PEFT
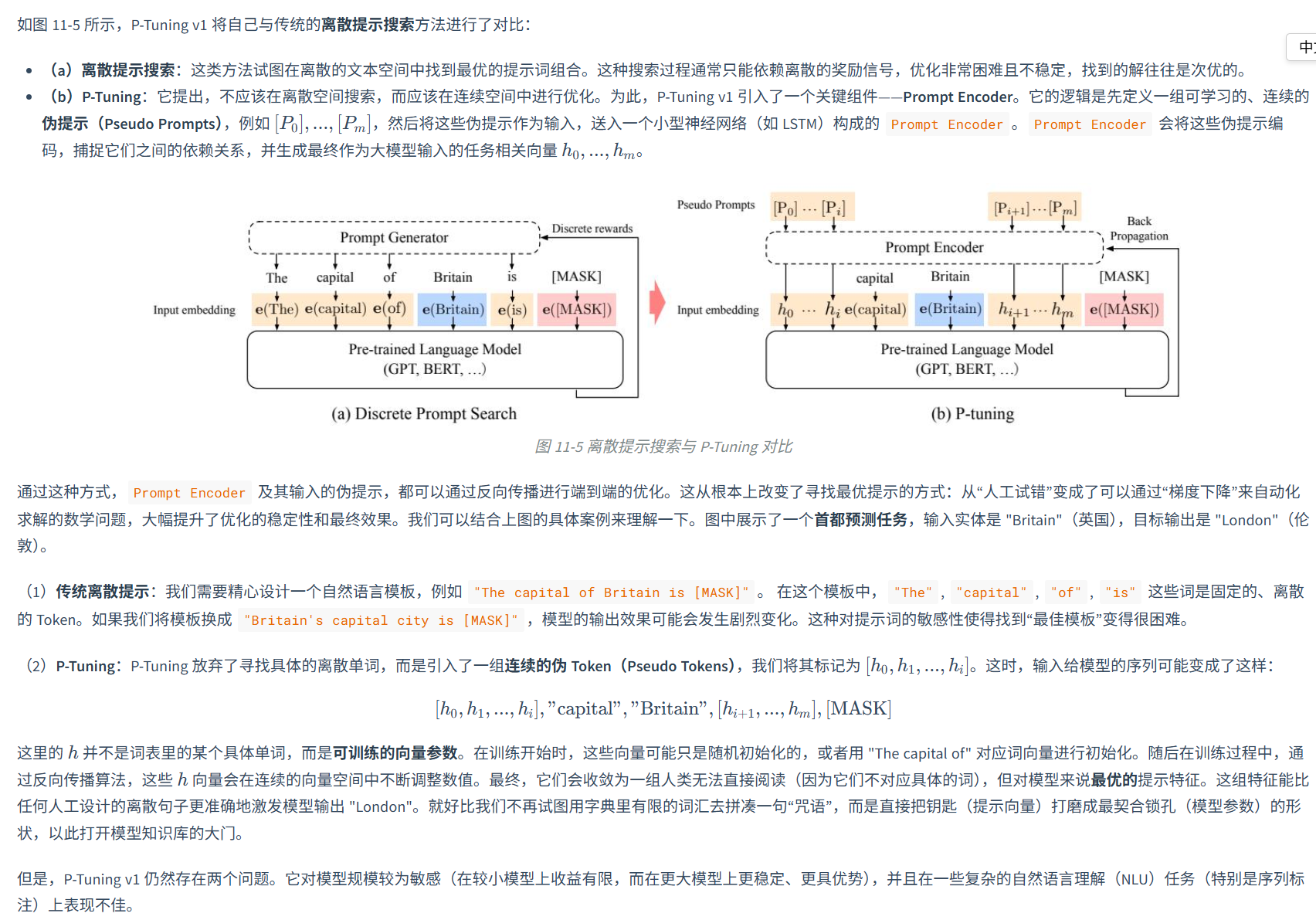
人工设计的、离散的文本指令,我们称之为"硬提示"(Hard Prompt)。但是,"硬提示"这种"刀耕火种"式的方法存在三个明显的局限。找到最优的提示词往往需要大量的试错和经验,过程繁琐且不稳定,充满了"玄学";离散的文本提示在表达能力上存在上限,难以充分激发和精确控制大模型的潜力;而且在一个模型上精心设计的提示,换到另一个模型或另一种语言上,效果可能大打折扣。
学术界和工业界开始探索一种全新的方法------参数高效微调(Parameter-Efficient Fine-Tuning, PEFT) 。核心思想 :冻结(freeze) 预训练模型 99% 以上的参数,仅调整其中极小一部分(通常<1%)的参数,或者增加一些额外的"小参数",从而以极低的成本让模型适应下游任务。
Adapter Tuning
其思路是在 Transformer 的每个块中插入 小型的"适配器"(Adapter)模块。左侧的 Transformer 层展示了 Adapter 模块是如何被集成进去的。Adapter 被插入到每个子层(注意力层和前馈网络)的内部,并与主干网络形成残差连接。在训练时,只有 Adapter 模块的参数会被更新。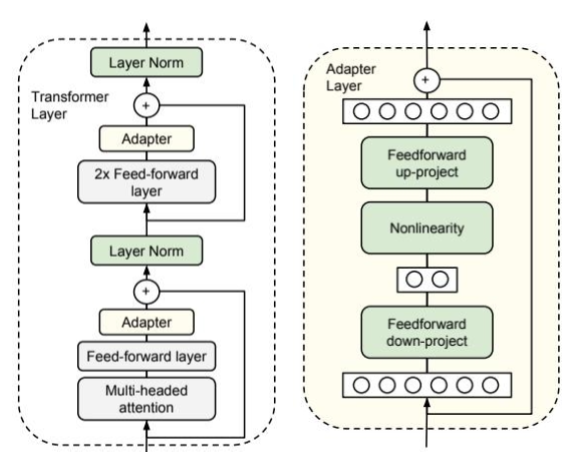
图 11-1 的右侧展示了 Adapter 模块自身的结构,主要包括一个"降维"的全连接层(Feedforward down-project)将高维特征映射到低维空间,一个非线性激活函数(Nonlinearity),一个"升维"的全连接层(Feedforward up-project)再将特征映射回原始维度,以及一个贯穿该模块的残差连接将模块的输出与原始输入相加,保证信息流的稳定。通过这种"瓶颈式"的结构,Adapter 模块可以用极少的参数量来模拟特定任务的知识。缺点是依旧吃很大资源。
Prefix Tuning
- 前缀激活值(Prefix Activations) :图中
PREFIX部分对应的激活值 hihi(其中 i∈Pidx)是从一个专门的可训练矩阵 Pθ 中提取的,这部分参数就是微调的对象。 - 模型计算的激活值 : 而原始输入 x 和输出 y 对应的激活值,则是由冻结的 Transformer 模型正常计算得出的。

直接优化 Prefix 向量比微调 Adapter 更困难,训练相对不稳定,对超参数和初始化较为敏感;同时,多数实现将前缀作为各层注意力的额外 K/V 记忆,其长度通常计入注意力配额,可能会减少可用的有效上下文窗口。
Prompt Tuning
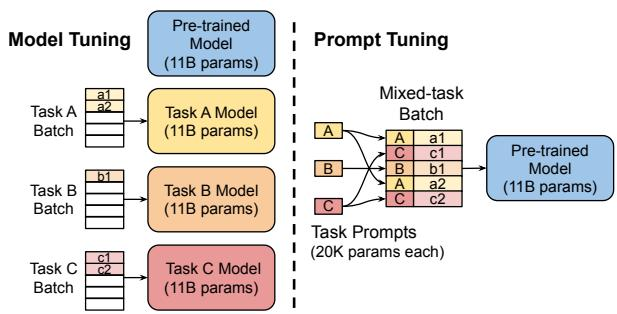
它的做法就是只在输入的 Embedding 层 添加可学习的虚拟 Token(称为 Soft Prompt ),不再干预 Transformer 的任何中间层。图 11-3 直观地展示了 Prompt Tuning 这种简化思路在实践中所带来的巨大差异,它不仅是参数效率的提升,更在使用范式上迈出了新的一步。
对于具体任务加上提示词前缀,调参时只对提示词前缀参数做调整。

实验表明当模型规模较小(如 1 亿参数)时,Prompt Tuning 的效果(绿线)远不如传统的模型微调(红线和橙线)。但当模型规模超过 100 亿时,Prompt Tuning 的性能开始追平甚至超越全量微调。
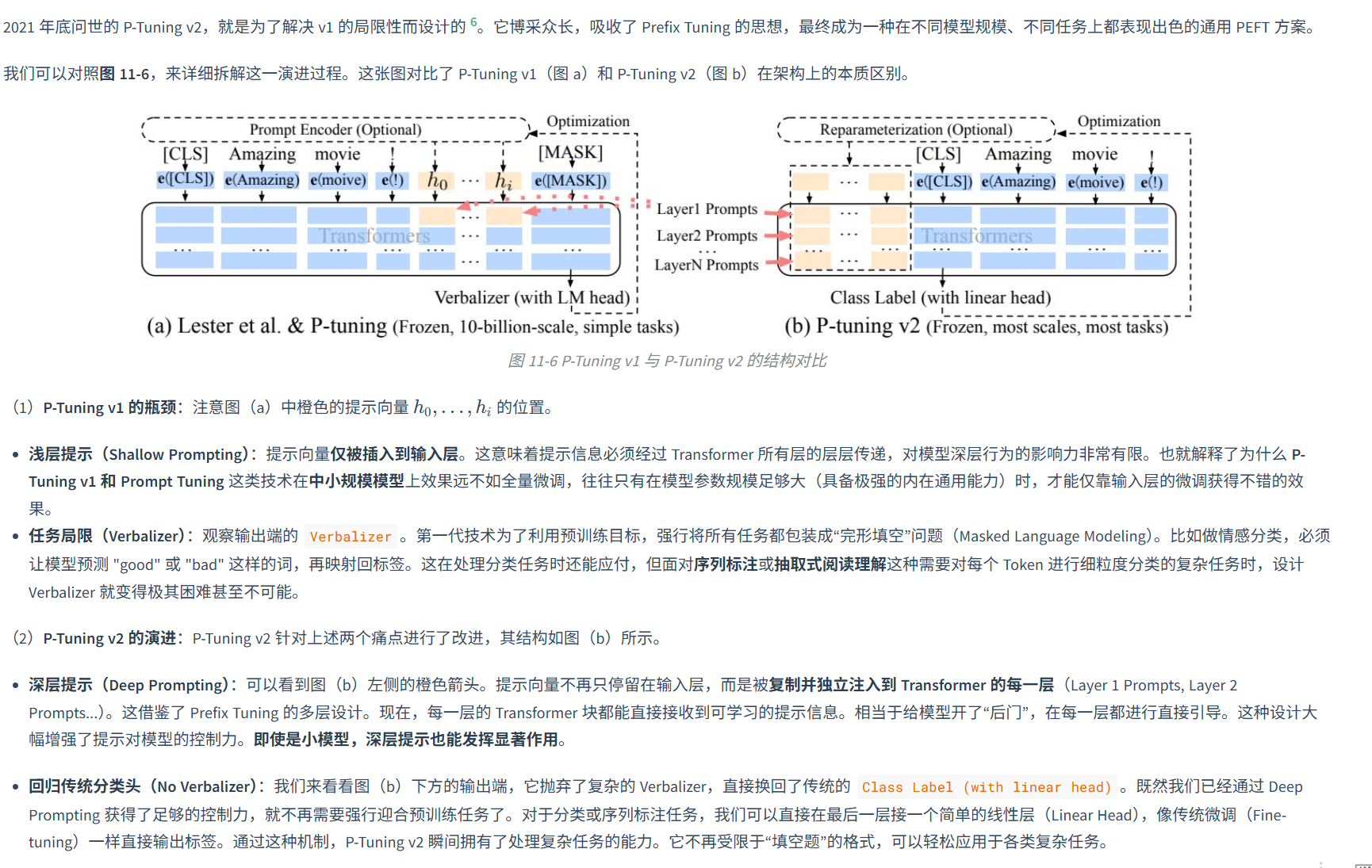
P-Tuning v2
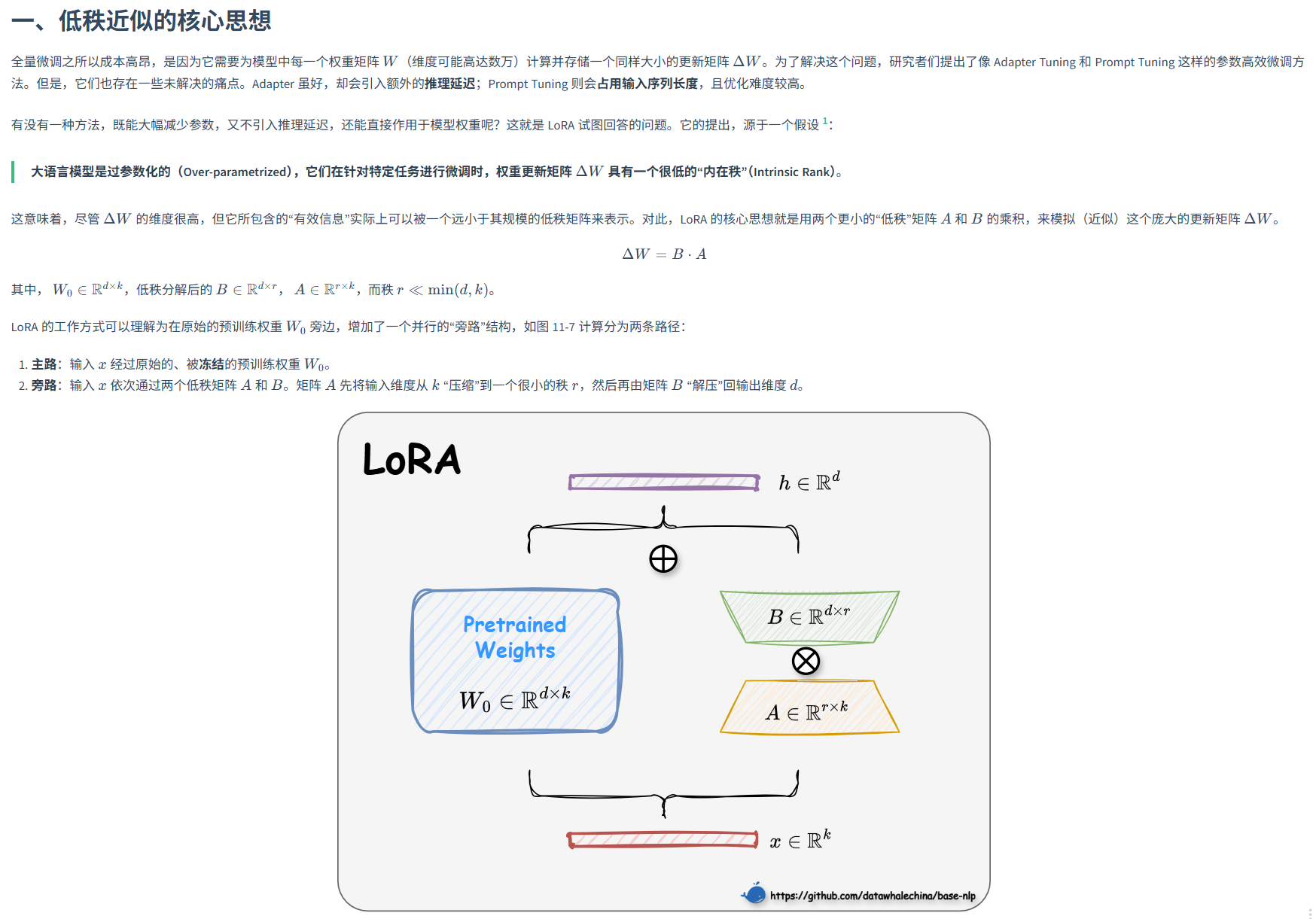
LoRA

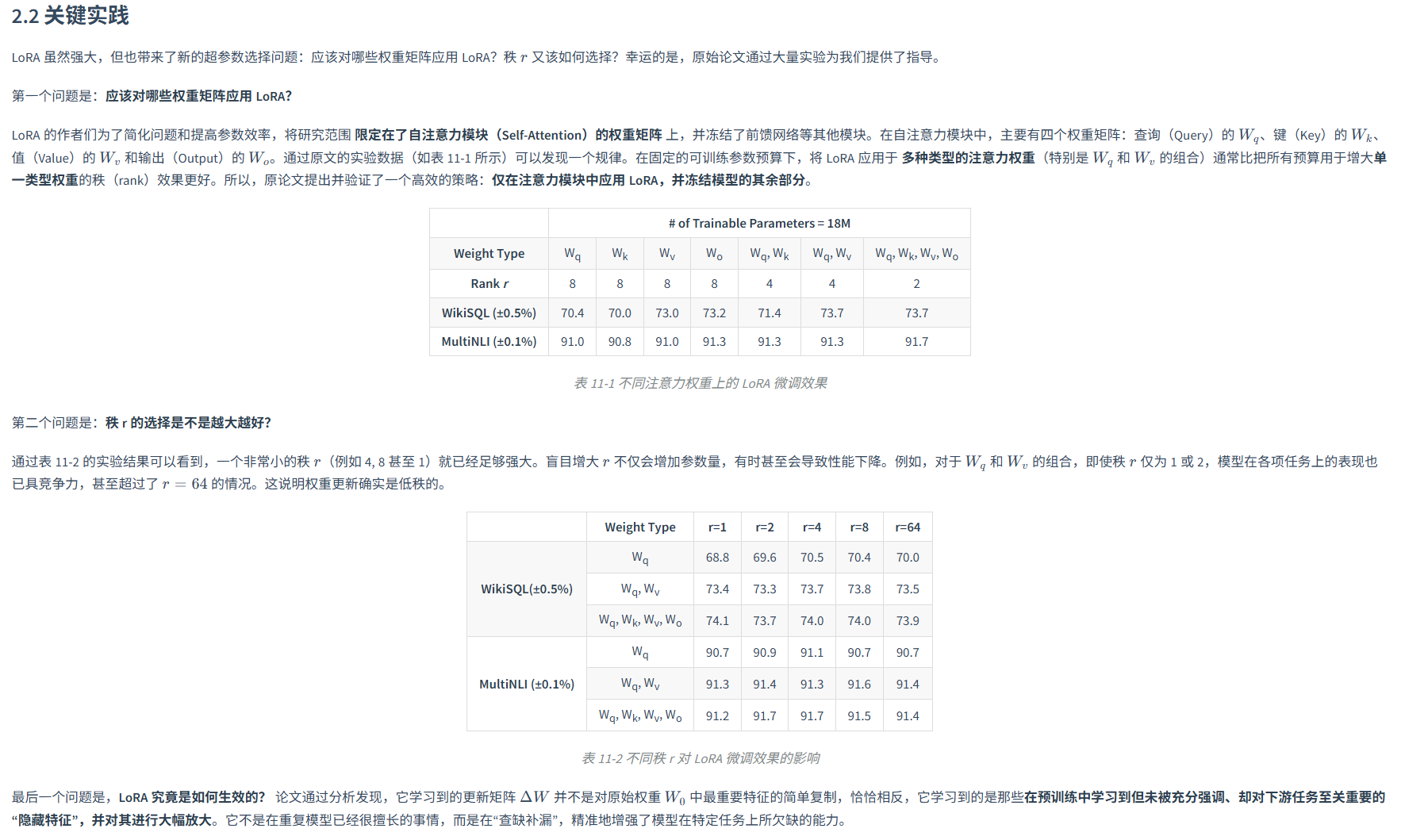
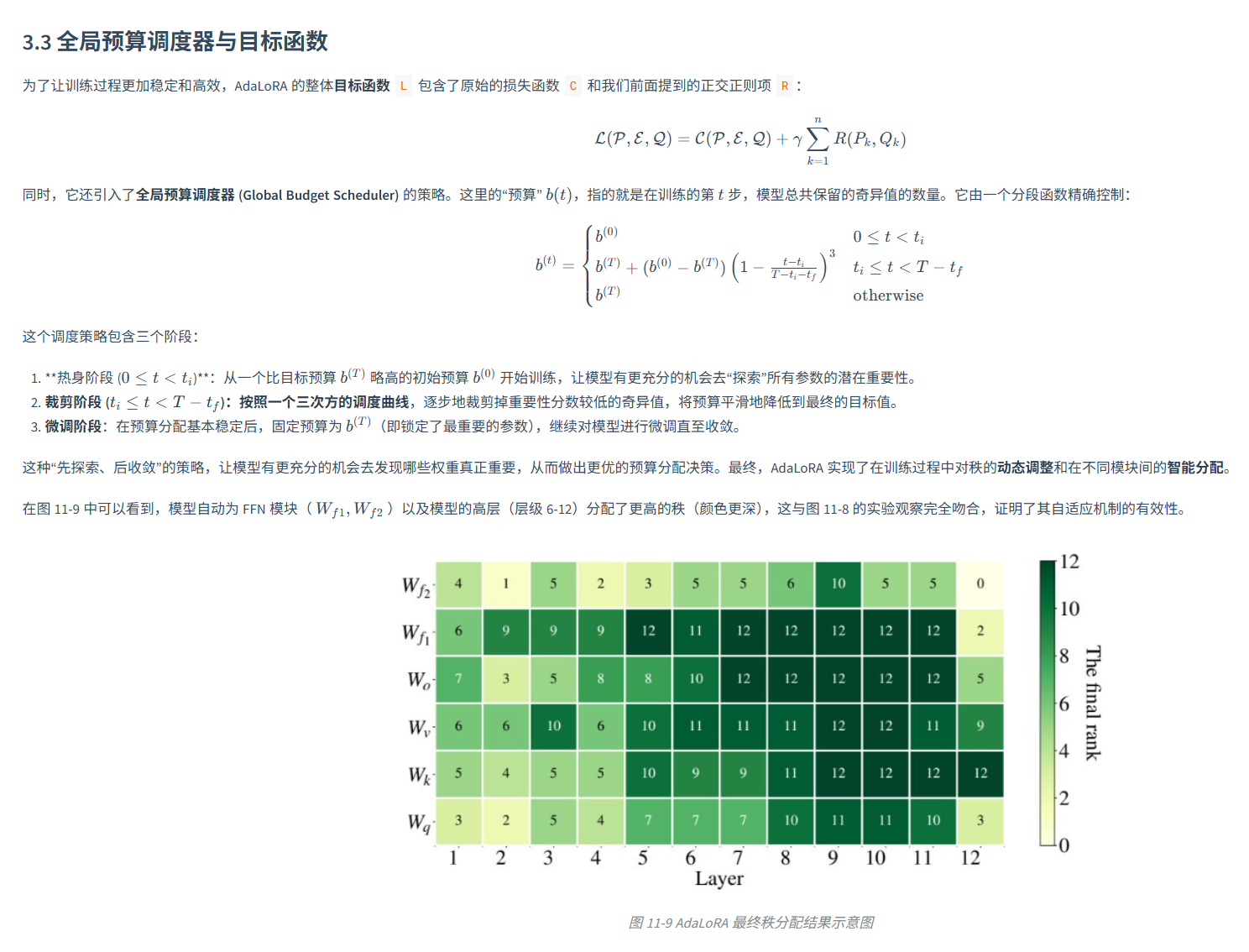
AdaLoRA (Adaptive LoRA)
用SVD的思想将更新w变为三个矩阵的元素,并不是说真的用SVD。

重要性评分,对于每个W计算其敏感度,以及分批次的敏感度稳定性,结合二者得到W重要性分数,将其svd特征值设为0,计算敏感度的反向传播参数总是需要计算的,对模型的速度影响很小。

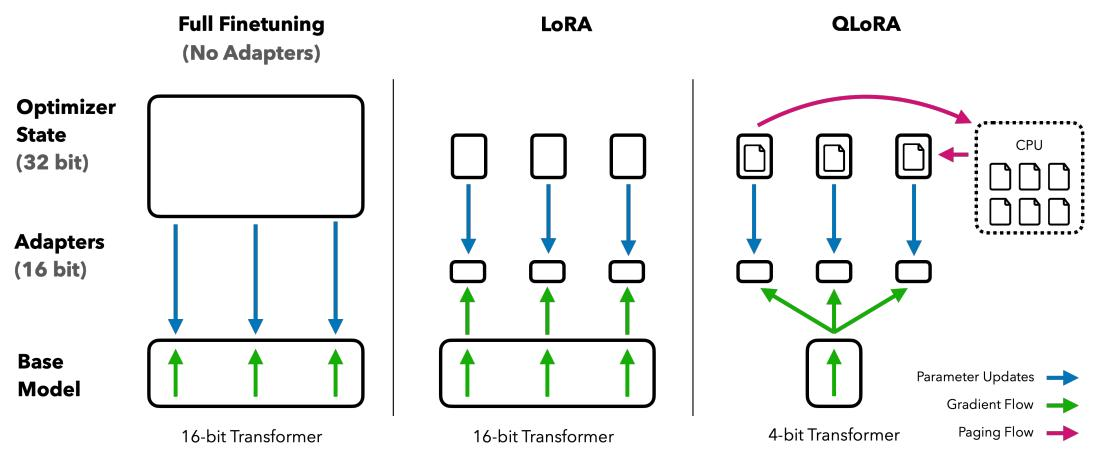
QLoRA
LoRA 和 AdaLoRA 分别从"低秩近似"和"自适应秩分配"两个角度优化了微调过程,但它们都还有一个共同的前提,原始的、被冻结的大模型权重仍然是以较高的精度(如 FP16 或 BF16)加载到显存中的。对于动辄几百上千亿参数的模型来说,这部分权重本身就是一笔巨大的显存开销。
与冻结 16-bit 模型的标准 LoRA 相比,QLoRA 更进一步,将基座模型量化为 4-bit 。训练时,梯度会穿过被冻结的 4-bit 模型,反向传播到 16-bit 的适配器中,并只更新适配器参数。此外,它还引入了 分页优化器,在显存不足时,可以将优化器状态临时卸载到 CPU 内存,从而有效管理内存峰值。