
-
因为约束二:\\epsilon_i \\ge 0
既然我们的目标函数是在最小化 \\epsilon_i,那么 \\epsilon_i 必然会取到满足上述两个条件的最小值。
也就是说,\\epsilon_i 实际上就等于 0 和 1 - z_i 这两个数中较大的那一个!
用严谨的数学式子表达就是:
\\epsilon_i = \\max(0, 1 - y\^{(i)}(\\beta\^T x\^{(i)} + b))
2、什么是合页损失函数 (Hinge Loss)?
上面推导出的函数 L(z) = \\max(0, 1-z),在机器学习中大名鼎鼎,被称为合页损失函数(Hinge Loss)。因为它的图像看起来像一个翻折的合页(铰链)。
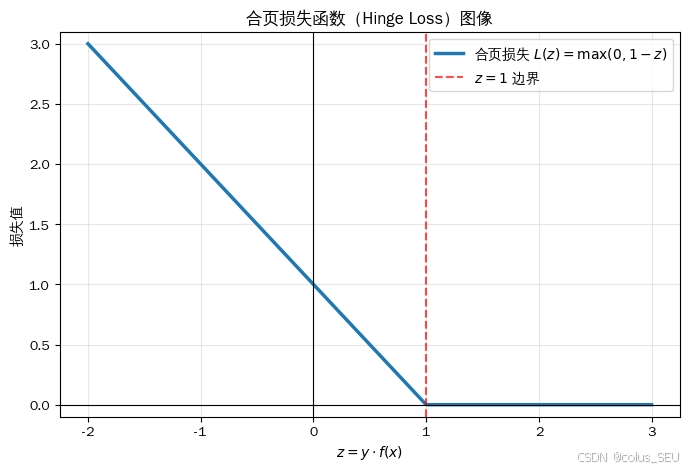
根据 z(即正确分类的置信度)的大小,它分为三种情况:
-
z \\ge 1 :点在安全区(分类完全正确且在隔离带之外)。此时 1-z \\le 0,所以 Loss 为 0。模型对此十分满意,不产生任何惩罚。
-
0 \< z \< 1 :点在隔离带内(分类正确,但置信度不够高)。Loss 为 1-z。模型产生轻微惩罚。
-
z \\le 0 :点越过中心超平面(被彻底分错类)。Loss 大于 1 且随距离线性增加。模型产生严重惩罚。
3、统一范式与"稀疏性"的最终解释
我们将 \\epsilon_i = \\max(0, 1 - y\^{(i)}(\\beta\^T x\^{(i)} + b)) 直接代回 SVC 的目标函数中。
原本带着繁琐约束条件的 SVC,瞬间化身为一个极其优雅的无约束优化问题:
\\min_{\\beta, b} \\sum_{i=1}\^n \\max\\left(0, 1 - y\^{(i)}(\\beta\^T x\^{(i)} + b)\\right) + \\lambda \\\|\\beta\\\|\^2
(注:这里将常数 C 进行了等价代换,令 \\lambda = \\frac{1}{2C})
这个公式的伟大意义在于:
-
统一了机器学习框架:它完美契合了现代机器学习最通用的结构定义:
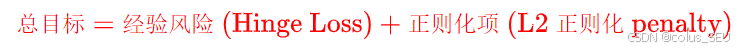
这说明,SVC 在本质上就是一个使用 Hinge Loss 作为损失函数,并自带 L2 正则化(权重衰减)的线性分类器!它和逻辑回归(使用交叉熵损失)在架构上没有任何区别,只是换了损失函数。
-
彻底解释了支持向量的"稀疏性":
为什么大部分数据点的 \\alpha_i = 0?从 Hinge Loss 的视角看简直一目了然:
如果一个点足够安全(z \\ge 1),它的 Hinge Loss 就是绝对的 0。在微积分里,一块平坦的 0 区域,它的梯度(导数)就是 0!
既然梯度为 0,它对优化参数 \\beta 就不会产生任何拉扯的作用力,模型完全当它不存在。所以,天然的 0 损失,造就了 SVM 那神乎其技的稀疏性。