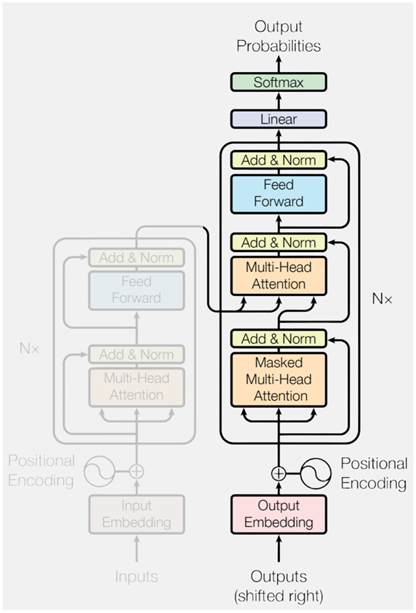
一、Seq2Seq 模型出现的问题
由于其核心依然依赖于 RNN 结构
1.计算过程无法并行,必须顺序执行,限制了训练效率和硬件资源的利用率。
2.对于超长序列,训练过程中容易出现梯度消失,难以有效建模长距离依赖关系。
二、模型结构
1.Transformer基于Attention Is All You Need这篇论文
其本质是在每一个目标位置上,显式建模该位置与源序列中各位置之间的依赖关系。
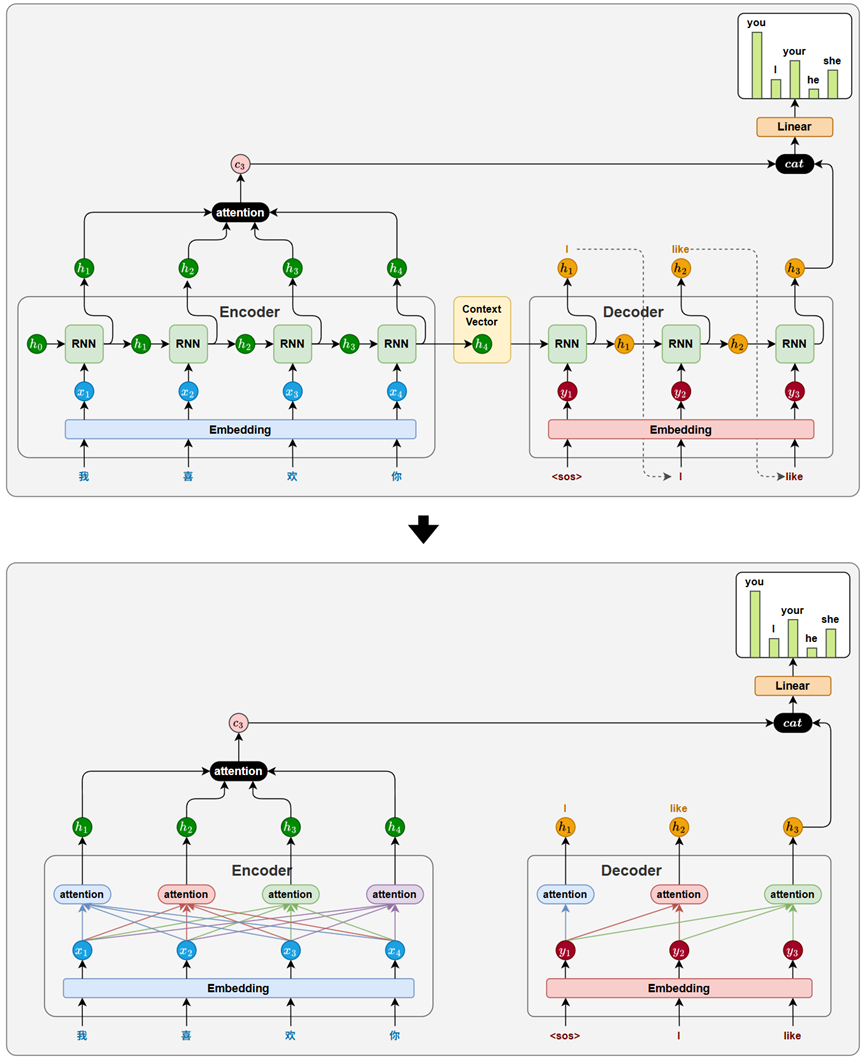
与此同时,循环神经网络(RNN)作为 Seq2Seq 模型的核心结构,其作用也在于建模序列中的依赖关系。通过隐藏状态的递归传递,RNN 使当前位置的表示能够整合前文信息,从而隐式捕捉上下文依赖。从功能角度看,RNN 与注意力机制完成的是同一类任务:建立序列中不同位置之间的依赖联系。
既然注意力机制也具备建模依赖关系的能力,那么理论上,它就可以在功能上替代 RNN。
此外,相比 RNN,注意力机制在结构上具备明显优势:无需顺序计算,便于并行处理;任意位置间可直接建立联系,更适合捕捉长距离依赖。因此,它不仅具备替代的可能,也在效率与效果上表现更优。
Transformer 模型正是在这一思路下诞生的。它摒弃了传统的循环结构,仅依靠注意力机制完成输入序列和输出序列中所有位置之间的依赖建模任务。这一结构上的彻底变革,也正是论文标题 Attention is All You Need 所体现的核心理念。
2.整体结构
与基于 RNN 的 Seq2Seq 模型一样,Transformer 的解码器采用自回归方式生成目标序列。不同之处在于,每一步的输入是此前已生成的全部词,模型会输出一个与输入长度相同的序列,但我们只取最后一个位置的结果作为当前预测。这个过程不断重复,直到生成结束标记 <eos>。
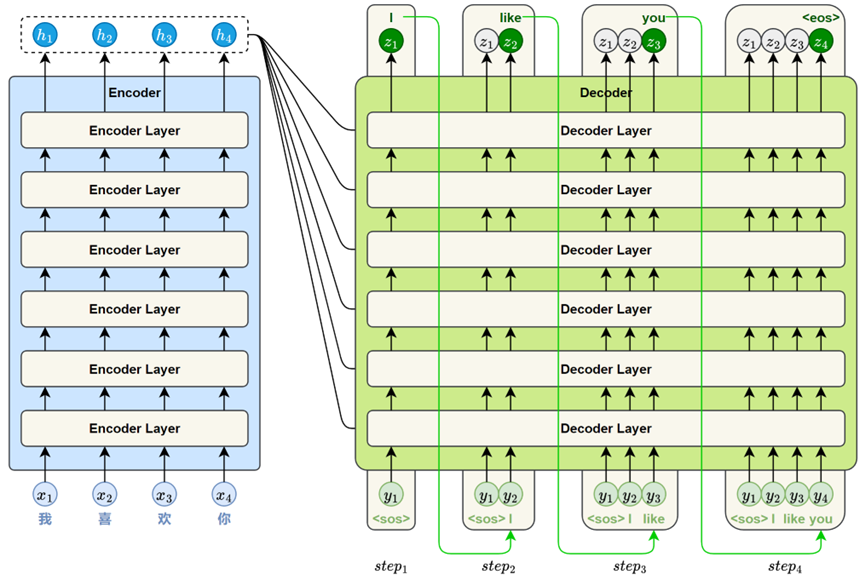
标准的 Transformer 模型通常包含 6个编码器层和 6 个解码器层。
3.编码器
每个 Encoder Layer的主要任务都是对其输入序列进行上下文建模,使每个位置的表示都能融合来自整个序列的全局信息。每个 Encoder Layer都包含两个子层(sublayer),分别是自注意力子层(Self-Attention Sublayer)和前馈神经网络子层(Feed-Forward Sublayer)。
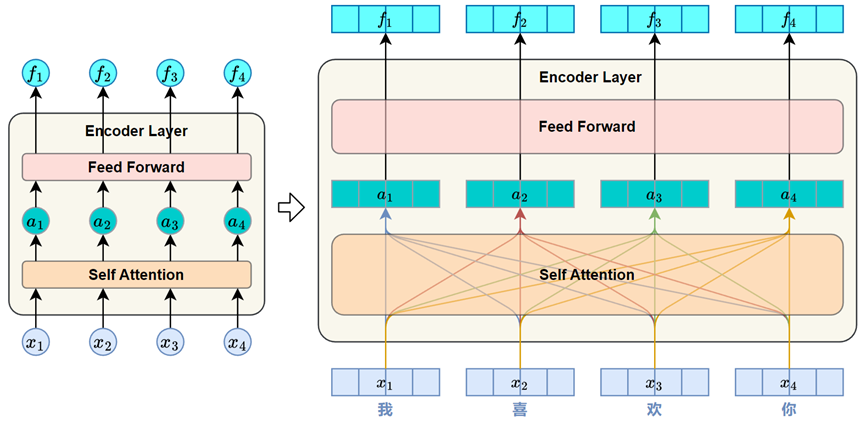
3.1 自注意力子层(Self-Attention Sublayer)
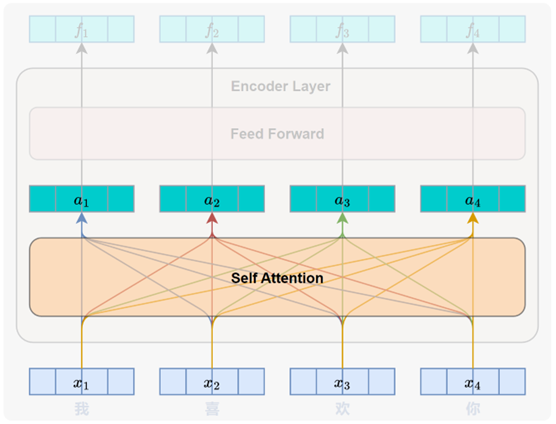
它的作用是在序列内部建立各位置之间的依赖关系,使模型能够为每个位置生成融合全局信息的表示。
计算过程:
1)Query、Key、Value向量
自注意力机制的第一步,是将输入序列中的每个位置表示映射为三个不同的向量,分别是 查询(Query)、键(Key) 和 值(Value)。
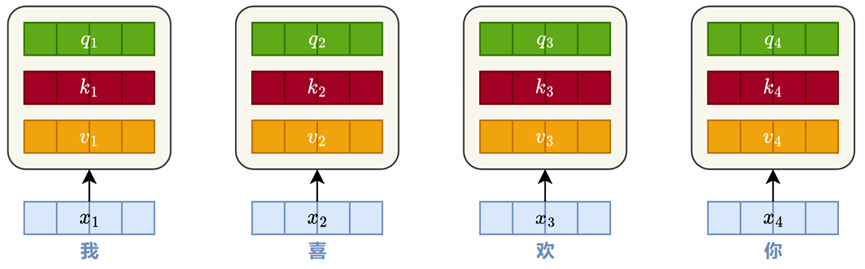
这些向量的作用如下:
Query:表示当前词的用于发起注意力匹配的向量;
Q也就是发起注意力匹配的向量,如上图'我'想要和'喜欢你'发生关系,就拿'我'的q去和'喜欢你'的k分别想乘
Key:表示序列中每个位置的内容标识,用于与 Query 进行匹配;
但q和k不表示当前文字的信息,只包含每个文字的位置关系,他们想乘后经过softmax层需要加权汇总v得到新的表示
Value:表示该位置携带的信息,用于加权汇总得到新的表示。
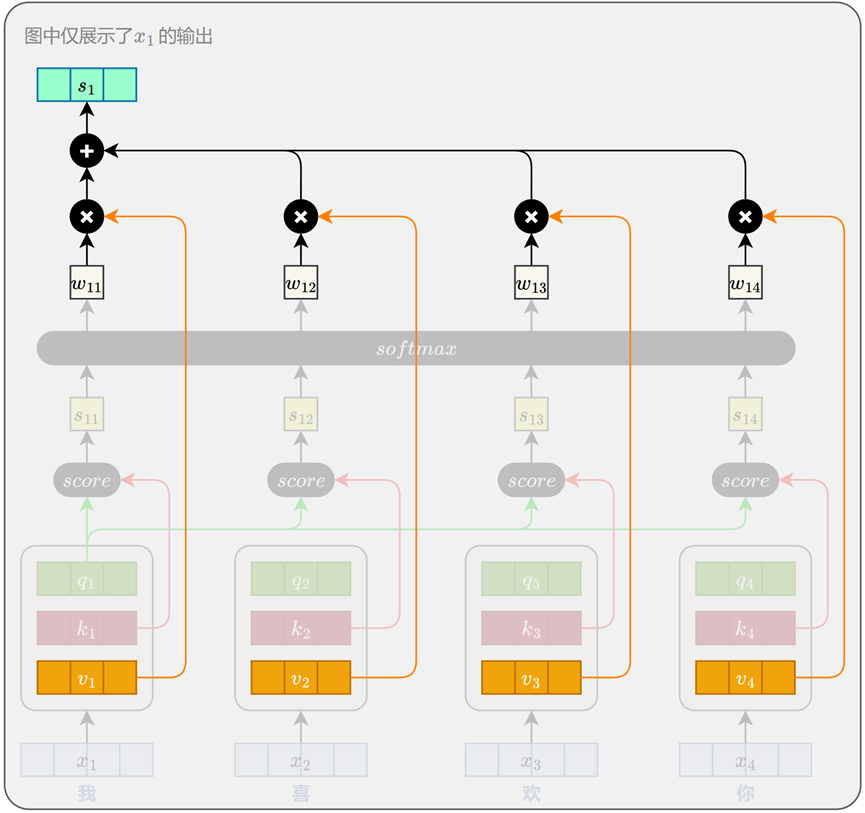
自注意力的核心思想是:每个位置用自身的 Query 向量,与整个序列中所有位置的 Key 向量进行相关性计算,从而得到注意力权重,并据此对对应的 Value 向量加权汇总,形成新的表示。
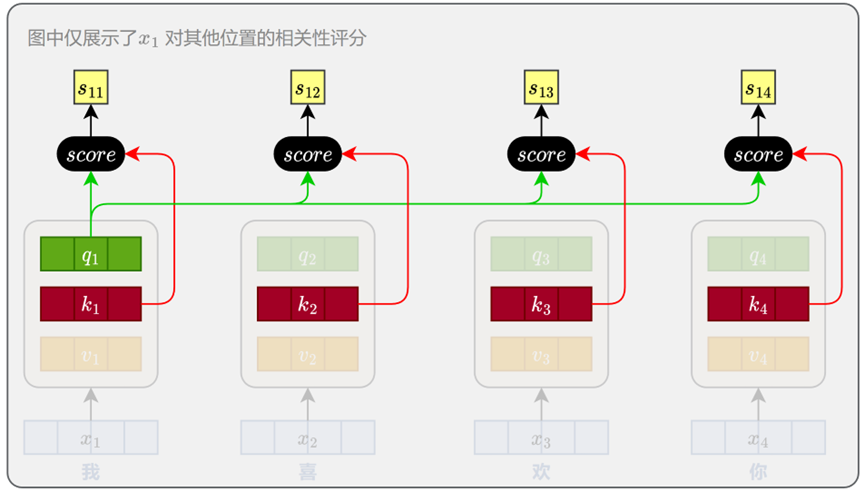
计算位置间相关性:
完成 Query、Key、Value 向量的生成后,模型会使用每个位置的 Query 向量与所有位置的 Key 向量进行相关性评分。
3.2 前馈神经网络子层(Feed-Forward Sublayer)
它通过对每个位置的表示进行逐位置 、非线性的特征变换,进一步提升模型对复杂语义的建模能力。
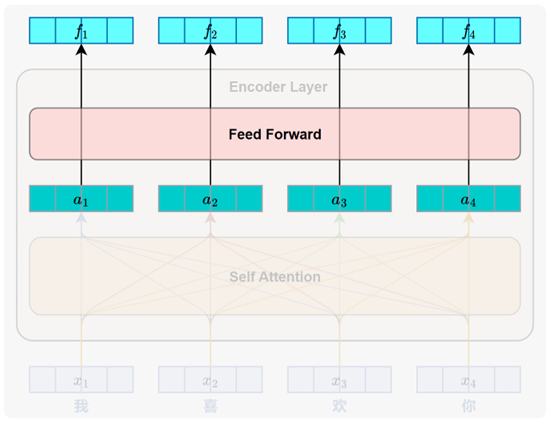
一个标准的 FFN 子层包含两个线性变换和一个非线性激活函数,中间通常使用 ReLU激活。其计算公式如下:
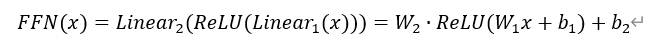
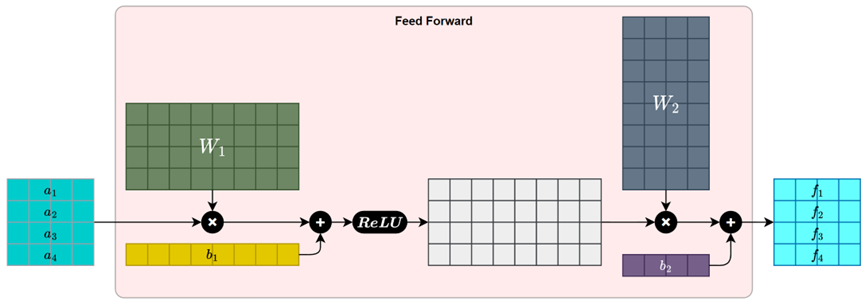
计算图如下:
3.3 残差连接
为什么要进行残差连接
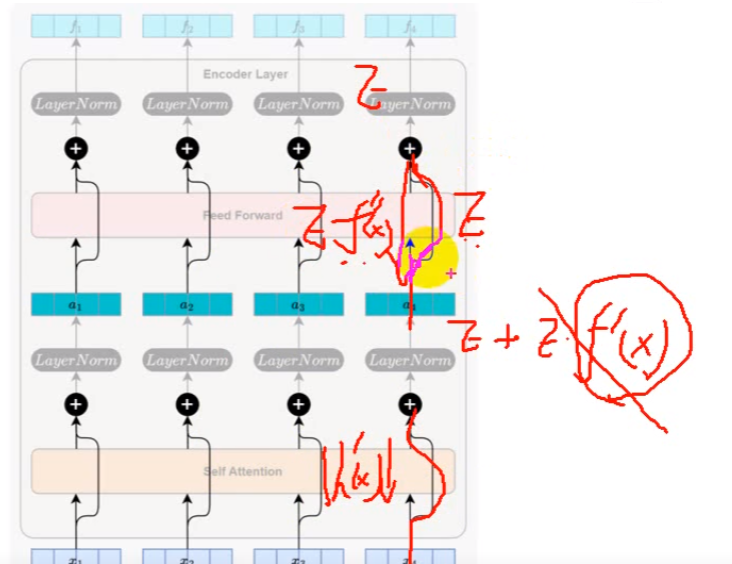
如果直接反向传播,结果是E*f'(x),此时如果出现梯度消失f'(x)无限趋近于0,E*f'(x)就等于0,如果有残差连接,则是E+E*f'(x),E*f'(x)等于0后还有E,可以供下一个子层继续计算,梯度减小不会累计
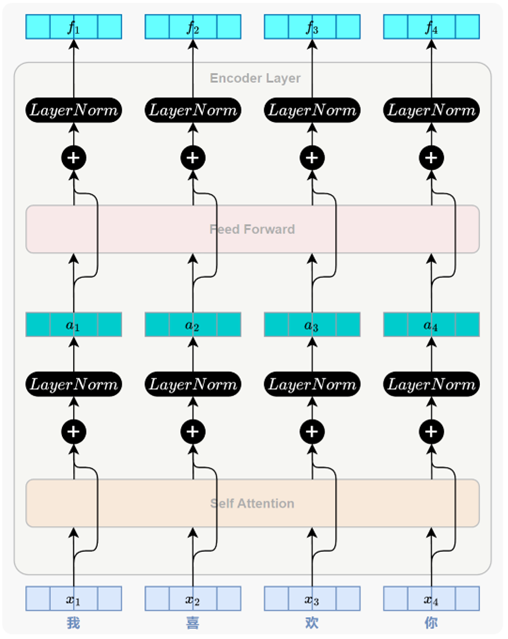
残差连接确保反向传播时,梯度至少有一条稳定通路可回传,是深层网络可稳定训练的关键结构。
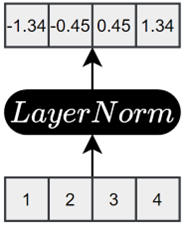
3.4 层归一化
每个子层在残差连接之后都会进行层归一化( Layer Normalization ,简称 LayerNorm )。它的主要作用是规范输入序列中每个token的特征分布(某个token的表示可能在不同维度上有较大数值差异),提升模型训练的稳定性。
这是一个真实的案例:
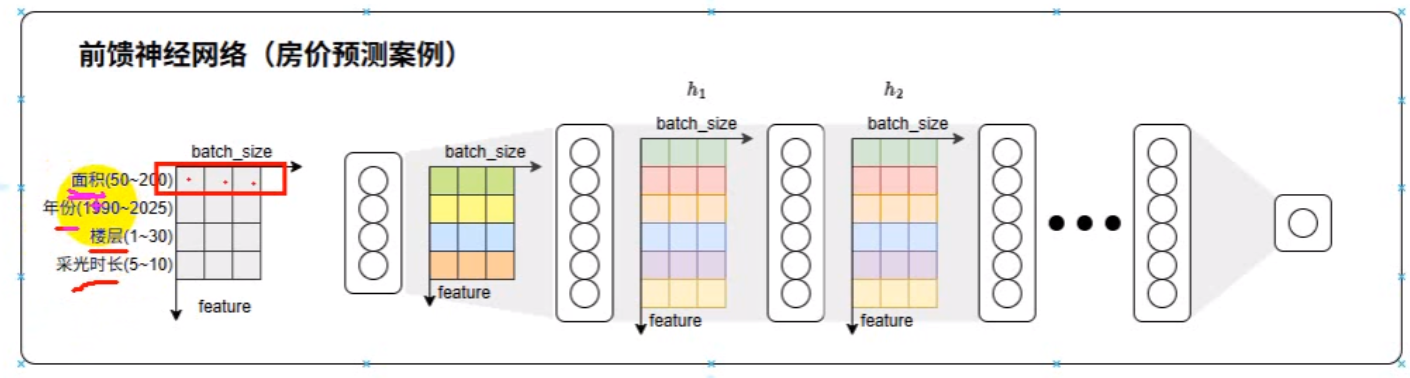
在整理数据时,可能聚合在一起的数据都不是相同单位,故大小更不可能相等,比如面积和年份就必须归一化处理然后使用
该操作会将每个token的向量调整为均值为 0、方差为 1 的规范分布,具体效果如下图所示:
计算该向量在所有特征维度上的平均值
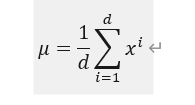
计算向量各维度的标准差
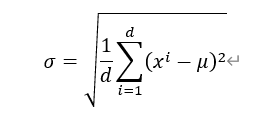
将每个特征值转换为均值为 0、方差为 1 的标准正态分布;
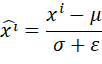
ε 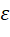 为一个小的常数,防止出现除以0的情况。
为一个小的常数,防止出现除以0的情况。
让模型可以学习在归一化后的基础上进行适当的调整,保证归一化不会限制模型的表示能力。
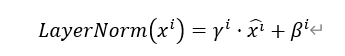
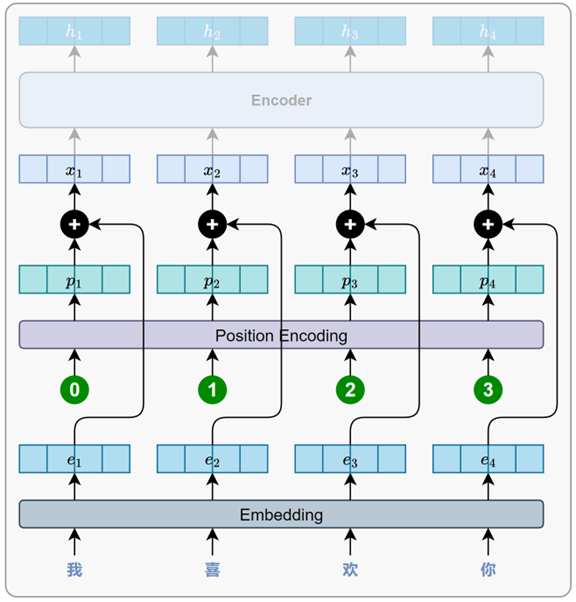
3.5 位置编码
在没有额外机制的情况下,Transformer 无法区分"猫吃鱼"和"鱼吃猫"这类语序不同但词汇相同的句子。
为了解决这一问题,Transformer 引入了一个关键机制------位置编码(Positional Encoding)。**该机制为每个词引入一个表示其位置信息的向量,并将其与对应的词向量相加,作为模型输入的一部分。**这样一来,模型在处理每个词时,既能获取词义信息,也能感知其在句子中的位置,从而具备对基本语序的理解能力。
为了解决上述问题,Transformer 使用了一种基于正弦(sin)和余弦(cos)函数的位置编码方式,具体定义如下:
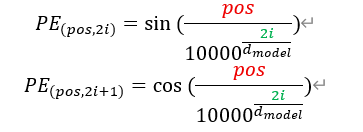
其中:
- pos是当前词在序列中的位置;
- i 用于表示位置编码向量的维度索引,2i 表示偶数维,*2i+*1表示奇数维;
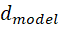 是词向量的维度大小。
是词向量的维度大小。
序列中的每个位置 pos 对应一个长度为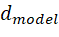 的位置编码向量。该向量的偶数维度 通过正弦函数生成,奇数维度通过余弦函数生成,如下图所示
的位置编码向量。该向量的偶数维度 通过正弦函数生成,奇数维度通过余弦函数生成,如下图所示
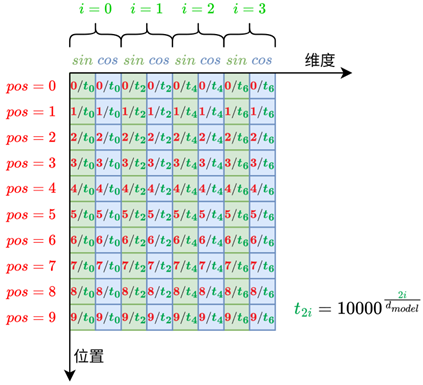
Transformer提出的这种编码方式不依赖任何可学习参数,数值稳定,并具备以下优势:
- 所有值都在−1,1范围内,数值稳定
- 编码方式固定、可预计算,无需训练;
- 相同位置的编码在不同句子中保持一致;
- 编码之间具有数学规律,便于模型在注意力机制中感知词语之间的相对位置关系。
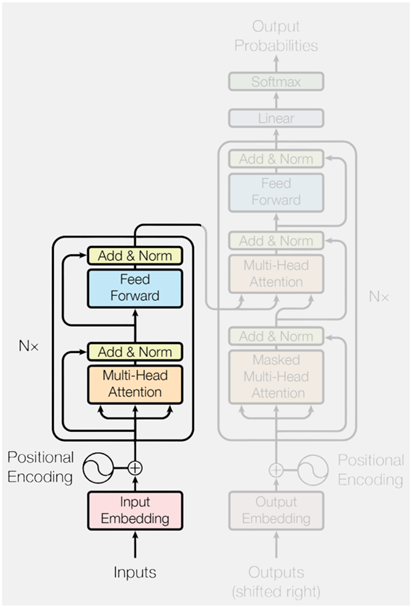
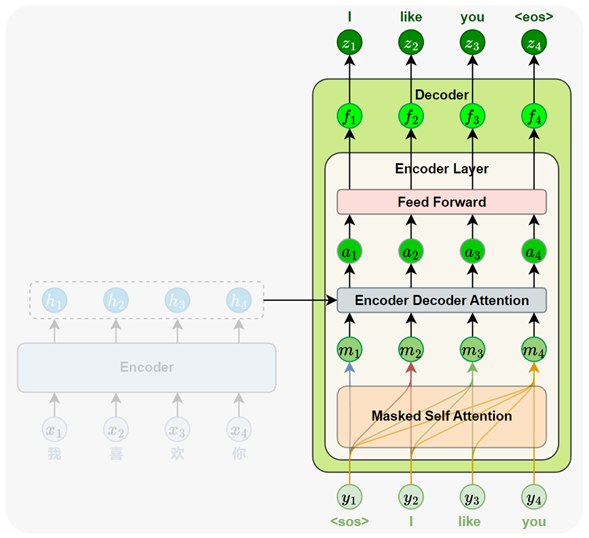
4.解码器
根据编码器的输出,逐步生成目标序列中的每一个词。其生成方式采用自回归机制(autoregressive):每一步的输入由此前已生成的所有词组成,模型将输出一个与当前输入长度相同的序列表示。我们只取最后一个位置的输出,作为当前步的预测结果。这一过程会不断重复,直到生成特殊的结束标记 <eos>,表示序列生成完成。
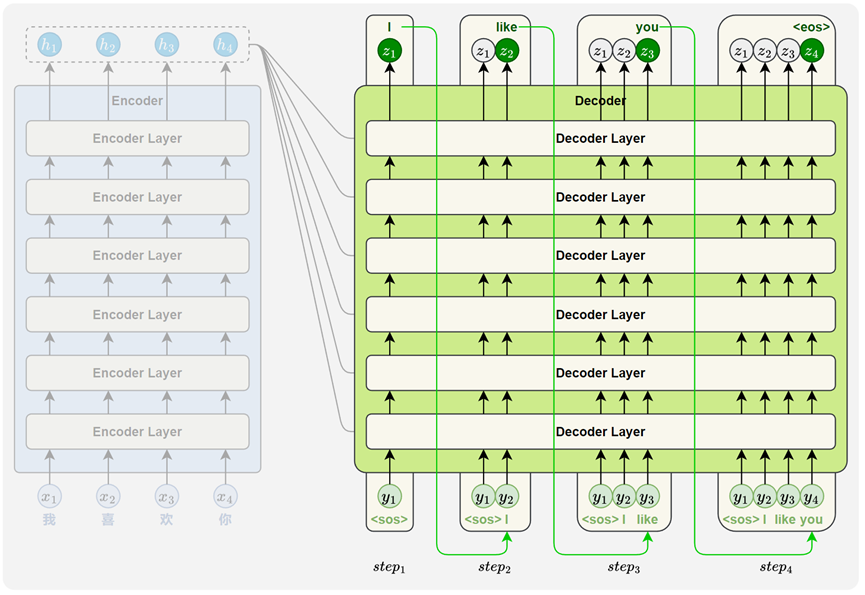
每个Decoder Layer都包含三个子层,分别是Masked自注意力子层 、编码器-解码器注意力子层(Encoder-Decoder Attention) 和前馈神经网络子层(Feed-Forward Network) 。还有残差连接与层归一化以及位置编码都有.
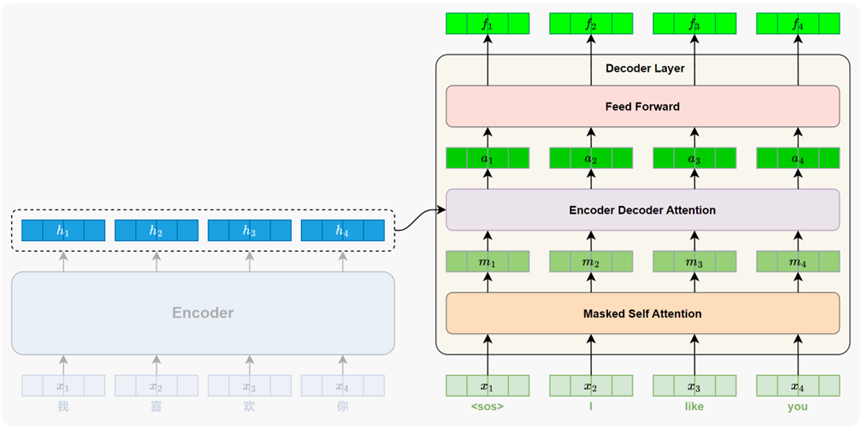
4.1 Masked自注意力子层
解码器在自注意力机制中引入了遮盖机制( Mask )。该机制会在计算注意力时,阻止模型访问当前位置之后的词,只允许它依赖自身及前文的信息。这样,即使在并行训练时,模型也只能像逐词生成一样"看见"它应该看到的内容,从而保持训练与推理阶段的一致性。如下图所示:
Mask 机制的实现非常简单:只需将注意力得分矩阵中当前位置对其后续位置的评分设置为 −∞,如下图所示:
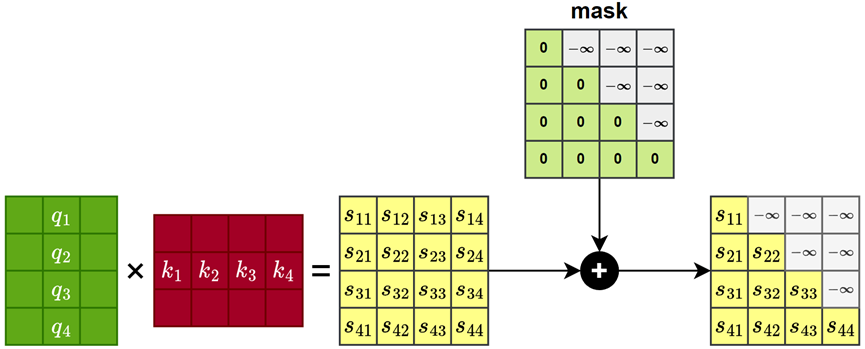
这样,在经过 softmax 运算后,这些位置的权重会趋近于 0。最终在加权求和时,来自未来位置的信息几乎不会参与计算,从而实现了"当前词只能看到它前面的词"的约束。如下图所示:

4.2 编码器-解码器注意力子层
该子层的主要作用是:建模当前解码位置与源语言序列中各位置之间的依赖关系,帮助模型在生成目标词时有效地参考输入内容,相当于Seq2Seq模型中的注意力机制。
也就是说,当前生成位置使用自己的Query,去"询问"编码器输出中的哪些位置最相关。注意力机制会根据 Query 与所有 Key 的相似度,为每个源位置分配一个权重,然后用这些权重对 Value 进行加权求和,得到当前生成词所需的上下文信息。
4.3 前馈神经网络子层(Feed-Forward Network)
它通过对每个位置的表示进行逐位置 、非线性的特征变换,进一步提升模型对复杂语义的建模能力。
一个标准的 FFN 子层包含两个线性变换和一个非线性激活函数,中间通常使用 ReLU激活。其计算公式如下:
计算图如下:
解码器完整结构如下图所示: