Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第五章 Functions(函数)
程序员在 Python 中使用的第一个组织工具就是函数。与其他编程语言一样,函数可使你将大型程序分解为更小、更简单的组成部分,并为每个部分赋予名称以表示其功能。这有助于提高代码的可读性,使其更加易于理解。同时,函数还支持代码的复用和重构。
Python 中的函数拥有多种附加特性,这些特性使程序员的编程工作变得更加轻松。其中一些特性与其他编程语言中的功能相似,但许多特性是 Python 所独有的。这些附加功能能够使函数的接口更加清晰明了。它们能够消除冗余信息,强化调用者的意图。此外,它们还能显著减少那些难以发现的细微错误。
Item 30:请知悉函数参数是可以被修改的
Python 并不支持指针类型(除了与 C 进行接口操作之外;详见 Item 95:"考虑使用 c 类型以快速与原生库集成")。但传递给函数的参数均是通过引用传递的。对于简单类型,如整型与字符串,参数似乎是以值传递的,因为它们是不可变的对象。但更为复杂的对象在传递给其他函数时则有可能被修改,无论调用者的意图如何。例如,如果我向另一个函数传递一个列表,那么该函数便具备对传入参数调用修改方法的能力:
def my_func(items):
items.append(4)
x = [1, 2, 3]
my_func(x)
print(x) # 4 is now in the list
>>>
[1, 2, 3, 4]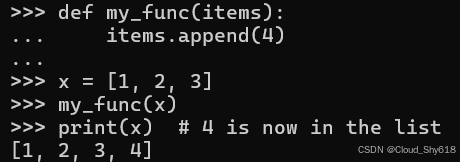
在此情况下,你无法像对待 C 风格的指针类型那样,在调用函数内部替换变量 x 的原始值。但你可以对分配给 x 的列表进行修改。同样地,当一个变量被赋值给另一个变量时,它实际上存储了对同一底层数据结构的引用或别名。因此,通过使用看似独立的变量来调用函数,实际上可以实现对原始值的修改:
a = [7, 6, 5]
b = a # Creates an alias
my_func(b)
print(a) # 4 is now in the list
>>>
[7, 6, 5, 4]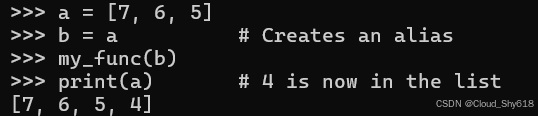
对于列表和字典,你可以通过传递容器的副本来解决此问题,以使您免受函数行为的影响。在这里,我使用没有起始或结束索引的切片操作创建一个副本(请参阅 Item 14:"了解如何对序列进行切片"):
def capitalize_items(items):
for i in range(len(items)):
items[i] = items[i].capitalize()
my_items = ["hello", "world"]
items_copy = my_items[:] # Creates a copy
capitalize_items(items_copy)
print(items_copy)
>>>
['Hello', 'World']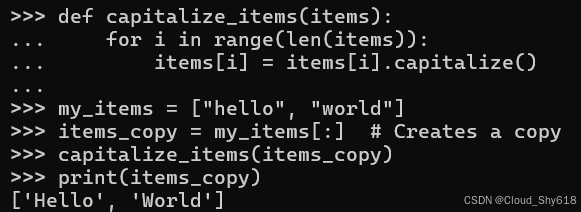
内置的字典类型提供了一个专门用于此目的的 copy 方法:
def concat_pairs(items):
for key in items:
items[key] = f"{key}={items[key]}"
my_pairs = {"foo": 1, "bar": 2}
pairs_copy = my_pairs.copy() # Creates a copy
concat_pairs(pairs_copy)
print(pairs_copy)
>>>
{'foo': 'foo=1', 'bar': 'bar=2'}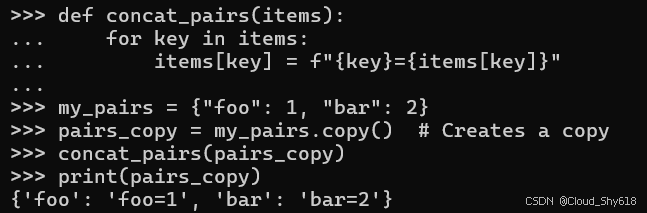
用户定义类(参见 Item 29:"构建类而非深度嵌套字典、列表和元组")也可被调用者进行修改。它们任何内部属性的访问或赋值均可由传递给它们的任何函数完成(参见 Item 55:"优先使用公共属性而非私有属性"):
class MyClass:
def __init__(self, value):
self.value = value
x = MyClass(10)
def my_func(obj):
obj.value = 20 # Modifies the object
my_func(x)
print(x.value)
>>>
20
在实现一个会被他人调用的函数时,不应修改任何所提供的可变值,除非这种行为在函数名称、参数名称或文档中明确有所提及。此外,你或许还应当为接收到的所有参数进行防御性复制,以避免与迭代相关的各种潜在问题(请参阅 Item 21:"在迭代参数时应保持谨慎"和 Item 22:"在迭代过程中切勿修改容器;应使用复制或缓存取而代之")。
在调用函数时,应谨慎处理可变参数的传递,因为你的数据可能会因此被修改,这可能导致难以察觉的漏洞。对于你控制的复杂对象而言,添加有助于创建防御性副本的辅助函数和方法可能颇为有益。此外,你还可以采用更具功能性的风格,尝试利用不可变对象和纯函数(参见 Item 56:"优先使用 dataclasses 来创建不可变对象")。
注意:
- 在 Python 中,参数是通过引用传递的,这意味着它们的属性可以通过接收函数和方法进行修改。
- 函数应明确说明(通过命名和文档说明)它们何时会修改输入参数,并避免在其他情况下对参数进行修改。
- 创建从输入中获取的集合和对象的副本是一种可靠的方法,有助于确保你的函数不会在不经意间修改数据。
Item 31:返回专用结果对象,而非要求函数调用者自行解包超过三个变量
这种解包语法(见 Item 5:"优先采用多重赋值解包而非索引法")的一个影响是它使得 Python 函数似乎能够返回不止一个值。例如,假设我正试图为一群短吻鳄计算各种统计数据。给定一个长度列表,我需要计算种群中长度最小值和最大值。在此情况下,我通过一个看似返回两个值的单一函数来完成这一操作:
def get_stats(numbers):
minimum = min(numbers)
maximum = max(numbers)
return minimum, maximum
lengths = [63, 73, 72, 60, 67, 66, 71, 61, 72, 70]
minimum, maximum = get_stats(lengths) # Two return values
print(f"Min: {minimum}, Max: {maximum}")
>>>
Min: 60, Max: 73
其工作原理是多个值被一同以一对元素的元组形式返回。调用代码随后通过指定两个变量来解包所返回的元组。在此示例中,我使用一个更为简单的例子来展示解包语句和多重返回函数的工作原理是相同的:
first, second = 1, 2
assert first == 1
assert second == 2
def my_function():
return 1, 2
first, second = my_function()
assert first == 1
assert second == 2使用星号表达式进行通用解包时,同样可以接收多个返回值(参见 Item 16:"优先选择通用解包而非切片")。例如,假设我需要另一个函数来计算每条鳄鱼相对于种群平均大小的大小比值。该函数会返回一个比率列表,但我可以通过使用星号表达式来获取列表中间部分的单个最长和最短项:
def get_avg_ratio(numbers):
average = sum(numbers) / len(numbers)
scaled = [x / average for x in numbers]
scaled.sort(reverse=True)
return scaled
longest, *middle, shortest = get_avg_ratio(lengths)
print(f"Longest: {longest:>4.0%}")
print(f"Shortest: {shortest:>4.0%}")
>>>
Longest: 108%
Shortest: 89%
现在,假设程序的要求有所变化,我还需确定鳄鱼的均值长度、中位数长度以及总体种群规模。我可以通过扩展 get_stats 函数来实现这一目标,使其能够同时计算这些统计数据,并将结果以元组的形式返回,供调用者进行解包:
def get_median(numbers):
count = len(numbers)
sorted_numbers = sorted(numbers)
middle = count // 2
if count % 2 == 0:
lower = sorted_numbers[middle - 1]
upper = sorted_numbers[middle]
median = (lower + upper) / 2
else:
median = sorted_numbers[middle]
return median
def get_stats_more(numbers):
minimum = min(numbers)
maximum = max(numbers)
count = len(numbers)
average = sum(numbers) / count
median = get_median(numbers)
return minimum, maximum, average, median, count
minimum, maximum, average, median, count = get_stats_more(lengths)
print(f"Min: {minimum}, Max: {maximum}")
print(f"Average: {average}, Median: {median}, Count {count}")
这段代码有两个问题。 首先,所有返回值都是数字,因此很容易意外地对它们重新排序(例如,交换平均值和中位数),这可能会导致以后难以发现的错误。使用大量返回值非常容易出错:
# Correct:
minimum, maximum, average, median, count = get_stats_more(lengths)
# Oops! Median and average swapped:
minimum, maximum, median, average, count = get_stats_more(lengths)其次,调用函数并解包值的行很长,并且可能需要以多种方式之一进行包装(由于 PEP 8 风格;请参阅 Item 2 :"遵循 PEP 8 风格指南"),这会损害可读性:
minimum, maximum, average, median, count = get_stats_more(
lengths)
minimum, maximum, average, median, count =
get_stats_more(lengths)
(minimum, maximum, average,
median, count) = get_stats_more(lengths)
(minimum, maximum, average, median, count
) = get_stats_more(lengths)为了避免这些问题,在从函数中解包多个返回值时,切勿使用超过三个变量。这些可以是来自三元组、两个变量和一个包罗万象的星号表达式的单个值,或更短的值。
如果您需要解包比这更多的返回值,那么最好定义一个轻量级类(请参阅 Item 29:"组合使用类而不是深度嵌套字典、列表和元组"和 Item 51:"首选数据类来定义轻量级类")并让您的函数返回该类的实例。在这里,我编写了 get_stats 函数的另一个版本,它返回结果对象而不是元组:
from dataclasses import dataclass
@dataclass
class Stats:
minimum: float
maximum: float
average: float
median: float
count: int
def get_stats_obj(numbers):
return Stats(
minimum=min(numbers),
maximum=max(numbers),
count=len(numbers),
average=sum(numbers) / count,
median=get_median(numbers),
)
result = get_stats_obj(lengths)
print(result)
>>>
Stats(minimum=60, maximum=73, average=67.5, median=68.5, count=10)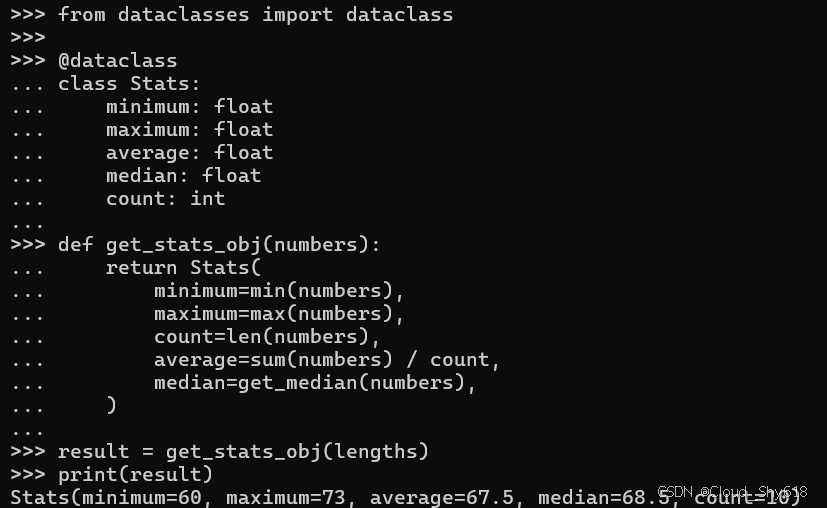
修改后的代码更清晰,不易出错,以后也更容易重构。
注意:
- 您可以让函数返回多个值,方法是将它们放入元组中并让调用者利用 Python 的解包语法。
- 函数的多个返回值也可以通过包罗万象的星号表达式来解包。
- 解包为四个或更多变量很容易出错,应该避免;相反,返回一个轻量级类的实例。
Item 32:宁愿引发异常也不愿返回任何异常
在编写实用函数时,Python 程序员倾向于为返回值 None 赋予特殊含义。在某些情况下这似乎是有意义的(参见 Item 26:"优先使用 get 而不是 in 操作符和 Key Error 来处理丢失的字典键")。例如,假设我想要一个将一个数字除以另一个数字的辅助函数。在除以零的情况下,返回 None 似乎很自然,因为结果是未定义的:
def careful_divide(a, b):
try:
return a / b
except ZeroDivisionError:
return None使用此函数的代码可以相应地解释返回值:
x, y = 1, 0
result = careful_divide(x, y)
if result is None:
print("Invalid inputs")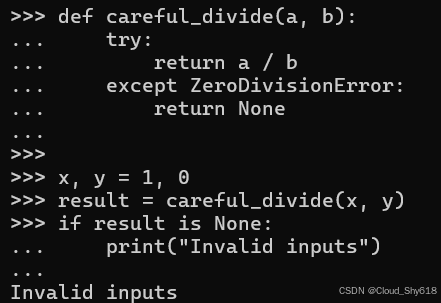
当分子为零时,careful_divide 函数会发生什么情况?如果分母不为零,则该函数返回零。问题是,当你在 if 语句等条件下评估结果时,零返回值可能会导致问题。你可能会意外地查找任何 false 值来指示错误,而不是仅查找 None(请参阅 Item 4:"编写辅助函数而不是复杂表达式"和 Item 7:"考虑简单内联逻辑的条件表达式"):
x, y = 0, 5
result = careful_divide(x, y)
if not result: # Changed
print("Invalid inputs") # This runs! But shouldn't
>>>
Invalid inputs
当 None 具有特殊含义时,这种对 False 等效返回值的误解是 Python 代码中的常见错误。这就是为什么从careful_divide 之类的函数返回 None 容易出错的原因。有两种方法可以减少出现此类错误的可能性。
第一种方法是将返回值拆分为二元组(请参阅 Item 31)。元组的第一部分指示操作是成功还是失败。第二部分是计算的实际结果:
def careful_divide(a, b):
try:
return True, a / b
except ZeroDivisionError:
return False, None该函数的调用者必须解包元组。这迫使他们考虑元组的状态部分,而不仅仅是查看除法的结果:
success, result = careful_divide(x, y)
if not success:
print("Invalid inputs")问题是调用者可以轻松忽略元组的第一部分(使用下划线变量名称,这是未使用变量的 Python 约定)。乍一看,生成的代码并没有错,但这可能与返回 None 一样容易出错:
_, result = careful_divide(x, y)
if not result:
print("Invalid inputs")减少这些错误的第二种更好的方法是在特殊情况下永远不返回 None。相反,向调用者引发异常并让调用者处理它。在这里,我将零除错误转换为值错误,以向调用者指示输入值是错误的(有关详细信息,请参阅 Item 88:"考虑显式链接异常以澄清回溯"和 Item 121:"定义根异常以将调用者与 APIs 隔离"):
def careful_divide(a, b):
try:
return a / b
except ZeroDivisionError:
raise ValueError("Invalid inputs") # Changed调用者不再需要函数返回值的条件。相反,它可以假设返回值始终有效,并在 try 之后立即在 else 块中使用结果(有关信息,请参阅 Item 80:"利用 try/ except/else/finally 中的每个块"):
x, y = 5, 2
try:
result = careful_divide(x, y)
except ValueError:
print("Invalid inputs")
else:
print(f"Result is {result:.1f}")
>>>
Result is 2.5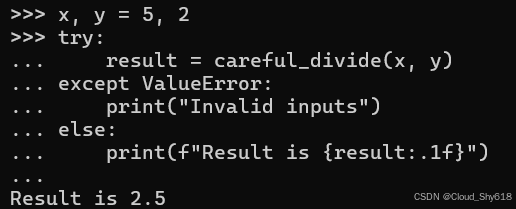
这种方法可以扩展到使用类型注释的代码(请参阅 Item 124:"通过打字考虑静态分析以消除错误" 了解背景)。 你可以指定函数的返回值始终为浮点数,因此永远不会为 None。然而,Python 的渐进式类型故意没有提供一种方法来指示异常何时成为函数接口的一部分(也称为检查异常)。相反,您必须记录异常引发行为,并期望调用者依赖该行为,以便知道他们应该计划捕获哪些异常(请参阅 Item 118:"为每个函数、类和模块编写文档字符串")。总而言之,使用类型注释和文档字符串时该函数应如下所示:
def careful_divide(a: float, b: float) -> float:
"""Divides a by b.
Raises:
ValueError: When the inputs cannot be divided.
"""
try:
return a / b
except ZeroDivisionError:
raise ValueError("Invalid inputs")
try:
result = careful_divide(1, 0)
except ValueError:
print("Invalid inputs") # Expected
else:
print(f"Result is {result:.1f}")
>>>
$ python3 -m mypy --strict example.py
Success: no issues found in 1 source file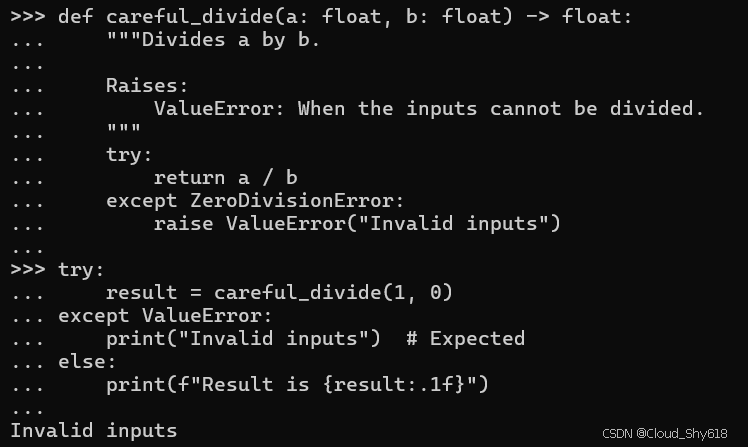
现在,输入、输出和异常行为都一目了然,调用者做错事情的可能性极低。
注意:
- 返回 None 来指示特殊含义的函数很容易出错,因为 None 和许多其他值(例如零和空字符串)在布尔表达式中计算结果为 False。
- 引发异常来指示特殊情况,而不是返回 None。期望调用代码在记录异常后能够正确处理异常。
- 类型注释可用于明确函数永远不会返回 None 值,即使在特殊情况下也是如此。