
Python中SQLite数据类型的相关知识:
-
NULL - 这是SQLite中的特殊值,用来表示一个字段没有值。
-
INTEGER - 用于存储整数值。尽管SQLite允许你在整数列中存储文本,但如果需要执行数值运算,最好确保数据是整数类型。
-
REAL - 用于存储浮点数(即实数)。与INTEGER类似,尽管可以存储文本,但最好确保用于数值计算。
-
TEXT - 用于存储文本字符串。可以是任何文本数据,包括字符串、二进制数据等。
-
BLOB - 用于存储二进制对象。可以用来存储图片、音频或其他非文本数据。
解题:
这里我们的INT没有缩写,一定要INTEGER才可以

解题:
A:在 SQLite 中,SQL 语句不区分大小写。创建表格结构时,既可以使用大写字母,也可以使用小写字母,或者大小写混合。
B:在使用 SQLite 时,建立数据库连接和游标后,通常需要关闭游标和连接以释放资源。关闭游标和关闭连接的顺序是有要求的,应该先关闭游标,再关闭数据库连接。因为游标是依赖于数据库连接存在的,如果先关闭了数据库连接,游标就无法正常关闭,可能会导致资源泄漏或其他问题。
C:在 Python 中使用 sqlite3.connect() 建立数据库实例时,变量的命名方式遵循 Python 变量命名规则。变量名可以包含字母、数字和下划线,但不能以数字开头,且不能使用 Python 的关键字。
D:execute() 方法用于执行单条 SQL 语句,而 executemany() 方法用于批量执行相同结构的 SQL 语句,它接收一个 SQL 语句模板和一个参数序列,会将参数序列中的每个参数组合依次应用到 SQL 语句模板中执行,而不是用逗号分隔多条 SQL 语句。

代码解释:
with open("t.txt","w") as t1: #以写的方式打开一个叫做t.txt的文件并且命名为t1
t1.write("姓名:") #在t1里面写入姓名:
t1.write("性别:") #在t1里面写入性别:tips:
with open打开的文件会自己关闭不需要自己close
w是只写模式,会清空原文件
w+是可读可写,文件不存在则创建,存在则清空再写入
换行输出时要使用换行符\n
解题:
这里C选项没有进行换行处理所以实现不了上述的结果

import sqlite3 # 导入sqlite3库
k = sqlite3.connect('题库.db') # 连接数据库
a = k.cursor() # 创建游标
a.execute('SELECT rowid, 题目, 答案 FROM tiku ORDER BY rowid') # 执行查询语句,在查询tiku ORDER这个表的rowid, 题目, 答案这些字段,按照rowid进行升序排列
for row in ______: # 填空处
print(f"{row[1]}{row[2]}") #f"..." 是 f-string(格式化字符串),{row[1]} 会被替换成题目的内容{row[2]} 会被替换成答案的内容tips:
游标对象是a,这里的a.execute(...) 执行了查询,结果保存在游标对象 a 中
如何获取所有记录?游标对象有 .fetchall() 方法,返回所有记录的列表。
也可以循环直接迭代游标对象本身。
a.fetchmany()括号里面需填入size(具体数量)来指定数量,不能直接一次获取全部
k 是连接对象,不存在.fetchmany()和.fetchall()这些方法

tips:使用conn = sqlite3.connect('example.db')连接数据库时,如果example.db不存在,程序将新建数据库。

解题:
A:f.readline() 只读取第一行,输出第一行内容
B:f.readlines()[1] 返回第二行的内容(索引从 0 开始),而不是第一行
C:使用 open() 打开文件后,如果没有手动调用 close(),可能导致资源泄漏(除非程序立即结束或由垃圾回收关闭,但不安全)
D:with open(...) as f: 会自动在代码块结束后调用 close(),因此不需要手动 f.close()
7.

代码解析
f=open('a.txt','w') #以写的方式打开a.txt文档
f.write('测试写入') #写入内容
f.flush() #强制将缓冲区中的数据立即写入磁盘文件解题:
A:用open方式打开的文件没有使用f.close()是错误的
B:r这种形式打开文件是只读无法写入
C:这种方式打开的会自己关闭文件,完全正确
D:结束时没有f.close()所以也是不对的

解题:
未签到的同学学号记录在文件student.txt中,通过读取该文件即可查询未签到同学,已经签到的同学不用重新签到

代码解析
import numpy as np # 导入 numpy 库,简写为 np
arr = np.array([1, 2, 3, 4, 5]) # 创建一个包含 1,2,3,4,5 的一维数组
print(arr[::2].sum()) # 输出:从索引0开始,步长为2取元素,然后求和解题:
arr::2切片操作选取第0、2、4个元素(1,3,5),求和结果为9
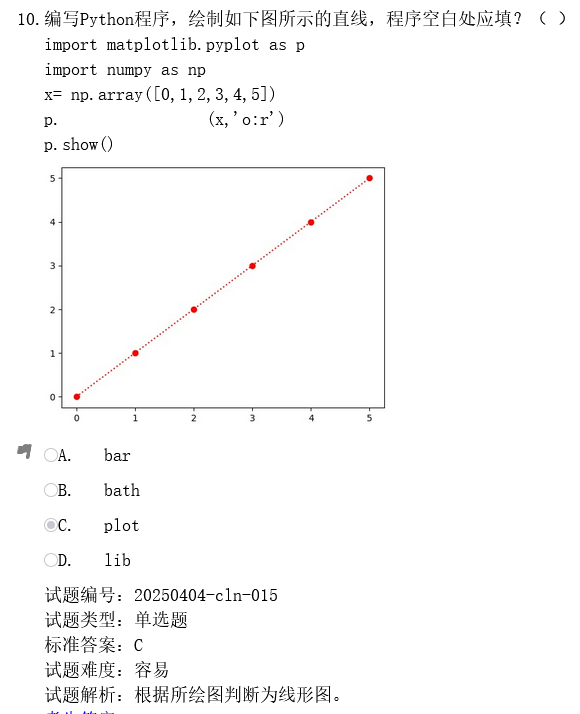
代码解析
import matplotlib.pyplot as p
import numpy as np
x= np.array([0,1,2,3,4,5])
p. (x,'o:r')
p.show() 注:这里的(x,'o:r')
'o:r' 是绘图样式字符串:
-
'o'表示圆点标记 -
':'表示虚线 -
'r'表示红色
matplotlib.pyplot相关知识:
plot表示折线图/点线图
bar表示柱状图
scatter表示散点图
hist表示直方图
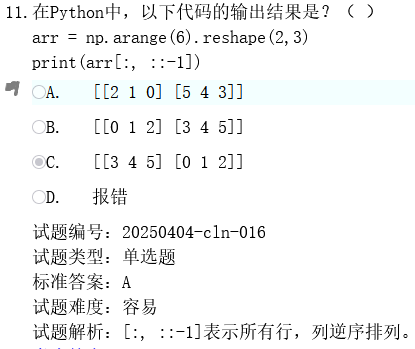
代码解析:
arr = np.arange(6).reshape(2,3)
#生成一个一维数组[0, 1, 2, 3, 4, 5],然后将一维数组转换为 2 行 3 列的二维数组
print(arr[:, ::-1])
#这是二维数组的切片,格式为 [行切片, 列切片],: 表示所有行(行不变)::-1 表示列方向从右向左取,步长为 -1(即整行倒序)解题一开始生成的是
0,1,2,3,4,5这个数组
然后重新塑性变成
\[0,1,2,
3,4,5\]
最后就是切片
arr[:, ::-1]这个可以理解为行不变,列变成倒序
得到的结果就是
-
原始行:
[0, 1, 2]→ 倒序:[2, 1, 0] -
原始行:
[3, 4, 5]→ 倒序:[5, 4, 3]
最后得到
[[2 1 0]
[5 4 3]]
12.

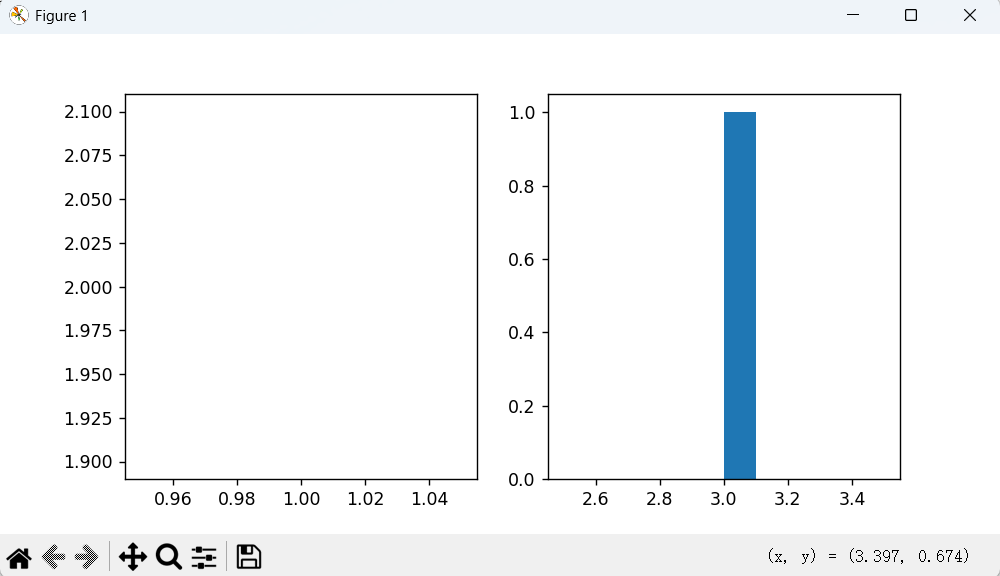
代码解析
import matplotlib.pyplot as plt
x=1;y1=2;y2=3 #定义三个标量数值
plt.figure(figsize=(8,4)) #创建一个宽 8 英寸、高 4 英寸的画布
plt.subplot(121) #121 表示:1 行、2 列、第 1 个子图,等同于 plt.subplot(1, 2, 1)
plt.plot(x, y1) #plot() 期望接收序列(如列表、数组)或多个点的坐标
plt.subplot(122) #1 行、2 列、第 2 个子图
plt.hist(y2) #hist() 期望接收一组数据(列表或数组),用于统计频率分布
plt.show() #显示图形 实际运行效果
-
左子图:空白(只有一个点且没有标记)
-
右子图:一个柱子,横坐标 3,纵坐标 1
结果如下

tips:
创建对象的语法是:类名(参数1, 参数2, ...),如 Car("Toyota", "Corolla", 2025),
必须用变量接收,即 car = Car(...)

代码解析
class Animal: #定义一个Animal的类
def sound(self): #定义sound方法
return "叫声" #返回参数
class Dog(Animal): #定义一个Dog的子类(Animal的子类),继承了父类的所有属性和方法
def sound(self): #定义sound方法
return "汪汪"
a = Animal() #调用Animal类
d = Dog() #调用Dog类解题
这里的考察是子类是否会继承父类的时出现相同方法的继承性
子类Dog重写了父类的sound()方法,调用d.sound()时会优先使用子类的版本,输出"汪汪"

解题:
需要使用 self.battery 才能访问实例属性,
赋值语句使用 = 而非 ==,
必须传入 percent 参数
A:错在定义方法时没有self
B:正确答案
C:没有用self.battery 才能访问实例属性
D:==是判断左右是否相等

解题:
首先在类里面定义方法需要在括号写入(self)这里我们发现A,B不满足
其次是调用类里面的属性,需要用self.属性名调用
综合上述,c是正确答案

在python中关于json的相关知识
|---------------------|------|---------------------|-----------------|
| 方法 | 操作对象 | 方向 | 用途 |
| json.dump(obj,file) | 文件 | Python → JSON(写入文件) | 保存数据到文件 |
| json.load(file) | 文件 | JSON → Python(读取文件) | 从文件加载数据 |
| json.dumps(obj) | 字符串 | Python → JSON 字符串 | 网络传输、存数据库文本字段 |
| json.loads(str) | 字符串 | JSON 字符串 → Python | 解析接收到的 JSON 字符串 |
总结:(记忆技巧)
出现s就是和字符串有关
dump是python变json
load是json变python


代码解析
import csv #导入csv库
total_visitors = [] #创建空列表
with open('tourist_data.csv', 'r') as f:
reader = csv.reader(f)
#创建csv读取器,reader 是一个可迭代对象,每次迭代返回一行数据(列表形式)
for row in reader: #遍历每一行
total = sum([int(num) for num in row[1:]]) #计算游客总数,从第二个元素开始按行累加
total_visitors.append(total) # 将每行的总和添加到列表
print(total_visitors) #输出结果这里涉及到一个绝对路径和相对路径的表达
tips:

代码解析
scores = [[80, 85, 90], [75, 80, 88], [92, 95, 98]]
average_scores = [] #创建空列表,用于存储每个学生的平均分
for i in range(len(scores)): #外层循环:遍历每个学生
total = 0 #初始化总分
for j in range(len(scores[i])): #内层循环:遍历该学生的每门成绩
total += scores[i][j] #累加该学生的所有成绩
avg = total / len(scores[i]) #计算平均值
average_scores.append(avg) #存储结果到空列表中
print(average_scores) #输出结果scores 是一个二维列表,包含三个子列表,每个子列表代表一个学生的成绩
average_scores 是一个空列表,用于存储每个学生的平均成绩。
外层循环 for i in range(len(scores)) 遍历每个学生(即 scores 的每个子列表)。
内层循环 for j in range(len(scoresi)) 遍历当前学生的所有成绩,并累加到 total。
计算平均成绩 avg = total / len(scoresi),并将 avg 添加到 average_scores。
最后打印 average_scores。注意除是实除,需要保留小数

解题:
关于csv文件的相关知识
CSV 文件可存储一维和二维数据,A 错误;
CSV 文件每一行数据通常包含相同数量的元素,以保证数据结构的一致性,B 正确;
CSV 文件扩展名一般为.csv,随意修改可能导致相关程序无法正确识别,C 错误;
CSV 文件数据之间常用逗号分隔,但也可以指定其他分隔符,D 错误 。

关于tkinter的相关知识
pack 布局管理器会按照添加控件的顺序,默认从左到右、从上到下排列控件。
grid 布局是将控件放置在一个二维的网格中。
place 布局是通过指定控件的精确坐标来放置控件。
在tkinter不存在middle这种布局

解题:
A:在 tkinter 中,tk.Tk() 用于创建主窗口(即根窗口)。
-
B:
tk.Window()不存在于标准 tkinter 中。 -
C:
tk.MainWindow()也不存在,主窗口类就是Tk。 -
D:
tk.Frame()用于创建框架(容器),不是主窗口

解题:
place()方法用来指定组件的绝对位置;
grid()方法是按照行、列的方式摆放组件;
pack()方法既可实现水平排列,也可实现垂直排列。
geometry() 方法可以以字符串的形式设置窗口的宽度、高度和位置。

解题:
一维数据由对等关系的有序或者无序数据构成

mainloop()方法启动了事件循环,这是任何Tkinter应用程序的主要事件循环。
它保持应用程序活动并响应各种GUI事件,例如按钮点击和键盘按键。












参考程序:
class Box():
def __init__(self,l,w,h):
self.l=l
self.w=w
self.h=h
def a4(self):
return float((self.l*self.w*2+self.l*self.h*2+self.w*self.h*2)/600)
def chang(self):
return (self.l+self.w)*4+self.h*4
a,b,c=input('输入箱子的长宽高(cm):').split()
a=float(a)
b=float(b)
c=float(c)
d=Box(a,b,c)
print("共需要铁丝:%dcm,A4纸:%0.2f张。"%(d.chang(),d.a4()))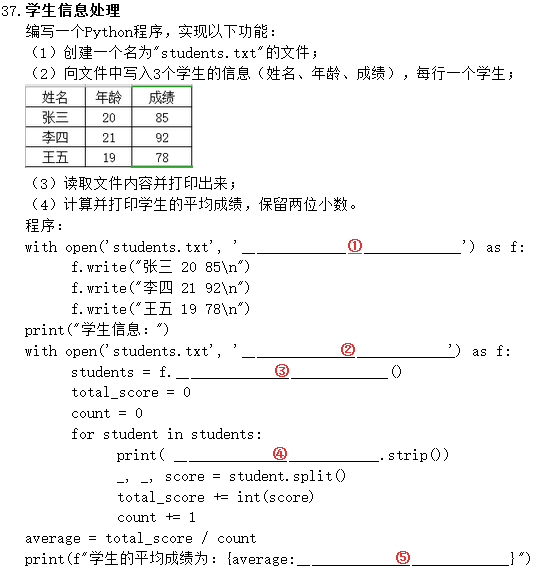

参考程序:
# 写入学生信息到文件
with open('students.txt', 'w') as f:
f.write("张三 20 85\n")
f.write("李四 21 92\n")
f.write("王五 19 78\n")
# 读取文件内容并打印
print("学生信息:")
with open('students.txt', 'r') as f:
students = f.readlines()
total_score = 0
count = 0
for student in students:
print(student.strip())
_, _, score = student.split()
total_score += int(score)
count += 1
# 计算并打印平均成绩
average = total_score / count
print(f"学生的平均成绩为:{average:.2f}") 

import sqlite3
# 连接数据库
conn = sqlite3.connect('gym.db')
# 创建表
conn.execute('''CREATE TABLE IF NOT EXISTS member
(id TEXT PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
days INTEGER);''')
# 插入一条数据
conn.execute("INSERT INTO member VALUES('M001', '小红', 25)")
# 查询剩余天数小于30天的会员
cur = conn.cursor()
cur.execute("SELECT * FROM member WHERE days < 30 ")
for row in cur.fetchall():
print("会员", row[1], "剩余天数不足,请尽快续费!(剩余",row[2], "天)")
# 提交并关闭
conn.commit()
conn.close()