0.一图流
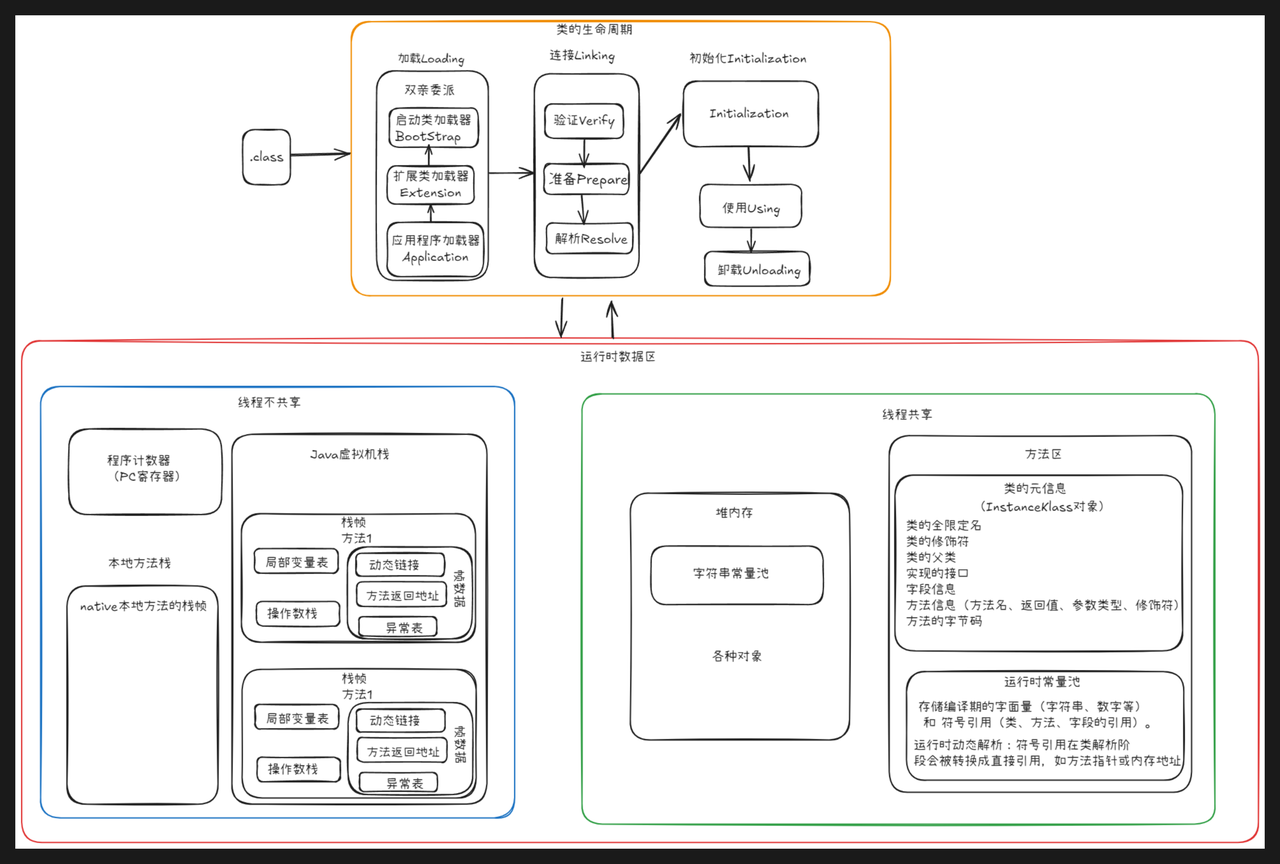
1.加载
双亲委派
类加载器有 启动类加载器(Bootstrap)- > 扩展类加载器(Extention) -> 应用程序类加载器(Application)。
双亲委派机制要求类的加载向上委托给父类加载器,向下进行加载。
即 Application 委托给 extention,Extention 委托给 Bootstrap,这时候 Bootstrap 看自己是否能加载,不能加载则向下委派给 Extention...
2.连接
连接阶段又细分为 验证 - 准备 - 解析 三个小阶段
验证阶段
验证的主要目的是检测 Java 字节码文件是否遵守了《Java 虚拟机规范》中的约束。这个阶段一般不需要程序员参与。主要包含如下四部分,具体详见《Java 虚拟机规范》:
-
文件格式验证,比如文件是否以 0xCAFEBABE 开头,主次版本号是否满足当前 Java 虚拟机版本要求。
-
元信息验证,例如类必须有父类(super 不能为空)。
-
验证程序执行指令的语义,比如方法内的指令执行中跳转到不正确的位置。
-
符号引用验证,例如是否访问了其他类中 private 的方法等。
准备
准备阶段为**静态变量(static)**分配内存并设置初值,每一种基本数据类型和引用数据类型都有其初值。
| 数据类型 | 初始值 |
|---|---|
| int | 0 |
| long | 0L |
| short | 0 |
| char | '\u0000' |
| byte | 0 |
| boolean | false |
| double | 0.0 |
| 引用数据类型 | null |
解析
解析阶段主要是将常量池中的符号引用替换为直接引用,符号引用就是在字节码文件中使用编号来访问常量池中的内容。
直接引用不再使用编号,而是使用内存中地址进行访问具体的数据。
3.初始化
初始化阶段会执行字节码文件中 clinit(class init 类的初始化)方法的字节码指令,包含了静态代码块中的代码,并为静态变量赋值。
类文件编译为字节码文件后会生成三个方法:
-
init 方法:会在对象初始化时执行
-
main 方法:主方法
-
clinit 方法:类的初始化阶段执行,主要包含静态代码块中的代码,为静态变量赋值
导致类初始化(执行 clinit)的情况:
-
访问一个类的静态变量或者静态方法,注意变量是 final 修饰的并且等号右边是常量不会触发初始化。
-
调用 Class.forName(String className)。
-
new 一个该类的对象时。
-
执行 Main 方法的当前类。
添加-XX:+TraceClassLoading 参数可以打印出加载并初始化的类
clinit 不会执行的几种情况
-
无静态代码块且无静态变量赋值语句。
-
有静态变量的声明,但是没有赋值语句。

- 静态变量的定义使用 final 关键字,这类变量会在准备阶段直接进行初始化。
4.运行时数据区
**线程共享的:**堆、方法区。
**线程不共享的:**PC 寄存器、Java 虚拟机栈、本地方法栈(执行 native 方法服务)。(HotSpot 两栈合一)
JVM 进程 OS 视角
OS 会给所有进程分配虚拟内存空间等资源,如 mm_struct(虚拟内存空间结构体),将进程的虚拟空间分为多段:
JVM 是在 OS 进程资源之上玩的各种花样:
-
JVM 的堆是在 OS 堆中划分的一片逻辑区域
-
方法区则在 OS 堆中 JVM 堆外的元空间中(OS 本地内存)
-
PC 寄存器是属于 CPU 中的一个硬件寄存器
-
每个线程的栈就是进程栈空间的一部分
-
直接内存指的也是 OS 进程本地内存
4.1 Java 虚拟机栈
Java 虚拟机栈(Java Virtual Machine Stack)采用栈的数据结构来管理方法调用中的基本数据,先进后出(First In Last Out),每一个方法的调用使用一个栈帧(Stack Frame)来保存。
Java 虚拟机栈随着线程的创建而创建,而回收则会在线程的销毁时进行。由于方法可能会在不同线程中执行,每个线程都会包含一个自己的虚拟机栈。
栈帧中主要包含三方面的内容:
- **局部变量表:**局部变量表的作用是在运行过程中存放所有的局部变量
栈帧中的局部变量表是一个数组,数组中每一个位置称之为槽(slot) ,long 和 double 类型占用两个槽,其他类型占用一个槽。
实例方法中的序号为 0 的位置存放的是 this,指的是当前调用方法的对象,运行时会在内存中存放实例对象的地址。
方法参数也会保存在局部变量表中,其顺序与方法中参数定义的顺序一致。局部变量表保存的内容有:实例方法的 this 对象,方法的参数,方法体中声明的局部变量。
为了节省空间,局部变量表中的槽是可以复用的,一旦某个局部变量不再生效,当前槽就可以再次被使用。
- **操作数栈:**操作数栈是栈帧中虚拟机在执行指令过程中用来存放中间数据的一块区域。
他是一种栈式的数据结构,如果一条指令将一个值压入操作数栈,则后面的指令可以弹出并使用该值。
在编译期就可以确定操作数栈的最大深度,从而在执行时正确的分配内存大小。
- **帧数据:**帧数据主要包含动态链接、方法出口、异常表的引用
-
动态连接:当前类的字节码指令引用了其他类的属性或者方法时,需要将符号引用(编号)转换成对应的运行时常量池中的内存地址。动态链接就保存了编号到运行时常量池的内存地址的映射关系。
-
方法出口:方法在正确或者异常结束时,当前栈帧会被弹出,同时程序计数器应该指向上一个栈帧中的下一条指令的地址。所以在当前栈帧中,需要存储此方法出口的地址。
-
异常表:异常表存放的是代码中异常的处理信息,包含了异常捕获的生效范围以及异常发生后跳转到的字节码指令位置。
栈内存溢出
Java 虚拟机栈如果栈帧过多,占用内存超过栈内存可以分配的最大大小就会出现内存溢出。Java 虚拟机栈内存溢出时会出现 StackOverflowError 的错误。
本地方法栈
Java 虚拟机栈存储了 Java 方法调用时的栈帧,而本地方法栈存储的是 native 本地方法的栈帧。
在 Hotspot 虚拟机中,Java 虚拟机栈和本地方法栈实现上使用了同一个栈空间。本地方法栈会在栈内存上生成一个栈帧,临时保存方法的参数同时方便出现异常时也把本地方法的栈信息打印出来(与 java 方法栈帧一样)。
4.2 堆内存
创建出来的对象都存在于堆上。栈上的局部变量表中,可以存放堆上对象的引用。静态变量也可以存放堆对象的引用,通过静态变量就可以实现对象在线程之间共享。
堆内存大小是有上限的,当对象一直向堆中放入对象达到上限之后,就会抛出 OutOfMemory 错误,堆内存溢出。
堆空间有三个需要关注的值,used、total、max。used 指的是当前已使用的堆内存,total 是 java 虚拟机已经分配的可用堆内存(从 OS 堆中拿过来的),max 是 java 虚拟机可以分配的最大堆内存。
如果不设置任何的虚拟机参数,max 默认是系统内存的 1/4,total 默认是系统内存的 1/64。在实际应用中一般都需要设置 total 和 max 的值。
TLAB( Thread Local Allocation Buffer)
堆内存是全局共享的,新生代内存又是连续紧凑的,靠一个指针来划分 。新对象创建时指针右移对象大小就行,这叫指针碰撞(bump the pointer)。多线程同时分配对象,这个指针就成了热点资源,得加锁互斥,效率直接拉胯。
TLAB 的思路就是预先给每个线程圈一块地,线程只在自己那块地里分配,各玩各的不用抢。用完了再去申请一块新的。这个思路很常见,比如分布式发号器,每次批量取一批号,用完再申请,不会一个一个取。
TLAB 大小不是固定的,HotSpot 会根据线程的历史分配行为动态调整。一个线程如果一直在疯狂创建对象,JVM 会给它分配更大的 TLAB;一个线程几乎不创建对象,TLAB 就小一点,避免浪费 Eden 空间。
TLAB 用到最后可能剩一点空间,比如剩 8 字节,但下一个对象要 16 字节,这时候得申请新的 TLAB,老 TLAB 里那 8 字节就浪费了。
HotSpot 的处理方式是用一个填充对象(dummy object)把这块空间填满。为啥要填?因为堆需要线性遍历,GC 扫描时通过对象头拿到对象大小,然后跳到下一个对象。如果有空洞,遍历就断了。
TLAB 只给小对象用。对象超过一定阈值(通常几 KB)就直接在 Eden 区分配,不走 TLAB。原因很简单:大对象放 TLAB 里会迅速把 TLAB 撑爆,频繁申请新 TLAB 反而更慢。而且大对象通常生命周期长,直接分配在共享区更合理。
TLAB 分配对象失败后有哪些后续处理策略?
TLAB 分配失败后 JVM 会看剩余空间大小。如果剩余空间小于 refill_waste 阈值,就废弃当前 TLAB 申请新的;如果剩余空间还比较大但装不下当前对象,会直接在 Eden 区分配这个对象,TLAB 留着继续用。这样能平衡碎片浪费和分配效率。
字符串常量池
JDK7 之后字符串常量池存储在堆中,不再是方法区中。
字符串常量池本质是一个 StringTable(Java 堆中的一个哈希表),用于维护从字符串内容到其堆内实例引用的唯一映射。(如果字符串没有任何引用指向它,Full GC 时会被回收)
new String("abc") 会先看 StringTable 中是否有"abc",有则代表已经被缓存,堆中有"abc"的一个实例对象,但这里是新 new,所以会在堆中重新创建一个对象,将 StringTable 中的"abc"内容(不是引用)复制给新对象,改过程创建一个对象。
如果发现 StringTable 中没有"abc",则会将该字符串缓存到 StringTable 中,并在堆中实例化一个"abc"对象,并返回这个对象地址,即 new 的"abc"对象就是字符串常量池里缓存的字符串实例,改过程创建一个对象。
eg: String s = new String("abc");
情况一:类中第一次出现
"abc"字面量
首先 :
"abc"字面量会被 JVM 在类加载或解析常量时放入 StringTable(字符串常量池);
这会在堆中创建一个
String对象 ,其value字段指向一个char[],内容是{'a','b','c'};该对象的引用被存入 StringTable。
然后 :执行代码
new String("abc")时:
"abc"这个字面量已经被缓存,所以会获取到 StringTable 中已有的那个对象的引用(作为构造函数的参数)。
new String()会在堆中创建另一个全新的String对象 ,并且通过构造函数把这个"abc"字面量对象的char[]复制(其实是引用拷贝)到新对象的value字段。返回这个新对象的引用。
因此这种情况下总共会创建 2 个
String对象:
字面量
"abc"对应的 String 对象(被 StringTable 引用);
new出来的新 String 对象。即使 StringTable 中没有"abc",也是先为字面量创建并放入池,然后
new再创建另外一个独立的对象。返回值是 new 的这个,不是池中的那个。 所以new String("abc") == "abc"为false,因为地址不同(除非手动intern)。情况二:类中之前已经有别的地方用过
"abc"字面量过程与上面类似,区别在于第 1 步中的
"abc"对象在之前就已经创建并放入 StringTable 了,所以new String("abc")时不需要再创建字面量对象,直接使用 StringTable 已有的引用,然后new出一个新对象。此时创建的对象数:只创建 1 个对象(字面量对象已存在,只创建 new 的这个新对象)。
实际是 新 String 对象会共享(或复制)原字面量对象的底层
char[](Java 9 之前是共享char[]引用,Java 9 之后使用byte[],并且new String(String)会复制这个数组)。
4.3 方法区
包含两部分:
- 类的元信息,保存了所有类的基本信息
方法区是用来存储每个类的基本信息(元信息),一般称之为 InstanceKlass 对象。在类的加载阶段完成。其中就包含了类的字段、方法等字节码文件中的内容,同时还保存了运行过程中需要使用的虚方法表(实现多态的基础)等信息。
- 运行时常量池,保存了字节码文件中的常量池内容
字节码文件中通过编号查表的方式找到常量,这种常量池称为静态常量池。当常量池加载到内存中之后,可以通过内存地址快速的定位到常量池中的内容,这种常量池称为运行时常量池。
JDK7 将方法区存放在堆区域中的永久代空间,堆的大小由虚拟机参数-XX:MaxPermSize=值来控制。
JDK8 将方法区存放在元空间中,元空间位于操作系统维护的直接内存中,默认情况下只要不超过操作系统承受的上限,可以一直分配。可以使用-XX:MaxMetaspaceSize=值将元空间最大大小进行限制。
为什么 Java 8 移除了永久代(PermGen)并引入了元空间(Metaspace)?
-
大小在启动时就定死了,很难调。设小了动态加载类多的应用动不动就 OOM,设大了又浪费内存。
-
永久代归堆管,但里面存的都是类元数据这种几乎不会被回收的东西 。永久代满了会触发 Full GC,但回收率极低,触发了也是白忙活
-
和堆放一起导致 GC 算法设计困难,不同的数据特性混在一起不好优化
元空间用本地内存存储类元数据,不再受堆大小限制。默认情况下只受机器物理内存约束,可以动态扩展,OOM 的风险大大降低。
4.4 直接内存
直接内存(Direct Memory)并不在《Java 虚拟机规范》中存在,所以并不属于 Java 运行时的内存区域。
在 JDK 1.4 中引入了 NIO 机制,使用了直接内存,主要为了解决以下两个问题:
1、Java 堆中的对象如果不再使用要回收,回收时会影响对象的创建和使用。
2、IO 操作比如读文件,需要先把文件读入直接内存(缓冲区)再把数据复制到 Java 堆中。
现在直接放入直接内存即可,同时 Java 堆上维护直接内存的引用,减少了数据复制的开销。写文件也是类似的思路。
要创建直接内存上的数据,可以使用ByteBuffer。
语法: ByteBuffer directBuffer = ByteBuffer.allocateDirect(size);
DirectByteBuffer 的内存什么时候会被回收?
DirectByteBuffer 本身是个堆上的对象,它持有堆外内存的地址。当 DirectByteBuffer 对象被 GC 回收时,会触发 Cleaner 去释放对应的堆外内存。问题是 DirectByteBuffer 对象本身很小,可能在老年代躺着不触发 GC,堆外内存就一直占着。所以 Netty 自己管理 DirectByteBuffer 的生命周期,用引用计数手动释放,不依赖 GC。
4.5 对象是怎么存的
5.垃圾回收
5.1 判断方式
Java 中的对象是否能被回收,是根据对象是否被引用来决定的。如果对象被引用了,说明该对象还在使用,不允许被回收。
判断对象是否可以回收,主要有两种方式:引用计数法和可达性分析法。
引用计数法
引用计数法会为每个对象维护一个引用计数器,当对象被引用时加 1,取消引用时减 1。
引用计数法的优点是实现简单,C++中的智能指针就采用了引用计数法,但是它也存在缺点,主要有两点:
-
每次引用和取消引用都需要维护计数器,对系统性能会有一定的影响。
-
存在循环引用问题,所谓循环引用就是当 A 引用 B,B 同时引用 A 时会出现对象无法回收的问题。
可达性分析法
Java 使用的是可达性分析算法来判断对象是否可以被回收。可达性分析将对象分为两类:垃圾回收的根对象(GC Root)和普通对象,对象与对象之间存在引用关系。
哪些对象被称之为 GC Root 对象呢?
-
线程 Thread 对象,引用线程栈帧中的方法参数、局部变量等。
-
系统类加载器加载的 java.lang.Class 对象,引用类中的静态变量。
-
监视器对象,用来保存同步锁 synchronized 关键字持有的对象。
-
本地方法调用时使用的全局对象。
5.2 引用方式
可达性算法中描述的对象引用,一般指的是强引用,即是 GCRoot 对象对普通对象有引用关系,只要这层关系存在,普通对象就不会被回收。除了强引用之外,Java 中还设计了几种其他引用方式:
软引用
软引用相对于强引用是一种比较弱的引用关系,如果一个对象只有软引用关联到它,当程序内存不足时,就会将软引用中的数据进行回收。在 JDK 1.2 版之后提供了 SoftReference 类来实现软引用,软引用常用于缓存中。
**特别注意:**软引用对象本身,也需要被强引用,否则软引用对象也会被回收掉。
软引用的执行过程如下:
-
将对象使用软引用包装起来,new SoftReference<对象类型>(对象)。
-
内存不足时,虚拟机尝试进行垃圾回收。
-
如果垃圾回收仍不能解决内存不足的问题,回收软引用中的对象。
-
如果依然内存不足,抛出 OutOfMemory 异常。
软引用对象本身怎么回收呢?
如果软引用对象里边包含的数据已经被回收了,那么软引用对象本身其实也可以被回收了。
SoftReference 提供了一套队列机制:
-
软引用创建时,通过构造器传入引用队列
-
在软引用中包含的对象被回收时,该软引用对象会被放入引用队列
-
通过代码遍历引用队列,将 SoftReference 的强引用删除
弱引用
弱引用的整体机制和软引用基本一致,区别在于弱引用包含的对象在垃圾回收时,不管内存够不够都会直接被回收。在 JDK 1.2 版之后提供了 WeakReference 类来实现弱引用,弱引用主要在ThreadLocal中使用。
弱引用对象本身也可以使用引用队列进行回收。
虚引用和终结器引用
这两种引用在常规开发中是不会使用的。
-
虚引用也叫幽灵引用/幻影引用,不能通过虚引用对象获取到包含的对象。虚引用唯一的用途是当对象被垃圾回收器回收时可以接收到对应的通知。Java 中使用 PhantomReference 实现了虚引用,直接内存中为了及时知道直接内存对象不再使用,从而回收内存,使用了虚引用来实现。
-
终结器引用指的是在对象需要被回收时,终结器引用会关联对象并放置在 Finalizer 类中的引用队列中,在稍后由一条由 FinalizerThread 线程从队列中获取对象,然后执行对象的 finalize 方法,在对象第二次被回收时,该对象才真正的被回收。在这个过程中可以在 finalize 方法中再将自身对象使用强引用关联上,但是不建议这样做。
5.3 方法区回收
方法区中能回收的内容主要就是不再使用的类。
判定一个类可以被卸载。需要同时满足下面三个条件:
-
此类所有实例对象都已经被回收,在堆中不存在任何该类的实例对象以及子类对象。
-
加载该类的类加载器已经被回收。
-
该类对应的 java.lang.Class 对象没有在任何地方被引用。
5.4 垃圾回收算法
5.4.1 标记清楚法
-
标记阶段,将所有存活的对象进行标记。Java 中使用可达性分析算法,从 GC Root 开始通过引用链遍历出所有存活对象。
-
清除阶段,从内存中删除没有被标记也就是非存活对象。
优点:实现简单,只需要在第一阶段给每个对象维护标志位,第二阶段删除对象即可。
缺点:
-
碎片化问题
-
分配速度慢。由于内存碎片的存在,需要维护一个空闲链表,极有可能发生每次需要遍历到链表的最后才能获得合适的内存空间。
我们需要用一个链表来维护,哪些空间可以分配对象,很有可能需要遍历这个链表到最后,才能发现这块空间足够我们去创建一个对象。如下图,遍历到最后才发现有足够的空间分配 3 个字节的对象了。如果链表很长,遍历也会花费较长的时间。
5.4.2 复制算法
-
准备两块空间 From 空间和 To 空间,每次在对象分配阶段,只能使用其中一块空间(From 空间)。
-
在垃圾回收 GC 阶段,将 From 中存活对象复制到 To 空间。
-
将两块空间的 From 和 To 名字互换。
优点:
-
吞吐量高,复制算法只需要遍历一次存活对象复制到 To 空间即可,比标记-整理算法少了一次遍历的过程,因而性能较好,但是不如标记-清除算法,因为标记清除算法不需要进行对象的移动
-
不会发生碎片化,复制算法在复制之后就会将对象按顺序放入 To 空间中,所以对象以外的区域都是可用空间,不存在碎片化内存空间。
缺点:内存使用效率低,每次只能让一半的内存空间来为创建对象使用。
5.4.3 标记整理算法
标记整理算法也叫标记压缩算法,是对标记清理算法中容易产生内存碎片问题的一种解决方案。
-
标记阶段,将所有存活的对象进行标记。Java 中使用可达性分析算法,从 GC Root 开始通过引用链遍历出所有存活对象。
-
整理阶段,将存活对象移动到堆的一端,并回收无效对象占用的空间。
优点:
-
内存使用效率高,整个堆内存都可以使用,不会像复制算法只能使用半个堆内存
-
不会发生碎片化,在整理阶段可以将对象往内存的一侧进行移动,剩下的空间都是可以分配对象的有效空间
缺点:整理阶段的效率不高,整理算法有很多种,比如 Lisp2 整理算法需要对整个堆中的对象搜索 3 次,整体性能不佳。可以通过 Two-Finger、表格算法、ImmixGC 等高效的整理算法优化此阶段的性能。
5.4.4 分代垃圾回收算法
-
分代回收时,创建出来的对象,首先会被放入 Eden 伊甸园区。
-
随着对象在 Eden 区越来越多,如果 Eden 区满,新创建的对象已经无法放入,就会触发年轻代的 GC,称为 Minor GC 或者 Young GC。Minor GC 会把需要 eden 中和 From 需要回收的对象回收,把没有回收的对象放入 To 区。
-
接下来,S0 会变成 To 区,S1 变成 From 区。当 eden 区满时再往里放入对象,依然会发生 Minor GC。
-
此时会回收 eden 区和 S1(from)中的对象,并把 eden 和 from 区中剩余的对象放入 S0。注意:每次 Minor GC 中都会为对象记录他的年龄,初始值为 0,每次 GC 完加 1。
-
如果 Minor GC 后对象的年龄达到阈值(最大 15,默认值和垃圾回收器有关),对象就会被晋升至老年代。
-
当老年代中空间不足,无法放入新的对象时,先尝试 minor gc 如果还是不足,就会触发 Full GC,Full GC 会对整个堆进行垃圾回收。
-
如果 Full GC 依然无法回收掉老年代的对象,那么当对象继续放入老年代时,就会抛出 Out Of Memory 异常。
为什么分代 GC 算法要把堆分成年轻代和老年代?首先我们要知道堆内存中对象的特性:
-
系统中的大部分对象,都是创建出来之后很快就不再使用可以被回收,比如用户获取订单数据,订单数据返回给用户之后就可以释放了。
-
老年代中会存放长期存活的对象,比如 Spring 的大部分 bean 对象,在程序启动之后就不会被回收了。
-
在虚拟机的默认设置中,新生代大小要远小于老年代的大小。
分代 GC 算法将堆分成年轻代和老年代主要原因有:
-
可以通过调整年轻代和老年代的比例来适应不同类型的应用程序,提高内存的利用率和性能。
-
新生代和老年代使用不同的垃圾回收算法,新生代一般选择复制算法,老年代可以选择标记-清除和标记-整理算法,由程序员来选择灵活度较高。
-
分代的设计中允许只回收新生代(minor gc),如果能满足对象分配的要求就不需要对整个堆进行回收(full gc),STW 时间就会减少。
5.4.5 三色标记法
5.5 垃圾回收器
5.5.1 Serial
Serial 是是一种单线程串行回收年轻代的垃圾回收器,采用复制算法。
**优点:**单 CPU 处理器下吞吐量非常出色
**缺点:**多 CPU 下吞吐量不如其他垃圾回收器,堆如果偏大会让用户线程处于长时间的等待
**适用场景:**Java 编写的客户端程序或者硬件配置有限的场景
流程: 垃圾回收时需要先 STW,因为是复制算法,需要将存活对象从年轻代的 from 移到 to 区域,物理地址会改变。**对象移动后,JVM 通过更新所有相关的 Java 层引用(虚拟地址层面的指针)来保证程序的正确性,而不是去修改底层操作系统的页表映射。**在此期间不允许用户访问存活对象,需要原子地完成对象移动和引用更新,如果访问会出现不存在等错误现象。
SerialOld 是 Serial 垃圾回收器的老年代版本,采用单线程串行回收,标记-整理算法。
**优点:**单 CPU 处理器下吞吐量非常出色
**缺点:**多 CPU 下吞吐量不如其他垃圾回收器,堆如果偏大会让用户线程处于长时间的等待
**适用场景:**与 Serial 垃圾回收器搭配使用,或者在 CMS 特殊情况下使用
**流程:**JVM 会先暂停所有用户线程(STW),然后由单个收集线程执行标记-整理算法------先标记出老年代中的所有存活对象,再将这些对象移动到堆的一端进行整理压缩,并更新相关引用,最后清理剩余空间,完成回收。
为什么需要一开始就 STW,只有第二阶段是移动对象,地址改变,到第二阶段再 STW 不行吗?
标记阶段必须基于一个"一致性快照"
所有追踪式垃圾收集算法(包括标记-复制和标记-整理)都包含"标记"阶段,其目的是找出所有存活对象 。进行可达性分析(即标记)时,理论上必须全过程都基于一个能保障一致性的快照 ,这意味着必须冻结用户线程(STW)。如果标记阶段允许用户线程并发运行,用户线程可能会修改对象之间的引用关系 ,导致标记结果出错(例如,本应存活的对象被错误标记为垃圾)。因此,为了保证标记结果的正确性,最简单的实现方式就是在标记阶段开始时就直接暂停所有用户线程 。
5.5.2 ParNew+CMS
Parallel New Generation 垃圾回收器本质上是对 Serial 在多 CPU 下的优化,使用多线程进行垃圾回收,复制算法。
**优点:**多 CPU 处理器下停顿时间较短
**缺点:**吞吐量和停顿时间不如 G1,所以在 JDK9 之后不建议使用
**适用场景:**JDK8 及之前的版本中,与 CMS 老年代垃圾回收器搭配使用
流程 :触发 Minor GC 后,先 STW 暂停所有用户线程,然后由多条收集器线程并行地执行标记-复制算法------标记存活对象,并将它们从 Eden 和 From Survivor 复制到 To Survivor(或晋升到老年代),最后清理原空间,完成回收。 其设计目标是利用多核处理器的并行能力来缩短单次 STW 的持续时间 ,但并未能减少 STW 发生的频率,其收集过程本身仍然是需要全局停顿的。
CMS(Concurrent Mark Sweep)垃圾回收器关注的是系统的暂停时间,允许用户线程和垃圾回收线程在某些步骤中同时执行,减少了用户线程的等待时间---标记清除算法。
**优点:**系统由于垃圾回收出现的停顿时间较短,用户体验好。
**缺点:**内存碎片问题;退化问题;浮动垃圾问题。
**适用场景:**大型的互联网系统中用户请求数据量大、频率高的场景,比如订单接口、商品接口等
CMS 执行步骤:
-
初始标记(CMS initial mark) :这是需要首次短暂停顿(STW) 的阶段。此阶段仅标记一下 GC Roots 能直接关联到的对象,速度非常快 。
-
并发标记(CMS concurrent mark) :这是 CMS 实现并发收集 的核心阶段。它会从 GC Roots 的直接关联对象开始,遍历整个对象图 ,找出所有存活对象 。这个过程耗时较长,但不需要停顿用户线程,可以与用户线程一起并发运行。
-
重新标记(CMS remark) :这是需要第二次短暂停顿(STW) 的阶段。它的目的是修正并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录。这个停顿时间会比初始标记稍长一些,但远比并发标记阶段的时间短。
-
并发清除(CMS concurrent sweep) :这个阶段负责清理删除掉在标记阶段被判断为已经死亡的对象 。由于 CMS 基于标记-清除算法,不需要移动存活对象 ,所以这个阶段同样可以与用户线程并发执行。
缺点:
-
CMS 使用了标记-清除算法,在垃圾收集结束之后会出现大量的内存碎片,CMS 会在 Full GC 时进行碎片的整理。这样会导致用户线程暂停,可以使用-XX:CMSFullGCsBeforeCompaction=N 参数(默认 0)调整 N 次 Full GC 之后再整理。
-
无法处理在并发清理过程中产生的"浮动垃圾",不能做到完全的垃圾回收。
-
如果老年代内存不足无法分配对象,CMS 就会退化成 Serial Old 单线程回收老年代。
**并发线程数:**在 CMS 中并发阶段运行时的线程数可以通过-XX:ConcGCThreads 参数设置,默认值为 0,由系统计算得出。
计算公式为(-XX:ParallelGCThreads 定义的线程数 + 3) / 4, ParallelGCThreads 是 STW 停顿之后的并行线程数
ParallelGCThreads 是由处理器核数决定的:
-
当 cpu 核数小于 8 时,ParallelGCThreads = CPU 核数
-
否则 ParallelGCThreads = 8 + (CPU 核数 -- 8 )*5/8
5.5.3 Parallel
Parallel Scavenge 是 JDK8 默认的年轻代垃圾回收器,多线程并行回收,关注的是系统的吞吐量。具备自动调整堆内存大小的特点 --- 复制算法。
**优点:**吞吐量高,而且手动可控。为了提高吞吐量,虚拟机会动态调整堆的参数。
**缺点:**不能保证单次的停顿时间。
**适用场景:**后台任务,不需要与用户交互,并且容易产生大量的对象。比如:大数据的处理,大文件导出。
流程: 当新生代空间不足触发 GC 时,Parallel Scavenge 会暂停所有用户线程(STW),然后由多线程并行执行标记-复制算法。整个流程的设计和具体细节(如区域大小)并非固定,而是可以通过参数设定吞吐量或停顿时间目标,并由虚拟机的自适应调节策略 动态优化,以达成其高吞吐量的核心目标 。
Parallel Scavenge 允许手动设置最大暂停时间和吞吐量。Oracle 官方建议在使用这个组合时,不要设置堆内存的最大值,垃圾回收器会根据最大暂停时间和吞吐量自动调整内存大小。
Parallel Old 是为 Parallel Scavenge 收集器设计的老年代版本,利用多线程并发收集 --- 标记-整理算法。
**优点:**并发收集,在多核 CPU 下效率较高。
**缺点:**暂停时间会比较长。
**适用场景:**与 Parallel Scavenge 配套使用。
5.5.4 G1
JDK9 之后默认的垃圾回收器是 G1(Garbage First)垃圾回收器。Parallel Scavenge 关注吞吐量,允许用户设置最大暂停时间 ,但是会减少年轻代可用空间的大小。CMS 关注暂停时间,但是吞吐量方面会下降。
而 G1 设计目标就是将上述两种垃圾回收器的优点融合:
-
支持巨大的堆空间回收,并有较高的吞吐量。
-
支持多 CPU 并行垃圾回收。
-
允许用户设置最大暂停时间。
G1 的整个堆会被划分成多个大小相等的区域,称之为区 Region,区域不要求是连续的。分为 Eden、Survivor、Old 区。Region 的大小通过堆空间大小/2048 计算得到,也可以通过参数-XX:G1HeapRegionSize=32m 指定(其中 32m 指定 region 大小为 32M),Region size 必须是 2 的指数幂,取值范围从 1M 到 32M。
年轻代回收(Young GC),回收 Eden 区和 Survivor 区中不用的对象。会导致 STW,G1 中可以通过参数
-XX:MaxGCPauseMillis=n(默认 200) 设置每次垃圾回收时的最大暂停时间毫秒数,G1 垃圾回收器会尽可能地保证暂停时间。
-
新创建的对象会存放在 Eden 区。当 G1 判断年轻代区不足(max 默认 60%),无法分配对象时需要回收时会执行 Young GC。
-
标记出 Eden 和 Survivor 区域中的存活对象
-
根据配置的最大暂停时间选择某些区域将存活对象复制到一个新的 Survivor 区中(年龄 +1),清空这些区域。
-
G1 在进行 Young GC 的过程中会去记录每次垃圾回收时每个 Eden 区和 Survivor 区的平均耗时,以作为下次回收时的参考依据。这样就可以根据配置的最大暂停时间计算出本次回收时最多能回收多少个 Region 区域了。比如 -XX:MaxGCPauseMillis=n(默认 200),每个 Region 回收耗时 40ms,那么这次回收最多只能回收 4 个 Region。
-
后续 Young GC 时与之前相同,只不过 Survivor 区中存活对象会被搬运到另一个 Survivor 区。
-
当某个存活对象的年龄到达阈值(默认 15),将被放入老年代。
-
部分对象如果大小超过 Region 的一半,会直接放入老年代,这类老年代被称为 Humongous 区。比如堆内存是 4G,每个 Region 是 2M,只要一个大对象超过了 1M 就被放入 Humongous 区,如果对象过大会横跨多个 Region。
-
多次回收之后,会出现很多 Old 老年代区,此时总堆占有率达到阈值时(-XX:InitiatingHeapOccupancyPercent 默认 45%)会触发混合回收 MixedGC。回收所有年轻代和部分老年代的对象以及大对象区。采用复制算法来完成。
混合回收
混合回收分为:初始标记(initial mark)、并发标记(concurrent mark)、最终标记(remark 或者 Finalize Marking)、并发清理(cleanup)。G1 对老年代的清理会选择存活度最低的区域来进行回收,这样可以保证回收效率最高。
注意:如果清理过程中发现没有足够的空 Region 存放转移的对象,会出现 Full GC。单线程执行标记-整理算法,此时会导致用户线程的暂停。所以尽量保证应该用的堆内存有一定多余的空间。
5.6 卡表
Java 的 CMS 垃圾回收器和 G1 垃圾回收器在记忆集的维护上有什么不同?
记忆集的一种最常用、最具体的实现方式是卡表(Card Table),两者可以理解为抽象接口与具体实现的关系。
在 G1 收集器中,每个 Region 都维护着自己的记忆集,这个记忆集记录了其他 Region 指向本 Region 的跨 Region 引用,并以卡页的粒度进行标识。
当需要回收某个 Eden Region 时,G1 收集器会执行以下步骤:
-
定位 GC Roots :除了传统的 GC Roots(如虚拟机栈、方法区中引用的对象等),为了实现部分区域收集 (Partial GC),确保可达性分析的正确性,还需要将与该回收区域关联的其他区域的对象也一并加入 GC Roots 集合。
-
利用记忆集快速查找关联对象 :这时,待回收 Region 自己的记忆集就发挥了关键作用。通过查閱这个记忆集,G1 可以快速、精确地知道有哪些其他的 Region(无论是 Eden、Survivor 还是 Old)中存在指向本 Region 内对象的引用。
-
有选择性地扫描,避免全堆扫描 :回收时,G1 会将这些被记忆集记录下来的、来自其他 Region 的引用对象 ,与传统的 GC Roots 一起作为本次收集的 GC Roots 起点,进行扫描和标记。这样,就不需要为了查找跨 Region 引用而扫描整个 Java 堆,从而极大地缩小了扫描范围,提升了收集效率。
我的理解:当回收 eden region 时,查看自己的卡表,发现有其他 region 指向自己(即其他 region 的对象引用了在我里面的 对象),无论是 eden 还是 old,不做区分,就可以快速定位到 GC Roots,去相应的 region 扫描+标记,而不是全堆扫描。
5.7 空间划分
为什么 Java 新生代被划分为 S0、S1 和 Eden 区?
6.监控调优
6.1 工具
6.1.1 Top
top 命令是 linux 下用来查看系统信息的一个命令,它提供给我们去实时地去查看系统的资源,比如执行时的进程、线程和系统参数等信息。进程使用的内存为 RES(常驻内存)- SHR(共享内存)
**优点:**操作简单;无额外的软件安装
**缺点:**只能查看最基础的进程信息,无法查看到每个部分的内存占用(堆、方法区、堆外)
第一行:系统概览
top - 12:18:44 up 4 days, 18:17, 0 user, load average: 0.00, 0.01, 0.00
top: 工具名,意为 "进程表的顶部"。
12:18:44: 当前系统时间。
up 4 days, 18:17: 系统运行时间 。单词up表示"自启动以来",这里表示系统已运行 4 天 18 小时 17 分钟,稳定性不错哦!💪
0 user: 登录用户数。当前有 0 个用户登录。
load average: 0.00, 0.01, 0.00: 系统平均负载 。这不是 CPU 使用率 ,而是系统在过去 1 分钟、5 分钟、15 分钟 的平均任务队列长度(等待运行的进程数)。对于单核 CPU,小于 1.00 表示负载很轻,您的系统很空闲。第二行:任务/进程 摘要
Tasks: 160 total, 1 running, 159 sleeping, 0 stopped, 0 zombie
Tasks: 任务/进程的总数。
running: 正在运行的进程数(占用 CPU 或在就绪队列中)。
sleeping: 休眠/等待状态的进程数(大部分进程都在此状态,等待资源)。
stopped: 被停止的进程数 (通常由信号SIGSTOP等控制)。
zombie: 僵尸进程数 。非常重要!🚨 这是指已经结束但父进程尚未"收尸"(读取其退出状态)的进程。如果数量非 0 且持续增长,表示程序有 bug,可能造成资源泄露。这里为 0,很健康。第三行:CPU 状态
%Cpu(s): 0.8 us, 1.7 sy, 0.0 ni, 97.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us(user ): 用户空间 CPU 占用率。运行普通用户程序(如您的 Java、Nginx 等)的 CPU 时间百分比。一般这个值高表示应用繁忙。
sy(system ): 内核空间 CPU 占用率 。运行系统内核进程的 CPU 时间百分比。如果us和sy加起来长期很高,说明 CPU 是瓶颈。
ni(nice ): 调整过优先级的用户进程 CPU 占用率 。nice值越高,优先级越低。
id(idle ): CPU 空闲率 。这个值越高越好 ,表明 CPU 有很多空闲时间。您这里高达 97.6%,系统负载非常轻。
wa(I/O wait ): 等待 I/O 的 CPU 时间百分比 。如果这个值长时间很高(如>20%),表示磁盘 I/O 可能是瓶颈(磁盘太慢或读写频繁)。您这里为 0,说明没有 I/O 等待问题。
hi(hardware interrupt ): 硬件中断占用率。
si(software interrupt ): 软件中断占用率。
st(steal time ): 被偷走的时间 。仅在虚拟化环境(如云服务器)有意义。表示宿主机从您的虚拟机"偷走"CPU 给其他虚拟机用的时间。如果这个值高,说明宿主机资源紧张。第四、五行 :内存与交换空间
MiB Mem : 3656.7 total, 200.5 free, 2222.2 used, 1537.7 buff/cacheMiB Swap: 1025.0 total, 548.1 free, 476.9 used. 1434.5 avail Mem
total: 物理内存总量 。这里是 3.6 GB。
free: 完全未使用的内存 。这个数字不一定代表内存紧张。
used: 已使用的内存。包括应用程序内存和缓存。
buff/cache: 内核缓冲区(buffer)和页缓存(cache)占用的内存 。这部分内存在应用程序需要时可以快速释放 ,所以Linux设计理念是尽量利用内存做缓存 ,只要free不是特别低就正常。
avail Mem: 可供应用程序使用的内存估算值 (比free更准确)。这里约 1.4 GB 可用,内存充足。
Swap: 交换分区 。当物理内存不足时,会将不常用的内存页交换到硬盘上。used交换空间有使用是正常的,但如果持续增长,说明物理内存可能不足。进程列表字段
这是每个进程的详细信息:
PID: 进程 ID。每个进程的唯一身份证号码。
USER: 进程所有者。
PR(Priority ) &NI(Nice Value ): 进程优先级 。PR是内核看到的动态优先级,NI是用户可调整的静态优先级(范围 -20 到 19,值越低优先级越高)。
VIRT: 虚拟内存使用量。进程申请的总地址空间。
RES(Resident Memory ): 常驻内存/物理内存使用量 。这是进程实际占用的、不能被置换出去的物理内存 ,是我们最关心的内存指标。
SHR(Shared Memory ): 共享内存大小。可能被其他进程共享的部分。
S(Process Status ): 进程状态。常见值:
R(Running): 运行中/可运行
S(Sleeping): 休眠中(等待事件)
D(Disk Sleep): 不可中断休眠(通常与 I/O 相关)
Z(Zombie): 僵尸进程(需要关注)
T(Stopped): 被信号停止
%CPU: 进程的 CPU 使用率 。是单个核心的百分比,所以多核 CPU 上总和可能超过 100%。
%MEM: 进程的物理内存使用率 (占Mem total的百分比)。
TIME+: 进程使用的累计 CPU 时间 ,格式是分:秒.毫秒。这里java进程占用了15.9%的内存,是当前的内存消耗大户。
COMMAND: 启动进程的命令名 。按c键可以切换显示完整命令行。
6.1.2 VisualVM
优点:
-
功能丰富,实时监控 CPU、内存、线程等详细信息
-
支持 Idea 插件,开发过程中也可以使用
缺点:
对大量集群化部署的 Java 进程需要手动进行管理
如果需要进行远程监控,可以通过 jmx 方式进行连接。在启动 java 程序时添加如下参数:
6.1.3 Arthas
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load 、内存 、gc 、线程的状态信息 ,并能在不修改应用代码的情况下,对业务问题进行诊断 ,包括**查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,**大大提升线上问题排查效率。
优点:
-
功能强大,不止于监控基础的信息,还能监控单个方法的执行耗时等细节内容。
-
支持应用的集群管理。
**缺点:**部分高级功能使用门槛较高。
使用阿里 arthas tunnel 管理所有的需要监控的程序。
6.1.4 Prometheus+Grafana
6.2 堆内存溢出原因
6.2.1 equals()和 hashCode()
在定义新类时没有重写正确的 equals()和 hashCode()方法。在使用 HashMap 的场景下,如果使用这个类对象作为 key,HashMap 在判断 key 是否已经存在时会使用这些方法,如果重写方式不正确,会导致相同的数据被保存多份。
异常情况:
-
hashCode 方法实现不正确,会导致相同 id 的学生对象计算出来的 hash 值不同,可能会被分到不同的槽中
-
equals 方法实现不正确,会导致 key 在比对时,即便学生对象的 id 是相同的,也被认为是不同的 key。
-
长时间运行之后 HashMap 中会保存大量相同 id 的学生数据。
解决方案:
-
在定义新实体时,始终重写 equals()和 hashCode()方法。
-
重写时一定要确定使用了唯一标识去区分不同的对象,比如用户的 id 等。
-
hashmap 使用时尽量使用编号 id 等数据作为 key,不要将整个实体类对象作为 key 存放。
6.2.2 内部类引用外部类
异常清理:
-
非静态的内部类默认会持有外部类,尽管代码上不再使用外部类,所以如果有地方引用了这个非静态内部类,会导致外部类也被引用,垃圾回收时无法回收这个外部类。
-
匿名内部类对象如果在非静态方法中被创建,会持有调用者对象,垃圾回收时无法回收调用者。
解决方案:
-
这个案例中,使用内部类的原因是可以直接获取到外部类中的成员变量值,简化开发。如果不想持有外部类对象,应该使用静态内部类。
-
使用静态方法,可以避免匿名内部类持有调用者对象。
6.2.3 ThreadLocal
**问题:**如果仅仅使用手动创建的线程,就算没有调用 ThreadLocal 的 remove 方法清理数据,也不会产生内存泄漏。因为当线程被回收时,ThreadLocal 也同样被回收。但是如果使用线程池就不一定了。
解决方案: 线程方法执行完,一定要调用 ThreadLocal 中的 remove 方法清理对象。调用 remove()方法会直接删除当前线程 ThreadLocalMap 中的对应 Entry。
6.2.4 String 的 intern 方法
**问题:**JDK6 中字符串常量池位于堆内存中的 Perm Gen 永久代中,如果不同字符串的 intern 方法被大量调用,字符串常量池会不停的变大超过永久代内存上限之后就会产生内存溢出问题。
解决方案:
-
注意代码中的逻辑,尽量不要将随机生成的字符串加入字符串常量池
-
增大永久代空间的大小,根据实际的测试/估算结果进行设置-XX:MaxPermSize=256M
6.2.5 通过静态字段保存对象
**问题:**如果大量的数据在静态变量中被长期引用,数据就不会被释放,如果这些数据不再使用,就成为了内存泄漏。
解决方案:
-
尽量减少将对象长时间的保存在静态变量中,如果不再使用,必须将对象删除(比如在集合中)或者将静态变量设置为 null。
-
使用单例模式时,尽量使用懒加载,而不是立即加载。
-
Spring 的 Bean 中不要长期存放大对象,如果是缓存用于提升性能,尽量设置过期时间定期失效。
6.2.6 资源没有正常关闭
**问题:**连接和流这些资源会占用内存,如果使用完之后没有关闭,这部分内存不一定会出现内存泄漏,但是会导致 close 方法不被执行。
同学们可以测试一下这段代码会不会产生内存泄漏,应该是不会的。但是这个结论不是确定的,所以建议编程时养成良好的习惯,尽量关闭不再使用的资源。
解决方案:
-
为了防止出现这类的资源对象泄漏问题,必须在 finally 块中关闭不再使用的资源。
-
从 Java 7 开始,使用 try-with-resources 语法可以用于自动关闭资源。
6.2.7 并发请求问题
通过发送请求向 Java 应用获取数据,正常情况下 Java 应用将数据返回之后,这部分数据就可以在内存中被释放掉。
接收到请求时创建对象 --- 响应返回之后,对象就可以被回收掉。
并发请求问题 指的是由于用户的并发请求量有可能很大 ,同时处理数据的时间很长 ,导致大量的数据存在于内存中 ,最终超过了内存的上限 ,导致内存溢出。这类问题的处理思路和内存泄漏类似,首先要定位到对象产生的根源。
6.3 诊断
6.3.1 内存快照
当堆内存溢出时,需要在堆内存溢出时将整个堆内存保存下来,生成内存快照(Heap Profile )文件。
使用 MAT 打开 hprof 文件,并选择内存泄漏检测功能,MAT 会自行根据内存快照中保存的数据分析内存泄漏的根源。
生成内存快照的 Java 虚拟机参数:
-XX:+HeapDumpOnOutOfMemoryError:发生 OutOfMemoryError 错误时,自动生成 hprof 内存快照文件。
-XX:HeapDumpPath=<path>:指定 hprof 文件的输出路径。
使用 MAT 打开 hprof 文件,并选择内存泄漏检测功能,MAT 会自行根据内存快照中保存的数据分析内存泄漏的根源。
使用 MAT 打开 hprof 文件,首页就展示了 MAT 检测出来的内存泄漏问题原因。
导出运行中系统的内存快照,比较简单的方式有两种,注意只需要导出标记为存活的对象
-
通过 JDK 自带的jmap 命令导出,格式为:
jmap -dump:live,format=b,file=文件路径和文件名 进程ID,先使用jps或者ps -ef查看进程 ID。 -
通过 arthas 的 heapdump 命令导出,格式为:
heapdump --live 文件路径和文件名。
在程序员开发用的机器内存范围之内的快照文件,直接使用 MAT 打开分析即可。
但是经常会遇到服务器上的程序占用的内存达到 10G 以上,开发机无法正常打开此类内存快照,此时需要下载服务器操作系统对应的 MAT。
说白了就是,本地电脑内存不够不能打开快照文件,就用内存更大的服务器下载 MAT 去分析快照文件,然后将分析报告下载到本地查看。
6.3.2 在线定位问题
诊断问题有三种方法,优先级由高到低:
日志定位 ──→ 90%的问题在这里解决
↓ 搞不定
Arthas ────→ 动态看运行时状态,定位活着的问题
↓ 还搞不定 / 需要完整现场
内存快照 ──→ 把"尸体"带回来解剖,信息最全但最笨重
生成内存快照并分析
**优点:**通过完整的内存快照准确地判断出问题产生的原因
**缺点:**内存较大时,生成内存快照较慢,这个过程中会影响用户的使用;通过 MAT 分析内存快照,至少要准备 1.5 -- 2 倍大小的内存空间
在线定位问题
**优点:**无需生成内存快照,整个过程对用户的影响较小
**缺点:**无法查看到详细的内存信息;需要通过 arthas 或者 btrace 工具调测发现问题产生的原因,需要具备一定的经验。
6.4 GC 调优
6.4.1 工具
- Jstat工具是 JDK 自带的一款监控工具,可以提供各种垃圾回收、类加载、编译信息等不同的数据。
使用方法为: jstat -gc 进程ID 每次统计的间隔(毫秒) 统计次数 。
**优点:**操作简单;无额外的软件安装。
**缺点:**无法精确到 GC 产生的时间,只能用于判断 GC 是否存在问题 。
- VisualVm 中提供了一款Visual GC 插件 ,实时监控 Java 进程的堆内存结构 、堆内存变化趋势 以及垃圾回收时间 的变化趋势。同时还可以监控对象晋升的直方图。
**优点:**适合开发使用,能直观的看到堆内存和 GC 的变化趋势。
**缺点:**对程序运行性能有一定影响;生产环境程序员一般没有权限进行操作。
- 通过 GC 日志,可以更好的看到垃圾回收细节上的数据,同时也可以根据每款垃圾回收器的不同特点更好地发现存在的问题。
使用方法(JDK 8 及以下):-XX:+PrintGCDetails -Xloggc:文件名
使用方法(JDK 9+):-Xlog:gc*:file=文件名
- 分析 GC 日志 - GCViewer
GCViewer 是一个将 GC 日志转换成可视化图表的小工具,github 地址: https://github.com/chewiebug/GCViewer
使用方法:java -jar gcviewer_1.3.4.jar 日志文件.log
- 分析 GC 日志 - GCEasy
GCeasy 是业界首款使用 AI 机器学习技术在线进行 GC 分析和诊断的工具。定位内存泄漏、GC 延迟高的问题,提供 JVM 参数优化建议,支持在线的可视化工具图表展示。
官方网站:https://gceasy.io/
6.4.2 调优方法
解决 GC 问题的手段中,前三种是比较推荐的手段,第四种仅在前三种无法解决时选用:
-
优化基础 JVM 参数,基础 JVM 参数的设置不当,会导致频繁 FULLGC 的产生
-
减少对象产生,大多数场景下的 FULLGC 是由于对象产生速度过快导致的,减少对象产生可以有效的缓解 FULLGC 的发生
-
更换垃圾回收器,选择适合当前业务场景的垃圾回收器,减少延迟、提高吞吐量
-
优化垃圾回收器参数,优化垃圾回收器的参数,能在一定程度上提升 GC 效率
6.5 OOM
方法区中类卸载的条件非常苛刻:
这个类所有实例都被回收、加载这个类的 ClassLoader 被回收、这个类的 Class 对象没有被引用。关键卡点在 ClassLoader,像 AppClassLoader 这种系统类加载器是不会被回收的,它加载的类也就永远卸不掉。Spring 的类都是 AppClassLoader 加载的,所以正常情况下这些类一直驻留内存。只有用自定义 ClassLoader 加载的类,把 ClassLoader 置空才有机会卸载。
6.6 内存泄露排查
6.7 GC 触发
young GC、old GC、full GC 和 mixed GC 的区别是什么?
7.JIT
7.1 触发条件
JIT 不是一上来就编译所有代码,它只关心热点代码。HotSpot 用两个计数器来判断:
-
方法调用计数器:记录方法被调用的次数,默认阈值 1 万次(可以通过 -XX:CompileThreshold 调整)
-
回边计数器:记录循环体执行的次数,循环跑得多也算热点
任意一个计数器超过阈值,就触发 JIT 编译。编译完成前程序不会停下来等,而是继续用解释器跑,编译好了再切换过去,这叫栈上替换(OSR,On-Stack Replacement)。
JIT 编译是异步的,有专门的编译线程在后台跑。触发编译后程序不会停下来等,继续用解释器执行当前代码。编译完成后通过 OSR 技术把解释执行切换成编译后的机器码。所以用户感知不到编译过程,只会感觉程序越跑越快。
7.2 分层编译
HotSpot 虚拟机从 JDK 7 开始引入分层编译(Tiered Compilation),把编译分成 5 个层级:
-
第 0 层:纯解释执行,不做任何编译优化
-
第 1 层:C1 编译器编译,不开启性能监控
-
第 2 层:C1 编译器编译,开启方法调用计数和回边计数
-
第 3 层:C1 编译器编译,开启全部性能监控
-
第 4 层:C2 编译器编译,做激进优化
C1 编译器编译速度快但优化程度低,C2 编译器编译慢但能做逃逸分析、标量替换这些激进优化。分层编译让 JVM 可以根据代码的热度动态选择编译级别,冷代码用解释器或 C1 凑合跑,热点代码上 C2 榨干性能。
7.3 核心优化技术
-
方法内联:把被调用方法的代码直接嵌入调用处,省掉方法调用的栈帧开销。比如 getter/setter 这种小方法,内联后跟直接访问字段一样快。
-
逃逸分析:分析对象的作用域,如果一个对象只在方法内部使用、不会逃逸到外部,JIT 可以把它分配在栈上而不是堆上,省掉 GC 压力;甚至直接把对象拆成几个基本类型变量,这叫标量替换。
-
循环展开:把循环体复制多份减少循环判断次数。比如原来循环 100 次,展开后变成循环 25 次但每次执行 4 份代码,减少了 75 次循环判断。
-
空值检查消除:如果 JIT 分析出某个引用不可能为 null,就把 null 检查的指令删掉。
7.4 逃逸分析
逃逸分两种程度:
-
方法逃逸:对象被 return 出去了,或者作为参数传给别的方法,总之跑出了当前方法的作用域。
-
线程逃逸:对象被赋值给静态变量、实例变量,或者被其他线程访问到了,这种逃逸程度最高。
根据逃逸分析的结果,JVM 能做三种优化:
-
栈上分配:对象没逃逸,直接在栈帧里分配,方法一结束内存就跟着回收了,压根不用 GC 操心。
-
标量替换:如果对象没逃逸,JVM 干脆把对象"打散",把里面的字段当成独立的局部变量来用,连对象头都省了。优化后这些对象全变成栈上的基本类型变量。
-
同步消除:对象只在单线程内使用、不会被其他线程看到,那加在上面的 synchronized 就是多余的,直接去掉。
7.5 AOT
JIT 编译流程:Java 源码编译成字节码,JVM 启动后解释执行字节码,运行时 JIT 编译器检测热点代码,将热点代码编译成机器码缓存起来。
AOT 编译流程:Java 源码编译成字节码,构建阶段 AOT 编译器将字节码编译成机器码,打包成可执行文件,运行时直接执行机器码,无需 JVM。
简单说,JIT 擅长长时间运行的服务,跑得越久优化越到位;AOT 擅长启动快、用完就走的场景。
AOT 编译需要在构建阶段确定所有会用到的类和方法,但 Java 有很多动态特性会在运行时才知道具体类型:
-
反射:
Class.forName("com.example.Foo")这种代码,编译器不知道 Foo 是啥,需要手动配置 reflect-config.json 告诉它。 -
动态代理:JDK Proxy、CGLIB 生成的代理类在运行时才产生,AOT 编译器看不到。
-
序列化:JSON 序列化框架通常用反射读写字段,需要额外配置。
-
类路径扫描:Spring 的
@ComponentScan会扫描 classpath 下的类,AOT 模式下需要提前分析好。
Spring Boot 3.0 和 Quarkus 为了支持 Native Image,做了大量适配工作,在构建阶段就把这些动态行为静态化了。
为什么 Serverless 场景特别需要 AOT?
Serverless 的计费模式是按调用次数和执行时间收费的,启动时间也算在执行时间里。传统 Java 应用启动要 3~5 秒,这 3 秒就是白花钱。而且云厂商为了节省资源,会在没有请求的时候把你的实例销毁,下次请求来了再重新拉起,这就是冷启动 。如果冷启动要好几秒,用户体验就很差。用 AOT 编译成 native image 后,冷启动能降到几十毫秒,跟 Node.js、Go 一个级别,Java 终于能在 Serverless 领域跟其他语言竞争了。
7.6 Code Cache
JIT 编译生成的机器码存在 Code Cache 里,这是一块独立于堆的本地内存区域。
Code Cache 直接向操作系统申请内存,不受 -Xmx 参数控制。JIT 编译器把热点方法编译成机器码后就塞进这块区域,下次调用直接跑机器码,不用再走解释执行。
Java 9 之后,Code Cache 被拆成了三个独立的区域,每个区存不同类型的代码:
-
**non-method 区:**存的不是 Java 方法,是 JVM 内部用的代码,比如编译器生成的桩代码、适配器代码。这部分代码生命周期跟 JVM 一样长,基本不会被回收。
-
**profiled 区:**存 C1 编译器生成的代码,带着性能采样信息。这些代码是过渡性质的,等 C2 编译器生成更优化的版本后就会被替换掉。
-
**non-profiled 区:**存 C2 编译器生成的完全优化代码,还有一些不需要再优化的 C1 代码。这是最终形态,性能最好。
分区的好处是减少内存碎片 。以前所有代码混在一起,**短命的 profiled 代码被回收后留下一堆小空洞,大的编译结果塞不进去。**分开之后各玩各的,碎片问题好多了。
Code Cache 满了会怎么样?
JIT 编译器就被强制关闭,控制台会蹦出这行警告:
从这一刻起,所有新执行的代码都只能走解释器,性能直接跳水。更坑的是,已经编译好的代码还占着空间,新的热点方法进不来,老的冷门方法又不会主动让位。
碰到这种情况有几个思路:
-
调大 Code Cache:
-XX:ReservedCodeCacheSize=256m,简单粗暴 -
开启代码刷新:
-XX:+UseCodeCacheFlushing,让 JVM 把一些冷代码踢出去腾地方 -
排查是不是代码写法有问题:比如大量动态生成类、反射调用过多,每个都要编译一份机器码
7.7 监控
运行时可以通过 JMX 拿到 Code Cache 的使用情况,MBean 名字是 java.lang:type=MemoryPool,name=Code Cache。
也可以加启动参数让 JVM 自己打日志:java -XX:+PrintCodeCache -XX:+PrintCompilation -jar app.jar
-XX:+PrintCompilation 会打印每个方法的编译事件,能看到什么时候编译的、用的哪个编译器、编译后多大。
如果用的是 Java 9+,用 jcmd 命令更方便:
输出会告诉你三个分区分别用了多少、剩多少、有多少方法被编译了。
8.读写屏障
什么是 Java 中的 logging write barrier?
9.参数
10.1 栈
要修改 Java 虚拟机栈的大小,可以使用虚拟机参数 -Xss 。
-
语法:-Xss 栈大小
-
单位:字节(默认,必须是 1024 的倍数)、k 或者 K(KB)、m 或者 M(MB)、g 或者 G(GB)
10.2 堆
要修改堆的大小,可以使用虚拟机参数 --Xmx(max 最大值)和-Xms (初始的 total)。
语法:-Xmx值 -Xms值
单位:字节(默认,必须是 1024 的倍数)、k 或者 K(KB)、m 或者 M(MB)、g 或者 G(GB)
限制:Xmx 必须大于 2 MB,Xms 必须大于 1MB
建议将-Xmx 和-Xms 设置为相同的值,这样在程序启动之后可使用的总内存就是最大内存,而无需向 java 虚拟机再次申请,减少了申请并分配内存时间上的开销,同时也不会出现内存过剩之后堆收缩的情况。
10.3 TLAB
TLAB 默认开启,一般不用动。但如果需要调优可以用这些参数:
-
-XX:+UseTLAB启用 TLAB,默认就是开的 -
-XX:-UseTLAB禁用 TLAB,几乎不会用 -
-XX:TLABSize=512k设置初始 TLAB 大小,JVM 会动态调整所以一般不手动设 -
-XX:+PrintTLAB打印 TLAB 的分配信息,调优时用来分析
10.4 直接内存
但需要设置直接内存的最大值。如果需要手动调整直接内存的大小,可以使用XX:MaxDirectMemorySize=大小
10.5 GC
-XX:+UseSerialGC 新生代、老年代都使用串行回收器。
-XX:+UseParNewGC 新生代使用 ParNew 回收器, 老年代使用串行回收器
参数:XX:+UseConcMarkSweepGC
Parallel Scavenge允许手动设置最大暂停时间和吞吐量。Oracle 官方建议在使用这个组合时,不要设置堆内存的最大值,垃圾回收器会根据最大暂停时间和吞吐量自动调整内存大小。
-
最大暂停时间,
-XX:MaxGCPauseMillis=n设置每次垃圾回收时的最大停顿毫秒数 -
吞吐量,
-XX:GCTimeRatio=n设置吞吐量为 n(用户线程执行时间 = n/n + 1) -
自动调整内存大小,
-XX:+UseAdaptiveSizePolicy设置可以让垃圾回收器根据吞吐量和最大停顿的毫秒数自动调整内存大小
Parallel Old是为 Parallel Scavenge 收集器设计的老年代版本,利用多线程并发收集。
参数: -XX:+UseParallelGC 或
-XX:+UseParallelOldGC 可以使用 Parallel Scavenge + Parallel Old 这种组合。
**G1:**通过参数-XX:G1HeapRegionSize=32m 指定(其中 32m 指定 region 大小为 32M),Region size 必须是 2 的指数幂,取值范围从 1M 到 32M。
G1 中可以通过参数-XX:MaxGCPauseMillis=n(默认 200) 设置每次垃圾回收时的最大暂停时间毫秒数,
(-XX:InitiatingHeapOccupancyPercent 默认 45%)会触发混合回收 MixedGC。回收所有年轻代和部分老年代的对象以及大对象区。采用复制算法来完成。
内存快照:
-XX:+HeapDumpOnOutOfMemoryError:发生 OutOfMemoryError 错误时,自动生成 hprof 内存快照文件。
-XX:HeapDumpPath=<path>:指定 hprof 文件的输出路径。
使用方法(JDK 8 及以下):-XX:+PrintGCDetails -Xloggc:文件名
使用方法(JDK 9+):-Xlog:gc*:file=文件名