写在前面:
在构建 AI 语音应用时,开发者常面临一个尴尬的"最后一公里"问题:大模型(LLM)虽能理解万物,却听不懂方言。 尤其是在应急汇报、乡镇政务或医疗问诊等特定场景中,标准普通话往往让位给情感更真切、但也更难识别的方言口音。如何利用 Dify 的强大编排能力,结合 讯飞(iFLYTEK) 深耕多年的方言识别引擎,构建一套高效、稳健的方言转写服务?
目录
[1、讯飞 API credentials](#1、讯飞 API credentials)
[1、AudioConverter 类设计](#1、AudioConverter 类设计)
2、核心转换方法(download_and_convert)
[2、WebSocket 通信](#2、WebSocket 通信)
一、项目背景与架构
1、项目需求
我们需要构建一个语音转文字系统,实现以下功能:
-
用户在 Dify 平台上传音频文件(M4A/MP3/WAV 等格式)
-
将音频转换为讯飞 API 要求的 PCM 格式(16kHz, 16bit, 单声道)
-
调用讯飞方言识别 API 进行语音识别
-
将识别结果返回给 Dify 进行后续处理
科大讯飞语音识别 API是讯飞开放平台核心的语音转文字(ASR)云服务,依托自研深度神经网络与星火大模型技术,提供高精度、低延迟、多语种、强降噪的流式与非流式识别能力。
科大讯飞语音识别 API 以98%+的安静环境准确率、毫秒级响应与阵列降噪 为核心优势,支持RESTful/WebSocket 双接口、74 种语种 + 23 种方言 (大模型版免切换 200 + 方言),兼容 PCM/MP3 等主流音频格式,提供实时转写、文件转写、录音文件识别等多形态服务,可自定义专业词库适配医疗 / 金融 / 政务等领域讯飞开放平台,覆盖 Android/iOS/Java/ 小程序等全平台 SDK讯飞开放平台,支持公有云 / 私有化部署,广泛用于智能硬件、会议转写、客服质检、直播字幕等场景,接入门槛低、文档完善、服务稳定。
| 对比项 | RESTful API(HTTP) | WebSocket API(wss) |
|---|---|---|
| 适用场景 | 短语音识别、录音文件识别、批量离线转写 | 实时语音转写、流式听写、边录边转、长语音连续识别 |
| 典型接口名称 | 一句话识别、录音文件识别、异步转写 | 实时语音转写(IAT/RTASR)、流式语音听写 |
| 连接方式 | 短连接,一次请求一次响应 | 长连接,双向持续通信 |
| 音频传输 | 一次性上传完整音频文件 / Base64 | 分片流式传输音频流 |
| 返回结果 | 识别完成后一次性返回 | 实时增量返回,边说边出字 |
| 延迟 | 较高,适合非实时场景 | 低延迟,适合实时交互场景 |
| 音频时长限制 | 一般支持较短语音,或长音频异步处理 | 支持超长连续语音识别 |
| 鉴权方式 | Authorization 头鉴权 | URL 拼接签名鉴权 |
| 调用复杂度 | 简单,通用 HTTP 调用即可 | 稍复杂,需处理连接、心跳、分片 |
| 典型用途 | 语音录入、文件转写、客服录音质检 | 实时字幕、语音助手、直播转写、车载对话 |
本项目使用的方言识别大模型仅支持WebSocke接口,
💡为什么需要PCM转换?
该项目使用的方言识别大模型(控制台-讯飞开放平台)对输入音频有严格要求:
采样率:必须是 16000Hz(16kHz)
位深:必须是 16bit
声道:必须是单声道(mono)
格式:必须是原始 PCM 数据(无文件头)
而用户上传的音频可能是 M4A、MP3、WAV 等格式,采样率和声道数也不统一,因此必须进行标准化转换。
【可查看官方的方言大模型协议:方言大模型 协议 | 讯飞开放平台文档中心】

2、系统架构
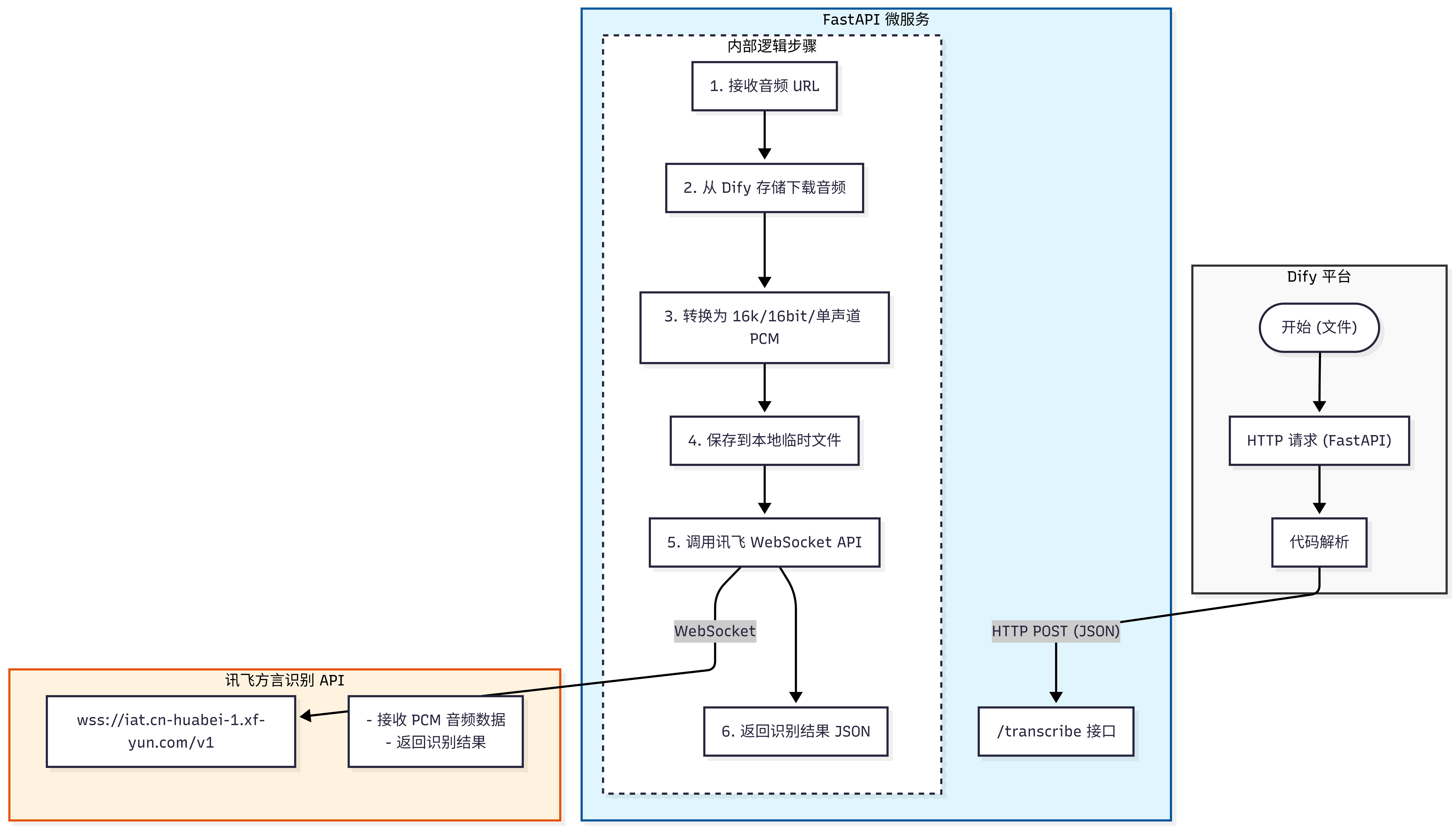
💡为什么不直接在Dify的HTTP节点上传文件,而要引入 FastAPI 中转层?
(1)Dify HTTP 节点的文件上传限制
Dify 的 HTTP 请求节点对文件上传采用form-data格式,但该项目采用的讯飞 API 要求WebSocket 持续传输。
HTTP 节点无法处理 WebSocket 协议,只能进行简单的请求 - 响应式 HTTP 调用。
文件需要经过格式转换(M4A/MP3 → PCM),Dify 内置节点无法完成复杂音频处理。
(2)协议转换需求
Dify → 本地:HTTP/HTTPS( RESTful API)
本地 → 讯飞:WebSocket(长连接,流式传输)
需要中转层进行协议适配和数据格式转换
(3)业务逻辑封装
音频下载、格式转换、WebSocket 通信、错误重试等逻辑需要代码实现
FastAPI 提供清晰的 API 接口,便于 Dify 调用和调试
中转层可以缓存、日志记录、错误处理,提高系统可靠性
3、核心流程
-
**音频 URL 获取:**Dify HTTP 节点将文件 URL 传递给 FastAPI
-
**文件下载:**FastAPI 从 Dify 存储目录读取音频文件
-
**格式转换:**使用 pydub+ffmpeg 转换为标准 PCM
-
**本地保存:**PCM 数据保存到临时文件
-
**WebSocket 识别:**分帧发送 PCM 数据到讯飞 API
-
**结果返回:**将识别文字以 JSON 格式返回 Dify
二、环境准备
1、讯飞 API credentials
在讯飞开放平台创建应用,获取以下凭证:
| 参数 | 说明 |
|---|---|
| APPID | 应用唯一标识 |
| APIKey | API 调用密钥 |
| APISecret | API 签名密钥(base64 编码) |
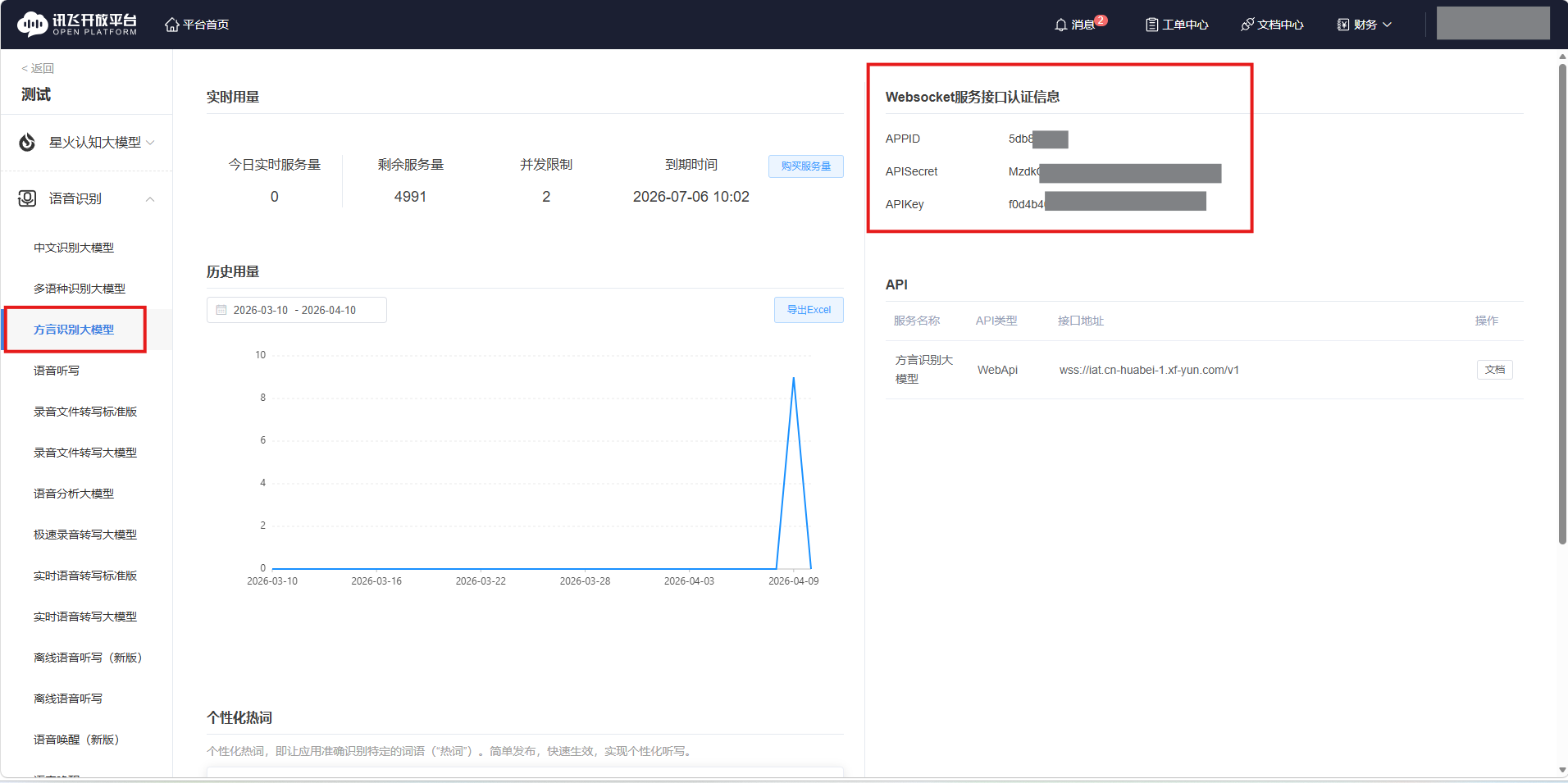
新用户注册可以获得免费的使用量!
2、项目目录结构
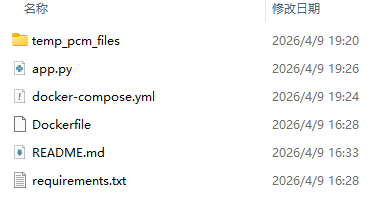
-
app.py # FastAPI 主服务
-
Dockerfile # Docker 镜像构建文件
-
docker-compose.yml # Docker 编排配置
-
requirements.txt # Python 依赖
-
temp_pcm_files/ # PCM 临时文件目录(运行时创建)
三、FastAPI服务搭建
1、创建requirements.txt
fastapi==0.104.1
uvicorn==0.24.0
pydub==0.25.1
requests==2.31.0
websocket-client==1.6.4
python-multipart==0.0.6💡依赖库说明
fastapi:现代高性能 Web 框架
uvicorn:ASGI 服务器,运行 FastAPI
pydub:音频处理库,需要 ffmpeg 支持
requests:HTTP 请求库,用于下载音频
websocket-client:讯飞 WebSocket 通信
python-multipart:处理 form-data 上传
2、创建Dockerfile
Dockerfile是Docker镜像的构建脚本,前面我们已经将Dify的环境用Docker打包,这里的Dockerfile 定义了如何将FastAPI服务(FastAPI接口调用讯飞方言识别服务API提供给Dify调用)、依赖(如 ffmpeg、Python 库)打包成一个可移植的容器镜像,保证服务在任意支持Docker的环境中能一致运行。
-
环境一致性:确保开发、测试、生产环境完全一致
-
依赖隔离:ffmpeg 等系统级依赖打包在镜像内,不污染宿主机
-
一键部署:构建一次,到处运行,无需手动安装依赖
完整Dockerfile内容:
# 使用 Python 3.10 精简版作为基础镜像
FROM python:3.10-slim
# 安装 ffmpeg(pydub 音频处理库的依赖)
# apt-get update: 更新软件包索引
# apt-get install -y ffmpeg: 安装 ffmpeg,-y 表示自动确认
# rm -rf /var/lib/apt/lists/*: 清理缓存,减小镜像体积
RUN apt-get update && apt-get install -y ffmpeg && rm -rf /var/lib/apt/lists/*
# 设置工作目录为 /app,后续命令都在此目录下执行
WORKDIR /app
# 复制依赖文件到容器
COPY requirements.txt .
# 安装 Python 依赖包
# --no-cache-dir: 不缓存下载的安装包,减小镜像体积
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码到容器
COPY app.py .
# 声明容器运行时监听的端口(文档作用,不实际绑定)
EXPOSE 8000
# 容器启动命令:使用 uvicorn 运行 FastAPI 应用
# app:app 表示 app.py 中的 app 对象
# --host 0.0.0.0: 监听所有网络接口(允许外部访问)
# --port 8000: 监听 8000 端口
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]逐行解析:
# 使用 Python 3.10 精简版作为基础镜像
FROM python:3.10-slim-
FROM:指定构建镜像的基础镜像,python:3.10-slim是 Python 3.10 的精简版镜像(体积小、仅包含核心运行环境),适合生产环境,避免冗余。安装 ffmpeg(pydub 音频处理库的依赖)
apt-get update: 更新软件包索引
apt-get install -y ffmpeg: 安装 ffmpeg,-y 表示自动确认
rm -rf /var/lib/apt/lists/*: 清理缓存,减小镜像体积
RUN apt-get update && apt-get install -y ffmpeg && rm -rf /var/lib/apt/lists/*
-
RUN:执行 Linux 命令,构建镜像时运行; -
apt-get update:更新 Debian 系统的软件包索引(因为基础镜像是 slim 版,索引可能过时); -
apt-get install -y ffmpeg:安装音频处理工具**ffmpeg**(pydub 库依赖 ffmpeg 实现音频格式转换,如 MP3/M4A 转 PCM); -
rm -rf /var/lib/apt/lists/*:删除 apt 缓存文件,大幅减小镜像体积(否则缓存会占用数百 MB 空间)。设置工作目录为 /app,后续命令都在此目录下执行
WORKDIR /app
-
WORKDIR:指定容器内的工作目录,后续的COPY、RUN、CMD等命令都会在/app目录下执行,避免文件散落在容器根目录。复制依赖文件到容器
COPY requirements.txt .
-
COPY:将宿主机当前目录下的requirements.txt(Python 依赖清单)复制到容器的/app目录(.代表当前工作目录)。安装 Python 依赖包
--no-cache-dir: 不缓存下载的安装包,减小镜像体积
RUN pip install --no-cache-dir -r requirements.txt
-
pip install --no-cache-dir -r requirements.txt:安装requirements.txt中列出的 Python 库(如 fastapi、pydub、websocket-client 等); -
--no-cache-dir:不缓存 pip 下载的安装包,进一步减小镜像体积。复制应用代码到容器
COPY app.py .
-
将宿主机当前目录下的
app.py(FastAPI 主服务代码)复制到容器的/app目录。声明容器运行时监听的端口(文档作用,不实际绑定)
EXPOSE 8000
-
EXPOSE:声明容器运行时会监听 8000 端口(仅为 "文档说明",不会自动映射宿主机端口),目的是告诉使用者该容器需要暴露 8000 端口,实际端口映射需在docker run或docker-compose中配置。容器启动命令:使用 uvicorn 运行 FastAPI 应用
app:app 表示 app.py 中的 app 对象
--host 0.0.0.0: 监听所有网络接口(允许外部访问)
--port 8000: 监听 8000 端口
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
-
CMD:定义容器启动后执行的命令,启动 FastAPI 服务; -
uvicorn:FastAPI 依赖的 ASGI 服务器(负责处理 HTTP/WebSocket 请求); -
app:app:第一个app是app.py文件,第二个app是app.py中创建的 FastAPI 实例(如app = FastAPI()); -
--host 0.0.0.0:让服务监听容器的所有网络接口(否则仅能容器内部访问,宿主机 / 其他容器无法调用); -
--port 8000:指定服务在容器内的 8000 端口运行。
3、创建docker-compose.yml
docker-compose.yml是Docker Compose工具的核心配置文件,采用YAML 格式,用于定义和管理多个 Docker 容器组成的应用集群 。简单来说,它是一套「容器编排脚本」,可以把原本需要手动执行的docker run命令、网络配置、数据挂载、依赖关系等,集中写在一个文件里,通过docker-compose up/down等命令一键启动 / 停止整个应用系统。
完整docker-compose.yml内容:
# 定义服务列表
services:
# 服务名称:xunfei-service(讯飞方言识别服务)
xunfei-service:
# 使用当前目录的 Dockerfile 构建镜像
build: .
# 端口映射:宿主机 8000 端口 → 容器内 8000 端口
ports:
- "8000:8000"
# 网络配置:加入两个外部网络
networks:
- docker_default
- dify-service_default
# 重启策略:除非手动停止,否则容器崩溃/重启后自动恢复
restart: unless-stopped
# 额外主机配置:让容器内能访问宿主机服务(host.docker.internal 指向宿主机IP)
extra_hosts:
- "host.docker.internal:host-gateway"
# 卷挂载:将 Dify 存储目录挂载到容器内(只读)
volumes:
- /mnt/e/Dify/dify-main/docker/volumes/app/storage:/app/dify-storage:ro
# 网络定义(引用外部已存在的网络)
networks:
# Docker 默认网络(外部网络,无需手动创建)
docker_default:
external: true
# Dify 启动时自动创建的容器网络(外部网络)
dify-service_default:
external: true逐行解析:
| 配置项 | 取值 | 作用说明 |
|---|---|---|
build: . |
.(当前目录) |
指定从当前目录的 Dockerfile 构建镜像,无需提前手动构建镜像,docker-compose up 时会自动构建。 |
ports: - "8000:8000" |
宿主机 8000 → 容器 8000 | 端口映射,外部(宿主机 / 其他机器)可通过 http://宿主机IP:8000 访问容器内的 FastAPI 服务;格式:宿主机端口:容器端口,容器内 FastAPI 监听 8000 端口,因此映射到宿主机 8000 端口。 |
networks |
docker_default + dify-service_default |
让 xunfei-service 容器加入两个网络:- docker_default:Docker 默认桥接网络,用于外部访问容器;- dify-service_default:Dify 平台启动时自动创建的容器网络,核心作用是让讯飞服务容器能直接访问 Dify 内部服务(如文件存储、API),实现跨容器通信。 |
restart: unless-stopped |
unless-stopped |
容器重启策略:- no:默认值,容器退出后不重启;- always:无论退出码是什么,始终重启;- unless-stopped:除非手动执行 docker stop,否则容器崩溃 / 宿主机重启后自动重启(生产环境推荐);- on-failure:仅当容器异常退出(退出码非 0)时重启。 |
extra_hosts: - "host.docker.internal:host-gateway" |
映射宿主机 IP | 解决容器内访问宿主机服务的问题:- host.docker.internal 是 Docker 内置的宿主机别名;- host-gateway 表示将该别名映射到宿主机的网关 IP,容器内通过 host.docker.internal 即可访问宿主机上的服务(如本地数据库、调试用 API)。 |
volumes: - /mnt/e/.../storage:/app/dify-storage:ro |
宿主机路径 → 容器路径 | 卷挂载(数据持久化 / 文件共享):- 宿主机路径:/mnt/e/Dify/dify-main/docker/volumes/app/storage(Dify 实际存储音频文件的目录);- 容器路径:/app/dify-storage(容器内访问 Dify 文件的目录);- :ro:只读挂载,容器内只能读取 Dify 存储的文件,无法修改,保证数据安全;- 核心作用 :讯飞服务无需通过 HTTP 下载 Dify 上传的音频文件,直接读取挂载目录的文件,提升效率且避免下载失败问题。 |
💡网络配置说明
dify-service_default:Dify 容器网络,用于访问 Dify API 和文件服务
docker_default:Docker 默认网络,用于外部访问
volume 挂载:直接读取 Dify 存储目录,避免 HTTP 下载失败问题
💡为什么要写docker-compose.yml呢?
1、让 Dify 能访问你的讯飞服务
Dify 是运行在 Docker 里的,讯飞服务也是运行在Docker里的,两个Docker容器默认是隔离的, 通过写以下代码才能让两个容器在同一个内部网络里互相通信。
networks: - dify-service_default2、让服务能读取 Dify 的音频文件
Dify 的上传文件存在宿主机里,容器默认看不到宿主机文件,通过写以下代码来读取用户上传的语音。
volumes: - 你的Dify路径:/app/dify-storage:ro
补充:Dockerfile和docker-compose.yml的联系区别
| 对比项 | Dockerfile | docker-compose.yml |
|---|---|---|
| 核心作用 | 构建 Docker 镜像(打包环境与代码) | 运行 / 编排容器(配置怎么启动镜像) |
| 身份定位 | 镜像构建说明书 | 容器运行 / 编排脚本 |
| 关键内容 | 基础镜像、安装依赖、复制代码、启动命令 | 服务名、端口映射、网络、挂载、重启策略 |
| 依赖关系 | 可独立使用(docker build) |
依赖 Dockerfile 或已有镜像 |
| 你的项目里 | 打包 FastAPI + 讯飞识别环境 | 启动讯飞容器、对接 Dify 网络与存储 |
| 常用命令 | docker build -t 镜像名 . |
docker-compose up -d |
| 能否单独运行 | 不能直接运行,只能构建镜像 | 可直接运行并启动完整服务 |
四、音频下载与PCM转换
1、AudioConverter 类设计
🔧 AudioConverter 类职责
AudioConverter 类负责音频文件的下载和格式转换,是整个流程的第一步:
文件 ID 提取:从 Dify 文件 URL 中解析出实际的文件路径
存储读取:优先从挂载的 volume 直接读取 Dify 存储文件
HTTP 下载:作为备用方案,通过 HTTP 从 Dify API 下载文件
格式转换:使用 pydub 将任意格式音频转换为标准 PCM
文件保存:将 PCM 数据保存为临时文件供讯飞识别使用
核心代码如下:
# ==================== 音频转换类 ====================
class AudioConverter:
"""音频下载和转换类"""
def __init__(self, sample_rate=16000, channels=1, sample_width=2):
# 讯飞要求的标准参数:16kHz 采样率, 单声道, 16bit(2字节) 位深
self.sample_rate = sample_rate
self.channels = channels
self.sample_width = sample_width
# Dify 存储目录(在 docker-compose 中通过 volume 挂载到容器内)
self.dify_storage = "/app/dify-storage/upload_files"
def _extract_file_id(self, audio_url: str) -> str:
"""
从 Dify 文件 URL 中提取文件 ID
URL 示例:/files/tenant_id/file_id.ext?params
"""
parts = audio_url.split('/')
if len(parts) >= 4 and parts[1] == 'files':
tenant_id = parts[2]
# 提取文件 ID 并去掉 URL 后的查询参数
file_part = parts[3].split('?')[0]
return f"{tenant_id}/{file_part}"
return None
def _read_from_storage(self, file_id: str) -> bytes:
"""
核心优化:直接从挂载的物理路径读取文件,避免网络开销
"""
file_path = os.path.join(self.dify_storage, file_id)
logger.info(f"尝试从存储目录读取:{file_path}")
if os.path.exists(file_path):
with open(file_path, 'rb') as f:
return f.read()
return None-
参数标准化 :初始化时设置
16000Hz和16bit位深,这是为了满足讯飞识别精度的硬性要求。 -
物理挂载优先 :设计了
_read_from_storage方法。因为在 Docker 环境中,直接读取挂载的volume速度最快且最稳定,避免了容器间 HTTP 通信可能产生的超时或 404 错误。
2、核心转换方法(download_and_convert)
核心代码如下:
def download_and_convert(self, audio_url: str) -> str:
"""
下载或读取音频并转换为 PCM,保存到本地,返回临时文件路径
"""
audio_data = None
# 步骤 1: 优先尝试物理路径读取(性能最优)
if audio_url.startswith('/files/'):
file_id = self._extract_file_id(audio_url)
if file_id:
audio_data = self._read_from_storage(file_id)
# 步骤 2: 备用方案 - HTTP 下载
# 如果物理读取失败,程序会循环尝试 Dify 内部网络的多个地址(如 nginx:80)
if audio_data is None:
# ... 此处省略 app.py 中的多地址循环逻辑 ...
response = requests.get(full_url, timeout=30)
audio_data = response.content
try:
# 步骤 3: 使用 pydub 进行转码
logger.info("使用 pydub 转码...")
# 将二进制流加载为音频对象
audio = AudioSegment.from_file(io.BytesIO(audio_data))
# 强制转换参数:16k/16bit/单声道
audio = audio.set_frame_rate(self.sample_rate) \
.set_channels(self.channels) \
.set_sample_width(self.sample_width)
# 步骤 4: 导出并存为临时 PCM 文件
file_name = f"{uuid.uuid4()}.pcm"
file_path = os.path.join(TEMP_PCM_DIR, file_name)
# 注意:这里导出的是 raw_data,即不带任何文件头的纯 PCM 流
with open(file_path, "wb") as f:
f.write(audio.raw_data)
logger.info(f"音频已保存至本地:{file_path}")
return file_path
except Exception as e:
logger.error(f"转换流程失败:{e}")
raise RuntimeError(f"音频处理失败:{str(e)}")-
多路径兼容 :由于 Dify 在 Docker 环境下的网络复杂性,代码同时支持 Volume 挂载读取 和 内网 HTTP 下载,确保即使配置变动也能获取到音频。
-
强制采样率转换 :人声频率范围约 300Hz-3400Hz,
16kHz的采样率(根据奈奎斯特定理可捕捉最高 8kHz 频率)是捕捉语音细节的最佳平衡点。 -
提取
raw_data:常见的 WAV 文件包含 44 字节的文件头,而讯飞 WebSocket 要求的是纯 PCM 数据流。使用audio.raw_data可以剥离所有元数据,只提供识别引擎需要的采样数值。 -
临时文件保存 :将处理后的 PCM 保存为本地文件,是为了方便后续
XunfeiASR类进行分帧读取发送,降低内存占用,特别是在处理大音频文件时更具稳定性。
💡 为什么使用 volume 挂载而不是 HTTP 下载?
在实践过程中发现,Dify 的文件 URL 带有签名和时间戳限制,且容器间网络访问存在以下问题:
签名 URL 会过期,导致 404 错误
Dify 内部网络配置复杂,容器间访问不稳定
HTTP 下载增加网络开销和延迟
通过 volume 直接挂载 Dify 存储目录,可以:
直接读取文件,无需 HTTP 请求
不受 URL 签名过期影响
性能更高,无网络延迟
五、讯飞WebSocket对接
🔑 讯飞 WebSocket 通信原理
讯飞方言识别 API 采用 WebSocket 协议进行双向通信,主要包含三个阶段:
鉴权阶段:生成带 HMAC-SHA256 签名的 URL,通过 HTTPS 建立 WebSocket 连接
音频传输:将 PCM 音频按 1280 字节分帧,每帧间隔 40ms 发送
结果接收:服务端实时返回识别结果,客户端解析 Base64 编码的 JSON 数据
1、鉴权URL生成
为了安全通信,讯飞要求对每一个 WebSocket 请求进行鉴权。鉴权的核心是利用APIkey和APISecret对请求头(Host, Date, Request-Line)进行 HMAC-SHA256 签名。
核心代码如下:
def create_url(self):
# 1. 生成 RFC1123 格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 2. 拼接签名原文 (注意顺序必须固定)
signature_origin = "host: " + HOST + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + PAGE_PATH + " " + "HTTP/1.1"
# 3. 使用 APISecret 进行 HMAC-SHA256 加密并 Base64 编码
signature_sha = hmac.new(
self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256
).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
# 4. 构建 authorization 参数
authorization_origin = 'api_key="%s", algorithm="%s", headers="%s", signature="%s"' % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha
)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 5. 将参数组合成最终的 URL
v = {
"authorization": authorization,
"date": date,
"host": HOST
}
return URL + '?' + urlencode(v)-
时间戳校验 :讯飞服务器会校验
date参数,如果与服务器当前时间偏差过大,请求会被拒绝。 -
Base64 编码:所有的签名结果和授权信息最终都需要通过 Base64 转换为字符串形式,以便在 URL 中传输。
⚠️ 关键点 :request-line 格式必须是 "GET /v1 HTTP/1.1"(注意 /v1 后面有空格)
2、WebSocket 通信
📡XunfeiASR 类职责
XunfeiASR 类负责与讯飞 WebSocket API 进行完整通信:
on_open:连接建立后,分帧发送 PCM 音频数据
on_message:接收服务端返回的识别结果并解析
on_error:处理 WebSocket 错误
on_close:连接关闭时设置完成标志
recognize:执行完整的识别流程
语音识别采用流式传输。前端或服务端通过 WebSocket 建立连接后,分帧发送音频数据。
核心代码如下:
def on_open(self, ws):
def run(*args):
frameSize = 1280 # 每一帧的音频大小
intervel = 0.04 # 发送间隔 (40ms)
status = STATUS_FIRST_FRAME # 0:首帧, 1:中间帧, 2:尾帧
with open(self.pcm_file, "rb") as fp:
while True:
buf = fp.read(frameSize)
audio = str(base64.b64encode(buf), 'utf-8')
if not audio: # 数据读完,发送最后一帧
status = STATUS_LAST_FRAME
if status == STATUS_FIRST_FRAME:
# 第一帧需包含 business 参数(如 dialect, domain 等)
d = {"header": {"status": 0, "app_id": self.appid},
"parameter": {"iat": self.wsParam.iat_params},
"payload": {"audio": {"audio": audio, "sample_rate": 16000, "encoding": "raw"}}}
ws.send(json.dumps(d))
status = STATUS_CONTINUE_FRAME
elif status == STATUS_CONTINUE_FRAME:
# 中间帧仅发送音频 payload
d = {"header": {"status": 1, "app_id": self.appid},
"payload": {"audio": {"audio": audio, "sample_rate": 16000, "encoding": "raw"}}}
ws.send(json.dumps(d))
elif status == STATUS_LAST_FRAME:
# 最后一帧 status 设为 2
d = {"header": {"status": 2, "app_id": self.appid},
"payload": {"audio": {"audio": audio, "sample_rate": 16000, "encoding": "raw"}}}
ws.send(json.dumps(d))
break
sleep(intervel)
threading.Thread(target=run).start()-
分帧发送:音频被切割成每帧 1280 字节的数据块。
-
状态控制 :
status字段非常关键。0通知服务器初始化识别引擎;1持续上传数据;2告诉服务器数据已结束,可以返回最终结果并关闭连接。 -
Base64 编码:PCM 原始二进制数据必须转为 Base64 字符串才能放入 JSON 结构中。
3、识别结果解析
讯飞返回的结果是分段的 JSON 字符串,且核心识别文本被二次 Base64 编码在 payload.result.text 字段中。
核心代码如下:
def on_message(self, ws, message):
msg_dict = json.loads(message)
code = msg_dict["header"]["code"]
if code != 0:
self.error_detail = msg_dict["header"].get("message", "")
ws.close()
else:
payload = msg_dict.get("payload")
if payload:
# 1. 提取 Base64 编码的 result 文本
text_base64 = payload.get("result", {}).get("text", "")
if text_base64:
# 2. 解码 Base64 得到原始 JSON 字节流,转为 utf8
text_json = json.loads(str(base64.b64decode(text_base64), "utf8"))
# 3. 遍历 ws (words) 结构拼接识别出的汉字
result = ''
for i in text_json.get('ws', []):
for j in i.get("cw", []):
result += j.get("w", "")
self.result += result # 累加实时识别结果
# 如果 status 为 2,表示服务器已处理完最后一帧
if msg_dict["header"]["status"] == 2:
ws.close()-
多层级解构 :讯飞返回的
ws结构是为了支持显示词语的置信度和时间戳。我们在代码中通过双重循环ws -> cw -> w提取最纯粹的文本内容。 -
增量拼接 :流式识别中,服务器会多次推送结果,代码使用
self.result += result将每一段识别出的文字拼成完整的句子。 -
异常处理 :
code != 0表示识别过程中出现错误(如 API 次数耗尽、音频格式错误等),此时需要捕获错误信息并强制关闭 WebSocket 避免死循环。
六、Docker容器化部署
1、构建镜像并启动
在该目录下执行构建镜像(首次需要):
docker-compose build启动服务:
docker-compose up -d
查看日志:
docker logs -f xunfei-service-xunfei-service-1-
项目名 (
xunfei-service) : 通常是你存放docker-compose.yml文件的目录名称 。如果你的文件夹叫xunfei-service,Docker Compose 就会默认将其作为项目前缀。 -
服务名 (
xunfei-service) : 这是在docker-compose.yml文件内部定义的。在services:层级下,你给这个 API 服务起的名字。 -
编号 (
1) : 这是容器的实例编号。因为 Docker Compose 支持横向扩展(Scale),第一个启动的实例编号就是1。
💡容器名称的由来
当你使用 docker-compose up -d 启动服务时,Docker Compose 会自动给容器命名:
<project-name>-<service-name>-<number>
project-name: 默认为当前目录名(xunfei-service)
service-name: docker-compose.yml 中定义的服务名(xunfei-service)
number: 实例编号(1)
所以容器全名是:xunfei-service-xunfei-service-1
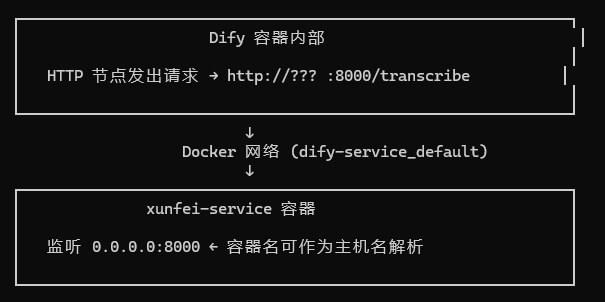
💡为什么使用容器名而不是localhost?
Dify 的 HTTP 节点在 Dify 容器内部运行,不是在宿主机
localhost 或 127.0.0.1 指向的是 Dify 容器自己,不是宿主机
Docker 网络中,容器名会自动解析为容器 IP(内置 DNS)
所以必须使用容器名作为主机名
Ctrl+C退出日志。
2、验证服务状态
检查容器运行状态:
docker ps | grep xunfei看到状态为"Up"即可。

测试健康检查端点:
curl http://localhost:8000/health预期输出:{"status": "ok"}。

3、网络配置验证
验证 xunfei 容器是否在 dify 网络中:
docker network inspect dify-service_default --format="{{range .Containers}}{{.Name}}: {{.IPv4Address}}{{\"\n\"}}{{end}}"
应该看到 xunfei-service-xunfei-service-1 在列表中。
七、Dify工作流配置
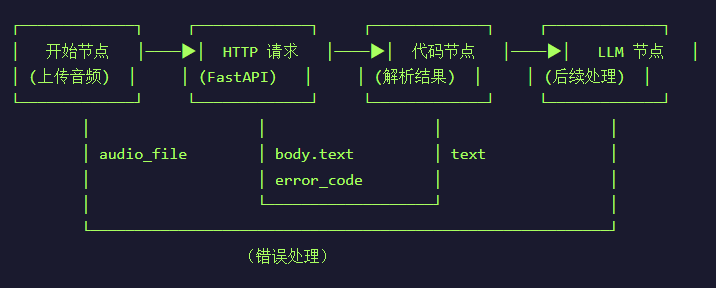
完整的Dify工作流节点如下图所示:

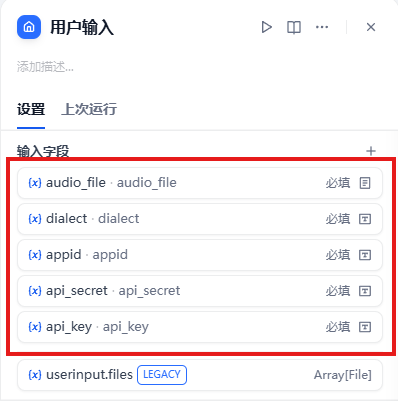
1、用户输入
用户输入内容包括audio_file音频文件(本地或URL),dialect方言设置(讯飞API默认为mulacc),应用标识appid,API签名密钥api_secret,API调用密钥api_key。
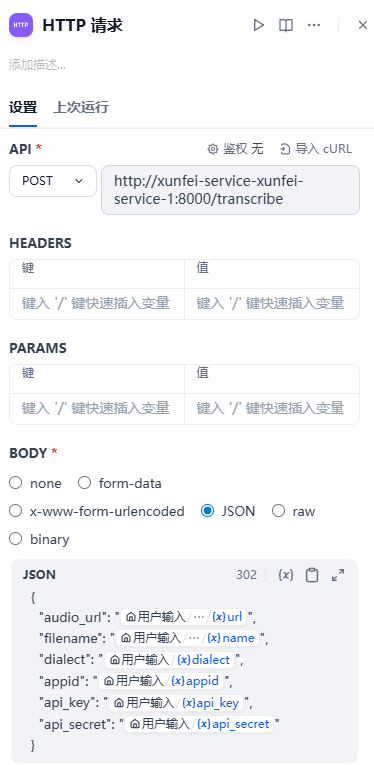
2、HTTP请求
设置POST请求方法,URL如下:
http://xunfei-service-xunfei-service-1:8000/transcribe-
http://: 协议头。虽然讯飞后端是对接 WebSocket (wss://),但你的app.py作为一个中间层代理,是通过 FastAPI 暴露的 HTTP 接口。 -
xunfei-service-xunfei-service-1:如前所述,由docker-compose.yml中的服务名和项目目录名自动生成。作为内网域名,指引请求发送到运行识别程序的那个特定容器。 -
:8000:在app.py的末尾uvicorn.run(app, host="0.0.0.0", port=8000)中定义,这是 FastAPI 服务监听的端口。 -
/transcribe:在app.py中通过装饰器@app.post("/transcribe")定义。指定调用语音转录的逻辑路由。
默认Content-Type为application/json,Headers和Params不填,如图所示配置JOSN Body。
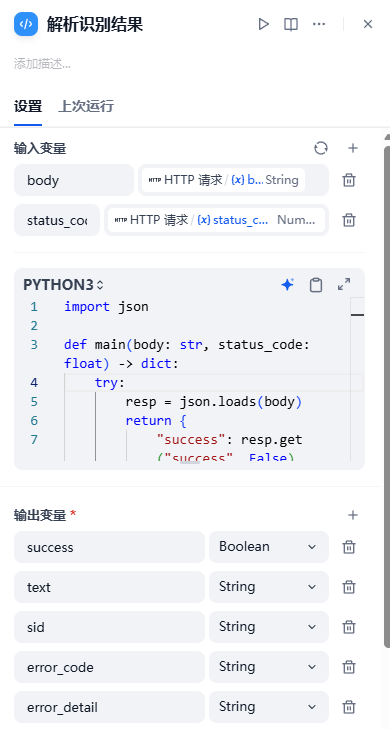
3、解析识别结果
输入变量为HTTP请求的输出body和status_code,输出变量要和代码中的return一样。
代码如下:
import json
def main(body: str, status_code: float) -> dict:
try:
resp = json.loads(body)
return {
"success": resp.get("success", False),
"text": resp.get("text", ""),
"sid": resp.get("sid", ""),
"error_code": resp.get("error_code", ""),
"error_detail": resp.get("error_detail", "")
}
except Exception as e:
return {
"success": False,
"text": "",
"sid": "",
"error_code": "parse_error",
"error_detail": str(e)
}
4、LLM信息提取
设置提示词解析语音识别的结果,提取关键信息用于后续分析。
八、测试与调试
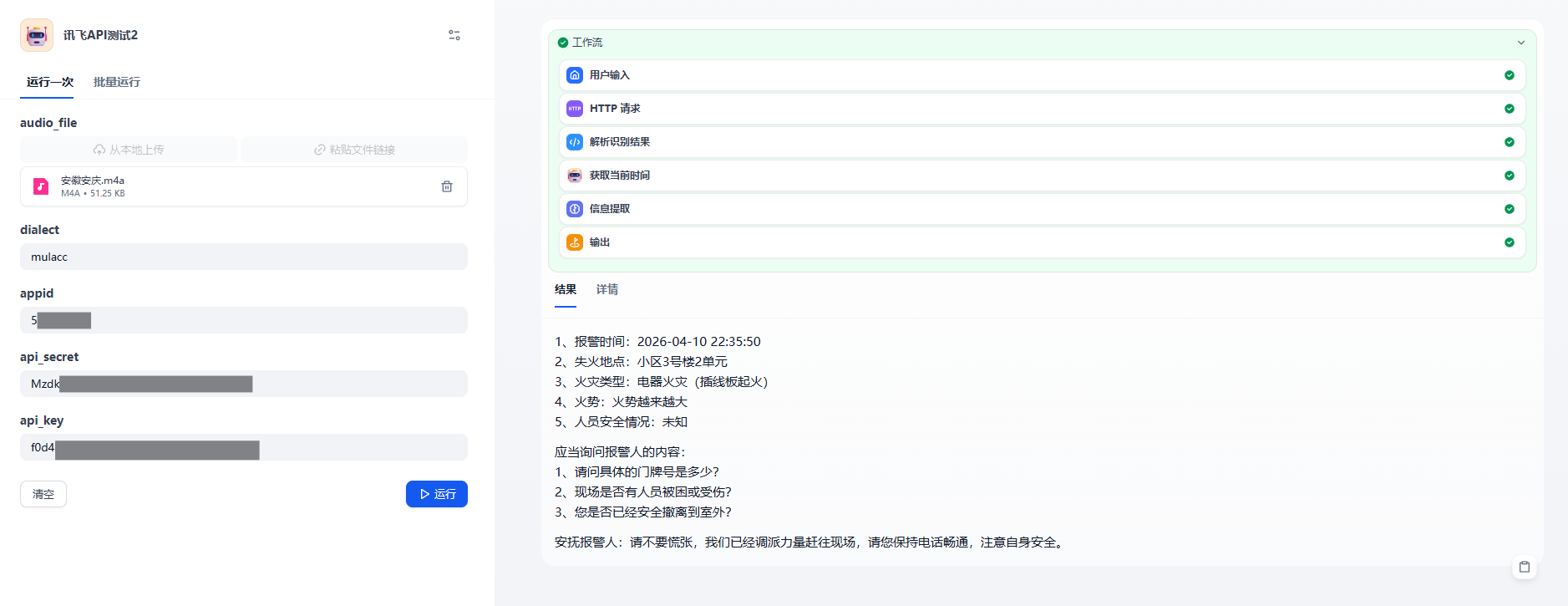
笔者实现的是上传火警报警通话,通过工作流识别报警信息并提取关键要素,分析报警人没有提供说明关键信息并指导接警员进行下一步的询问。
附录:完整代码
app.py完整代码如下:
# -*- coding:utf-8 -*-
import io
import os
import uuid
import json
import base64
import hashlib
import hmac
import ssl
import threading
import logging
from datetime import datetime
from time import mktime, sleep
from wsgiref.handlers import format_date_time
from urllib.parse import urlencode
import requests
import websocket
from pydub import AudioSegment
from fastapi import FastAPI
from pydantic import BaseModel
from typing import Optional
# ==================== 配置区域 ====================
# 讯飞方言识别接口(华北一)
HOST = "iat.cn-huabei-1.xf-yun.com"
URL = "wss://iat.cn-huabei-1.xf-yun.com/v1"
PAGE_PATH = "/v1"
# 帧状态标识
STATUS_FIRST_FRAME = 0
STATUS_CONTINUE_FRAME = 1
STATUS_LAST_FRAME = 2
# 临时文件存储目录
TEMP_PCM_DIR = "temp_pcm_files"
if not os.path.exists(TEMP_PCM_DIR):
os.makedirs(TEMP_PCM_DIR)
# 设置 logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
app = FastAPI(
title="讯飞语音识别服务",
description="基于讯飞官方 demo 的语音识别 API,支持方言识别",
version="1.0.0"
)
# ==================== 请求/响应模型 ====================
class SpeechRequest(BaseModel):
"""语音识别请求模型"""
audio_url: str # 音频文件 URL(Dify 文件下载链接)
filename: Optional[str] = "audio.m4a"
dialect: Optional[str] = "mulacc"
appid: Optional[str] = "xxx"(填写自己的APPID)
api_key: Optional[str] = "xxx"(填写自己的APIKEY)
api_secret: Optional[str] = "xxx"(填写自己的APISECRET)
class SpeechResponse(BaseModel):
"""语音识别响应模型"""
success: bool
text: str = ""
sid: str = ""
error_code: str = ""
error_detail: str = ""
# ==================== 音频转换类 ====================
class AudioConverter:
"""音频下载和转换类"""
def __init__(self, sample_rate=16000, channels=1, sample_width=2):
self.sample_rate = sample_rate
self.channels = channels
self.sample_width = sample_width
# Dify 存储目录(通过 volume 挂载)
self.dify_storage = "/app/dify-storage/upload_files"# 请替换为你的Dify存储路径
def _extract_file_id(self, audio_url: str) -> str:
"""从 Dify 文件 URL 中提取文件 ID"""
# URL 格式:/files/{tenant_id}/{file_id}.{ext}
parts = audio_url.split('/')
if len(parts) >= 4 and parts[1] == 'files':
tenant_id = parts[2]
# 提取文件 ID(去掉查询参数)
file_part = parts[3].split('?')[0]
return f"{tenant_id}/{file_part}"
return None
def _read_from_storage(self, file_id: str) -> bytes:
"""从 Dify 存储目录读取文件"""
file_path = os.path.join(self.dify_storage, file_id)
logger.info(f"尝试从存储目录读取:{file_path}")
if os.path.exists(file_path):
with open(file_path, 'rb') as f:
return f.read()
return None
def download_and_convert(self, audio_url: str) -> str:
"""
下载或读取音频并转换为 PCM,保存到本地,返回文件路径
"""
audio_data = None
# 1. 首先尝试从 Dify 存储目录直接读取
if audio_url.startswith('/files/'):
file_id = self._extract_file_id(audio_url)
if file_id:
audio_data = self._read_from_storage(file_id)
if audio_data:
logger.info(f"成功从存储目录读取文件:{file_id}")
# 2. 如果存储目录读取失败,尝试 HTTP 下载
if audio_data is None:
if audio_url.startswith('/files/'):
# 尝试多个可能的 Dify API 地址
base_urls = [
'http://your-dify-nginx:80',# 请替换为你的Dify Nginx地址
'http://your-dify-api:5001',# 请替换为你的Dify API地址
]
full_url = None
for base_url in base_urls:
try:
test_url = f"{base_url}{audio_url}"
logger.info(f"尝试从 {test_url} 下载")
resp = requests.get(test_url, timeout=10)
if resp.status_code == 200 and len(resp.content) > 0:
full_url = test_url
audio_data = resp.content
logger.info(f"成功从 {base_url} 下载")
break
except Exception as e:
logger.warning(f"{base_url} 失败:{e}")
continue
if full_url is None and audio_data is None:
raise RuntimeError("无法从任何 Dify 地址下载文件")
else:
full_url = audio_url
logger.info(f"正在从 URL 下载音频:{full_url}")
response = requests.get(full_url, timeout=30)
response.raise_for_status()
audio_data = response.content
try:
# 3. 使用 pydub 转码
logger.info("使用 pydub 转码...")
audio = AudioSegment.from_file(io.BytesIO(audio_data))
# 标准化为 16k/16bit/单声道
audio = audio.set_frame_rate(self.sample_rate) \
.set_channels(self.channels) \
.set_sample_width(self.sample_width)
# 4. 保存为本地 PCM 文件
file_name = f"{uuid.uuid4()}.pcm"
file_path = os.path.join(TEMP_PCM_DIR, file_name)
# 导出为原始 raw 数据 (PCM)
with open(file_path, "wb") as f:
f.write(audio.raw_data)
logger.info(f"音频已保存至本地:{file_path}")
return file_path
except Exception as e:
logger.error(f"转换流程失败:{e}")
raise RuntimeError(f"音频处理失败:{str(e)}")
# ==================== 讯飞 WebSocket 参数类 ====================
class Ws_Param(object):
"""讯飞 WebSocket 鉴权参数类 - 参考官方 demo"""
def __init__(self, APPID, APIKey, APISecret, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
# 讯飞方言识别参数(官方 demo)
self.iat_params = {
"domain": "slm",
"language": "zh_cn",
"accent": "mulacc",
"result": {
"encoding": "utf8",
"compress": "raw",
"format": "json"
}
}
def create_url(self):
"""生成鉴权 URL - 参考官方 demo"""
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
signature_origin = "host: " + HOST + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + PAGE_PATH + " " + "HTTP/1.1"
signature_sha = hmac.new(
self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256
).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = 'api_key="%s", algorithm="%s", headers="%s", signature="%s"' % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha
)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
v = {
"authorization": authorization,
"date": date,
"host": HOST
}
url = URL + '?' + urlencode(v)
logger.info(f'websocket url: {url}')
return url
# ==================== 语音识别类 ====================
class XunfeiASR:
"""讯飞语音识别类 - 参考官方 demo"""
def __init__(self, appid, api_key, api_secret, pcm_file):
self.appid = appid
self.api_key = api_key
self.api_secret = api_secret
self.pcm_file = pcm_file
self.result = ""
self.sid = ""
self.code = ""
self.error_detail = ""
self.done = threading.Event()
self.ws = None
self.wsParam = None
def on_message(self, ws, message):
"""收到 websocket 消息的处理 - 参考官方 demo"""
message = json.loads(message)
code = message["header"]["code"]
status = message["header"]["status"]
if code != 0:
logger.error(f"请求错误:{code}")
self.code = str(code)
self.error_detail = message["header"].get("message", "")
ws.close()
else:
payload = message.get("payload")
if payload:
text = payload.get("result", {}).get("text", "")
if text:
text_json = json.loads(str(base64.b64decode(text), "utf8"))
text_ws = text_json.get('ws', [])
result = ''
for i in text_ws:
for j in i.get("cw", []):
w = j.get("w", "")
result += w
self.result += result
logger.info(f"识别结果:{result}")
if status == 2:
ws.close()
def on_error(self, ws, error):
"""收到 websocket 错误的处理 - 参考官方 demo"""
logger.error(f"### error: {error}")
self.code = "error"
self.error_detail = str(error)
self.done.set()
def on_close(self, ws, close_status_code, close_msg):
"""收到 websocket 关闭的处理 - 参考官方 demo"""
logger.info(f"### closed ###")
self.done.set()
def on_open(self, ws):
"""收到 websocket 连接建立的处理 - 参考官方 demo"""
logger.info("WebSocket 连接已建立,开始发送音频数据...")
self.ws = ws
def run(*args):
frameSize = 1280 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔 (单位:s)
status = STATUS_FIRST_FRAME
with open(self.pcm_file, "rb") as fp:
while True:
buf = fp.read(frameSize)
audio = str(base64.b64encode(buf), 'utf-8')
# 文件结束
if not audio:
status = STATUS_LAST_FRAME
# 第一帧
if status == STATUS_FIRST_FRAME:
d = {
"header": {
"status": 0,
"app_id": self.appid
},
"parameter": {
"iat": self.wsParam.iat_params
},
"payload": {
"audio": {
"audio": audio,
"sample_rate": 16000,
"encoding": "raw"
}
}
}
ws.send(json.dumps(d))
status = STATUS_CONTINUE_FRAME
# 中间帧
elif status == STATUS_CONTINUE_FRAME:
d = {
"header": {"status": 1, "app_id": self.appid},
"payload": {
"audio": {
"audio": audio,
"sample_rate": 16000,
"encoding": "raw"
}
}
}
ws.send(json.dumps(d))
# 最后一帧
elif status == STATUS_LAST_FRAME:
d = {
"header": {"status": 2, "app_id": self.appid},
"payload": {
"audio": {
"audio": audio,
"sample_rate": 16000,
"encoding": "raw"
}
}
}
ws.send(json.dumps(d))
break
sleep(intervel)
threading.Thread(target=run).start()
def recognize(self):
"""执行识别 - 参考官方 demo"""
try:
# 创建 WebSocket 参数
self.wsParam = Ws_Param(
APPID=self.appid,
APIKey=self.api_key,
APISecret=self.api_secret,
AudioFile=self.pcm_file
)
# 生成 URL
ws_url = self.wsParam.create_url()
# 创建 WebSocket 连接
websocket.enableTrace(False)
ws = websocket.WebSocketApp(
ws_url,
on_message=self.on_message,
on_error=self.on_error,
on_close=self.on_close
)
ws.on_open = self.on_open
# 运行
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
# 返回结果
if self.code:
return {
"success": False,
"text": "",
"sid": self.sid,
"error_code": self.code,
"error_detail": self.error_detail
}
else:
return {
"success": True,
"text": self.result,
"sid": self.sid,
"error_code": "",
"error_detail": ""
}
except Exception as e:
logger.error(f"识别异常:{e}")
import traceback
traceback.print_exc()
return {
"success": False,
"text": "",
"sid": "",
"error_code": "exception",
"error_detail": str(e)
}
# ==================== API 端点 ====================
@app.post("/transcribe", response_model=SpeechResponse)
async def transcribe(req: SpeechRequest):
"""
语音转文字接口
完整流程:
1. 接收 Dify 传来的音频 URL
2. 下载并转换为 16k/16bit/单声道 PCM
3. 保存到本地临时文件
4. 通过讯飞 WebSocket API 识别
5. 返回 JSON 结果
"""
logger.info(f"收到转录请求:filename={req.filename}, dialect={req.dialect}, appid={req.appid}")
logger.info(f"音频 URL: {req.audio_url}")
try:
# 1. 下载并转换音频
converter = AudioConverter()
pcm_file = converter.download_and_convert(req.audio_url)
except Exception as e:
logger.error(f"音频处理失败:{e}")
return SpeechResponse(
success=False,
error_code="convert_error",
error_detail=str(e)
)
try:
# 2. 执行识别
asr = XunfeiASR(
appid=req.appid,
api_key=req.api_key,
api_secret=req.api_secret,
pcm_file=pcm_file
)
result = asr.recognize()
finally:
# 3. 清理临时文件
try:
os.unlink(pcm_file)
logger.info(f"已删除临时文件:{pcm_file}")
except:
pass
return SpeechResponse(
success=result.get("success", False),
text=result.get("text", ""),
sid=result.get("sid", ""),
error_code=result.get("error_code", ""),
error_detail=result.get("error_detail", "")
)
@app.get("/health")
async def health():
"""健康检查"""
return {"status": "ok"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)欢迎交流!🌹🌹